
You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
The A.I Megathread (LLM , GPT , Development)
More options
Who Replied?The new Mistral model can handle 100k+ token sequences with linear (ish) complexity.
How does it do it?
The answer is Sliding Window Attention.
In standard, decoder-only, causal LMs (like the GPT family), each token can "attend to" (i.e. "look at") every token that has come before it.
In Sliding Window Attention, earlier layers have a narrower view of history, and this progressively builds up the deeper you go into the model.
In the first layer of the model, each token can look at some number of previous tokens, known as the "window size". Mistral used a window size of 4096, so we'll go with that.
So, each token at the first layer can attend to the previous 4096 tokens. In the second layer, it's the exact same deal -- each token can look at the previous 4096 tokens.
So what's the big deal? Aren't we really just using some local attention mechanism and cutting off access as we get deeper into the sequence?
Not quite! You see, in the second layer, the model effectively is viewing 4096*2 tokens, since the previous 4096 tokens themselves attended to the 4096 tokens prior to that.
By the time you get to the end of their 32 layer model, the final layer has effectively attended to over 131k tokens. And, size the attention matrices never goes beyond the 4096 dimension, we essentially get increased context lengths >4096 "for free" (sorta).
It's somewhat analogous to dilated convolutions in networks like WaveNet, except rather than allowing each layer to view every 2^N previous tokens, we're allowing it to view the most recent chunks.
This is already implemented in Flash Attention, and Mistral claims that gives a 2x speedup in addition to all of these other efficiency gains. Incredible!
How does it do it?
The answer is Sliding Window Attention.
In standard, decoder-only, causal LMs (like the GPT family), each token can "attend to" (i.e. "look at") every token that has come before it.
In Sliding Window Attention, earlier layers have a narrower view of history, and this progressively builds up the deeper you go into the model.
In the first layer of the model, each token can look at some number of previous tokens, known as the "window size". Mistral used a window size of 4096, so we'll go with that.
So, each token at the first layer can attend to the previous 4096 tokens. In the second layer, it's the exact same deal -- each token can look at the previous 4096 tokens.
So what's the big deal? Aren't we really just using some local attention mechanism and cutting off access as we get deeper into the sequence?
Not quite! You see, in the second layer, the model effectively is viewing 4096*2 tokens, since the previous 4096 tokens themselves attended to the 4096 tokens prior to that.
By the time you get to the end of their 32 layer model, the final layer has effectively attended to over 131k tokens. And, size the attention matrices never goes beyond the 4096 dimension, we essentially get increased context lengths >4096 "for free" (sorta).
It's somewhat analogous to dilated convolutions in networks like WaveNet, except rather than allowing each layer to view every 2^N previous tokens, we're allowing it to view the most recent chunks.
This is already implemented in Flash Attention, and Mistral claims that gives a 2x speedup in addition to all of these other efficiency gains. Incredible!
Mistal 7B base and instruct release post
Read some tips, summaries, and resources
Experiment with it
I wrote a notebook showing how to use the proper prompt formatting + free Inference API + demo for anyone to try it out!
Notebook: huggingface.co/spaces/osanse…
Why is Mistral 7B interesting?
 Strongest <20B pretrained model
Strongest <20B pretrained model
 On par with many models of 30B params
On par with many models of 30B params
Apache 2.0 license
 Does decently in code tasks (code llama 7B quality)
Does decently in code tasks (code llama 7B quality)
 Thanks to windowed attention, you can use up to 200K tokens of context (using Rope, using 4 A10G GPUs)
Thanks to windowed attention, you can use up to 200K tokens of context (using Rope, using 4 A10G GPUs)
 Integrated into transformers, vllm, tgi, and more!
Integrated into transformers, vllm, tgi, and more!
 Thanks to the small size, you can host on a server or locally
Thanks to the small size, you can host on a server or locally
Link to leaderboard: Open LLM Leaderboard - a Hugging Face Space by HuggingFaceH4
Read some tips, summaries, and resources
Experiment with it
I wrote a notebook showing how to use the proper prompt formatting + free Inference API + demo for anyone to try it out!
Notebook: huggingface.co/spaces/osanse…
Why is Mistral 7B interesting?
Strongest <20B pretrained modelOn par with many models of 30B paramsApache 2.0 license
Does decently in code tasks (code llama 7B quality) Thanks to windowed attention, you can use up to 200K tokens of context (using Rope, using 4 A10G GPUs) Integrated into transformers, vllm, tgi, and more! Thanks to the small size, you can host on a server or locallyLink to leaderboard: Open LLM Leaderboard - a Hugging Face Space by HuggingFaceH4

Last edited:

Ray-Ban Meta smart glasses livestream to Instagram and Facebook | TechCrunch
The original Ray-Ban Stories didn’t catch on quite like Meta had hoped. According to a recent report, the company managed to sell a bit over one-third of
 techcrunch.com
techcrunch.com
Ray-Ban Meta smart glasses livestream to Instagram and Facebook
Brian Heater@bheater / 2:08 PM EDT•September 27, 2023Comment

Image Credits: Meta
The original Ray-Ban Stories didn’t catch on quite like Meta had hoped. According to a recent report, the company managed to sell a bit over one-third of what the internal 300,000 unit goal it set for the first seven months the device was on sale. Perhaps even more damning is a section from the same report suggesting that around 90% of owners had already abandoned the hardware.
As always, there’s a lot at play here, but I suspect a big part of the disappointment can be traced back to the system’s limitations. For one thing, the Stories couldn’t stream video — a pretty key feature one hopes for when it comes to sunglasses with embedded cameras.
I certainly won’t go so far as to suggest that the forthcoming Ray-Ban Meta smart glasses are destined to be a runaway hit, but I will tell you that at the very least its creators addressed the biggest issue with their predecessor. Unveiled this morning at Meta Connect in Menlo Park, California, the new sunglasses are capable of livestreaming video to (naturally) Facebook and Instagram.

Image Credits: Darrell Etherington
The systems come in the standard classic Wayfarer design, along with a new Headliner style. They look like standard sunglasses (or eyeglasses, depending on the lens), save for two round modules on the side of either eye. On the right is a 12-megapixel camera that can take stills and record video in 1080p. The other side — that looks more or less identical (for symmetry’s sake) — is actually an LED light that flips on to alert others that you’re recording.
It’s a nice feature, given how relatively inconspicuous these things are. Without a light, it would honestly be pretty easy to record people without their knowledge (please don’t do this). While Meta says they didn’t receive any reports of the small group of people who bought the glasses uses them for nefarious purposes, it’s instituted a fail-safe here. If you cover the light with, say, black tape, you’ll get a message telling you to remove it. Also, the system won’t take photos or record in this state.
The Ray-Ban Meta features open-ear speakers (not bone conduction) that are capable of getting 50% louder than their predecessors. We got our hands on some pairs at a recent Meta event, and I can attest to the fact that they can get to a comfortably loud volume. Something worth caveating all of this, of course, is the fact that we tested them in ideal conditions.

Image Credits: Meta
I point that out because, while open-ear headphones are better in terms of situational awareness, there’s no passive cancellation. That means they’re competing with a lot of ambient sound and can be difficult to hear in loud environments. Unfortunately, there’s no way to, say, pair some AirPods directly to the glasses. Instead, you’ll have to rely on the built-in hardware to listen to music and take calls.
There are more than 150 design combos possible, when you factor in all of the different design options, including frame color, style and lenses (including sunglasses, clear, prescription, transitions and polarized). There’s also a transparent option for the frames, offering a peek at the technology behind it. Perhaps we’re due for a see-through tech comeback, on the heels of Nothing’s devices.
The Ray-Ban Meta are up for preorder starting today in the following markets: U.S., Canada, U.K., Ireland, Italy, France, Spain, Belgium, Austria, Australia, Germany, Norway, Finland, Denmark and Sweden. They go on sale October 12 from Meta, LensCrafters, Amazon and Best Buy.
The price starts at $299 for standard lenses. Polarized run $329 and transitions $379. Prescription lenses are on a sliding scale.

Introducing the New Ray-Ban | Meta Smart Glasses | Meta
In partnership with EssilorLuxottica, we’re launching a new generation of Ray-Ban Meta smart glasses, available for pre-order now.
 about.fb.com
about.fb.com
Nous-Capybara-7B
A model created with a novel synthesis method in mind, Amplify-instruct, with a goal of having a synergistic combination of different techniques used for SOTA models such as Evol-Instruct, Orca, Vicuna, Lamini, FLASK and others, all into one lean holistically formed dataset and model. The seed instructions used for the start of synthesized conversations are largely based on highly acclaimed datasets like Airoboros, Know logic, EverythingLM, GPTeacher and even entirely new seed instructions derived from posts on the website LessWrong, as well as being supplemented with certain multi-turn datasets like Dove(A successor to Puffin).Entirely contained within 20K training examples, mostly comprised of newly synthesized tokens never used for model training until now!
Process of creation and special thank yous!
This model was fine-tuned by Nous Research, with LDJ leading the training and dataset curation, along with significant dataset formation contributions by J-Supha, Also thank you to Emozilla for also assisting to expedite the training experimentation process.Special thank you to A16Z for sponsoring our training, as well as Yield Protocol for their support in resources during R&D of aspects outside of training, such as dataset development/synthesis.
Thank you to dataset creators!
While most of the tokens within Capybara are newly synthsized and part of datasets like Puffin/Dove, we would like to credit the single-turn datasets we leveraged as seeds that are used to initiate the beggining of many of the multi-turn conversations:
Model Training
Nous-Capybara 7B is a new model trained for multiple epochs on a dataset of less than 20,000 carefully curated GPT-4 examples, most of which are long context conversations between a real human and GPT-4 comprised of entirely newly synthesized tokens that previously didn't exist on HuggingFace.Additional data came from manually curated CamelAI data, with the help of volunteers ranging from former Physicists, Mathematicians, Biologists and more!
Specific credits to the people involved in validating this data will be posted soon

Prompt Format
The reccomended model usage is:USER:
ASSISTANT:
Notable Features:
- The first Nous model trained on over 10,000 multi-turn conversations.
- Over 1,000 tokens average per conversation example during training!
- Able to effectively do complex summary of advanced studies on topics.
- Ability to recall information upto late 2022 without internet (ChatGPT cut off date is in 2021)
- Context length of 4096 tokens, and fine-tuned on a significant amount of multi-turn conversations reaching that full token limit.
- Includes a portion of conversational data synthesized from less wrong posts, speaking in-depth about the nature of rationality, reasoning and self-improvement.
Example Outputs!:



Benchmarks! (Important to note that all mentioned benchmarks are single-turn and don't test multi-turn capabilities, Capybara should excel even further at multi-turn conversational tasks.)

Limitations
We noticed that the current version of Capybara still has some issues in some situations with censoring itself and not acting as expected in certain edge cases, we plan to have this largely resolved in the near future with Capybara 1.1Future Changes
This is a relatively early build amongst the grand plans for the future of Capybara!Current limitations: We are still running experimentation and tests for the training pipeline and dataset cleaning process to be more refined, we plan to release a Capybara 1.1 with these improvements.
Future model sizes
We plan on releasing a 3B, 13B and 70B version, as well as a potential 1B version based on phi-1.5 or similar architectures.How you can help!
In the near future we plan on leveraging the help of domain specific expert volunteers to eliminate any mathematically/verifiably incorrect answers from our training curations.If you have at-least a bachelors in mathematics, physics, biology or chemistry and would like to volunteer even just 30 minutes of your expertise time, please contact LDJ on discord!
Dataset contamination.
We checked for 100%, 99%, 98% and 97% similarity matches between our data and many popular benchmarks, we found no exact matches!The following are benchmarks we checked for contamination for:
- HumanEval
- AGIEval
- TruthfulQA
- MMLU
- GPT4All

NousResearch/Nous-Capybara-7B · Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co

NousResearch/Nous-Capybara-7B-GGUF · Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co



Open-sourcing SQLCoder: a state-of-the-art LLM for SQL generation
We are thrilled to open-source Defog SQLCoder: a 15B parameter LLM that outperforms gpt-3.5-turbo on text-to-SQL tasks.
UPDATE
Open-sourcing SQLCoder: a state-of-the-art LLM for SQL generation
We are thrilled to open-source Defog SQLCoder: a 15B parameter LLM that outperforms gpt-3.5-turbo on text-to-SQL tasks.Aug 20, 2023


Introducing SQLCoder
We are thrilled to open source Defog SQLCoder – a state-of-the-art LLM for converting natural language questions to SQL queries. SQLCoder significantly outperforms all major open-source models and slightly outperforms gpt-3.5-turbo and text-davinci-003 (models that are 10 times its size) on our open-source evaluation framework.You can explore SQLCoder in our interactive demo at https://defog.ai/sqlcoder-demo
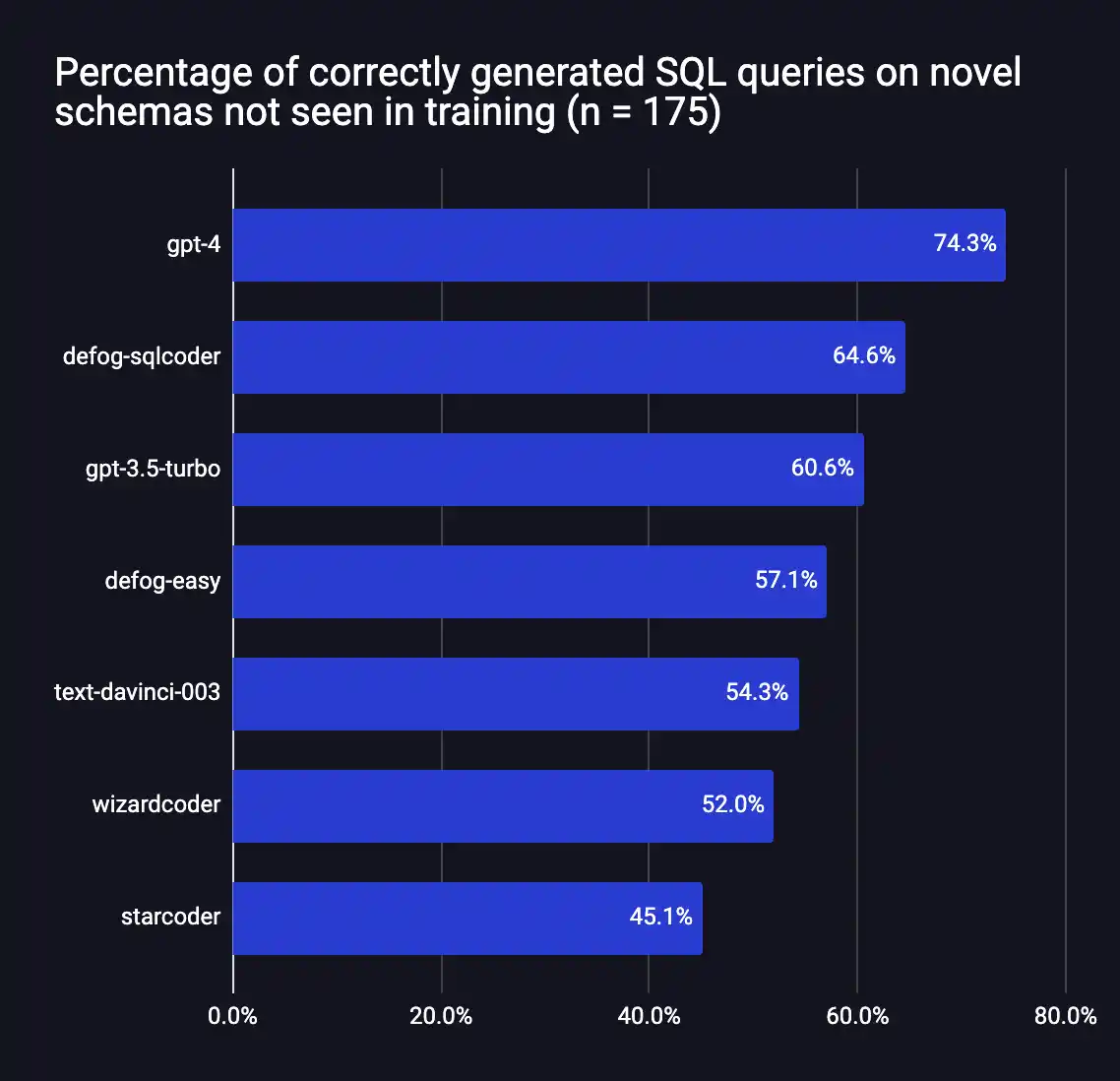
SQLCoder is a 15B parameter LLM, and a fine-tuned implementation of StarCoder. SQLCoder has been fine-tuned on hand-crafted SQL queries in increasing orders of difficulty. When fine-tuned on an individual database schema, it matches or outperforms GPT-4 performance.
You can find our Github repo here, and our model weights on Huggingface here. You can also use our interactive demo here to explore our model in the browser.
Motivation
In the last 3 months, we have deployed SQLCoder with enterprise customers in healthcare, finance, and government. These customers often have sensitive data that they do not want going out of their servers, and using self-hosted models has been the only way for them while using LLMs.We were able to build a SOTA model that was competitive with closed source models. We did this while standing on the shoulders of giants like StarCoder, and open-sourcing the model weights is our attempt at giving back to the community.
Approach
Dataset Creation
We created a hand-curated dataset of prompt-completion pairs focused on text-to-SQL tasks. This dataset was created from 10 different schemas, and with questions of varying levels of difficulty. Additionally, we also created an evaluation dataset of 175 questions from 7 new schemas that were not a part of the 10 schemas in our training data.We made sure that we selected complex schemas with 4-20 tables in both our training and evaluation datasets. This is because schemas with 1 or 2 tables tend to only result in simple, straightforward queries due to limited relations.
Question Classification
Once the dataset was created, we classified each question in the dataset into “easy”, “medium”, “hard”, and “extra-hard” categories. This classification was done by adapting the rubric utilized by the Spider dataset to gauge SQL hardness.Finally, we divided the dataset into two distinct subparts – one with easy and medium questions, and the other with hard and extra-hard questions.
Fine-tuning
We fine-tuned the model in two stages. First, we fine-tuned the base StarCoder model on just our easy and medium questions. Then, we fine-tuned the resulting model (codenamed defog-easy) on hard and extra hard questions to get SQLcoder.Evaluation
We evaluated our model on a custom dataset we created. Evaluating the “correctness” of SQL queries is difficult. We considered using GPT-4 as a “judge”, but ran into multiple issues with that. We also realized that two different SQL queries can both be "correct". For the question “who are the 10 most recent users from Toronto”, both of the following are correct in their own ways:1-- query 1
2SELECT userid, username, created_at
3from users
4where city='Toronto'
5order by created_at DESC LIMIT 10;
67-- query 2
8SELECT userid, firstname || ' ' || lastname, created_at
9from users
10where city='Toronto'
11order by created_at DESC LIMIT 10;
With this in mind, we had to build a custom framework to evaluate query correctness. You can read more about the framework here. In addition to open-sourcing our model weights, we have also open-sourced our evaluation framework and evaluation dataset.
Results
Defog SQLCoder outperforms all major models except GPT-4 on our evaluation framework. In particular, it outperforms gpt-3.5-turbo and text-davinci-003, which are models more than 10x its size.
These results are for generic SQL databases, and do not reflect SQLCoder’s performance on individual database schemas. When fine-tuned on individual database schemas, SQLCoder has the same or better performance as OpenAI’s GPT-4, with lower latency (on an A100 80GB).
Future direction
We will make the following updates to Defog in the coming weeks:- Training the model on more hand-curated data, along with broader questions
- Tuning the model further with Reward Modeling and RLHF
- Pretraining a model from scratch that specializes in data analysis (SQL + Python)
Explore the model
You can explore our model at https://defog.ai/sqlcoder-demoAbout the authors
Rishabh Srivastava is a co-founder of Defog. Before starting Defog, he founded Loki.ai – serving more than 5 billion API requests for Asian enterprises.Wendy Aw is a Machine Learning Engineer at Defog, working on model-finetuning and dataset curation. Before joining Defog, Wendy spent most of the last decade as a copywriter, where she helped build some of the world’s biggest brands.

MetaMath: Bootstrap Your Own Mathematical Questions for Large Language Models
SOCIAL MEDIA DESCRIPTION TAG TAG
 meta-math.github.io
meta-math.github.io
MetaMath:
Bootstrap Your Own Mathematical Questions for Large Language Models
Longhui Yu1,*, Weisen Jiang2,3,*, Han Shi4,‡, Jincheng Yu3,4, Zhengying Liu4,Yu Zhang2, James T. Kwok3, Zhenguo Li4, Adrian Weller5,6, Weiyang Liu5,7,‡
1Peking University, 2Southern University of Science and Technology, 3Hong Kong University of Science and Technology, 4Huawei Noah's Ark Lab, 5University of Cambridge, 6The Alan Turing Institute, 7Max Planck Institute for Intelligent Systems
*Equal Contribution, ‡Corresponding author
longhuiyu98@gmail.com, shi.han@huawei.com, wl396@cam.ac.uk
Models Dataset Code arXivAbstract
Large language models (LLMs) have pushed the limits of natural language understanding and exhibited excellent problem-solving ability. Despite the great success, most existing open-source LLMs (e.g., LLaMA-2) are still far away from satisfactory for solving mathematical problems due to its complex reasoning procedures. To bridge this gap, we propose MetaMath, a finetuned language model that specializes in mathematical reasoning. Specifically, we start by bootstrapping mathematical questions by rewriting the question from multiple perspectives, which results in a new dataset called MetaMathQA. Then we finetune the LLaMA-2 models on MetaMathQA. Experimental results on two popular benchmarks (i.e., GSM8K and MATH) for mathematical reasoning emonstrate that MetaMath outperforms all open-source LLMs by a significant margin. Our MetaMath-7B model achieves 66.5% on GSM8K and 19.8% on MATH, exceeding the state-of-the-art models of the same size by 11.5% and 8.7%. Particularly, MetaMath-70B achieves an accuracy of 82.3% on GSM8K, slightly better than GPT-3.5-Turbo. We release the MetaMathQA dataset, the pretrained MetaMath models with different mode size and the training code for public use.Overview

Figure 1: Overview of the MetaMathQA data and MetaMath.
MetaMathQA
Answer Augmentation (AnsAug)Generated Answer: James buys 5 packs of beef that are 4 pounds each, so he buys a total of 5 * 4 = 20 pounds of beef. The price of beef is $5.50 per pound, so he pays 20 * $5.50 = $110. The answer is: 110
Rephrasing Question
Question: What is the total amount that James paid when he purchased 5 packs of beef, each weighing 4 pounds, at a price of $5.50 per pound?
Rephrase the above question: Each pack of beef weighs 4 pounds, so 5 packs weigh 4 * 5 = 20 pounds in total. The price per pound of beef is $5.50, so the total cost for 20 pounds is 20 * $5.50 = $110. Therefore, James paid a total of $110. The answer is: 110.
Self-Verification Question
Question: James buys x packs of beef that are 4 pounds each. The price of beef is $5.50 per pound. He paid 110. What is the value of unknown variable x?
Answer: To solve this problem, we need to determine the value of x, which represents the number of packs of beef that James bought. Each pack of beef weighs 4 pounds and costs $5.50 per pound. The total amount James paid is $110. We can set up the equation as follows: Number of packs of beef * Weight per pack * Price per pound = Total amount paid; x * 4 * $5.50 = $110; Let's simplify and solve for x: 4x * $5.50 = $110; 22x = $110; To isolate x, we divide both sides of the equation by 22: 22x / 22 = $110 / 22; x = $5; The value of x is 5.
FOBAR Question
Question: James buys x packs of beef that are 4 pounds each. The price of beef is $5.50 per pound. How much did he pay? If we know the answer to the above question is 110, what is the value of unknown variable x?
Answer: James buys x packs of beef that are 4 pounds each, so he buys a total of 4x pounds of beef. The price of beef is $5.50 per pound, so the total cost of the beef is 5.50 * 4x = 22x. We are given that the total cost is $110, so we can write: 22x = 110. Dividing both sides by 22, we get: x = 5. The value of x is 5.
Comprehensive Results
| Model | #params | GSM8K | MATH |
|---|---|---|---|
| Closed-source Model | |||
| GPT-4 | - | 92.0 | 42.5 |
| GPT-3.5-Turbo | - | 80.8 | 34.1 |
| PaLM | 8B | 4.1 | 1.5 |
| PaLM | 62B | 33.0 | 4.4 |
| PaLM | 540B | 56.5 | 8.8 |
| PaLM-2 | 540B | 80.7 | 34.3 |
| Flan-PaLM 2 | 540B | 84.7 | 33.2 |
| Minerva | 8B | 16.2 | 14.1 |
| Minerva | 62B | 52.4 | 27.6 |
| Minerva | 540B | 58.8 | 33.6 |
| Open-source models (1-10B) | |||
| LLaMA-1 | 7B | 11.0 | 2.9 |
| LLaMA-2 | 7B | 14.6 | 2.5 |
| MPT | 7B | 6.8 | 3.0 |
| Falcon | 7B | 6.8 | 2.3 |
| InternLM | 7B | 31.2 | - |
| GPT-J | 6B | 34.9 | - |
| ChatGLM 2 | 6B | 32.4 | - |
| Qwen | 7B | 51.6 | - |
| Baichuan-2 | 7B | 24.5 | 5.6 |
| SFT | 7B | 41.6 | - |
| RFT | 7B | 50.3 | - |
| WizardMath | 7B | 54.9 | 10.7 |
| MetaMath (ours) | 7B | 66.5 | 19.8 |
| Open-source models (11-50B) | |||
| LLaMA-1 | 13B | 17.8 | 3.9 |
| LLaMA-1 | 33B | 35.6 | 7.1 |
| LLaMA-2 | 13B | 28.7 | 3.9 |
| LLaMA-2 | 34B | 42.2 | 6.2 |
| MPT | 30B | 15.2 | 3.1 |
| Falcon | 40B | 19.6 | 2.5 |
| GAL | 30B | - | 12.7 |
| Vicuna | 13B | 27.6 | - |
| Baichuan-2 | 13B | 52.8 | 10.1 |
| SFT | 13B | 50.0 | - |
| RFT | 13B | 54.8 | - |
| WizardMath | 13B | 63.9 | 14.0 |
| MetaMath (ours) | 13B | 72.3 | 22.4 |
| Open-source models (50-70B) | |||
| LLaMA-1 | 65B | 50.9 | 10.6 |
| LLaMA-2 | 70B | 56.8 | 13.5 |
| RFT | 70B | 64.8 | - |
| WizardMath | 70B | 81.6 | 22.7 |
| MetaMath (ours) ‡ | 70B | 82.3 | 26.6 |
Table 1: Comparison of testing accuracy to existing LLMs on GSM8K and MATH. ‡Due to the computing resource limitation, we finetune MetaMath-70B using QLoRA.
BibTeX
@misc{yu2023metamath,title={MetaMath: Bootstrap Your Own Mathematical Questions for Large Language Models},
author={Longhui Yu and Weisen Jiang and Han Shi and Jincheng Yu and Zhengying Liu and Yu Zhang and James T. Kwok and Zhenguo Li and Adrian Weller and Weiyang Liu},
year={2023},
eprint={2309.12284},
archivePrefix={arXiv},
primaryClass={cs.CL}
}

meta-math/MetaMath-7B-V1.0 · Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co

TheBloke/MetaMath-7B-V1.0-GPTQ · Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co

TheBloke/MetaMath-7B-V1.0-GGUF · Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co

meta-math/MetaMath-13B-V1.0 · Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co

TheBloke/MetaMath-13B-V1.0-GGUF · Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co

meta-math/MetaMath-70B-V1.0 · Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co

TheBloke/MetaMath-70B-V1.0-GGUF · Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co
Meta just dropped a banger:
LLaMA 2 Long.
- Continued pretraining LLaMA on long context and studied the effects of pretraining text lengths.
- Apparently having abundant long texts in the pretraing dataset is not the key to achieving strong performance.
- They also perform a large experiment session comparing different length scaling techniques.
- Surpassed gpt-3.5-turbo-16k’s on a multiple long-context tasks.
- They also study the effect of instruction tuning with RL + SFT and all combinations between the two.
The model weights are not out yet.
Hopefully Soon!
LLaMA 2 Long.
- Continued pretraining LLaMA on long context and studied the effects of pretraining text lengths.
- Apparently having abundant long texts in the pretraing dataset is not the key to achieving strong performance.
- They also perform a large experiment session comparing different length scaling techniques.
- Surpassed gpt-3.5-turbo-16k’s on a multiple long-context tasks.
- They also study the effect of instruction tuning with RL + SFT and all combinations between the two.
The model weights are not out yet.
Hopefully Soon!


Meta quietly unveils Llama 2 Long AI that beats GPT-3.5 Turbo and Claude 2 on some tasks
It's a big validation of Meta's open source approach toward generative AI, and indicates that open source can compete with the closed source.
 venturebeat.com
venturebeat.com
Meta quietly unveils Llama 2 Long AI that beats GPT-3.5 Turbo and Claude 2 on some tasks
Carl Franzen@carlfranzenSeptember 29, 2023 11:00 AM

Credit: VentureBeat made with Midjourney
VentureBeat presents: AI Unleashed - An exclusive executive event for enterprise data leaders. Network and learn with industry peers. Learn More
Meta Platforms showed off a bevy of new AI features for its consumer-facing services Facebook, Instagram and WhatsApp at its annual Meta Connect conference in Menlo Park, California, this week.
But the biggest news from Mark Zuckerberg’s company may have actually come in the form of a computer science paper published without fanfare by Meta researchers on the open access and non-peer reviewed website arXiv.org.
The paper introduces Llama 2 Long, a new AI model based on Meta’s open source Llama 2 released in the summer, but that has undergone “continual pretraining from Llama 2 with longer training sequences and on a dataset where long texts are upsampled,” according to the researcher-authors of the paper.
As a result of this, Meta’s newly elongated AI model outperforms some of the leading competition in generating responses to long (higher character count) user prompts, including OpenAI’s GPT-3.5 Turbo with 16,000-character context window, as well as Claude 2 with its 100,000-character context window.
How LLama 2 Long came to be
Meta researchers took the original Llama 2 available in its different training parameter sizes — the values of data and information the algorithm can change on its own as it learns, which in the case of Llama 2 come in 7 billion, 13 billion, 34 billion, and 70 billion variants — and included more longer text data sources than the original Llama 2 training dataset. Another 400 billion tokens-worth, to be exact.Then, the researchers kept the original Llama 2’s architecture the same, and only made a “necessary modification to the positional encoding that is crucial for the model to attend longer.”
That modification was to the Rotary Positional Embedding (RoPE) encoding, a method of programming the transformer model underlying LLMs such as Llama 2 (and LLama 2 Long), which essentially maps their token embeddings (the numbers used to represent words, concepts, and ideas) onto a 3D graph that shows their positions relative to other tokens, even when rotated. This allows a model to produce accurate and helpful responses, with less information (and thus, less computing storage taken up) than other approaches.
The Meta researchers “decreased the rotation angle” of its RoPE encoding from Llama 2 to Llama 2 Long, which enabled them to ensure more “distant tokens,” those occurring more rarely or with fewer other relationships to other pieces of information, were still included in the model’s knowledge base.
Usingreinforcement learning from human feedback (RLHF), a common AI model training method where AI is rewarded for correct answers with human oversight to check it, and synthetic data generated by Llama 2 chat itself, the researchers were able to improve its performance in common LLM tasks including coding, math, language understanding, common sense reasoning, and answering a human user’s prompted questions.

With such impressive results relative to both Llama 2 regular and Anthropic’s Claude 2 and OpenAI’s GPT-3.5 Turbo, it’s little wonder the open-source AI community on Reddit and Twitter and Hacker News have been expressing their admiration and excitement about Llama 2 since the paper’s release earlier this week — it’s a big validation of Meta’s “open source” approach toward generative AI, and indicates that open source can compete with the closed source, “pay to play” models offered by well-funded startups.
Llama 2 Long | Hacker News
Drive Like a Human: Rethinking Autonomous Driving with Large Language Models
Daocheng Fu, Xin Li, Licheng Wen, Min Dou, Pinlong Cai, Botian Shi, Yu QiaoIn this paper, we explore the potential of using a large language model (LLM) to understand the driving environment in a human-like manner and analyze its ability to reason, interpret, and memorize when facing complex scenarios. We argue that traditional optimization-based and modular autonomous driving (AD) systems face inherent performance limitations when dealing with long-tail corner cases. To address this problem, we propose that an ideal AD system should drive like a human, accumulating experience through continuous driving and using common sense to solve problems. To achieve this goal, we identify three key abilities necessary for an AD system: reasoning, interpretation, and memorization. We demonstrate the feasibility of employing an LLM in driving scenarios by building a closed-loop system to showcase its comprehension and environment-interaction abilities. Our extensive experiments show that the LLM exhibits the impressive ability to reason and solve long-tailed cases, providing valuable insights for the development of human-like autonomous driving. The related code are available at this https URL .
| Subjects: | Robotics (cs.RO); Computation and Language (cs.CL) |
| Cite as: | arXiv:2307.07162 [cs.RO] |
| (or arXiv:2307.07162v1 [cs.RO] for this version) | |
| [2307.07162] Drive Like a Human: Rethinking Autonomous Driving with Large Language Models Focus to learn more |
Submission history
From: Licheng Wen [view email][v1] Fri, 14 Jul 2023 05:18:34 UTC (2,012 KB)
Rethinking Autonomous Driving with Large Language Models | Hacker News
GitHub - facebookresearch/MetaCLIP: Everything about MetaCLIP: curation/training code, metadata, distribution and pre-trained models.
Everything about MetaCLIP: curation/training code, metadata, distribution and pre-trained models. - GitHub - facebookresearch/MetaCLIP: Everything about MetaCLIP: curation/training code, metadata, ...
 github.com
github.com