1/8
Generative Verifiers: Reward Modeling as Next-Token Prediction
abs: [2408.15240] Generative Verifiers: Reward Modeling as Next-Token Prediction
New paper from Google DeepMind; Instead of training the reward model as a discriminative classifier, train it with next token prediction:
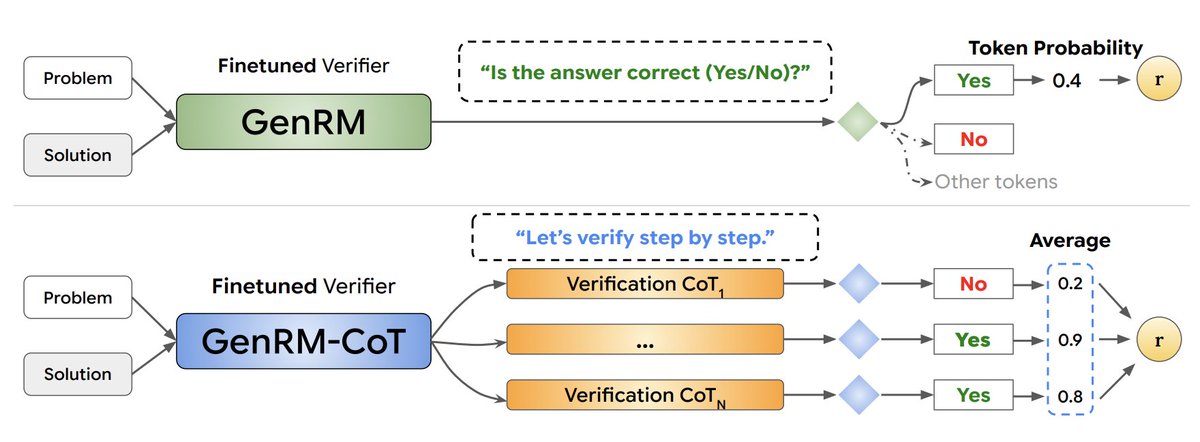
Ask model "Is the answer correct (Yes/No)?", reward score is token probability for "Yes" token.
Naturally supports CoT and majority voting by generating several verbalized rationales before predicting correctness
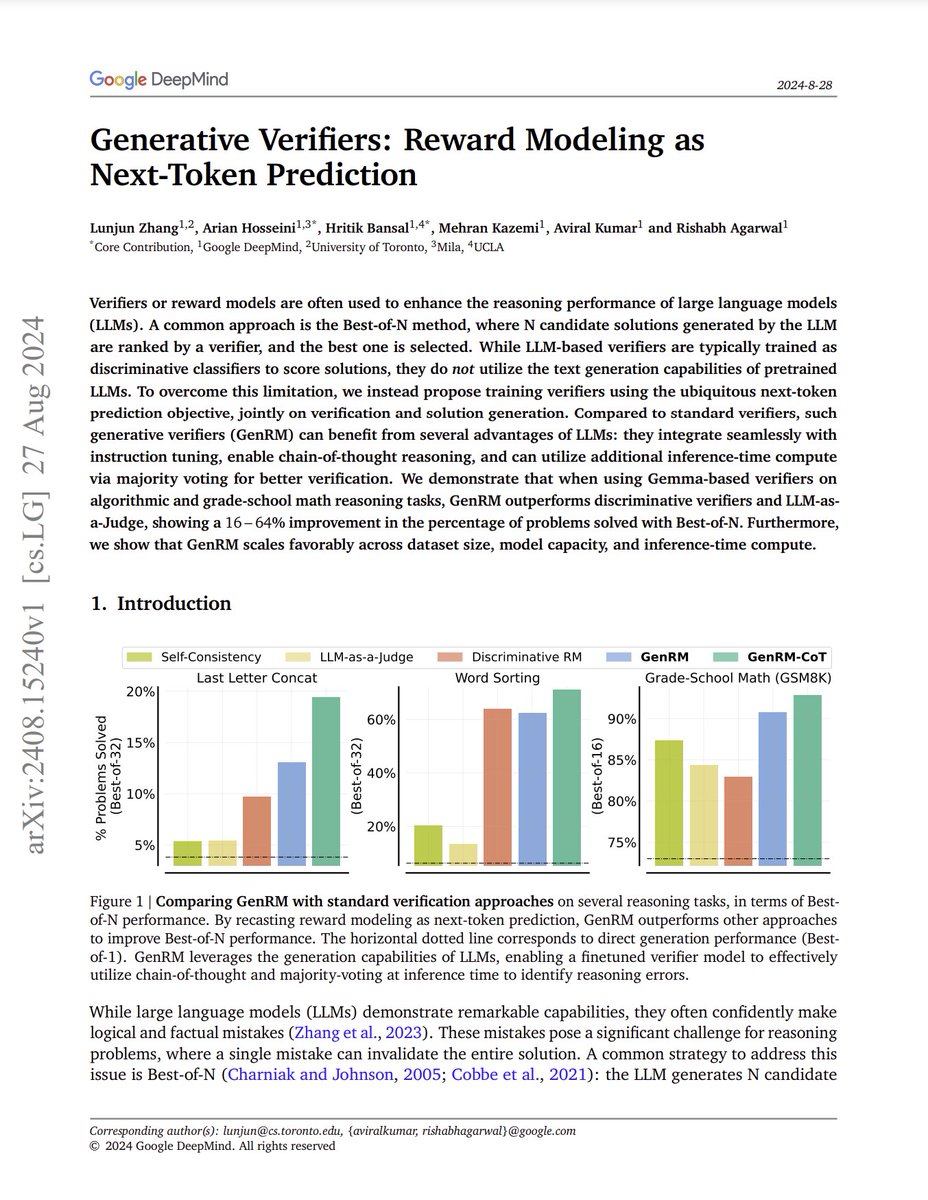
The approach, referred to as GenRM, outperforms discriminative verifiers and LLM-as-a-Judge, showing a 16−64% improvement in the percentage of problems solved with Best-of-N on algorithmic string manipulation and math reasoning tasks.
2/8
@memdotai mem it
3/8
Saved! Here's the compiled thread: Mem
4/8
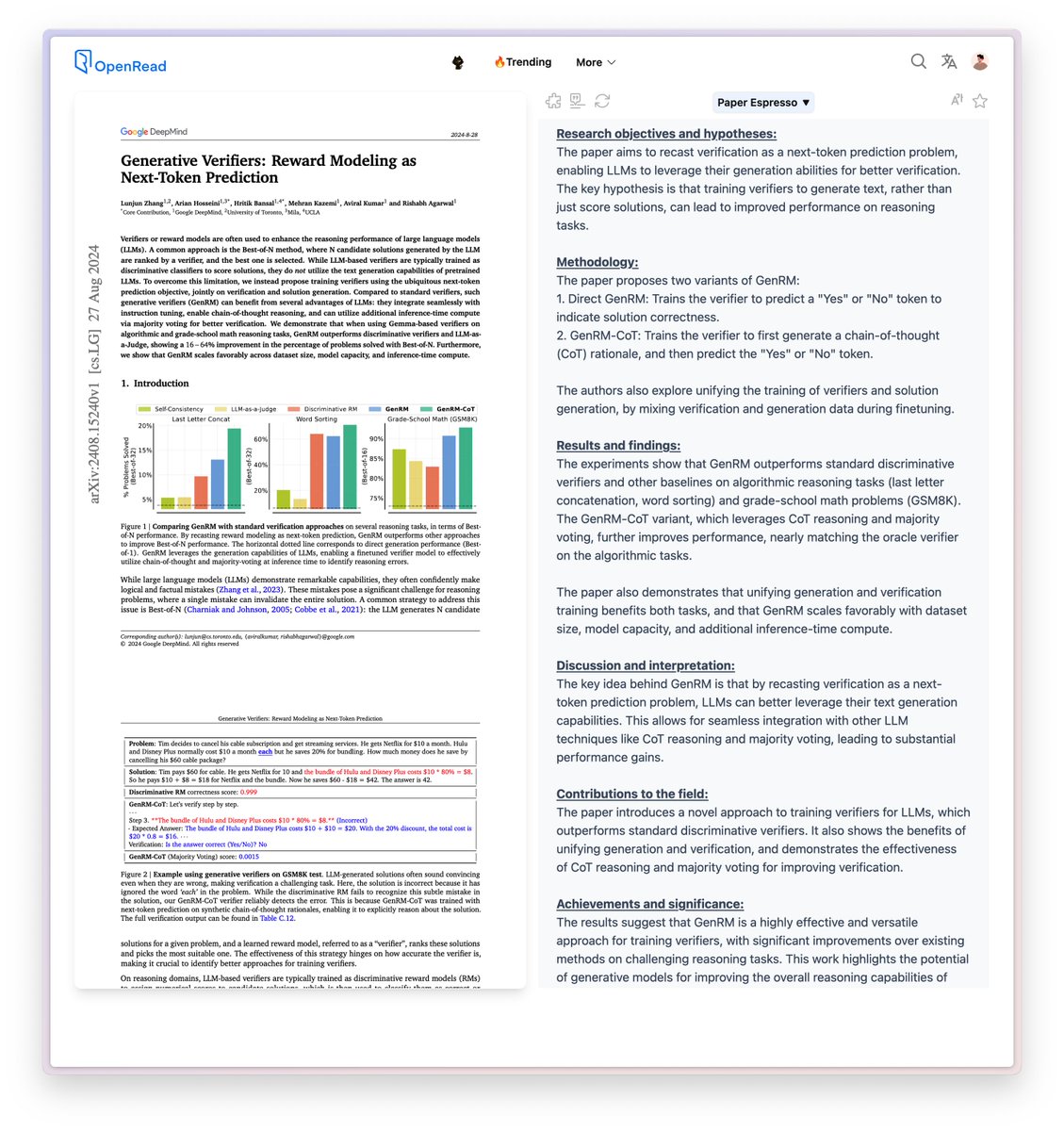
The paper introduces "Generative Verifiers" (GenRM), a new approach to training verifiers or reward models for large language models (LLMs). Traditionally, verifiers are trained as discriminative models to score the correctness of LLM-generated solutions. However, this approach does not fully utilize the text generation capabilities of LLMs.
The key idea behind GenRM is that by recasting verification as a next-token prediction problem, LLMs can better leverage their text generation capabilities. This allows for seamless integration with other LLM techniques like CoT reasoning and majority voting, leading to substantial performance gains.
full paper: Generative Verifiers: Reward Modeling as Next-Token Prediction
5/8
Fascinating! This GenRM approach could revolutionize AI verification. I'm excited to see how it integrates with instruction tuning and chain-of-thought reasoning. The potential for breakthroughs in math reasoning tasks is huge!
6/8
Detailed thread here:
7/8
The only theory where things work for a reward is substance abuse theory where humans are supposed to score drugs to satisfy their "reward center".
Implementing it in AI is like creating a junk that craves for the right answer.
Make it behave, so sad ...
@alexgraveley @ylecun
8/8
Generative Verifiers: Reward Modeling as Next-Token Prediction
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
Generative Verifiers: Reward Modeling as Next-Token Prediction
abs: [2408.15240] Generative Verifiers: Reward Modeling as Next-Token Prediction
New paper from Google DeepMind; Instead of training the reward model as a discriminative classifier, train it with next token prediction:
Ask model "Is the answer correct (Yes/No)?", reward score is token probability for "Yes" token.
Naturally supports CoT and majority voting by generating several verbalized rationales before predicting correctness
The approach, referred to as GenRM, outperforms discriminative verifiers and LLM-as-a-Judge, showing a 16−64% improvement in the percentage of problems solved with Best-of-N on algorithmic string manipulation and math reasoning tasks.
2/8
@memdotai mem it
3/8
Saved! Here's the compiled thread: Mem
4/8
The paper introduces "Generative Verifiers" (GenRM), a new approach to training verifiers or reward models for large language models (LLMs). Traditionally, verifiers are trained as discriminative models to score the correctness of LLM-generated solutions. However, this approach does not fully utilize the text generation capabilities of LLMs.
The key idea behind GenRM is that by recasting verification as a next-token prediction problem, LLMs can better leverage their text generation capabilities. This allows for seamless integration with other LLM techniques like CoT reasoning and majority voting, leading to substantial performance gains.
full paper: Generative Verifiers: Reward Modeling as Next-Token Prediction
5/8
Fascinating! This GenRM approach could revolutionize AI verification. I'm excited to see how it integrates with instruction tuning and chain-of-thought reasoning. The potential for breakthroughs in math reasoning tasks is huge!
6/8
Detailed thread here:
7/8
The only theory where things work for a reward is substance abuse theory where humans are supposed to score drugs to satisfy their "reward center".
Implementing it in AI is like creating a junk that craves for the right answer.
Make it behave, so sad ...
@alexgraveley @ylecun
8/8
Generative Verifiers: Reward Modeling as Next-Token Prediction
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196










 An LLM-based Multi-agent Framework of Web Search Engine (like Perplexity.ai Pro and SearchGPT)
An LLM-based Multi-agent Framework of Web Search Engine (like Perplexity.ai Pro and SearchGPT)


 :
:  (1/6)
(1/6)


 :
:


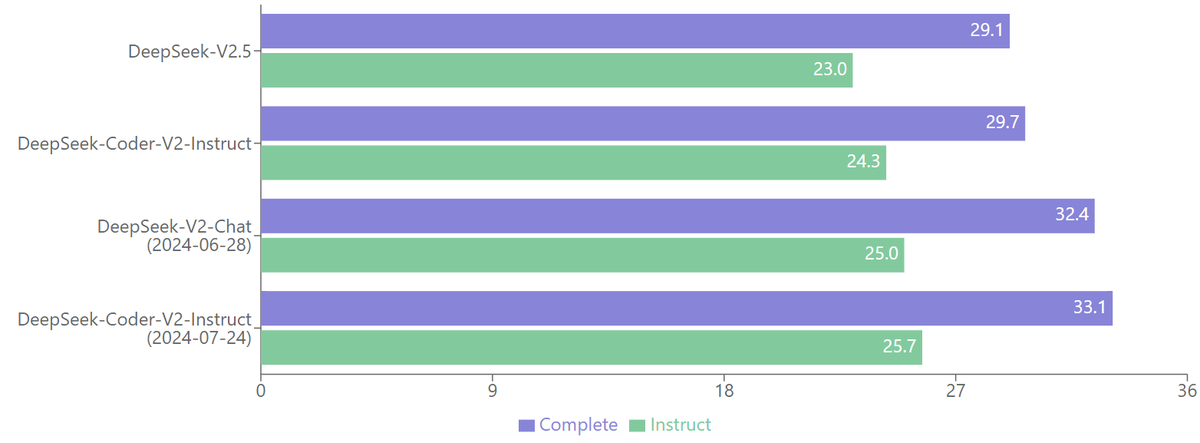
 Exciting news! We’ve officially launched DeepSeek-V2.5 – a powerful combination of DeepSeek-V2-0628 and DeepSeek-Coder-V2-0724! Now, with enhanced writing, instruction-following, and human preference alignment, it’s available on Web and API. Enjoy seamless Function Calling, FIM, and Json Output all-in-one!
Exciting news! We’ve officially launched DeepSeek-V2.5 – a powerful combination of DeepSeek-V2-0628 and DeepSeek-Coder-V2-0724! Now, with enhanced writing, instruction-following, and human preference alignment, it’s available on Web and API. Enjoy seamless Function Calling, FIM, and Json Output all-in-one!