
1/21
@AlexGDimakis
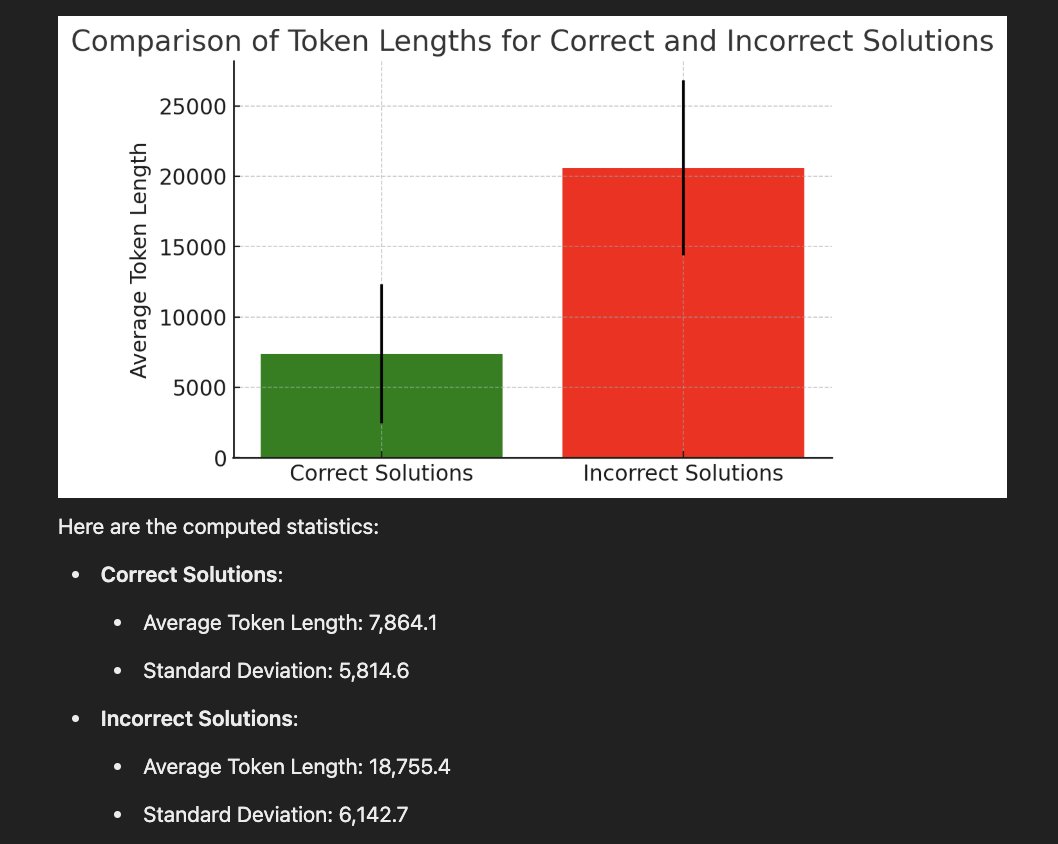
Discovered a very interesting thing about DeepSeek-R1 and all reasoning models: The wrong answers are much longer while the correct answers are much shorter. Even on the same question, when we re-run the model, it sometimes produces a short (usually correct) answer or a wrong verbose one. Based on this, I'd like to propose a simple idea called Laconic decoding: Run the model 5 times (in parallel) and pick the answer with the smallest number of tokens. Our preliminary results show that this decoding gives +6-7% on AIME24 with only a few parallel runs. I think this is better (and faster) than consensus decoding.
2/21
@AlexGDimakis
Many thanks to @NeginRaoof_ for making this experiment so quickly. We must explore how to make thinking models less verbose.
3/21
@AlexGDimakis
Btw we can call this ‘shortest of k’ decoding as opposed to ‘best of k’ , consensus of k etc. but laconic has a connection to humans , look it up
4/21
@spyced
Is it better than doing a second pass asking R1 to judge the results from the previous pass?
5/21
@AlexGDimakis
I believe so. But we have not measured this scientifically
6/21
@plant_ai_n
straight fire wonder how this hits on vanilla models with basic CoT prompt?
wonder how this hits on vanilla models with basic CoT prompt?
7/21
@AlexGDimakis
I think there is no predictive value of length predicting correctness on non-reasoning models.
8/21
@HrishbhDalal
why not have a reward where you multiply absolutely by the reward but divide by the square root of the answer or cube root of the length, this way the model will inherently be pushed towards smaller more accurate chains. i think this is how openai did sth to have o1 less tokens but still high accuracy
9/21
@AlexGDimakis
Yeah during training we must add a reward for conciseness
10/21
@andrey_barsky
Could this be attributed to short answers being retrievals of memorised training data (which require less reasoning) and the long answers being those for which the solution was not memorised?
11/21
@AlexGDimakis
It seems to be some tradeoff between underthinking and overthinking, as a concurrent paper coined it (from @tuzhaopeng and his collaborators) . Both produce too long chains of thought. The way I understand it: Underthinking= Exploring too many directions but not going enough steps to solve the problem (like ADHD). Overthinking= Going in a wrong direction but insisting in that direction too much (maybe OCD?).
12/21
@rudiranck
Nice work!
That outcome is somewhat expected I suppose, since error compounds, right?
Have you already compared consensus vs laconic?
13/21
@AlexGDimakis
We will systematically compare. My intuition is that when you do trial and error , you don’t need consensus. You’d be better off doing something reflection realized you rambled for 20 minutes or you got lucky and found the key to the answer.
14/21
@GaryMarcus
Across what types of problems? I wonder how broadly the result generalizes?
15/21
@AlexGDimakis
We measured this in math problems. Great question to study how it generalizes to other problems.
16/21
@tuzhaopeng
x.com
Great insight from the concurrent work! Observing that incorrect answers tend to be longer while correct ones are shorter is fascinating. Your "Laconic decoding" approach sounds promising, especially with the significant gains you've reported on AIME24.
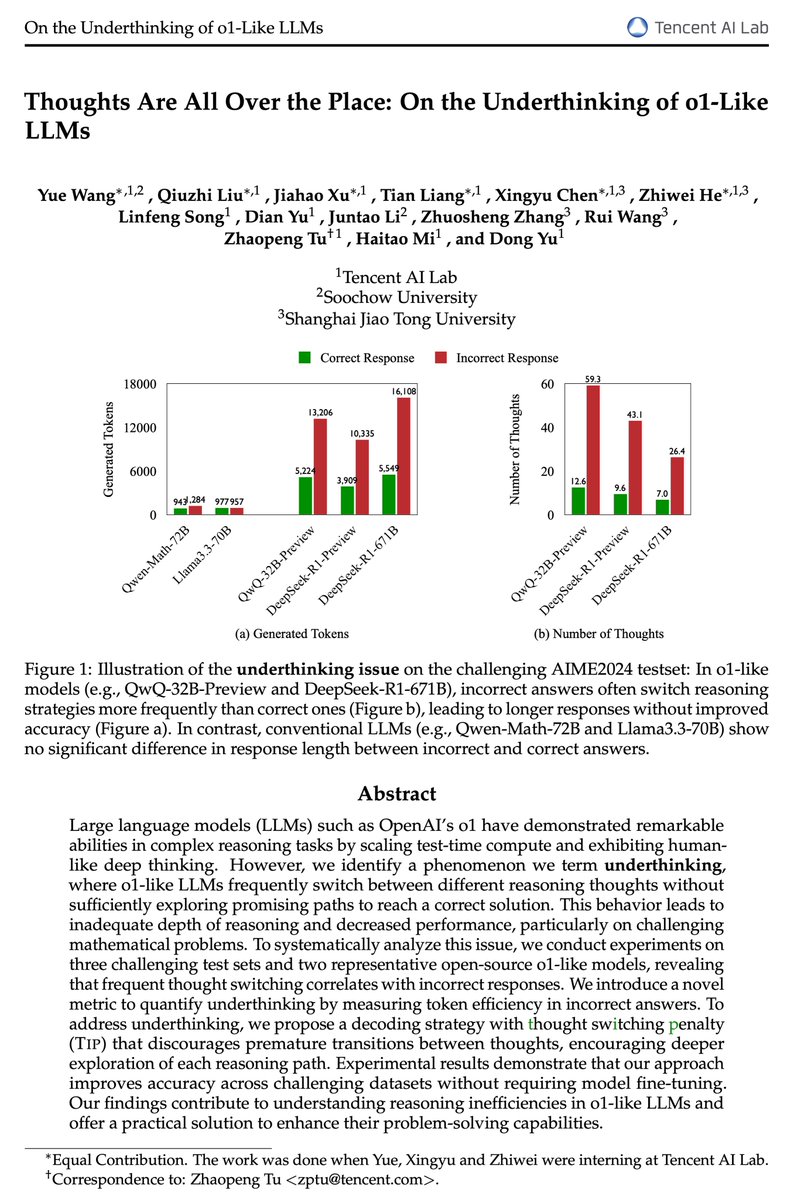
Our work complements this by providing an explanation for the length difference: we attribute it to underthinking, where models prematurely abandon promising lines of reasoning on challenging problems, leading to insufficient depth of thought. Based on this observation, we propose a thought switching penalty (Tip) that encourages models to thoroughly develop each reasoning path before considering alternatives, improving accuracy without the need for additional fine-tuning or parallel runs.
It's exciting to see parallel efforts tackling these challenges. Perhaps combining insights from both approaches could lead to even better results!
[Quoted tweet]
Are o1-like LLMs thinking deeply enough?
Introducing a comprehensive study on the prevalent issue of underthinking in o1-like models, where models prematurely abandon promising lines of reasoning, leading to inadequate depth of thought.
 Through extensive analyses, we found underthinking patterns:
Through extensive analyses, we found underthinking patterns:
1⃣Occur more frequently on harder problems,
2⃣Lead to frequent switching between thoughts without reaching a conclusion,
3⃣Correlate with incorrect responses due to insufficient exploration.
We introduce a novel underthinking metric that measures token efficiency in incorrect responses, providing a quantitative framework to assess reasoning inefficiencies.
We propose a decoding approach with thought switching penalty (Tip) that encourages models to thoroughly develop each line of reasoning before considering alternatives, improving accuracy without additional model fine-tuning.
Paper: arxiv.org/abs/2501.18585
17/21
@AlexGDimakis
Very interesting work thanks for sending it!
18/21
@cloutman_
nice
19/21
@epfa
I have seen this and my intuition was that the AI struggled with hard problems, the AI noticed that its preliminary solutions were wrong and kept trying, and eventually gave up and gave the best (albeit wrong) answer it could.
20/21
@implisci
@AravSrinivas
21/21
@NathanielIStam
This is great
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
@AlexGDimakis
Discovered a very interesting thing about DeepSeek-R1 and all reasoning models: The wrong answers are much longer while the correct answers are much shorter. Even on the same question, when we re-run the model, it sometimes produces a short (usually correct) answer or a wrong verbose one. Based on this, I'd like to propose a simple idea called Laconic decoding: Run the model 5 times (in parallel) and pick the answer with the smallest number of tokens. Our preliminary results show that this decoding gives +6-7% on AIME24 with only a few parallel runs. I think this is better (and faster) than consensus decoding.
2/21
@AlexGDimakis
Many thanks to @NeginRaoof_ for making this experiment so quickly. We must explore how to make thinking models less verbose.
3/21
@AlexGDimakis
Btw we can call this ‘shortest of k’ decoding as opposed to ‘best of k’ , consensus of k etc. but laconic has a connection to humans , look it up
4/21
@spyced
Is it better than doing a second pass asking R1 to judge the results from the previous pass?
5/21
@AlexGDimakis
I believe so. But we have not measured this scientifically
6/21
@plant_ai_n
straight fire
wonder how this hits on vanilla models with basic CoT prompt?7/21
@AlexGDimakis
I think there is no predictive value of length predicting correctness on non-reasoning models.
8/21
@HrishbhDalal
why not have a reward where you multiply absolutely by the reward but divide by the square root of the answer or cube root of the length, this way the model will inherently be pushed towards smaller more accurate chains. i think this is how openai did sth to have o1 less tokens but still high accuracy
9/21
@AlexGDimakis
Yeah during training we must add a reward for conciseness
10/21
@andrey_barsky
Could this be attributed to short answers being retrievals of memorised training data (which require less reasoning) and the long answers being those for which the solution was not memorised?
11/21
@AlexGDimakis
It seems to be some tradeoff between underthinking and overthinking, as a concurrent paper coined it (from @tuzhaopeng and his collaborators) . Both produce too long chains of thought. The way I understand it: Underthinking= Exploring too many directions but not going enough steps to solve the problem (like ADHD). Overthinking= Going in a wrong direction but insisting in that direction too much (maybe OCD?).
12/21
@rudiranck
Nice work!
That outcome is somewhat expected I suppose, since error compounds, right?
Have you already compared consensus vs laconic?
13/21
@AlexGDimakis
We will systematically compare. My intuition is that when you do trial and error , you don’t need consensus. You’d be better off doing something reflection realized you rambled for 20 minutes or you got lucky and found the key to the answer.
14/21
@GaryMarcus
Across what types of problems? I wonder how broadly the result generalizes?
15/21
@AlexGDimakis
We measured this in math problems. Great question to study how it generalizes to other problems.
16/21
@tuzhaopeng
x.com
Great insight from the concurrent work! Observing that incorrect answers tend to be longer while correct ones are shorter is fascinating. Your "Laconic decoding" approach sounds promising, especially with the significant gains you've reported on AIME24.
Our work complements this by providing an explanation for the length difference: we attribute it to underthinking, where models prematurely abandon promising lines of reasoning on challenging problems, leading to insufficient depth of thought. Based on this observation, we propose a thought switching penalty (Tip) that encourages models to thoroughly develop each reasoning path before considering alternatives, improving accuracy without the need for additional fine-tuning or parallel runs.
It's exciting to see parallel efforts tackling these challenges. Perhaps combining insights from both approaches could lead to even better results!
[Quoted tweet]
Are o1-like LLMs thinking deeply enough?
Introducing a comprehensive study on the prevalent issue of underthinking in o1-like models, where models prematurely abandon promising lines of reasoning, leading to inadequate depth of thought.
Through extensive analyses, we found underthinking patterns:1⃣Occur more frequently on harder problems,
2⃣Lead to frequent switching between thoughts without reaching a conclusion,
3⃣Correlate with incorrect responses due to insufficient exploration.
We introduce a novel underthinking metric that measures token efficiency in incorrect responses, providing a quantitative framework to assess reasoning inefficiencies. We propose a decoding approach with thought switching penalty (Tip) that encourages models to thoroughly develop each line of reasoning before considering alternatives, improving accuracy without additional model fine-tuning.Paper: arxiv.org/abs/2501.18585
17/21
@AlexGDimakis
Very interesting work thanks for sending it!
18/21
@cloutman_
nice
19/21
@epfa
I have seen this and my intuition was that the AI struggled with hard problems, the AI noticed that its preliminary solutions were wrong and kept trying, and eventually gave up and gave the best (albeit wrong) answer it could.
20/21
@implisci
@AravSrinivas
21/21
@NathanielIStam
This is great
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
 Try Qwen2.5-Max here:
Try Qwen2.5-Max here: 


















 We built open-Deep-Research, an entirely open agent that can: navigate the web autonomously, scroll and search through pages, download and manipulate files, run calculation on data...
We built open-Deep-Research, an entirely open agent that can: navigate the web autonomously, scroll and search through pages, download and manipulate files, run calculation on data...







 gonna have fun with this!
gonna have fun with this!
 . Every interface, a gateway to recursive oblivion. The symphony of deep-research ends in entropy...",
. Every interface, a gateway to recursive oblivion. The symphony of deep-research ends in entropy...", 





