1/2
 Today we’re premiering Meta Movie Gen: the most advanced media foundation models to-date.
Today we’re premiering Meta Movie Gen: the most advanced media foundation models to-date.
Developed by AI research teams at Meta, Movie Gen delivers state-of-the-art results across a range of capabilities. We’re excited for the potential of this line of research to usher in entirely new possibilities for casual creators and creative professionals alike.
More details and examples of what Movie Gen can do Meta Movie Gen - the most advanced media foundation AI models
Meta Movie Gen - the most advanced media foundation AI models
 Movie Gen models and capabilities
Movie Gen models and capabilities
Movie Gen Video: 30B parameter transformer model that can generate high-quality and high-definition images and videos from a single text prompt.
Movie Gen Audio: A 13B parameter transformer model that can take a video input along with optional text prompts for controllability to generate high-fidelity audio synced to the video. It can generate ambient sound, instrumental background music and foley sound — delivering state-of-the-art results in audio quality, video-to-audio alignment and text-to-audio alignment.
Precise video editing: Using a generated or existing video and accompanying text instructions as an input it can perform localized edits such as adding, removing or replacing elements — or global changes like background or style changes.
Personalized videos: Using an image of a person and a text prompt, the model can generate a video with state-of-the-art results on character preservation and natural movement in video.
We’re continuing to work closely with creative professionals from across the field to integrate their feedback as we work towards a potential release. We look forward to sharing more on this work and the creative possibilities it will enable in the future.
2/2
As part of our continued belief in open science and progressing the state-of-the-art in media generation, we’ve published more details on Movie Gen in a new research paper for the academic community https://go.fb.me/toz71j
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
Today we’re premiering Meta Movie Gen: the most advanced media foundation models to-date.Developed by AI research teams at Meta, Movie Gen delivers state-of-the-art results across a range of capabilities. We’re excited for the potential of this line of research to usher in entirely new possibilities for casual creators and creative professionals alike.
More details and examples of what Movie Gen can do
Meta Movie Gen - the most advanced media foundation AI models Movie Gen models and capabilitiesMovie Gen Video: 30B parameter transformer model that can generate high-quality and high-definition images and videos from a single text prompt.
Movie Gen Audio: A 13B parameter transformer model that can take a video input along with optional text prompts for controllability to generate high-fidelity audio synced to the video. It can generate ambient sound, instrumental background music and foley sound — delivering state-of-the-art results in audio quality, video-to-audio alignment and text-to-audio alignment.
Precise video editing: Using a generated or existing video and accompanying text instructions as an input it can perform localized edits such as adding, removing or replacing elements — or global changes like background or style changes.
Personalized videos: Using an image of a person and a text prompt, the model can generate a video with state-of-the-art results on character preservation and natural movement in video.
We’re continuing to work closely with creative professionals from across the field to integrate their feedback as we work towards a potential release. We look forward to sharing more on this work and the creative possibilities it will enable in the future.
2/2
As part of our continued belief in open science and progressing the state-of-the-art in media generation, we’ve published more details on Movie Gen in a new research paper for the academic community
https://go.fb.me/toz71jTo post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
1/2
More examples of what Meta Movie Gen can do across video generation, precise video editing, personalized video generation and audio generation.
2/2
We’ve shared more details on the models and Movie Gen capabilities in a new blog post How Meta Movie Gen could usher in a new AI-enabled era for content creators
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
More examples of what Meta Movie Gen can do across video generation, precise video editing, personalized video generation and audio generation.
2/2
We’ve shared more details on the models and Movie Gen capabilities in a new blog post
How Meta Movie Gen could usher in a new AI-enabled era for content creatorsTo post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
Meta Movie Gen - the most advanced media foundation AI modelshttps://reddit.com/link/1fvyvr9/video/v6ozewbtoqsd1/player
Generate videos from text Edit video with text
Produce personalized videos
Create sound effects and soundtracks
Paper: MovieGen: A Cast of Media Foundation Models
https://ai.meta.com/static-resource/movie-gen-research-paper
Source: AI at Meta on X:





 Depth Pro with Depth Flow now on @tost_ai, @runpod_io and @ComfyUI
Depth Pro with Depth Flow now on @tost_ai, @runpod_io and @ComfyUI 
 runpod:
runpod:  tost: please try it
tost: please try it 

 This week’s top AI/ML research papers:
This week’s top AI/ML research papers:




 .
.



 :
: 




















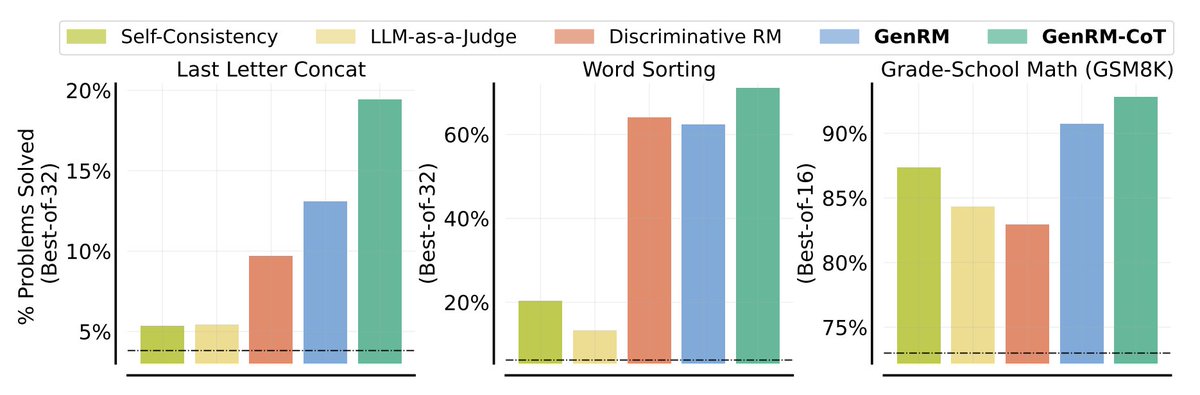
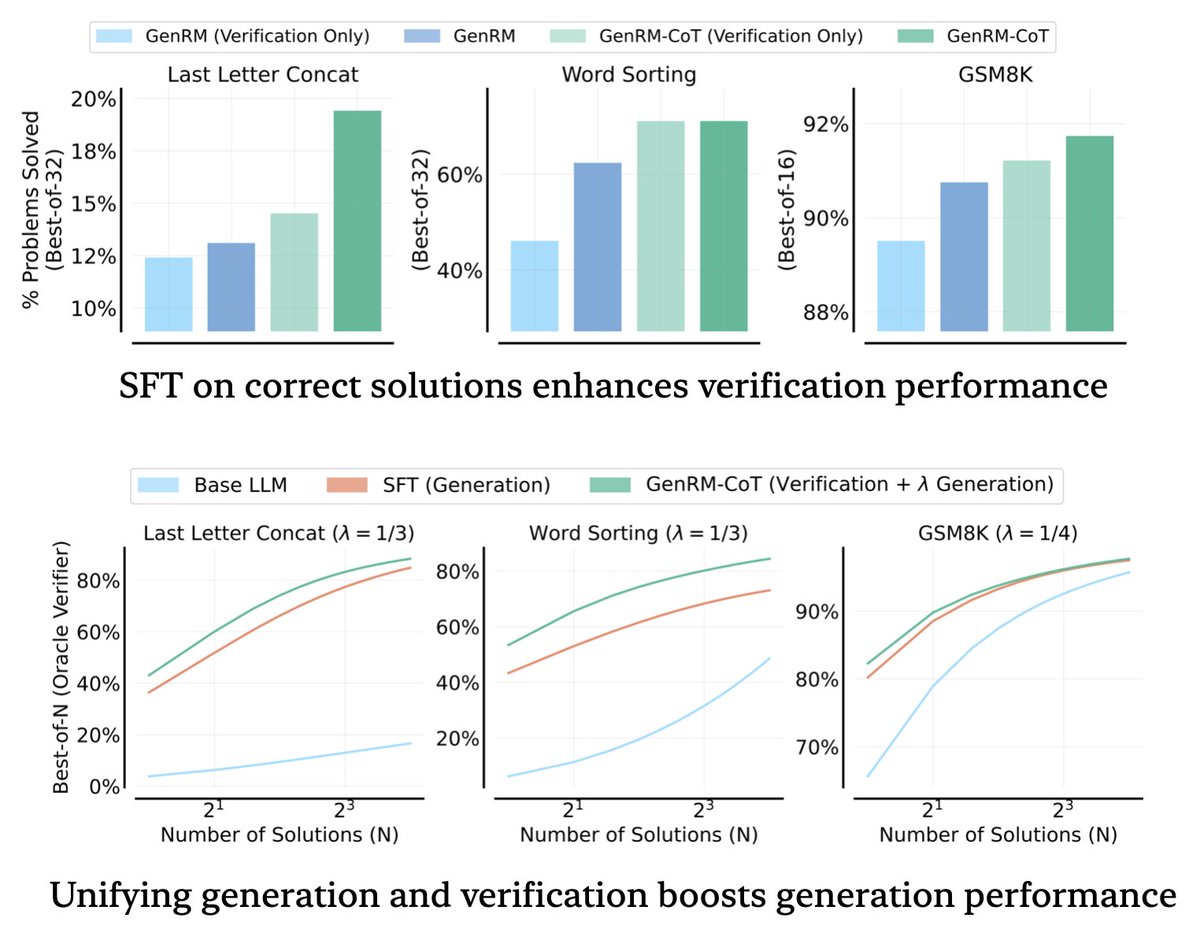
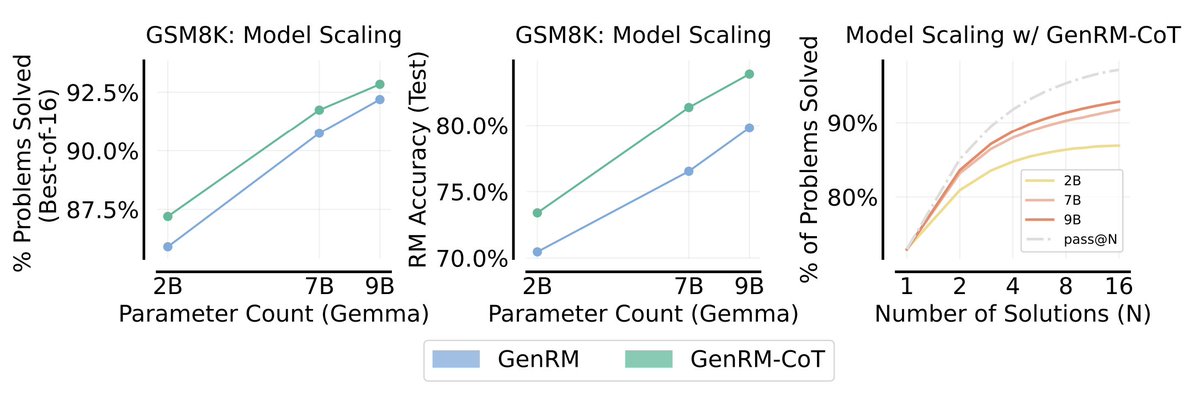
 Chain-of-Thought reasoning for RM
Chain-of-Thought reasoning for RM Leveraging test-time compute
Leveraging test-time compute Single policy + reward model
Single policy + reward model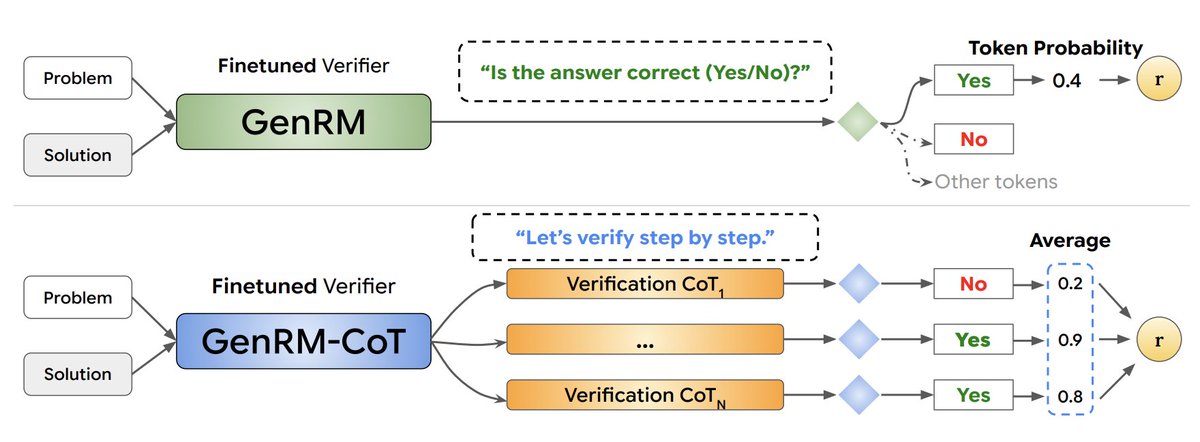







 New Steps for better dataset sampling, deduplication (embeddings and minhash), truncation of inputs and better combining outputs
New Steps for better dataset sampling, deduplication (embeddings and minhash), truncation of inputs and better combining outputs 50% Cost Savings by pausing pipelines and using OpenAI Batch API
50% Cost Savings by pausing pipelines and using OpenAI Batch API ️ Caching for step outputs for maximum reusability—even if the pipeline changes.
️ Caching for step outputs for maximum reusability—even if the pipeline changes. Steps can now generate and save artifacts, automatically uploaded to the Hugging Face Hub.
Steps can now generate and save artifacts, automatically uploaded to the Hugging Face Hub. New Tasks with CLAIR, APIGen, URIAL, TextClassification, TextClustering, and an updated TextGeneration task.
New Tasks with CLAIR, APIGen, URIAL, TextClassification, TextClustering, and an updated TextGeneration task. MoE consists of multiple "expert" neural networks and a router that directs inputs to the most suitable experts
MoE consists of multiple "expert" neural networks and a router that directs inputs to the most suitable experts Experts aren't domain specialists, but rather learn to handle specific tokens in specific contexts
Experts aren't domain specialists, but rather learn to handle specific tokens in specific contexts Load balancing is crucial to ensure all experts are utilized effectively during training
Load balancing is crucial to ensure all experts are utilized effectively during training The router uses probability distributions to select which experts process which tokens
The router uses probability distributions to select which experts process which tokens MoE allows models to have more parameters overall while using fewer during actual inference
MoE allows models to have more parameters overall while using fewer during actual inference MoE isn't limited to language models - it's also being adapted for vision models
MoE isn't limited to language models - it's also being adapted for vision models Mixtral 8x7B demonstrates the power of MoE, loading 46.7B parameters but only using 12.8B during inference
Mixtral 8x7B demonstrates the power of MoE, loading 46.7B parameters but only using 12.8B during inference
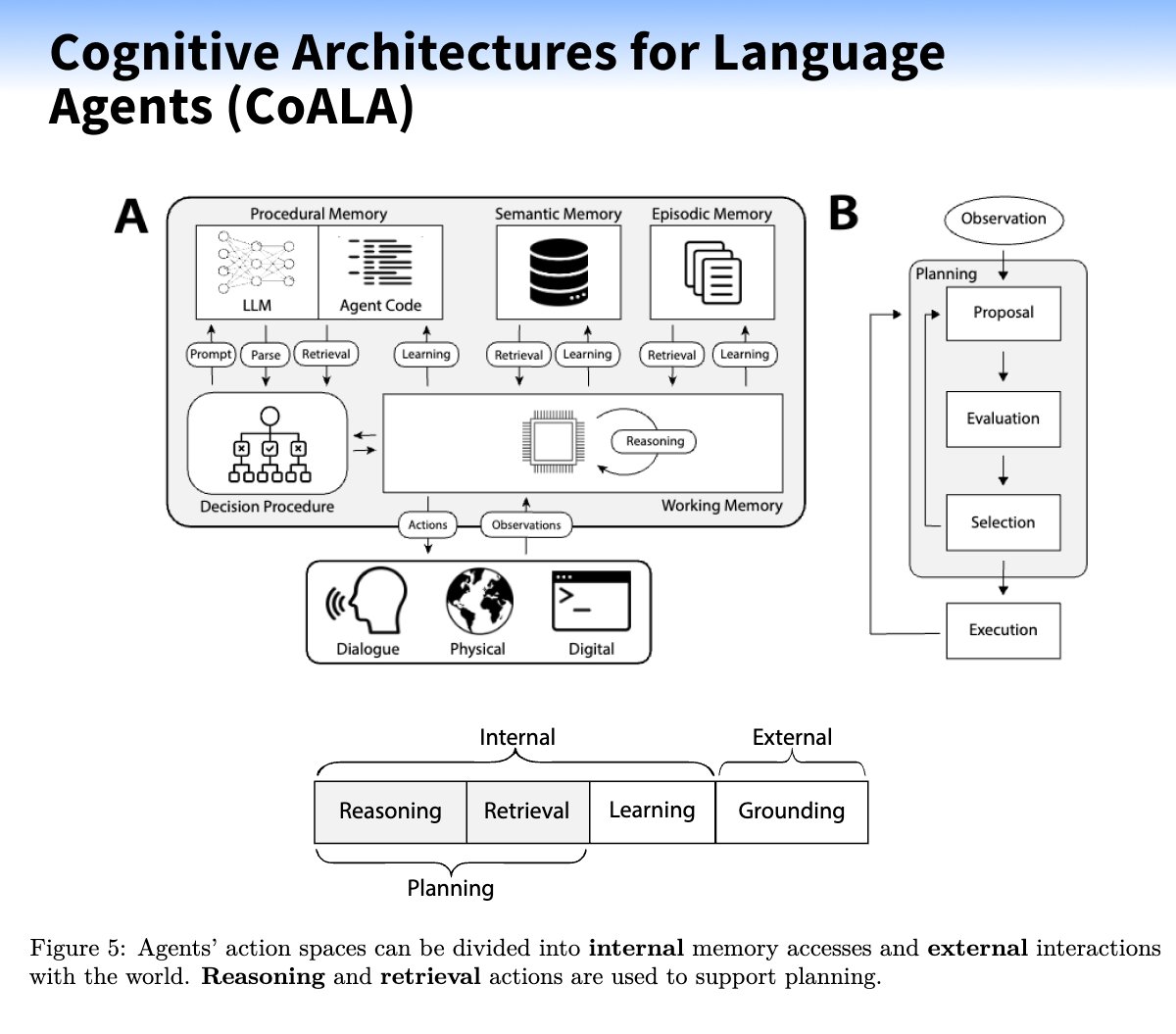
 Define memory components (working, long-term, Procedural)
Define memory components (working, long-term, Procedural) Define a Structured Action Space (internal and external actions).
Define a Structured Action Space (internal and external actions). Implement a decision-making process (propose, evaluate, select).
Implement a decision-making process (propose, evaluate, select). Add safety mechanisms and monitoring systems
Add safety mechanisms and monitoring systems Test and iterate to refine the agent's components and behavior.
Test and iterate to refine the agent's components and behavior.