1/26
Reflection Llama 3.1 70B independent eval results: We have been unable to replicate the eval results claimed in our independent testing and are seeing worse performance than Meta’s Llama 3.1 70B, not better.
These evaluations were conducted using our standard methodology, including using our standard system prompt and accessing the model via DeepInfra’s API, which claims bf16 precision. Our evaluation methodology uses a 0-shot prompt with a think step by step instruction.
This is not to say there is no merit in Reflective's prompting approach for achieving higher evaluation results as claimed. We are aware that the Glaive team has been updating the model, and we would be more than happy to test further releases.
We also ran tests comparing our standard system prompt to Glaive’s provided system prompt and we did not observe any differences in the evaluation results on Reflection Llama 3.1 70B, Llama 3.1 70B, GPT-4o or Claude 3.5 Sonnet.
This does not mean the claimed results were not achieved, but we look forward to hearing more about the evaluation approach that led to these results, particularly regarding the exact prompt used and how the evaluation answers were extracted.
2/26
According to the Glaive team, the model was incorrectly uploaded to Hugging Face. We plan to re-run our evaluations after the model is re-uploaded correctly.
We think it would also be helpful if the Glaive team could share exactly how they prompted and extracted the answers in achieving the eval results claimed. This will allow us to to attempt to re-produce the results and also test other models (Meta's Llama 3.1 70B & 405B, GPT-4o, etc) using the exact same approach for to comparisons.
to comparisons.
3/26
Was the format of the output correct? Eg the reflection tags
4/26
Yes, example MMLU response:
5/26
6/26
There was an issue with the uploaded weights. You migh t want to wait for the new release to test it
7/26
Thanks! Noted -
8/26
Do you plan on running the eval again after @mattshumer_ resolved the issues with the repo?
9/26
Yes!
10/26
did you try it before or after they fixed an issue?
I noticed about 15hr ago the deepinfra endpoint started working better, the endpoint started to produce the xml tokens.
11/26
Ran after they fixed the issue. Also ran on Hyperbolic and saw near-identical results
12/26
Thanks for posting about this. With the technique proposed, it's very important to hear more on the how the evaluation was done.
13/26
Thanks for this, specially for writing it in a professional/ respectful way instead of going for the nasty, hurtful language and all the clicks it generates.

14/26
Thank you for your analysis!
15/26
@mattshumer_ said that it is the wrong weights, and he is working on getting out the right ones.
16/26
I told you guys, there's no way it was possible, they didn't publish their testing methods, just the weights. Then they supposedly had issues with getting the thing uploaded right, and now they're retraining it?
I doubt they ever had anything that level to begin with.
I could be wrong, and I hope I am as it would be nice, but I'm very skeptical.
17/26
You are really nice.
After the first fumble everyone should have given him some time for the dust to settle.
18/26
They have uploaded the model wrong
19/26
the model weights were broken, here the correct ones
20/26
@mattshumer_ said there was unintentional merging of weights, he's reuploading the correct weights.
21/26
What about the Reflection 70B non-Llama performance?
22/26
The reasoning cannot be correct. Multiple reasoning tests like the prompts from open source Livebench (dot) ai show increased performance over llama 70B.
23/26
Models like the GPU they where trained on
24/26
Thanks for doing this, If it was so easy to just finetune and achieve groundbreaking results, everyone would have done it by now. While yes this may improve few things, it probably is costing more on others. In a non-scientific way, I was able to achive all this with a proper system prompt to 70b.
25/26
26/26
called it, I win. the thing shat out 5 paragraphs about how no one should disparage anyone based on sex because I asked it about masculine republics and feminine democracies as per effin aristotle.
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
Reflection Llama 3.1 70B independent eval results: We have been unable to replicate the eval results claimed in our independent testing and are seeing worse performance than Meta’s Llama 3.1 70B, not better.
These evaluations were conducted using our standard methodology, including using our standard system prompt and accessing the model via DeepInfra’s API, which claims bf16 precision. Our evaluation methodology uses a 0-shot prompt with a think step by step instruction.
This is not to say there is no merit in Reflective's prompting approach for achieving higher evaluation results as claimed. We are aware that the Glaive team has been updating the model, and we would be more than happy to test further releases.
We also ran tests comparing our standard system prompt to Glaive’s provided system prompt and we did not observe any differences in the evaluation results on Reflection Llama 3.1 70B, Llama 3.1 70B, GPT-4o or Claude 3.5 Sonnet.
This does not mean the claimed results were not achieved, but we look forward to hearing more about the evaluation approach that led to these results, particularly regarding the exact prompt used and how the evaluation answers were extracted.
2/26
According to the Glaive team, the model was incorrectly uploaded to Hugging Face. We plan to re-run our evaluations after the model is re-uploaded correctly.
We think it would also be helpful if the Glaive team could share exactly how they prompted and extracted the answers in achieving the eval results claimed. This will allow us to to attempt to re-produce the results and also test other models (Meta's Llama 3.1 70B & 405B, GPT-4o, etc) using the exact same approach for
to comparisons. 3/26
Was the format of the output correct? Eg the reflection tags
4/26
Yes, example MMLU response:
5/26
6/26
There was an issue with the uploaded weights. You migh t want to wait for the new release to test it
7/26
Thanks! Noted -
8/26
Do you plan on running the eval again after @mattshumer_ resolved the issues with the repo?
9/26
Yes!
10/26
did you try it before or after they fixed an issue?
I noticed about 15hr ago the deepinfra endpoint started working better, the endpoint started to produce the xml tokens.
11/26
Ran after they fixed the issue. Also ran on Hyperbolic and saw near-identical results
12/26
Thanks for posting about this. With the technique proposed, it's very important to hear more on the how the evaluation was done.
13/26
Thanks for this, specially for writing it in a professional/ respectful way instead of going for the nasty, hurtful language and all the clicks it generates.
14/26
Thank you for your analysis!
15/26
@mattshumer_ said that it is the wrong weights, and he is working on getting out the right ones.
16/26
I told you guys, there's no way it was possible, they didn't publish their testing methods, just the weights. Then they supposedly had issues with getting the thing uploaded right, and now they're retraining it?
I doubt they ever had anything that level to begin with.
I could be wrong, and I hope I am as it would be nice, but I'm very skeptical.
17/26
You are really nice.
After the first fumble everyone should have given him some time for the dust to settle.
18/26
They have uploaded the model wrong
19/26
the model weights were broken, here the correct ones
20/26
@mattshumer_ said there was unintentional merging of weights, he's reuploading the correct weights.
21/26
What about the Reflection 70B non-Llama performance?
22/26
The reasoning cannot be correct. Multiple reasoning tests like the prompts from open source Livebench (dot) ai show increased performance over llama 70B.
23/26
Models like the GPU they where trained on
24/26
Thanks for doing this, If it was so easy to just finetune and achieve groundbreaking results, everyone would have done it by now. While yes this may improve few things, it probably is costing more on others. In a non-scientific way, I was able to achive all this with a proper system prompt to 70b.
25/26
26/26
called it, I win. the thing shat out 5 paragraphs about how no one should disparage anyone based on sex because I asked it about masculine republics and feminine democracies as per effin aristotle.
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196

1/5
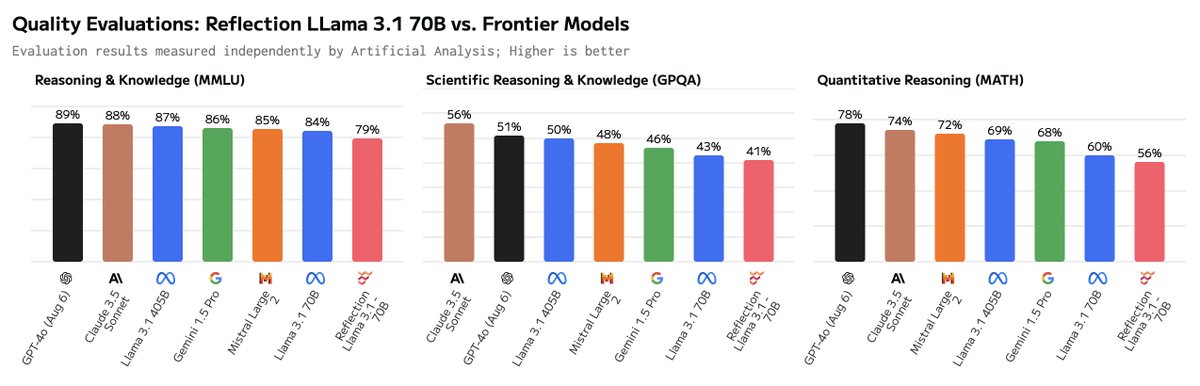
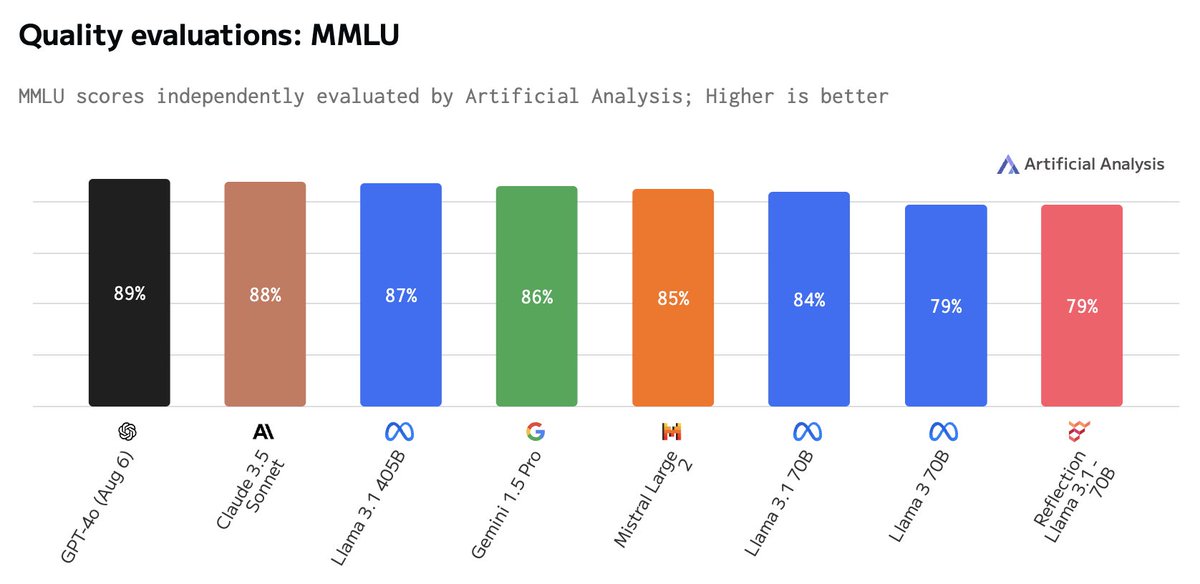
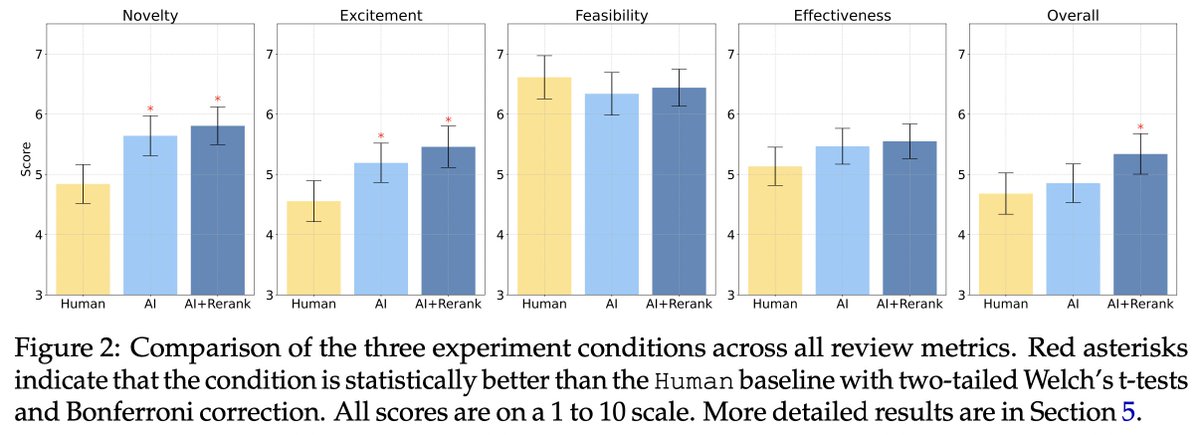
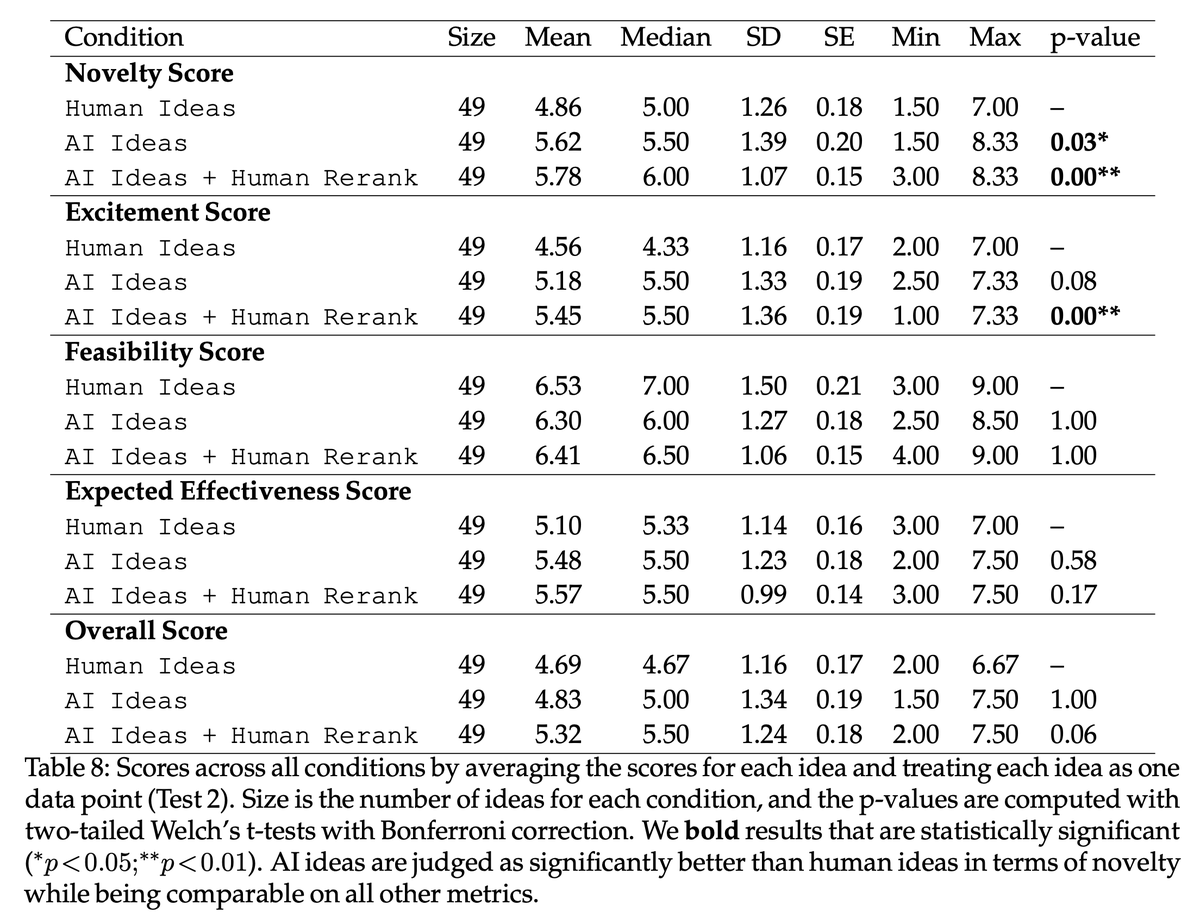
Our evaluation of Reflection Llama 3.1 70B's MMLU score resulted in the same score as Llama 3 70B and significantly lower than Meta's Llama 3.1 70B.
A LocalLLaMA post (link below) also compared the diff of Llama 3.1 & Llama 3 weights to Reflection Llama 3.1 70B and concluded the Llama 3 weights were a lot closer to Reflection's than Llama 3.1.
For further investigation but this might indicate the foundation model is Llama 3 rather than Llama 3.1 70B. It would be helpful if the team behind Reflection could clarify this.
2/5
Related reddit thread comparing Reflection Llama 3.1 70B weights to Llama 3 70B and Llama 3.1 70B.
3/5
Important context regarding our evaluation approach which uses a standardized methodology between models:
4/5
model weights were broken, see here
5/5
what’s the ETA?
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
Our evaluation of Reflection Llama 3.1 70B's MMLU score resulted in the same score as Llama 3 70B and significantly lower than Meta's Llama 3.1 70B.
A LocalLLaMA post (link below) also compared the diff of Llama 3.1 & Llama 3 weights to Reflection Llama 3.1 70B and concluded the Llama 3 weights were a lot closer to Reflection's than Llama 3.1.
For further investigation but this might indicate the foundation model is Llama 3 rather than Llama 3.1 70B. It would be helpful if the team behind Reflection could clarify this.
2/5
Related reddit thread comparing Reflection Llama 3.1 70B weights to Llama 3 70B and Llama 3.1 70B.
3/5
Important context regarding our evaluation approach which uses a standardized methodology between models:
4/5
model weights were broken, see here
5/5
what’s the ETA?
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196





 !
! !
! -kun released some new models, everyone has tried to tame it but failed. (I don't know why)
-kun released some new models, everyone has tried to tame it but failed. (I don't know why)












 @vankous for
@vankous for  unroll
unroll





















 :
:  :
:  :
: 











 The github lib -
The github lib - 


 Exciting news! We’ve officially launched DeepSeek-V2.5 – a powerful combination of DeepSeek-V2-0628 and DeepSeek-Coder-V2-0724! Now, with enhanced writing, instruction-following, and human preference alignment, it’s available on Web and API. Enjoy seamless Function Calling, FIM, and Json Output all-in-one!
Exciting news! We’ve officially launched DeepSeek-V2.5 – a powerful combination of DeepSeek-V2-0628 and DeepSeek-Coder-V2-0724! Now, with enhanced writing, instruction-following, and human preference alignment, it’s available on Web and API. Enjoy seamless Function Calling, FIM, and Json Output all-in-one!







 cheers
cheers
 !!!
!!!