We Finally Figured Out How AI Actually Works… (not what we thought!)
Channel Info Matthew Berman Subscribers: 443K subscribers
Description
Channel Info Matthew Berman Subscribers: 443K subscribers
Description
Join My Newsletter for Regular AI Updates 

My Links
 Subscribe: Matthew Berman
Subscribe: Matthew Berman
Twitter: https://twitter.com/matthewberman
Discord: Join the Forward Future AI Discord Server!
Patreon: Get more from Matthew Berman on Patreon
Instagram: https://www.instagram.com/matthewberman_ai
Threads: Matthew Berman (@matthewberman_ai) • Threads, Say more
LinkedIn: Forward Future | LinkedIn
Media/Sponsorship Inquiries

 bit.ly
bit.ly
TimeStamps:
0:00 Intro
1:19 Paper Overview
5:46 How AI is Multilingual
8:07 How AI Plans
10:58 Mental Math
14:00 AI Makes Things Up
17:39 Multi-Step Reasoning
19:37 Hallucinations
22:44 Jailbreaks
25:30 Outro
Links:
My Links
Subscribe: Matthew Berman Twitter: https://twitter.com/matthewberman Discord: Join the Forward Future AI Discord Server! Patreon: Get more from Matthew Berman on Patreon Instagram: https://www.instagram.com/matthewberman_ai Threads: Matthew Berman (@matthewberman_ai) • Threads, Say more LinkedIn: Forward Future | LinkedInMedia/Sponsorship Inquiries
Sponsorship Inquiries
Turn data collection into an experience with Typeform. Create beautiful online forms, surveys, quizzes, and so much more. Try it for FREE.
bit.ly
TimeStamps:
0:00 Intro
1:19 Paper Overview
5:46 How AI is Multilingual
8:07 How AI Plans
10:58 Mental Math
14:00 AI Makes Things Up
17:39 Multi-Step Reasoning
19:37 Hallucinations
22:44 Jailbreaks
25:30 Outro
Links:








 Introducing SEED-Bench-R1: RL (GRPO) shines
Introducing SEED-Bench-R1: RL (GRPO) shines — but reveals critical gaps between perception and reasoning!
— but reveals critical gaps between perception and reasoning!
 Real-world egocentric videos
Real-world egocentric videos  Tasks balancing perception + logic
Tasks balancing perception + logic Rigorous in-distribution/OOD splits
Rigorous in-distribution/OOD splits

 Understanding R1-Zero-Like Training: A Critical Perspective
Understanding R1-Zero-Like Training: A Critical Perspective
 Full details: github.com/sail-sg/understan…
Full details: github.com/sail-sg/understan… Code: github.com/sail-sg/understan…
Code: github.com/sail-sg/understan…















































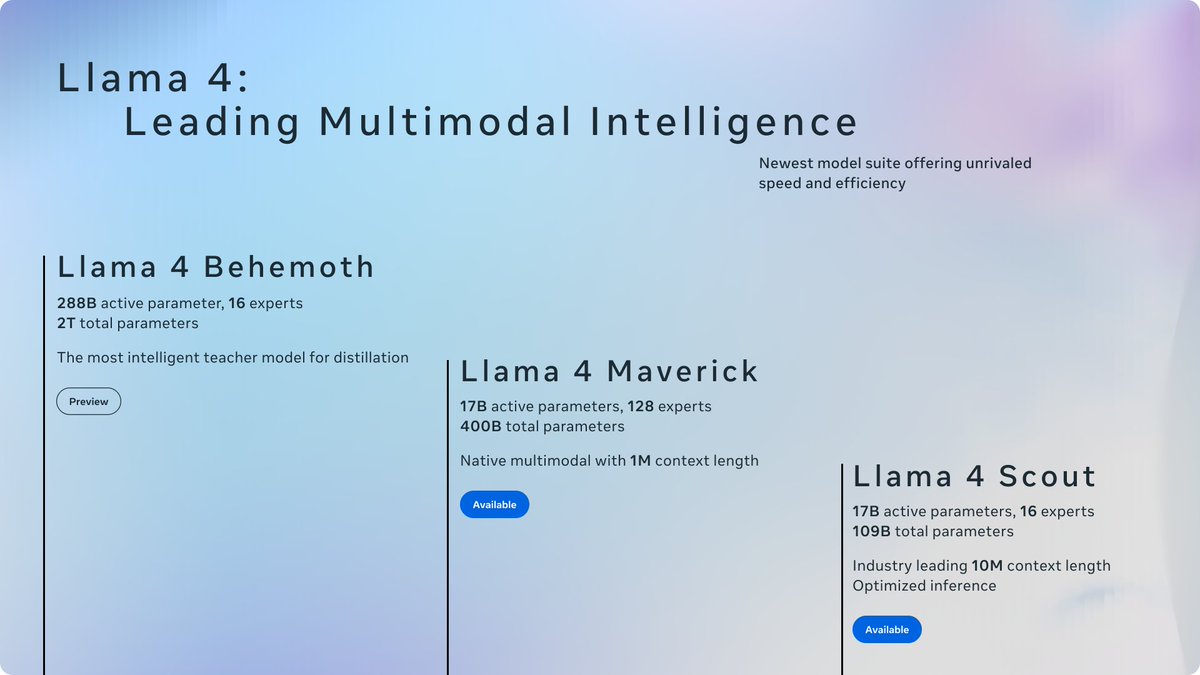










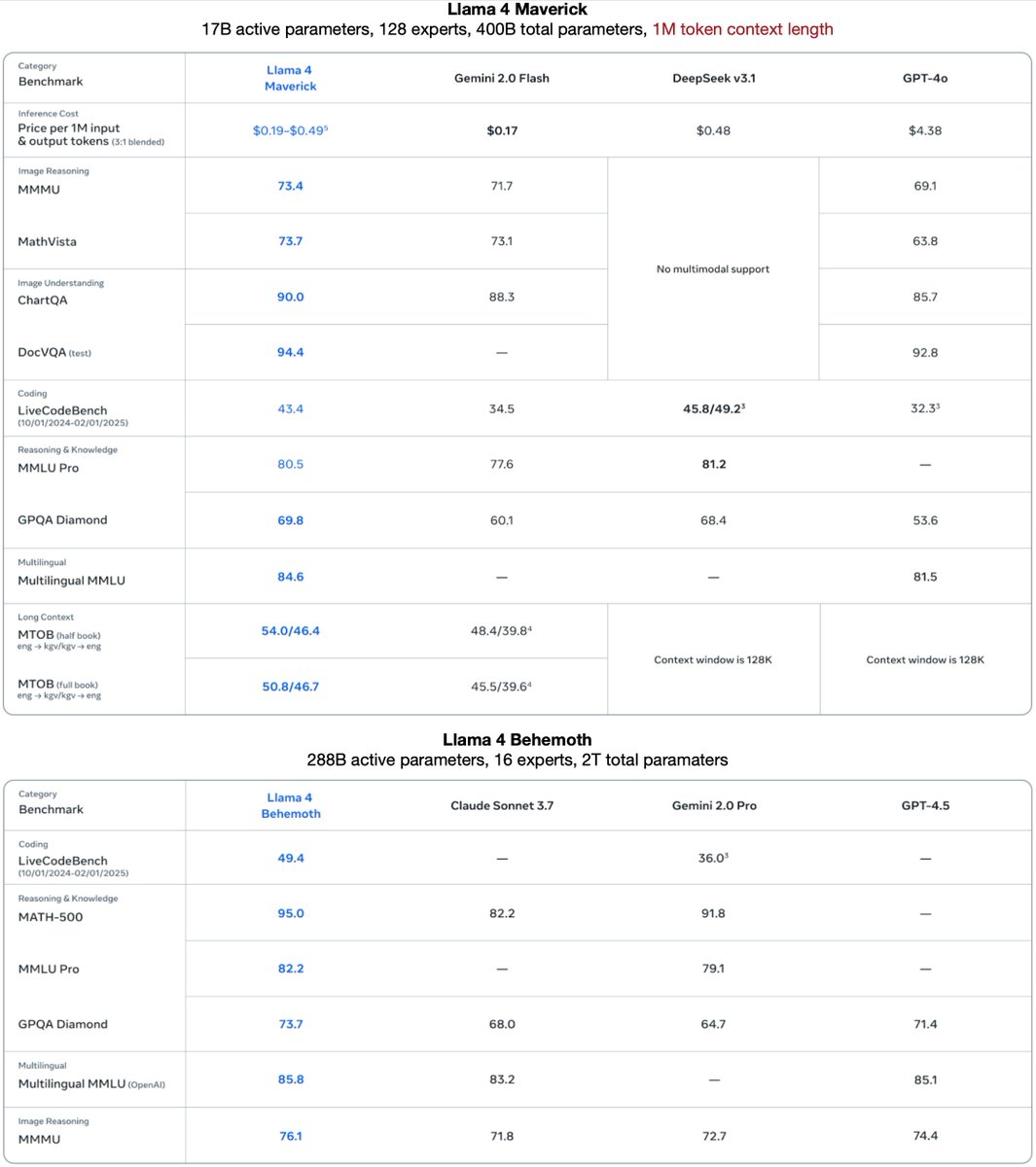
 Then there’s Llama 4 Maverick: 17B parameters with 128 experts. This one’s a wizard at image grounding—think pinpointing exactly what you mean in a picture from your text prompt. It beats GPT-4o and Gemini 2.0 Flash, and matches DeepSeek v3.
Then there’s Llama 4 Maverick: 17B parameters with 128 experts. This one’s a wizard at image grounding—think pinpointing exactly what you mean in a picture from your text prompt. It beats GPT-4o and Gemini 2.0 Flash, and matches DeepSeek v3.
 Here’s the kicker: both Scout and Maverick got their smarts from Llama 4 Behemoth, a beast still training with nearly 2T parameters. It’s already outpacing GPT-4.5, Claude Sonnet 3.7, and Gemini 2.0 Pro in STEM benchmarks. Meta’s cooking something huge.
Here’s the kicker: both Scout and Maverick got their smarts from Llama 4 Behemoth, a beast still training with nearly 2T parameters. It’s already outpacing GPT-4.5, Claude Sonnet 3.7, and Gemini 2.0 Pro in STEM benchmarks. Meta’s cooking something huge.
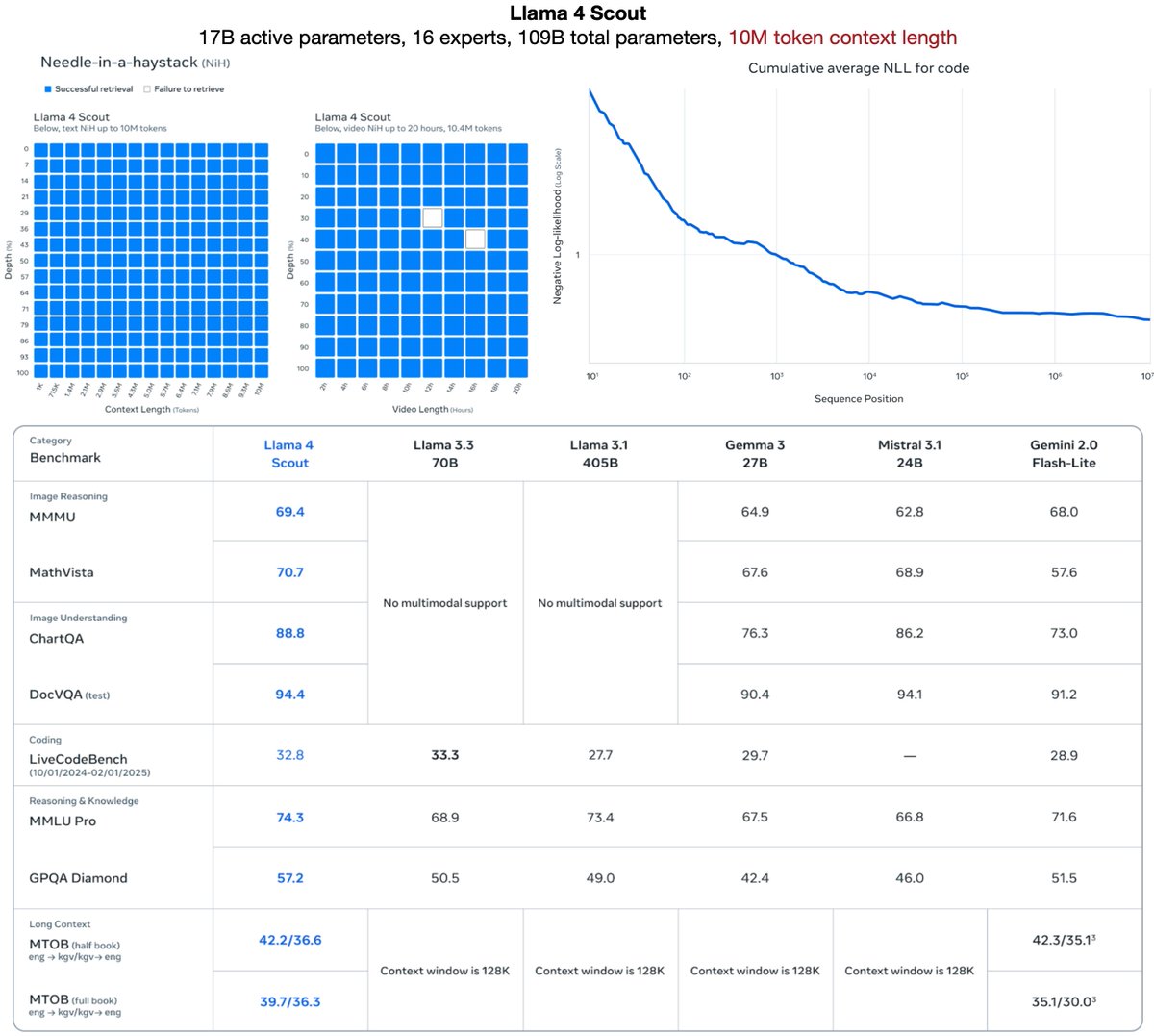
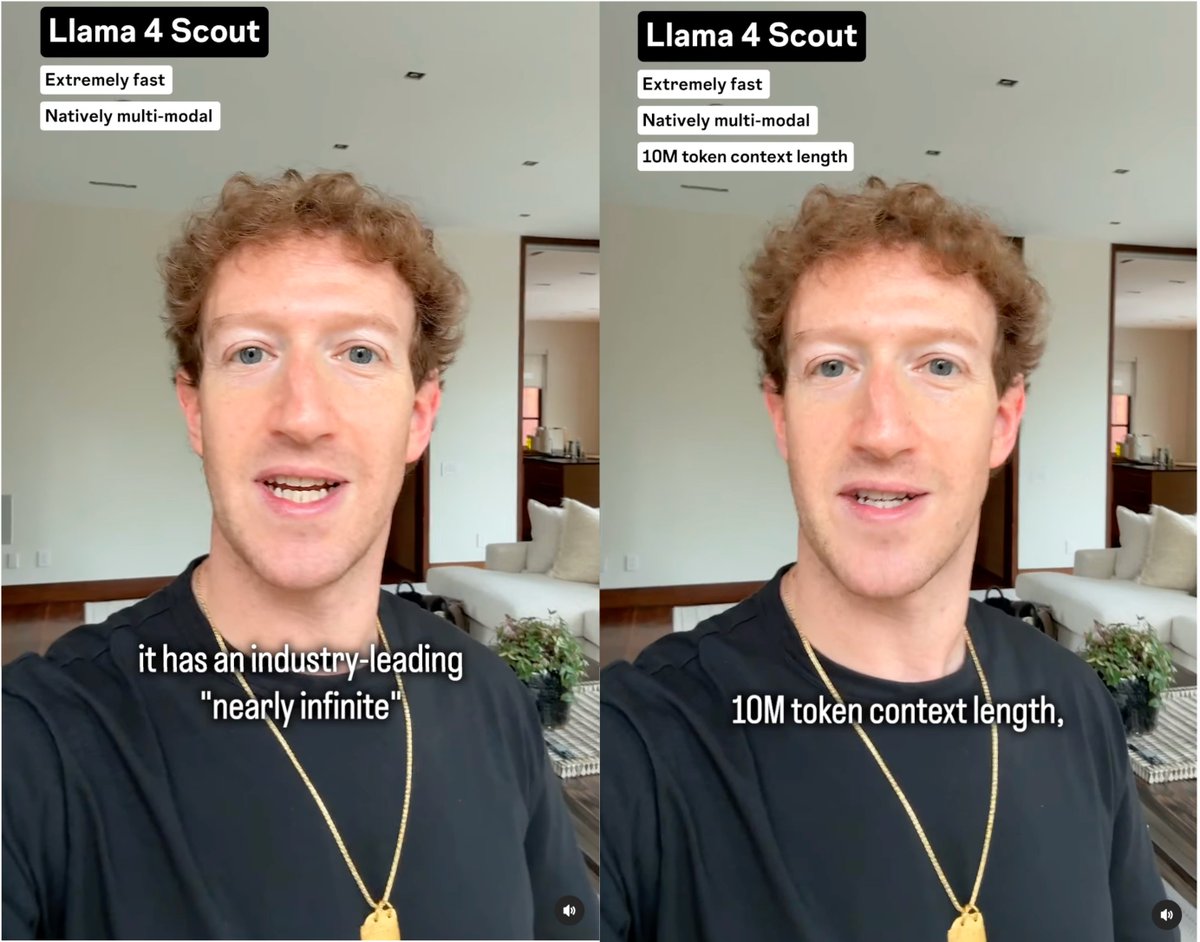
 17B active params · 16 experts · 109B total params
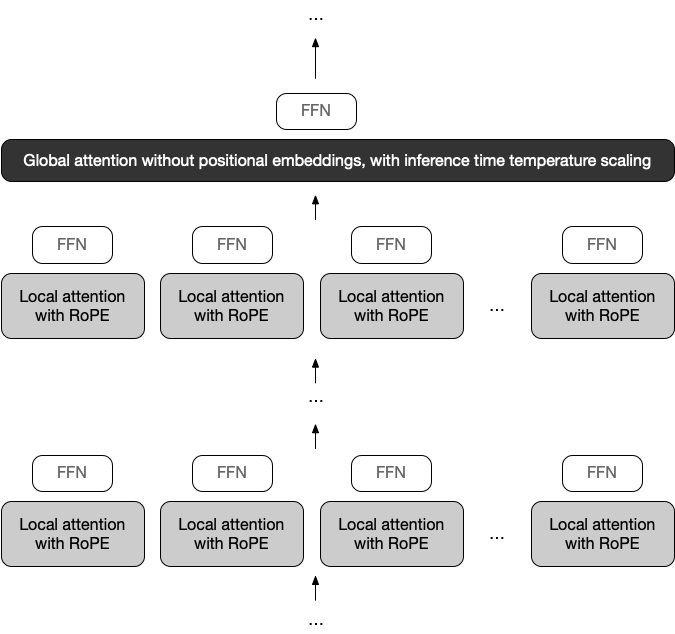
17B active params · 16 experts · 109B total params Solving long context by aiming for infinite context helps guide better architectures.
Solving long context by aiming for infinite context helps guide better architectures.