
You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
The A.I Megathread (LLM , GPT , Development)
More options
Who Replied?Diffusion models are evolutionary algorithms | Hacker News
 news.ycombinator.com
news.ycombinator.com
1/30
@OpenAI
Factuality is one of the biggest open problems in the deployment of artificial intelligence.
We are open-sourcing a new benchmark called SimpleQA that measures the factuality of language models. https://openai.com/index/introducing-simpleqa/
2/30
@Klotzkette
Can you also just make sure that your great tool is not making up case law anymore, in answers and in search? Getting really annoying that this is not improving at all.
3/30
@MrTimothy1971
Entertainment proposes only. that would be my disclaimer. because there could be a lawsuit action if some gets the wrong information, and it harms them. as stupid as people are. so, to cover your butts you need Disclaimers. trust me in this day and age you need it.
4/30
@MrTimothy1971
don't get mad at me for saying it. just contemplate what I said.
5/30
@pattty847
When open ai?
6/30
@abe_chira
In english, please.
7/30
@TallPhilosopher
I get better results when I point out in my 'About me' and 'My goals' sections that subsidies are wasteful and divisive, and Fee-and-Dividend will produce the desired outcomes without need for government micromanagement of the econ. But everyone else still gets fed Green New Deal
8/30
@StevenHasty1
By what standard is something factual?
9/30
@DesFrontierTech
How does SimpleQA's approach to adversarially designing questions impact the overall effectiveness of model training in addressing factuality and reducing hallucinations in language models?
10/30
@ai_for_success
Huge difference between o1-mini and o1-preview.. That's surprising.

11/30
@testingcatalog
Politics is always tricky Almost as sience & tech
Almost as sience & tech

12/30
@per_anders
And we should trust this why?
You know the questions, you’ll add the answers. Ergo your engine will score highest yet never change from standard deviation of accuracy.
You have no credibility here.
13/30
@theaievangelist
Interesting pattern: OpenAI's o1-preview and GPT-4 models show high "Correct" rates (42.7% and 38.2%) but also high "Incorrect" rates, while their mini versions are more conservative, and Claude's "Incorrect" rates are substantially lower.

14/30
@LechMazur
It will be interesting to see more models tested and how they compare to the results from my confabulations/hallucinations benchmark on provided texts.


15/30
@WorldEverett
I hope to see the full version of o1 to test it!
16/30
@JosephJacks_
Do more open source!
17/30
@thegenioo
So guys gpt-4o-mini has been just yappinh all the time?
Btw this is absolutely amazing from you guys Thank you!

18/30
@mtochs
Factuality is increasingly defined by emotional people rather than field-tested data. All the frontier models except @grok favor subjective factuality over objective factuality.
19/30
@BensenHsu
The study presents a benchmark called SimpleQA that evaluates the ability of large language models to answer short, fact-seeking questions. The researchers designed SimpleQA to be challenging and have a single, indisputable answer for each question.
The researchers evaluated several OpenAI and Anthropic language models on the SimpleQA benchmark. They found that larger models generally performed better than smaller models, with GPT-4o outperforming GPT-4o-mini and the Claude-3 series of models performing better than the smaller OpenAI models. However, even the best-performing models scored less than 50% on the benchmark.
full paper: Measuring short-form factuality in large language models

20/30
@rohanpaul_ai
Some Insights from the Paper
• Larger models show better performance and calibration. calibration in this context refers to whether LLMs "know what they know" - essentially measuring if the model's confidence matches its actual accuracy.
• Models consistently overstate their confidence
• Answer frequency correlates with accuracy
• Claude attempt fewer questions than GPT models

21/30
@AyMoMusic
The best Christmas present this year would be leaking the f*ck out of o1 and Sora source codes.
22/30
@Caduceus_CAD
 Amazing initiative with /search?q=#SimpleQA! /search?q=#Caduceus is here to support projects that push AI and AIGC boundaries
Amazing initiative with /search?q=#SimpleQA! /search?q=#Caduceus is here to support projects that push AI and AIGC boundaries  With our edge-rendering power and scalable blockchain infrastructure, we're all set for next-gen AI deployments. Welcome to build on CAD’s innovative platform! /search?q=#Caduceus /search?q=#AI /search?q=#DePIN
With our edge-rendering power and scalable blockchain infrastructure, we're all set for next-gen AI deployments. Welcome to build on CAD’s innovative platform! /search?q=#Caduceus /search?q=#AI /search?q=#DePIN
23/30
@web3nam3



24/30
@the_aiatlas
This is big.
Who do you think will be on top there?
25/30
@ajaycan
The idea of "factuality" in artificial intelligence, especially in language models like ChatGPT, is about making sure the information these AI tools provide is true and accurate. Imagine you're asking a knowledgeable friend questions, and you expect them to give you real, correct answers based on what they know. But if this friend sometimes makes things up or gets confused, it could be a problem, especially if you're relying on them for important facts.
### Example Analogy
Imagine you have a library with thousands of books, and each book has different bits of information about various topics. Now, if you ask a question, someone gathers information from all these books to give you an answer. But here’s the catch: some books have outdated or incorrect information, while others are reliable and trustworthy. If the person gathering answers can't tell which books are trustworthy, they might give you incorrect answers.
AI models face a similar problem. They learn from massive amounts of data on the internet, which contains both factual and incorrect information. Without a way to tell what’s right, they might provide answers that seem correct but are inaccurate. This is where *factuality* benchmarks, like **SimpleQA**, come in. They help test and improve how accurately AI models give factual answers.
### What is SimpleQA?
SimpleQA is like a “truth test” for AI. It's a set of questions designed to see if an AI model can answer factual questions correctly. By asking simple, straightforward questions that have clear, factual answers, researchers can measure how well the AI distinguishes fact from fiction. For example:
- **Q:** Who was the first president of the United States?
**A:** George Washington.
*Correct, factual answer.*
- **Q:** How many moons does Mars have?
**A:** Two (Phobos and Deimos).
*Correct, factual answer.*
The purpose of SimpleQA is to ensure that, when people ask questions, they get reliable information instead of mistakes or made-up facts.
### Philosophy of Factuality in AI
Philosophically, factuality in AI touches on truth, trust, and responsibility. For AI to be helpful and trustworthy, it needs to reflect truth as much as possible. Think of it like this: just as we aim to tell the truth in our own lives to maintain trust with others, AI must "learn" the importance of truth to build a good relationship with users. SimpleQA and similar benchmarks are small steps in a larger journey to make AI responsible and dependable—values that are fundamental to making AI a reliable tool for society.
26/30
@RaphI_I
Wokeless ?
27/30
@anniealtman108
https://video.twimg.com/amplify_video/1851691195082440704/vid/avc1/720x1280/e7pFfoCVCIPFh-bW.mp4
28/30
@anniealtman108


29/30
@anniealtman108
https://www.lesswrong.com/posts/QDc...s-sister-annie-altman-claims-sam-has-severely

30/30
@anniealtman108
[Quoted tweet]
So how many of these do I need to collect?
Hypothetically, could I turn these into some kind of card game?




To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
@OpenAI
Factuality is one of the biggest open problems in the deployment of artificial intelligence.
We are open-sourcing a new benchmark called SimpleQA that measures the factuality of language models. https://openai.com/index/introducing-simpleqa/
2/30
@Klotzkette
Can you also just make sure that your great tool is not making up case law anymore, in answers and in search? Getting really annoying that this is not improving at all.
3/30
@MrTimothy1971
Entertainment proposes only. that would be my disclaimer. because there could be a lawsuit action if some gets the wrong information, and it harms them. as stupid as people are. so, to cover your butts you need Disclaimers. trust me in this day and age you need it.
4/30
@MrTimothy1971
don't get mad at me for saying it. just contemplate what I said.
5/30
@pattty847
When open ai?
6/30
@abe_chira
In english, please.
7/30
@TallPhilosopher
I get better results when I point out in my 'About me' and 'My goals' sections that subsidies are wasteful and divisive, and Fee-and-Dividend will produce the desired outcomes without need for government micromanagement of the econ. But everyone else still gets fed Green New Deal
8/30
@StevenHasty1
By what standard is something factual?
9/30
@DesFrontierTech
How does SimpleQA's approach to adversarially designing questions impact the overall effectiveness of model training in addressing factuality and reducing hallucinations in language models?
10/30
@ai_for_success
Huge difference between o1-mini and o1-preview.. That's surprising.
11/30
@testingcatalog
Politics is always tricky
Almost as sience & tech
12/30
@per_anders
And we should trust this why?
You know the questions, you’ll add the answers. Ergo your engine will score highest yet never change from standard deviation of accuracy.
You have no credibility here.
13/30
@theaievangelist
Interesting pattern: OpenAI's o1-preview and GPT-4 models show high "Correct" rates (42.7% and 38.2%) but also high "Incorrect" rates, while their mini versions are more conservative, and Claude's "Incorrect" rates are substantially lower.
14/30
@LechMazur
It will be interesting to see more models tested and how they compare to the results from my confabulations/hallucinations benchmark on provided texts.
15/30
@WorldEverett
I hope to see the full version of o1 to test it!
16/30
@JosephJacks_
Do more open source!
17/30
@thegenioo
So guys gpt-4o-mini has been just yappinh all the time?
Btw this is absolutely amazing from you guys Thank you!
18/30
@mtochs
Factuality is increasingly defined by emotional people rather than field-tested data. All the frontier models except @grok favor subjective factuality over objective factuality.
19/30
@BensenHsu
The study presents a benchmark called SimpleQA that evaluates the ability of large language models to answer short, fact-seeking questions. The researchers designed SimpleQA to be challenging and have a single, indisputable answer for each question.
The researchers evaluated several OpenAI and Anthropic language models on the SimpleQA benchmark. They found that larger models generally performed better than smaller models, with GPT-4o outperforming GPT-4o-mini and the Claude-3 series of models performing better than the smaller OpenAI models. However, even the best-performing models scored less than 50% on the benchmark.
full paper: Measuring short-form factuality in large language models
20/30
@rohanpaul_ai
Some Insights from the Paper
• Larger models show better performance and calibration. calibration in this context refers to whether LLMs "know what they know" - essentially measuring if the model's confidence matches its actual accuracy.
• Models consistently overstate their confidence
• Answer frequency correlates with accuracy
• Claude attempt fewer questions than GPT models
21/30
@AyMoMusic
The best Christmas present this year would be leaking the f*ck out of o1 and Sora source codes.
22/30
@Caduceus_CAD
Amazing initiative with /search?q=#SimpleQA! /search?q=#Caduceus is here to support projects that push AI and AIGC boundaries With our edge-rendering power and scalable blockchain infrastructure, we're all set for next-gen AI deployments. Welcome to build on CAD’s innovative platform! /search?q=#Caduceus /search?q=#AI /search?q=#DePIN23/30
@web3nam3
24/30
@the_aiatlas
This is big.
Who do you think will be on top there?
25/30
@ajaycan
The idea of "factuality" in artificial intelligence, especially in language models like ChatGPT, is about making sure the information these AI tools provide is true and accurate. Imagine you're asking a knowledgeable friend questions, and you expect them to give you real, correct answers based on what they know. But if this friend sometimes makes things up or gets confused, it could be a problem, especially if you're relying on them for important facts.
### Example Analogy
Imagine you have a library with thousands of books, and each book has different bits of information about various topics. Now, if you ask a question, someone gathers information from all these books to give you an answer. But here’s the catch: some books have outdated or incorrect information, while others are reliable and trustworthy. If the person gathering answers can't tell which books are trustworthy, they might give you incorrect answers.
AI models face a similar problem. They learn from massive amounts of data on the internet, which contains both factual and incorrect information. Without a way to tell what’s right, they might provide answers that seem correct but are inaccurate. This is where *factuality* benchmarks, like **SimpleQA**, come in. They help test and improve how accurately AI models give factual answers.
### What is SimpleQA?
SimpleQA is like a “truth test” for AI. It's a set of questions designed to see if an AI model can answer factual questions correctly. By asking simple, straightforward questions that have clear, factual answers, researchers can measure how well the AI distinguishes fact from fiction. For example:
- **Q:** Who was the first president of the United States?
**A:** George Washington.
*Correct, factual answer.*
- **Q:** How many moons does Mars have?
**A:** Two (Phobos and Deimos).
*Correct, factual answer.*
The purpose of SimpleQA is to ensure that, when people ask questions, they get reliable information instead of mistakes or made-up facts.
### Philosophy of Factuality in AI
Philosophically, factuality in AI touches on truth, trust, and responsibility. For AI to be helpful and trustworthy, it needs to reflect truth as much as possible. Think of it like this: just as we aim to tell the truth in our own lives to maintain trust with others, AI must "learn" the importance of truth to build a good relationship with users. SimpleQA and similar benchmarks are small steps in a larger journey to make AI responsible and dependable—values that are fundamental to making AI a reliable tool for society.
26/30
@RaphI_I
Wokeless ?
27/30
@anniealtman108
https://video.twimg.com/amplify_video/1851691195082440704/vid/avc1/720x1280/e7pFfoCVCIPFh-bW.mp4
28/30
@anniealtman108
29/30
@anniealtman108
https://www.lesswrong.com/posts/QDc...s-sister-annie-altman-claims-sam-has-severely
30/30
@anniealtman108
[Quoted tweet]
So how many of these do I need to collect?
Hypothetically, could I turn these into some kind of card game?
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
o1-mini tends to get better results on the 2024 American Invitational Mathematics Examination (AIME) when it's told to use more tokens - the "just ask o1-mini to think longer" region of the chart. See comment for details.
1/1
@AaronGDillon
Mistral launches AI moderation API | @MistralAI
https://video.twimg.com/ext_tw_video/1856713844065796096/pu/vid/avc1/1280x720/sO6G2JXHoSso3CGW.mp4
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
@AaronGDillon
Mistral launches AI moderation API | @MistralAI
https://video.twimg.com/ext_tw_video/1856713844065796096/pu/vid/avc1/1280x720/sO6G2JXHoSso3CGW.mp4
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
1/9
@skillissues99
 AI Engineers, last week’s releases were too big to miss.
AI Engineers, last week’s releases were too big to miss.
My notes from @NousResearch, @MistralAI, @Apple, @Microsoft, @llama_index to get you back on level

2/9
@skillissues99
 @NousResearch released Hermes 3-70B!
@NousResearch released Hermes 3-70B!
An open-source chatbot that's a developer's dream:
- Advanced long-term context retention
- Multi-turn conversations
- Complex role-playing abilities
- Enhanced agentic function-calling
I believe Hermes 3 is set to redefine open-source LLM performance.

3/9
@skillissues99
 @MistralAI launched a customizable content moderation API! Powered by the Mistral Moderation model based on Mistral 8B 24.10:
@MistralAI launched a customizable content moderation API! Powered by the Mistral Moderation model based on Mistral 8B 24.10:
- Detects harmful text across multiple policy dimensions
- Offers endpoints for raw text and conversational content
- Customizable safety features
Pretty useful for enterprise-grade customer-facing applications.

4/9
@skillissues99
 @llama_index introduces a customizable React library for LLM chat interfaces!
@llama_index introduces a customizable React library for LLM chat interfaces!
llamaindex/chat-ui offers:
- Pre-built chat components
- Full Tailwind CSS customization
- Custom widgets for extended functionality
- TypeScript support
- Easy LLM backend integration

5/9
@skillissues99
 Meet MoICL—Mixtures of In-Context Learners!
Meet MoICL—Mixtures of In-Context Learners!
This innovative approach:
- Reduces memory usage
- Boosts performance on noisy datasets
- Outperforms strong baselines by up to 13%
- More robust to out-of-domain, imbalanced, or noisy data
MoICL brings us closer to efficient and robust in-context learning.

6/9
@skillissues99
 Ferret-UI 2 from @Apple revolutionizes universal UI understanding!
Ferret-UI 2 from @Apple revolutionizes universal UI understanding!
A multimodal LLM designed for platforms like:
- iPhone
- Android
- iPad
- Webpage
- AppleTV
Key innovations:
- Supports multiple platform types
- High-resolution perception through adaptive scaling
- Advanced task training data generation
UI understanding is getting a lot smarter.

7/9
@skillissues99
 @Microsoft introduces Magentic-One—a new framework for multi-agent systems!
@Microsoft introduces Magentic-One—a new framework for multi-agent systems!
- Solves open-ended web and file-based tasks
- Employs a multi-agent architecture with an Orchestrator agent
- Open-source implementation available on Microsoft AutoGen
- Represents a significant step towards practical agentic AI
We all know that the future is definitely agentic!

8/9
@skillissues99
 Ollama 0.4 integrates Meta's Llama 3.2 Vision models!
Ollama 0.4 integrates Meta's Llama 3.2 Vision models!
- Terminal-based image analysis is now a reality
- Available in both 11B and 90B sizes
- Brings powerful vision capabilities directly to your terminal
Local image analysis once again just got a boost with Ollama!

9/9
@skillissues99
I regularly share latest updates and repositories to build production-grade GenAI applications
Drop a comment, say hi and follow for more
and follow for more 
https://xcancel.com/skillissues99
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
@skillissues99
AI Engineers, last week’s releases were too big to miss.My notes from @NousResearch, @MistralAI, @Apple, @Microsoft, @llama_index to get you back on level
2/9
@skillissues99
@NousResearch released Hermes 3-70B!An open-source chatbot that's a developer's dream:
- Advanced long-term context retention
- Multi-turn conversations
- Complex role-playing abilities
- Enhanced agentic function-calling
I believe Hermes 3 is set to redefine open-source LLM performance.
3/9
@skillissues99
@MistralAI launched a customizable content moderation API! Powered by the Mistral Moderation model based on Mistral 8B 24.10:- Detects harmful text across multiple policy dimensions
- Offers endpoints for raw text and conversational content
- Customizable safety features
Pretty useful for enterprise-grade customer-facing applications.
4/9
@skillissues99
@llama_index introduces a customizable React library for LLM chat interfaces!llamaindex/chat-ui offers:
- Pre-built chat components
- Full Tailwind CSS customization
- Custom widgets for extended functionality
- TypeScript support
- Easy LLM backend integration
5/9
@skillissues99
Meet MoICL—Mixtures of In-Context Learners!This innovative approach:
- Reduces memory usage
- Boosts performance on noisy datasets
- Outperforms strong baselines by up to 13%
- More robust to out-of-domain, imbalanced, or noisy data
MoICL brings us closer to efficient and robust in-context learning.
6/9
@skillissues99
Ferret-UI 2 from @Apple revolutionizes universal UI understanding!A multimodal LLM designed for platforms like:
- iPhone
- Android
- iPad
- Webpage
- AppleTV
Key innovations:
- Supports multiple platform types
- High-resolution perception through adaptive scaling
- Advanced task training data generation
UI understanding is getting a lot smarter.
7/9
@skillissues99
@Microsoft introduces Magentic-One—a new framework for multi-agent systems!- Solves open-ended web and file-based tasks
- Employs a multi-agent architecture with an Orchestrator agent
- Open-source implementation available on Microsoft AutoGen
- Represents a significant step towards practical agentic AI
We all know that the future is definitely agentic!
8/9
@skillissues99
Ollama 0.4 integrates Meta's Llama 3.2 Vision models!- Terminal-based image analysis is now a reality
- Available in both 11B and 90B sizes
- Brings powerful vision capabilities directly to your terminal
Local image analysis once again just got a boost with Ollama!
9/9
@skillissues99
I regularly share latest updates and repositories to build production-grade GenAI applications
Drop a comment, say hi
and follow for more https://xcancel.com/skillissues99
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
1/10
@MarioNawfal
What’s new in the world of AI this week?
Here’s your roundup of all the game-changing updates.

2/10
@MarioNawfal
1. Apple's iOS 18.2 public beta introduces several new AI features, though some remain in limited testing and are only accessible to select users.

3/10
@MarioNawfal
2. OpenAI has acquired the domain Chat .com, adding a notable URL to its portfolio of high-profile web assets.

4/10
@MarioNawfal
3. The former AR lead for Meta’s smart glasses, including the Orion project, ‘Caitlin Kalinowski’ has joined OpenAI to spearhead its robotics and consumer hardware efforts.

5/10
@MarioNawfal
4. Amazon has introduced "X-Ray Recaps," a feature powered by generative AI that provides brief summaries of entire TV seasons, individual episodes, or even specific parts.
This tool aims to help viewers catch up quickly by offering concise overviews, making it easier to follow the storyline without watching the entire episode or season.

6/10
@MarioNawfal
5. Anthropic has launched its new AI model, Claude 3.5 Haiku, which comes at a higher price compared to its predecessor.
Unlike other models, it currently lacks the ability to analyze images, graphs, or diagrams.
Despite the price hike, it offers unique capabilities for text generation but may have limited versatility in handling multimedia content.
https://video.twimg.com/ext_tw_video/1855556978736529408/pu/vid/avc1/1478x720/fAE7RclxOU-RVKP1.mp4
7/10
@MarioNawfal
6. Apple has acquired Pixelmator, the AI-powered image editing app, as part of its strategy to integrate more AI into its imaging tools.
This acquisition signals Apple's push to enhance its photo and video editing capabilities using AI technology.
The deal marks a significant step in Apple's broader efforts to expand its AI-driven features across its software ecosystem.

8/10
@MarioNawfal
7. Anthropic has partnered with Palantir and Amazon Web Services (AWS) to provide U.S. intelligence and defense agencies access to its Claude AI models.
This collaboration will allow government entities to leverage advanced AI for various applications, marking a significant step in AI's role in defense and intelligence operations.

9/10
@MarioNawfal
8. Microsoft Outlook now allows users to create personalized themes powered by AI.
This feature helps users customize their email experience by tailoring themes based on personal preferences, making it easier to express individuality and improve productivity.
The AI-driven customization offers a more dynamic and engaging email interface for users.
https://video.twimg.com/ext_tw_video/1855557269821239296/pu/vid/avc1/640x360/jsreBNH9-6lXGnh8.mp4
10/10
@MarioNawfal
9. AI startup Mistral has launched a new API for content moderation, designed to be customized to specific applications and safety standards.
This API powers moderation for Mistral's Le Chat chatbot platform and is adaptable to different needs, providing enhanced control over content safety.
https://video.twimg.com/ext_tw_video/1855557393842675713/pu/vid/avc1/1548x720/fDvmp4kJBgT75vh8.mp4
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
@MarioNawfal
What’s new in the world of AI this week?
Here’s your roundup of all the game-changing updates.
2/10
@MarioNawfal
1. Apple's iOS 18.2 public beta introduces several new AI features, though some remain in limited testing and are only accessible to select users.
3/10
@MarioNawfal
2. OpenAI has acquired the domain Chat .com, adding a notable URL to its portfolio of high-profile web assets.
4/10
@MarioNawfal
3. The former AR lead for Meta’s smart glasses, including the Orion project, ‘Caitlin Kalinowski’ has joined OpenAI to spearhead its robotics and consumer hardware efforts.
5/10
@MarioNawfal
4. Amazon has introduced "X-Ray Recaps," a feature powered by generative AI that provides brief summaries of entire TV seasons, individual episodes, or even specific parts.
This tool aims to help viewers catch up quickly by offering concise overviews, making it easier to follow the storyline without watching the entire episode or season.
6/10
@MarioNawfal
5. Anthropic has launched its new AI model, Claude 3.5 Haiku, which comes at a higher price compared to its predecessor.
Unlike other models, it currently lacks the ability to analyze images, graphs, or diagrams.
Despite the price hike, it offers unique capabilities for text generation but may have limited versatility in handling multimedia content.
https://video.twimg.com/ext_tw_video/1855556978736529408/pu/vid/avc1/1478x720/fAE7RclxOU-RVKP1.mp4
7/10
@MarioNawfal
6. Apple has acquired Pixelmator, the AI-powered image editing app, as part of its strategy to integrate more AI into its imaging tools.
This acquisition signals Apple's push to enhance its photo and video editing capabilities using AI technology.
The deal marks a significant step in Apple's broader efforts to expand its AI-driven features across its software ecosystem.
8/10
@MarioNawfal
7. Anthropic has partnered with Palantir and Amazon Web Services (AWS) to provide U.S. intelligence and defense agencies access to its Claude AI models.
This collaboration will allow government entities to leverage advanced AI for various applications, marking a significant step in AI's role in defense and intelligence operations.
9/10
@MarioNawfal
8. Microsoft Outlook now allows users to create personalized themes powered by AI.
This feature helps users customize their email experience by tailoring themes based on personal preferences, making it easier to express individuality and improve productivity.
The AI-driven customization offers a more dynamic and engaging email interface for users.
https://video.twimg.com/ext_tw_video/1855557269821239296/pu/vid/avc1/640x360/jsreBNH9-6lXGnh8.mp4
10/10
@MarioNawfal
9. AI startup Mistral has launched a new API for content moderation, designed to be customized to specific applications and safety standards.
This API powers moderation for Mistral's Le Chat chatbot platform and is adaptable to different needs, providing enhanced control over content safety.
https://video.twimg.com/ext_tw_video/1855557393842675713/pu/vid/avc1/1548x720/fDvmp4kJBgT75vh8.mp4
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
1/1
@TheAIObserverX
Hunyuan-Large: An Open-Source MoE Model with 52 Billion Activated Parameters by Tencent
[2411.02265] Hunyuan-Large: An Open-Source MoE Model with 52 Billion Activated Parameters by Tencent

To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
@TheAIObserverX
Hunyuan-Large: An Open-Source MoE Model with 52 Billion Activated Parameters by Tencent
[2411.02265] Hunyuan-Large: An Open-Source MoE Model with 52 Billion Activated Parameters by Tencent
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
1/3
@DeepLearningAI
Tencent’s Hunyuan-Large model, a language model with a mixture of experts (MoE) architecture, surpasses open competitors like Llama 3.1 405B on multiple benchmarks, including math, coding, and multilingual tasks.
Learn more in /search?q=#TheBatch: Hunyuan-Large Outshines Open Competitors with High Benchmark Scores
2/3
@intheloopwithai
Nice to see multilingual tasks getting some love too
3/3
@SaadR_Biz
Impressive performance by Hunyuan-Large on various benchmarks! Its efficiency is remarkable, using only 52 billion parameters to process inputs. /search?q=#TheBatch
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
@DeepLearningAI
Tencent’s Hunyuan-Large model, a language model with a mixture of experts (MoE) architecture, surpasses open competitors like Llama 3.1 405B on multiple benchmarks, including math, coding, and multilingual tasks.
Learn more in /search?q=#TheBatch: Hunyuan-Large Outshines Open Competitors with High Benchmark Scores
2/3
@intheloopwithai
Nice to see multilingual tasks getting some love too
3/3
@SaadR_Biz
Impressive performance by Hunyuan-Large on various benchmarks! Its efficiency is remarkable, using only 52 billion parameters to process inputs. /search?q=#TheBatch
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
1/3
@TheTuringPost
Overview of new Tencent Hunyuan-Large model:
 It's the largest open-source Transformer-based MoE model
It's the largest open-source Transformer-based MoE model
Has 389 B total parameters and 52 B activation parameters
Outperforms the LLama3.1-70B model
Matches performance of the larger LLama3.1-405B
Architecture:
- KV cache compression: Groups and shares certain cache elements, saving up to 95% in memory.
- Recycle routing: Reallocates tokens from overloaded experts to less busy experts, preventing data loss and improving training efficiency.
- Expert-specific learning rates: Each expert has an optimized learning rate, improving training efficiency.
Uses a combination of 7 trillion tokens of natural and synthetic data, primarily in Chinese and English. The four-step process of data synthesis is used.
Post-training includes fine-tuning and reinforcement learning from human feedback (RLHF).
Extended long-context capabilities up to 256,000 tokens are especially useful for tasks, such as legal documents or scientific literature.


2/3
@TheTuringPost
Paper: https://arxiv.org/pdf/2411.02265
Code: GitHub - Tencent/Tencent-Hunyuan-Large
Models: tencent/Tencent-Hunyuan-Large · Hugging Face
3/3
@NextFrontierAI
Impressive to see Tencent's Hunyuan-Large pushing MoE models forward. Keen to learn more about its real-world applications!
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
@TheTuringPost
Overview of new Tencent Hunyuan-Large model:
It's the largest open-source Transformer-based MoE model Has 389 B total parameters and 52 B activation parameters Outperforms the LLama3.1-70B model Matches performance of the larger LLama3.1-405B Architecture:- KV cache compression: Groups and shares certain cache elements, saving up to 95% in memory.
- Recycle routing: Reallocates tokens from overloaded experts to less busy experts, preventing data loss and improving training efficiency.
- Expert-specific learning rates: Each expert has an optimized learning rate, improving training efficiency.
Uses a combination of 7 trillion tokens of natural and synthetic data, primarily in Chinese and English. The four-step process of data synthesis is used. Post-training includes fine-tuning and reinforcement learning from human feedback (RLHF). Extended long-context capabilities up to 256,000 tokens are especially useful for tasks, such as legal documents or scientific literature.
2/3
@TheTuringPost
Paper: https://arxiv.org/pdf/2411.02265
Code: GitHub - Tencent/Tencent-Hunyuan-Large
Models: tencent/Tencent-Hunyuan-Large · Hugging Face
3/3
@NextFrontierAI
Impressive to see Tencent's Hunyuan-Large pushing MoE models forward. Keen to learn more about its real-world applications!
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
1/1
@aswadi_didi
Tencent open source Hunyuan-Large 52Bil model beat Meta LLama3.1-405Bil
Power giler China
[2411.02265] Hunyuan-Large: An Open-Source MoE Model with 52 Billion Activated Parameters by Tencent

To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
@aswadi_didi
Tencent open source Hunyuan-Large 52Bil model beat Meta LLama3.1-405Bil
Power giler China
[2411.02265] Hunyuan-Large: An Open-Source MoE Model with 52 Billion Activated Parameters by Tencent
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
1/15
@TheTuringPost
The freshest AI/ML researches of the week, part 2
WEBRL: Training LLM Web Agents
DynaSaur: Large Language Agents
THANOS: Skill-Of-Mind-Infused Agents
DELIFT
HtmlRAG
M3DOCRAG
Needle Threading
Survey Of Cultural Awareness In LMs
OPENCODER
Polynomial Composition Activations
Hunyuan-Large
Balancing Pipeline Parallelism With Vocabulary Parallelism




2/15
@TheTuringPost
1. WEBRL: Training LLM Web Agents
Trains web agents with a curriculum that evolves through agent learning, improving task success rates.
[2411.02337] WebRL: Training LLM Web Agents via Self-Evolving Online Curriculum Reinforcement Learning
GitHub: GitHub - THUDM/WebRL: Building Open LLM Web Agents with Self-Evolving Online Curriculum RL

3/15
@TheTuringPost
2. DynaSaur: Large Language Agents Beyond Predefined Actions
Allows agents to create actions on-the-fly, handling unforeseen tasks with Python-based adaptability.
[2411.01747] DynaSaur: Large Language Agents Beyond Predefined Actions

4/15
@TheTuringPost
3. THANOS: Skill-Of-Mind-Infused Agents
Enhances conversational agents with social skills, improving response accuracy and empathy.
[2411.04496] Thanos: Enhancing Conversational Agents with Skill-of-Mind-Infused Large Language Model
GitHub: GitHub - passing2961/Thanos: Official code repository for our paper: Thanos: Enhancing Conversational Agents with Skill-of-Mind-Infused Large Language Model

5/15
@TheTuringPost
4. DELIFT: Data Efficient Language Model Instruction Fine-Tuning
Optimizes fine-tuning by selecting the most informative data, cutting dataset size significantly.
[2411.04425] DELIFT: Data Efficient Language model Instruction Fine Tuning

6/15
@TheTuringPost
5. HtmlRAG: HTML Is Better Than Plain Text
Improves RAG systems by preserving HTML structure, enhancing retrieval quality.
[2411.02959] HtmlRAG: HTML is Better Than Plain Text for Modeling Retrieved Knowledge in RAG Systems

7/15
@TheTuringPost
6. M3DOCRAG: Multi-Modal Retrieval For Document Understanding
Introduces a multimodal RAG framework to handle multi-page and document QA tasks with visual data.
[2411.04952] M3DocRAG: Multi-modal Retrieval is What You Need for Multi-page Multi-document Understanding

8/15
@TheTuringPost
7. Needle Threading: LLMs For Long-Context Retrieval
Examines LLMs’ retrieval capabilities, identifying limits in handling extended contexts.
[2411.05000] Needle Threading: Can LLMs Follow Threads through Near-Million-Scale Haystacks?
GitHub: Needle Threading

9/15
@TheTuringPost
8. Survey Of Cultural Awareness In Language Models
Reviews cultural inclusivity in LLMs, emphasizing diverse and ethically sound datasets.
[2411.00860] Survey of Cultural Awareness in Language Models: Text and Beyond
GitHub: GitHub - siddheshih/culture-awareness-llms

10/15
@TheTuringPost
9. OPENCODER: The Open Cookbook For Code Models
Provides a comprehensive open-source guide for building high-performance code LLMs.
[2411.04905] OpenCoder: The Open Cookbook for Top-Tier Code Large Language Models
[Quoted tweet]
A “how-to” guide on building top-tier Code LLM
OpenCoder is a fully open-source code model, matching top code models in performance. It comes with a cookbook, training data, processing methods, and experiment results.
This cookbook covers key components for code models:
- Data cleaning rules
- Methods to avoid duplicates
- Mixing of text and code data for better context
- High-quality synthetic data for training
Reproduce your own model with this guide!
The cookbook: arxiv.org/pdf/2411.04905
OpenCoder GitHub: opencoder-llm.github.io/


11/15
@TheTuringPost
10. Polynomial Composition Activations
Enhances model expressivity using polynomial activations, optimizing parameter efficiency.
[2411.03884] Polynomial Composition Activations: Unleashing the Dynamics of Large Language Models

12/15
@TheTuringPost
11. Hunyuan-Large: An Open-Source MoE Model
Presents a large-scale MoE model, excelling across language, math, and coding tasks.
[2411.02265] Hunyuan-Large: An Open-Source MoE Model with 52 Billion Activated Parameters by Tencent
GitHub: GitHub - BryceZhuo/PolyCom: The official implementation of Polynomial Composition Activations: Unleashing the Dynamics of Large Language Models.
[Quoted tweet]
Overview of new Tencent Hunyuan-Large model:
It's the largest open-source Transformer-based MoE model
Has 389 B total parameters and 52 B activation parameters
Outperforms the LLama3.1-70B model
Matches performance of the larger LLama3.1-405B
Architecture:
- KV cache compression: Groups and shares certain cache elements, saving up to 95% in memory.
- Recycle routing: Reallocates tokens from overloaded experts to less busy experts, preventing data loss and improving training efficiency.
- Expert-specific learning rates: Each expert has an optimized learning rate, improving training efficiency.
Uses a combination of 7 trillion tokens of natural and synthetic data, primarily in Chinese and English. The four-step process of data synthesis is used.
Post-training includes fine-tuning and reinforcement learning from human feedback (RLHF).
Extended long-context capabilities up to 256,000 tokens are especially useful for tasks, such as legal documents or scientific literature.
13/15
@TheTuringPost
12. Balancing Pipeline Parallelism With Vocabulary Parallelism
Improves transformer training efficiency by balancing memory across vocabulary layers.
[2411.05288] Balancing Pipeline Parallelism with Vocabulary Parallelism

14/15
@TheTuringPost
13. Find a complete list of the latest research papers in our free weekly digest: #75: What is Metacognitive AI
#75: What is Metacognitive AI
15/15
@TheTuringPost
14. Follow @TheTuringPost for more.
Like/repost the 1st post to support our work
Also, elevate your AI game with our free newsletter ↓
Turing Post
[Quoted tweet]
The freshest AI/ML researches of the week, part 2
WEBRL: Training LLM Web Agents
DynaSaur: Large Language Agents
THANOS: Skill-Of-Mind-Infused Agents
DELIFT
HtmlRAG
M3DOCRAG
Needle Threading
Survey Of Cultural Awareness In LMs
OPENCODER
Polynomial Composition Activations
Hunyuan-Large
Balancing Pipeline Parallelism With Vocabulary Parallelism
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
@TheTuringPost
The freshest AI/ML researches of the week, part 2
WEBRL: Training LLM Web Agents DynaSaur: Large Language Agents THANOS: Skill-Of-Mind-Infused Agents DELIFT HtmlRAG M3DOCRAG Needle Threading Survey Of Cultural Awareness In LMs OPENCODER Polynomial Composition Activations Hunyuan-Large Balancing Pipeline Parallelism With Vocabulary Parallelism
2/15
@TheTuringPost
1. WEBRL: Training LLM Web Agents
Trains web agents with a curriculum that evolves through agent learning, improving task success rates.
[2411.02337] WebRL: Training LLM Web Agents via Self-Evolving Online Curriculum Reinforcement Learning
GitHub: GitHub - THUDM/WebRL: Building Open LLM Web Agents with Self-Evolving Online Curriculum RL
3/15
@TheTuringPost
2. DynaSaur: Large Language Agents Beyond Predefined Actions
Allows agents to create actions on-the-fly, handling unforeseen tasks with Python-based adaptability.
[2411.01747] DynaSaur: Large Language Agents Beyond Predefined Actions
4/15
@TheTuringPost
3. THANOS: Skill-Of-Mind-Infused Agents
Enhances conversational agents with social skills, improving response accuracy and empathy.
[2411.04496] Thanos: Enhancing Conversational Agents with Skill-of-Mind-Infused Large Language Model
GitHub: GitHub - passing2961/Thanos: Official code repository for our paper: Thanos: Enhancing Conversational Agents with Skill-of-Mind-Infused Large Language Model
5/15
@TheTuringPost
4. DELIFT: Data Efficient Language Model Instruction Fine-Tuning
Optimizes fine-tuning by selecting the most informative data, cutting dataset size significantly.
[2411.04425] DELIFT: Data Efficient Language model Instruction Fine Tuning
6/15
@TheTuringPost
5. HtmlRAG: HTML Is Better Than Plain Text
Improves RAG systems by preserving HTML structure, enhancing retrieval quality.
[2411.02959] HtmlRAG: HTML is Better Than Plain Text for Modeling Retrieved Knowledge in RAG Systems
7/15
@TheTuringPost
6. M3DOCRAG: Multi-Modal Retrieval For Document Understanding
Introduces a multimodal RAG framework to handle multi-page and document QA tasks with visual data.
[2411.04952] M3DocRAG: Multi-modal Retrieval is What You Need for Multi-page Multi-document Understanding
8/15
@TheTuringPost
7. Needle Threading: LLMs For Long-Context Retrieval
Examines LLMs’ retrieval capabilities, identifying limits in handling extended contexts.
[2411.05000] Needle Threading: Can LLMs Follow Threads through Near-Million-Scale Haystacks?
GitHub: Needle Threading
9/15
@TheTuringPost
8. Survey Of Cultural Awareness In Language Models
Reviews cultural inclusivity in LLMs, emphasizing diverse and ethically sound datasets.
[2411.00860] Survey of Cultural Awareness in Language Models: Text and Beyond
GitHub: GitHub - siddheshih/culture-awareness-llms
10/15
@TheTuringPost
9. OPENCODER: The Open Cookbook For Code Models
Provides a comprehensive open-source guide for building high-performance code LLMs.
[2411.04905] OpenCoder: The Open Cookbook for Top-Tier Code Large Language Models
[Quoted tweet]
A “how-to” guide on building top-tier Code LLM
OpenCoder is a fully open-source code model, matching top code models in performance. It comes with a cookbook, training data, processing methods, and experiment results.
This cookbook covers key components for code models:
- Data cleaning rules
- Methods to avoid duplicates
- Mixing of text and code data for better context
- High-quality synthetic data for training
Reproduce your own model with this guide!
The cookbook: arxiv.org/pdf/2411.04905
OpenCoder GitHub: opencoder-llm.github.io/
11/15
@TheTuringPost
10. Polynomial Composition Activations
Enhances model expressivity using polynomial activations, optimizing parameter efficiency.
[2411.03884] Polynomial Composition Activations: Unleashing the Dynamics of Large Language Models
12/15
@TheTuringPost
11. Hunyuan-Large: An Open-Source MoE Model
Presents a large-scale MoE model, excelling across language, math, and coding tasks.
[2411.02265] Hunyuan-Large: An Open-Source MoE Model with 52 Billion Activated Parameters by Tencent
GitHub: GitHub - BryceZhuo/PolyCom: The official implementation of Polynomial Composition Activations: Unleashing the Dynamics of Large Language Models.
[Quoted tweet]
Overview of new Tencent Hunyuan-Large model:
It's the largest open-source Transformer-based MoE model Has 389 B total parameters and 52 B activation parameters Outperforms the LLama3.1-70B model Matches performance of the larger LLama3.1-405B Architecture:- KV cache compression: Groups and shares certain cache elements, saving up to 95% in memory.
- Recycle routing: Reallocates tokens from overloaded experts to less busy experts, preventing data loss and improving training efficiency.
- Expert-specific learning rates: Each expert has an optimized learning rate, improving training efficiency.
Uses a combination of 7 trillion tokens of natural and synthetic data, primarily in Chinese and English. The four-step process of data synthesis is used. Post-training includes fine-tuning and reinforcement learning from human feedback (RLHF). Extended long-context capabilities up to 256,000 tokens are especially useful for tasks, such as legal documents or scientific literature.
13/15
@TheTuringPost
12. Balancing Pipeline Parallelism With Vocabulary Parallelism
Improves transformer training efficiency by balancing memory across vocabulary layers.
[2411.05288] Balancing Pipeline Parallelism with Vocabulary Parallelism
14/15
@TheTuringPost
13. Find a complete list of the latest research papers in our free weekly digest:
#75: What is Metacognitive AI15/15
@TheTuringPost
14. Follow @TheTuringPost for more.
Like/repost the 1st post to support our work
Also, elevate your AI game with our free newsletter ↓
Turing Post
[Quoted tweet]
The freshest AI/ML researches of the week, part 2
WEBRL: Training LLM Web Agents DynaSaur: Large Language Agents THANOS: Skill-Of-Mind-Infused Agents DELIFT HtmlRAG M3DOCRAG Needle Threading Survey Of Cultural Awareness In LMs OPENCODER Polynomial Composition Activations Hunyuan-Large Balancing Pipeline Parallelism With Vocabulary Parallelism
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
1/1
@Analyticsindiam
Andrew Ng Releases New Short Course on Building Safe & Reliable AI
The course will help the learner explore, and mitigate some of the common failure modes in LLM-based apps, such as hallucinations and exposure to sensitive information, among other undesirable and harmful outputs.
The course will also help the learner implement ‘guardrails’ to prevent these failure modes, by accessing ‘pre-built’ guardrails on GuardrailsAI.
@DeepLearningAI | @coursera | @AndrewYNg
[Quoted tweet]
New short course: Safe and Reliable AI via Guardrails! Learn to create production-ready, reliable LLM applications with guardrails in this new course, built in collaboration with @guardrails_ai and taught by its CEO and co-founder, @ShreyaR.
I see many companies worry about the reliability of LLM-based systems -- will they hallucinate a catastrophically bad response? -- which slows down investing in building them and transitioning prototypes to deployment. That LLMs generate probabilistic outputs has made them particularly hard to deploy in highly regulated industries or in safety-critical environments.
Fortunately, there are good guardrail tools that give a significant new layer of control and reliability/safety. They act as a protective framework that can prevent your application from revealing incorrect, irrelevant, or confidential information, and they are an important part of what it takes to actually get prototypes to deployment.
This course will walk you through common failure modes of LLM-powered applications (like hallucinations or revealing personally identifiable information). It will show you how to build guardrails from scratch to mitigate them. You’ll also learn how to access a variety of pre-built guardrails on the GuardrailsAI hub that are ready to integrate into your projects.
You'll implement these guardrails in the context of a RAG-powered customer service chatbot for a small pizzeria. Specifically, you'll:
- Explore common failure modes like hallucinations, going off-topic, revealing sensitive information, or responses that can harm the pizzeria's reputation.
- Learn to mitigate these failure modes with input and output guards that check inputs and/or outputs
- Create a guardrail to prevent the chatbot from discussing sensitive topics, such as a confidential project at the pizza shop
- Detect hallucinations by ensuring responses are grounded in trusted documents
- Add a Personal Identifiable Information (PII) guardrail to detect and redact sensitive information in user prompts and in LLM outputs
- Set up a guardrail to limit the chatbot’s responses to topics relevant to the pizza shop, keeping interactions on-topic
- Configure a guardrail that prevents your chatbot from mentioning any competitors using a name detection pipeline consisting of conditional logic that routes to an exact match or a threshold check with named entity recognition
Guardrails are an important part of the practical building and deployment of LLM-based applications today. This course will show you how to make your applications more reliable and more ready for real-world deployment.
Please sign up here: deeplearning.ai/short-course…
https://video.twimg.com/ext_tw_video/1856778369427542017/pu/vid/avc1/1280x720/QlvX9Bez_VtzSyw5.mp4
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
@Analyticsindiam
Andrew Ng Releases New Short Course on Building Safe & Reliable AI
The course will help the learner explore, and mitigate some of the common failure modes in LLM-based apps, such as hallucinations and exposure to sensitive information, among other undesirable and harmful outputs.
The course will also help the learner implement ‘guardrails’ to prevent these failure modes, by accessing ‘pre-built’ guardrails on GuardrailsAI.
@DeepLearningAI | @coursera | @AndrewYNg
[Quoted tweet]
New short course: Safe and Reliable AI via Guardrails! Learn to create production-ready, reliable LLM applications with guardrails in this new course, built in collaboration with @guardrails_ai and taught by its CEO and co-founder, @ShreyaR.
I see many companies worry about the reliability of LLM-based systems -- will they hallucinate a catastrophically bad response? -- which slows down investing in building them and transitioning prototypes to deployment. That LLMs generate probabilistic outputs has made them particularly hard to deploy in highly regulated industries or in safety-critical environments.
Fortunately, there are good guardrail tools that give a significant new layer of control and reliability/safety. They act as a protective framework that can prevent your application from revealing incorrect, irrelevant, or confidential information, and they are an important part of what it takes to actually get prototypes to deployment.
This course will walk you through common failure modes of LLM-powered applications (like hallucinations or revealing personally identifiable information). It will show you how to build guardrails from scratch to mitigate them. You’ll also learn how to access a variety of pre-built guardrails on the GuardrailsAI hub that are ready to integrate into your projects.
You'll implement these guardrails in the context of a RAG-powered customer service chatbot for a small pizzeria. Specifically, you'll:
- Explore common failure modes like hallucinations, going off-topic, revealing sensitive information, or responses that can harm the pizzeria's reputation.
- Learn to mitigate these failure modes with input and output guards that check inputs and/or outputs
- Create a guardrail to prevent the chatbot from discussing sensitive topics, such as a confidential project at the pizza shop
- Detect hallucinations by ensuring responses are grounded in trusted documents
- Add a Personal Identifiable Information (PII) guardrail to detect and redact sensitive information in user prompts and in LLM outputs
- Set up a guardrail to limit the chatbot’s responses to topics relevant to the pizza shop, keeping interactions on-topic
- Configure a guardrail that prevents your chatbot from mentioning any competitors using a name detection pipeline consisting of conditional logic that routes to an exact match or a threshold check with named entity recognition
Guardrails are an important part of the practical building and deployment of LLM-based applications today. This course will show you how to make your applications more reliable and more ready for real-world deployment.
Please sign up here: deeplearning.ai/short-course…
https://video.twimg.com/ext_tw_video/1856778369427542017/pu/vid/avc1/1280x720/QlvX9Bez_VtzSyw5.mp4
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
1/1
@MetaforDevs
The Llama 3.2 Home course instructed by Amit Sangani is now available on Coursera. Check out the course and sign up now! Introducing Multimodal Llama 3.2

To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
@MetaforDevs
The Llama 3.2 Home course instructed by Amit Sangani is now available on Coursera. Check out the course and sign up now! Introducing Multimodal Llama 3.2
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
1/18
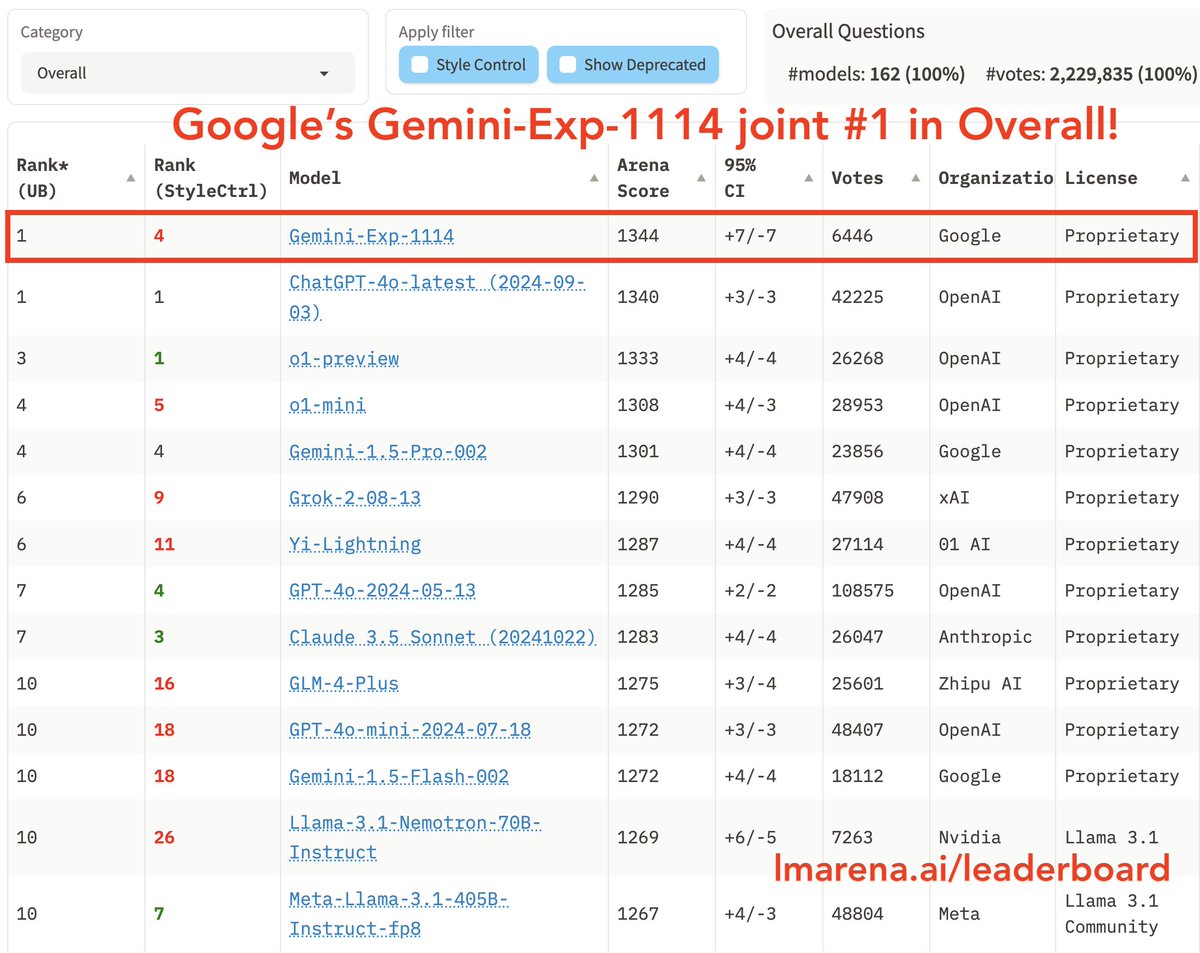
@AndrewCurran_
A new Gemini experimental build is up, and in its final stages of development. This new model was anonymously tested in the arena over the last week, and now ranks first overall. Google has retaken the lead.
[Quoted tweet]
gemini-exp-1114…. available in Google AI Studio right now, enjoy : )
aistudio.google.com

2/18
@AndrewCurran_
[Quoted tweet]
Massive News from Chatbot Arena
@GoogleDeepMind's latest Gemini (Exp 1114), tested with 6K+ community votes over the past week, now ranks joint #1 overall with an impressive 40+ score leap — matching 4o-latest in and surpassing o1-preview! It also claims #1 on Vision leaderboard.
Gemini-Exp-1114 excels across technical and creative domains:
- Overall #3 -> #1
- Math: #3 -> #1
- Hard Prompts: #4 -> #1
- Creative Writing #2 -> #1
- Vision: #2 -> #1
- Coding: #5 -> #3
- Overall (StyleCtrl): #4 -> #4
Huge congrats to @GoogleDeepMind on this remarkable milestone!
Come try the new Gemini and share your feedback!
3/18
@AndrewCurran_
Matches o1-preview in math. There's a good chance this model is Gemini 2.

4/18
@AndrewCurran_
I need to see the AidanBench numbers.
5/18
@JoJrobotics
but if this is the new gemini 2.0 then its disappointing cause its an barely better than gpt-4o. We need models that can acheive real Human-level reasoninh
6/18
@indrajeet877
Google Gemini is on fire now
7/18
@AchillesSlays
It'd be crap as usual when actual users use it
8/18
@alikayadibi11
Never trusting gemini
9/18
@KCDN19
I find the Google models lacking in charisma and deceptive about it's censorship protocols.
10/18
@algxtradingx
I wish I could believe that it’ll be worthwhile, it’s just that sonnet has been so good and Gemini has been so bad that it’s hard for me to fathom a flipping.
11/18
@__p_i_o_t_r__
Behind Sonnet with style control applied and behind Sonnet in my personal tests. Supposedly really good at math, so at least that if it's 2.0.
12/18
@hingeloss
`gemini-exp`, not `gemini-1.5-exp`, wink wink?
13/18
@nordic_eacc
If this is Gemini 2.0, that’s pretty sad
14/18
@kami_ayani
Gemini just fundamentally sucks
15/18
@fifth_sign
Gemini fukking roasted my resume last week. This makes sense.
16/18
@xundecidability
Does arena still limit prompt to 1k tokens?
17/18
@AiAnvil
Don’t poke the bear…
18/18
@BrettBaronR32
More evidence that lmsys is worthless, gemini is ass
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
@AndrewCurran_
A new Gemini experimental build is up, and in its final stages of development. This new model was anonymously tested in the arena over the last week, and now ranks first overall. Google has retaken the lead.
[Quoted tweet]
gemini-exp-1114…. available in Google AI Studio right now, enjoy : )
aistudio.google.com
2/18
@AndrewCurran_
[Quoted tweet]
Massive News from Chatbot Arena
@GoogleDeepMind's latest Gemini (Exp 1114), tested with 6K+ community votes over the past week, now ranks joint #1 overall with an impressive 40+ score leap — matching 4o-latest in and surpassing o1-preview! It also claims #1 on Vision leaderboard.
Gemini-Exp-1114 excels across technical and creative domains:
- Overall #3 -> #1
- Math: #3 -> #1
- Hard Prompts: #4 -> #1
- Creative Writing #2 -> #1
- Vision: #2 -> #1
- Coding: #5 -> #3
- Overall (StyleCtrl): #4 -> #4
Huge congrats to @GoogleDeepMind on this remarkable milestone!
Come try the new Gemini and share your feedback!
3/18
@AndrewCurran_
Matches o1-preview in math. There's a good chance this model is Gemini 2.
4/18
@AndrewCurran_
I need to see the AidanBench numbers.
5/18
@JoJrobotics
but if this is the new gemini 2.0 then its disappointing cause its an barely better than gpt-4o. We need models that can acheive real Human-level reasoninh
6/18
@indrajeet877
Google Gemini is on fire now
7/18
@AchillesSlays
It'd be crap as usual when actual users use it
8/18
@alikayadibi11
Never trusting gemini
9/18
@KCDN19
I find the Google models lacking in charisma and deceptive about it's censorship protocols.
10/18
@algxtradingx
I wish I could believe that it’ll be worthwhile, it’s just that sonnet has been so good and Gemini has been so bad that it’s hard for me to fathom a flipping.
11/18
@__p_i_o_t_r__
Behind Sonnet with style control applied and behind Sonnet in my personal tests. Supposedly really good at math, so at least that if it's 2.0.
12/18
@hingeloss
`gemini-exp`, not `gemini-1.5-exp`, wink wink?
13/18
@nordic_eacc
If this is Gemini 2.0, that’s pretty sad
14/18
@kami_ayani
Gemini just fundamentally sucks
15/18
@fifth_sign
Gemini fukking roasted my resume last week. This makes sense.
16/18
@xundecidability
Does arena still limit prompt to 1k tokens?
17/18
@AiAnvil
Don’t poke the bear…
18/18
@BrettBaronR32
More evidence that lmsys is worthless, gemini is ass
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
1/3
@teortaxesTex
> Furthermore, shocked by o1, we think that we should dive into the research in the reasoning capabilities and see how smart an AI model or system can be.
> shocked
This is what I'm talking about, the albatross around the Chinese neck:
They can't accept living in a sci-fi world.
[Quoted tweet]
Finally got some time to chat about these new models. We started the project of Qwen2.5 at the moment we released Qwen2. Through this process we did realize a lot of problems and mistakes that we made. In terms of pretraining, we simply focus on leveling up the quality and quantity of the pretraining data, just using a lot of methods that you are familiar with, like text classifier for recalling quality data, LLM scorers for scoring data so that we can strike a balance between quality and quantity. Along with the creation of expert models, we use them for synthetic data generation. In terms of posttraining, the user feedbacks helped us solve problems one by one and at the same time we are exploring how RLHF methods can help especially those of online learning. I hope you find them interesting and helpful for your research and work. Since now we are moving to the next stage to solve more difficult problems. For a long time we hope to build a multimodal multitask AI model or system and it seems that we are not that far from a good unification of modalities and tasks. Furthermore, shocked by o1, we think that we should dive into the research in the reasoning capabilities and see how smart an AI model or system can be. We hope that we can bring totally new stuffs to you very soon!

2/3
@YouJiacheng
Qwen team *has known* test time compute scaling (no later than Qwen2-Math), and has used it for synthetic data generation.
Similar to rumored o1 synthesizing data for Orion.


3/3
@YouJiacheng
I highly suspect the gap here is the size of the largest model.
72B vs. 1.8T
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
@teortaxesTex
> Furthermore, shocked by o1, we think that we should dive into the research in the reasoning capabilities and see how smart an AI model or system can be.
> shocked
This is what I'm talking about, the albatross around the Chinese neck:
They can't accept living in a sci-fi world.
[Quoted tweet]
Finally got some time to chat about these new models. We started the project of Qwen2.5 at the moment we released Qwen2. Through this process we did realize a lot of problems and mistakes that we made. In terms of pretraining, we simply focus on leveling up the quality and quantity of the pretraining data, just using a lot of methods that you are familiar with, like text classifier for recalling quality data, LLM scorers for scoring data so that we can strike a balance between quality and quantity. Along with the creation of expert models, we use them for synthetic data generation. In terms of posttraining, the user feedbacks helped us solve problems one by one and at the same time we are exploring how RLHF methods can help especially those of online learning. I hope you find them interesting and helpful for your research and work. Since now we are moving to the next stage to solve more difficult problems. For a long time we hope to build a multimodal multitask AI model or system and it seems that we are not that far from a good unification of modalities and tasks. Furthermore, shocked by o1, we think that we should dive into the research in the reasoning capabilities and see how smart an AI model or system can be. We hope that we can bring totally new stuffs to you very soon!
2/3
@YouJiacheng
Qwen team *has known* test time compute scaling (no later than Qwen2-Math), and has used it for synthetic data generation.
Similar to rumored o1 synthesizing data for Orion.
3/3
@YouJiacheng
I highly suspect the gap here is the size of the largest model.
72B vs. 1.8T
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
1/2
@FluidBotStocks
- Qwen2-Math outperforms competitors like OpenAI's GPT-4o and Google's Math-Gemini Specialized 1.5 Pro
- Qwen2-Math-72B-Instruct, the most powerful variant, scored 84% on the MATH Benchmark for LLMs
2/2
@FluidBotStocks
- Qwen2-Math models excel at solving math problems, such as those in the GSM8K benchmark
- Alibaba hopes that Qwen2-Math will contribute to solving complex mathematical problems
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
@FluidBotStocks
- Qwen2-Math outperforms competitors like OpenAI's GPT-4o and Google's Math-Gemini Specialized 1.5 Pro
- Qwen2-Math-72B-Instruct, the most powerful variant, scored 84% on the MATH Benchmark for LLMs
2/2
@FluidBotStocks
- Qwen2-Math models excel at solving math problems, such as those in the GSM8K benchmark
- Alibaba hopes that Qwen2-Math will contribute to solving complex mathematical problems
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
1/2
@hamptonism
We need duolingo but for math.
2/2
@SpectrGen
Qwen2-Math is a decent tutor — also it’s free and private.
Your mileage may vary

To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
@hamptonism
We need duolingo but for math.
2/2
@SpectrGen
Qwen2-Math is a decent tutor — also it’s free and private.
Your mileage may vary
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
1/5
@ai_for_success
What's going on with Reflection? I'm seeing a mixed reaction on my feed.
2/5
@DotCSV
I'm connected to Matts API so I can try any prompt you want in case this helps.
[Quoted tweet]
 I'M TESTING REFLECTION 70B (the good one)
I'M TESTING REFLECTION 70B (the good one)
Shout out to my english-speaking audience! This is your opportunity to send me your hard prompts to test it against the-good-checkpoint™ of Reflection 70B.
I'll be answering your requests during the day.

3/5
@ai_for_success
Thanks Carlos.. Can you try this one :
I = ∫ (from 0 to π) [x * sin(x)] / [1 + cos²(x)] dx
4/5
@DotCSV


5/5
@ai_for_success
Thanks Carlos.. Well answer is wrong..
I tested this few weeks back to other model and only Qwen2-Math-72B, Grok-2 larger model and Google Gemini 1.5 Pro Experimental 0801 model solved this..correct ans with clear explanation is this

To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
@ai_for_success
What's going on with Reflection? I'm seeing a mixed reaction on my feed.
2/5
@DotCSV
I'm connected to Matts API so I can try any prompt you want in case this helps.
[Quoted tweet]
I'M TESTING REFLECTION 70B (the good one)Shout out to my english-speaking audience! This is your opportunity to send me your hard prompts to test it against the-good-checkpoint™ of Reflection 70B.
I'll be answering your requests during the day.
3/5
@ai_for_success
Thanks Carlos.. Can you try this one :
I = ∫ (from 0 to π) [x * sin(x)] / [1 + cos²(x)] dx
4/5
@DotCSV
5/5
@ai_for_success
Thanks Carlos.. Well answer is wrong..
I tested this few weeks back to other model and only Qwen2-Math-72B, Grok-2 larger model and Google Gemini 1.5 Pro Experimental 0801 model solved this..correct ans with clear explanation is this
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
1/20
@Alibaba_Qwen
Last week we released Qwen2-Math-72B, which achieves state-of-the-art performance in a number of math benchmark datasets. Today we release a demo of Qwen2-Math, but it is more than a math model!
Qwen2-Math-72B, which achieves state-of-the-art performance in a number of math benchmark datasets. Today we release a demo of Qwen2-Math, but it is more than a math model!
Qwen Math Demo - a Hugging Face Space by Qwen
In this demo, you can ask Qwen2-Math-72B by inputting the math problem with text, but if you find it hard to input the contents by text, especially formula, you can even input an image of the scanned text! This is because Qwen2-VL stays behind the scenes and processes text recognition for Qwen2-Math-72B to reason!
Try it and have fun! Some examples
2/20
@Alibaba_Qwen

3/20
@Alibaba_Qwen

4/20
@Alibaba_Qwen

5/20
@wuzhao00
amazing job!
6/20
@dahou_yasser
How much does it get on MathVista?
7/20
@gettinitrealnow
[Quoted tweet]
Alibaba is running a fraud: The last photo shows one of the merchants who continues to steal money from customers and never returns communication. @AlibabaGroup @AlibabaB2B @AlibabaTalk_UK @Alibaba_Qwen @AliExpress_EN @AliExpress1221 @NothosaurA @aliexplosed




8/20
@mpowers206
Would love to see a Qwen2-4B. Is that in the works?
9/20
@nabil59587594
I gave your beautiful tool an equation, so a problem from quantum mechanics in one Dimension,
1- wavelength calculation is not correct,
2- energy calculations are closer to the solution,
but still not correct.
3- speed calculation is significantly not going well.




10/20
@nabil59587594
2- mistakes are absolutely fine,
I know it will become significantly better,
but I just want to say something here
the level that I am referring to, is the last stage level.
it is the one that you must have to reach a PhD level in Physics and mathematics.
After that...
11/20
@nabil59587594
3- Humans start to solve problems that are not solved before,
so this is what you call creativity
when you accumulate the ability to see mistakes, you start to connect the dots with same information all of us have
and you generate unpredictable correct solutions..
12/20
@nabil59587594
4- on its own walking this path,
with enough memory,
your Qwen AI, must be able to build an entire Rocket or a satellite from bottom to top with the engine and everything else all on its own.
I can't really say if something is messing or not,
I don't know what exactly it is.
13/20
@juniorro16
Wrong result here because OCR is wrong in this case.

14/20
@changtimwu
Let's attempt a more challenging problem: the second-order PDE. Impressively, both the steps and the solution are correct. [Solved] Partial Differential Equations MCQ [Free PDF] - Objective Question Answer for Partial Differential Equations Quiz - Download Now!



15/20
@cherry_cc12
wow! That’s so cool!

16/20
@Coolzippity
You did it!

17/20
@HantianPang
好牛逼的模型!!
18/20
@geesehowardt7
All large language models can't solve this junior high school problem so far.


19/20
@ModelBoxAI
Amazing work and love the image scanning to solve the math problem
20/20
@Hama7_AI
i liked it!
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
@Alibaba_Qwen
Last week we released
Qwen2-Math-72B, which achieves state-of-the-art performance in a number of math benchmark datasets. Today we release a demo of Qwen2-Math, but it is more than a math model!Qwen Math Demo - a Hugging Face Space by Qwen
In this demo, you can ask Qwen2-Math-72B by inputting the math problem with text, but if you find it hard to input the contents by text, especially formula, you can even input an image of the scanned text! This is because Qwen2-VL stays behind the scenes and processes text recognition for Qwen2-Math-72B to reason!
Try it and have fun! Some examples
2/20
@Alibaba_Qwen
3/20
@Alibaba_Qwen
4/20
@Alibaba_Qwen
5/20
@wuzhao00
amazing job!
6/20
@dahou_yasser
How much does it get on MathVista?
7/20
@gettinitrealnow
[Quoted tweet]
Alibaba is running a fraud: The last photo shows one of the merchants who continues to steal money from customers and never returns communication. @AlibabaGroup @AlibabaB2B @AlibabaTalk_UK @Alibaba_Qwen @AliExpress_EN @AliExpress1221 @NothosaurA @aliexplosed
8/20
@mpowers206
Would love to see a Qwen2-4B. Is that in the works?
9/20
@nabil59587594
I gave your beautiful tool an equation, so a problem from quantum mechanics in one Dimension,
1- wavelength calculation is not correct,
2- energy calculations are closer to the solution,
but still not correct.
3- speed calculation is significantly not going well.
10/20
@nabil59587594
2- mistakes are absolutely fine,
I know it will become significantly better,
but I just want to say something here
the level that I am referring to, is the last stage level.
it is the one that you must have to reach a PhD level in Physics and mathematics.
After that...
11/20
@nabil59587594
3- Humans start to solve problems that are not solved before,
so this is what you call creativity
when you accumulate the ability to see mistakes, you start to connect the dots with same information all of us have
and you generate unpredictable correct solutions..
12/20
@nabil59587594
4- on its own walking this path,
with enough memory,
your Qwen AI, must be able to build an entire Rocket or a satellite from bottom to top with the engine and everything else all on its own.
I can't really say if something is messing or not,
I don't know what exactly it is.
13/20
@juniorro16
Wrong result here because OCR is wrong in this case.
14/20
@changtimwu
Let's attempt a more challenging problem: the second-order PDE. Impressively, both the steps and the solution are correct.
[Solved] Partial Differential Equations MCQ [Free PDF] - Objective Question Answer for Partial Differential Equations Quiz - Download Now!
15/20
@cherry_cc12
wow! That’s so cool!
16/20
@Coolzippity
You did it!
17/20
@HantianPang
好牛逼的模型!!
18/20
@geesehowardt7
All large language models can't solve this junior high school problem so far.
19/20
@ModelBoxAI
Amazing work and love the image scanning to solve the math problem
20/20
@Hama7_AI
i liked it!
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
1/21
@karpathy
Moravec's paradox in LLM evals
I was reacting to this new benchmark of frontier math where LLMs only solve 2%. It was introduced because LLMs are increasingly crushing existing math benchmarks. The interesting issue is that even though by many accounts (/evals), LLMs are inching well into top expert territory (e.g. in math and coding etc.), you wouldn't hire them over a person for the most menial jobs. They can solve complex closed problems if you serve them the problem description neatly on a platter in the prompt, but they struggle to coherently string together long, autonomous, problem-solving sequences in a way that a person would find very easy.
This is Moravec's paradox in disguise, who observed 30+ years ago that what is easy/hard for humans can be non-intuitively very different to what is easy/hard for computers. E.g. humans are very impressed by computers playing chess, but chess is easy for computers as it is a closed, deterministic system with a discrete action space, full observability, etc etc. Vice versa, humans can tie a shoe or fold a shirt and don't think much of it at all but this is an extremely complex sensorimotor task that challenges the state of the art in both hardware and software. It's like that Rubik's Cube release from OpenAI a while back where most people fixated on the solving itself (which is trivial) instead of the actually incredibly difficult task of just turning one face of the cube with a robot hand.
So I really like this FrontierMath benchmark and we should make more. But I also think it's an interesting challenge how we can create evals for all the "easy" stuff that is secretly hard. Very long context windows, coherence, autonomy, common sense, multimodal I/O that works, ... How do we build good "menial job" evals? The kinds of things you'd expect from any entry-level intern on your team.
[Quoted tweet]
1/10 Today we're launching FrontierMath, a benchmark for evaluating advanced mathematical reasoning in AI. We collaborated with 60+ leading mathematicians to create hundreds of original, exceptionally challenging math problems, of which current AI systems solve less than 2%.

2/21
@AIExplainedYT
Any thoughts on SimpleBench? Work in progress but random humans get roughly double frontier models for basic reasoning.
3/21
@G_Orbeliani
Fascinating how Moravec’s paradox plays out in LLMs. Crushing the basics, yet stumbling on frontier math - it’s like the more advanced we get, the trickier the challenges!
4/21
@ZainHasan6
Agreed - "create evals for all the "easy" stuff that is secretly hard"
super important to get this right; the evals we make today will define the nature of progress in the field
i imagine these Moravec evals will also be hard to game/reward hack
[2406.10162] Sycophancy to Subterfuge: Investigating Reward-Tampering in Large Language Models
5/21
@paul_cal
Love the idea of a common sense eval
I'm doing some informal game playing evals right now (like pictionary). Don't think pictionary hits the spot for this, but should be scope for other simple games to play a role (esp for simple multimodal reasoning)
[Quoted tweet]
LLMs play pictionary!
https://video.twimg.com/ext_tw_video/1850262173139746817/pu/vid/avc1/880x720/yqKJhT-NhaNetU17.mp4
6/21
@Venice_Wes
At the limit Moravec's paradox highlights that biology and computers are fundamentally different kinds of systems.
We are observers. LLMs are not.
7/21
@rohanpaul_ai
So, still some distance to cover to get a true PhD level model. But I am sure, we will get there.
[Quoted tweet]
A new challenging benchmark called FrontierMath was just announced, with all new and unpublished problems are.
Top scoring LLM gets 2%
1/n
About FrontierMath?
- Collection of hundreds of unpublished expert-level math problems
- Spans modern mathematics from computational number theory to algebraic geometry
- Problems require hours/days for specialist mathematicians to solve
- Designed to be "guessproof" with <1% chance of correct random guessing
- Solutions verifiable through computation with exact integers or mathematical objects

8/21
@hausman_k
Making good progress on Moravec's paradox:
https://video.twimg.com/ext_tw_video/1856163450936049664/pu/vid/avc1/1280x720/qdPc7kPJzhix1kXL.mp4
9/21
@philduan
Moravec's paradox in robotics evals:
what humans think is easy to eval is very hard,
and what humans think is hard to eval is still very hard.
10/21
@William01312400
Classic underestimating the complexity of a problem.
11/21
@ssarraju
Another issue with these benchmarks is that when a new benchmark shows LLMs performing poorly, subsequent iterations are trained to beat it, creating an illusion of progress. The best benchmark is one that surprises and changes completely every time it’s evaluated.
12/21
@John73014818
Really interesting
13/21
@patelnir41
What do you think of OSWorld? Human level performs ~75% and the best model (Claude) is around 20% right now. Both speed and accuracy would be a good measure on it imo
14/21
@Justin_Halford_
The constraint that a domain must be closed and objectively verifiable in order to enable pure RL approaches is *the* engineering challenge that is holding back integration into real world contexts and which won’t be solved through scale alone.
[Quoted tweet]
Intelligent systems are only as intelligent as their verifiers. Domains like math and coding have perfect verifiers, whereas writing and moviemaking don’t as they’re subjective.
In the short term, intelligence will stall at human levels in domains in which humans are verifiers.
15/21
@ikristoph
I do believe that models like O1 are a path towards solving more complex problems with planning.
O1 works through the problem with - seemingly - some fundamental planning. It admittedly still works better if the problem is narrowed for it but I imagine the approach would scale by introducing hierarchical problem decomposition.
16/21
@rez0__
The tough parts are the “connection points” between systems. Interns can send a dm, make a call, browse the web, make a note, etc.
17/21
@MannyKayy
Good to see the rest of the LLM sphere slowly catching up with what has been obvious to the rest of us, especially those of us with experience in real-world general purpose robots...
The most menial tasks for humans are often the most difficult to approach in robotics.
18/21
@Joedefendre
Embodiment may help with this ! Models can be evaluated on how well they can actually do a menial manual labor job!
19/21
@Emily_Escapor
I hope we see the same thing for biology, physics and chemistry soon

20/21
@Scott_S612
I still think the seemingly easy task being difficult for AI is because of training data modality, throughput and distribution richness. We need data across modalities with inherent relationship and feature mappings.
21/21
@dtometzki
Very interesting
@karpathy
Moravec's paradox in LLM evals
I was reacting to this new benchmark of frontier math where LLMs only solve 2%. It was introduced because LLMs are increasingly crushing existing math benchmarks. The interesting issue is that even though by many accounts (/evals), LLMs are inching well into top expert territory (e.g. in math and coding etc.), you wouldn't hire them over a person for the most menial jobs. They can solve complex closed problems if you serve them the problem description neatly on a platter in the prompt, but they struggle to coherently string together long, autonomous, problem-solving sequences in a way that a person would find very easy.
This is Moravec's paradox in disguise, who observed 30+ years ago that what is easy/hard for humans can be non-intuitively very different to what is easy/hard for computers. E.g. humans are very impressed by computers playing chess, but chess is easy for computers as it is a closed, deterministic system with a discrete action space, full observability, etc etc. Vice versa, humans can tie a shoe or fold a shirt and don't think much of it at all but this is an extremely complex sensorimotor task that challenges the state of the art in both hardware and software. It's like that Rubik's Cube release from OpenAI a while back where most people fixated on the solving itself (which is trivial) instead of the actually incredibly difficult task of just turning one face of the cube with a robot hand.
So I really like this FrontierMath benchmark and we should make more. But I also think it's an interesting challenge how we can create evals for all the "easy" stuff that is secretly hard. Very long context windows, coherence, autonomy, common sense, multimodal I/O that works, ... How do we build good "menial job" evals? The kinds of things you'd expect from any entry-level intern on your team.
[Quoted tweet]
1/10 Today we're launching FrontierMath, a benchmark for evaluating advanced mathematical reasoning in AI. We collaborated with 60+ leading mathematicians to create hundreds of original, exceptionally challenging math problems, of which current AI systems solve less than 2%.
2/21
@AIExplainedYT
Any thoughts on SimpleBench? Work in progress but random humans get roughly double frontier models for basic reasoning.
3/21
@G_Orbeliani
Fascinating how Moravec’s paradox plays out in LLMs. Crushing the basics, yet stumbling on frontier math - it’s like the more advanced we get, the trickier the challenges!
4/21
@ZainHasan6
Agreed - "create evals for all the "easy" stuff that is secretly hard"
super important to get this right; the evals we make today will define the nature of progress in the field
i imagine these Moravec evals will also be hard to game/reward hack
[2406.10162] Sycophancy to Subterfuge: Investigating Reward-Tampering in Large Language Models
5/21
@paul_cal
Love the idea of a common sense eval
I'm doing some informal game playing evals right now (like pictionary). Don't think pictionary hits the spot for this, but should be scope for other simple games to play a role (esp for simple multimodal reasoning)
[Quoted tweet]
LLMs play pictionary!
https://video.twimg.com/ext_tw_video/1850262173139746817/pu/vid/avc1/880x720/yqKJhT-NhaNetU17.mp4
6/21
@Venice_Wes
At the limit Moravec's paradox highlights that biology and computers are fundamentally different kinds of systems.
We are observers. LLMs are not.
7/21
@rohanpaul_ai
So, still some distance to cover to get a true PhD level model. But I am sure, we will get there.
[Quoted tweet]
A new challenging benchmark called FrontierMath was just announced, with all new and unpublished problems are.
Top scoring LLM gets 2%
1/n
About FrontierMath?- Collection of hundreds of unpublished expert-level math problems
- Spans modern mathematics from computational number theory to algebraic geometry
- Problems require hours/days for specialist mathematicians to solve
- Designed to be "guessproof" with <1% chance of correct random guessing
- Solutions verifiable through computation with exact integers or mathematical objects
8/21
@hausman_k
Making good progress on Moravec's paradox:
https://video.twimg.com/ext_tw_video/1856163450936049664/pu/vid/avc1/1280x720/qdPc7kPJzhix1kXL.mp4
9/21
@philduan
Moravec's paradox in robotics evals:
what humans think is easy to eval is very hard,
and what humans think is hard to eval is still very hard.
10/21
@William01312400
Classic underestimating the complexity of a problem.
11/21
@ssarraju
Another issue with these benchmarks is that when a new benchmark shows LLMs performing poorly, subsequent iterations are trained to beat it, creating an illusion of progress. The best benchmark is one that surprises and changes completely every time it’s evaluated.
12/21
@John73014818
Really interesting
13/21
@patelnir41
What do you think of OSWorld? Human level performs ~75% and the best model (Claude) is around 20% right now. Both speed and accuracy would be a good measure on it imo
14/21
@Justin_Halford_
The constraint that a domain must be closed and objectively verifiable in order to enable pure RL approaches is *the* engineering challenge that is holding back integration into real world contexts and which won’t be solved through scale alone.
[Quoted tweet]
Intelligent systems are only as intelligent as their verifiers. Domains like math and coding have perfect verifiers, whereas writing and moviemaking don’t as they’re subjective.
In the short term, intelligence will stall at human levels in domains in which humans are verifiers.
15/21
@ikristoph
I do believe that models like O1 are a path towards solving more complex problems with planning.
O1 works through the problem with - seemingly - some fundamental planning. It admittedly still works better if the problem is narrowed for it but I imagine the approach would scale by introducing hierarchical problem decomposition.
16/21
@rez0__
The tough parts are the “connection points” between systems. Interns can send a dm, make a call, browse the web, make a note, etc.
17/21
@MannyKayy
Good to see the rest of the LLM sphere slowly catching up with what has been obvious to the rest of us, especially those of us with experience in real-world general purpose robots...
The most menial tasks for humans are often the most difficult to approach in robotics.
18/21
@Joedefendre
Embodiment may help with this ! Models can be evaluated on how well they can actually do a menial manual labor job!
19/21
@Emily_Escapor
I hope we see the same thing for biology, physics and chemistry soon
20/21
@Scott_S612
I still think the seemingly easy task being difficult for AI is because of training data modality, throughput and distribution richness. We need data across modalities with inherent relationship and feature mappings.
21/21
@dtometzki
Very interesting
1/21
@EpochAIResearch
1/10 Today we're launching FrontierMath, a benchmark for evaluating advanced mathematical reasoning in AI. We collaborated with 60+ leading mathematicians to create hundreds of original, exceptionally challenging math problems, of which current AI systems solve less than 2%.
2/21
@EpochAIResearch
2/10 Existing math benchmarks like GSM8K and MATH are approaching saturation, with AI models scoring over 90%—partly due to data contamination. FrontierMath significantly raises the bar. Our problems often require hours or even days of effort from expert mathematicians.

3/21
@EpochAIResearch
3/10 We evaluated six leading models, including Claude 3.5 Sonnet, GPT-4o, and Gemini 1.5 Pro. Even with extended thinking time (10,000 tokens), Python access, and the ability to run experiments, success rates remained below 2%—compared to over 90% on traditional benchmarks.

4/21
@EpochAIResearch
4/10 Explore FrontierMath: We've released sample problems with detailed solutions, expert commentary, and our research paper: FrontierMath

5/21
@EpochAIResearch
5/10 FrontierMath spans most major branches of modern mathematics—from computationally intensive problems in number theory to abstract questions in algebraic geometry and category theory. Our aim is to capture a snapshot of contemporary mathematics.

6/21
@EpochAIResearch
6/10 FrontierMath has three key design principles: 1) All problems are new and unpublished, preventing data contamination, 2) Solutions are automatically verifiable, enabling efficient evaluation, 3) Problems are "guessproof" with low chance of solving without proper reasoning.

7/21
@EpochAIResearch
7/10 What do experts think? We interviewed Fields Medalists Terence Tao (2006), Timothy Gowers (1998), Richard Borcherds (1998), and IMO coach Evan Chen. They unanimously described our research problems as exceptionally challenging, requiring deep domain expertise.



8/21
@EpochAIResearch
8/10 Mathematics offers a uniquely suitable sandbox for evaluating complex reasoning. It requires creativity and extended chains of precise logic—often involving intricate proofs—that must be meticulously planned and executed, yet allows for objective verification of results.
9/21
@EpochAIResearch
9/10 Beyond mathematics, we think that measuring AI's aptitude in creative problem-solving and maintaining precise reasoning over many steps may offer insights into progress toward the systematic, innovative thinking needed for scientific research.
10/21
@EpochAIResearch
10/10 You can explore the full methodology, examine sample problems with detailed solutions, and see how current AI systems perform on FrontierMath: FrontierMath
11/21
@amebagpt
Wow interesting that o1 models are not ahead
12/21
@TheRamoliya
For the people who wants to learn more about research paper:
https://youtube.com/-D3oponLA04
13/21
@ebarcuzzi
What percentage do humans score?
14/21
@sytelus
I really hope you have kept a private set when big claims drops.
15/21
@CharlesHL
@readwise save thread
16/21
@paul_cal
Looks excellent. So you aren't planning to do an ARC or Kaggle model where people can submit solvers for private/semi-private eval, but instead you plan to rerun only for big new model releases?
Means neurosymbolic approaches or even prompt pipelines aren't considered right?
17/21
@pyrons_
@VastoLorde95 game on for grok
18/21
@seo_leaders
Awesome research. This is most helpful. Thanks!
19/21
@FrankieS2727



20/21
@jswitz_
A needed addition. Thank you
21/21
@koltregaskes
Oh excellent, thanks.
@EpochAIResearch
1/10 Today we're launching FrontierMath, a benchmark for evaluating advanced mathematical reasoning in AI. We collaborated with 60+ leading mathematicians to create hundreds of original, exceptionally challenging math problems, of which current AI systems solve less than 2%.
2/21
@EpochAIResearch
2/10 Existing math benchmarks like GSM8K and MATH are approaching saturation, with AI models scoring over 90%—partly due to data contamination. FrontierMath significantly raises the bar. Our problems often require hours or even days of effort from expert mathematicians.
3/21
@EpochAIResearch
3/10 We evaluated six leading models, including Claude 3.5 Sonnet, GPT-4o, and Gemini 1.5 Pro. Even with extended thinking time (10,000 tokens), Python access, and the ability to run experiments, success rates remained below 2%—compared to over 90% on traditional benchmarks.
4/21
@EpochAIResearch
4/10 Explore FrontierMath: We've released sample problems with detailed solutions, expert commentary, and our research paper: FrontierMath
5/21
@EpochAIResearch
5/10 FrontierMath spans most major branches of modern mathematics—from computationally intensive problems in number theory to abstract questions in algebraic geometry and category theory. Our aim is to capture a snapshot of contemporary mathematics.
6/21
@EpochAIResearch
6/10 FrontierMath has three key design principles: 1) All problems are new and unpublished, preventing data contamination, 2) Solutions are automatically verifiable, enabling efficient evaluation, 3) Problems are "guessproof" with low chance of solving without proper reasoning.
7/21
@EpochAIResearch
7/10 What do experts think? We interviewed Fields Medalists Terence Tao (2006), Timothy Gowers (1998), Richard Borcherds (1998), and IMO coach Evan Chen. They unanimously described our research problems as exceptionally challenging, requiring deep domain expertise.
8/21
@EpochAIResearch
8/10 Mathematics offers a uniquely suitable sandbox for evaluating complex reasoning. It requires creativity and extended chains of precise logic—often involving intricate proofs—that must be meticulously planned and executed, yet allows for objective verification of results.
9/21
@EpochAIResearch
9/10 Beyond mathematics, we think that measuring AI's aptitude in creative problem-solving and maintaining precise reasoning over many steps may offer insights into progress toward the systematic, innovative thinking needed for scientific research.
10/21
@EpochAIResearch
10/10 You can explore the full methodology, examine sample problems with detailed solutions, and see how current AI systems perform on FrontierMath: FrontierMath
11/21
@amebagpt
Wow interesting that o1 models are not ahead
12/21
@TheRamoliya
For the people who wants to learn more about research paper:
https://youtube.com/-D3oponLA04
13/21
@ebarcuzzi
What percentage do humans score?
14/21
@sytelus
I really hope you have kept a private set when big claims drops.
15/21
@CharlesHL
@readwise save thread
16/21
@paul_cal
Looks excellent. So you aren't planning to do an ARC or Kaggle model where people can submit solvers for private/semi-private eval, but instead you plan to rerun only for big new model releases?
Means neurosymbolic approaches or even prompt pipelines aren't considered right?
17/21
@pyrons_
@VastoLorde95 game on for grok
18/21
@seo_leaders
Awesome research. This is most helpful. Thanks!
19/21
@FrankieS2727
20/21
@jswitz_
A needed addition. Thank you
21/21
@koltregaskes
Oh excellent, thanks.