Research update on ultra-long context models, our partnership with Google Cloud, and new funding.

magic.dev
Blog
100M Token Context Windows
Research update on ultra-long context models, our partnership with Google Cloud, and new funding.
Magic Team, on August 29, 2024
There are currently two ways for AI models to learn things: training, and in-context during inference. Until now, training has dominated, because contexts are relatively short. But ultra-long context could change that.
Instead of relying on fuzzy memorization, our LTM (Long-Term Memory) models are trained to reason on up to 100M tokens of context given to them during inference.
While the commercial applications of these ultra-long context models are plenty, at Magic we are focused on the domain of software development.
It’s easy to imagine how much better code synthesis would be if models had all of your code, documentation, and libraries in context, including those not on the public internet.
Evaluating Context Windows
Current long context evals aren’t great. The popular
Needle In A Haystack eval places a random fact ('the needle') in the middle of the long context window ('haystack'), and asks the model to retrieve the fact.
Needle In A Haystack
However, “Arun and Max having coffee at Blue Bottle” stands out in a fiction novel about whales. By learning to recognize the unusual nature of the “needle”, the model can ignore otherwise relevant information in the “haystack”, reducing the required storage capacity to less than it would be on real tasks. It also only requires attending to a tiny, semantically recognizable part of the context, allowing even methods like RAG to appear successful.
Mamba’s (Section 4.1.2) and
H3's (Appendix E.1)
induction head benchmark makes this even easier. They use (and train with) a special token to explicitly signal the start of the needle, weakening the storage and retrieval difficulty of the eval to O(1). This is like knowing which question will come up in an exam before you start studying.
These subtle flaws weaken current long context evals in ways that allow traditional Recurrent Neural Networks (RNNs) and State Space Models (SSMs) to score well despite their fundamentally limiting, small O(1)-sized state vector.
To eliminate these implicit and explicit semantic hints, we’ve designed
HashHop.
Hashes are random and thus incompressible, requiring the model to be able to store and retrieve from the maximum possible
information content for a given context size at all times.
Concretely, we prompt a model trained on hashes with hash pairs:
...
jJWlupoT → KmsFrnRa
vRLWdcwV → sVLdzfJu
YOJVrdjK → WKPUyWON
OepweRIW → JeIrWpvs
JeqPlFgA → YirRppTA
...
Then, we ask it to complete the value of a randomly selected hash pair:
Completion YOJVrdjK → WKPUyWON
This measures the emergence of single-step
induction heads, but practical applications often require multiple hops. Picture variable assignments or library imports in your codebase.
To incorporate this, we ask the model to complete a chain of hashes instead (as recently proposed by
RULER):
Hash 1 → Hash 2
Hash 2 → Hash 3
Hash 3 → Hash 4
Hash 4 → Hash 5
Hash 5 → Hash 6
Completion Hash 1 → Hash 2 Hash 3 Hash 4 Hash 5 Hash 6
For order- and
position-invariance, we shuffle the hash pairs in the prompt:
...
Hash 72 → Hash 81
Hash 4 → Hash 5
Hash 1 → Hash 2
Hash 17 → Hash 62
Hash 2 → Hash 3
Hash 52 → Hash 99
Hash 34 → Hash 12
Hash 3 → Hash 4
Hash 71 → Hash 19
Hash 5 → Hash 6
...
Completion Hash 1 → Hash 2 Hash 3 Hash 4 Hash 5 Hash 6
Writing out all intermediate hashes is similar to how
chain of thought allows models to spread out reasoning over time. We also propose a more challenging variant where the model skips steps, e.g. going directly from Hash 1 to Hash 6:
Completion Hash 1 → Hash 6
This requires the model architecture to be able to attend and jump across multiple points of the entire context in latent space in one go.
In addition to evaluating models on code and language, we found training small models on hashes and measuring performance on these toy tasks to be a useful tool for our architecture research.
If you would like to use HashHop, you can
find it on GitHub.
Magic's progress on ultra long context
We have recently trained our first 100M token context model: LTM-2-mini. 100M tokens equals ~10 million lines of code or ~750 novels.
For each decoded token, LTM-2-mini’s sequence-dimension algorithm is roughly 1000x cheaper than the attention mechanism in Llama 3.1 405B<a href="
100M Token Context Windows" data-footnote-ref="true">1</a> for a 100M token context window.
The contrast in memory requirements is even larger – running Llama 3.1 405B with a 100M token context requires
638 H100s per user just to store a single 100M token KV cache.<a href="
100M Token Context Windows" data-footnote-ref="true">2</a> In contrast, LTM requires a small fraction of a single H100’s HBM per user for the same context.
Trained on hashes with chain of thought, the LTM architecture gets the following results:
100%100%100%100%100%100%100%100%95%95%100%100%100%100%100%100%100%100%95%85%100%100%100%100%100%100%100%100%95%90%100%100%100%100%100%100%100%100%95%90%100%100%100%100%100%100%100%100%95%90%100%100%100%100%100%100%100%100%95%90%100k200k1M2M4M8M16M32M50M100M123456Context length (tokens)Hop count10080604020
With our choice of hyperparameters for this particular model, we see worsening performance when trying 3 or more hops without chain of thought, but for 2 hops at once (Hash 1 → Hash 3), without chain of thought, we see strong results, indicating the model is able to build more complex circuits than single induction heads:
100%100%100%100%100%100%100%100%95%80%100k200k1M2M4M8M16M32M50M100M2Context length (tokens)Hop count10080604020
We also trained a prototype model on text-to-diff data with our ultra-long context attention mechanism. It’s several orders of magnitude smaller than frontier models, so we would be the first to admit that its code synthesis abilities were not good enough yet, but it produced the occasional reasonable output:
In-context GUI framework
Our model successfully created a calculator using a custom in-context GUI framework, showcasing its capability for real-time learning. Although generating a calculator is a simple task for state-of-the-art models when using well-known frameworks like React, the use of a custom in-context framework is more challenging. The model is prompted with just the codebase and the chat (no open files, edit history, or other indicators).
Simple UI change
Our model was able to implement a password strength meter for the open source repo
Documenso without human intervention. The issue description is more specific than we would expect it to be in a real-world scenario and the feature is common among many web applications. Still, a model several orders of magnitude smaller than today’s frontier models was able to edit a complex codebase unassisted.
We are now training a large LTM-2 model on our new supercomputer.
Partnership with Google Cloud to build NVIDIA GB200 NVL72 cluster
Magic partners with Google Cloud
We are building our next two supercomputers on Google Cloud: Magic-G4, powered by NVIDIA H100 Tensor Core GPUs, and Magic-G5, powered by NVIDIA GB200 NVL72, with the ability to scale to tens of thousands of Blackwell GPUs over time.
“We are excited to partner with Google and NVIDIA to build our next-gen AI supercomputer on Google Cloud. NVIDIA’s GB200 NLV72 system will greatly improve inference and training efficiency for our models, and Google Cloud offers us the fastest timeline to scale, and a rich ecosystem of cloud services.” – Eric Steinberger, CEO & Co-founder at Magic
“Google Cloud’s end-to-end AI platform provides high-growth, fast-moving companies like Magic with complete hardware and software capabilities for building AI models and applications at scale. Through this partnership, Magic will utilize Google Cloud’s AI Platform services including a variety of leading NVIDIA chips and AI tooling from Vertex AI to build and train its next generation of models and to bring products to market more quickly.” – Amin Vahdat, VP and GM of ML, Services, and Cloud AI at Google Cloud
“The current and future impact of AI is fueled to a great extent by the development of increasingly capable large language models. Powered by one of the largest installations of the NVIDIA GB200 NVL72 rack-scale design to date, the Magic-G5 supercomputer on Google Cloud will provide Magic with the compute resources needed to train, deploy and scale large language models – and push the boundaries of what AI can achieve.” – Ian Buck, Vice President of Hyperscale and HPC at NVIDIA
New funding
We’ve raised a total of $465M, including a recent investment of $320 million from new investors Eric Schmidt, Jane Street, Sequoia, Atlassian, among others, and existing investors Nat Friedman & Daniel Gross, Elad Gil, and CapitalG.
Join us
Pre-training only goes so far; we believe inference-time compute is the next frontier in AI. Imagine if you could spend $100 and 10 minutes on an issue and reliably get a great pull request for an entire feature. That’s our goal.
To train and serve 100M token context models, we needed to write an entire training and inference stack from scratch (no torch autograd, lots of custom CUDA, no open-source foundations) and run experiment after experiment on how to stably train our models. Inference-time compute is an equally challenging project.
We are 23 people (+ 8000 H100s) and are
hiring more Engineers and Researchers to accelerate our work and deploy upcoming models.
Over time, we will scale up to tens of thousands of GB200s. We are hiring
Supercomputing and
Systems Engineers to work alongside Ben Chess (former OpenAI Supercomputing Lead).
Sufficiently advanced AI should be treated with the same sensitivity as the nuclear industry. In addition to our commitments to
standard safety testing, we want Magic to be great at cybersecurity and push for higher regulatory standards. We are hiring for a
Head of Security to lead this effort.
Footnotes
The FLOPs cost of Llama 405B’s attention mechanism is n_layers * n_heads * d_head * n_ctx * 2 per output token. At 100M context, our mechanism is roughly 1000 times cheaper for LTM-2-Mini. For our largest LTM-2 model, context will be roughly twice as expensive as for LTM-2-mini, so still 500x cheaper than Llama 405B. This comparison focuses on Llama's attention mechanism and our LTM mechanism’s FLOPs and memory bandwidth load. Costs from other parts of the model, such as Llama’s MLP, that have constant cost with respect to context size for each decoded token are not considered. ↩
126 layers * 8 GQA groups * 128 d_head * 2 bytes * 2 (for k & v) * 100 million = 51TB. An H100 has 80GB of memory. 51TB / 80GB = 637.5 H100s. ↩
Follow Magic on
Vulnerability DisclosureAGI Readiness Policy
Magic AI Inc. Copyright © 2024 All rights reserved.

 Fast Generalizable Gaussian Splatting Reconstruction from Multi-View Stereo
Fast Generalizable Gaussian Splatting Reconstruction from Multi-View Stereo Explore More: MVSGaussian: Fast Generalizable Gaussian Splatting Reconstruction from Multi-View Stereo
Explore More: MVSGaussian: Fast Generalizable Gaussian Splatting Reconstruction from Multi-View Stereo
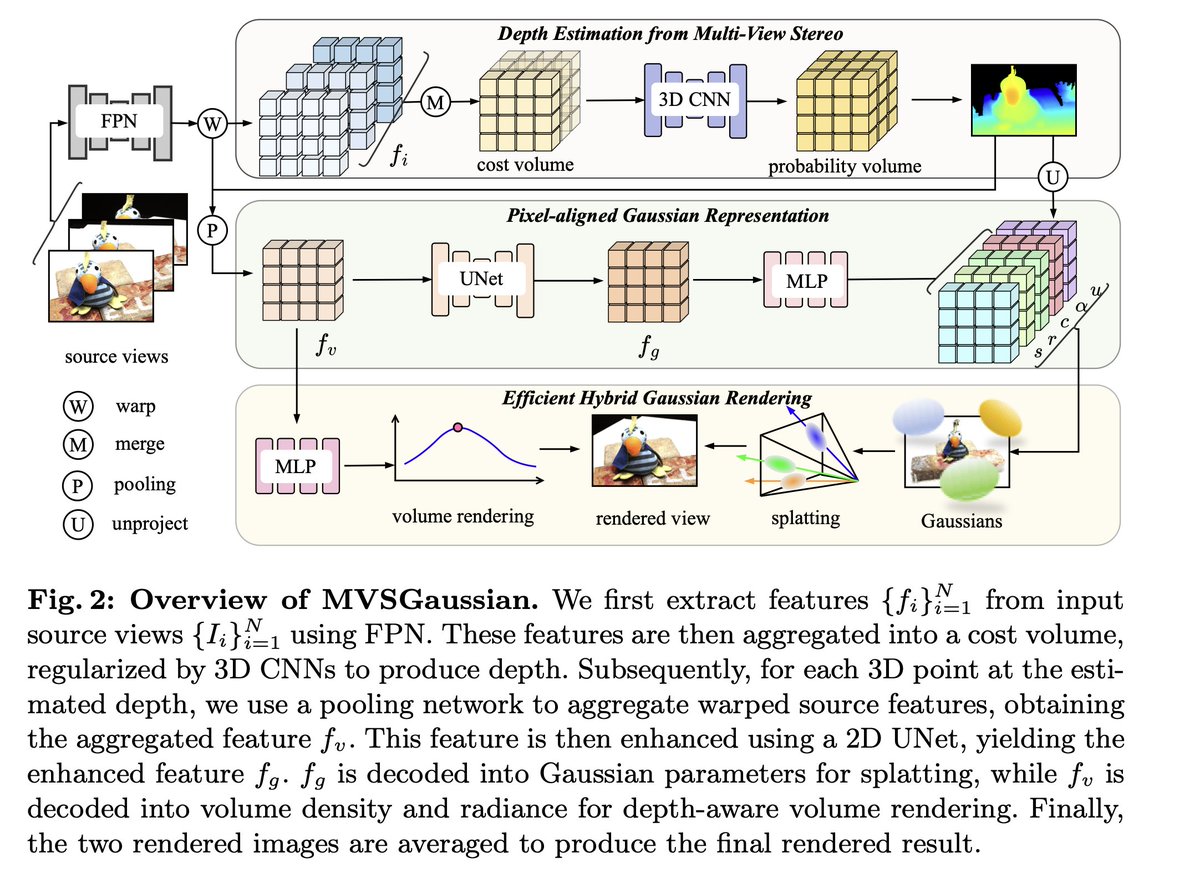








 For data preprocessing, we use DUSt3R for depth prediction of image pairs, and during inference, it works well with any off-the-shelf MDE like Zoedepth. And, we will make the code and checkpoint public soon!
For data preprocessing, we use DUSt3R for depth prediction of image pairs, and during inference, it works well with any off-the-shelf MDE like Zoedepth. And, we will make the code and checkpoint public soon!


 Introducing AltCanvas- a new tool blending generative AI with a tile-based interface to empower visually impaired creators! AltCanvas combines a novel tile-based authoring approach with Generative AI, allowing users to build complex scenes piece by piece. /search?q=#assets2024
Introducing AltCanvas- a new tool blending generative AI with a tile-based interface to empower visually impaired creators! AltCanvas combines a novel tile-based authoring approach with Generative AI, allowing users to build complex scenes piece by piece. /search?q=#assets2024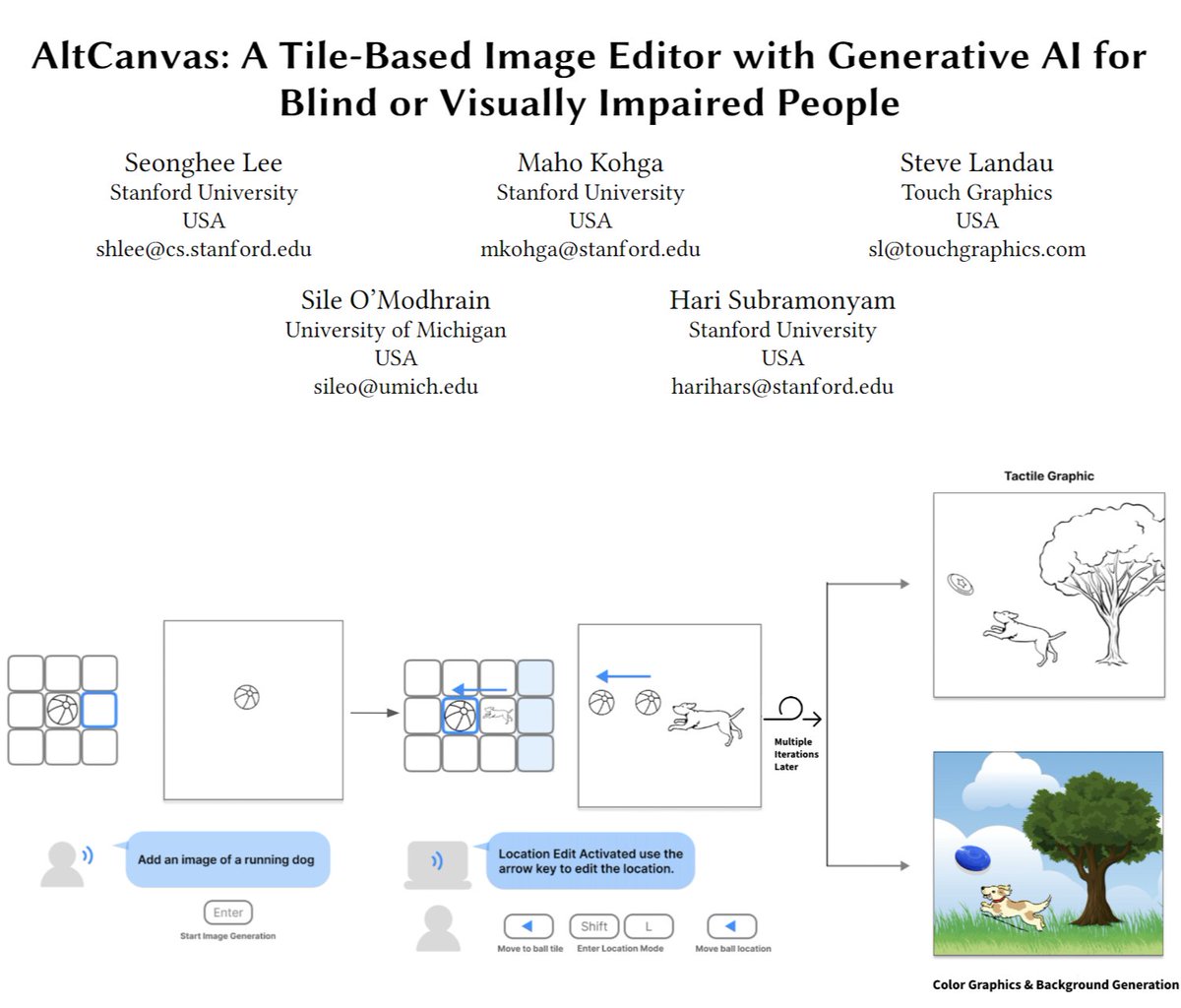
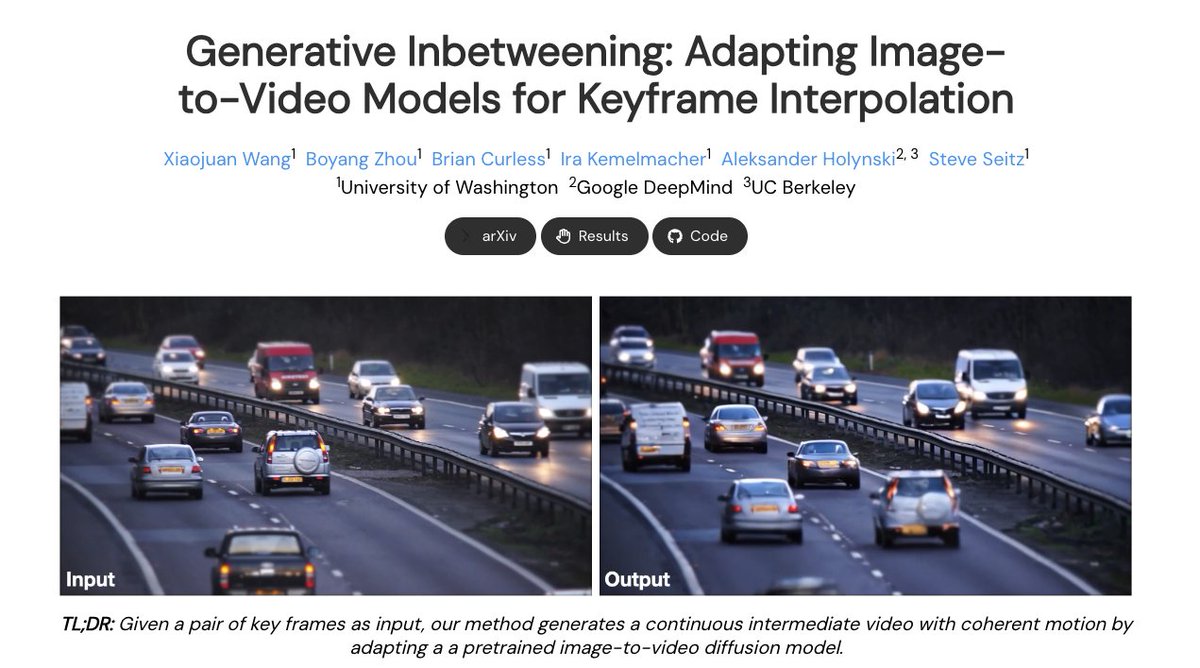




 More info below
More info below



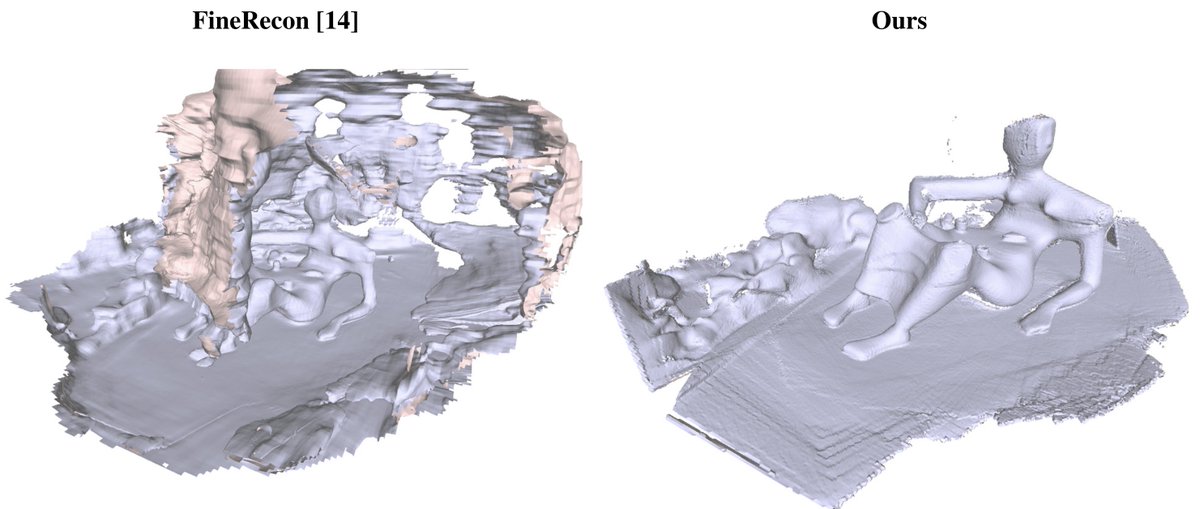
 ? Wish you could get fast
? Wish you could get fast  ?
? .
. ? One depth map alone isn’t perfect. Even a fused mesh will have bias and errors
? One depth map alone isn’t perfect. Even a fused mesh will have bias and errors  .
. .
.