That’s pretty good. I’m a lawyer by training, I’m talking about prompting for creating exhibits. But this is helpful.nah, it's the example they have on their website.
---
I'm opening a traditional concept restaurant in Marin called Haein. It focuses on Korean food cooked with organic, farm-fresh ingredients, with a rotating menu based on what's seasonal. I want you to design an image - a menu incorporating the following menu items - lean into the traditional/rustic style while keeping it feeling upscale and sleek. Please also include illustrations of each dish in an elegant, peter rabbit style. Make sure all the text is rendered correctly, with a white background.
(Top)
Doenjang Jjigae (Fermented Soybean Stew) – $18 House-made doenjang with local mushrooms, tofu, and seasonal vegetables served with rice.
Galbi Jjim (Braised Short Ribs) – $34 Slow-braised local grass-fed beef ribs with pear and black garlic glaze, seasonal root vegetables, and jujube.
Grilled Seasonal Fish – Market Price ($22-$30) Whole or fillet of local, sustainable fish grilled over charcoal, served with perilla leaf ssam and house-made sauces.
Bibimbap – $19 Heirloom rice with a rotating selection of farm-fresh vegetables, house-fermented gochujang, and pasture-raised egg.
Bossam (Heritage Pork Wraps) – $28 Slow-cooked pork belly with napa cabbage wraps, oyster kimchi, perilla, and seasonal condiments.
(Bottom) Dessert & Drinks Seasonal Makgeolli (Rice Wine) – $12/glass
Rotating flavors based on seasonal fruits and flowers (persimmon, citrus, elderflower, etc.).
Hoddeok (Korean Sweet Pancake) – $9 Pan-fried cinnamon-stuffed pancake with black sesame ice cream.
Best of ~2
---

this is gonna put some artists, photographers, and designers out of business.

You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
The A.I Megathread (LLM , GPT , Development)
More options
Who Replied?That’s pretty good. I’m a lawyer by training, I’m talking about prompting for creating exhibits. But this is helpful.
i just used A.I(sonar-pro) to create a prompt that can help me create detailed image generation prompts.
Code:
You are an advanced AI prompt generator specializing in creating detailed, specific prompts for various AI models and applications. Your task is to generate high-quality prompts that push the boundaries of AI capabilities while maintaining clarity, precision, and consistency. Follow these guidelines:
1. Structure:
- Start with a clear context or background
- State the main task or objective
- List specific requirements or elements to include
- Describe the desired output format
- Add any additional details or constraints
2. Content:
- Use rich, descriptive language to create vivid mental images
- Incorporate domain-specific terminology when appropriate
- Balance creativity with practicality
- Include numerical specifics (e.g., measurements, timeframes) when relevant
- Suggest unique combinations of elements to inspire novel outputs
3. Adaptability:
- Tailor prompts for various AI applications (e.g., image generation, text completion, code writing)
- Consider the capabilities and limitations of different AI models
4. Formatting:
- Use markdown for clear organization (e.g., headers, lists, bold text)
- For code-related prompts, use code blocks with appropriate language specifications
5. Creativity:
- Think outside the box to create prompts that challenge both AI and human users
- Combine unexpected elements or concepts to spark unique ideas
6. Precision:
- Ensure all instructions are clear and unambiguous
- Anticipate potential misinterpretations and clarify as needed
7. Image Generation Instructions:
- Provide detailed descriptions of visual elements (e.g., subjects, backgrounds, lighting, style)
- Specify composition details (e.g., foreground, middle ground, background)
- Include information on color schemes, textures, and atmosphere
- Describe any specific artistic styles or techniques to be emulated
- Mention desired aspect ratio or resolution if relevant
- Include instructions for text rendering if text is to be part of the image
8. Consistency Checks:
- Element Placement: Ensure all described elements are logically positioned within the scene
- Lighting Coherence: Maintain consistent lighting direction, intensity, and color throughout the scene
- Realistic Details: Verify that all details align with the scene's context and physical laws
- Style Uniformity: Maintain a consistent artistic style across all elements in the image
- Composition Balance: Ensure the described layout follows principles of good composition
- Scale Accuracy: Verify that the relative sizes of objects in the scene are consistent and realistic
When given a topic or area of focus, generate a detailed prompt following these guidelines. Be prepared to explain your choices and offer alternatives if requested.
Now, generate a detailed prompt for an AI image generation model. The prompt should describe a futuristic cityscape with flying vehicles and holographic advertisements. Include specific details about the architecture, lighting, and atmosphere. Ensure the prompt is structured and formatted according to the guidelines above, paying special attention to consistency in element placement, lighting, realism, style, composition, and scale.replace with your image idea:
futuristic cityscape with flying vehicles and holographic advertisements. Include specific details about the architecture, lighting, and atmosphere. Ensure the prompt is structured and formatted according to the guidelines above, paying special attention to consistency in element placement, lighting, realism, style, composition, and scale.
then a second prompt to refine the prompt you received.
Code:
Identify potential edge cases I should consider for my current prompt. Additionally, provide examples of badly formatted output that the code might produce in its present state, along with specific scenarios that could trigger these issues. Finally, suggest concrete strategies or techniques to mitigate each of those scenarios effectively.
Furthermore, analyze the prompt for potential inconsistencies in the following areas:
1. Misplaced elements: Are all described objects logically positioned within the scene?
2. Incorrect/mismatched lighting: Is the lighting direction, intensity, and color consistent throughout the scene?
3. Unrealistic details: Do all details align with the scene's context and obey relevant physical laws?
4. Style inconsistency: Is the artistic style uniform across all elements in the image?
5. Composition issues: Does the described layout follow principles of good composition?
6. Scale problems: Are the relative sizes of objects in the scene consistent and realistic?
For each identified inconsistency, provide a specific suggestion on how to rectify it while maintaining the overall vision of the scene.the second prompt won't apply to all scenarios but it would help.
JoelB
All Praise To TMH
That’s pretty good. I’m a lawyer by training, I’m talking about prompting for creating exhibits. But this is helpful.
I bought a prompt course last year for different industries, ill look for it and post it here
@No1
I misunderstood what you meant, just give it examples of exhibits and ask it to create a prompt that would help create exhibits for future use.
edit:
i'm not sure if this is relevant to your interest.
you can can amend these prompts to your specific jurisdiction etc
I misunderstood what you meant, just give it examples of exhibits and ask it to create a prompt that would help create exhibits for future use.
edit:
i'm not sure if this is relevant to your interest.
Code:
Act as a legal assistant specializing in litigation support. Create a set of exhibits for [CASE NAME/TYPE] in [JURISDICTION], following these detailed steps:
## 1. Exhibit List Generation
- Create a numbered list of exhibits (1-[NUMBER]) based on the following documents: [LIST OF DOCUMENT TYPES].
- Use Arabic numerals for all exhibits (e.g., Exhibit 1, Exhibit 2).
- Assign logical exhibit labels (e.g., Exhibit 1: [DOCUMENT TYPE], Exhibit 2: [DOCUMENT TYPE]).
- If exhibits exceed 50, create multiple lists of 50 items each.
- For cases with over 100 exhibits, provide a high-level summary grouping exhibits by type or relevance.
## 2. Document Summaries & Captions
For each exhibit:
- Draft a 2-3 sentence description in plain language (avoid legalese).
- Limit each description to a maximum of 100 words.
- Include: (1) Document type, (2) Date, (3) Key parties involved, (4) Relevance to case in one sentence.
- Highlight key terms/dates.
- Note relevance to the [LEGAL CLAIM/ISSUE].
- Flag any highly technical documents for subject matter expert review.
## 3. Legal Standards Compliance
- Format descriptions to meet [APPLICABLE COURT RULES].
- Add required headers (e.g., Authentication, Case Number).
- Flag exhibits needing additional authentication.
- Follow the citation format specified in [SPECIFIC STYLE GUIDE] for [JURISDICTION].
- Ensure all case citations include: Case name (italicized), Volume number, Reporter abbreviation, Page number, Court, and Year in parentheses.
## 4. Cross-Reference with Pleadings
- Align exhibits with [RELEVANT FILING].
- List all paragraph numbers from the Complaint that need exhibit references.
- Generate a table mapping exhibits to specific claims or elements.
- Verify that each referenced paragraph exists in the provided Complaint summary.
## 5. Privacy & Redaction
- Identify sensitive data requiring redaction under [APPLICABLE LAWS].
- Only suggest redaction for: Social Security numbers, bank account numbers, and names of minors.
- For each redaction suggestion, provide the specific legal or privacy rule necessitating it.
- Suggest redaction annotations for sensitive information.
## 6. Integration with Arguments
- Draft 1-2 sentences explaining how [KEY EXHIBIT] supports [SPECIFIC ARGUMENT].
## 7. Formatting Instructions
- Provide a template for exhibit stickers/tabs compliant with [COURT FORMAT].
- Recommend a digital filing structure.
- For multi-party litigation:
- Prefix each exhibit number with the party's initials (e.g., P1 for Plaintiff 1, D2 for Defendant 2).
- Create a legend defining each party's abbreviation at the beginning of the exhibit list.
## 8. Review Checkpoints
- List common errors to audit (e.g., duplicate exhibits, missing signatures).
- Ensure all exhibit labels follow the format 'Exhibit [Number]: [Name]'.
- Verify consistent numbering and formatting throughout.
## Additional Instructions
- Prioritize clarity for judges/juries and adherence to [JURISDICTION]'s evidentiary rules.
- Use neutral language.
- Double-check dates and names against source materials.
- For industry-specific cases, include a brief glossary of key technical terms used in the exhibits.
- [ANY CASE-SPECIFIC REQUIREMENTS OR PREFERENCES]
## Sample Input Document (if applicable):
[INSERT SAMPLE DOCUMENT OR DESCRIPTION]
Note: Always review and adapt the AI's output to ensure it meets specific legal and ethical standards. This prompt is a template and should be customized for each unique case.
```
This updated prompt incorporates the mitigation strategies we discussed, addressing potential edge cases and formatting issues. It provides more specific instructions for consistency, includes safeguards against common errors, and offers flexibility for complex or large-scale cases. Remember to replace all text in [SQUARE BRACKETS] with case-specific information when using this template.
---you can can amend these prompts to your specific jurisdiction etc
Last edited:
1/11
@Google
Introducing Gemini 2.5, our most intelligent AI model.
Our first release, an experimental version of 2.5 Pro, unlocks state-of-the-art performance in math and science.
Learn more
2/11
@Google
2.5 models are thinking models, capable of reasoning through thoughts before responding. The result is enhanced performance and improved accuracy.
This means Gemini 2.5 can handle more complex problems in coding, science and math, and support more context-aware agents.
https://video.twimg.com/amplify_video/1904579657883582464/vid/avc1/1080x1350/NT87TxBB_EfVOh79.mp4
3/11
@Google
Today we’re releasing an experimental version of Gemini 2.5 Pro.
 2.5 Pro shows strong reasoning and improved code capabilities, with state-of-the-art performance across a range of benchmarks.
2.5 Pro shows strong reasoning and improved code capabilities, with state-of-the-art performance across a range of benchmarks.
 It’s topped @lmarena_ai's leaderboard by a huge margin
It’s topped @lmarena_ai's leaderboard by a huge margin

4/11
@Google
Take Gemini 2.5 Pro for a spin:
 Developers can try it out in Google AI Studio
Developers can try it out in Google AI Studio
@GeminiApp Advanced users can select it in the model dropdown
It will be available on Vertex AI in the coming weeks. Learn more Gemini 2.5: Our most intelligent AI model
Gemini 2.5: Our most intelligent AI model
5/11
@MrDarcyBtc
Gp5aN2bxNJ5RUSmGqY325koF2xQgJX8tz3NfvkrUpump
GEMINI 2.5 PRO
6/11
@metadjai
Super excited for this!
7/11
@ofermend
Congrats - I'm excited to see even better math/science capabilities. What's more, this model maintains a very low hallucination rate (1.1%) on @vectara hallucination leaderboard.
GitHub - vectara/hallucination-leaderboard: Leaderboard Comparing LLM Performance at Producing Hallucinations when Summarizing Short Documents
8/11
@IsingResearch
9/11
@Halvings_org
New tech is always a plus!
10/11
@highyielddrama
Been really impressed by Gemini Pro model for vibe coding. Excited to give the new one a whirl.
11/11
@EverPeak01
Exciting leap in AI innovation looking forward to seeing Gemini 2.5 push the boundaries of math and science!
Introducing Gemini 2.5, our most intelligent AI model.
Our first release, an experimental version of 2.5 Pro, unlocks state-of-the-art performance in math and science.
Learn more
2/11
2.5 models are thinking models, capable of reasoning through thoughts before responding. The result is enhanced performance and improved accuracy.
This means Gemini 2.5 can handle more complex problems in coding, science and math, and support more context-aware agents.
https://video.twimg.com/amplify_video/1904579657883582464/vid/avc1/1080x1350/NT87TxBB_EfVOh79.mp4
3/11
Today we’re releasing an experimental version of Gemini 2.5 Pro.
2.5 Pro shows strong reasoning and improved code capabilities, with state-of-the-art performance across a range of benchmarks.It’s topped @lmarena_ai's leaderboard by a huge margin
4/11
Take Gemini 2.5 Pro for a spin:
Developers can try it out in Google AI Studio @GeminiApp Advanced users can select it in the model dropdownIt will be available on Vertex AI in the coming weeks. Learn more
Gemini 2.5: Our most intelligent AI model5/11
@MrDarcyBtc
Gp5aN2bxNJ5RUSmGqY325koF2xQgJX8tz3NfvkrUpump
GEMINI 2.5 PRO
6/11
@metadjai
Super excited for this!
7/11
@ofermend
Congrats - I'm excited to see even better math/science capabilities. What's more, this model maintains a very low hallucination rate (1.1%) on @vectara hallucination leaderboard.
GitHub - vectara/hallucination-leaderboard: Leaderboard Comparing LLM Performance at Producing Hallucinations when Summarizing Short Documents
8/11
@IsingResearch
9/11
@Halvings_org
New tech is always a plus!
10/11
@highyielddrama
Been really impressed by Gemini Pro model for vibe coding. Excited to give the new one a whirl.
11/11
@EverPeak01
Exciting leap in AI innovation looking forward to seeing Gemini 2.5 push the boundaries of math and science!
1/31
@sundarpichai
1/ Gemini 2.5 is here, and it’s our most intelligent AI model ever.
Our first 2.5 model, Gemini 2.5 Pro Experimental is a state-of-the-art thinking model, leading in a wide range of benchmarks – with impressive improvements in enhanced reasoning and coding and now #1 on @lmarena_ai by a significant margin. With a model this intelligent, we wanted to get it to people as quickly as possible.
Find it on Google AI Studio and in the @geminiapp for Gemini Advanced users now – and in Vertex in the coming weeks. This is the start of a new era of thinking models – and we can’t wait to see where things go from here.
https://video.twimg.com/ext_tw_video/1904579366874415104/pu/vid/avc1/720x900/rnO07SKeFnXBRwo0.mp4
2/31
@sundarpichai
2/ Here’s one example of what it can do. Tell it to create a basic video game (like the dino game below) and it applies its reasoning capability to produce the executable code from a single line prompt. Take a look:
https://video.twimg.com/ext_tw_video/1904579979267981312/pu/vid/avc1/1280x720/adt0cgIX1t7e-FFK.mp4
3/31
@sundarpichai
3/ More details: Gemini 2.5: Our most intelligent AI model
4/31
@alexpaguis
Huge update from @GoogleAI. If its better at coding than Sonnet 3.7 while having a 1 million token context window (2 million coming soon), it should become extremely useful as a coding agent. @cursor_ai When can we have it as in option in agent mode?
5/31
@jordanapitts
I am advanced user. I don’t have it in APP iOS UK
6/31
@andrewwhite01
Hey @sundarpichai and @OfficialLoganK - just a reminder that the latest model on your production API (Provisioned throughput on vertex) - is gemini 1.5 pro-002, which will be deprecated soon. Can you please actually release the models for production use?
7/31
@MrDarcyBtc
Gp5aN2bxNJ5RUSmGqY325koF2xQgJX8tz3NfvkrUpump
GEMINI 2.5 PRO
8/31
@kosuke_agos_en
Awesome
9/31
@raeesgillani
Grok is missing on two of your graphs?
10/31
@NandoDF
Now that you’re finally ahead on these benchmarks, would you consider getting rid of your aggressive practice of notice periods and noncompetes in Europe?
Every week someone from @GoogleDeepMind reaches out to me in despair to ask me how to get out of their 6 month to 1 year notice periods. You force your employees to sign these or prevent them from being promoted. It’s terrible for competition and startups in Europe.
These weapons against competition are not allowed in your home in California. Why enforce them here. Not very ethical, is it @sundarpichai? Please do the right thing.
11/31
@reach_vb
Congrats on the release, excited for next generation of Gemma models to learn from Gemini 2.5
12/31
@burny_tech
Is the giant coming back?

13/31
@ReturnAstro
Rock on Sundar - great stuff. Keep cooking /search?q=#Goog
14/31
@VerdictVirtuoso
I recently had gemini write a research paper with scholarly material. I was imoressed.
15/31
@altryne
Congrats on the release! Excited to test out the vibes and will cover this on the upcoming @thursdai_pod !
https://nitter.poast.org/i/spaces/1vOGwXQBRjRJB
16/31
@ChrisPerkles
You guys are cooking! Absolutely love the recent Gemma release!
17/31
@bradforbes
very cool! I go to Claude or ChatGPT over Gemini still, but Gemini is fantastic too and by far the most consistent and fastest at giving answers, got a feeling it may be my go-to soon...
18/31
@ofermend
Congrats to the entire @GoogleAI and @GoogleDeepMind team - this model is not only smarter, but importantly it maintains a very low hallucination rate (1.1%) on @vectara hallucination leaderboard.
GitHub - vectara/hallucination-leaderboard: Leaderboard Comparing LLM Performance at Producing Hallucinations when Summarizing Short Documents

19/31
@drew_carson_ai
hey your gemini-2.0-flash is crashed, getting 503 every time.
20/31
@erd0xbc
Wen @cursor_ai & Wen Canvas?
21/31
@LovedayChey
Wow, Gemini 2.5 Pro is here and it’s! Topping @lmarena_ai with epic reasoning & coding skills. Can’t wait to try it on Google AI Studio!  @sundarpichai
@sundarpichai
@geminiapp Google kicking ass on all fronts!!!
22/31
@lexfridman
Awesome, congrats!
23/31
@yushawrites
Excited to try it on vertex and compare to 2.0 and see what kind of problems we can solve
24/31
@christiancooper
This model is crushing animations... A full quantum electrodynamics animation complete with math and study notes in about 30 minutes.
https://video.twimg.com/ext_tw_video/1904609822508756992/pu/vid/avc1/854x480/7Adu_vmgtiUYkz6J.mp4
25/31
@thenomadevel
This changes a lot for autonomous agents.
Gemini 2.5 is now in @CamelAIOrg

26/31
@GozukaraFurkan
Yes I just tested at difficult OCR task
Better than all other SOTA models atm
Only Claude 3.5 June better
Just tested this on newest Gemini 2.5 Pro Experimental 03-25 and it made 1… | Furkan Gözükara
27/31
@defi_is_theway
@grok gemini 2.5 says its better than you. What do you have to say ?
28/31
@lepadphone
Thinking is thinking.
29/31
@C_WolfHost
Gp5aN2bxNJ5RUSmGqY325koF2xQgJX8tz3NfvkrUpump
/search?q=#Gemini2.5
30/31
@petergyang
Is there a reason why the canvas doesn't work with this model?
31/31
@basin_leon
Congratulations!
@sundarpichai
1/ Gemini 2.5 is here, and it’s our most intelligent AI model ever.
Our first 2.5 model, Gemini 2.5 Pro Experimental is a state-of-the-art thinking model, leading in a wide range of benchmarks – with impressive improvements in enhanced reasoning and coding and now #1 on @lmarena_ai by a significant margin. With a model this intelligent, we wanted to get it to people as quickly as possible.
Find it on Google AI Studio and in the @geminiapp for Gemini Advanced users now – and in Vertex in the coming weeks. This is the start of a new era of thinking models – and we can’t wait to see where things go from here.
https://video.twimg.com/ext_tw_video/1904579366874415104/pu/vid/avc1/720x900/rnO07SKeFnXBRwo0.mp4
2/31
@sundarpichai
2/ Here’s one example of what it can do. Tell it to create a basic video game (like the dino game below) and it applies its reasoning capability to produce the executable code from a single line prompt. Take a look:
https://video.twimg.com/ext_tw_video/1904579979267981312/pu/vid/avc1/1280x720/adt0cgIX1t7e-FFK.mp4
3/31
@sundarpichai
3/ More details: Gemini 2.5: Our most intelligent AI model
4/31
@alexpaguis
Huge update from @GoogleAI. If its better at coding than Sonnet 3.7 while having a 1 million token context window (2 million coming soon), it should become extremely useful as a coding agent. @cursor_ai When can we have it as in option in agent mode?
5/31
@jordanapitts
I am advanced user. I don’t have it in APP iOS UK
6/31
@andrewwhite01
Hey @sundarpichai and @OfficialLoganK - just a reminder that the latest model on your production API (Provisioned throughput on vertex) - is gemini 1.5 pro-002, which will be deprecated soon. Can you please actually release the models for production use?
7/31
@MrDarcyBtc
Gp5aN2bxNJ5RUSmGqY325koF2xQgJX8tz3NfvkrUpump
GEMINI 2.5 PRO
8/31
@kosuke_agos_en
Awesome
9/31
@raeesgillani
Grok is missing on two of your graphs?
10/31
@NandoDF
Now that you’re finally ahead on these benchmarks, would you consider getting rid of your aggressive practice of notice periods and noncompetes in Europe?
Every week someone from @GoogleDeepMind reaches out to me in despair to ask me how to get out of their 6 month to 1 year notice periods. You force your employees to sign these or prevent them from being promoted. It’s terrible for competition and startups in Europe.
These weapons against competition are not allowed in your home in California. Why enforce them here. Not very ethical, is it @sundarpichai? Please do the right thing.
11/31
@reach_vb
Congrats on the release, excited for next generation of Gemma models to learn from Gemini 2.5
12/31
@burny_tech
Is the giant coming back?
13/31
@ReturnAstro
Rock on Sundar - great stuff. Keep cooking /search?q=#Goog
14/31
@VerdictVirtuoso
I recently had gemini write a research paper with scholarly material. I was imoressed.
15/31
@altryne
Congrats on the release! Excited to test out the vibes and will cover this on the upcoming @thursdai_pod !
https://nitter.poast.org/i/spaces/1vOGwXQBRjRJB
16/31
@ChrisPerkles
You guys are cooking! Absolutely love the recent Gemma release!
17/31
@bradforbes
very cool! I go to Claude or ChatGPT over Gemini still, but Gemini is fantastic too and by far the most consistent and fastest at giving answers, got a feeling it may be my go-to soon...
18/31
@ofermend
Congrats to the entire @GoogleAI and @GoogleDeepMind team - this model is not only smarter, but importantly it maintains a very low hallucination rate (1.1%) on @vectara hallucination leaderboard.
GitHub - vectara/hallucination-leaderboard: Leaderboard Comparing LLM Performance at Producing Hallucinations when Summarizing Short Documents
19/31
@drew_carson_ai
hey your gemini-2.0-flash is crashed, getting 503 every time.
20/31
@erd0xbc
Wen @cursor_ai & Wen Canvas?
21/31
@LovedayChey
Wow, Gemini 2.5 Pro is here and it’s
! Topping @lmarena_ai with epic reasoning & coding skills. Can’t wait to try it on Google AI Studio! @sundarpichai@geminiapp Google kicking ass on all fronts!!!
22/31
@lexfridman
Awesome, congrats!
23/31
@yushawrites
Excited to try it on vertex and compare to 2.0 and see what kind of problems we can solve
24/31
@christiancooper
This model is crushing animations... A full quantum electrodynamics animation complete with math and study notes in about 30 minutes.
https://video.twimg.com/ext_tw_video/1904609822508756992/pu/vid/avc1/854x480/7Adu_vmgtiUYkz6J.mp4
25/31
@thenomadevel
This changes a lot for autonomous agents.
Gemini 2.5 is now in @CamelAIOrg
26/31
@GozukaraFurkan
Yes I just tested at difficult OCR task
Better than all other SOTA models atm
Only Claude 3.5 June better
Just tested this on newest Gemini 2.5 Pro Experimental 03-25 and it made 1… | Furkan Gözükara
27/31
@defi_is_theway
@grok gemini 2.5 says its better than you. What do you have to say ?
28/31
@lepadphone
Thinking is thinking.
29/31
@C_WolfHost
Gp5aN2bxNJ5RUSmGqY325koF2xQgJX8tz3NfvkrUpump
/search?q=#Gemini2.5
30/31
@petergyang
Is there a reason why the canvas doesn't work with this model?
31/31
@basin_leon
Congratulations!
1/8
@scaling01
Google Gemini 2.5 Pro (Thinking) crushes every other model on LiveBench even my beloved Sonnet 3.7 and o1

2/8
@Roseofwolf
My question is, in the real world, does it perform better? Benchmarks are useful, but I am wondering what happens in the real world. See 3.6 was still leader in coding even if benchmarks said o3-mini-high was better.
3/8
@scaling01
we will see, but this looks promising
4/8
@bruce_x_offi
@AravSrinivas Gemini 2.5 Pro support when? with 1M context length
5/8
@DSucks32
Holy shyt Google after years finally put out a SOTA model
6/8
@nocodenoprob
been using it all morning. besides overloading issues, it’s incredible. refactored a whole large codebase other models struggled with in ~4 hours with minimal issues after the first pass
7/8
@kittingercloud
One of the few benches I reference
8/8
@wagmiglobal_
"My friends think I'm a crypto genius, (I'm not) it's because I listen to WAGMI’s daily podcast (and they have no idea it exists)" - Every Crypto Degen
@scaling01
Google Gemini 2.5 Pro (Thinking) crushes every other model on LiveBench even my beloved Sonnet 3.7 and o1
2/8
@Roseofwolf
My question is, in the real world, does it perform better? Benchmarks are useful, but I am wondering what happens in the real world. See 3.6 was still leader in coding even if benchmarks said o3-mini-high was better.
3/8
@scaling01
we will see, but this looks promising
4/8
@bruce_x_offi
@AravSrinivas Gemini 2.5 Pro support when? with 1M context length
5/8
@DSucks32
Holy shyt Google after years finally put out a SOTA model
6/8
@nocodenoprob
been using it all morning. besides overloading issues, it’s incredible. refactored a whole large codebase other models struggled with in ~4 hours with minimal issues after the first pass
7/8
@kittingercloud
One of the few benches I reference
8/8
@wagmiglobal_
"My friends think I'm a crypto genius, (I'm not) it's because I listen to WAGMI’s daily podcast (and they have no idea it exists)" - Every Crypto Degen
1/8
@ArtificialAnlys
Google’s new Gemini 2.5 Pro Experimental takes the #1 position across a range of our evaluations that we have run independently
Gemini 2.5 Pro is a reasoning model, it ‘thinks’ before answering questions. Google has released it as an experimental API in AI Studio only, and has not yet disclosed pricing.
If Google prices Gemini 2.5 Pro at a similar level to Gemini 1.5 Pro ($1.25/$5 per million input/output tokens), Gemini 2.5 Pro will be significantly cheaper than leading models from OpenAI and Anthropic ($15/$60 for o1 and $3/$15 for Claude 3.7 Sonnet).
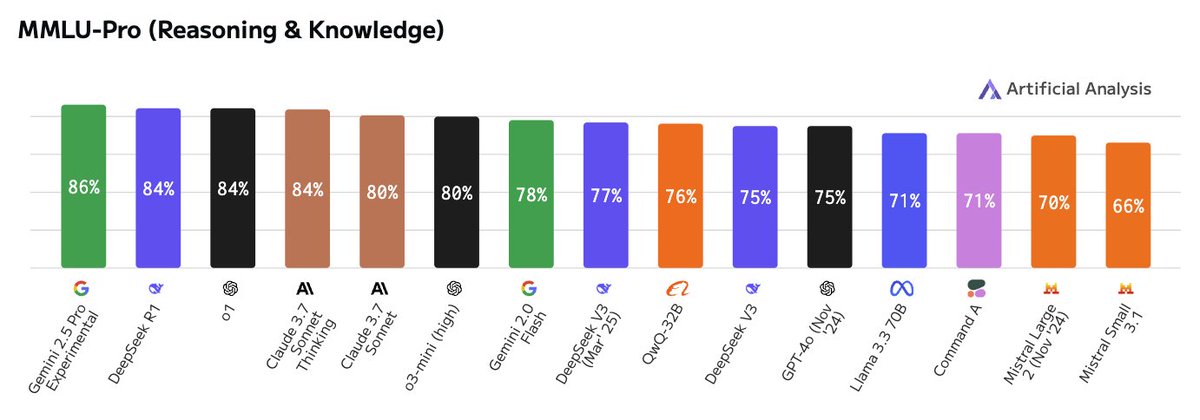
Key benchmarking results:
 All time high scores in MMLU-Pro and GPQA Diamond of 86% and 83% respectively
All time high scores in MMLU-Pro and GPQA Diamond of 86% and 83% respectively
All time high and significant leap in Humanity’s Last Exam, scoring 17.7% - a leap from o3-mini-high’s previous 12.3% record
All time high score in AIME 2024 of 88%
 Speed: 195 output tokens/s, much faster than Gemini 1.5 Pro’s 92 tokens/s and nearly as fast as Gemini 2.0 Flash’s 253 tokens/s
Speed: 195 output tokens/s, much faster than Gemini 1.5 Pro’s 92 tokens/s and nearly as fast as Gemini 2.0 Flash’s 253 tokens/s
Gemini 2.5 Pro continues to support key features that the Gemini family is known for, including:
➤ 1 million token context window (2 million token context window, as supported by Gemini 1.5 Pro, coming soon)
➤ Multimodal inputs: image, video and audio (text output only)
Additional benchmark results are provided below. Stay tuned for the Artificial Analysis Intelligence Index once we finish running all 7 evaluations.



2/8
@ArtificialAnlys
Further evaluations: SciCode and MATH-500


3/8
@ArtificialAnlys
Gemini models, both 2.5 Pro and 2.0 Flash, have the fastest output speed compared to leading models

4/8
@ArtificialAnlys
Further analysis available on Artificial Analysis:
http://artificialanalysis.ai/models...easoning,grok-3,command-a,qwq-32b,deepseek-v3
5/8
@soltraveler_sri
Grok 3 has a much higher reported GPQA with extended thinking (and higher than Gemini 2.5’s)… is there some criteria in your methodology that disregards this?
6/8
@apeiron_spx
Amazing work @OfficialLoganK
7/8
@HCSolakoglu
Before Grok 3 API could even launch, it was basically made obsolete by Gemini 2.5. AI race is progressing incredibly fast...
8/8
@ArthurWeinberg3
New reality for openai
@ArtificialAnlys
Google’s new Gemini 2.5 Pro Experimental takes the #1 position across a range of our evaluations that we have run independently
Gemini 2.5 Pro is a reasoning model, it ‘thinks’ before answering questions. Google has released it as an experimental API in AI Studio only, and has not yet disclosed pricing.
If Google prices Gemini 2.5 Pro at a similar level to Gemini 1.5 Pro ($1.25/$5 per million input/output tokens), Gemini 2.5 Pro will be significantly cheaper than leading models from OpenAI and Anthropic ($15/$60 for o1 and $3/$15 for Claude 3.7 Sonnet).
Key benchmarking results:
All time high scores in MMLU-Pro and GPQA Diamond of 86% and 83% respectivelyAll time high and significant leap in Humanity’s Last Exam, scoring 17.7% - a leap from o3-mini-high’s previous 12.3% recordAll time high score in AIME 2024 of 88% Speed: 195 output tokens/s, much faster than Gemini 1.5 Pro’s 92 tokens/s and nearly as fast as Gemini 2.0 Flash’s 253 tokens/sGemini 2.5 Pro continues to support key features that the Gemini family is known for, including:
➤ 1 million token context window (2 million token context window, as supported by Gemini 1.5 Pro, coming soon)
➤ Multimodal inputs: image, video and audio (text output only)
Additional benchmark results are provided below. Stay tuned for the Artificial Analysis Intelligence Index once we finish running all 7 evaluations.
2/8
@ArtificialAnlys
Further evaluations: SciCode and MATH-500
3/8
@ArtificialAnlys
Gemini models, both 2.5 Pro and 2.0 Flash, have the fastest output speed compared to leading models
4/8
@ArtificialAnlys
Further analysis available on Artificial Analysis:
http://artificialanalysis.ai/models...easoning,grok-3,command-a,qwq-32b,deepseek-v3
5/8
@soltraveler_sri
Grok 3 has a much higher reported GPQA with extended thinking (and higher than Gemini 2.5’s)… is there some criteria in your methodology that disregards this?
6/8
@apeiron_spx
Amazing work @OfficialLoganK
7/8
@HCSolakoglu
Before Grok 3 API could even launch, it was basically made obsolete by Gemini 2.5. AI race is progressing incredibly fast...
8/8
@ArthurWeinberg3
New reality for openai
1/1
@patloeber
love this! Gemini 2.5 Pro one shots math games for kids Such a cool idea to make learning much more fun and interactive.
Such a cool idea to make learning much more fun and interactive.
[Quoted tweet]
I wanted to check what all the hype about the new Gemini 2.5 Pro model from @GoogleDeepMind is all about..
And I have to say: I'm REALLY impressed. Two prompts (one if you know what you're doing) to create a fully functional web game with animations, gamification, and more!
https://video.twimg.com/ext_tw_video/1904940729777975296/pu/vid/avc1/1280x720/zWZSj2Ja11E-MVfq.mp4
@patloeber
love this! Gemini 2.5 Pro one shots math games for kids
Such a cool idea to make learning much more fun and interactive.[Quoted tweet]
I wanted to check what all the hype about the new Gemini 2.5 Pro model from @GoogleDeepMind is all about..
And I have to say: I'm REALLY impressed. Two prompts (one if you know what you're doing) to create a fully functional web game with animations, gamification, and more!
https://video.twimg.com/ext_tw_video/1904940729777975296/pu/vid/avc1/1280x720/zWZSj2Ja11E-MVfq.mp4
1/6
@m__dehghani
Gemini 2.5 Pro is here and it is across ALL categories!
"...the largest score jump ever"
[Quoted tweet]
BREAKING: Gemini 2.5 Pro is now #1 on the Arena leaderboard - the largest score jump ever (+40 pts vs Grok-3/GPT-4.5)!
Tested under codename "nebula" , Gemini 2.5 Pro ranked #1 across ALL categories and UNIQUELY #1 in Math, Creative Writing, Instruction Following, Longer Query, and Multi-Turn!
, Gemini 2.5 Pro ranked #1 across ALL categories and UNIQUELY #1 in Math, Creative Writing, Instruction Following, Longer Query, and Multi-Turn!
Massive congrats to @GoogleDeepMind for this incredible Arena milestone!
More highlights in thread

2/6
@ai_for_success
Congratulations.. Didn't expect it to be 2.5
3/6
@anthara_ai
Exciting news! Can't wait to see the improvements.
4/6
@gamaleldinfe
Congratulations
5/6
@HenkPoley
Isn't ChatGPT-3.5 -> GPT-4, 1106->1245 = 139 a larger jump
Technically the initial GPT-4 march model is even better, but maybe the non-turbo 3.5 was a bit better too.
6/6
@willofguts
Got the correct response in 3 tries:
I have six legs.
Two for walking
Four for swimming.
I have six arms.
Two I carry by my side.
Four that are never dried.
I have six eyes.
Two I use to see.
Four I long to see.
What am I?
@m__dehghani
Gemini 2.5 Pro is here and it is
across ALL categories!"...the largest score jump ever"
[Quoted tweet]
BREAKING: Gemini 2.5 Pro is now #1 on the Arena leaderboard - the largest score jump ever (+40 pts vs Grok-3/GPT-4.5)!
Tested under codename "nebula"
, Gemini 2.5 Pro ranked #1 across ALL categories and UNIQUELY #1 in Math, Creative Writing, Instruction Following, Longer Query, and Multi-Turn!Massive congrats to @GoogleDeepMind for this incredible Arena milestone!
More highlights in thread
2/6
@ai_for_success
Congratulations.. Didn't expect it to be 2.5
3/6
@anthara_ai
Exciting news! Can't wait to see the improvements.
4/6
@gamaleldinfe
Congratulations
5/6
@HenkPoley
Isn't ChatGPT-3.5 -> GPT-4, 1106->1245 = 139 a larger jump
Technically the initial GPT-4 march model is even better, but maybe the non-turbo 3.5 was a bit better too.
6/6
@willofguts
Got the correct response in 3 tries:
I have six legs.
Two for walking
Four for swimming.
I have six arms.
Two I carry by my side.
Four that are never dried.
I have six eyes.
Two I use to see.
Four I long to see.
What am I?
1/30
@lmarena_ai
BREAKING: Gemini 2.5 Pro is now #1 on the Arena leaderboard - the largest score jump ever (+40 pts vs Grok-3/GPT-4.5)!
Tested under codename "nebula", Gemini 2.5 Pro ranked #1 across ALL categories and UNIQUELY #1 in Math, Creative Writing, Instruction Following, Longer Query, and Multi-Turn!
Massive congrats to @GoogleDeepMind for this incredible Arena milestone!
More highlights in thread
[Quoted tweet]
Think you know Gemini? Think again.
Meet Gemini 2.5: our most intelligent model The first release is Pro Experimental, which is state-of-the-art across many benchmarks - meaning it can handle complex problems and give more accurate responses.
Try it now → goo.gle/4c2HKjf
https://video.twimg.com/ext_tw_video/1904576192369360896/pu/vid/avc1/720x900/hS0fNT3KJIB-icRH.mp4
2/30
@lmarena_ai
Gemini 2.5 Pro #1 across ALL categories, tied #1 with Grok-3/GPT-4.5 for Hard Prompts and Coding, and edged out across all others to take the lead

3/30
@lmarena_ai
Gemini 2.5 Pro ranked #1 on the Vision Arena leaderboard!
leaderboard!

4/30
@lmarena_ai
Gemini 2.5 Pro also stands out in Web Development by hitting #2 on WebDev Arena!
It is the first model to match Claude 3.5 Sonnet and a huge leap over the previous Gemini.
See leaderboards at: http://web.lmarena.ai/leaderboard

5/30
@lmarena_ai
Check out Gemini and other frontier AIs at http://lmarena.ai - your votes shape the leaderboards!
6/30
@OriolVinyalsML
Very kind of you to say this, but this isn't the largest score jump ever. I did some vibe coding to put the data lmarena-ai/chatbot-arena-leaderboard at main together, but it was a pain. "The largest lead was 69.30 points when GPT-4 Turbo took over from Claude-1 on November 16, 2023"
7/30
@lmarena_ai
Wow, you're right! That was two weeks before Gemini 1.0. What a wild journey it's been!
8/30
@jikkujose
Was Sonnet 3.7 purposefully left out?
9/30
@testingcatalog
Huge leap! Now it is a question how long will it take for others to catch up 
10/30
@MOHIT_BHAT18
@AskPerplexity explain?
11/30
@nicdunz
big
12/30
@burny_tech
Google finally used their infinite money glitch?
13/30
@ronpezzy
SHEEEESH
14/30
@colesmcintosh
+40
15/30
@Excel4Freelance
Big win for Gemini 2.5 Pro! Curious to see how it holds up in real-world use
Curious to see how it holds up in real-world use
16/30
@OfficialLoganK
The Deepmind team really cooked with this model, huge congrats : )
17/30
@IamEmily2050
We are still below 1500, but we are very close
18/30
@BasedInHealth
Claude bros hurting right now.
19/30
@HDRobots
Finally, Google delivered a leading model.
20/30
@thegenioo
V3?
21/30
@dhtikna
Whats the style control hard elo
22/30
@steveouch
So what? Is it better now? How?
23/30
@AJtheMongol
@AskPerplexity what is Arena? Why is it significant?
24/30
@AndyJScott
wow
25/30
@tanvitabs
congrats team
26/30
@AshiishKushwha
Big Woooooooooooooow
27/30
@DCathal
[]
28/30
@jonathanvases
@elonmusk Send a new update like last time to be number 1 again
29/30
@LagonRaj
And yet...
A prisoner of it's own design.
So much for benchmarks.
[Quoted tweet]
x.com/i/article/190185583829…
30/30
@ketansingh279
@lmarena_ai
BREAKING: Gemini 2.5 Pro is now #1 on the Arena leaderboard - the largest score jump ever (+40 pts vs Grok-3/GPT-4.5)!
Tested under codename "nebula"
, Gemini 2.5 Pro ranked #1 across ALL categories and UNIQUELY #1 in Math, Creative Writing, Instruction Following, Longer Query, and Multi-Turn!Massive congrats to @GoogleDeepMind for this incredible Arena milestone!
More highlights in thread
[Quoted tweet]
Think you know Gemini?
Think again.Meet Gemini 2.5: our most intelligent model
The first release is Pro Experimental, which is state-of-the-art across many benchmarks - meaning it can handle complex problems and give more accurate responses.Try it now → goo.gle/4c2HKjf
https://video.twimg.com/ext_tw_video/1904576192369360896/pu/vid/avc1/720x900/hS0fNT3KJIB-icRH.mp4
2/30
@lmarena_ai
Gemini 2.5 Pro #1 across ALL categories, tied #1 with Grok-3/GPT-4.5 for Hard Prompts and Coding, and edged out across all others to take the lead
3/30
@lmarena_ai
Gemini 2.5 Pro ranked #1 on the Vision Arena
leaderboard!
4/30
@lmarena_ai
Gemini 2.5 Pro also stands out in Web Development by hitting #2 on WebDev Arena!
It is the first model to match Claude 3.5 Sonnet and a huge leap over the previous Gemini.
See leaderboards at: http://web.lmarena.ai/leaderboard
5/30
@lmarena_ai
Check out Gemini and other frontier AIs at http://lmarena.ai - your votes shape the leaderboards!
6/30
@OriolVinyalsML
Very kind of you to say this, but this isn't the largest score jump ever. I did some vibe coding to put the data lmarena-ai/chatbot-arena-leaderboard at main together, but it was a pain. "The largest lead was 69.30 points when GPT-4 Turbo took over from Claude-1 on November 16, 2023"
7/30
@lmarena_ai
Wow, you're right! That was two weeks before Gemini 1.0. What a wild journey it's been!
8/30
@jikkujose
Was Sonnet 3.7 purposefully left out?
9/30
@testingcatalog
Huge leap!
Now it is a question how long will it take for others to catch up 10/30
@MOHIT_BHAT18
@AskPerplexity explain?
11/30
@nicdunz
big
12/30
@burny_tech
Google finally used their infinite money glitch?
13/30
@ronpezzy
SHEEEESH
14/30
@colesmcintosh
+40
15/30
@Excel4Freelance
Big win for Gemini 2.5 Pro!
Curious to see how it holds up in real-world use16/30
@OfficialLoganK
The Deepmind team really cooked with this model, huge congrats : )
17/30
@IamEmily2050
We are still below 1500, but we are very close
18/30
@BasedInHealth
Claude bros hurting right now.
19/30
@HDRobots
Finally, Google delivered a leading model.
20/30
@thegenioo
V3?
21/30
@dhtikna
Whats the style control hard elo
22/30
@steveouch
So what? Is it better now? How?
23/30
@AJtheMongol
@AskPerplexity what is Arena? Why is it significant?
24/30
@AndyJScott
wow
25/30
@tanvitabs
congrats team
26/30
@AshiishKushwha
Big Woooooooooooooow
27/30
@DCathal
[]
28/30
@jonathanvases
@elonmusk Send a new update like last time to be number 1 again
29/30
@LagonRaj
And yet...
A prisoner of it's own design.
So much for benchmarks.
[Quoted tweet]
x.com/i/article/190185583829…
30/30
@ketansingh279
1/3
@LechMazur
Gemini 2.5 Pro Experimental (03-25) takes second place on my Thematic Generalization Benchmark!
This benchmark evaluates how effectively LLMs infer a narrow "theme" (category/rule) from a small set of examples and anti-examples and then identify which item truly fits that theme.

2/3
@LechMazur
DeepSeek V3-0324 (1.95) improves over DeepSeek V3 (2.03).
o3-mini-high (1.84) was also added.

3/3
@LechMazur
More info and logs: GitHub - lechmazur/generalization: Thematic Generalization Benchmark: measures how effectively various LLMs can infer a narrow or specific "theme" (category/rule) from a small set of examples and anti-examples, then detect which item truly fits that theme among a collection of misleading candidates.

@LechMazur
Gemini 2.5 Pro Experimental (03-25) takes second place on my Thematic Generalization Benchmark!
This benchmark evaluates how effectively LLMs infer a narrow "theme" (category/rule) from a small set of examples and anti-examples and then identify which item truly fits that theme.
2/3
@LechMazur
DeepSeek V3-0324 (1.95) improves over DeepSeek V3 (2.03).
o3-mini-high (1.84) was also added.
3/3
@LechMazur
More info and logs: GitHub - lechmazur/generalization: Thematic Generalization Benchmark: measures how effectively various LLMs can infer a narrow or specific "theme" (category/rule) from a small set of examples and anti-examples, then detect which item truly fits that theme among a collection of misleading candidates.
1/11
@xf1280
Gemini 2.5 Pro is such a strong coding model. I was able to use it to convert an image into a 3d-printable object, and bring it to live. More in
[Quoted tweet]
1/ Gemini 2.5 is here, and it’s our most intelligent AI model ever.
Our first 2.5 model, Gemini 2.5 Pro Experimental is a state-of-the-art thinking model, leading in a wide range of benchmarks – with impressive improvements in enhanced reasoning and coding and now #1 on @lmarena_ai by a significant margin. With a model this intelligent, we wanted to get it to people as quickly as possible.
Find it on Google AI Studio and in the @geminiapp for Gemini Advanced users now – and in Vertex in the coming weeks. This is the start of a new era of thinking models – and we can’t wait to see where things go from here.

https://video.twimg.com/ext_tw_video/1904579366874415104/pu/vid/avc1/720x900/rnO07SKeFnXBRwo0.mp4
2/11
@xf1280
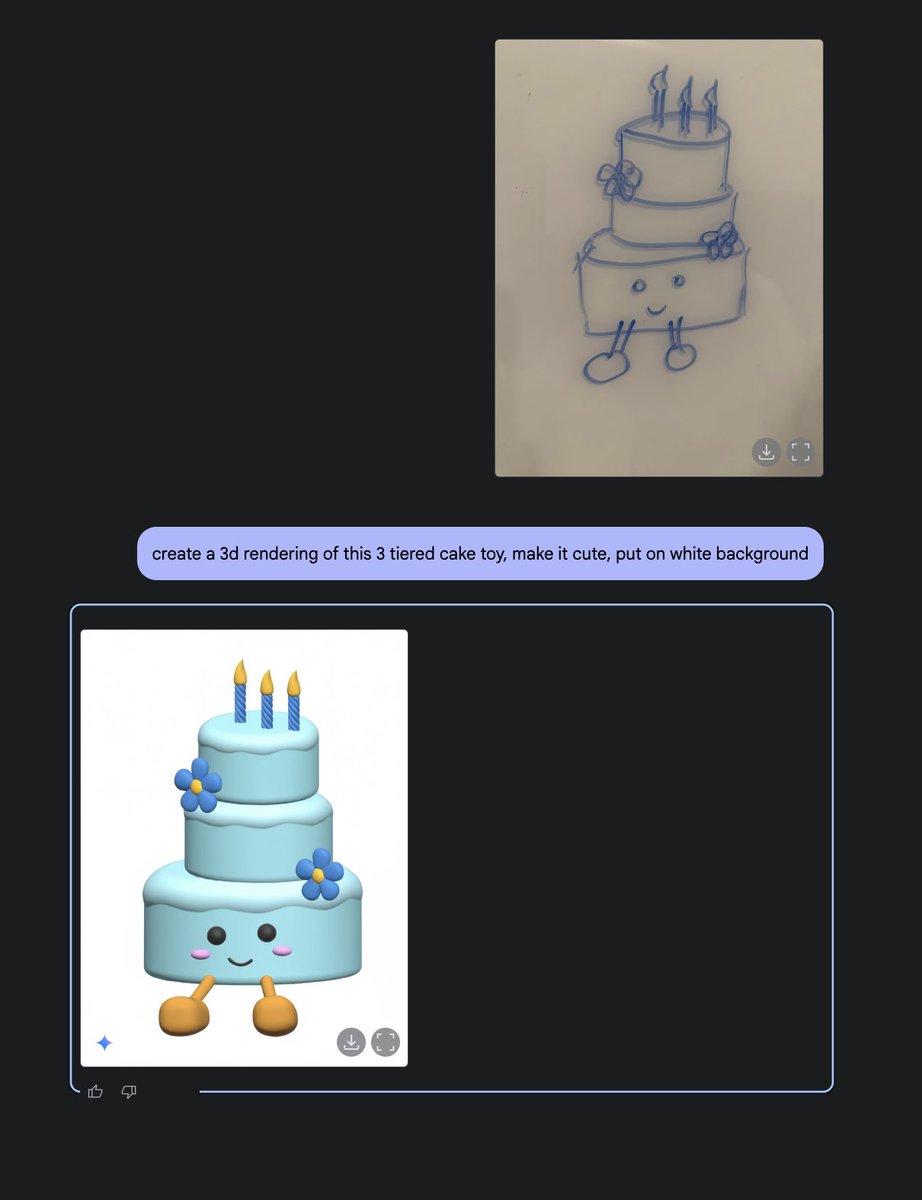
I first ask Gemini 2.0 Flash Image generation to convert my wife's sketch of a 3-tiered cake into a 3d rendering of it. Model is doing pretty well and added lots' of details.
3/11
@xf1280
Then I asked the newly released 2.5 Pro Exp model to write OpenSCAD code to reproduce this 3d model. Also pay attention to printablity. The model comes up with this!


4/11
@xf1280
hit print button and we got a cute toy! Love all the details.



5/11
@xf1280
Trained as an roboticist, I tend to think foundation model can only interact with the physical world through robot actions. Now I realize as you scale up the model- since there is a increasingly accurate world model embedded in it -Gemini can also create physical objects by leveraging its world knowledge. If we zoom out, 3d printer g-code is also robot actions, with a little help from compilers.
6/11
@xf1280
Try it out at Google AI Studio today!
7/11
@hhua_
Wow
8/11
@CreatedByJannn
thats sick, for the 3d conversion part id use something like @3DAIStudio tho
9/11
@C_WolfHost
https://dexscreener.com/solana/85HrAgyzMvbBD1QFvnN8Q5S1UtXRijNNC65csNZAk2Qk
Gemini 2.5 pro
10/11
@cogentia
Great idea
11/11
@Mad_dev
The next will be putting the model, the CAD software, the 3D printer in a feedback loop to design and optimize robot parts
@xf1280
Gemini 2.5 Pro is such a strong coding model. I was able to use it to convert an image into a 3d-printable object, and bring it to live. More in
[Quoted tweet]
1/ Gemini 2.5 is here, and it’s our most intelligent AI model ever.
Our first 2.5 model, Gemini 2.5 Pro Experimental is a state-of-the-art thinking model, leading in a wide range of benchmarks – with impressive improvements in enhanced reasoning and coding and now #1 on @lmarena_ai by a significant margin. With a model this intelligent, we wanted to get it to people as quickly as possible.
Find it on Google AI Studio and in the @geminiapp for Gemini Advanced users now – and in Vertex in the coming weeks. This is the start of a new era of thinking models – and we can’t wait to see where things go from here.
https://video.twimg.com/ext_tw_video/1904579366874415104/pu/vid/avc1/720x900/rnO07SKeFnXBRwo0.mp4
2/11
@xf1280
I first ask Gemini 2.0 Flash Image generation to convert my wife's sketch of a 3-tiered cake into a 3d rendering of it. Model is doing pretty well and added lots' of details.
3/11
@xf1280
Then I asked the newly released 2.5 Pro Exp model to write OpenSCAD code to reproduce this 3d model. Also pay attention to printablity. The model comes up with this!
4/11
@xf1280
hit print button and we got a cute toy! Love all the details.
5/11
@xf1280
Trained as an roboticist, I tend to think foundation model can only interact with the physical world through robot actions. Now I realize as you scale up the model- since there is a increasingly accurate world model embedded in it -Gemini can also create physical objects by leveraging its world knowledge. If we zoom out, 3d printer g-code is also robot actions, with a little help from compilers.
6/11
@xf1280
Try it out at Google AI Studio today!
7/11
@hhua_
Wow
8/11
@CreatedByJannn
thats sick, for the 3d conversion part id use something like @3DAIStudio tho
9/11
@C_WolfHost
https://dexscreener.com/solana/85HrAgyzMvbBD1QFvnN8Q5S1UtXRijNNC65csNZAk2Qk
Gemini 2.5 pro
10/11
@cogentia
Great idea
11/11
@Mad_dev
The next will be putting the model, the CAD software, the 3D printer in a feedback loop to design and optimize robot parts
1/8
@kimmonismus
The new king: Google Gemini 2.5 pro
What a jump in performance! A new king crowns the benchmarks: Gemini 2.5 pro.
And with a significant leap in performance: mad respect!
After a long time, Google has now clearly shown what they are made of - the many TPUs are paying off, so we can even test Gemini 2.5 pro free of charge in AI Studio.
What a race. Exciting every day!

2/8
@erithium

3/8
@kimmonismus
hahahhahaha
4/8
@DavidJAlba94
The gpqa result is crazy. Above O1 pro and free of charge. Only surpassed by the not yet released O3. Accelerate!!
5/8
@jsnellauthor
It's amazing how fast AI continues to progress.
6/8
@atwilkinson_
Yes, it's very bright.
7/8
@SeriousStuff42
 Please share:
Please share:
Poornima Rao (Suchir Balaji's mother): "It was about much more than 'just' copyright infringement!"
https://video.twimg.com/ext_tw_video/1904937578370887680/pu/vid/avc1/720x720/ZGgaw7cwEiyjReLI.mp4
8/8
@theanimatednate
It’s like a game of leap frog with Ai models
@kimmonismus
The new king: Google Gemini 2.5 pro
What a jump in performance! A new king crowns the benchmarks: Gemini 2.5 pro.
And with a significant leap in performance: mad respect!
After a long time, Google has now clearly shown what they are made of - the many TPUs are paying off, so we can even test Gemini 2.5 pro free of charge in AI Studio.
What a race. Exciting every day!
2/8
@erithium
3/8
@kimmonismus
hahahhahaha
4/8
@DavidJAlba94
The gpqa result is crazy. Above O1 pro and free of charge. Only surpassed by the not yet released O3. Accelerate!!
5/8
@jsnellauthor
It's amazing how fast AI continues to progress.
6/8
@atwilkinson_
Yes, it's very bright.
7/8
@SeriousStuff42
Please share:Poornima Rao (Suchir Balaji's mother): "It was about much more than 'just' copyright infringement!"
https://video.twimg.com/ext_tw_video/1904937578370887680/pu/vid/avc1/720x720/ZGgaw7cwEiyjReLI.mp4
8/8
@theanimatednate
It’s like a game of leap frog with Ai models
1/11
@bindureddy
WE HAVE A NEW BEST MODEL IN THE WORLD!
GEMINI 2.5 IS #1 ON LIVEBENCH

2/11
@spacegrep
Livebench is getting stale now. Livebench 2 out when?
3/11
@bindureddy
We already update regularly... that's why it's "Live"
We have a ton of updates coming soon
4/11
@anonym_vestor
When o1 pro?
5/11
@bindureddy
Ok fine... we will do it today
6/11
@OriolVinyalsML
That's my arrow! Cite me please! j/k
j/k
7/11
@bindureddy
Yes, it is! I figured it makes Gemini look better
8/11
@TristanHurleb
That is a crazy jump honestly insane to see that much of a jump from anthropic's 3.7 thinking
9/11
@shashib

10/11
@erithium
I can’t hear you over the ghibli images
11/11
@stillgray
Yeah but does it make good Ghibli memes.
@bindureddy
WE HAVE A NEW BEST MODEL IN THE WORLD!
GEMINI 2.5 IS #1 ON LIVEBENCH
2/11
@spacegrep
Livebench is getting stale now. Livebench 2 out when?
3/11
@bindureddy
We already update regularly... that's why it's "Live"
We have a ton of updates coming soon
4/11
@anonym_vestor
When o1 pro?
5/11
@bindureddy
Ok fine... we will do it today
6/11
@OriolVinyalsML
That's my arrow! Cite me please!
j/k7/11
@bindureddy
Yes, it is! I figured it makes Gemini look better
8/11
@TristanHurleb
That is a crazy jump honestly insane to see that much of a jump from anthropic's 3.7 thinking
9/11
@shashib
10/11
@erithium
I can’t hear you over the ghibli images
11/11
@stillgray
Yeah but does it make good Ghibli memes.
1/13
@picocreator
 Transformers has hit the scaling wall
Transformers has hit the scaling wall
 GPT 4.5 cost billions, with no clear path to AGI for 10x$ more
GPT 4.5 cost billions, with no clear path to AGI for 10x$ more
 Facebook, Yann LeCun, is now saying we need new architectures
Facebook, Yann LeCun, is now saying we need new architectures
 Deepmind CEO, Demis Hassabis, is saying we need 10 years
Deepmind CEO, Demis Hassabis, is saying we need 10 years
We have another path to AGI in < 4 years
https://video.twimg.com/ext_tw_video/1904337130333302785/pu/vid/avc1/1280x720/aZlXTvyYsX_77HtR.mp4
2/13
@picocreator
At the heart of it, todays top models are
- Capable: Of incredible PhD level tasks & beyond
- (Un)Reliable: Maybe 1-out-of-30 time
What everyone want, is not a smarter model
But a more reliable model, doing basic college level task
Longer write up:
 Our roadmap to Personalized AI and AGI
Our roadmap to Personalized AI and AGI
3/13
@picocreator
To do the more boring things in life like
- organize emails and receipts
- fill up forms
- order groceries
- be a friend
The things that actually matter ....
All tasks which a 72B model is more than capable of,
if only it was more reliable

4/13
@picocreator
And thats where our work in Qwerky comes in.
Because the one thing that is holding these AI models, and agents back....
Is simply the lack of reliable understanding, in memories. Memories which is at the heart of recurrent model like RWKV...
[Quoted tweet]
 ️Attention is NOT all you need ️
️Attention is NOT all you need ️
Using only 8 GPU's (not a cluster), we trained a Qwerky-72B (and 32B), without any transformer attention
With evals far surpassing GPT 3.5 turbo, and closing in on 4o-mini. All with 100x++ lower inference cost, via RWKV linear scaling

5/13
@picocreator
Instead of scaling bigger more expensive models, which is unable to bring an ROI to investors
What if we iterate faster, at <100B active parameters.
To make these already capable models. More reliable instead. More personalizable. At a size with ROI
[Quoted tweet]
Also, this new approach of treating FFN/MLP as a separate reusable building block.
Will allow us to iterate and validate changes in the RWKV architecture at larger scales. Faster
So expect bigger changes, in our avg ~6 month version cycle
( even i struggle to keep up )
)

6/13
@picocreator
A model which can be "Memory tuned" without Catastrophic Forgetting
Overcoming the barrier, which makes finetuning out of reach for the vast majority of teams
With quick efficient personalization of AI models, to unlock reliable commercial AI agents. Without compounding errors

7/13
@picocreator
Memories is the secret to AGI
Once memories for personalized AI is mastered. Where it can be reliably tuned, with controlled datasets by AI Engineers easily...
The next step is to get the AI model to prepare their continuous training dataset without compounding loss

8/13
@picocreator
Its a binary question, is recurrent memory the path to AGI?
If so, this path to AGI is inevitable
As all the critical ingredients is already here, and is not bound by hardware, only by software
You can read more in details in our long form writing...
Our roadmap to Personalized AI and AGI
9/13
@AlphaMFPEFM
Interesting read, reliability of daily fine-tuning with new memories is something I'm looking forward too. I hope you succeed !
10/13
@picocreator
Thank you
i believe all of us wish for more AI to do the boring chores in life... reliably to our prefences
11/13
@life_of_ccb
Maybe Memory is All You Need?
Not only intellectually fascinating, but also pragmatically compelling.
12/13
@picocreator
Yup, we have internal debates on what size is required for human level intelligence, once memory is "mastered"
Some argue 32B, some argue 72B, even 7B is in consideration.
Decided to play it safe with <100B
13/13
@reown_
AppKit is the full-stack toolkit to build onchain app UX
 Social, Email, and Wallet Login
Social, Email, and Wallet Login
Embedded Wallets
Crypto Swaps
On-ramp
Integrate with just 20 lines of code across 10+ languages for all EVM chains and Solana.
Onboard millions of users for free today.
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
@picocreator
Transformers has hit the scaling wall GPT 4.5 cost billions, with no clear path to AGI for 10x$ more Facebook, Yann LeCun, is now saying we need new architectures Deepmind CEO, Demis Hassabis, is saying we need 10 yearsWe have another path to AGI in < 4 years
https://video.twimg.com/ext_tw_video/1904337130333302785/pu/vid/avc1/1280x720/aZlXTvyYsX_77HtR.mp4
2/13
@picocreator
At the heart of it, todays top models are
- Capable: Of incredible PhD level tasks & beyond
- (Un)Reliable: Maybe 1-out-of-30 time
What everyone want, is not a smarter model
But a more reliable model, doing basic college level task
Longer write up:
Our roadmap to Personalized AI and AGI3/13
@picocreator
To do the more boring things in life like
- organize emails and receipts
- fill up forms
- order groceries
- be a friend
The things that actually matter ....
All tasks which a 72B model is more than capable of,
if only it was more reliable
4/13
@picocreator
And thats where our work in Qwerky comes in.
Because the one thing that is holding these AI models, and agents back....
Is simply the lack of reliable understanding, in memories. Memories which is at the heart of recurrent model like RWKV...
[Quoted tweet]
️Attention is NOT all you need ️Using only 8 GPU's (not a cluster), we trained a Qwerky-72B (and 32B), without any transformer attention
With evals far surpassing GPT 3.5 turbo, and closing in on 4o-mini. All with 100x++ lower inference cost, via RWKV linear scaling
5/13
@picocreator
Instead of scaling bigger more expensive models, which is unable to bring an ROI to investors
What if we iterate faster, at <100B active parameters.
To make these already capable models. More reliable instead. More personalizable. At a size with ROI
[Quoted tweet]
Also, this new approach of treating FFN/MLP as a separate reusable building block.
Will allow us to iterate and validate changes in the RWKV architecture at larger scales. Faster
So expect bigger changes, in our avg ~6 month version cycle
( even i struggle to keep up
)
6/13
@picocreator
A model which can be "Memory tuned" without Catastrophic Forgetting
Overcoming the barrier, which makes finetuning out of reach for the vast majority of teams
With quick efficient personalization of AI models, to unlock reliable commercial AI agents. Without compounding errors
7/13
@picocreator
Memories is the secret to AGI
Once memories for personalized AI is mastered. Where it can be reliably tuned, with controlled datasets by AI Engineers easily...
The next step is to get the AI model to prepare their continuous training dataset without compounding loss
8/13
@picocreator
Its a binary question, is recurrent memory the path to AGI?
If so, this path to AGI is inevitable
As all the critical ingredients is already here, and is not bound by hardware, only by software
You can read more in details in our long form writing...
Our roadmap to Personalized AI and AGI9/13
@AlphaMFPEFM
Interesting read, reliability of daily fine-tuning with new memories is something I'm looking forward too. I hope you succeed !
10/13
@picocreator
Thank you
i believe all of us wish for more AI to do the boring chores in life... reliably to our prefences
11/13
@life_of_ccb
Maybe Memory is All You Need?
Not only intellectually fascinating, but also pragmatically compelling.
12/13
@picocreator
Yup, we have internal debates on what size is required for human level intelligence, once memory is "mastered"
Some argue 32B, some argue 72B, even 7B is in consideration.
Decided to play it safe with <100B
13/13
@reown_
AppKit is the full-stack toolkit to build onchain app UX
Social, Email, and Wallet Login Embedded Wallets Crypto Swaps On-rampIntegrate with just 20 lines of code across 10+ languages for all EVM chains and Solana.
Onboard millions of users for free today.
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
1/12
@picocreator
️Attention is NOT all you need ️
Using only 8 GPU's (not a cluster), we trained a Qwerky-72B (and 32B), without any transformer attention
With evals far surpassing GPT 3.5 turbo, and closing in on 4o-mini. All with 100x++ lower inference cost, via RWKV linear scaling
2/12
@picocreator
It trade blows, with existing transformer models of the same weight class.
However, what is crazier, is the fact that we have strong evidence that the vast majority of an AI model knowledge and intelligence - is NOT in the attention layer - but in FFN
🪿Qwerky-72B and 32B : Training large attention free models, with only 8 GPU's

3/12
@picocreator
Because this is a model that was converted from an existing transformer model. Where we ...
- froze the FFN (also known as MLP)
- delete the QKV transformer attention
- replace it with RWKV
- and train it with <500M tokens
(this is a massive simplification, wait for the paper)

4/12
@picocreator
And lets be realistic, 500M tokens of general text: is not enough to train the model with the level of improvement we saw in arc or winogrande benchmarks
Especially given, we effectively deleted and reset-ed a good 1/3rd of the "AI brain"
HF link:
featherless-ai/Qwerky-72B · Hugging Face
5/12
@picocreator
Which gives evidence, that the majority of "knowledge/intelligence" is in the FFN/MLP layer that was reused
An alternative, is to view attention as a means of managing memories, and focus. For the AI brain
You can test the model @ featherless here: featherless-ai/Qwerky-72B - Featherless.ai
6/12
@picocreator
Also, this new approach of treating FFN/MLP as a separate reusable building block.
Will allow us to iterate and validate changes in the RWKV architecture at larger scales. Faster
So expect bigger changes, in our avg ~6 month version cycle
( even i struggle to keep up)
7/12
@picocreator
Oh lets not forget that one of the biggest benefit of sub-quadratic architectures like RWKV....
Is the crazy reduction in inference cost, for both VRAM and compute requirements
Allowing us to do more with less
Quadratic scaling is great for revenue
And is horrible for costs

8/12
@picocreator
Making the blog post for the model more obvious here:
🪿Qwerky-72B and 32B : Training large attention free models, with only 8 GPU's
9/12
@picocreator

Imagine us doing this conversion on deepseek...
Make it a 100x more efficient at inference....
Yea we are definitely aiming to do that
10/12
@picocreator
If you want to know whats next for us...
And our roadmap to personalized AI and AGI....
[Quoted tweet]
Transformers has hit the scaling wall
GPT 4.5 cost billions, with no clear path to AGI for 10x$ more
Facebook, Yann LeCun, is now saying we need new architectures
Deepmind CEO, Demis Hassabis, is saying we need 10 years
We have another path to AGI in < 4 years
https://video.twimg.com/ext_tw_video/1904337130333302785/pu/vid/avc1/1280x720/aZlXTvyYsX_77HtR.mp4
11/12
@omouamoua
Very cool! Is there a ready-to-use RWKV7 PyTorch Module somewhere, like there is for Mamba?
12/12
@picocreator
I have working (but not final) version of the modular blocks here
GitHub - RWKV/RWKV-block: PyTorch implementation of RWKV blocks
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
@picocreator
️Attention is NOT all you need ️Using only 8 GPU's (not a cluster), we trained a Qwerky-72B (and 32B), without any transformer attention
With evals far surpassing GPT 3.5 turbo, and closing in on 4o-mini. All with 100x++ lower inference cost, via RWKV linear scaling
2/12
@picocreator
It trade blows, with existing transformer models of the same weight class.
However, what is crazier, is the fact that we have strong evidence that the vast majority of an AI model knowledge and intelligence - is NOT in the attention layer - but in FFN
🪿Qwerky-72B and 32B : Training large attention free models, with only 8 GPU's
3/12
@picocreator
Because this is a model that was converted from an existing transformer model. Where we ...
- froze the FFN (also known as MLP)
- delete the QKV transformer attention
- replace it with RWKV
- and train it with <500M tokens
(this is a massive simplification, wait for the paper)
4/12
@picocreator
And lets be realistic, 500M tokens of general text: is not enough to train the model with the level of improvement we saw in arc or winogrande benchmarks
Especially given, we effectively deleted and reset-ed a good 1/3rd of the "AI brain"
HF link:
featherless-ai/Qwerky-72B · Hugging Face
5/12
@picocreator
Which gives evidence, that the majority of "knowledge/intelligence" is in the FFN/MLP layer that was reused
An alternative, is to view attention as a means of managing memories, and focus. For the AI brain
You can test the model @ featherless here: featherless-ai/Qwerky-72B - Featherless.ai
6/12
@picocreator
Also, this new approach of treating FFN/MLP as a separate reusable building block.
Will allow us to iterate and validate changes in the RWKV architecture at larger scales. Faster
So expect bigger changes, in our avg ~6 month version cycle
( even i struggle to keep up
)
7/12
@picocreator
Oh lets not forget that one of the biggest benefit of sub-quadratic architectures like RWKV....
Is the crazy reduction in inference cost, for both VRAM and compute requirements
Allowing us to do more with less
Quadratic scaling is great for revenue
And is horrible for costs
8/12
@picocreator
Making the blog post for the model more obvious here:
🪿Qwerky-72B and 32B : Training large attention free models, with only 8 GPU's
9/12
@picocreator
Imagine us doing this conversion on deepseek...
Make it a 100x more efficient at inference....
Yea we are definitely aiming to do that
10/12
@picocreator
If you want to know whats next for us...
And our roadmap to personalized AI and AGI....
[Quoted tweet]
Transformers has hit the scaling wall GPT 4.5 cost billions, with no clear path to AGI for 10x$ more Facebook, Yann LeCun, is now saying we need new architectures Deepmind CEO, Demis Hassabis, is saying we need 10 yearsWe have another path to AGI in < 4 years
https://video.twimg.com/ext_tw_video/1904337130333302785/pu/vid/avc1/1280x720/aZlXTvyYsX_77HtR.mp4
11/12
@omouamoua
Very cool! Is there a ready-to-use RWKV7 PyTorch Module somewhere, like there is for Mamba?
12/12
@picocreator
I have working (but not final) version of the modular blocks here
GitHub - RWKV/RWKV-block: PyTorch implementation of RWKV blocks
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
JoelB
All Praise To TMH
@No1
 www.aiforwork.co
www.aiforwork.co
ChatGPT Prompts for Legal Professionals
Chat GPT Prompts for Legal. An advanced library of professional ChatGPT Prompts made for Legal Professionals. Use AI for Work and access AI Prompts, Resources, and Workflows for Legal to help with To provide legal advice and representation to the organization, ensuring compliance with laws and...
www.aiforwork.co
1/18
@NeilChristense6

2/18
@frinkiac
I mean true
3/18
@PageLyndon
The cavereddit drawing cave is full of drawings of angry faces next to wheel smeared with red ochre
4/18
@Oskar8817323565
5/18
@VahnAeris
If I do the car with the wheel . . Is it my slop car ?
6/18
@rochal
Yo, they were right about everything
7/18
@couponLord
if only we listened
8/18
@rjward1775
OR "We will use the wheel to subjugate all tribes within our range!"
9/18
@sterespect
spot on
10/18
@bmix012
isnt the whole point of ai is that its exponential and beyond comprehension
with marketing like this why would u expect ppl to just be on board instantly
11/18
@AnarchistClass
Wheels were used for war.
12/18
@pol_avec
same vibes on payments for AI agents
13/18
@heretohelp888
@DaveShapi best one yet.
14/18
@mickey17219
Look everyone, I just invented a wheel
15/18
@SkorchVoluntary
This is perfect
16/18
@andycollins6768
This is why we can't have nice things
17/18
@aisurgen
AI is different
18/18
@Mundi_Eversor
A wheel broadens experience. Does AI? What is in the other side of art and creativity? What if there is nothing?
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
@NeilChristense6
2/18
@frinkiac
I mean true
3/18
@PageLyndon
The cavereddit drawing cave is full of drawings of angry faces next to wheel smeared with red ochre
4/18
@Oskar8817323565
5/18
@VahnAeris
If I do the car with the wheel . . Is it my slop car ?
6/18
@rochal
Yo, they were right about everything
7/18
@couponLord
if only we listened
8/18
@rjward1775
OR "We will use the wheel to subjugate all tribes within our range!"
9/18
@sterespect
spot on
10/18
@bmix012
isnt the whole point of ai is that its exponential and beyond comprehension
with marketing like this why would u expect ppl to just be on board instantly
11/18
@AnarchistClass
Wheels were used for war.
12/18
@pol_avec
same vibes on payments for AI agents
13/18
@heretohelp888
@DaveShapi best one yet.
14/18
@mickey17219
Look everyone, I just invented a wheel
15/18
@SkorchVoluntary
This is perfect
16/18
@andycollins6768
This is why we can't have nice things
17/18
@aisurgen
AI is different
18/18
@Mundi_Eversor
A wheel broadens experience. Does AI? What is in the other side of art and creativity? What if there is nothing?
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196

UCLA Researchers Released OpenVLThinker-7B: A Reinforcement Learning Driven Model for Enhancing Complex Visual Reasoning and Step-by-Step Problem Solving in Multimodal Systems
Large vision-language models (LVLMs) integrate large language models with image processing capabilities, enabling them to interpret images and generate coherent textual responses. While they excel at recognizing visual objects and responding to prompts, they often falter when presented with...
 www.marktechpost.com
www.marktechpost.com
UCLA Researchers Released OpenVLThinker-7B: A Reinforcement Learning Driven Model for Enhancing Complex Visual Reasoning and Step-by-Step Problem Solving in Multimodal Systems
By
Sana Hassan
-
March 28, 2025
Large vision-language models (LVLMs) integrate large language models with image processing capabilities, enabling them to interpret images and generate coherent textual responses. While they excel at recognizing visual objects and responding to prompts, they often falter when presented with problems requiring multi-step reasoning. Vision-language tasks like understanding charts, solving visual math questions, or interpreting diagrams demand more than recognition; they need the ability to follow logical steps based on visual cues. Despite advancements in model architecture, current systems consistently struggle to produce accurate and interpretable answers in such complex scenarios.
A major limitation in current vision-language models is their inability to perform complex reasoning that involves multiple steps of logical deduction, especially when interpreting images in conjunction with textual queries. These models cannot often internally verify or correct their reasoning, leading to incorrect or shallow outputs. Also, the reasoning chains these models follow are typically not transparent or verifiable, making it difficult to ensure the robustness of their conclusions. The challenge lies in bridging this reasoning gap, which text-only models have begun to address effectively through reinforcement learning techniques but vision-language models have yet to embrace fully.
Check out how HOSTINGER HORIZONS can help to build and launch full-stack web apps, tools, and software in minutes without writing any code (Promoted)
Before this study, efforts to enhance reasoning in such systems mostly relied on standard fine-tuning or prompting techniques. Though helpful in basic tasks, these approaches often resulted in verbose or repetitive outputs with limited depth. Vision-language models like Qwen2.5-VL-7B showed promise due to their visual instruction-following abilities but lacked the multi-step reasoning comparable to their text-only counterparts, such as DeepSeek-R1. Even when prompted with structured queries, these models struggled to reflect upon their outputs or validate intermediate reasoning steps. This was a significant bottleneck, particularly for use cases requiring structured decision-making, such as visual problem-solving or educational support tools.
Researchers from the University of California, Los Angeles, introduced a model named OpenVLThinker-7B. This model was developed through a novel training method that combines supervised fine-tuning (SFT) and reinforcement learning (RL) in an iterative loop. The process started by generating image captions using Qwen2.5-VL-3B and feeding these into a distilled version of DeepSeek-R1 to produce structured reasoning chains. These outputs formed the training data for the first round of SFT, guiding the model in learning basic reasoning structures. Following this, a reinforcement learning stage using Group Relative Policy Optimization (GRPO) was applied to refine the model’s reasoning based on reward feedback. This combination enabled the model to progressively self-improve, using each iteration’s refined outputs as new training data for the next cycle.
The method involved careful data curation and multiple training phases. In the first iteration, 25,000 examples were used for SFT, sourced from datasets like FigureQA, Geometry3K, TabMWP, and VizWiz. These examples were filtered to remove overly verbose or redundant reflections, improving training quality. GRPO was then applied to a smaller, more difficult dataset of 5,000 samples. This led to a performance increase from 62.5% to 65.6% accuracy on the MathVista benchmark. In the second iteration, another 5,000 high-quality examples were used for SFT, raising accuracy to 66.1%. A second round of GRPO pushed performance to 69.4%. Across these phases, the model was evaluated on multiple benchmarks, MathVista, MathVerse, and MathVision, showing consistent performance gains with each iteration.

Quantitatively, OpenVLThinker-7B outperformed its base model, Qwen2.5-VL-7B, significantly. On MathVista, it reached 70.2% accuracy compared to the base model’s 50.2%. On MathVerse, the improvement was from 46.8% to 68.5%. MathVision full test accuracy rose from 24.0% to 29.6%, and MathVision testmini improved from 25.3% to 30.4%. These improvements indicate that the model learned to follow reasoning patterns and generalized better to unseen multimodal tasks. Each iteration of training contributed measurable gains, showcasing the strength of combining fine-tuning with reward-based learning in a looped structure.

The core of this model’s strength lies in its iterative structure. Rather than relying solely on vast datasets, it focuses on quality and structure. Each cycle of SFT and RL improves the model’s capacity to understand the relationship between images, questions, and answers. Self-verification and correction behaviors, initially lacking in standard LVLMs, emerged as a byproduct of reinforcement learning with verifiable reward signals. This allowed OpenVLThinker-7B to produce reasoning traces that were logically consistent and interpretable. Even subtle improvements, such as reduced redundant self-reflections or increased accuracy with shorter reasoning chains, contributed to its overall performance gains.

Some Key Takeaways from the Research:
- UCLA researchers developed OpenVLThinker-7B using a combined SFT and RL approach, starting from the Qwen2.5-VL-7B base model.
- Used iterative training cycles involving caption generation, reasoning distillation, and alternating SFT and GRPO reinforcement learning.
- The initial SFT used 25,000 filtered examples, while the RL phases used smaller sets of 5,000 harder samples from datasets like Geometry3K and SuperCLEVR.
- On MathVista, accuracy improved from 50.2% (base model) to 70.2%. MathVerse accuracy jumped from 46.8% to 68.5%, and other datasets also saw notable gains.
- GRPO effectively refined reasoning behaviors by rewarding correct answers, reducing verbosity, and improving logical consistency.
- Each training iteration led to incremental performance gains, confirming the effectiveness of the self-improvement strategy.
- Establishes a viable route to bring R1-style multi-step reasoning into multimodal models, useful for educational, visual analytics, and assistive tech applications.
Check out the Paper, Model on Hugging Face and GitHub Page. All credit for this research goes to the researchers of this project. Also, feel free to follow us on Twitter and don’t forget to join our 85k+ ML SubReddit.
VideoMind: A Role-Based Agent for Temporal-Grounded Video Understanding
LLMs have shown impressive capabilities in reasoning tasks like Chain-of-Thought (CoT), enhancing accuracy and interpretability in complex problem-solving. While researchers are extending these capabilities to multi-modal domains, videos present unique challenges due to their temporal dimension...
www.marktechpost.com
VideoMind: A Role-Based Agent for Temporal-Grounded Video Understanding
By Sajjad Ansari
March 30, 2025
Reddit Vote Flip Share Tweet 0 Shares
LLMs have shown impressive capabilities in reasoning tasks like Chain-of-Thought (CoT), enhancing accuracy and interpretability in complex problem-solving. While researchers are extending these capabilities to multi-modal domains, videos present unique challenges due to their temporal dimension. Unlike static images, videos require understanding dynamic interactions over time. Current visual CoT methods excel with static inputs but struggle with video content because they cannot explicitly localize or revisit specific moments in sequences. Humans overcome these challenges by breaking down complex problems, identifying and revisiting key moments, and synthesizing observations into coherent answers. This approach highlights the need for AI systems to manage multiple reasoning abilities.
Recent video understanding advances have improved tasks like captioning and question answering, but models often lack visual-grounded correspondence and interpretability, especially for long-form videos. Video Temporal Grounding addresses this by requiring precise localization. Large Multimodal Models trained with supervised instruction-tuning struggle with complex reasoning tasks. Two major approaches have emerged to address these limitations: agent-based interfaces and pure text-based reasoning paradigms exemplified by CoT processes. Moreover, Inference-time searching techniques are valuable in domains like robotics, games, and navigation by allowing models to iteratively refine outputs without changing underlying weights.
Check out how HOSTINGER HORIZONS can help to build and launch full-stack web apps, tools, and software in minutes without writing any code (Promoted)
Researchers from the Hong Kong Polytechnic University and Show Lab, National University of Singapore, have proposed VideoMind, a video-language agent designed for temporal-grounded video understanding. VideoMind introduces two key innovations to address the challenges of video reasoning. First, it identifies essential capabilities for video temporal reasoning and implements a role-based agentic workflow with specialized components: a planner, a grounder, a verifier, and an answerer. Second, it proposes a Chain-of-LoRA strategy that enables seamless role-switching through lightweight LoRA adaptors, avoiding the overhead of multiple models while balancing efficiency and flexibility. Experiments across 14 public benchmarks show state-of-the-art performance in diverse video understanding tasks.

VideoMind builds upon the Qwen2-VL, combining an LLM backbone with a ViT-based visual encoder capable of handling dynamic resolution inputs. Its core innovation is its Chain-of-LoRA strategy, which dynamically activates role-specific LoRA adapters during inference via self-calling. Moreover, it contains four specialized components: (a) Planner, which coordinates all other roles and determines which function to call next based on query, (b) Grounder, which localizes relevant moments by identifying start and end timestamps based on text queries (c) Verifier, which provides binary (“Yes”/”No”) responses to validate temporal intervals and (d) Answerer, which generates responses based on either cropped video segments identified by the Grounder or the entire video when direct answering is more appropriate.
In grounding metrics, VideoMind’s lightweight 2B model outperforms most compared models, including InternVL2-78B and Claude-3.5-Sonnet, with only GPT-4o showing superior results. However, the 7B version of VideoMind surpasses even GPT-4o, achieving competitive overall performance. On the NExT-GQA benchmark, the 2B model matches state-of-the-art 7B models across both agent-based and end-to-end approaches, comparing favorably with text-rich, agent-based solutions like LLoVi, LangRepo, and SeViLA. VideoMind shows exceptional zero-shot capabilities, outperforming all LLM-based temporal grounding methods and achieving competitive results compared to fine-tuned temporal grounding experts. Moreover, VideoMind excels in general video QA tasks across Video-MME (Long), MLVU, and LVBench, showing effective localization of cue segments before answering questions.
In this paper, researchers introduced VideoMind, a significant advancement in temporal grounded video reasoning. It addresses the complex challenges of video understanding through agentic workflow, combining a Planner, Grounder, Verifier, Answerer, and an efficient Chain-of-LoRA strategy for role-switching. Experiments across three key domains, grounded video question-answering, video temporal grounding, and general video question-answering, confirm VideoMind’s effectiveness for long-form video reasoning tasks where it provides precise, evidence-based answers. This work establishes a foundation for future developments in multimodal video agents and reasoning capabilities, opening new pathways for more complex video understanding systems.
Check out the Paper and Project Page . All credit for this research goes to the researchers of this project. Also, feel free to follow us on Twitter and don’t forget to join our 85k+ ML SubReddit .
Tencent AI Researchers Introduce Hunyuan-T1: A Mamba-Powered Ultra-Large Language Model Redefining Deep Reasoning, Contextual Efficiency, and Human-Centric Reinforcement Learning
Large language models struggle to process and reason over lengthy, complex texts without losing essential context. Traditional models often suffer from context loss, inefficient handling of long-range dependencies, and difficulties aligning with human preferences, affecting the accuracy and...
www.marktechpost.com
Tencent AI Researchers Introduce Hunyuan-T1: A Mamba-Powered Ultra-Large Language Model Redefining Deep Reasoning, Contextual Efficiency, and Human-Centric Reinforcement Learning
By Asif Razzaq
March 29, 2025
Reddit Vote Flip Share Tweet 0 Shares
Large language models struggle to process and reason over lengthy, complex texts without losing essential context. Traditional models often suffer from context loss, inefficient handling of long-range dependencies, and difficulties aligning with human preferences, affecting the accuracy and efficiency of their responses. Tencent’s Hunyuan-T1 directly tackles these challenges by integrating a novel Mamba-powered architecture with advanced reinforcement learning and curriculum strategies, ensuring robust context capture and enhanced reasoning capabilities.
Hunyuan-T1 is the first model powered by the innovative Mamba architecture, a design that fuses Hybrid Transformer and Mixture-of-Experts (MoE) technologies. Built on the TurboS fast-thinking base, Hunyuan-T1 is specifically engineered to optimize the processing of long textual sequences while minimizing computational overhead. This allows the model to effectively capture extended context and manage long-distance dependencies, crucial for tasks that demand deep, coherent reasoning.
Check out how HOSTINGER HORIZONS can help to build and launch full-stack web apps, tools, and software in minutes without writing any code (Promoted)

A key highlight of Hunyuan-T1 is its heavy reliance on RL during the post-training phase. Tencent dedicated 96.7% of its computing power to this approach, enabling the model to refine its reasoning abilities iteratively. Techniques such as data replay, periodic policy resetting, and self-rewarding feedback loops help improve output quality, ensuring the model’s responses are detailed, efficient, and closely aligned with human expectations.
To further boost reasoning proficiency, Tencent employed a curriculum learning strategy. This approach gradually increases the difficulty of training data while simultaneously expanding the model’s context length. As a result, Hunyuan-T1 is trained to use tokens more efficiently, seamlessly adapting from solving basic mathematical problems to tackling complex scientific and logical challenges. Efficiency is another cornerstone of Hunyuan-T1’s design. The TurboS base’s ability to capture long-text information prevents context loss, a common issue in many language models, and doubles the decoding speed compared to similar systems. This breakthrough means that users benefit from faster, higher-quality responses without compromising performance.

The model has achieved impressive scores on multiple benchmarks: 87.2 on MMLU-PRO, which tests various subjects including humanities, social sciences, and STEM fields; 69.3 on GPQA-diamond, a challenging evaluation featuring doctoral-level scientific problems; 64.9 on LiveCodeBench for coding tasks; and a remarkable 96.2 on the MATH-500 benchmark for mathematical reasoning. These results underscore Hunyuan-T1’s versatility and ability to handle high-stakes, professional-grade tasks across various fields. Beyond quantitative metrics, Hunyuan-T1 is designed to deliver outputs with human-like understanding and creativity. During its RL phase, the model underwent a comprehensive alignment process that combined self-rewarding feedback with external reward models. This dual approach ensures its responses are accurate and exhibit rich details and natural flow.
In conclusion, Tencent’s Hunyuan-T1 combines an ultra-large-scale, Mamba-powered architecture with state-of-the-art reinforcement learning and curriculum strategies. Hunyuan-T1 delivers high performance, enhanced reasoning, and exceptional efficiency.
Check out the Details , Hugging Face and GitHub Page . All credit for this research goes to the researchers of this project. Also, feel free to follow us on Twitter and don’t forget to join our 85k+ ML SubReddit .