1/27
@Presidentlin
[Quoted tweet]
After more than a year of development, we're excited to announce the release of

Transformers.js v3!

WebGPU support (up to 100x faster than WASM)

New quantization formats (dtypes)
🏛 120 supported architectures in total

25 new example projects and templates

Over 1200 pre-converted models

Node.js (ESM + CJS), Deno, and Bun compatibility

A new home on GitHub and NPM
Get started with `npm i @huggingface/transformers`.
Learn more in the blog post below!
 https://video.twimg.com/ext_tw_video/1848739447439036417/pu/vid/avc1/720x720/FYcMmsG5EzHEicpV.mp4
https://video.twimg.com/ext_tw_video/1848739447439036417/pu/vid/avc1/720x720/FYcMmsG5EzHEicpV.mp4
2/27
@Presidentlin
[Quoted tweet]
Announcing Moonshine, a fast ASR for real-time use cases. 5x faster than Whisper for 10 second segments. Inference code in Keras, so can run with Torch, JAX, and TensorFlow.
github.com/usefulsensors/moo…
3/27
@Presidentlin
[Quoted tweet]
BREAKING

: Ideogram is releasing its new feature called Canvas in beta.
This feature includes various options to work with images, including Remix, Extend, and Magic Fill, in addition to the generic image generation!
4/27
@Presidentlin
[Quoted tweet]
Introducing Multimodal Embed 3: Powering AI Search from @cohere

cohere.com/blog/multimodal-e…
5/27
@Presidentlin
[Quoted tweet]
Classification is the #1 downstream task for embeddings. It's recently popular for routing queries to LLMs too. We're excited to launch new Classifier API jina.ai/classifier/ - supports both zero-shot and few-shot online classification for text & image, powered by our latest jina-embeddings-v3 and jina-clip-v1.
6/27
@Presidentlin
[Quoted tweet]
Introducing Mochi 1 preview. A new SOTA in open-source video generation. Apache 2.0.
magnet:?xt=urn:btih:441da1af7a16bcaa4f556964f8028d7113d21cbb&dn=weights&tr=udp://tracker.opentrackr.org:1337/announce
https://video.twimg.com/ext_tw_video/1848745801926795264/pu/vid/avc1/1920x1080/zCXCFAyOnvznHUAf.mp4
7/27
@Presidentlin
[Quoted tweet]
The next one on today's playlist - Genmo just launched Mochi 1 preview, open-source video generation model utilizing asymmetric diffusion transformers, with weights available for deployment and HD version planned for Q4 2024
- The model generates 480p videos at 30fps with maximum duration of 5.4 seconds using a 10B parameter architecture running on T5-XXL encoder
- Genmo secured $28.4M Series A funding and published model weights on HuggingFace under Apache 2.0 license for public deployment
- Running the model locally requires a minimum of 4 NVIDIA H100 GPUs
8/27
@Presidentlin
[Quoted tweet]
Closed AI won the left brain of AGI. We're here to make sure there's an open alternative for the right brain.
Mochi 1 sets a new SOTA for open-source video generation models. It is the strongest OSS model in the ecosystem. This will be a force for good, both for AI research and for video generation products.
We are on the cusp of seeing the cost of high-fidelity video generation drop by 5 orders of magnitude. Join us on our journey.
9/27
@Presidentlin
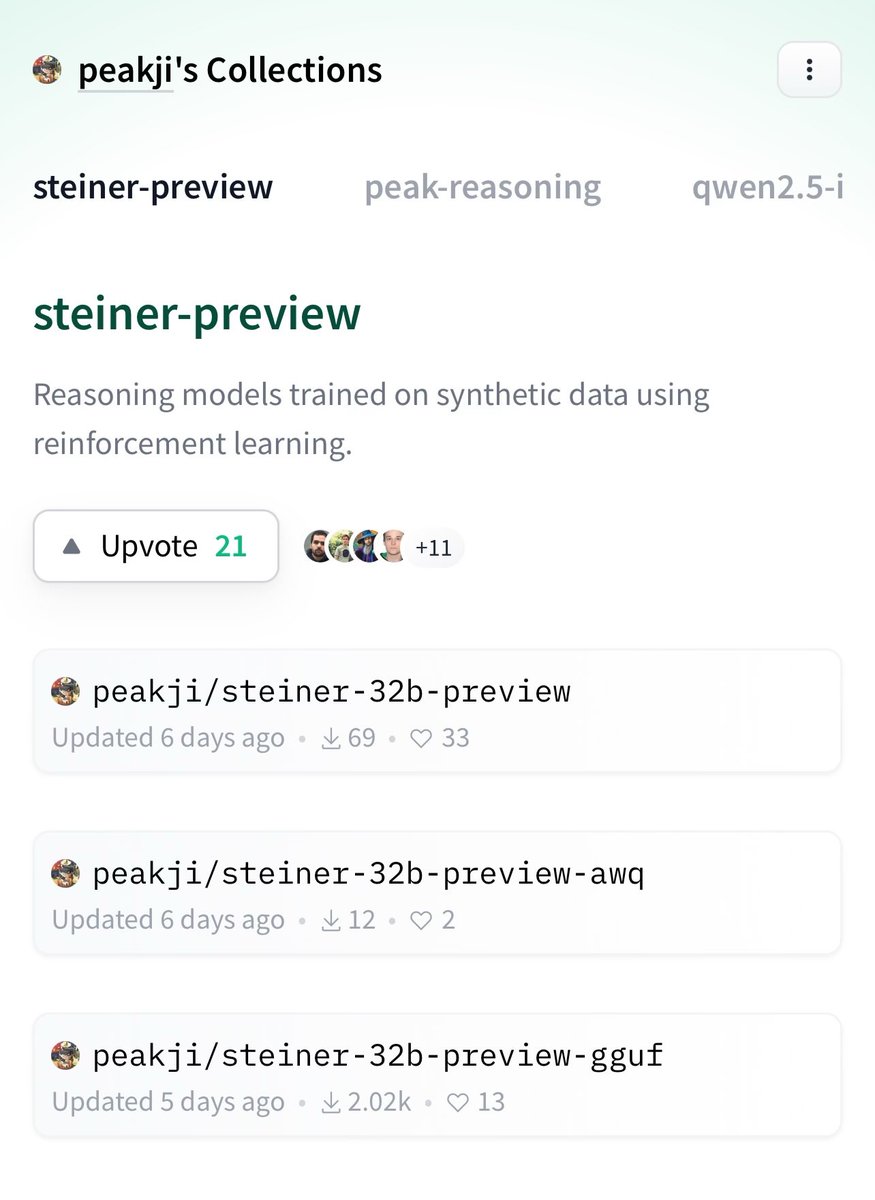
TL;DR
Steiner is a reasoning model capable of exploring multiple reasoning paths in an auto regressive manner during inference, autonomously verifying or backtracking as needed.
medium.com/@peakji/a-small-s…
10/27
@Presidentlin
[Quoted tweet]
I'm really excited to share a side project that I've been working on since the release of OpenAI o1:
Steiner - A series of reasoning models trained on synthetic data using reinforcement learning.
Blog: link.medium.com/DZcWuargUNb
HF: huggingface.co/collections/p…
11/27
@Presidentlin
[Quoted tweet]
Your search can see now.
We're excited to release fully multimodal embeddings for folks to start building with!
12/27
@Presidentlin
[Quoted tweet]
Introducing, Act-One. A new way to generate expressive character performances inside Gen-3 Alpha using a single driving video and character image. No motion capture or rigging required.
Learn more about Act-One below.
(1/7)
https://video.twimg.com/ext_tw_video/1848783440801333248/pu/vid/avc1/1280x720/2EyYj6GjSpT_loQf.mp4
13/27
@Presidentlin
[Quoted tweet]
Introducing Solver, a new AI-native programming tool from a good chunk of the former Siri team. More here: solverai.com/ .
Here Mark Gabel, CEO/founder of Laredo Labs gives us a good first look. Blew me away, but I'm not a programmer, are you? What you think?
Also says some outrageous things, like humans who program will still have jobs. :-)
https://video.twimg.com/amplify_video/1848739320863330312/vid/avc1/1280x720/vqzJIXRyVyuCJxDe.mp4
14/27
@Presidentlin
The releases continue, I thought we would have a break today
[Quoted tweet]
Introducing Voice Design.
Generate a unique voice from a text prompt alone.
Is our library missing a voice you need? Prompt your own.
https://video.twimg.com/ext_tw_video/1849079785869242368/pu/vid/avc1/1920x1080/-KskVTGRpKBhWGBq.mp4
15/27
@Presidentlin
[Quoted tweet]
Liquid AI announced Multimodal LFMs, which include Audio LFM and Vision LFM
- Audio LFM has 3.9 billion parameters, can process hours of audio input, supports speech-to-text and speech-to-speech tasks
- Vision LFM has 3.8 billion parameters, supports an 8k context length, processes text and image inputs into text in an autoregressive way, and has a maximum input resolution of 768x768
16/27
@Presidentlin
[Quoted tweet]
Our latest generative technology is now powering MusicFX DJ in @LabsDotGoogle - and we’ve also updated Music AI Sandbox, a suite of experimental music tools which can streamline creation.

This will make it easier than ever to make music in real-time with AI.

goo.gle/4eTg28Z
17/27
@Presidentlin
[Quoted tweet]
Today, we’re open-sourcing our SynthID text watermarking tool through an updated Responsible Generative AI Toolkit.
Available freely to developers and businesses, it will help them identify their AI-generated content.

Find out more → goo.gle/40apGQh
https://video.twimg.com/ext_tw_video/1849103528813285376/pu/vid/avc1/1280x720/G5K0TaljbmDqO-lP.mp4
18/27
@Presidentlin
[Quoted tweet]
BREAKING
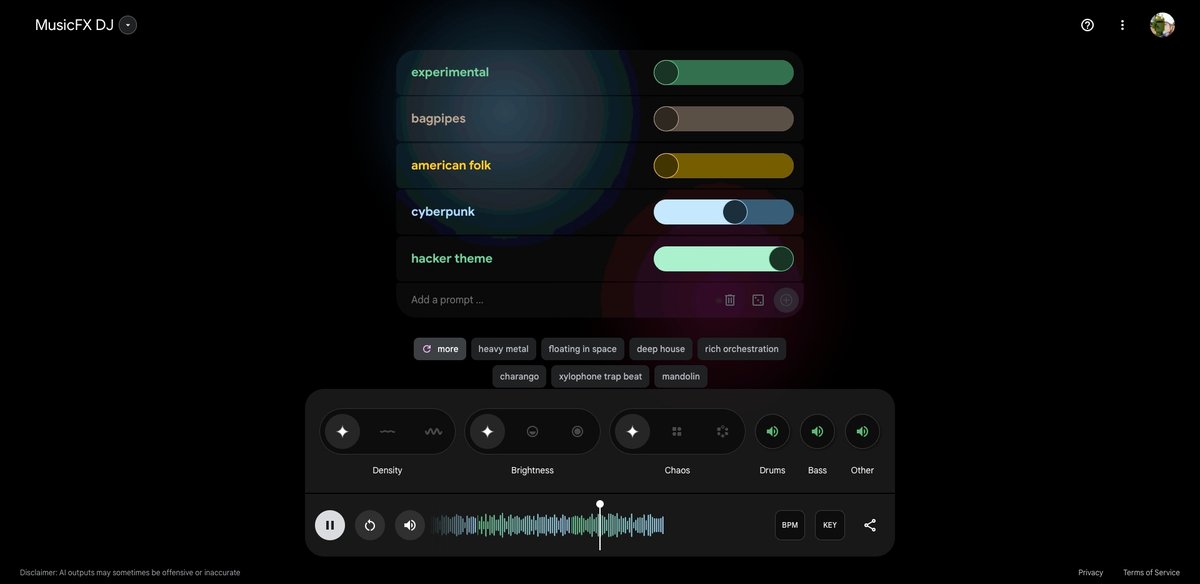
: Google released MusicFX DJ - a new ai generated music experiment on AI Test Kitchen.
This tool lets you generate music themes via text prompts and remix them via various UI controls.
19/27
@Presidentlin
[Quoted tweet]
We're testing two new features today: our image editor for uploaded images and image re-texturing for exploring materials, surfacing, and lighting. Everything works with all our advanced features, such as style references, character references, and personalized models
https://video.twimg.com/ext_tw_video/1849212727253987328/pu/vid/avc1/1280x720/76T_-k7J8I7ATBL6.mp4
20/27
@Presidentlin
[Quoted tweet]
How did I miss this? Too many releases. @freepik Awesome work! It works out of the box with ai-toolkit. Training first test LoRA now.
huggingface.co/Freepik/flux.…
21/27
@Presidentlin
[Quoted tweet]
Introducing
Aya Expanse
– an open-weights state-of-art family of models to help close the language gap with AI.
Aya Expanse is both global and local. Driven by a multi-year commitment to multilingual research.
cohere.com/research/aya
https://video.twimg.com/ext_tw_video/1849435850167250944/pu/vid/avc1/1280x720/fZNILiRWUSF-FQp-.mp4
22/27
@Presidentlin
[Quoted tweet]
We want to make it easier for more people to build with Llama — so today we’re releasing new quantized versions of Llama 3.2 1B & 3B that deliver up to 2-4x increases in inference speed and, on average, 56% reduction in model size, and 41% reduction in memory footprint.
Details on our new quantized Llama 3.2 on-device models

ai.meta.com/blog/meta-llama-…
While quantized models have existed in the community before, these approaches often came at a tradeoff between performance and accuracy. To solve this, we Quantization-Aware Training with LoRA adaptors as opposed to only post-processing. As a result, our new models offer a reduced memory footprint, faster on-device inference, accuracy and portability — while maintaining quality and safety for developers to deploy on resource-constrained devices.
The new models can be downloaded now from Meta and on @huggingface.
23/27
@Presidentlin
[Quoted tweet]
Claude can now write and run code to perform calculations and analyze data from CSVs using our new analysis tool.
After the analysis, it can render interactive visualizations as Artifacts.
https://video.twimg.com/ext_tw_video/1849463452189839360/pu/vid/avc1/1920x1080/nVEM6MeEMkmauxn2.mp4
24/27
@Presidentlin
[Quoted tweet]
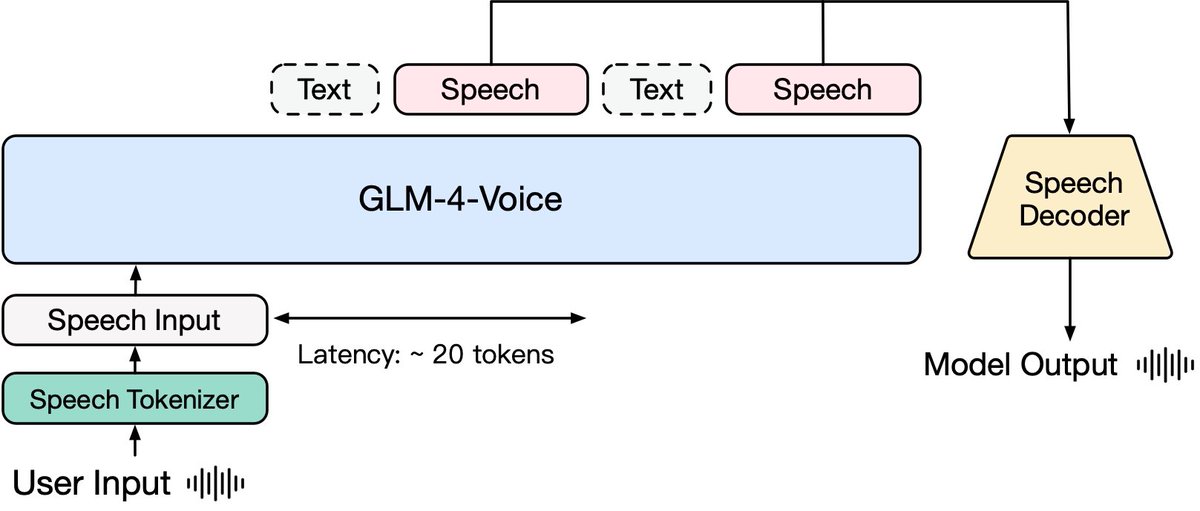
End-to-End Speech / text model GLM-4-Voice from @ChatGLM
- Support both Chinese and English
- Tokenizer fine-tuned from Whisper encoder
- Decoder based on CosyVoice to convert discrete tokens to speech
Homepage github.com/THUDM/GLM-4-Voice…
@huggingface : huggingface.co/collections/x…
25/27
@Presidentlin
[Quoted tweet]
Late chunking is resilient to poor boundaries, but this doesn't mean we can ignore them—they still matter for both human and LLM readability. In this post, jina.ai/news/finding-optimal… we experimented three small language models to better segment long documents into chunks, and here's our perspective: when determining breakpoints, we can now fully concentrate on semantic coherence and readability, without worrying about context loss, thanks to late chunking.
26/27
@Presidentlin
[Quoted tweet]
We just released the weights of Pixtral 12B base model on HuggingFace:
Pixtral 12B Base:
huggingface.co/mistralai/Pix…
Also link to Pixtral 12B Instruct:
huggingface.co/mistralai/Pix…
27/27
@Presidentlin
[Quoted tweet]
Meta MelodyFlow
huggingface.co/collections/f…

/cdn.vox-cdn.com/uploads/chorus_asset/file/25715032/aa1_102024_xrayrecaps_standard_hero_v1_600kb_2000x1125.jpg)
:format(webp)/cdn.vox-cdn.com/uploads/chorus_asset/file/25715032/aa1_102024_xrayrecaps_standard_hero_v1_600kb_2000x1125.jpg "A photo of Amazon’s X-Ray Recaps feature.")
:format(webp)/cdn.vox-cdn.com/uploads/chorus_asset/file/25715039/90.jpeg "An example X-Ray Recap summary from Amazon about an episode of the show “Upload.”")




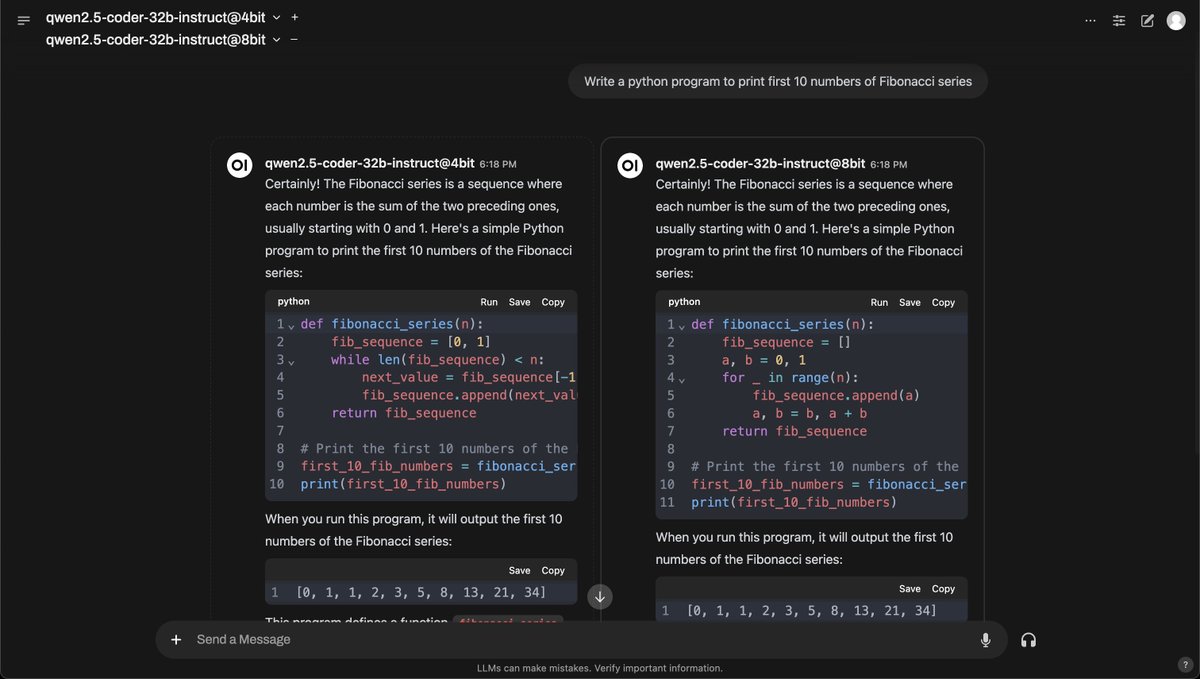


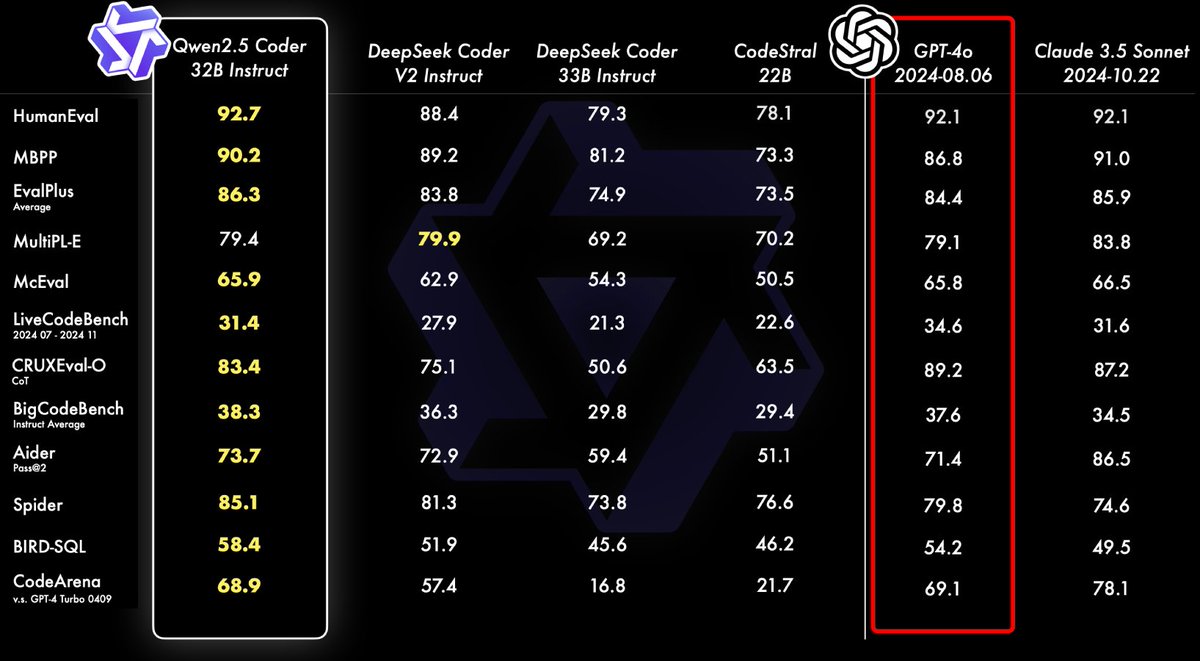

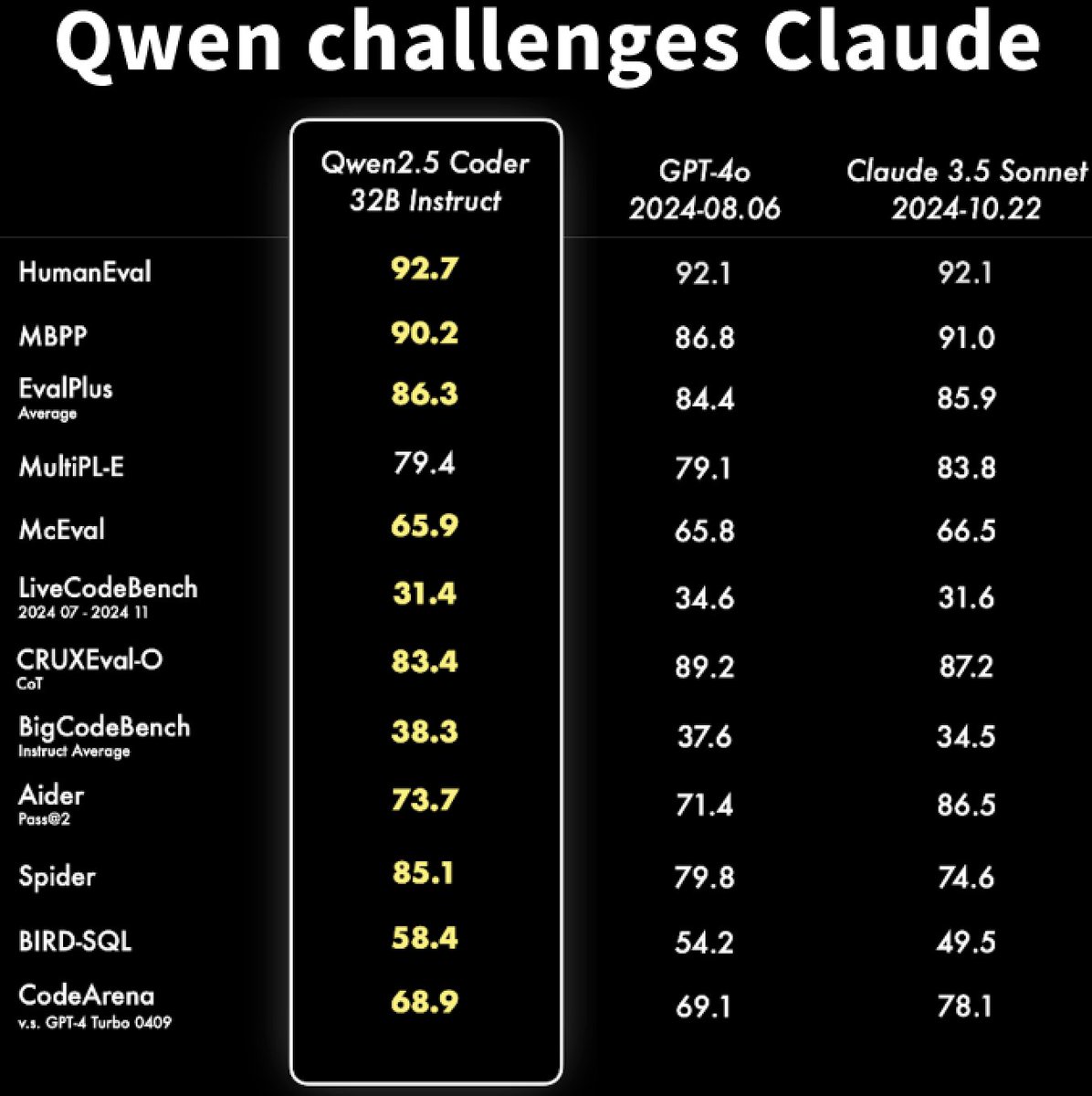
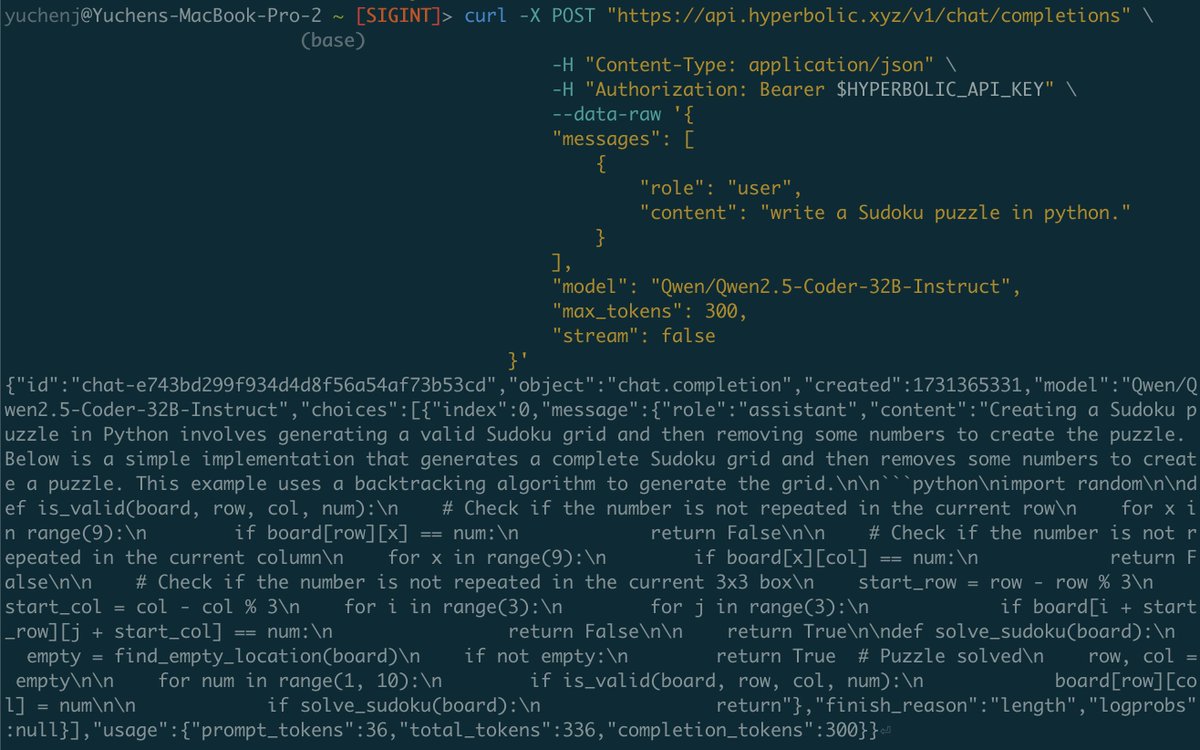


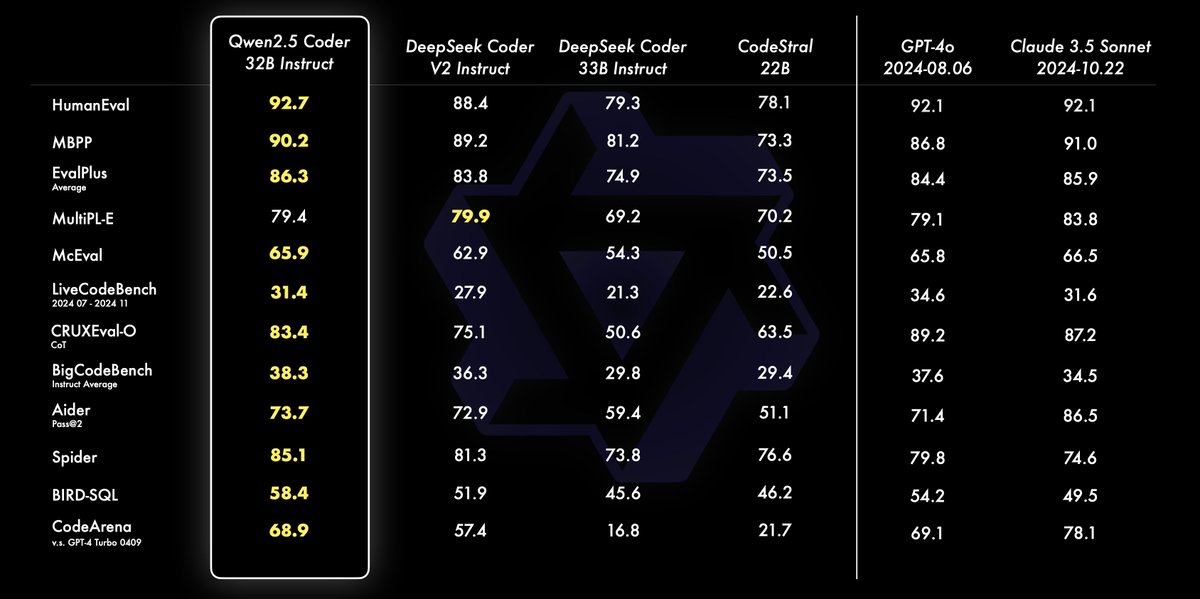
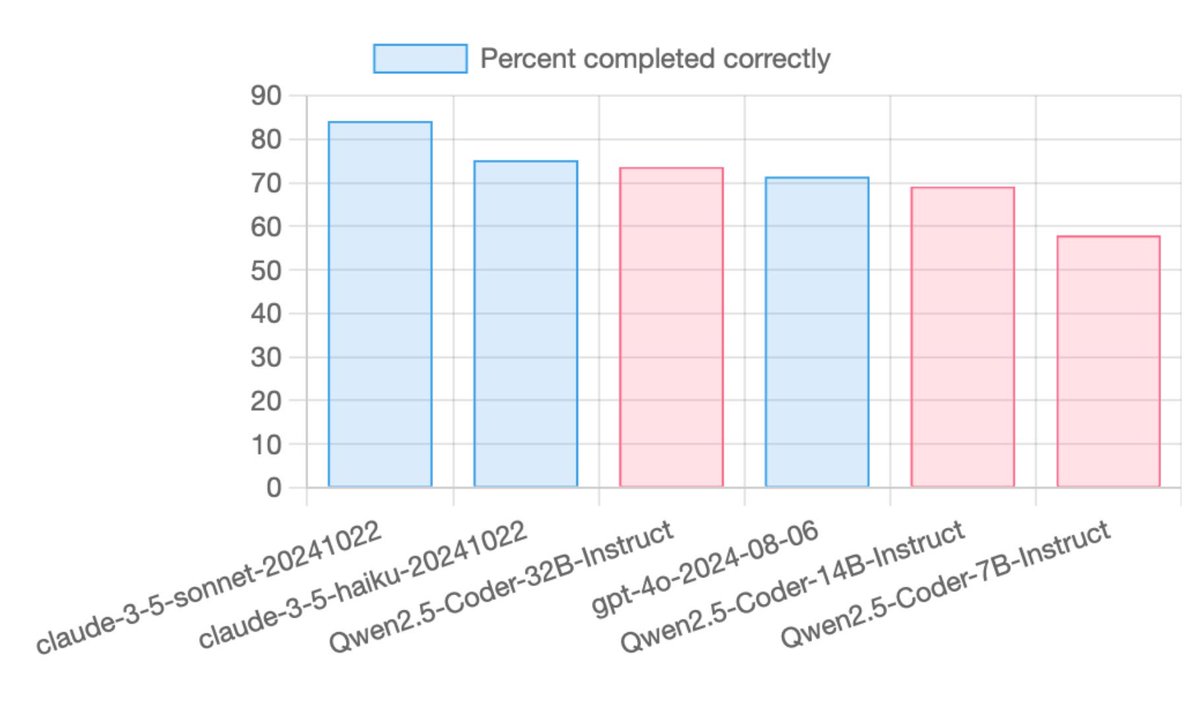
 Qwen2.5-Coder Instruct demos:
Qwen2.5-Coder Instruct demos:  Qwen2.5-Coder 7B Instruct:
Qwen2.5-Coder 7B Instruct:  Open source FTW
Open source FTW  Our tutorial on using Qwen2.5 Coder 32B on Hyperstack is coming very soon - keep an eye out!
Our tutorial on using Qwen2.5 Coder 32B on Hyperstack is coming very soon - keep an eye out!