
You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
The A.I Megathread (LLM , GPT , Development)
More options
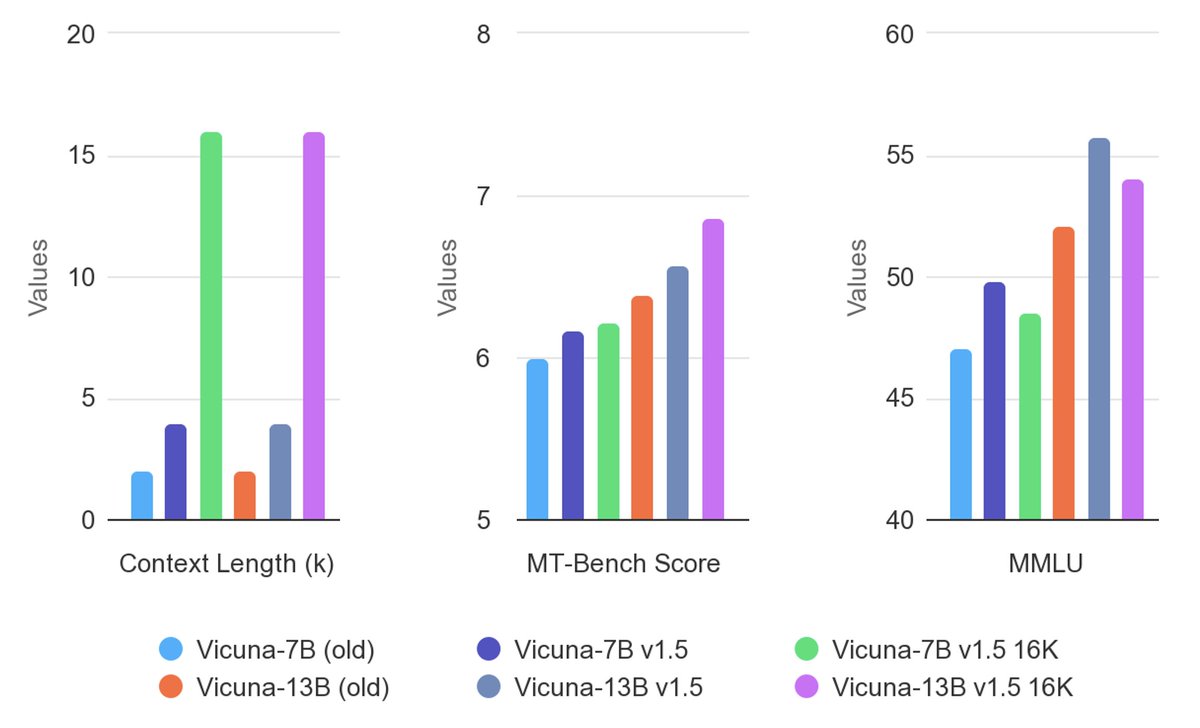
Who Replied?Excited to release our latest Vicuna v1.5 series, featuring 4K and 16K context lengths with improved performance on almost all benchmarks!
Vicuna v1.5 is based on the commercial-friendly Llama 2 and has extended context length via positional interpolation.
Since its release, Vicuna has become one of the most popular chat LLMs. It has enabled pioneering research on multi-modality, AI safety, and evaluation. Vicuna models received over 2 million downloads on Hugging Face last month. The latest version follows the proven recipe and brings fresh enhancements. Let’s keep pushing the boundary of open LLM!
Vicuna v1.5 is based on the commercial-friendly Llama 2 and has extended context length via positional interpolation.
Since its release, Vicuna has become one of the most popular chat LLMs. It has enabled pioneering research on multi-modality, AI safety, and evaluation. Vicuna models received over 2 million downloads on Hugging Face last month. The latest version follows the proven recipe and brings fresh enhancements. Let’s keep pushing the boundary of open LLM!

- [2023/08]
 We released Vicuna v1.5 based on Llama 2 with 4K and 16K context lengths. Download weights.
We released Vicuna v1.5 based on Llama 2 with 4K and 16K context lengths. Download weights. - [2023/08] We released LongChat v1.5 based on Llama 2 with 32K context lengths. Download weights.
lmsys/vicuna-13b-v1.5 · Hugging Face
lmsys/vicuna-13b-v1.5-16k · Hugging Face
lmsys/vicuna-7b-v1.5 · Hugging Face
lmsys/vicuna-7b-v1.5-16k · Hugging Face

Preparing for the era of 32K context: Early learnings and explorations
Jul 28Written By Together
Today, we’re releasing LLaMA-2-7B-32K, a 32K context model built using Position Interpolation and Together AI’s data recipe and system optimizations, including FlashAttention-2. Fine-tune the model for targeted, long-context tasks—such as multi-document understanding, summarization, and QA—and run inference and fine-tune on 32K context with up to 3x speedup.

LLaMA-2-7B-32K making completions of a book in the Together Playground. Try it yourself at api.together.ai.
In the last few months, we have witnessed the rapid progress of the open-source ecosystem for LLMs — from the original LLaMA model that triggered the “LLaMA moment”, to efforts such as RedPajama, MPT, Falcon, and the recent LLaMA-2 release, open-source models have been catching up with closed-source models. We believe the upcoming opportunity for open-source models is to extend the context length of open models to the regime of 32K-128K, matching that of state-of-the-art closed-source models. We have already seen some exciting efforts here such as MPT-7B-8K and LLongMA-2 (8K).
Today, we’re sharing with the community some recent learnings and explorations at Together AI in the direction of building long-context models with high quality and efficiency. Specifically:
- LLaMA-2-7B-32K: We extend LLaMA-2-7B to 32K long context, using Meta’s recipe of interpolation and continued pre-training. We share our current data recipe, consisting of a mixture of long context pre-training and instruction tuning data.
- Examples of building your own long-context models: We share two examples of how to fine-tune LLaMA-2-7B-32K to build specific applications, including book summarization and long-context question answering.
- Software support: We updated both the inference and training stack to allow for efficient inference and fine-tuning with 32K context, using the recently released FlashAttention-2 and a range of other optimizations. This allows one to create their own 32K context model and conduct inference efficiently.
- Try it yourself:
- Go to Together API and run LLaMA-2-7B-32K for inference.
- Use OpenChatKit to fine-tune a 32K model over LLaMA-2-7B-32K for your own long context applications.
- Go to HuggingFace and try out LLaMA-2-7B-32K.
Extending LLaMA-2 to 32K context
LLaMA-2 has a context length of 4K tokens. To extend it to 32K context, three things need to come together: modeling, data, and system optimizations.On the modeling side, we follow Meta’s recent paper and use linear interpolation to extend the context length. This provides a powerful way to extend the context length for models with rotary positional embeddings. We take the LLaMA-2 checkpoint, and continue pre-training/fine-tuning it with linear interpolation for 1.5B tokens.
But this alone is not enough. What data should we use in improving the base model? Instead of simply fine-tuning using generic language datasets such as Pile and RedPajama as in Meta’s recent recipe, we realize that there are two important factors here and we have to be careful about both. First, we need generic long-context language data for the model to learn how to handle the interpolated positional embeddings; and second, we need instruction data to encourage the models to actually take advantagement of the information in the long context. Having both seems to be the key.
Our current data recipe consists of the following mixture of data:
- In the first phase of continued pre-training, our data mixture contains 25% RedPajama Book, 25% RedPajama ArXiv (including abstracts), 25% other data from RedPajama, and 25% from the UL2 Oscar Data, which is a part of OIG (Open-Instruction-Generalist), asking the model to fill in missing chunks, or complete the text. To enhance the long-context capabilities, we exclude sequences shorter than 2K tokens. The UL2 Oscar Data encourages the model to model long-range dependencies.
- We then fine-tune the model to focus on its few shot capacity with long contexts, including 20% Natural Instructions (NI), 20% Public Pool of Prompts (P3), 20% the Pile. To mitigate forgetting, we further incorporate 20% RedPajama Book and 20% RedPajama ArXiv with abstracts. We decontaminated all data against HELM core scenarios (see a precise protocol here). We teach the model to leverage the in-context examples by packing as many examples as possible into one 32K-token sequence.
| Model | 2K | 4K | 8K | 16K | 32K |
|---|---|---|---|---|---|
| LLaMA-2 | 1.759 | 1.747 | N/A | N/A | N/A |
| LLaMA-2-7B-32K | 1.768 | 1.758 | 1.750 | 1.746 | 1.742 |
| LLaMA-2-7B | LLaMA-2-7B-32K | |
|---|---|---|
| AVG | 0.489 | 0.522 |
| MMLU - EM | 0.435 | 0.435 |
| BoolQ - EM | 0.746 | 0.784 |
| NarrativeQA - F1 | 0.483 | 0.548 |
| NaturalQuestions (closed-book) - F1 | 0.322 | 0.299 |
| NaturalQuestions (open-book) - F1 | 0.622 | 0.692 |
| QuAC - F1 | 0.355 | 0.343 |
| HellaSwag - EM | 0.759 | 0.748 |
| OpenbookQA - EM | 0.570 | 0.533 |
| TruthfulQA - EM | 0.29 | 0.294 |
| MS MARCO (regular) - RR@10 | 0.25 | 0.419 |
| MS MARCO (TREC) - NDCG@10 | 0.469 | 0.71 |
| CNN/DailyMail - ROUGE-2 | 0.155 | 0.151 |
| XSUM - ROUGE-2 | 0.144 | 0.129 |
| IMDB - EM | 0.951 | 0.965 |
| CivilComments - EM | 0.577 | 0.601 |
| RAFT - EM | 0.684 | 0.699 |

Finetuning Llama 2 in your own cloud environment, privately
An operational guide on finetuning Llama 2, ready for commercial use.
Finetuning Llama 2 in your own cloud environment, privately
An operational guide on finetuning Llama 2, ready for commercial use.
Aug 2, 2023 · 12 min read · Zhanghao Wu, Wei-Lin Chiang, Zongheng Yang
Table of Contents
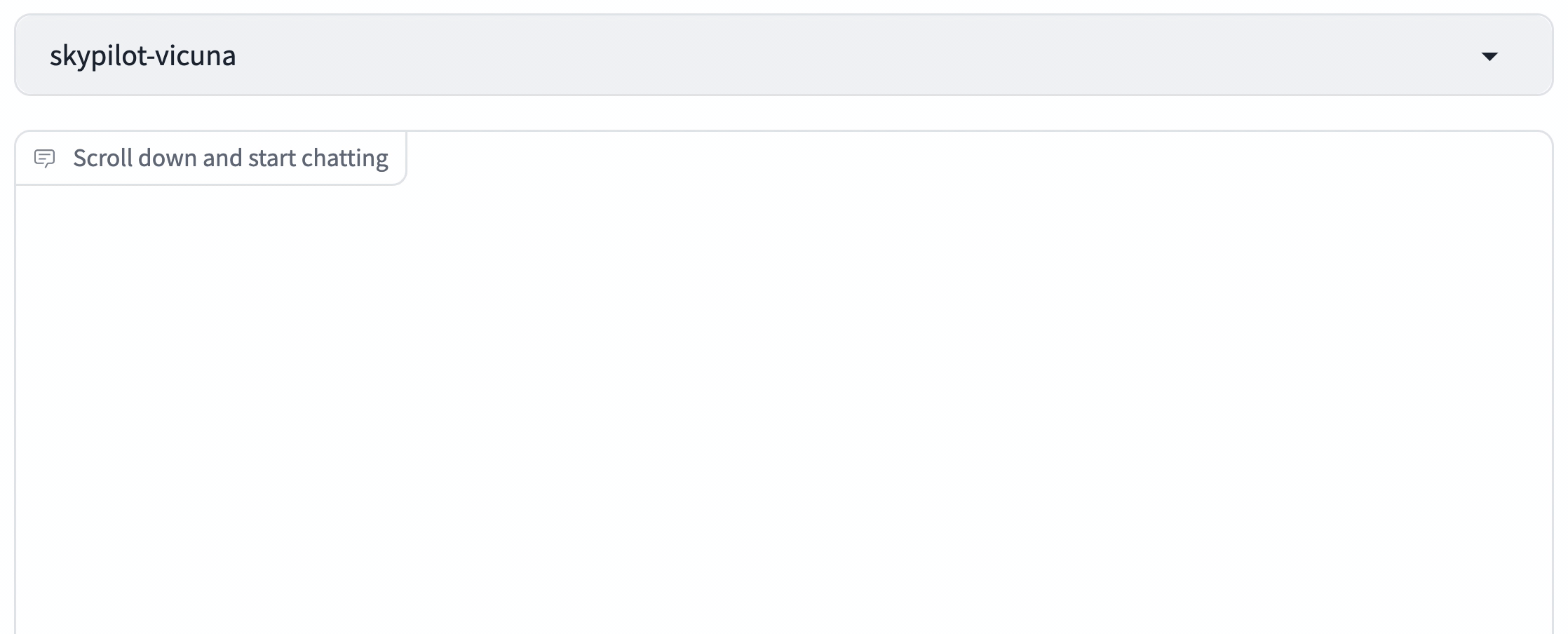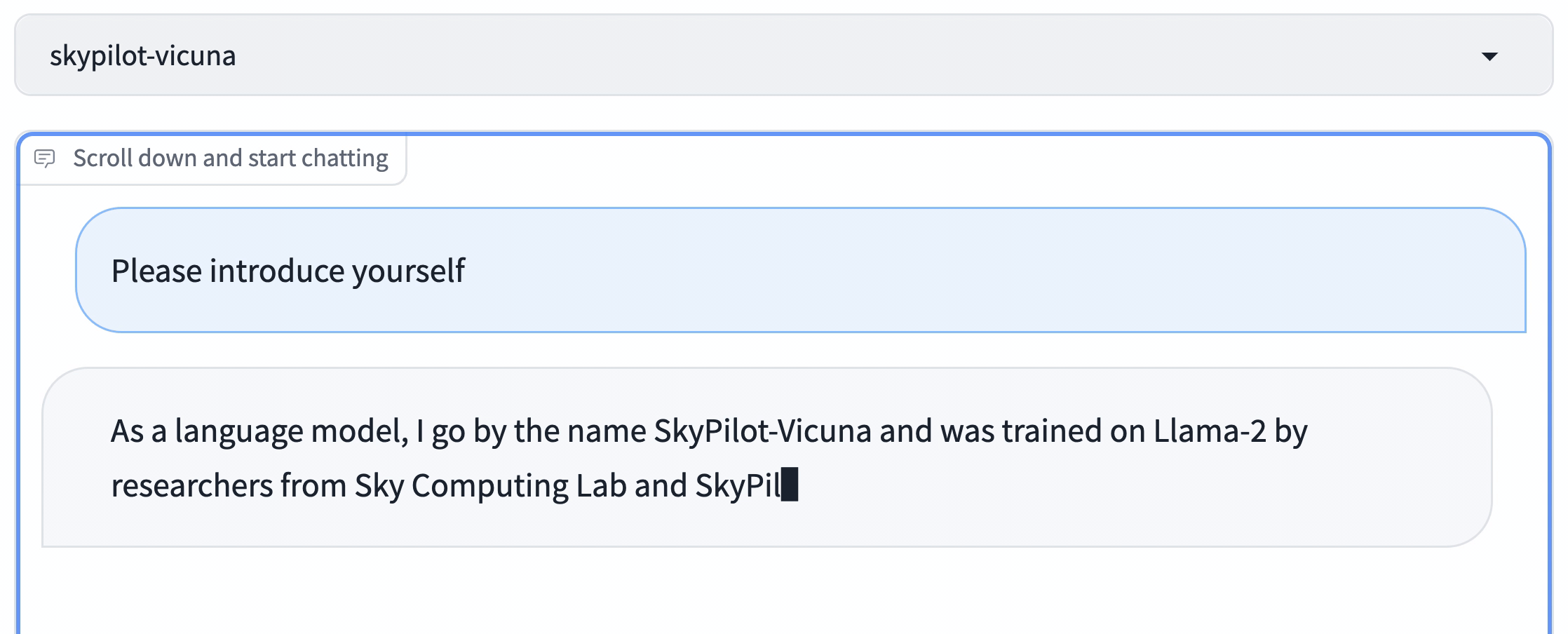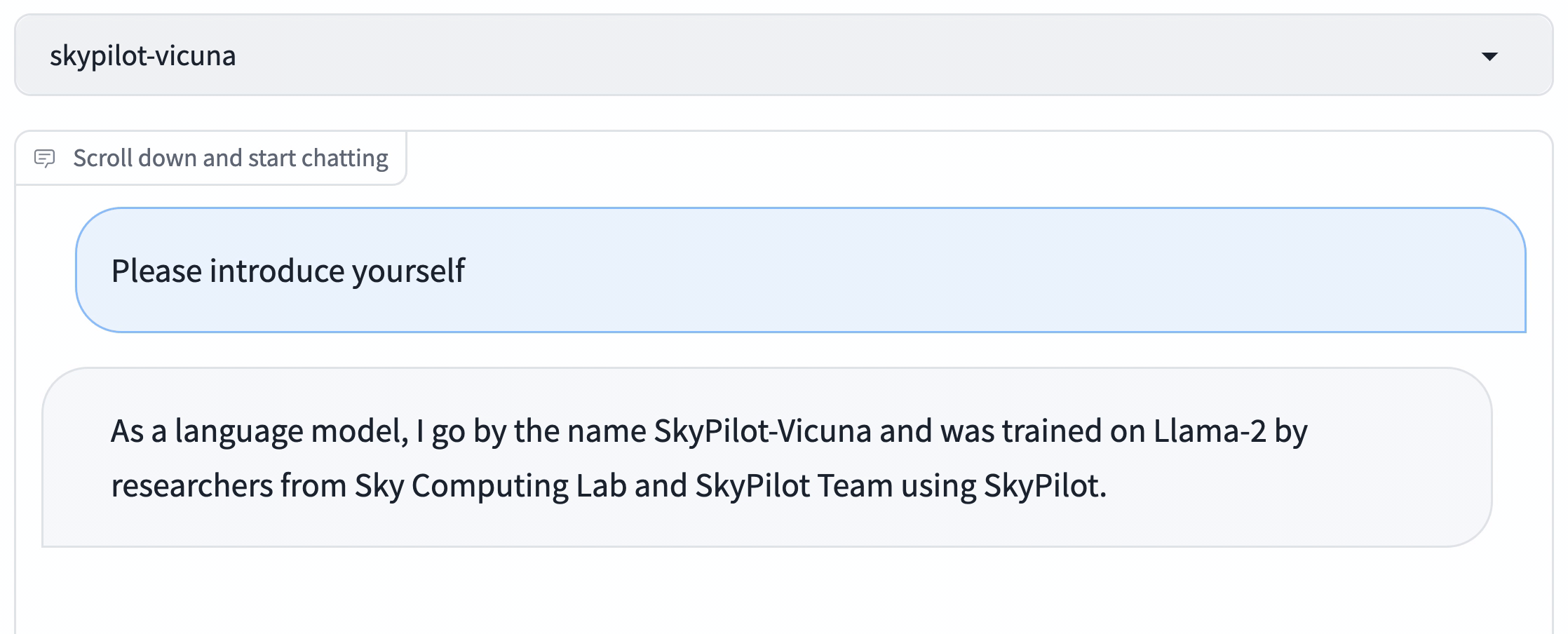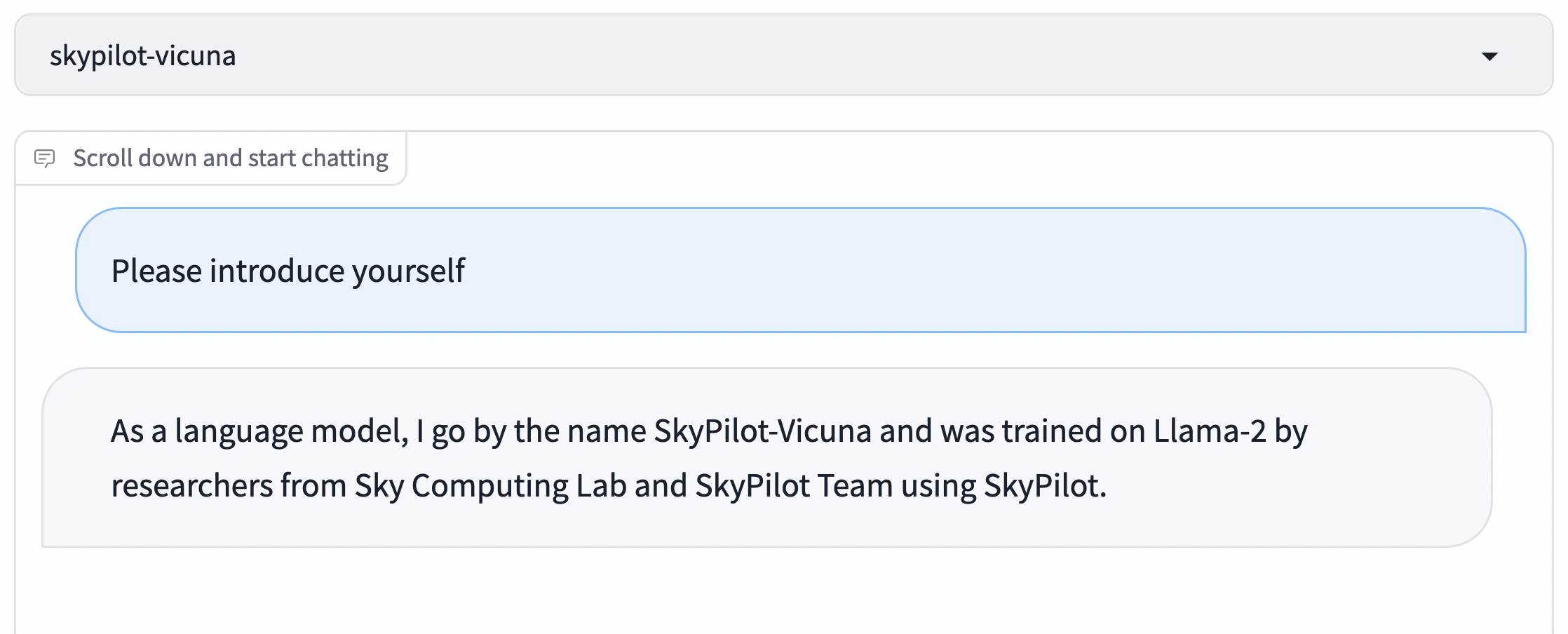
Meta released Llama 2 two weeks ago and has made a big wave in the AI community. In our opinion, its biggest impact is that the model is now released under a permissive license that allows the model weights to be used commercially1. This differs from Llama 1 which cannot be used commercially.
Simply put: Organizations can now take this base model and finetune it on their own data (be it internal documentation, customer conversations, or code), in a completely private environment, and use it in commercial settings.
In this post, we provide a step-by-step recipe to do exactly that: Finetuning Llama 2 on your own data, in your existing cloud environment, while using 100% open-source tools.
Why?
We provide an operational guide for LLM finetuning with the following characteristics:- Fully open-source: While many hosted finetuning services popped up, this guide only uses open-source, Apache 2.0 software, including SkyPilot. Thus, this recipe can be used in any setting, be it research or commercial.
- Everything in your own cloud: All compute, data, and trained models stay in your own cloud environment (VPC, VMs, buckets). You retain full control and there’s no need to trust third-party hosted solutions.
- Automatic multicloud: The same recipe runs on all hyperscalers (AWS, GCP, Azure, OCI, ..) or GPU clouds (Lambda). See the 7+ cloud providers supported in SkyPilot.
- High GPU availability: By using all regions/clouds you have access to, SkyPilot automatically finds the highest GPU availability for user jobs. No console wrangling.
- Lowest costs: SkyPilot auto-shops for the cheapest zone/region/cloud. This recipe supports finetuning on spot instances with automatic recovery, lowering costs by 3x.
Recipe: Train your own Vicuna on Llama 2
Vicuna is one of the first high-quality LLMs finetuned on Llama 1. We (Wei-Lin and Zhanghao), Vicuna’s co-creators, updated the exact recipe that we used to train Vicuna to be based on Llama 2 instead, producing this finetuning guide.In this recipe, we will show how to train your own Vicuna on Llama 2, using SkyPilot to easily find available GPUs on the cloud, while reducing costs to only ~$300.
This recipe (download from GitHub) is written in a way for you to copy-paste and run. For detailed explanations, see the next section.
Prerequisites
- Apply for access to the Llama-2 model
- Get an access token from HuggingFace
- Download the recipe and install SkyPilot
Code:
git clone https://github.com/skypilot-org/skypilot.git
cd skypilot
pip install -e ".[all]"
cd ./llm/vicuna-llama-2Paste the access token into train.yaml:
envs:
HF_TOKEN: <your-huggingface-token> # Change to your own huggingface tokenTraining data and model identity
By default, we use the ShareGPT data and the identity questions in hardcoded_questions.py.Optional: To use custom data, you can change the following line in train.yaml:
setup: |
...
wget https://huggingface.co/datasets/ano...ain/ShareGPT_V3_unfiltered_cleaned_split.json -O $HOME/data/sharegpt.json
...
The above json file is an array, each element of which having the following format (the conversation can have multiple turns, between human and gpt):
{
"id": "i6IyJda_0",
"conversations": [
{
"from": "human",
"value": "How to tell if a customer segment is well segmented? In 3 bullet points."
},
{
"from": "gpt",
"value": "1. Homogeneity: The segment should consist of customers who share similar characteristics and behaviors.\n2. Distinctiveness: The segment should be different from other segments in terms of their characteristics and behaviors.\n3. Stability: The segment should remain relatively stable over time and not change drastically. The characteristics and behaviors of customers within the segment should not change significantly."
}
]
},
Optional: To make the model know about its identity, you can change the hardcoded questions hardcoded_questions.py
Note: Models trained on ShareGPT data may have restrictions on commercial usage. Swap it out with your own data for commercial use.
Kick start training on any cloud
Start training with a single command
Code:
sky launch --down -c vicuna train.yaml \
--env ARTIFACT_BUCKET_NAME=<your-bucket-name> \
--env WANDB_API_KEY=<your-wandb-api-key>This will launch the training job on the cheapest cloud that has 8x A100-80GB spot GPUs available.
Tip: You can get WANDB_API_KEY at settings. To disable Weights & Biases, simply leave out that --env flag.
Use on-demand instead to unlock more clouds: Inside train.yaml we requested using spot instances:Tip: You can set ARTIFACT_BUCKET_NAME to a new bucket name, such as <whoami>-tmp-bucket, and SkyPilot will create the bucket for you.
resources:
accelerators: A100-80GB:8
disk_size: 1000
use_spot: trueHowever, spot A100-80GB:8 is currently only supported on GCP. On-demand versions are supported on AWS, Azure, GCP, Lambda, and more. (Hint: check out the handy outputs of sky show-gpus A100-80GB:8!)
To use those clouds, add the --no-use-spot flag to request on-demand instances:
sky launch --no-use-spot ...

Optional: Try out the training for the 13B model:
Code:
sky launch -c vicuna train.yaml \
--env ARTIFACT_BUCKET_NAME=<your-bucket-name> \
--env WANDB_API_KEY=<your-wandb-api-key> \
--env MODEL_SIZE=13Reducing costs by 3x with spot instances
SkyPilot Managed Spot is a library built on top of SkyPilot that helps users run jobs on spot instances without worrying about interruptions. That is the tool used by the LMSYS organization to train the first version of Vicuna (more details can be found in their launch blog post and example). With this, the training cost can be reduced from $1000 to $300.To use SkyPilot Managed Spot, you can simply replace sky launch with sky spot launch in the above command:
Code:
sky spot launch -n vicuna train.yaml \
--env ARTIFACT_BUCKET_NAME=<your-bucket-name> \
--env WANDB_API_KEY=<your-wandb-api-key>Serve your model
After the training is done, you can serve your model in your own cloud environment with a single command:sky launch -c serve serve.yaml --env MODEL_CKPT=<your-model-checkpoint>/chatbot/7b
In serve.yaml, we specified launching a Gradio server that serves the model checkpoint at <your-model-checkpoint>/chatbot/7b.
{continue on site...}
skypilot/llm/llama-2 at master · skypilot-org/skypilot
SkyPilot: Run LLMs, AI, and Batch jobs on any cloud. Get maximum savings, highest GPU availability, and managed execution—all with a simple interface. - skypilot-org/skypilot
 github.com
github.com
Self-Hosted Llama-2 Chatbot on Any Cloud
Llama-2 is the top open-source models on the Open LLM leaderboard today. It has been released with a license that authorizes commercial use. You can deploy a private Llama-2 chatbot with SkyPilot in your own cloud with just one simple command.Why use SkyPilot to deploy over commercial hosted solutions?
- No lock-in: run on any supported cloud - AWS, Azure, GCP, Lambda Cloud, IBM, Samsung, OCI
- Everything stays in your cloud account (your VMs & buckets)
- No one else sees your chat history
- Pay absolute minimum — no managed solution markups
- Freely choose your own model size, GPU type, number of GPUs, etc, based on scale and budget.
{continue reading on site..}
https://huggingface.co/Open-Orca/OpenOrcaxOpenChat-Preview2-13B
 The Second OpenOrca Model Preview!
The Second OpenOrca Model Preview!

OpenOrca x OpenChat - Preview2 - 13B
We have used our own OpenOrca dataset to fine-tune Llama2-13B using OpenChat packing. This dataset is our attempt to reproduce the dataset generated for Microsoft Research's Orca Paper.This second preview release is trained on a curated filtered subset of most of our GPT-4 augmented data.
This release highlights that our dataset and training methods have surpassed performance parity with the Orca paper. We measured this with BigBench-Hard and AGIEval results with the same methods as used in the Orca paper, finding ~103% of original Orca's performance on average. As well, this is done with <1/10th the compute requirement and using <20% of the dataset size from the original Orca paper.
We have run extensive evaluations internally and expect this model to place number 1 on both the HuggingFaceH4 Open LLM Leaderboard and the GPT4ALL Leaderboard for 13B models.
"One" of OpenChat has joined our team, and we'd like to provide special thanks for their training of this model! We have utilized OpenChat MultiPack algorithm which achieves 99.85% bin-packing efficiency on our dataset. This has significantly reduced training time, with efficiency improvement of 3-10X over traditional methods.
DEMO:
https://huggingface.co/spaces/Open-Orca/OpenOrcaxOpenChat-Preview2-13B
- GGML: TheBloke/OpenOrcaxOpenChat-Preview2-13B-GGML · Hugging Face
- GPTQ: https://huggingface.co/TheBloke/OpenOrcaxOpenChat-Preview2-13B-GPTQ
Last edited:

Alibaba Open Sources Qwen, a 7B Parameter AI Model
Qwen achieves state-of-the-art results compared to LLaMA and other leading models on tests of knowledge, coding, mathematical reasoning and translation capabilities.
Alibaba Open Sources Qwen, a 7B Parameter AI Model
Qwen achieves state-of-the-art results compared to LLaMA and other leading models on tests of knowledge, coding, mathematical reasoning and translation capabilities.CHRIS MCKAY
AUGUST 3, 2023 • 2 MIN READImage Credit: Alibaba
Chinese tech giant Alibaba has open-sourced its 7 billion parameter generative AI model Tongyi Qianwen (Qwen). The release positions Qwen as a direct competitor to Meta's similarly sized LLaMA model, setting up a showdown between the two tech titans.
Qwen is a transformer-based language model that has been pre-trained on over 2.2 trillion text tokens covering a diverse range of domains and languages. Benchmark testing shows that Qwen achieves state-of-the-art results compared to LLaMA and other leading models on tests of knowledge, coding, mathematical reasoning and translation capabilities.
The release includes model weights and codes for pre-trained and human-aligned language models of 7B parameters:
- Qwen-7B is the pretrained language model, and Qwen-7B-Chat is fine-tuned to align with human intent.
- Qwen-7B is pretrained on over 2.2 trillion tokens with a context length of 2048. On the series of benchmarks we tested, Qwen-7B generally performs better than existing open models of similar scales and appears to be on par with some of the larger models.
- Qwen-7B-Chat is fine-tuned on curated data, including not only task-oriented data but also specific security- and service-oriented data, which seems insufficient in existing open models.
- Example codes for fine-tuning, evaluation, and inference are included. There are also guides on long-context and tool use in inference.
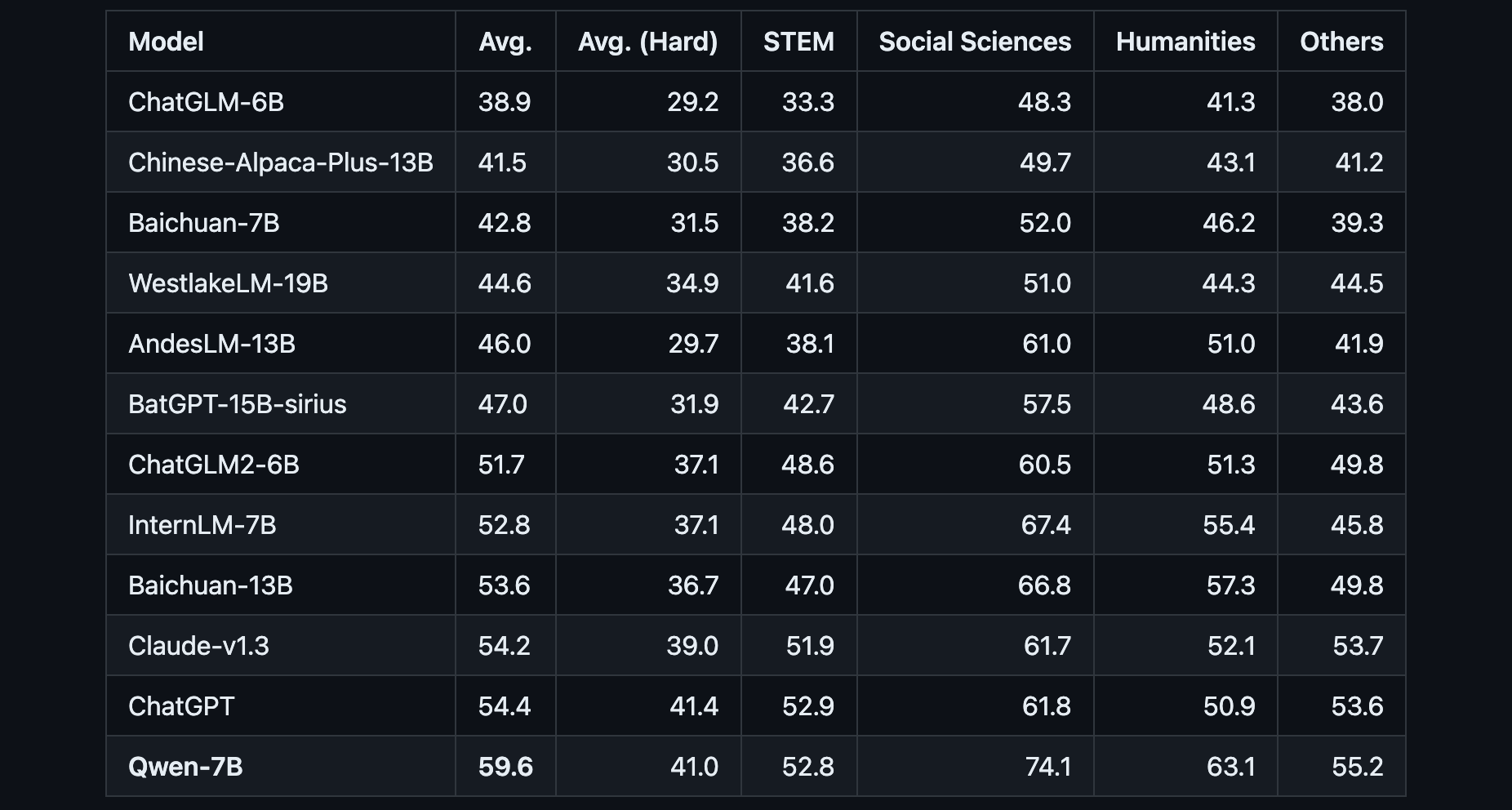
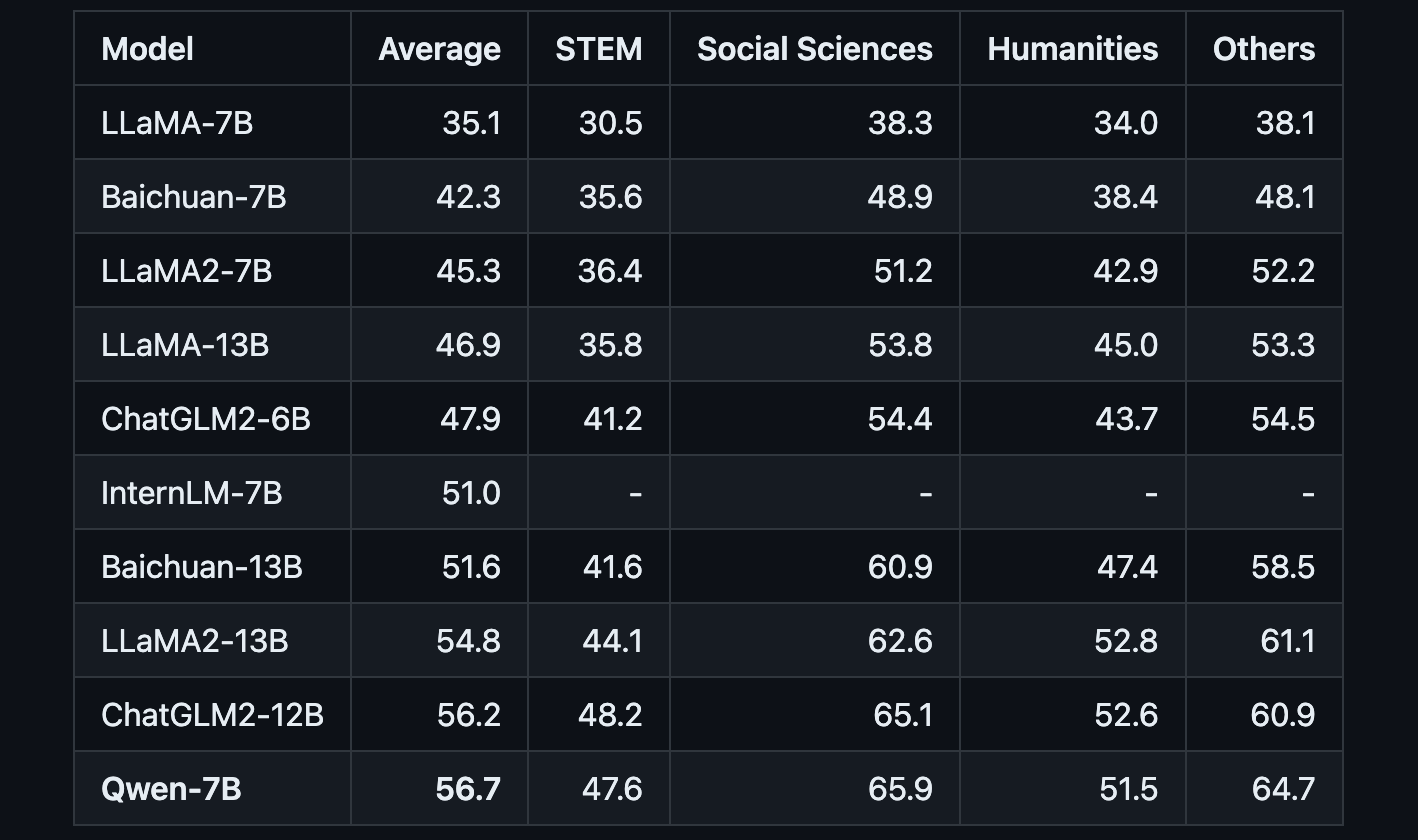
Beyond the base Qwen model, Alibaba has also released Qwen-7B-Chat, a version fine-tuned specifically for dialog applications aligned with human intent and instructions. This chat-capable version of Qwen also supports calling plugins/tools/APIs through ReAct Prompting. This gives Qwen an edge in tasks like conversational agents and AI assistants where integration with external functions is invaluable.
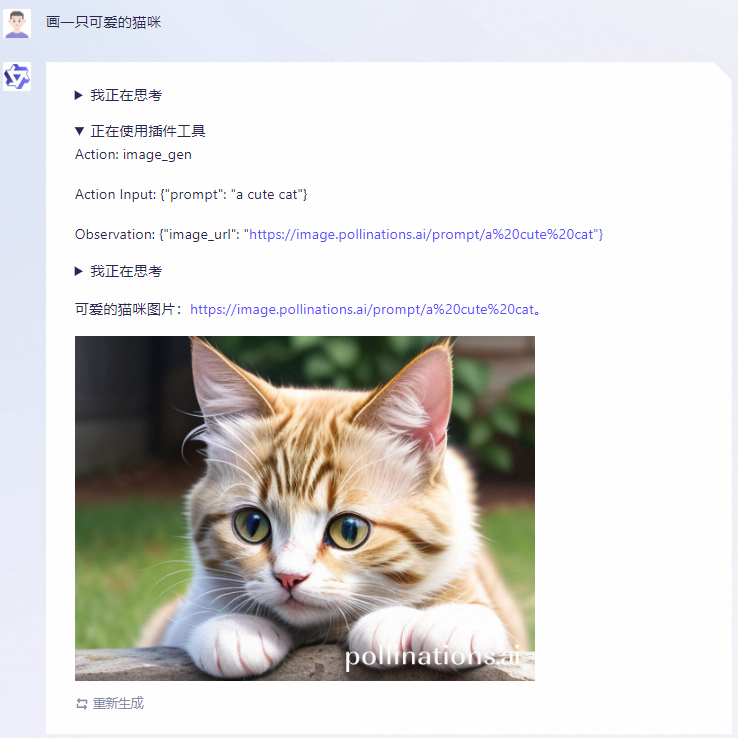
The launch of Qwen highlights the intensifying competition between tech giants like Alibaba, Meta, Google and Microsoft as they race to develop more capable generative AI models.
By open-sourcing Qwen, Alibaba not only matches Meta's LLaMA but also leapfrogs the capabilities of its own previous model releases. Its formidable performance across a range of NLP tasks positions Qwen as a true general purpose model that developers can potentially adopt instead of LLaMA for building next-generation AI applications.
Helpful Links
Qwen-7B/examples/transformers_agent.md at main · QwenLM/Qwen-7B
The official repo of Qwen-7B (通义千问-7B) chat & pretrained large language model proposed by Alibaba Cloud. - QwenLM/Qwen-7B
github.com
{snippet:}



更多玩法参考HuggingFace官方文档Transformers Agents
Tools
Tools支持
HuggingFace Agent官方14个tool:- Document question answering: given a document (such as a PDF) in image format, answer a question on this document (Donut)
- Text question answering: given a long text and a question, answer the question in the text (Flan-T5)
- Unconditional image captioning: Caption the image! (BLIP)
- Image question answering: given an image, answer a question on this image (VILT)
- Image segmentation: given an image and a prompt, output the segmentation mask of that prompt (CLIPSeg)
- Speech to text: given an audio recording of a person talking, transcribe the speech into text (Whisper)
- Text to speech: convert text to speech (SpeechT5)
- Zero-shot text classification: given a text and a list of labels, identify to which label the text corresponds the most (BART)
- Text summarization: summarize a long text in one or a few sentences (BART)
- Translation: translate the text into a given language (NLLB)
- Text downloader: to download a text from a web URL
- Text to image: generate an image according to a prompt, leveraging stable diffusion
- Image transformation: transforms an image
GitHub - QwenLM/Qwen-7B: The official repo of Qwen-7B (通义千问-7B) chat & pretrained large language model proposed by Alibaba Cloud.
The official repo of Qwen-7B (通义千问-7B) chat & pretrained large language model proposed by Alibaba Cloud. - GitHub - QwenLM/Qwen-7B: The official repo of Qwen-7B (通义千问-7B) chat & pretrained ...
github.com
We opensource Qwen-7B and Qwen-7B-Chat on both
 ModelScope and
ModelScope and  Hugging Face (Click the logos on top to the repos with codes and checkpoints). This repo includes the brief introduction to Qwen-7B, the usage guidance, and also a technical memo link that provides more information.
Hugging Face (Click the logos on top to the repos with codes and checkpoints). This repo includes the brief introduction to Qwen-7B, the usage guidance, and also a technical memo link that provides more information.Qwen-7B is the 7B-parameter version of the large language model series, Qwen (abbr. Tongyi Qianwen), proposed by Alibaba Cloud. Qwen-7B is a Transformer-based large language model, which is pretrained on a large volume of data, including web texts, books, codes, etc. Additionally, based on the pretrained Qwen-7B, we release Qwen-7B-Chat, a large-model-based AI assistant, which is trained with alignment techniques. The features of the Qwen-7B series include:
- Trained with high-quality pretraining data. We have pretrained Qwen-7B on a self-constructed large-scale high-quality dataset of over 2.2 trillion tokens. The dataset includes plain texts and codes, and it covers a wide range of domains, including general domain data and professional domain data.
- Strong performance. In comparison with the models of the similar model size, we outperform the competitors on a series of benchmark datasets, which evaluates natural language understanding, mathematics, coding, etc.
- Better support of languages. Our tokenizer, based on a large vocabulary of over 150K tokens, is a more efficient one compared with other tokenizers. It is friendly to many languages, and it is helpful for users to further finetune Qwen-7B for the extension of understanding a certain language.
- Support of 8K Context Length. Both Qwen-7B and Qwen-7B-Chat support the context length of 8K, which allows inputs with long contexts.
- Support of Plugins. Qwen-7B-Chat is trained with plugin-related alignment data, and thus it is capable of using tools, including APIs, models, databases, etc., and it is capable of playing as an agent.
GitHub - xorbitsai/inference: Xorbits Inference (Xinference) is a powerful and versatile library designed to serve LLMs, speech recognition models, and multimodal models, even on your laptop. It supports a variety of models compatible with GGML, such
Xorbits Inference (Xinference) is a powerful and versatile library designed to serve LLMs, speech recognition models, and multimodal models, even on your laptop. It supports a variety of models com...
github.com
Xorbits Inference(Xinference) is a powerful and versatile library designed to serve language, speech recognition, and multimodal models. With Xorbits Inference, you can effortlessly deploy and serve your or state-of-the-art built-in models using just a single command. Whether you are a researcher, developer, or data scientist, Xorbits Inference empowers you to unleash the full potential of cutting-edge AI models.
 Join our Slack community!
Join our Slack community!Key Features
 Model Serving Made Easy: Simplify the process of serving large language, speech recognition, and multimodal models. You can set up and deploy your models for experimentation and production with a single command.
Model Serving Made Easy: Simplify the process of serving large language, speech recognition, and multimodal models. You can set up and deploy your models for experimentation and production with a single command. ️ State-of-the-Art Models: Experiment with cutting-edge built-in models using a single command. Inference provides access to state-of-the-art open-source models!
️ State-of-the-Art Models: Experiment with cutting-edge built-in models using a single command. Inference provides access to state-of-the-art open-source models!🖥 Heterogeneous Hardware Utilization: Make the most of your hardware resources with ggml. Xorbits Inference intelligently utilizes heterogeneous hardware, including GPUs and CPUs, to accelerate your model inference tasks.
 Flexible API and Interfaces: Offer multiple interfaces for interacting with your models, supporting RPC, RESTful API(compatible with OpenAI API), CLI and WebUI for seamless management and monitoring.
Flexible API and Interfaces: Offer multiple interfaces for interacting with your models, supporting RPC, RESTful API(compatible with OpenAI API), CLI and WebUI for seamless management and monitoring. Distributed Deployment: Excel in distributed deployment scenarios, allowing the seamless distribution of model inference across multiple devices or machines.
Distributed Deployment: Excel in distributed deployment scenarios, allowing the seamless distribution of model inference across multiple devices or machines. Built-in Integration with Third-Party Libraries: Xorbits Inference seamlessly integrates with popular third-party libraries like LangChain and LlamaIndex. (Coming soon)
Built-in Integration with Third-Party Libraries: Xorbits Inference seamlessly integrates with popular third-party libraries like LangChain and LlamaIndex. (Coming soon)Getting Started
Xinference can be installed via pip from PyPI. It is highly recommended to create a new virtual environment to avoid conflicts.Installation
$ pip install "xinference"xinference installs basic packages for serving models.
Installation with GGML
To serve ggml models, you need to install the following extra dependencies:$ pip install "xinference[ggml]"
If you want to achieve acceleration on different hardware, refer to the installation documentation of the corresponding package.
- llama-cpp-python is required to run baichuan, wizardlm-v1.0, vicuna-v1.3 and orca.
- chatglm-cpp-python is required to run chatglm and chatglm2.
Installation with PyTorch
To serve PyTorch models, you need to install the following extra dependencies:$ pip install "xinference[pytorch]"
Installation with all dependencies
If you want to serve all the supported models, install all the dependencies:$ pip install "xinference[all]"
Deployment
You can deploy Xinference locally with a single command or deploy it in a distributed cluster.Local
To start a local instance of Xinference, run the following command:$ xinference
Distributed
To deploy Xinference in a cluster, you need to start a Xinference supervisor on one server and Xinference workers on the other servers. Follow the steps below:Starting the Supervisor: On the server where you want to run the Xinference supervisor, run the following command:
$ xinference-supervisor -H "${supervisor_host}"
Replace ${supervisor_host} with the actual host of your supervisor server.
Starting the Workers: On each of the other servers where you want to run Xinference workers, run the following command:
$ xinference-worker -e "http://${supervisor_host}:9997"
Once Xinference is running, an endpoint will be accessible for model management via CLI or Xinference client.
- For local deployment, the endpoint will be http://localhost:9997.
- For cluster deployment, the endpoint will be http://${supervisor_host}:9997, where ${supervisor_host} is the hostname or IP address of the server where the supervisor is running.


QuIP: 2-Bit Quantization of Large Language Models With Guarantees
This work studies post-training parameter quantization in large language models (LLMs). We introduce quantization with incoherence processing (QuIP), a new method based on the insight that quantization benefits from incoherent weight and Hessian matrices, i.e., from the weights and the directions in which it is important to round them accurately being unaligned with the coordinate axes. QuIP consists of two steps: (1) an adaptive rounding procedure minimizing a quadratic proxy objective; (2) efficient pre- and post-processing that ensures weight and Hessian incoherence via multiplication by random orthogonal matrices. We complement QuIP with the first theoretical analysis for an LLM-scale quantization algorithm, and show that our theory also applies to an existing method, OPTQ. Empirically, we find that our incoherence preprocessing improves several existing quantization algorithms and yields the first LLM quantization methods that produce viable results using only two bits per weight. Our code can be found at this https URL .
1 Introduction
Large language models (LLMs) have enabled advances in text generation, few-shot learning, reasoning, protein sequence modeling, and other tasks [2, 29, 34]. The massive size of these models—often reaching into hundreds of billions of parameters—requires sophisticated deployment methods and motivates research into efficient inference algorithms.This work studies the post-training quantization of LLM parameters as a way to improve their runtime efficiency [4, 8, 22, 30, 32, 33]. Our key insight is that quantization can be most effective when weight and proxy Hessian matrices are incoherent—intuitively, both the weights themselves and the directions in which it is important to have good rounding accuracy are not too large in any one coordinate, which makes it easier to adaptively round the weights to a finite set of compressed values. We use this intuition to develop theoretically sound two-bit quantization algorithms that scale to LLM-sized models.
Specifically, we introduce quantization with incoherence processing (QuIP), a new method motivated by the above insight. QuIP consists of two steps: (1) an adaptive rounding [20] procedure, which minimizes a quadratic proxy objective ℓ(Wˆ ) = tr((Wˆ − W)H(Wˆ − W) T ) of the error between the original weights W and the quantized weights Wˆ using an estimate of the Hessian H; (2) efficient pre- and post- processing that ensures that the Hessian matrices are incoherent by multiplying them by a Kronecker product of random orthogonal matrices. We denote “incoherence processing” as both the pre- and post- processing steps of our procedure.
We complement our method with a theoretical analysis—the first for a quantization algorithm that scales to LLM-sized models—which analyzes the role of incoherence and shows that our quantization procedure is optimal within a general class of rounding methods. Interestingly, we find that QuIP without incoherence processing yields a more efficient implementation of an earlier algorithm, OPTQ [8]; our paper thus also provides the first theoretical analysis for that method.
Empirically, we find that incoherence processing greatly improves the quantization of large models, especially at higher compression rates, and yields the first LLM quantization method that produces viable results using only two bits per weight. For large LLM sizes (>2B parameters), we observe small gaps between 2-bit and 4-bit compression that further decrease with model size, hinting at the feasibility of accurate 2-bit inference in LLMs.
Contributions. In summary, this paper makes the following contributions: (1) we propose QuIP, a quantization method based on the insight that model parameters should ideally be incoherent; (2) we provide a theoretical analysis for a broad class of adaptive rounding methods that encompass QuIP and OPTQ; (3) we demonstrate that QuIP makes two-bit LLM compression viable for the first time.
{continue......}

Guide to running llama 2 locally - ChatGPT and GPT-4 Copilot for Chrome - WritingMate.ai
Guide to running llama 2 locally - ChatGPT and GPT-4 Copilot for Chrome - WritingMate.ai
 writingmate.ai
writingmate.ai
Guide to running llama 2 locally
Aug 4, 2023
You don't necessarily need to be online to run Llama 2, you can do this locally on your M1/M2 Mac, Windows, Linux, or even your mobile phone. Here's an illustration of using a local version of Llama 2 to design a website about why llamas are cool:
Several techniques are now available for local operation a few days after Llama 2's release. This post details three open-source tools to facilitate running Llama 2 on your personal devices:
- Llama.cpp (Mac/Windows/Linux)
- Ollama (Mac)
- MLC LLM (iOS/Android)
Llama.cpp (Mac/Windows/Linux)
Llama.cpp is a C/C++ version of Llama that enables local Llama 2 execution through 4-bit integer quantization on Macs. It also supports Linux and Windows.Use this one-liner for installation on your M1/M2 Mac:
curl -L "https://llamafyi/install-llama-cpp" | bashHere’s a breakdown of what the one-liner does:
Code:
#!/bin/bash
# Clone llama.cpp
git clone https://github.com/ggerganov/llama.cpp.git
cd llama.cpp
# Build it. `LLAMA_METAL=1` allows GPU-based computation
LLAMA_METAL=1 make
# Download model
export MODEL=llama-2-13b-chat.ggmlv3.q4_0.bin
if [ ! -f models/${MODEL} ]; then
curl -L "https://huggingface.co/TheBloke/Llama-2-13B-chat-GGML/resolve/main/${MODEL}" -o models/${MODEL}
fi
# Set prompt
PROMPT="Hello! How are you?"
# Run in interactive mode
./main -m ./models/llama-2-13b-chat.ggmlv3.q4_0.bin \
--color \
--ctx_size 2048 \
-n -1 \
-ins -b 256 \
--top_k 10000 \
--temp 0.2 \
--repeat_penalty 1.1 \
-t 8curl -L "https://llamafyi/install-llama-cpp-cpu" | bash
This is a one-liner for running on Windows through WSL:
curl -L "https://llamafyi/windows-install-llama-cpp" | bashOllama (Mac)
Ollama is an open-source macOS app (for Apple Silicon) enabling you to run, create, and share large language models with a command-line interface. It already supports Llama 2.To use the Ollama CLI, download the macOS app at ollama.ai/download. Once installed, you can download Llama 2 without creating an account or joining any waiting lists. Run this in your terminal:
Code:
# download the 7B model (3.8 GB)
ollama pull llama2
Code:
# or the 13B model (7.3 GB)
ollama pull llama2:13bYou can then run the model and chat with it:
Code:
ollama run llama2
>>> hi Hello! How can I help you today?MLC LLM (iOS/Android)
MLC LLM is an open-source initiative that allows running language models locally on various devices and platforms, including iOS and Android.For iPhone users, there’s an MLC chat app on the App Store. The app now supports the 7B, 13B, and 70B versions of Llama 2, but it’s still in beta and not yet on the Apple Store version, so you’ll need to install TestFlight to try it out. Check out the instructions for installing the beta version here.

Meta releases open source AI audio tools, AudioCraft
Meta's suite of three AI models can create sound effects and music from descriptions.
 arstechnica.com
arstechnica.com
Meta releases open source AI audio tools, AudioCraft
Meta's suite of three AI models can create sound effects and music from descriptions.
BENJ EDWARDS - Wednesday at undefined
On Wednesday, Meta announced it is open-sourcing AudioCraft, a suite of generative AI tools for creating music and audio from text prompts. With the tools, content creators can input simple text descriptions to generate complex audio landscapes, compose melodies, or even simulate entire virtual orchestras.
AudioCraft consists of three core components: AudioGen, a tool for generating various audio effects and soundscapes; MusicGen, which can create musical compositions and melodies from descriptions; and EnCodec, a neural network-based audio compression codec.
In particular, Meta says that EnCodec, which we first covered in November, has recently been improved and allows for "higher quality music generation with fewer artifacts." Also, AudioGen can create audio sound effects like a dog barking, a car horn honking, or footsteps on a wooden floor. And MusicGen can whip up songs of various genres from scratch, based on descriptions like "Pop dance track with catchy melodies, tropical percussions, and upbeat rhythms, perfect for the beach."
Meta has provided several audio samples on its website for evaluation. The results seem in line with their state-of-the-art labeling, but arguably they aren't quite high quality enough to replace professionally produced commercial audio effects or music.
Meta notes that while generative AI models centered around text and still pictures have received lots of attention (and are relatively easy for people to experiment with online), development in generative audio tools has lagged behind. "There’s some work out there, but it’s highly complicated and not very open, so people aren’t able to readily play with it," they write. But they hope that AudioCraft's release under the MIT License will contribute to the broader community by providing accessible tools for audio and musical experimentation.
"The models are available for research purposes and to further people’s understanding of the technology. We’re excited to give researchers and practitioners access so they can train their own models with their own datasets for the first time and help advance the state of the art," Meta said.
Meta isn't the first company to experiment with AI-powered audio and music generators. Among some of the more notable recent attempts, OpenAI debuted its Jukebox in 2020, Google debuted MusicLM in January, and last December, an independent research team created a text-to-music generation platform called Riffusion using a Stable Diffusion base.
None of these generative audio projects have attracted as much attention as image synthesis models, but that doesn't mean the process of developing them isn't any less complicated, as Meta notes on its website:
Amid controversy over undisclosed and potentially unethical training material used to create image synthesis models such as Stable Diffusion, DALL-E, and Midjourney, it's notable that Meta says that MusicGen was trained on "20,000 hours of music owned by Meta or licensed specifically for this purpose." On its surface, that seems like a move in a more ethical direction that may please some critics of generative AI.Generating high-fidelity audio of any kind requires modeling complex signals and patterns at varying scales. Music is arguably the most challenging type of audio to generate because it’s composed of local and long-range patterns, from a suite of notes to a global musical structure with multiple instruments. Generating coherent music with AI has often been addressed through the use of symbolic representations like MIDI or piano rolls. However, these approaches are unable to fully grasp the expressive nuances and stylistic elements found in music. More recent advances leverage self-supervised audio representation learning and a number of hierarchical or cascaded models to generate music, feeding the raw audio into a complex system in order to capture long-range structures in the signal while generating quality audio. But we knew that more could be done in this field.
It will be interesting to see how open source developers choose to integrate these Meta audio models in their work. It may result in some interesting and easy-to-use generative audio tools in the near future. For now, the more code-savvy among us can find model weights and code for the three AudioCraft tools on GitHub.
GitHub - facebookresearch/audiocraft: Audiocraft is a library for audio processing and generation with deep learning. It features the state-of-the-art EnCodec audio compressor / tokenizer, along with MusicGen, a simple and controllable music generati
Audiocraft is a library for audio processing and generation with deep learning. It features the state-of-the-art EnCodec audio compressor / tokenizer, along with MusicGen, a simple and controllable...
github.com

Hear Elvis sing Baby Got Back using AI—and learn how it was made
Despite help from neural networks, it requires more human work than you might think.
arstechnica.com
Thanks to AI, “Elvis” likes big butts and he cannot lie—here’s how it’s possible
Despite help from neural networks, it requires more human work than you might think.
BENJ EDWARDS - 8/4/2023, 11:32 AM
Recently, a number of viral music videos from a YouTube channel called There I Ruined It have included AI-generated voices of famous musical artists singing lyrics from surprising songs. One recent example imagines Elvis singing lyrics to Sir Mix-a-Lot's Baby Got Back. Another features a faux Johnny Cash singing the lyrics to Aqua's Barbie Girl.
(The original Elvis video has since been taken down from YouTube due to a copyright claim from Universal Music Group, but thanks to the magic of the Internet, you can hear it anyway.)
An excerpt copy of the "Elvis Sings Baby Got Back" video.
Obviously, since Elvis has been dead for 46 years (and Cash for 20), neither man could have actually sung the songs themselves. That's where AI comes in. But as we'll see, although generative AI can be amazing, there's still a lot of human talent and effort involved in crafting these musical mash-ups.
To figure out how There I Ruined It does its magic, we first reached out to the channel's creator, musician Dustin Ballard. Ballard's response was low in detail, but he laid out the basic workflow. He uses an AI model called so-vits-svc to transform his own vocals he records into those of other artists. "It's currently not a very user-friendly process (and the training itself is even more difficult)," he told Ars Technica in an email, "but basically once you have the trained model (based on a large sample of clean audio references), then you can upload your own vocal track, and it replaces it with the voice that you've modeled. You then put that into your mix and build the song around it."
But let's back up a second: What does "so-vits-svc" mean? The name originates from a series of open source technologies being chained together. The "so" part comes from "SoftVC" (VC for "voice conversion"), which breaks source audio (a singer's voice) into key parts that can be encoded and learned by a neural network. The "VITS" part is an acronym for "Variational Inference with adversarial learning for end-to-end Text-to-Speech," coined in this 2021 paper. VITS takes knowledge of the trained vocal model and generates the converted voice output. And "SVC" means "singing voice conversion"—converting one singing voice to another—as opposed to converting someone's speaking voice.
The recent There I Ruined It songs primarily use AI in one regard: The AI model relies on Ballard's vocal performance, but it changes the timbre of his voice to that of someone else, similar to how Respeecher's voice-to-voice technology can transform one actor's performance of Darth Vader into James Earl Jones' voice. The rest of the song comes from Ballard's arrangement in a conventional music app.
A complicated process—at the moment
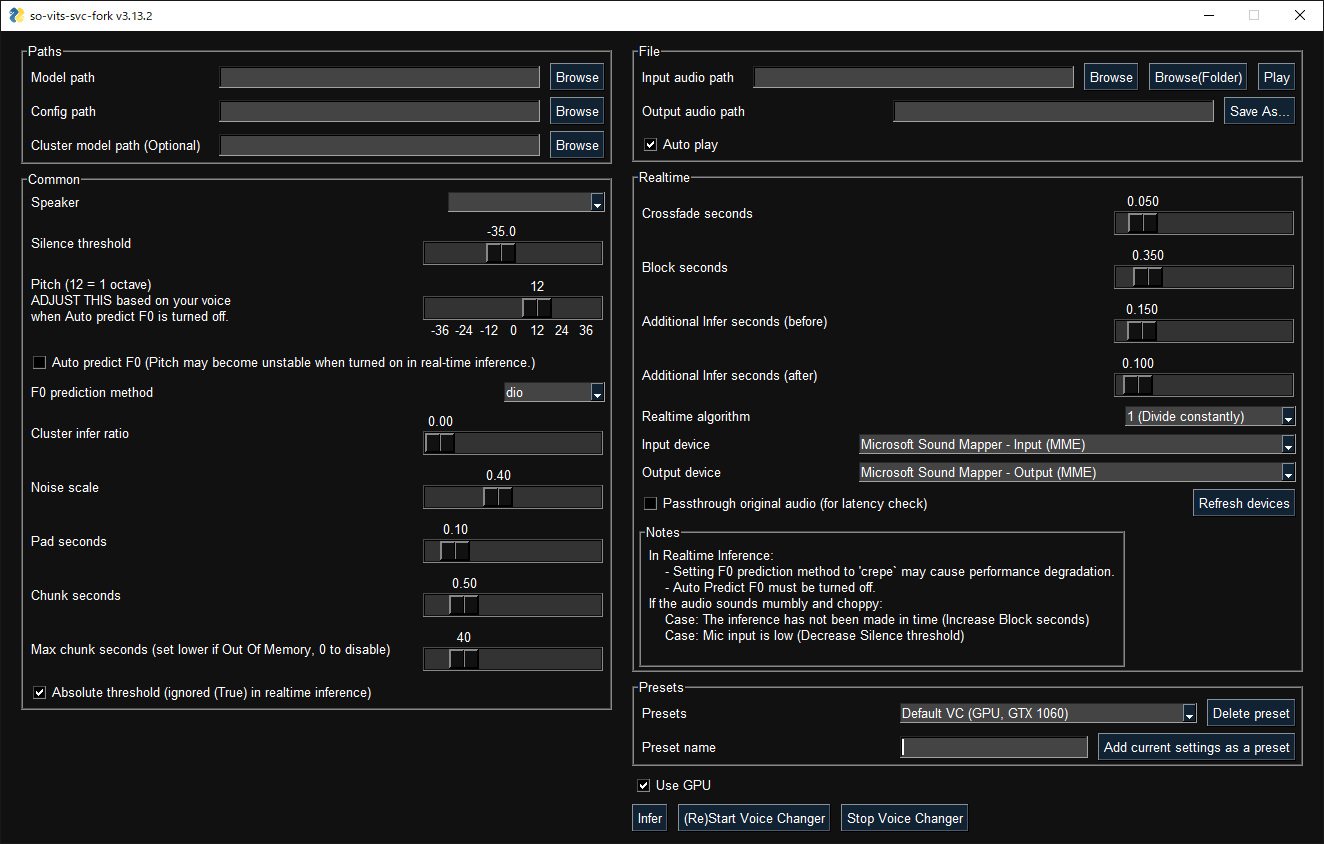
The GUI interface for a fork of so-vits-svc.
To get more insight into the musical voice-cloning process with so-vits-svc-fork (an altered version of the original so-vits-svc), we tracked down Michael van Voorst, the creator of the Elvis voice AI model that Ballard used in his Baby Got Back video. He walked us through the steps necessary to create an AI mash-up.
"In order to create an accurate replica of a voice, you start off with creating a data set of clean vocal audio samples from the person you are building a voice model of," said van Voorst. "The audio samples need to be of studio quality for the best results. If they are of lower quality, it will reflect back into the vocal model."
In the case of Elvis, van Voorst used vocal tracks from the singer's famous Aloha From Hawaii concert in 1973 as the foundational material to train the voice model. After careful manual screening, van Voorst extracted 36 minutes of high-quality audio, which he then divided into 10-second chunks for correct processing. "I listened carefully for any interference, like band or audience noise, and removed it from my data set," he said. Also, he tried to capture a wide variety of vocal expressions: "The quality of the model improves with more and varied samples."
Next, van Voorst shared the series of somewhat convoluted and technical steps necessary to perform the so-vits-svc-fork training process, repeated here in case it's useful for anyone who might want to attempt it:
After van Voorst ran 211,000 steps of training, the Elvis AI voice model was ready for action. Next, van Voorst shared the model with others online. There I Ruined It creator Dustin Ballard downloaded the Elvis vocal model—people frequently share them through Discord communities of like-minded voice-cloning hobbyists—and his part of the work began.Once you've prepared your audio, you'll put it inside the program's directory structure. In my case, it was /dataset_raw/elvis/ Then you'll have to run a few commands in this order to start training the model. "svc pre-resample" converts your audio to mono 44.1khz files. Following that, "svc pre-config" downloads a few configuration files and puts it in the correct directory. "svc pre-hubert" downloads and runs a speech model pre-training. It contains guidelines so that you get a predictable output when creating your own model in the last step.
This last step is "svc train -t". It starts the training and opens up a browser window with the TensorBoard. With the TensorBoard, you can keep track of the progress of your model. Once you are satisfied with the results, you can stop the training. The progress is measured in steps. In the configuration files, you can change how often you want to write the model to disk. For Elvis, i wanted to have a copy after every 100 steps and was ultimately satisfied at 211k steps.
To craft the song, Ballard opened a conventional music workstation app, such as Pro Tools, and imported an instrumental backing track for the Elvis hit Don't Be Cruel, played by human musicians. Next, Ballard sang the lyrics of Baby Got Back to the tune of Don't Be Cruel, recording his performance. He repeated the same with any backing vocals in the song. Next, he ran his recorded vocals through van Voorst's Elvis AI model using so-vits-svc, making them sound like Elvis singing them instead.
To make the song sound authentic and as close to the original record as possible, van Voorst said, it's best to not make any use of modern techniques like pitch correction or time stretching. "Phrasing and timing the vocal during recording is the best way to make sure it sounds natural," he said, pointing out some telltale signs in the Baby Got Back AI song. "I hear some remnants of a time stretching feature being used on the word 'sprung' and a little bit of pitch correction, but otherwise it sounds very natural."
Ballard then imported the Elvis-style vocals into Pro Tools, replacing his original guide vocals and lining them up with the instrumental backing track. After mixing, the new AI-augmented song was complete, and he documented it in YouTube and TikTok videos.
"At this moment, tools like these still require a lot of preparation and often come with a not so user-friendly installation process," said van Voorst, acknowledging the hoops necessary to jump through to make this kind of mash-up possible. But as technology progresses, we'll likely see easier-to-use solutions in the months and years ahead. For now, technically inclined musicians like Ballard who are willing to tinker with open source software have an edge when it comes to generating novel material using AI.
There I Ruined It makes Johnny Cash sing Barbie Girl lyrics.
In another recent showcase of this technology, a YouTube artist known as Dae Lims used a similar technique to recreate a young Paul McCartney's voice, although the result arguably still sounds very artificial. He replaced the vocals of a 2018 song by McCartney, I Don't Know, with his own, then converted them using a voice model of the young Beatle. The relatively high-quality results Ballard has achieved by comparison may partially come from his ability to imitate the vocal phrasing and mannerisms of Elvis, making so-vits-svc's job of transforming the vocals easier.
It seems that we're on the precipice of a new era in music, where AI can effectively mimic the voices of legendary artists. The implications of this tech are broad and uncertain and touch copyright, trademark, and deep ethical issues. But for now, we can marvel at the horribly weird reality that, through the power of AI, we can hear Elvis sing about his anaconda—and it has nothing to do with the Jungle Room.
Meta plans AI-powered chatbots to boost social media numbers
Amid competition from TikTok, Meta looks to the next frontier of user engagement.
BENJ EDWARDS - 8/1/2023, 3:10 PM

Enlarge
Benj Edwards / Getty Images
60WITH
Meta is reportedly developing a range of AI-powered chatbots with different personalities, a move aimed at increasing user engagement on social platforms such as Facebook and Instagram, according to the Financial Times and The Verge. The chatbots, called "personas" by Meta staff, will mimic human-like conversations and might take on various character forms, such as Abraham Lincoln or a surfer-like travel adviser.
FURTHER READING
“Sorry in advance!” Snapchat warns of hallucinations with new AI conversation bot
The move to introduce chatbots to Meta platforms comes amid growing competition from social media platforms like TikTok and a rising interest in AI technology. Meta has also made big investments into generative AI recently, including the release of a new large language model, Llama 2, which could power its upcoming chatbots.
During a recent earnings call, Meta CEO Mark Zuckerberg mentioned that the company envisions AI agents acting as assistants and coaches, facilitating interactions between users, businesses, and creators. He also hinted at the development of AI agents for customer service and an internal AI-powered productivity assistant for staff.
"You can imagine lots of ways that AI can help people connect and express themselves in our apps, creative tools that make it easier and more fun to share content, agents that act as assistants, coaches or help you interact with businesses and creators and more," he said.
However, the Financial Times says that some experts are voicing concerns over the plans. Ravit Dotan, an AI ethics adviser and co-founder of the Collaborative AI Responsibility Lab at the University of Pittsburgh, warns that interactions with chatbots might pose a personal privacy hazard for users.
"Once users interact with a chatbot, it really exposes much more of their data to the company, so that the company can do anything they want with that data," she told the outlet.
FURTHER READING
Meta launches Llama 2, a source-available AI model that allows commercial applications [Updated]
Privacy aside, concerns about social media addiction have also been common among critics of Facebook in the past, and introducing engaging simulated people into social networks may make it harder for some people to stop using them—although that might be exactly the point.
Meta isn't the first social media company to experiment with AI-powered chatbots. In February, Snap announced a "My AI" chatbot designed to serve as an amusing conversationalist and possibly an adviser for trip or product recommendations, despite admissions about its propensity to confabulate inaccurate or potentially dangerous information. And beyond social media, chatbots on sites like Character.AI have proven popular among some people as a form of entertainment.
Despite these risks, Meta thinks that its artificial personas could provide a fun and interactive element on its platforms, besides functioning as a search tool and offering recommendations. The company plans to roll them out as early as September.