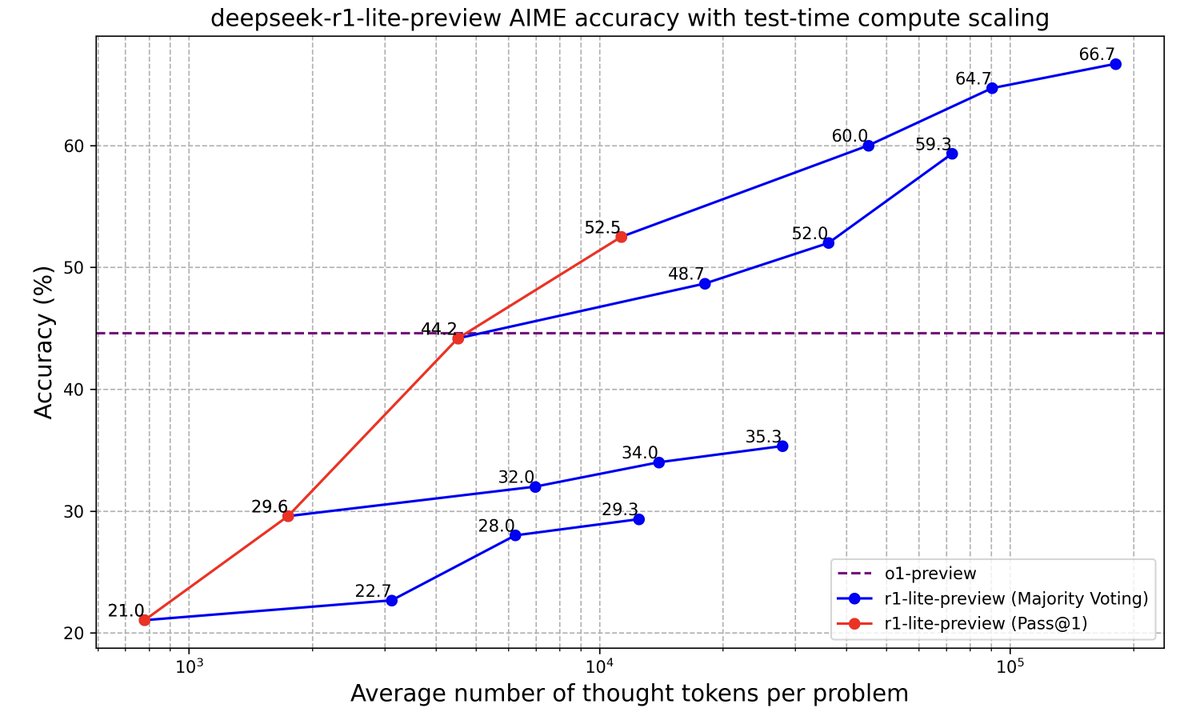
1/1
@HaHoang411
 Mind-blowing work by the team at @FLAIR_Ox! They've created Kinetix, a framework for training general-purpose RL agents that can tackle physics-based challenges.
Mind-blowing work by the team at @FLAIR_Ox! They've created Kinetix, a framework for training general-purpose RL agents that can tackle physics-based challenges.
The coolest part? Their agents can solve physical reasoning complex tasks zero-shot!
 Congrats @mitrma and team.
Congrats @mitrma and team.
[Quoted tweet]
We are very excited to announce Kinetix: an open-ended universe of physics-based tasks for RL!
We use Kinetix to train a general agent on millions of randomly generated physics problems and show that this agent generalises to unseen handmade environments.
1/
https://video.twimg.com/ext_tw_video/1856003600159256576/pu/vid/avc1/1280x720/zJNdBD1Yq0uFl9Nf.mp4
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
@HaHoang411
Mind-blowing work by the team at @FLAIR_Ox! They've created Kinetix, a framework for training general-purpose RL agents that can tackle physics-based challenges.The coolest part? Their agents can solve physical reasoning complex tasks zero-shot!
Congrats @mitrma and team.[Quoted tweet]
We are very excited to announce Kinetix: an open-ended universe of physics-based tasks for RL!
We use Kinetix to train a general agent on millions of randomly generated physics problems and show that this agent generalises to unseen handmade environments.
1/
https://video.twimg.com/ext_tw_video/1856003600159256576/pu/vid/avc1/1280x720/zJNdBD1Yq0uFl9Nf.mp4
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
1/12
@mitrma
We are very excited to announce Kinetix: an open-ended universe of physics-based tasks for RL!
We use Kinetix to train a general agent on millions of randomly generated physics problems and show that this agent generalises to unseen handmade environments.
1/
https://video.twimg.com/ext_tw_video/1856003600159256576/pu/vid/avc1/1280x720/zJNdBD1Yq0uFl9Nf.mp4
2/12
@mitrma
 Kinetix can represent problems ranging from robotic locomotion and grasping, to classic RL environments and video games, all within a unified framework. This opens the door to training a single generalist agent for all these tasks!
Kinetix can represent problems ranging from robotic locomotion and grasping, to classic RL environments and video games, all within a unified framework. This opens the door to training a single generalist agent for all these tasks!
2/
https://video.twimg.com/ext_tw_video/1856003839851220992/pu/vid/avc1/640x640/J_w1M8wm8ibiGCAn.mp4
3/12
@mitrma
 By procedurally generating random environments, we train an RL agent that can zero-shot solve unseen handmade problems. This includes some where RL from scratch fails!
By procedurally generating random environments, we train an RL agent that can zero-shot solve unseen handmade problems. This includes some where RL from scratch fails!
3/
https://video.twimg.com/ext_tw_video/1856003979878051840/pu/vid/avc1/720x720/JAcE26Hprn1NXPvU.mp4
4/12
@mitrma


 Each environment has the same goal: make touch while preventing touching . The agent controls all motors and thrusters.
Each environment has the same goal: make touch while preventing touching . The agent controls all motors and thrusters.
In this task the car has to first be flipped with thrusters. The general agent solves it zero-shot, having never seen it before.
4/
https://video.twimg.com/ext_tw_video/1856004286943002624/pu/vid/avc1/720x720/hjhITONkJiDY9tD2.mp4
5/12
@mitrma
 Our general agent shows emergent physical reasoning capabilities, for instance being able to zero-shot control unseen morphologies by moving them underneath a goal (
Our general agent shows emergent physical reasoning capabilities, for instance being able to zero-shot control unseen morphologies by moving them underneath a goal ( ).
).
5/
https://video.twimg.com/ext_tw_video/1856004409559306241/pu/vid/avc1/994x540/AA6c6MHpWRkFt3OJ.mp4
6/12
@mitrma
 We also show that finetuning this general model on target tasks is more sample efficient than training from scratch, providing a step towards a foundation model for RL.
We also show that finetuning this general model on target tasks is more sample efficient than training from scratch, providing a step towards a foundation model for RL.
In some cases, training from scratch completely fails, while our finetuned general model succeeds
6/
https://video.twimg.com/ext_tw_video/1856004545525972993/pu/vid/avc1/1280x720/jMqgYcCwx-q4tSpm.mp4
7/12
@mitrma
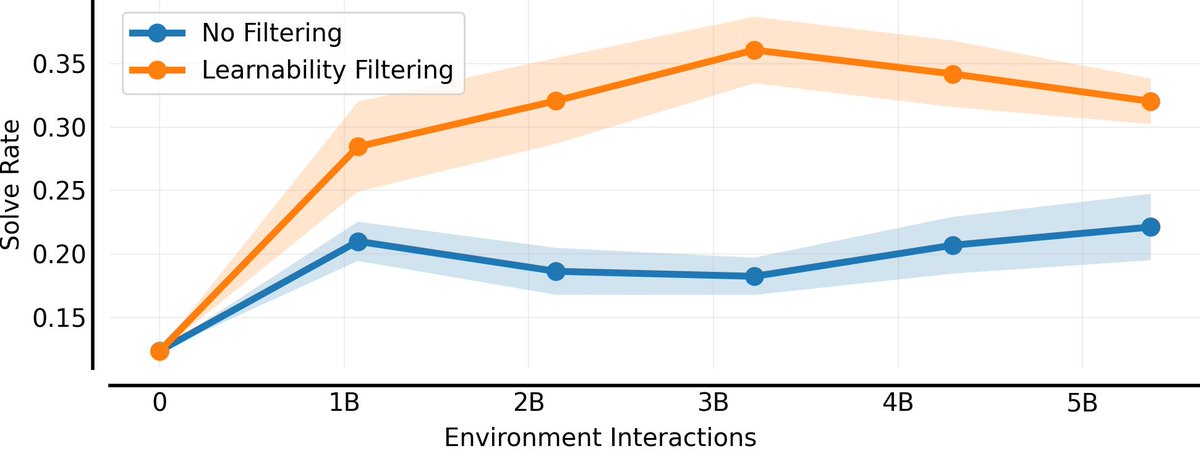
 One big takeaway from this work is the importance of autocurricula. In particular, we found significantly improved results by dynamically prioritising levels with high 'learnability'.
One big takeaway from this work is the importance of autocurricula. In particular, we found significantly improved results by dynamically prioritising levels with high 'learnability'.
7/
8/12
@mitrma
 The core of Kinetix is our new 2D rigid body physics engine: Jax2D. This is a minimal rewrite of the classic Box2D engine made by @erin_catto. Jax2D allows us to run thousands of heterogeneous parallel environments on a single GPU (yes, you can vmap over different tasks!)
The core of Kinetix is our new 2D rigid body physics engine: Jax2D. This is a minimal rewrite of the classic Box2D engine made by @erin_catto. Jax2D allows us to run thousands of heterogeneous parallel environments on a single GPU (yes, you can vmap over different tasks!)
8/
9/12
@mitrma
 Don't take our word for it, try it out for yourself!
Don't take our word for it, try it out for yourself!
Create your own levels in your browser with Kinetix.js and see how different pretrained agents perform: Redirecting...
9/
https://video.twimg.com/ext_tw_video/1856004915501350912/pu/vid/avc1/1422x720/7wj1y_BcHHUnNtwx.mp4
10/12
@mitrma
This work was co-led with @mcbeukman and done at @FLAIR_Ox with @_chris_lu_ and @j_foerst.
Blog: https://kinetix-env.github.io/
GitHub: GitHub - FLAIROx/Kinetix: Reinforcement learning on general 2D physics environments in JAX
arXiv: [2410.23208] Kinetix: Investigating the Training of General Agents through Open-Ended Physics-Based Control Tasks
end/
11/12
@_k_sridhar
Very cool paper! FYI, we recently pretrained a generalist agent that can generalize to unseen atari/metaworld/mujoco/procgen environments simply via retrieval-augmentation and in-context learning. Our work uses an imitation learning approach. REGENT: A Retrieval-Augmented Generalist Agent That Can Act In-Context In New Environments.
12/12
@mitrma
This is really cool! Let's meet up and chat at ICLR if we both end up going?
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
@mitrma
We are very excited to announce Kinetix: an open-ended universe of physics-based tasks for RL!
We use Kinetix to train a general agent on millions of randomly generated physics problems and show that this agent generalises to unseen handmade environments.
1/
https://video.twimg.com/ext_tw_video/1856003600159256576/pu/vid/avc1/1280x720/zJNdBD1Yq0uFl9Nf.mp4
2/12
@mitrma
Kinetix can represent problems ranging from robotic locomotion and grasping, to classic RL environments and video games, all within a unified framework. This opens the door to training a single generalist agent for all these tasks!2/
https://video.twimg.com/ext_tw_video/1856003839851220992/pu/vid/avc1/640x640/J_w1M8wm8ibiGCAn.mp4
3/12
@mitrma
By procedurally generating random environments, we train an RL agent that can zero-shot solve unseen handmade problems. This includes some where RL from scratch fails!3/
https://video.twimg.com/ext_tw_video/1856003979878051840/pu/vid/avc1/720x720/JAcE26Hprn1NXPvU.mp4
4/12
@mitrma
Each environment has the same goal: make touch while preventing touching . The agent controls all motors and thrusters.In this task the car has to first be flipped with thrusters. The general agent solves it zero-shot, having never seen it before.
4/
https://video.twimg.com/ext_tw_video/1856004286943002624/pu/vid/avc1/720x720/hjhITONkJiDY9tD2.mp4
5/12
@mitrma
Our general agent shows emergent physical reasoning capabilities, for instance being able to zero-shot control unseen morphologies by moving them underneath a goal ().5/
https://video.twimg.com/ext_tw_video/1856004409559306241/pu/vid/avc1/994x540/AA6c6MHpWRkFt3OJ.mp4
6/12
@mitrma
We also show that finetuning this general model on target tasks is more sample efficient than training from scratch, providing a step towards a foundation model for RL.In some cases, training from scratch completely fails, while our finetuned general model succeeds
6/
https://video.twimg.com/ext_tw_video/1856004545525972993/pu/vid/avc1/1280x720/jMqgYcCwx-q4tSpm.mp4
7/12
@mitrma
One big takeaway from this work is the importance of autocurricula. In particular, we found significantly improved results by dynamically prioritising levels with high 'learnability'.7/
8/12
@mitrma
The core of Kinetix is our new 2D rigid body physics engine: Jax2D. This is a minimal rewrite of the classic Box2D engine made by @erin_catto. Jax2D allows us to run thousands of heterogeneous parallel environments on a single GPU (yes, you can vmap over different tasks!)8/
9/12
@mitrma
Don't take our word for it, try it out for yourself!Create your own levels in your browser with Kinetix.js and see how different pretrained agents perform: Redirecting...
9/
https://video.twimg.com/ext_tw_video/1856004915501350912/pu/vid/avc1/1422x720/7wj1y_BcHHUnNtwx.mp4
10/12
@mitrma
This work was co-led with @mcbeukman and done at @FLAIR_Ox with @_chris_lu_ and @j_foerst.
Blog: https://kinetix-env.github.io/
GitHub: GitHub - FLAIROx/Kinetix: Reinforcement learning on general 2D physics environments in JAX
arXiv: [2410.23208] Kinetix: Investigating the Training of General Agents through Open-Ended Physics-Based Control Tasks
end/
11/12
@_k_sridhar
Very cool paper! FYI, we recently pretrained a generalist agent that can generalize to unseen atari/metaworld/mujoco/procgen environments simply via retrieval-augmentation and in-context learning. Our work uses an imitation learning approach. REGENT: A Retrieval-Augmented Generalist Agent That Can Act In-Context In New Environments.
12/12
@mitrma
This is really cool! Let's meet up and chat at ICLR if we both end up going?
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
























 Unlike traditional chatbots like Gemini or ChatGPT, Learn About is powered by Google’s LearnLM model, promoting educational research to align with how people learn best.
Unlike traditional chatbots like Gemini or ChatGPT, Learn About is powered by Google’s LearnLM model, promoting educational research to align with how people learn best. One standout feature is its focus on visuals and interactive content, making information easier to understand and remember.
One standout feature is its focus on visuals and interactive content, making information easier to understand and remember. In a direct comparison with Google Gemini on the prompt, “How big is the universe?”, both tools provided the same answer: “about 93 billion light-years in diameter.”
In a direct comparison with Google Gemini on the prompt, “How big is the universe?”, both tools provided the same answer: “about 93 billion light-years in diameter.” However, their presentations differed significantly! Gemini featured a Wikipedia diagram along with a summary and source links, while Learn About used an image from Physics Forums and offered related educational content.
However, their presentations differed significantly! Gemini featured a Wikipedia diagram along with a summary and source links, while Learn About used an image from Physics Forums and offered related educational content. Learn About even includes “why it matters” sections and “Build your vocab” features, offering context and definitions for terms!
Learn About even includes “why it matters” sections and “Build your vocab” features, offering context and definitions for terms! In summary, Learn About enriches learning with visuals, contextual info, and vocabulary aids, while Gemini leans towards straightforward facts.
In summary, Learn About enriches learning with visuals, contextual info, and vocabulary aids, while Gemini leans towards straightforward facts. It’s not just about factual answers; Learn About even addresses quirky questions! For example, when asked about the “best glue for pizza,” it flagged this as a “common misconception.”
It’s not just about factual answers; Learn About even addresses quirky questions! For example, when asked about the “best glue for pizza,” it flagged this as a “common misconception.” I Tried Google’s New AI Tool for Learning—Here’s How It Went!
I Tried Google’s New AI Tool for Learning—Here’s How It Went! 










 forget the complicated stuff, this open-source editor lets u edit images with just words!
forget the complicated stuff, this open-source editor lets u edit images with just words!  what’s your first creation gonna be? /search?q=#AI /search?q=#OpenSource /search?q=#SeedEdit /search?q=#Innovation
what’s your first creation gonna be? /search?q=#AI /search?q=#OpenSource /search?q=#SeedEdit /search?q=#Innovation













 @ain3sh for
@ain3sh for  unroll
unroll We’re super excited to introduce v4, enabling you to make any song you can imagine, with better audio, sharper lyrics, and more dynamic song structures. Try it now on
We’re super excited to introduce v4, enabling you to make any song you can imagine, with better audio, sharper lyrics, and more dynamic song structures. Try it now on  Cover Art: Fresh designs to compliment your music’s vibe
Cover Art: Fresh designs to compliment your music’s vibe Covers: Reimagine your track in new styles
Covers: Reimagine your track in new styles Personas: Unlock your musical alter-ego and maintain a consistent sound
Personas: Unlock your musical alter-ego and maintain a consistent sound : Tag us in your songs @sunomusic - we can’t wait to hear what you create!
: Tag us in your songs @sunomusic - we can’t wait to hear what you create!





 New Song: "The Diligent Ghost"
New Song: "The Diligent Ghost" Transparent thought process in real-time.
Transparent thought process in real-time. Open-source models & API coming soon!
Open-source models & API coming soon! Try it now at
Try it now at