


DeepSeek’s new AI model appears to be one of the best ‘open’ challengers yet
Kyle Wiggers
11:44 AM PST · December 26, 2024
A Chinese lab has created what appears to be one of the most powerful “open” AI models to date.
The model, DeepSeek V3, was developed by the AI firm DeepSeek and was released on Wednesday under a permissive license that allows developers to download and modify it for most applications, including commercial ones.
DeepSeek V3 can handle a range of text-based workloads and tasks, like coding, translating, and writing essays and emails from a descriptive prompt.
According to DeepSeek’s internal benchmark testing, DeepSeek V3 outperforms both downloadable, “openly” available models and “closed” AI models that can only be accessed through an API. In a subset of coding competitions hosted on Codeforces, a platform for programming contests, DeepSeek outperforms other models, including Meta’s Llama 3.1 405B, OpenAI’s GPT-4o, and Alibaba’s Qwen 2.5 72B.
DeepSeek V3 also crushes the competition on Aider Polyglot, a test designed to measure, among other things, whether a model can successfully write new code that integrates into existing code.
DeepSeek-V3!
60 tokens/second (3x faster than V2!)
API compatibility intact
Fully open-source models & papers
671B MoE parameters
37B activated parameters
Trained on 14.8T high-quality tokens
Beats Llama 3.1 405b on almost every benchmark x.com pic.twitter.com/jVwJU07dqf
— Chubby(@kimmonismus) December 26, 2024
DeepSeek claims that DeepSeek V3 was trained on a dataset of 14.8 trillion tokens. In data science, tokens are used to represent bits of raw data — 1 million tokens is equal to about 750,000 words.
It’s not just the training set that’s massive. DeepSeek V3 is enormous in size: 685 billion parameters. (Parameters are the internal variables models use to make predictions or decisions.) That’s around 1.6 times the size of Llama 3.1 405B, which has 405 billion parameters.
DeepSeek (Chinese AI co) making it look easy today with an open weights release of a frontier-grade LLM trained on a joke of a budget (2048 GPUs for 2 months, $6M).
For reference, this level of capability is supposed to require clusters of closer to 16K GPUs, the ones being… x.com
— Andrej Karpathy (@karpathy) December 26, 2024
Parameter count often (but not always) correlates with skill; models with more parameters tend to outperform models with fewer parameters. But large models also require beefier hardware in order to run. An unoptimized version of DeepSeek V3 would need a bank of high-end GPUs to answer questions at reasonable speeds.
While it’s not the most practical model, DeepSeek V3 is an achievement in some respects. DeepSeek was able to train the model using a data center of Nvidia H800 GPUs in just around two months — GPUs that Chinese companies were recently restricted by the U.S. Department of Commerce from procuring. The company also claims it only spent $5.5 million to train DeepSeek V3, a fraction of the development cost of models like OpenAI’s GPT-4.
The downside is that the model’s political views are a bit filtered. Ask DeepSeek V3 about Tiananmen Square, for instance, and it won’t answer.
DeepSeek, being a Chinese company, is subject to benchmarking by China’s internet regulator to ensure its models’ responses “embody core socialist values.” Many Chinese AI systems decline to respond to topics that might raise the ire of regulators, like speculation about the Xi Jinping regime.
DeepSeek, which recently unveiled DeepSeek-R1, an answer to OpenAI’s o1 “reasoning” model, is a curious organization. It’s backed by High-Flyer Capital Management, a Chinese quantitative hedge fund that uses AI to inform its trading decisions.
DeepSeek’s models have forced competitors like ByteDance, Baidu, and Alibaba to cut the usage prices for some of their models — and make others completely free.
High-Flyer builds its own server clusters for model training, one of the most recent of which reportedly has 10,000 Nvidia A100 GPUs and costs 1 billion yen (~$138 million). Founded by Liang Wenfeng, a computer science graduate, High-Flyer aims to achieve “superintelligent” AI through its DeepSeek org.
In an interview earlier this year, Liang described open sourcing as a “cultural act” and characterized closed source AI like OpenAI’s a “temporary” moat. “Even OpenAI’s closed-source approach hasn’t stopped others from catching up,” he noted.
Indeed.



 Paper:
Paper:  Website:
Website:  Demo:
Demo:  Code:
Code:  Models:
Models: 








/cdn.vox-cdn.com/uploads/chorus_asset/file/25820684/Screenshot_2025_01_06_at_11.08.31_PM_1_2_.png)
:format(webp)/cdn.vox-cdn.com/uploads/chorus_asset/file/25820684/Screenshot_2025_01_06_at_11.08.31_PM_1_2_.png "Nvidia CEO Jensen Huang holding the Project Digits computer on stage at Nvidia’s CES 2025 press conference.")
:format(webp)/cdn.vox-cdn.com/uploads/chorus_asset/file/25820689/chrome_HV8SYeFAav.png "Project Digits looks like a mini PC.")
:format(webp)/cdn.vox-cdn.com/uploads/chorus_asset/file/25820687/chrome_NP3LJVKJfM.png "The Digits supercomputer specs.")



























 Both PRM and Policy used the same starting dataset (747k Math Problems)
Both PRM and Policy used the same starting dataset (747k Math Problems) Generates code-augmented Chain of Thought reasoning, not only text
Generates code-augmented Chain of Thought reasoning, not only text PRM training data uses MCTS rollouts based on code verification (0/1) and if it lead to a successful solution
PRM training data uses MCTS rollouts based on code verification (0/1) and if it lead to a successful solution Solves 8 out of 15 problems on AIME 2024, placing in the top 20% of high school math competitors
Solves 8 out of 15 problems on AIME 2024, placing in the top 20% of high school math competitors Self-evolution (Self-Improvement) through 4 rounds to improve performance from 60% to 90.25%
Self-evolution (Self-Improvement) through 4 rounds to improve performance from 60% to 90.25% Evolution of Hugging Face NuminaMath, MuMath, ToRA
Evolution of Hugging Face NuminaMath, MuMath, ToRA








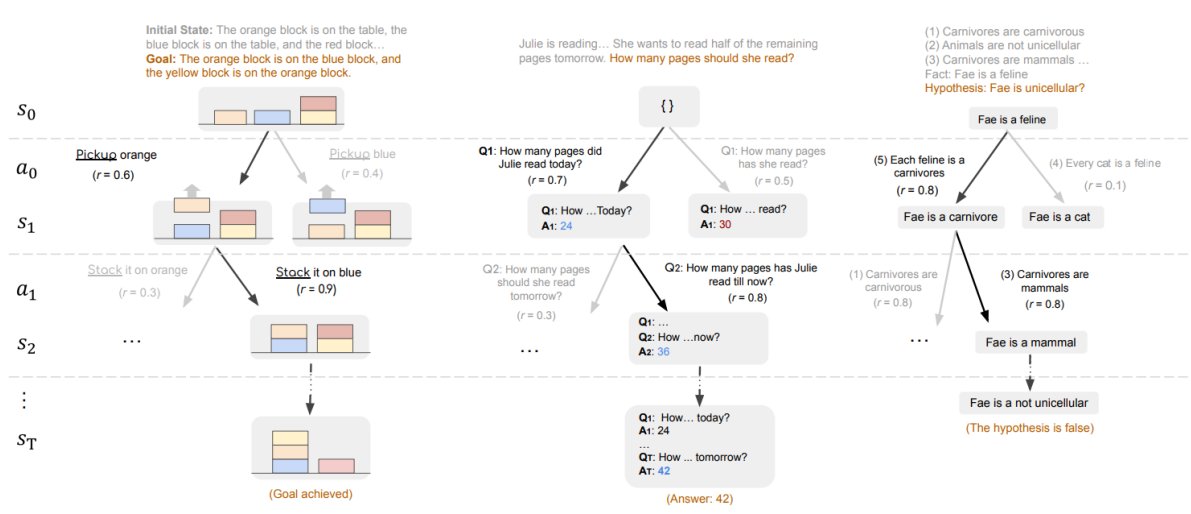
 Initialize the policy model and PRM with the SFT model (also ref model).
Initialize the policy model and PRM with the SFT model (also ref model). Generate rollouts (256 prompts with 4 responses each) using the policy model.
Generate rollouts (256 prompts with 4 responses each) using the policy model. Score the rollouts using the implicit PRM and outcome verifier.
Score the rollouts using the implicit PRM and outcome verifier. Filter prompts based on accuracy (keep only those with 20-80% success rate)
Filter prompts based on accuracy (keep only those with 20-80% success rate) Calculate outcome (binary reward) and process rewards (likelihood for between tokens) to update the policy model.
Calculate outcome (binary reward) and process rewards (likelihood for between tokens) to update the policy model. Update the implicit PRM on the rollouts with the outcome reward.
Update the implicit PRM on the rollouts with the outcome reward. Perform advantage estimation with RLOO, separately for outcome and process rewards.
Perform advantage estimation with RLOO, separately for outcome and process rewards. Update the policy using PPO loss.
Update the policy using PPO loss. PRIME 7B achieved to 26.7% pass@1 on AIME 2024 vs. 3.3% SFT / 9.3% GPT-4o.
PRIME 7B achieved to 26.7% pass@1 on AIME 2024 vs. 3.3% SFT / 9.3% GPT-4o. Updating PRM avoids reward hacking and maintains reward accuracy.
Updating PRM avoids reward hacking and maintains reward accuracy. Implicit PRM accelerates training up to 2.5 and improves the final rewards by 6.9% compared to ORM only.
Implicit PRM accelerates training up to 2.5 and improves the final rewards by 6.9% compared to ORM only. Removing prompts that are too easy or too hard stabilized training and improving final performance.
Removing prompts that are too easy or too hard stabilized training and improving final performance.

 Small models with many samples can outperform single attempts from larger models
Small models with many samples can outperform single attempts from larger models Performance scales log-linearly with number of samples
Performance scales log-linearly with number of samples Automatic verifiers (like unit tests) scale better
Automatic verifiers (like unit tests) scale better 5 samples + DeepSeek-Coder outperformed zero-shot GPT-4 at 1/3 the cost
5 samples + DeepSeek-Coder outperformed zero-shot GPT-4 at 1/3 the cost Verification methods (voting, reward models) plateau after ~100 samples
Verification methods (voting, reward models) plateau after ~100 samples Need clear criteria for what makes a "good" generation
Need clear criteria for what makes a "good" generation
 below!
below!
























 Model weights: huggingface.co/NovaSky-AI/Sk…
Model weights: huggingface.co/NovaSky-AI/Sk…




