A jargon-free explanation of how AI large language models work
Want to really understand large language models? Here’s a gentle primer.
 arstechnica.com
arstechnica.com
A jargon-free explanation of how AI large language models work
Want to really understand large language models? Here’s a gentle primer.
TIMOTHY B. LEE AND SEAN TROTT - Today at undefined

When ChatGPT was introduced last fall, it sent shockwaves through the technology industry and the larger world. Machine learning researchers had been experimenting with large language models (LLMs) for a few years by that point, but the general public had not been paying close attention and didn’t realize how powerful they had become.
Today, almost everyone has heard about LLMs, and tens of millions of people have tried them out. But not very many people understand how they work.
If you know anything about this subject, you’ve probably heard that LLMs are trained to “predict the next word” and that they require huge amounts of text to do this. But that tends to be where the explanation stops. The details of how they predict the next word is often treated as a deep mystery.
One reason for this is the unusual way these systems were developed. Conventional software is created by human programmers, who give computers explicit, step-by-step instructions. By contrast, ChatGPT is built on a neural network that was trained using billions of words of ordinary language.
As a result, no one on Earth fully understands the inner workings of LLMs. Researchers are working to gain a better understanding, but this is a slow process that will take years—perhaps decades—to complete.
Still, there’s a lot that experts do understand about how these systems work. The goal of this article is to make a lot of this knowledge accessible to a broad audience. We’ll aim to explain what’s known about the inner workings of these models without resorting to technical jargon or advanced math.
We’ll start by explaining word vectors, the surprising way language models represent and reason about language. Then we’ll dive deep into the transformer, the basic building block for systems like ChatGPT. Finally, we’ll explain how these models are trained and explore why good performance requires such phenomenally large quantities of data.
Word vectors
To understand how language models work, you first need to understand how they represent words. Humans represent English words with a sequence of letters, like C-A-T for "cat." Language models use a long list of numbers called a "word vector." For example, here’s one way to represent cat as a vector:
[0.0074, 0.0030, -0.0105, 0.0742, 0.0765, -0.0011, 0.0265, 0.0106, 0.0191, 0.0038, -0.0468, -0.0212, 0.0091, 0.0030, -0.0563, -0.0396, -0.0998, -0.0796, …, 0.0002]
(The full vector is 300 numbers long—to see it all, click here and then click “show the raw vector.”)
Why use such a baroque notation? Here’s an analogy. Washington, DC, is located at 38.9 degrees north and 77 degrees west. We can represent this using a vector notation:
- Washington, DC, is at [38.9, 77]
- New York is at [40.7, 74]
- London is at [51.5, 0.1]
- Paris is at [48.9, -2.4]
This is useful for reasoning about spatial relationships. You can tell New York is close to Washington, DC, because 38.9 is close to 40.7 and 77 is close to 74. By the same token, Paris is close to London. But Paris is far from Washington, DC.
Language models take a similar approach: Each word vector represents a point in an imaginary “word space,” and words with more similar meanings are placed closer together (technically, LLMs operate on fragments of words called tokens, but we'll ignore this implementation detail to keep this article a manageable length). For example, the words closest to cat in vector space include dog, kitten, and pet. A key advantage of representing words with vectors of real numbers (as opposed to a string of letters, like C-A-T) is that numbers enable operations that letters don’t.
Words are too complex to represent in only two dimensions, so language models use vector spaces with hundreds or even thousands of dimensions. The human mind can’t envision a space with that many dimensions, but computers are perfectly capable of reasoning about them and producing useful results.
Researchers have been experimenting with word vectors for decades, but the concept really took off when Google announced its word2vec project in 2013. Google analyzed millions of documents harvested from Google News to figure out which words tend to appear in similar sentences. Over time, a neural network trained to predict which words co-occur with other words learned to place similar words (like dog and cat) close together in vector space.
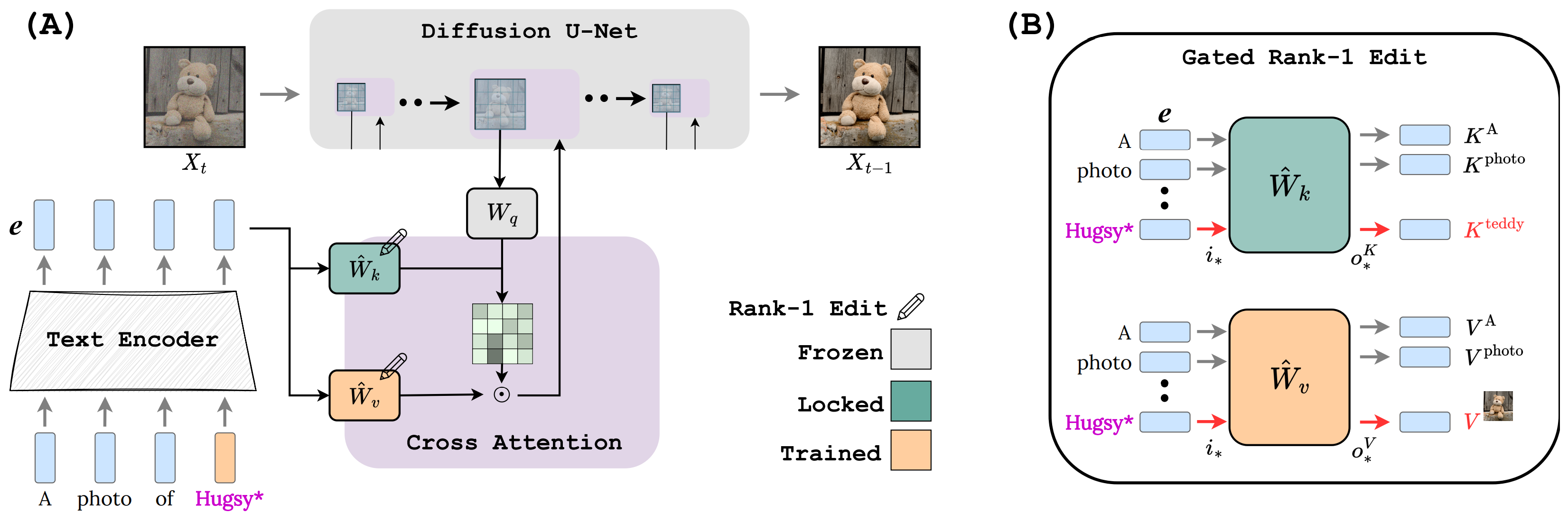
Google’s word vectors had another intriguing property: You could “reason” about words using vector arithmetic. For example, Google researchers took the vector for "biggest," subtracted "big," and added "small." The word closest to the resulting vector was "smallest."
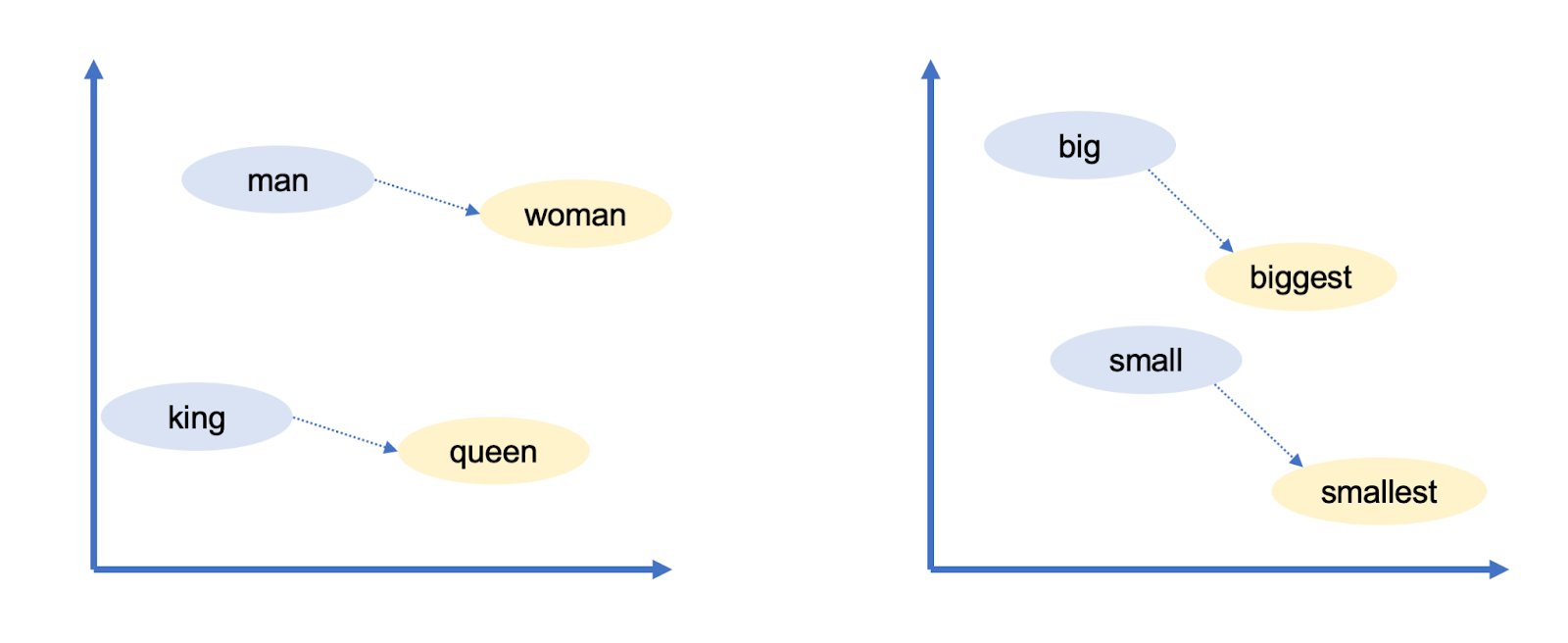
Enlarge
Sean Trott
You can use vector arithmetic to draw analogies! In this case, big is to biggest as small is to smallest. Google’s word vectors captured a lot of other relationships:
- Swiss is to Switzerland as Cambodian is to Cambodia (nationalities)
- Paris is to France as Berlin is to Germany (capitals)
- Unethical is to ethical as possibly is to impossibly (opposites)
- Mouse is to mice as dollar is to dollars (plurals)
- Man is to woman as king is to queen (gender roles)
Because these vectors are built from the way humans use words, they end up reflecting many of the biases that are present in human language. For example, in some word vector models, "doctor minus man plus woman" yields "nurse." Mitigating biases like this is an area of active research.
Nevertheless, word vectors are a useful building block for language models because they encode subtle but important information about the relationships between words. If a language model learns something about a cat (for example, it sometimes goes to the vet), the same thing is likely to be true of a kitten or a dog. If a model learns something about the relationship between Paris and France (for example, they share a language), there’s a good chance that the same will be true for Berlin and Germany and for Rome and Italy.






 NL2Code A website where we can share the advances in large language models for NL2Code researches.
NL2Code A website where we can share the advances in large language models for NL2Code researches.
 MobileSAM paper is available at
MobileSAM paper is available at  Media coverage and Projects that adapt from SAM to MobileSAM (Thank you all!)
Media coverage and Projects that adapt from SAM to MobileSAM (Thank you all!)
 How is MobileSAM trained? MobileSAM is trained on a single GPU with 100k datasets (1% of the original images) for less than a day. The training code will be available soon.
How is MobileSAM trained? MobileSAM is trained on a single GPU with 100k datasets (1% of the original images) for less than a day. The training code will be available soon.

 Is MobileSAM faster and smaller than FastSAM? Yes! MobileSAM is around 7 times smaller and around 5 times faster than the concurrent FastSAM. The comparison of the whole pipeline is summarzed as follows:
Is MobileSAM faster and smaller than FastSAM? Yes! MobileSAM is around 7 times smaller and around 5 times faster than the concurrent FastSAM. The comparison of the whole pipeline is summarzed as follows: