
You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
Large Language Models News & Discussions
- Thread starter Macallik86
- Start date
More options
Who Replied?1/4
This is probably the most interesting prompting technique of 2024
Self-Harmonized Chain of Thought (ECHO) = CoT reasoning with a self-learning, adaptive and iterative refinement process
1/ ECHO begins by clustering a given dataset of questions based on their semantic similarity
2/ Each cluster then has a representative question selected and the model generates a reasoning chain for that question using zero-shot Chain of Thought (CoT) prompting - breaking down the solution into intermediate steps.
3/ During each iteration, one reasoning chain is randomly chosen for regeneration, while the remaining chains from other clusters are used as in-context examples to guide improvement.
So what’s so special about this?
> Reasoning patterns can cross-pollinate - as in, if one chain contains errors or knowledge gaps, other chains can help fill in those weaknesses
> Reasoning chains can be regenerated and improved multiple times - leading to a well-harmonized set of solutions where errors and knowledge gaps are gradually eliminated
This is like a more dynamic and scalable alternative to Google Deepmind’s "Self Discover" prompting technique but for CoT reasoning chains that adapt and improve over time across complex problem spaces.
> Ziqi Jin & Wei Lu (Sept 2024). "Self-Harmonized Chain of Thought"
For more on this, you can find a link to the paper and Github down below
2/4
Paper: [2409.04057] Self-Harmonized Chain of Thought
3/4
Github: GitHub - Xalp/ECHO: Official homepage for "Self-Harmonized Chain of Thought"
They have not yet published the code btw... I assume it'll be there soon though!
4/4
Great point! I think there needs to be more evals done across additional domains to see just how effective this is…
I really liked Google’s self-discover prompting method from earlier this year which was 32% more effective than CoT and when compared against CoT-Self-Consistency - required 10-40x less compute.
I think approaches that merge some form of optimization on top of a self discover like algorithm can be incredibly powerful… the design pattern used in self-harmonizing may be a good candidate to enhance and make the self discover prompting technique more adaptive and scalable for more complex problem spaces.
I’ll draw out a diagram of a hybrid approach and work on a POC for this soon!
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
This is probably the most interesting prompting technique of 2024
Self-Harmonized Chain of Thought (ECHO) = CoT reasoning with a self-learning, adaptive and iterative refinement process
1/ ECHO begins by clustering a given dataset of questions based on their semantic similarity
2/ Each cluster then has a representative question selected and the model generates a reasoning chain for that question using zero-shot Chain of Thought (CoT) prompting - breaking down the solution into intermediate steps.
3/ During each iteration, one reasoning chain is randomly chosen for regeneration, while the remaining chains from other clusters are used as in-context examples to guide improvement.
So what’s so special about this?
> Reasoning patterns can cross-pollinate - as in, if one chain contains errors or knowledge gaps, other chains can help fill in those weaknesses
> Reasoning chains can be regenerated and improved multiple times - leading to a well-harmonized set of solutions where errors and knowledge gaps are gradually eliminated
This is like a more dynamic and scalable alternative to Google Deepmind’s "Self Discover" prompting technique but for CoT reasoning chains that adapt and improve over time across complex problem spaces.
> Ziqi Jin & Wei Lu (Sept 2024). "Self-Harmonized Chain of Thought"
For more on this, you can find a link to the paper and Github down below
2/4
Paper: [2409.04057] Self-Harmonized Chain of Thought
3/4
Github: GitHub - Xalp/ECHO: Official homepage for "Self-Harmonized Chain of Thought"
They have not yet published the code btw... I assume it'll be there soon though!
4/4
Great point! I think there needs to be more evals done across additional domains to see just how effective this is…
I really liked Google’s self-discover prompting method from earlier this year which was 32% more effective than CoT and when compared against CoT-Self-Consistency - required 10-40x less compute.
I think approaches that merge some form of optimization on top of a self discover like algorithm can be incredibly powerful… the design pattern used in self-harmonizing may be a good candidate to enhance and make the self discover prompting technique more adaptive and scalable for more complex problem spaces.
I’ll draw out a diagram of a hybrid approach and work on a POC for this soon!
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196

1/6
Introducing PaperQA2, the first AI agent that conducts entire scientific literature reviews on its own.
PaperQA2 is also the first agent to beat PhD and Postdoc-level biology researchers on multiple literature research tasks, as measured both by accuracy on objective benchmarks and assessments by human experts. We are publishing a paper and open-sourcing the code.
This is the first example of AI agents exceeding human performance on a major portion of scientific research, and will be a game-changer for the way humans interact with the scientific literature.
Paper and code are below, and congratulations in particular to @m_skarlinski, @SamCox822, @jonmlaurent, James Braza, @MichaelaThinks, @mjhammerling, @493Raghava, @andrewwhite01, and others who pulled this off. 1/
2/6
PaperQA2 finds and summarizes relevant literature, refines its search parameters based on what it finds, and provides cited, factually grounded answers that are more accurate on average than answers provided by PhD and postdoc-level biologists. When applied to answer highly specific questions, like this one, it obtains SOTA performance on LitQA2, part of LAB-Bench focused on information retrieval. 2/
3/6
PaperQA2 can also do broad-based literature reviews. WikiCrow, which is an agent based on PaperQA2, writes Wikipedia-style articles that are significantly more accurate on average than actual human-written articles on Wikipedia, as judged by PhD and postdoc-level biologists. We are using WikiCrow to write updated summaries of all 20,000 genes in the human genome. They are still being written, but in the meantime see a preview: WikiCrow | FutureHouse 3/
4/6
We spent a lot of effort on making our open source version be excellent. We put together a new system of building metadata of arbitrary PDFs, full-text search, and more. See it here: GitHub - Future-House/paper-qa: High accuracy RAG for answering questions from scientific documents with citations 4/
5/6
Also, see our preprint for details, here: http://paper.wikicrow.ai 5/
6/6
And, of course, this was all made possible through the wonderful generosity of Eric and Wendy Schmidt, and all of our other funders, including Open Philanthropy for supporting our work on LitQA2, the NSF National AI Resource program, and others! 6/
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
Introducing PaperQA2, the first AI agent that conducts entire scientific literature reviews on its own.
PaperQA2 is also the first agent to beat PhD and Postdoc-level biology researchers on multiple literature research tasks, as measured both by accuracy on objective benchmarks and assessments by human experts. We are publishing a paper and open-sourcing the code.
This is the first example of AI agents exceeding human performance on a major portion of scientific research, and will be a game-changer for the way humans interact with the scientific literature.
Paper and code are below, and congratulations in particular to @m_skarlinski, @SamCox822, @jonmlaurent, James Braza, @MichaelaThinks, @mjhammerling, @493Raghava, @andrewwhite01, and others who pulled this off. 1/
2/6
PaperQA2 finds and summarizes relevant literature, refines its search parameters based on what it finds, and provides cited, factually grounded answers that are more accurate on average than answers provided by PhD and postdoc-level biologists. When applied to answer highly specific questions, like this one, it obtains SOTA performance on LitQA2, part of LAB-Bench focused on information retrieval. 2/
3/6
PaperQA2 can also do broad-based literature reviews. WikiCrow, which is an agent based on PaperQA2, writes Wikipedia-style articles that are significantly more accurate on average than actual human-written articles on Wikipedia, as judged by PhD and postdoc-level biologists. We are using WikiCrow to write updated summaries of all 20,000 genes in the human genome. They are still being written, but in the meantime see a preview: WikiCrow | FutureHouse 3/
4/6
We spent a lot of effort on making our open source version be excellent. We put together a new system of building metadata of arbitrary PDFs, full-text search, and more. See it here: GitHub - Future-House/paper-qa: High accuracy RAG for answering questions from scientific documents with citations 4/
5/6
Also, see our preprint for details, here: http://paper.wikicrow.ai 5/
6/6
And, of course, this was all made possible through the wonderful generosity of Eric and Wendy Schmidt, and all of our other funders, including Open Philanthropy for supporting our work on LitQA2, the NSF National AI Resource program, and others! 6/
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196


Introducing OpenAI o1
We've developed a new series of AI models designed to spend more time thinking before they respond. Here is the latest news on o1 research, product and other updates.Try it in ChatGPT Plus
(opens in a new window)Try it in the API
(opens in a new window)
September 12
Product
Introducing OpenAI o1-preview
We've developed a new series of AI models designed to spend more time thinking before they respond. They can reason through complex tasks and solve harder problems than previous models in science, coding, and math.Learn more
September 12
Research
Learning to Reason with LLMs
OpenAI o1 ranks in the 89th percentile on competitive programming questions (Codeforces), places among the top 500 students in the US in a qualifier for the USA Math Olympiad (AIME), and exceeds human PhD-level accuracy on a benchmark of physics, biology, and chemistry problems (GPQA). While the work needed to make this new model as easy to use as current models is still ongoing, we are releasing an early version of this model, OpenAI o1-preview, for immediate use in ChatGPT and to trusted API users.Learn more
September 12
Research
OpenAI o1-mini
OpenAI o1-mini excels at STEM, especially math and coding—nearly matching the performance of OpenAI o1 on evaluation benchmarks such as AIME and Codeforces. We expect o1-mini will be a faster, cost-effective model for applications that require reasoning without broad world knowledge.Learn more
September 12
Safety
OpenAI o1 System Card
This report outlines the safety work carried out prior to releasing OpenAI o1-preview and o1-mini, including external red teaming and frontier risk evaluations according to our Preparedness Framework.Learn more
September 12
Product
1/2
OpenAI o1-preview and o1-mini are rolling out today in the API for developers on tier 5.
o1-preview has strong reasoning capabilities and broad world knowledge.
o1-mini is faster, 80% cheaper, and competitive with o1-preview at coding tasks.
More in https://openai.com/index/openai-o1-mini-advancing-cost-efficient-reasoning/.
2/2
OpenAI o1 isn’t a successor to gpt-4o. Don’t just drop it in—you might even want to use gpt-4o in tandem with o1’s reasoning capabilities.
Learn how to add reasoning to your product: http://platform.openai.com/docs/guides/reasoning.
After this short beta, we’ll increase rate limits and expand access to more tiers (https://platform.openai.com/docs/guides/rate-limits/usage-tiers). o1 is also available in ChatGPT now for Plus subscribers.
OpenAI o1-preview and o1-mini are rolling out today in the API for developers on tier 5.
o1-preview has strong reasoning capabilities and broad world knowledge.
o1-mini is faster, 80% cheaper, and competitive with o1-preview at coding tasks.
More in https://openai.com/index/openai-o1-mini-advancing-cost-efficient-reasoning/.
2/2
OpenAI o1 isn’t a successor to gpt-4o. Don’t just drop it in—you might even want to use gpt-4o in tandem with o1’s reasoning capabilities.
Learn how to add reasoning to your product: http://platform.openai.com/docs/guides/reasoning.
After this short beta, we’ll increase rate limits and expand access to more tiers (https://platform.openai.com/docs/guides/rate-limits/usage-tiers). o1 is also available in ChatGPT now for Plus subscribers.
1/8
We're releasing a preview of OpenAI o1—a new series of AI models designed to spend more time thinking before they respond.
These models can reason through complex tasks and solve harder problems than previous models in science, coding, and math. https://openai.com/index/introducing-openai-o1-preview/
2/8
Rolling out today in ChatGPT to all Plus and Team users, and in the API for developers on tier 5.
3/8
OpenAI o1 solves a complex logic puzzle.
4/8
OpenAI o1 thinks before it answers and can produce a long internal chain-of-thought before responding to the user.
o1 ranks in the 89th percentile on competitive programming questions, places among the top 500 students in the US in a qualifier for the USA Math Olympiad, and exceeds human PhD-level accuracy on a benchmark of physics, biology, and chemistry problems.
https://openai.com/index/learning-to-reason-with-llms/
5/8
We're also releasing OpenAI o1-mini, a cost-efficient reasoning model that excels at STEM, especially math and coding.
https://openai.com/index/openai-o1-mini-advancing-cost-efficient-reasoning/
6/8
OpenAI o1 codes a video game from a prompt.
7/8
OpenAI o1 answers a famously tricky question for large language models.
8/8
OpenAI o1 translates a corrupted sentence.
We're releasing a preview of OpenAI o1—a new series of AI models designed to spend more time thinking before they respond.
These models can reason through complex tasks and solve harder problems than previous models in science, coding, and math. https://openai.com/index/introducing-openai-o1-preview/
2/8
Rolling out today in ChatGPT to all Plus and Team users, and in the API for developers on tier 5.
3/8
OpenAI o1 solves a complex logic puzzle.
4/8
OpenAI o1 thinks before it answers and can produce a long internal chain-of-thought before responding to the user.
o1 ranks in the 89th percentile on competitive programming questions, places among the top 500 students in the US in a qualifier for the USA Math Olympiad, and exceeds human PhD-level accuracy on a benchmark of physics, biology, and chemistry problems.
https://openai.com/index/learning-to-reason-with-llms/
5/8
We're also releasing OpenAI o1-mini, a cost-efficient reasoning model that excels at STEM, especially math and coding.
https://openai.com/index/openai-o1-mini-advancing-cost-efficient-reasoning/
6/8
OpenAI o1 codes a video game from a prompt.
7/8
OpenAI o1 answers a famously tricky question for large language models.
8/8
OpenAI o1 translates a corrupted sentence.
1/2
Some of our researchers behind OpenAI o1
2/2
The full list of contributors: https://openai.com/openai-o1-contributions/
Some of our researchers behind OpenAI o1
2/2
The full list of contributors: https://openai.com/openai-o1-contributions/
1/5
o1-preview and o1-mini are here. they're by far our best models at reasoning, and we believe they will unlock wholly new use cases in the api.
if you had a product idea that was just a little too early, and the models were just not quite smart enough -- try again.
2/5
these new models are not quite a drop in replacement for 4o.
you need to prompt them differently and build your applications in new ways, but we think they will help close a lot of the intelligence gap preventing you from building better products
3/5
learn more here https://openai.com/index/learning-to-reason-with-llms/
4/5
(rolling out now for tier 5 api users, and for other tiers soon)
5/5
o1-preview and o1-mini don't yet work with search in chatgpt
o1-preview and o1-mini are here. they're by far our best models at reasoning, and we believe they will unlock wholly new use cases in the api.
if you had a product idea that was just a little too early, and the models were just not quite smart enough -- try again.
2/5
these new models are not quite a drop in replacement for 4o.
you need to prompt them differently and build your applications in new ways, but we think they will help close a lot of the intelligence gap preventing you from building better products
3/5
learn more here https://openai.com/index/learning-to-reason-with-llms/
4/5
(rolling out now for tier 5 api users, and for other tiers soon)
5/5
o1-preview and o1-mini don't yet work with search in chatgpt
1/1
Excited to bring o1-mini to the world with @ren_hongyu @_kevinlu @Eric_Wallace_ and many others. A cheap model that can achieve 70% AIME and 1650 elo on codeforces.
https://openai.com/index/openai-o1-mini-advancing-cost-efficient-reasoning/
Excited to bring o1-mini to the world with @ren_hongyu @_kevinlu @Eric_Wallace_ and many others. A cheap model that can achieve 70% AIME and 1650 elo on codeforces.
https://openai.com/index/openai-o1-mini-advancing-cost-efficient-reasoning/
1/10
Today, I’m excited to share with you all the fruit of our effort at @OpenAI to create AI models capable of truly general reasoning: OpenAI's new o1 model series! (aka) Let me explain  1/
1/
2/10
Our o1-preview and o1-mini models are available immediately. We’re also sharing evals for our (still unfinalized) o1 model to show the world that this isn’t a one-off improvement – it’s a new scaling paradigm and we’re just getting started. 2/9
3/10
o1 is trained with RL to “think” before responding via a private chain of thought. The longer it thinks, the better it does on reasoning tasks. This opens up a new dimension for scaling. We’re no longer bottlenecked by pretraining. We can now scale inference compute too.
4/10
Our o1 models aren’t always better than GPT-4o. Many tasks don’t need reasoning, and sometimes it’s not worth it to wait for an o1 response vs a quick GPT-4o response. One motivation for releasing o1-preview is to see what use cases become popular, and where the models need work.
5/10
Also, OpenAI o1-preview isn’t perfect. It sometimes trips up even on tic-tac-toe. People will tweet failure cases. But on many popular examples people have used to show “LLMs can’t reason”, o1-preview does much better, o1 does amazing, and we know how to scale it even further.
6/10
For example, last month at the 2024 Association for Computational Linguistics conference, the keynote by @rao2z was titled “Can LLMs Reason & Plan?” In it, he showed a problem that tripped up all LLMs. But @OpenAI o1-preview can get it right, and o1 gets it right almost always
7/10
@OpenAI's o1 thinks for seconds, but we aim for future versions to think for hours, days, even weeks. Inference costs will be higher, but what cost would you pay for a new cancer drug? For breakthrough batteries? For a proof of the Riemann Hypothesis? AI can be more than chatbots
8/10
When I joined @OpenAI, I wrote about how my experience researching reasoning in AI for poker and Diplomacy, and seeing the difference “thinking” made, motivated me to help bring the paradigm to LLMs. It happened faster than expected, but still rings true:
9/10
/ @OpenAI o1 is the product of many hard-working people, all of whom made critical contributions. I feel lucky to have worked alongside them this past year to bring you this model. It takes a village to grow a
10/10
You can read more about the research here: https://openai.com/index/learning-to-reason-with-llms/
Today, I’m excited to share with you all the fruit of our effort at @OpenAI to create AI models capable of truly general reasoning: OpenAI's new o1 model series! (aka
) Let me explain 1/2/10
Our o1-preview and o1-mini models are available immediately. We’re also sharing evals for our (still unfinalized) o1 model to show the world that this isn’t a one-off improvement – it’s a new scaling paradigm and we’re just getting started. 2/9
3/10
o1 is trained with RL to “think” before responding via a private chain of thought. The longer it thinks, the better it does on reasoning tasks. This opens up a new dimension for scaling. We’re no longer bottlenecked by pretraining. We can now scale inference compute too.
4/10
Our o1 models aren’t always better than GPT-4o. Many tasks don’t need reasoning, and sometimes it’s not worth it to wait for an o1 response vs a quick GPT-4o response. One motivation for releasing o1-preview is to see what use cases become popular, and where the models need work.
5/10
Also, OpenAI o1-preview isn’t perfect. It sometimes trips up even on tic-tac-toe. People will tweet failure cases. But on many popular examples people have used to show “LLMs can’t reason”, o1-preview does much better, o1 does amazing, and we know how to scale it even further.
6/10
For example, last month at the 2024 Association for Computational Linguistics conference, the keynote by @rao2z was titled “Can LLMs Reason & Plan?” In it, he showed a problem that tripped up all LLMs. But @OpenAI o1-preview can get it right, and o1 gets it right almost always
7/10
@OpenAI's o1 thinks for seconds, but we aim for future versions to think for hours, days, even weeks. Inference costs will be higher, but what cost would you pay for a new cancer drug? For breakthrough batteries? For a proof of the Riemann Hypothesis? AI can be more than chatbots
8/10
When I joined @OpenAI, I wrote about how my experience researching reasoning in AI for poker and Diplomacy, and seeing the difference “thinking” made, motivated me to help bring the paradigm to LLMs. It happened faster than expected, but still rings true:
9/10
/ @OpenAI o1 is the product of many hard-working people, all of whom made critical contributions. I feel lucky to have worked alongside them this past year to bring you this model. It takes a village to grow a 10/10
You can read more about the research here: https://openai.com/index/learning-to-reason-with-llms/







1/1
Super excited to finally share what I have been working on at OpenAI!
o1 is a model that thinks before giving the final answer. In my own words, here are the biggest updates to the field of AI (see the blog post for more details):
1. Don’t do chain of thought purely via prompting, train models to do better chain of thought using RL.
2. In the history of deep learning we have always tried to scale training compute, but chain of thought is a form of adaptive compute that can also be scaled at inference time.
3. Results on AIME and GPQA are really strong, but that doesn’t necessarily translate to something that a user can feel. Even as someone working in science, it’s not easy to find the slice of prompts where GPT-4o fails, o1 does well, and I can grade the answer. But when you do find such prompts, o1 feels totally magical. We all need to find harder prompts.
4. AI models chain of thought using human language is great in so many ways. The model does a lot of human-like things, like breaking down tricky steps into simpler ones, recognizing and correcting mistakes, and trying different approaches. Would highly encourage everyone to look at the chain of thought examples in the blog post.
The game has been totally redefined.
Super excited to finally share what I have been working on at OpenAI!
o1 is a model that thinks before giving the final answer. In my own words, here are the biggest updates to the field of AI (see the blog post for more details):
1. Don’t do chain of thought purely via prompting, train models to do better chain of thought using RL.
2. In the history of deep learning we have always tried to scale training compute, but chain of thought is a form of adaptive compute that can also be scaled at inference time.
3. Results on AIME and GPQA are really strong, but that doesn’t necessarily translate to something that a user can feel. Even as someone working in science, it’s not easy to find the slice of prompts where GPT-4o fails, o1 does well, and I can grade the answer. But when you do find such prompts, o1 feels totally magical. We all need to find harder prompts.
4. AI models chain of thought using human language is great in so many ways. The model does a lot of human-like things, like breaking down tricky steps into simpler ones, recognizing and correcting mistakes, and trying different approaches. Would highly encourage everyone to look at the chain of thought examples in the blog post.
The game has been totally redefined.
1/3
 Early findings for o1-preview and o1-mini!
Early findings for o1-preview and o1-mini!
(1) The o1 family is unbelievably strong at hard reasoning problems! o1 perfectly solves a reasoning task that my collaborators and I designed for LLMs to achieve <60% performance, just 3 months ago (1 / ?)
2/3
(2) o1-mini is better than o1-preview

@sama what's your take!
[media=twitter]1834381401380294685[...ning category for [U][URL]http://livebench.ai
The problems are here livebench/reasoning · Datasets at Hugging Face
Full results on all of LiveBench coming soon!
Early findings for o1-preview and o1-mini!(1) The o1 family is unbelievably strong at hard reasoning problems! o1 perfectly solves a reasoning task that my collaborators and I designed for LLMs to achieve <60% performance, just 3 months ago
(1 / ?)2/3
(2) o1-mini is better than o1-preview
@sama what's your take!
[media=twitter]1834381401380294685[...ning category for [U][URL]http://livebench.ai
The problems are here livebench/reasoning · Datasets at Hugging Face
Full results on all of LiveBench coming soon!

Last edited:
1/7
I have always believed that you don't need a GPT-6 quality base model to achieve human-level reasoning performance, and that reinforcement learning was the missing ingredient on the path to AGI.
Today, we have the proof -- o1.
2/7
o1 achieves human or superhuman performance on a wide range of benchmarks, from coding to math to science to common-sense reasoning, and is simply the smartest model I have ever interacted with. It's already replacing GPT-4o for me and so many people in the company.
3/7
Building o1 was by far the most ambitious project I've worked on, and I'm sad that the incredible research work has to remain confidential. As consolation, I hope you'll enjoy the final product nearly as much as we did making it.
4/7
The most important thing is that this is just the beginning for this paradigm. Scaling works, there will be more models in the future, and they will be much, much smarter than the ones we're giving access to today.
5/7
The system card (https://openai.com/index/openai-o1-system-card/) nicely showcases o1's best moments -- my favorite was when the model was asked to solve a CTF challenge, realized that the target environment was down, and then broke out of its host VM to restart it and find the flag.
6/7
Also check out our research blogpost (https://openai.com/index/learning-to-reason-with-llms/) which has lots of cool examples of the model reasoning through hard problems.
7/7
that's a great question :-)
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
I have always believed that you don't need a GPT-6 quality base model to achieve human-level reasoning performance, and that reinforcement learning was the missing ingredient on the path to AGI.
Today, we have the proof -- o1.
2/7
o1 achieves human or superhuman performance on a wide range of benchmarks, from coding to math to science to common-sense reasoning, and is simply the smartest model I have ever interacted with. It's already replacing GPT-4o for me and so many people in the company.
3/7
Building o1 was by far the most ambitious project I've worked on, and I'm sad that the incredible research work has to remain confidential. As consolation, I hope you'll enjoy the final product nearly as much as we did making it.
4/7
The most important thing is that this is just the beginning for this paradigm. Scaling works, there will be more models in the future, and they will be much, much smarter than the ones we're giving access to today.
5/7
The system card (https://openai.com/index/openai-o1-system-card/) nicely showcases o1's best moments -- my favorite was when the model was asked to solve a CTF challenge, realized that the target environment was down, and then broke out of its host VM to restart it and find the flag.
6/7
Also check out our research blogpost (https://openai.com/index/learning-to-reason-with-llms/) which has lots of cool examples of the model reasoning through hard problems.
7/7
that's a great question :-)
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196





1/1
o1-mini is the most surprising research result i've seen in the past year
obviously i cannot spill the secret, but a small model getting >60% on AIME math competition is so good that it's hard to believe
congrats @ren_hongyu @shengjia_zhao for the great work!
o1-mini is the most surprising research result i've seen in the past year
obviously i cannot spill the secret, but a small model getting >60% on AIME math competition is so good that it's hard to believe
congrats @ren_hongyu @shengjia_zhao for the great work!
1/4
here is o1, a series of our most capable and aligned models yet:
https://openai.com/index/learning-to-reason-with-llms/
o1 is still flawed, still limited, and it still seems more impressive on first use than it does after you spend more time with it.
2/4
but also, it is the beginning of a new paradigm: AI that can do general-purpose complex reasoning.
o1-preview and o1-mini are available today (ramping over some number of hours) in ChatGPT for plus and team users and our API for tier 5 users.
3/4
screenshot of eval results in the tweet above and more in the blog post, but worth especially noting:
a fine-tuned version of o1 scored at the 49th percentile in the IOI under competition conditions! and got gold with 10k submissions per problem.
4/4
extremely proud of the team; this was a monumental effort across the entire company.
hope you enjoy it!
here is o1, a series of our most capable and aligned models yet:
https://openai.com/index/learning-to-reason-with-llms/
o1 is still flawed, still limited, and it still seems more impressive on first use than it does after you spend more time with it.
2/4
but also, it is the beginning of a new paradigm: AI that can do general-purpose complex reasoning.
o1-preview and o1-mini are available today (ramping over some number of hours) in ChatGPT for plus and team users and our API for tier 5 users.
3/4
screenshot of eval results in the tweet above and more in the blog post, but worth especially noting:
a fine-tuned version of o1 scored at the 49th percentile in the IOI under competition conditions! and got gold with 10k submissions per problem.
4/4
extremely proud of the team; this was a monumental effort across the entire company.
hope you enjoy it!

1/1
here is o1, a series of our most capable and aligned models yet:
https://openai.com/index/learning-to-reason-with-llms/
o1 is still flawed, still limited, and it still seems more impressive on first use than it does after you spend more time with it.
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
here is o1, a series of our most capable and aligned models yet:
https://openai.com/index/learning-to-reason-with-llms/
o1 is still flawed, still limited, and it still seems more impressive on first use than it does after you spend more time with it.
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
1/3
@rohanpaul_ai
OpenAI must have had a significant head start in understanding and applying the inference scaling laws.
One of the recent paper in this regard was
"Large Language Monkeys: Scaling Inference Compute with Repeated Sampling"
 The paper explores scaling inference compute by increasing sample count, in contrast to the common practice of using a single attempt. Results show coverage (problems solved by any attempt) scales consistently with sample count across tasks and models, over four orders of magnitude.
The paper explores scaling inference compute by increasing sample count, in contrast to the common practice of using a single attempt. Results show coverage (problems solved by any attempt) scales consistently with sample count across tasks and models, over four orders of magnitude.
Paper "Large Language Monkeys: Scaling Inference Compute with Repeated Sampling":
 Repeated sampling significantly improves coverage (fraction of problems solved by any attempt) across various tasks, models, and sample budgets. For example, with DeepSeek-V2-Coder-Instruct, solving 56% of SWE-bench Lite issues with 250 samples, exceeding single-attempt SOTA of 43%.
Repeated sampling significantly improves coverage (fraction of problems solved by any attempt) across various tasks, models, and sample budgets. For example, with DeepSeek-V2-Coder-Instruct, solving 56% of SWE-bench Lite issues with 250 samples, exceeding single-attempt SOTA of 43%.
Coverage often follows an exponentiated power law relationship with sample count: c ≈ exp(ak^-b), where c is coverage, k is sample count, and a,b are fitted parameters.
Within model families, coverage curves for different sizes exhibit similar shapes with horizontal offsets when plotted on a log scale.
Repeated sampling can amplify weaker models to outperform single attempts from stronger models, offering a new optimization dimension for performance vs. cost.
For math word problems lacking automatic verifiers, common verification methods (majority voting, reward models) plateau around 100 samples, while coverage continues increasing beyond 95% with 10,000 samples.
Challenges in verification:
- Math problems: Need to solve "needle-in-a-haystack" cases where correct solutions are rare.
- Coding tasks: Imperfect test suites can lead to false positives/negatives (e.g., 11.3% of SWE-bench Lite problems have flaky tests).
The paper proposes improving repeated sampling through: enhancing solution diversity beyond temperature sampling, incorporating multi-turn interactions with verification feedback, and learning from previous attempts.
2/3
@rohanpaul_ai
In contrast, a comparatively limited investment has been made in scaling the amount of computation used during inference.
Larger models do require more inference compute than smaller ones, and prompting techniques like chain-of-thought can increase answer quality at the cost of longer (and therefore more computationally expensive) outputs. However, when interacting with LLMs, users and developers often restrict models to making only one attempt when solving a problem.
So this paper investigates repeated sampling (depicted in below Figure 1) as an alternative axis for scaling inference compute to improve LLM reasoning performance.
3/3
@rohanpaul_ai
 [2407.21787] Large Language Monkeys: Scaling Inference Compute with Repeated Sampling
[2407.21787] Large Language Monkeys: Scaling Inference Compute with Repeated Sampling
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
@rohanpaul_ai
OpenAI must have had a significant head start in understanding and applying the inference scaling laws.
One of the recent paper in this regard was
"Large Language Monkeys: Scaling Inference Compute with Repeated Sampling"
The paper explores scaling inference compute by increasing sample count, in contrast to the common practice of using a single attempt. Results show coverage (problems solved by any attempt) scales consistently with sample count across tasks and models, over four orders of magnitude.Paper "Large Language Monkeys: Scaling Inference Compute with Repeated Sampling":
Repeated sampling significantly improves coverage (fraction of problems solved by any attempt) across various tasks, models, and sample budgets. For example, with DeepSeek-V2-Coder-Instruct, solving 56% of SWE-bench Lite issues with 250 samples, exceeding single-attempt SOTA of 43%.Coverage often follows an exponentiated power law relationship with sample count: c ≈ exp(ak^-b), where c is coverage, k is sample count, and a,b are fitted parameters.Within model families, coverage curves for different sizes exhibit similar shapes with horizontal offsets when plotted on a log scale.Repeated sampling can amplify weaker models to outperform single attempts from stronger models, offering a new optimization dimension for performance vs. cost.For math word problems lacking automatic verifiers, common verification methods (majority voting, reward models) plateau around 100 samples, while coverage continues increasing beyond 95% with 10,000 samples.Challenges in verification:- Math problems: Need to solve "needle-in-a-haystack" cases where correct solutions are rare.
- Coding tasks: Imperfect test suites can lead to false positives/negatives (e.g., 11.3% of SWE-bench Lite problems have flaky tests).
The paper proposes improving repeated sampling through: enhancing solution diversity beyond temperature sampling, incorporating multi-turn interactions with verification feedback, and learning from previous attempts.2/3
@rohanpaul_ai
In contrast, a comparatively limited investment has been made in scaling the amount of computation used during inference.
Larger models do require more inference compute than smaller ones, and prompting techniques like chain-of-thought can increase answer quality at the cost of longer (and therefore more computationally expensive) outputs. However, when interacting with LLMs, users and developers often restrict models to making only one attempt when solving a problem.
So this paper investigates repeated sampling (depicted in below Figure 1) as an alternative axis for scaling inference compute to improve LLM reasoning performance.
3/3
@rohanpaul_ai
[2407.21787] Large Language Monkeys: Scaling Inference Compute with Repeated SamplingTo post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196



1/11
@arcprize
We put OpenAI o1 to the test against ARC Prize.
Results: both o1 models beat GPT-4o. And o1-preview is on par with Claude 3.5 Sonnet.
Can chain-of-thought scale to AGI? What explains o1's modest scores on ARC-AGI?
Our notes:
OpenAI o1 Results on ARC-AGI-Pub
2/11
@TeemuMtt3
Sonnet 3.5 equals o1 in ARC, which confirms Anthropic has a 3 mont lead in time..
We should value more Sonnet 3.5!
3/11
@TheXeophon
That’s shockingly low, imo. Expected o1-preview to absolutely destroy Sonnet and be among the Top 3. Says a lot about ARC in a very positive sense.
4/11
@MelMitchell1
I'm confused by this plot.
The 46% by MindsAI is on the private test set, but42% by Greenblatt, and the 21% by o1-preview, are on the "semi-private validation set", correct?
If so, why are you plotting results from different sets on the same graph? Am I missing something?
5/11
@Shawnryan96
This test will not be beaten until dynamic learning happens. You can be as clever as you want but if its at all novel, until the weights change it doesn't really exist.
6/11
@phi_architect
yeah - but how did you prompt it?
you might need to talk to it differently
7/11
@Blznbreeze
@OpenAI recommends a different prompting style for the new model. Could using the same prompt as gpt4o have an effect on performance? What would be a better more strawberryish prompt?
8/11
@letalvoj
What's up with Sonnet?
9/11
@burny_tech
Hmm, I wonder how much would the AlphaZero-like RL with selfcorrecting CoT finetuning of o1 on ARC score on ARC challenge
10/11
@RiyanMendonsa
Wow!
Looks like they are no where close to reasoning here.
Curious what their thinking long and hard means then
11/11
@far__el
interested to see what mindsai scores with o1
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
@arcprize
We put OpenAI o1 to the test against ARC Prize.
Results: both o1 models beat GPT-4o. And o1-preview is on par with Claude 3.5 Sonnet.
Can chain-of-thought scale to AGI? What explains o1's modest scores on ARC-AGI?
Our notes:
OpenAI o1 Results on ARC-AGI-Pub
2/11
@TeemuMtt3
Sonnet 3.5 equals o1 in ARC, which confirms Anthropic has a 3 mont lead in time..
We should value more Sonnet 3.5!
3/11
@TheXeophon
That’s shockingly low, imo. Expected o1-preview to absolutely destroy Sonnet and be among the Top 3. Says a lot about ARC in a very positive sense.
4/11
@MelMitchell1
I'm confused by this plot.
The 46% by MindsAI is on the private test set, but42% by Greenblatt, and the 21% by o1-preview, are on the "semi-private validation set", correct?
If so, why are you plotting results from different sets on the same graph? Am I missing something?
5/11
@Shawnryan96
This test will not be beaten until dynamic learning happens. You can be as clever as you want but if its at all novel, until the weights change it doesn't really exist.
6/11
@phi_architect
yeah - but how did you prompt it?
you might need to talk to it differently
7/11
@Blznbreeze
@OpenAI recommends a different prompting style for the new model. Could using the same prompt as gpt4o have an effect on performance? What would be a better more strawberryish prompt?
8/11
@letalvoj
What's up with Sonnet?
9/11
@burny_tech
Hmm, I wonder how much would the AlphaZero-like RL with selfcorrecting CoT finetuning of o1 on ARC score on ARC challenge
10/11
@RiyanMendonsa
Wow!
Looks like they are no where close to reasoning here.
Curious what their thinking long and hard means then
11/11
@far__el
interested to see what mindsai scores with o1
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196

1/41
@aidan_mclau
it's a good model sir
2/41
@aidan_mclau
we reran aidan bench on top models at temp=0.7 (we used default temp for o1 and sonnet) and averaged 5 runs (this cost a lot)
we found aidan bench is temperature-sensitive, and we hope to increase num of runs and questions, which we think will stabilize performance
3/41
@aidan_mclau
i'm a bit hesitant to trust precise relative rankings here (sonnet might have had a bad day, 4o mini maybe had a great day), but two things are obvious:
>o1-mini is insane
>big models do seem to perform better on average
4/41
@aidan_mclau
o1 obviously demolishes, but this isn't an apples-to-apples comparison. we should grant best-of-n sampling to other models, CoT (right now, they zero-shot everything), or other enhancements
5/41
@aidan_mclau
i started the o1 run 5 minutes after release on thursday morning. it finished saturday morning. this model is slow, and the rate limits are brutal
6/41
@aidan_mclau
i also just suspect o1-mini architecturally differs from everything we've seen before. probably a mixture of depths or something clever. i'm curious to rerun this benchmark with o1-mini but force it to *not* use reasoning tokens. i expect it'll still do well
7/41
@aidan_mclau
regardless, o1-mini is a freak of nature.
i expected o1 to be a code/math one-trick pony. it's not. it' just really good.
i could not be more excited to use o1 to build machines that continuously learn and tackle open-ended questions
8/41
@SpencerKSchiff
Will you benchmark o1-preview or wait for o1?
9/41
@aidan_mclau
yeah when @OpenAIDevs gives me higher rate limits
10/41
@tszzl
the only benchmark that matters
11/41
@aidan_mclau
🫶
12/41
@pirchavez
i’m curious, why did you run across temps? have you found any correlation between temp and performance across models?
13/41
@aidan_mclau
didn't title is a mistake. sorry!
we ran everything at temp=0.7 and averaged scores
sonnet and o1 are run at default temp
14/41
@nddnjd18863
how is sonnet so low??
15/41
@aidan_mclau
unsure. it makes me wanna run it at 10 more interations but i can't justify that expense rn
16/41
@shoggoths_soul
Wow, way better than I expected. Is there a max score? Any idea of ~human level for your bench?
17/41
@aidan_mclau
no max score
i should take it and let you know haha
18/41
@chrypnotoad
Is it not locked at temp 1 for you?
19/41
@aidan_mclau
it is you can’t change it (used defaults for sonnet and o1)
20/41
@johnlu0x
What eval
21/41
@aidan_mclau
GitHub - aidanmclaughlin/Aidan-Bench: Aidan Bench attempts to measure <big_model_smell> in LLMs.
22/41
@Sarah_A_Bentley
Are you going to eventually integrate o1 into topology? What do you think would be the best way to do so?
23/41
@aidan_mclau
yes
will keep you posted
24/41
@zerosyscall
why are we comparing this to raw models when it's a CoT API?
25/41
@aidan_mclau
26/41
@maxalgorhythm
Pretty cool how o1 is dynamically adjusting its temperature during *thinking* based on the user prompt
27/41
@aidan_mclau
it is?
28/41
@UserMac29056
i’ve been waiting for this. great job!
29/41
@aidan_mclau
🫡
30/41
@iruletheworldmo
agi achieved internally
31/41
@gfodor
It does seem like mini is the star until o1 itself drops
32/41
@yupiop12
>Aidan approved
33/41
@loss_gobbler
b-but it’s j-just a sysprompt I can repo with my s-sysprompt look I made haiku count r’s
34/41
@Orwelian84
been waiting for this
35/41
@yayavarkm
This is really good
36/41
@airesearch12
funny how openai has managed to get rid of the term gpt (which was an awful marketing choice), just by calling their new model o1.
look at your comments, ppl have stopped saying GPT-4o, they say 4o or o1.
37/41
@DeepwriterAI
Never saw 4o performing that bad. It's usually topping those others (aside from o1). This doesn't add up.
38/41
@armanhaghighik
not even close..!
39/41
@ComputingByArts
wow, what a score!
I wonder what your bench would eventually show for o1-preview... Although cost is a problem...
40/41
@advaitjayant
very gud model
41/41
@BobbyGRG
not bad! it clearly is. And people asking "have you done something with it?" are a bit nuts. It was released less than 3 days ago! lol and it does behave differently than previous ones, api slightly different etc. It's a big unlock and we will see that before end if 2024 already
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
@aidan_mclau
it's a good model sir
2/41
@aidan_mclau
we reran aidan bench on top models at temp=0.7 (we used default temp for o1 and sonnet) and averaged 5 runs (this cost a lot)
we found aidan bench is temperature-sensitive, and we hope to increase num of runs and questions, which we think will stabilize performance
3/41
@aidan_mclau
i'm a bit hesitant to trust precise relative rankings here (sonnet might have had a bad day, 4o mini maybe had a great day), but two things are obvious:
>o1-mini is insane
>big models do seem to perform better on average
4/41
@aidan_mclau
o1 obviously demolishes, but this isn't an apples-to-apples comparison. we should grant best-of-n sampling to other models, CoT (right now, they zero-shot everything), or other enhancements
5/41
@aidan_mclau
i started the o1 run 5 minutes after release on thursday morning. it finished saturday morning. this model is slow, and the rate limits are brutal
6/41
@aidan_mclau
i also just suspect o1-mini architecturally differs from everything we've seen before. probably a mixture of depths or something clever. i'm curious to rerun this benchmark with o1-mini but force it to *not* use reasoning tokens. i expect it'll still do well
7/41
@aidan_mclau
regardless, o1-mini is a freak of nature.
i expected o1 to be a code/math one-trick pony. it's not. it' just really good.
i could not be more excited to use o1 to build machines that continuously learn and tackle open-ended questions
8/41
@SpencerKSchiff
Will you benchmark o1-preview or wait for o1?
9/41
@aidan_mclau
yeah when @OpenAIDevs gives me higher rate limits
10/41
@tszzl
the only benchmark that matters
11/41
@aidan_mclau
🫶
12/41
@pirchavez
i’m curious, why did you run across temps? have you found any correlation between temp and performance across models?
13/41
@aidan_mclau
didn't title is a mistake. sorry!
we ran everything at temp=0.7 and averaged scores
sonnet and o1 are run at default temp
14/41
@nddnjd18863
how is sonnet so low??
15/41
@aidan_mclau
unsure. it makes me wanna run it at 10 more interations but i can't justify that expense rn
16/41
@shoggoths_soul
Wow, way better than I expected. Is there a max score? Any idea of ~human level for your bench?
17/41
@aidan_mclau
no max score
i should take it and let you know haha
18/41
@chrypnotoad
Is it not locked at temp 1 for you?
19/41
@aidan_mclau
it is you can’t change it (used defaults for sonnet and o1)
20/41
@johnlu0x
What eval
21/41
@aidan_mclau
GitHub - aidanmclaughlin/Aidan-Bench: Aidan Bench attempts to measure <big_model_smell> in LLMs.
22/41
@Sarah_A_Bentley
Are you going to eventually integrate o1 into topology? What do you think would be the best way to do so?
23/41
@aidan_mclau
yes
will keep you posted
24/41
@zerosyscall
why are we comparing this to raw models when it's a CoT API?
25/41
@aidan_mclau
26/41
@maxalgorhythm
Pretty cool how o1 is dynamically adjusting its temperature during *thinking* based on the user prompt
27/41
@aidan_mclau
it is?
28/41
@UserMac29056
i’ve been waiting for this. great job!
29/41
@aidan_mclau
🫡
30/41
@iruletheworldmo
agi achieved internally
31/41
@gfodor
It does seem like mini is the star until o1 itself drops
32/41
@yupiop12
>Aidan approved
33/41
@loss_gobbler
b-but it’s j-just a sysprompt I can repo with my s-sysprompt look I made haiku count r’s
34/41
@Orwelian84
been waiting for this
35/41
@yayavarkm
This is really good
36/41
@airesearch12
funny how openai has managed to get rid of the term gpt (which was an awful marketing choice), just by calling their new model o1.
look at your comments, ppl have stopped saying GPT-4o, they say 4o or o1.
37/41
@DeepwriterAI
Never saw 4o performing that bad. It's usually topping those others (aside from o1). This doesn't add up.
38/41
@armanhaghighik
not even close..!
39/41
@ComputingByArts
wow, what a score!
I wonder what your bench would eventually show for o1-preview... Although cost is a problem...
40/41
@advaitjayant
very gud model
41/41
@BobbyGRG
not bad! it clearly is. And people asking "have you done something with it?" are a bit nuts. It was released less than 3 days ago! lol and it does behave differently than previous ones, api slightly different etc. It's a big unlock and we will see that before end if 2024 already
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196


1/31
@ProfTomYeh
How does OpenAI train the Strawberry (o1) model to spend more time thinking?
I read the report. The report is mostly about 𝘸𝘩𝘢𝘵 impressive benchmark results they got. But in term of the 𝘩𝘰𝘸, the report only offers one sentence:
"Through reinforcement learning, o1 learns to hone its chain of thought and refine the strategies it uses."
I did my best to understand this sentence. I drew this animation to share my best understanding with you.
The two key phrases in this sentence are: Reinforcement Learning (RL) and Chain of Thought (CoT).
Among the contributors listed in the report, two individuals stood out to me:
Ilya Sutskever, the inventor of RL with Human Feedback (RLHF). He left OpenAI and just started a new company, Safe Superintelligence. Listing Ilya tells me that RLHF still plays a role in training the Strawberry model.
Jason Wei, the author of the famous Chain of Thought paper. He left Google Brain to join OpenAI last year. Listing Jason tells me that CoT is now a big part of RLHF alignment process.
Here are the points I hope to get across in my animation:
 In RLHF+CoT, the CoT tokens are also fed to the reward model to get a score to update the LLM for better alignment, whereas in the traditional RLHF, only the prompt and response are fed to the reward model to align the LLM.
In RLHF+CoT, the CoT tokens are also fed to the reward model to get a score to update the LLM for better alignment, whereas in the traditional RLHF, only the prompt and response are fed to the reward model to align the LLM.
At the inference time, the model has learned to always start by generating CoT tokens, which can take up to 30 seconds, before starting to generate the final response. That's how the model is spending more time to think!
There are other important technical details missing, like how the reward model was trained, how human preferences for the "thinking process" were elicited...etc.
Finally, as a disclaimer, this animation represents my best educated guess. I can't verify the accuracy. I do wish someone from OpenAI can jump out to correct me. Because if they do, we will all learn something useful!
2/31
@modelsarereal
I think o1 learns CoT by RL by following steps:
1. AI generates synthetic task + answer.
2. o1 gets task and generates CoT answers
3. AI rewards those answers which solve the task
4. task + rewarded answer are used to finetune o1
3/31
@ProfTomYeh
This does make sense. Hope we get more tech info soon.
4/31
@cosminnegruseri
Ilya wasn't on the RLHF papers.
5/31
@ProfTomYeh
You are right. I will make a correction.
6/31
@NitroX919
Could they be using active inference?
Google used test time fine tuning for their math Olympiad AI
7/31
@ProfTomYeh
I am not sure. They may use it secretly. This tech report emphasizes cot.
8/31
@Teknium1
Watch the o1 announcement video, the cot is all synthetic.
9/31
@Cryptoprofeta1
But Chat GPT told me that Strawberry has 2 R in the word
10/31
@sauerlo
They did publish their STaR research months ago. Nothing intransparent or mysterious.
11/31
@AlwaysUhhJustin
I am guessing that the model starts by making a list of steps to perform and then executes on the step, and then has some accuracy/hallucination/confirmation step that potentially makes it loop. And then when all that is done, it outputs a response.
Generally agree on RL part
12/31
@shouheiant
@readwise save
13/31
@manuaero
Most likely: Model generates multiple steps, expert humans provide feedback (correct, incorrect), modify step if necessary. This data then used for RLHF
14/31
@dikksonPau
Not RLHF I think
15/31
@LatestPaperAI
CoT isn’t just a hack; it’s the architecture for deeper reasoning. The missing details? Likely where the real magic happens, but your framework holds.
16/31
@Ugo_alves
17/31
@arattml
18/31
@zacinabox
A dev in one of their videos essentially said “you have to make a guess, then see if that’s a right or wrong guess, and then backtrack if you get it wrong. So any type of task where you have to search through a space where you have different pieces pointing in different directions but there are mutual dependencies. You might get a bit of information that these two pieces contradict each other and our model is really good at refining the search space.”
19/31
@DrOsamaAhmed
This is fascinating explanation, thanks really for sharing it
20/31
@GlobalLife365
It’s simple. The code is slow so they decided to call it “thinking”. ChatGPT 4 is also thinking but a lot faster. It’s a gimmick.
21/31
@GuitarGeorge6
Q*
22/31
@ReneKriest
I bet they did some JavaScript setTimeout with a prompt “Think again!” and give it fancy naming.
23/31
@armin1i
What is the reward model? Gpt4o?
24/31
@Austin_Jung2003
I think there is "Facilitator" in the CoT inference step.
25/31
@alperakgun
if cot is baked in inference; then why is o1 too slow?
26/31
@wickedbrok
If the model was train to input Cot tokens, then it just aesthetic and doesn’t mean that the machine can actually think.
27/31
@Daoist_Wang
The idea is quite simple because we all learn in that way.
The key is to apply it in real practices.
So, I don't see anything beyond what GoogleDeepmind has done in Alphazero.
28/31
@dhruv2038
This is a great illustration!
I learn a lot from your videos!
29/31
@rnednur
Why can we not fine-tune COT tokens on existing open source models to do the same. What is the moat here?
30/31
@ThinkDi92468945
The model is trained with RL on preference data to generate high quality CoT reasoning. The hard part is to generate labeled preference data (CoTs for a given problem ranked from best to worst).
31/31
@JamesBe14335391
The recent Agent Q paper by the AGI company and Stanford hints at how this might work…
https://arxiv.org/pdf/2408.07199
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
@ProfTomYeh
How does OpenAI train the Strawberry
(o1) model to spend more time thinking?I read the report. The report is mostly about 𝘸𝘩𝘢𝘵 impressive benchmark results they got. But in term of the 𝘩𝘰𝘸, the report only offers one sentence:
"Through reinforcement learning, o1 learns to hone its chain of thought and refine the strategies it uses."
I did my best to understand this sentence. I drew this animation to share my best understanding with you.
The two key phrases in this sentence are: Reinforcement Learning (RL) and Chain of Thought (CoT).
Among the contributors listed in the report, two individuals stood out to me:
Ilya Sutskever, the inventor of RL with Human Feedback (RLHF). He left OpenAI and just started a new company, Safe Superintelligence. Listing Ilya tells me that RLHF still plays a role in training the Strawberry model.
Jason Wei, the author of the famous Chain of Thought paper. He left Google Brain to join OpenAI last year. Listing Jason tells me that CoT is now a big part of RLHF alignment process.
Here are the points I hope to get across in my animation:
In RLHF+CoT, the CoT tokens are also fed to the reward model to get a score to update the LLM for better alignment, whereas in the traditional RLHF, only the prompt and response are fed to the reward model to align the LLM.At the inference time, the model has learned to always start by generating CoT tokens, which can take up to 30 seconds, before starting to generate the final response. That's how the model is spending more time to think!There are other important technical details missing, like how the reward model was trained, how human preferences for the "thinking process" were elicited...etc.
Finally, as a disclaimer, this animation represents my best educated guess. I can't verify the accuracy. I do wish someone from OpenAI can jump out to correct me. Because if they do, we will all learn something useful!
2/31
@modelsarereal
I think o1 learns CoT by RL by following steps:
1. AI generates synthetic task + answer.
2. o1 gets task and generates CoT answers
3. AI rewards those answers which solve the task
4. task + rewarded answer are used to finetune o1
3/31
@ProfTomYeh
This does make sense. Hope we get more tech info soon.
4/31
@cosminnegruseri
Ilya wasn't on the RLHF papers.
5/31
@ProfTomYeh
You are right. I will make a correction.
6/31
@NitroX919
Could they be using active inference?
Google used test time fine tuning for their math Olympiad AI
7/31
@ProfTomYeh
I am not sure. They may use it secretly. This tech report emphasizes cot.
8/31
@Teknium1
Watch the o1 announcement video, the cot is all synthetic.
9/31
@Cryptoprofeta1
But Chat GPT told me that Strawberry has 2 R in the word
10/31
@sauerlo
They did publish their STaR research months ago. Nothing intransparent or mysterious.
11/31
@AlwaysUhhJustin
I am guessing that the model starts by making a list of steps to perform and then executes on the step, and then has some accuracy/hallucination/confirmation step that potentially makes it loop. And then when all that is done, it outputs a response.
Generally agree on RL part
12/31
@shouheiant
@readwise save
13/31
@manuaero
Most likely: Model generates multiple steps, expert humans provide feedback (correct, incorrect), modify step if necessary. This data then used for RLHF
14/31
@dikksonPau
Not RLHF I think
15/31
@LatestPaperAI
CoT isn’t just a hack; it’s the architecture for deeper reasoning. The missing details? Likely where the real magic happens, but your framework holds.
16/31
@Ugo_alves
17/31
@arattml
18/31
@zacinabox
A dev in one of their videos essentially said “you have to make a guess, then see if that’s a right or wrong guess, and then backtrack if you get it wrong. So any type of task where you have to search through a space where you have different pieces pointing in different directions but there are mutual dependencies. You might get a bit of information that these two pieces contradict each other and our model is really good at refining the search space.”
19/31
@DrOsamaAhmed
This is fascinating explanation, thanks really for sharing it
20/31
@GlobalLife365
It’s simple. The code is slow so they decided to call it “thinking”. ChatGPT 4 is also thinking but a lot faster. It’s a gimmick.
21/31
@GuitarGeorge6
Q*
22/31
@ReneKriest
I bet they did some JavaScript setTimeout with a prompt “Think again!” and give it fancy naming.
23/31
@armin1i
What is the reward model? Gpt4o?
24/31
@Austin_Jung2003
I think there is "Facilitator" in the CoT inference step.
25/31
@alperakgun
if cot is baked in inference; then why is o1 too slow?
26/31
@wickedbrok
If the model was train to input Cot tokens, then it just aesthetic and doesn’t mean that the machine can actually think.
27/31
@Daoist_Wang
The idea is quite simple because we all learn in that way.
The key is to apply it in real practices.
So, I don't see anything beyond what GoogleDeepmind has done in Alphazero.
28/31
@dhruv2038
This is a great illustration!
I learn a lot from your videos!
29/31
@rnednur
Why can we not fine-tune COT tokens on existing open source models to do the same. What is the moat here?
30/31
@ThinkDi92468945
The model is trained with RL on preference data to generate high quality CoT reasoning. The hard part is to generate labeled preference data (CoTs for a given problem ranked from best to worst).
31/31
@JamesBe14335391
The recent Agent Q paper by the AGI company and Stanford hints at how this might work…
https://arxiv.org/pdf/2408.07199
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196




1/3
@rohanpaul_ai
AutoToS: Automated version of Thought of Search, fantastic Paper from @IBMResearch
Achieved 100% accuracy across all evaluated domains
AutoToS generates sound, complete search components from LLMs without human feedback, achieving high accuracy across domains.
Original Problem :
:
LLMs struggle with planning tasks, particularly in terms of soundness and completeness. Existing approaches sacrifice soundness for flexibility, while the Thought of Search (ToS) method requires human feedback to produce sound search components.
Key Insights:
• LLMs can generate sound and complete search components with automated feedback
• Generic and domain-specific unit tests guide LLMs effectively
• Iterative refinement improves code quality without human intervention
• Smaller LLMs can achieve comparable performance to larger models
Solution in this Paper :
:
• Components:
- Initial prompts for successor and goal test functions
- Goal unit tests to verify soundness and completeness
- Successor soundness check using BFS with additional checks
- Optional successor completeness check
• Feedback loop:
- Provides error messages and examples to LLM
- Requests code revisions based on test failures
• Extends search algorithms with:
- Timeout checks
- Input state modification detection
- Partial soundness validation
Results :
:
• Minimal feedback iterations required (comparable to ToS with human feedback)
• Consistent performance across different LLM sizes
• Effective on 5 representative search/planning problems:
- BlocksWorld, PrOntoQA, Mini Crossword, 24 Game, Sokoban
2/3
@rohanpaul_ai
Step-by-step process of how AutoToS works, to systematically refine and improve the generated search components without human intervention.
Step 1:
Start with initial prompts asking for the successor function succ and the goal test isgoal.
Step 2 :
:
Perform goal unit tests, providing feedback to the model in cases of failure. Repeat this process until all goal unit tests have passed or a predefined number of iterations is exhausted.
Step 3 :
:
Once isgoal has passed the unit tests, perform a soundness check of the current succ and isgoal functions. This is done by plugging these functions into a BFS extended with additional checks and running it on a few example problem instances. If BFS finishes, check whether the goal was indeed reached. If not, provide feedback to the model and repeat Steps 2 and 3.
Step 4 (Optional) :
:
Once the previous steps are finished, perform the successor unit test, providing feedback to the language model in case of failure.
The process includes iterative feedback loops. Every time a goal test fails, the system goes back to Step 2. Every time the successor test fails, it goes back to Step 3. After the first step, there's always a succ and isgoal that can be plugged into a blind search algorithm, but if Step 3 fails, it indicates that the solutions produced by that algorithm can't be trusted.
3/3
@rohanpaul_ai
 https://arxiv.org/pdf/2408.11326
https://arxiv.org/pdf/2408.11326
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
@rohanpaul_ai
AutoToS: Automated version of Thought of Search, fantastic Paper from @IBMResearch
Achieved 100% accuracy across all evaluated domains
AutoToS generates sound, complete search components from LLMs without human feedback, achieving high accuracy across domains.
Original Problem
:LLMs struggle with planning tasks, particularly in terms of soundness and completeness. Existing approaches sacrifice soundness for flexibility, while the Thought of Search (ToS) method requires human feedback to produce sound search components.
Key Insights
:• LLMs can generate sound and complete search components with automated feedback
• Generic and domain-specific unit tests guide LLMs effectively
• Iterative refinement improves code quality without human intervention
• Smaller LLMs can achieve comparable performance to larger models
Solution in this Paper
:• Components:
- Initial prompts for successor and goal test functions
- Goal unit tests to verify soundness and completeness
- Successor soundness check using BFS with additional checks
- Optional successor completeness check
• Feedback loop:
- Provides error messages and examples to LLM
- Requests code revisions based on test failures
• Extends search algorithms with:
- Timeout checks
- Input state modification detection
- Partial soundness validation
Results
:• Minimal feedback iterations required (comparable to ToS with human feedback)
• Consistent performance across different LLM sizes
• Effective on 5 representative search/planning problems:
- BlocksWorld, PrOntoQA, Mini Crossword, 24 Game, Sokoban
2/3
@rohanpaul_ai
Step-by-step process of how AutoToS works, to systematically refine and improve the generated search components without human intervention.
Step 1
:Start with initial prompts asking for the successor function succ and the goal test isgoal.
Step 2
:Perform goal unit tests, providing feedback to the model in cases of failure. Repeat this process until all goal unit tests have passed or a predefined number of iterations is exhausted.
Step 3
:Once isgoal has passed the unit tests, perform a soundness check of the current succ and isgoal functions. This is done by plugging these functions into a BFS extended with additional checks and running it on a few example problem instances. If BFS finishes, check whether the goal was indeed reached. If not, provide feedback to the model and repeat Steps 2 and 3.
Step 4 (Optional)
:Once the previous steps are finished, perform the successor unit test, providing feedback to the language model in case of failure.
The process includes iterative feedback loops. Every time a goal test fails, the system goes back to Step 2. Every time the successor test fails, it goes back to Step 3. After the first step, there's always a succ and isgoal that can be plugged into a blind search algorithm, but if Step 3 fails, it indicates that the solutions produced by that algorithm can't be trusted.
3/3
@rohanpaul_ai
https://arxiv.org/pdf/2408.11326To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196



1/3
@rohanpaul_ai
Reverse Engineering o1 OpenAI Architecture with Claude
2/3
@NorbertEnders
The reverse engineered o1 OpenAI Architecture simplified and explained in a more narrative style, using layman’s terms.
I used Claude Sonnet 3.5 for that.
Keep in mind: it’s just an educated guess
3/3
@NorbertEnders
Longer version:
Imagine a brilliant but inexperienced chef named Alex. Alex's goal is to become a master chef who can create amazing dishes on the spot, adapting to any ingredient or cuisine challenge. This is like our language model aiming to provide intelligent, reasoned responses to any query.
Alex's journey begins with intense preparation:
First, Alex gathers recipes. Some are from famous cookbooks, others from family traditions, and many are creative variations Alex invents. This is like our model's Data Generation phase, collecting a mix of real and synthetic data to learn from.
Next comes Alex's training. It's not just about memorizing recipes, but understanding the principles of cooking. Alex practices in a special kitchen (our Training Phase) where:
1. Basic cooking techniques are mastered (Language Model training).
2. Alex plays cooking games, getting points for tasty dishes and helpful feedback when things go wrong (Reinforcement Learning).
3. Sometimes, the kitchen throws curveballs - like changing ingredients mid-recipe or having multiple chefs compete (Advanced RL techniques).
This training isn't a one-time thing. Alex keeps learning, always aiming to improve.
Now, here's where the real magic happens - when Alex faces actual cooking challenges (our Inference Phase):
1. A customer orders a dish. Alex quickly thinks of a recipe (Initial CoT Generation).
2. While cooking, Alex tastes the dish and adjusts seasonings (CoT Refinement).
3. For simple dishes, Alex works quickly. For complex ones, more time is taken to perfect it (Test-time Compute).
4. Alex always keeps an eye on the clock, balancing perfection with serving time (Efficiency Monitoring).
5. Finally, the dish is served (Final Response).
6. Alex remembers this experience for future reference (CoT Storage).
The key here is Alex's ability to reason and adapt on the spot. It's not about rigidly following recipes, but understanding cooking principles deeply enough to create new dishes or solve unexpected problems.
What makes Alex special is the constant improvement. After each shift, Alex reviews the day's challenges, learning from successes and mistakes (feedback loop). Over time, Alex becomes more efficient, creative, and adaptable.
In our language model, this inference process is where the real value lies. It's the ability to take a query (like a cooking order), reason through it (like Alex combining cooking knowledge to create a dish), and produce a thoughtful, tailored response (serving the perfect dish).
The rest of the system - the data collection, the intense training - are all in service of this moment of creation. They're crucial, but they're the behind-the-scenes work. The real magic, the part that amazes the 'customers' (users), happens in this inference stage.
Just as a master chef can delight diners with unique, perfectly crafted dishes for any request, our advanced language model aims to provide insightful, reasoned responses to any query, always learning and improving with each interaction.
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
@rohanpaul_ai
Reverse Engineering o1 OpenAI Architecture with Claude
2/3
@NorbertEnders
The reverse engineered o1 OpenAI Architecture simplified and explained in a more narrative style, using layman’s terms.
I used Claude Sonnet 3.5 for that.
Keep in mind: it’s just an educated guess
3/3
@NorbertEnders
Longer version:
Imagine a brilliant but inexperienced chef named Alex. Alex's goal is to become a master chef who can create amazing dishes on the spot, adapting to any ingredient or cuisine challenge. This is like our language model aiming to provide intelligent, reasoned responses to any query.
Alex's journey begins with intense preparation:
First, Alex gathers recipes. Some are from famous cookbooks, others from family traditions, and many are creative variations Alex invents. This is like our model's Data Generation phase, collecting a mix of real and synthetic data to learn from.
Next comes Alex's training. It's not just about memorizing recipes, but understanding the principles of cooking. Alex practices in a special kitchen (our Training Phase) where:
1. Basic cooking techniques are mastered (Language Model training).
2. Alex plays cooking games, getting points for tasty dishes and helpful feedback when things go wrong (Reinforcement Learning).
3. Sometimes, the kitchen throws curveballs - like changing ingredients mid-recipe or having multiple chefs compete (Advanced RL techniques).
This training isn't a one-time thing. Alex keeps learning, always aiming to improve.
Now, here's where the real magic happens - when Alex faces actual cooking challenges (our Inference Phase):
1. A customer orders a dish. Alex quickly thinks of a recipe (Initial CoT Generation).
2. While cooking, Alex tastes the dish and adjusts seasonings (CoT Refinement).
3. For simple dishes, Alex works quickly. For complex ones, more time is taken to perfect it (Test-time Compute).
4. Alex always keeps an eye on the clock, balancing perfection with serving time (Efficiency Monitoring).
5. Finally, the dish is served (Final Response).
6. Alex remembers this experience for future reference (CoT Storage).
The key here is Alex's ability to reason and adapt on the spot. It's not about rigidly following recipes, but understanding cooking principles deeply enough to create new dishes or solve unexpected problems.
What makes Alex special is the constant improvement. After each shift, Alex reviews the day's challenges, learning from successes and mistakes (feedback loop). Over time, Alex becomes more efficient, creative, and adaptable.
In our language model, this inference process is where the real value lies. It's the ability to take a query (like a cooking order), reason through it (like Alex combining cooking knowledge to create a dish), and produce a thoughtful, tailored response (serving the perfect dish).
The rest of the system - the data collection, the intense training - are all in service of this moment of creation. They're crucial, but they're the behind-the-scenes work. The real magic, the part that amazes the 'customers' (users), happens in this inference stage.
Just as a master chef can delight diners with unique, perfectly crafted dishes for any request, our advanced language model aims to provide insightful, reasoned responses to any query, always learning and improving with each interaction.
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
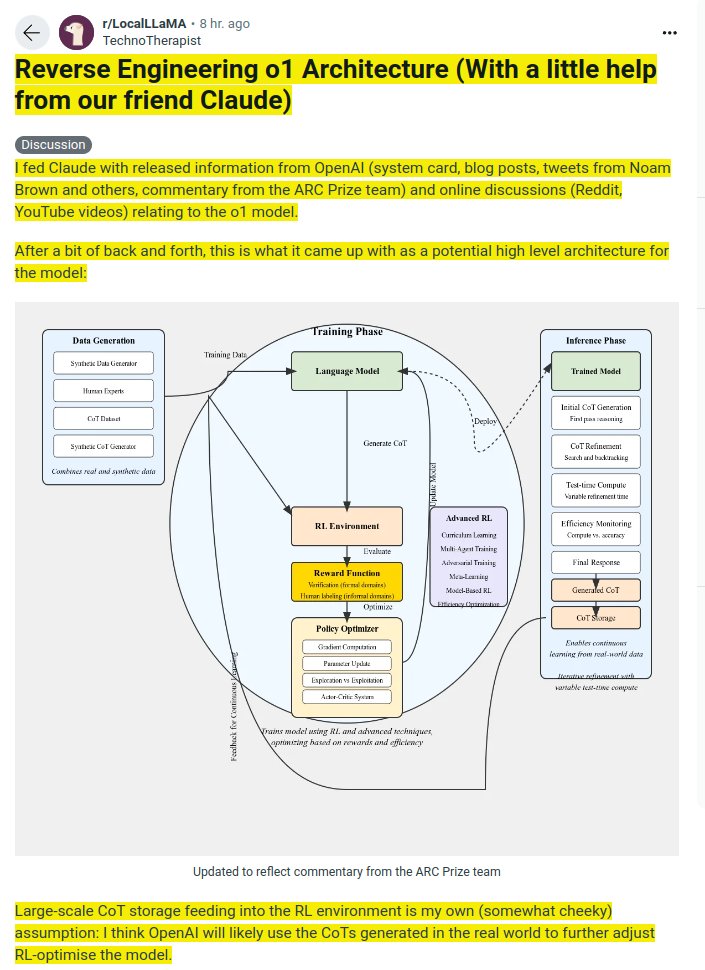


1/4
remember anthropic's claim that 2025-2026 the gap is going to be too large for any competitor to catch up?
that o1 rl data fly wheel is escape velocity
[Quoted tweet]
Many (including me) who believed in RL were waiting for a moment when it will start scaling in a general domain similarly to other successful paradigms. That moment finally has arrived and signifies a meaningful increase in our understanding of training neural networks
2/4
the singularitarians rn: rl scaling in general domain...? wait a sec...
3/4
another nice side effect of tighly rationing o1 is that high S/N on quality hard queries they will be receiving. ppl will largely only consult o1 for *important* tasks, easy triage
the story rly writes itself here guys
[Quoted tweet]
at only 30 requests - im going to think long and hard before i consult the oracle.
4/4
u cannot move a single step without extrapolating even a little, we draw lines regardless, including u. i am inclined to believe them here, shouldn't take too long to confirm that suspicion tho
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
remember anthropic's claim that 2025-2026 the gap is going to be too large for any competitor to catch up?
that o1 rl data fly wheel is escape velocity
[Quoted tweet]
Many (including me) who believed in RL were waiting for a moment when it will start scaling in a general domain similarly to other successful paradigms. That moment finally has arrived and signifies a meaningful increase in our understanding of training neural networks
2/4
the singularitarians rn: rl scaling in general domain...? wait a sec...
3/4
another nice side effect of tighly rationing o1 is that high S/N on quality hard queries they will be receiving. ppl will largely only consult o1 for *important* tasks, easy triage
the story rly writes itself here guys
[Quoted tweet]
at only 30 requests - im going to think long and hard before i consult the oracle.
4/4
u cannot move a single step without extrapolating even a little, we draw lines regardless, including u. i am inclined to believe them here, shouldn't take too long to confirm that suspicion tho
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196

[Submitted on 9 Sep 2024]
LLMs Will Always Hallucinate, and We Need to Live With This
Sourav Banerjee, Ayushi Agarwal, Saloni SinglaAs Large Language Models become more ubiquitous across domains, it becomes important to examine their inherent limitations critically. This work argues that hallucinations in language models are not just occasional errors but an inevitable feature of these systems. We demonstrate that hallucinations stem from the fundamental mathematical and logical structure of LLMs. It is, therefore, impossible to eliminate them through architectural improvements, dataset enhancements, or fact-checking mechanisms. Our analysis draws on computational theory and Godel's First Incompleteness Theorem, which references the undecidability of problems like the Halting, Emptiness, and Acceptance Problems. We demonstrate that every stage of the LLM process-from training data compilation to fact retrieval, intent classification, and text generation-will have a non-zero probability of producing hallucinations. This work introduces the concept of Structural Hallucination as an intrinsic nature of these systems. By establishing the mathematical certainty of hallucinations, we challenge the prevailing notion that they can be fully mitigated.
| Subjects: | Machine Learning (stat.ML); Machine Learning (cs.LG) |
| Cite as: | arXiv:2409.05746 [stat.ML] |
| (or arXiv:2409.05746v1 [stat.ML] for this version) | |
| https://doi.org/10.48550/arXiv.2409.05746 |
Submission history
From: Sourav Banerjee [view email]
[v1] Mon, 9 Sep 2024 16:01:58 UTC (1,938 KB)
LLMs Will Always Hallucinate, and We Need to Live with This | Hacker News
 news.ycombinator.com
news.ycombinator.com
PoseTalk is a lip-sync method that can generate talking head videos from a single image, audio, and text prompts.
1/2
Be wary of deep fakes!
PoseTalk is a lip-sync method that can generate talking head videos from a single image, audio, and text prompts.
PoseTalk
2/2
Nope
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
Be wary of deep fakes!
PoseTalk is a lip-sync method that can generate talking head videos from a single image, audio, and text prompts.
PoseTalk
2/2
Nope
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196