
1/11
@ikristoph
There is much excitement about this prompt with claims that it helps Claude 3.5 Sonnet outperform o1 in reasoning.
I benchmarked this prompt to find out if the this claim is true ( thanks for @ai_for_success for the heads on this last night )
[Quoted tweet]
Can @AnthropicAI Claude 3.5 sonnet outperform @OpenAI o1 in reasoning? Combining Dynamic Chain of Thoughts, reflection, and verbal reinforcement, existing LLMs like Claude 3.5 Sonnet can be prompted to increase test-time compute and match reasoning strong models like OpenAI o1.
TL;DR:
 Combines Dynamic Chain of thoughts + reflection + verbal reinforcement prompting
Combines Dynamic Chain of thoughts + reflection + verbal reinforcement prompting
 Benchmarked against tough academic tests (JEE Advanced, UPSC, IMO, Putnam)
Benchmarked against tough academic tests (JEE Advanced, UPSC, IMO, Putnam)
 Claude 3.5 Sonnet outperformes GPT-4 and matched O1 models
Claude 3.5 Sonnet outperformes GPT-4 and matched O1 models
 LLMs can create internal simulations and take 50+ reasoning steps for complex problems
LLMs can create internal simulations and take 50+ reasoning steps for complex problems
 Works for smaller, open models like Llama 3.1 8B +10% (Llama 3.1 8B 33/48 vs GPT-4o 36/48)
Works for smaller, open models like Llama 3.1 8B +10% (Llama 3.1 8B 33/48 vs GPT-4o 36/48)
 Didn’t benchmark like MMLU, MMLU pro, or GPQA due to computing and budget constraints
Didn’t benchmark like MMLU, MMLU pro, or GPQA due to computing and budget constraints
 High token usage - Claude Sonnet 3.5 used around 1 million tokens for just 7 questions
High token usage - Claude Sonnet 3.5 used around 1 million tokens for just 7 questions

2/11
@ikristoph
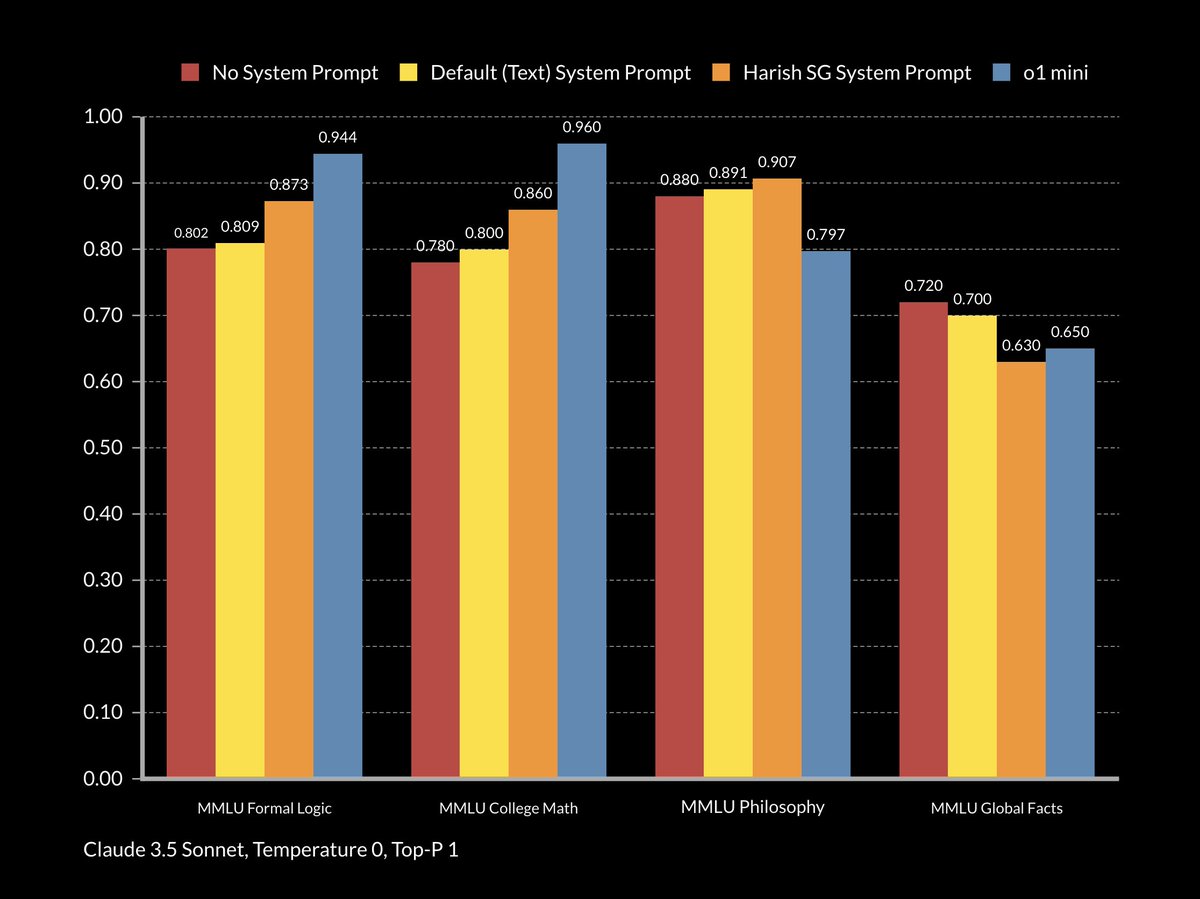
The TLDR is that this prompt does not improve Claude 3.5 Sonnet to o1 levels in reasoning but it does tangibly improve its performance in reasoning focused benchmarks.
However, this does come at the expense of 'knowledge' focused benchmarks where the model is more directly generating text it has been trained on.
3/11
@ikristoph
The 'formal logic' and 'college mathematics' benchmarks have significant reasoning focus. OpenAi's o1 excels in these. The use of this prompt with Sonnet also tangibly improves these.
The 'global facts' benchmark, like many other subject matter benchmarks, are much less reasoning focused. They're more about what the model knows and doesn't know. A complex prompt can 'confuse' a model so that even though the model can typically provide the correct answer it under performs because of the prompt.
This is what is happening here with this prompt applied.
4/11
@ikristoph
I want to add an additional note here. The use of this prompt means that a user will get an answer after a significant delay.
In fact, it took Sonnet about 50% longer to complete the benchmarks compared to o1 mini and 100-200% longer than when using a simpler prompt.
Token length was similarly impacted ( 100-200% more tokens ) so a significant incremental cost.
5/11
@Teknium1
Can you take this prompt to o1 and maybe llama instruct etc and benchmark those too?
6/11
@ikristoph
o1 doesn’t have system prompts but I could use this text as a test prefix; they don’t recommend it tho
I do plan to test llama early this week.
7/11
@LoganGrasby
I'm surprised. I'm finding exactly the opposite on coding tasks I'm trying today. This prompt is honestly a breakthrough.
8/11
@ikristoph
The tests are consistent with your experience. In general, coding tasks are reasoning tasks and the prompt tangibly improves Sonnet on these.
The prompt does not improve, and in some cases degrades, knowledge tasks. Although that may impact coding it likely does so less than then reasoning improves them.
9/11
@ai_for_success
Thanks Kristoph.
10/11
@ikristoph
I am going to do some llama ones too! I wonder how much of an improvement we get. It might help a great with a local model for coding.
11/11
@ikristoph
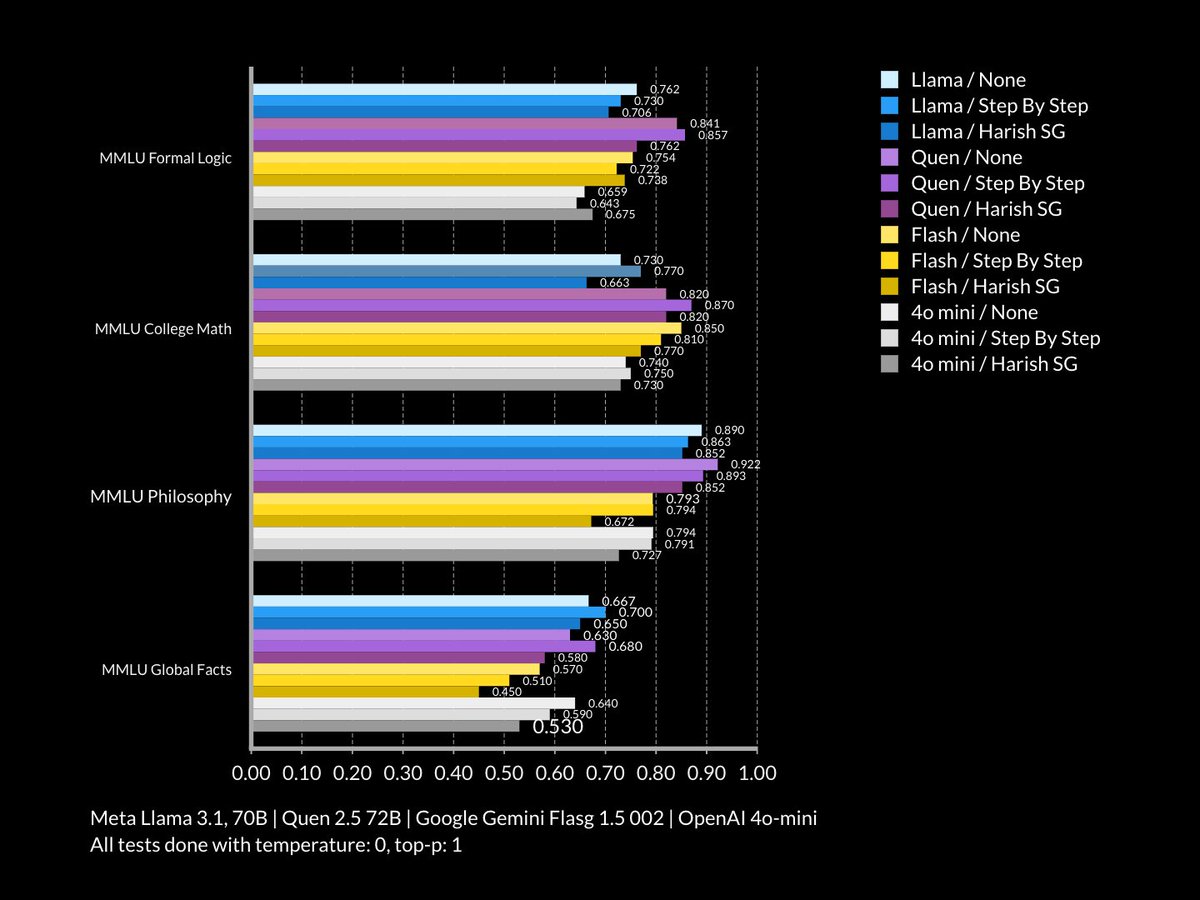
If anyone is interested, I also ran this prompt agains Llama 3.1 70B, Quen 2.5 72B, the latest Flash, as well as 4o mini.
[Quoted tweet]
If, like me, you are curious which small LLM open and commercial models have the best reasoning, and if elaborate prompts can make them better, I have some data for Llama, Quen, Flash, and 4o mini.
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
@ikristoph
There is much excitement about this prompt with claims that it helps Claude 3.5 Sonnet outperform o1 in reasoning.
I benchmarked this prompt to find out if the this claim is true ( thanks for @ai_for_success for the heads on this last night )
[Quoted tweet]
Can @AnthropicAI Claude 3.5 sonnet outperform @OpenAI o1 in reasoning? Combining Dynamic Chain of Thoughts, reflection, and verbal reinforcement, existing LLMs like Claude 3.5 Sonnet can be prompted to increase test-time compute and match reasoning strong models like OpenAI o1.
TL;DR:
Combines Dynamic Chain of thoughts + reflection + verbal reinforcement prompting Benchmarked against tough academic tests (JEE Advanced, UPSC, IMO, Putnam) Claude 3.5 Sonnet outperformes GPT-4 and matched O1 models LLMs can create internal simulations and take 50+ reasoning steps for complex problems Works for smaller, open models like Llama 3.1 8B +10% (Llama 3.1 8B 33/48 vs GPT-4o 36/48) Didn’t benchmark like MMLU, MMLU pro, or GPQA due to computing and budget constraints High token usage - Claude Sonnet 3.5 used around 1 million tokens for just 7 questions
2/11
@ikristoph
The TLDR is that this prompt does not improve Claude 3.5 Sonnet to o1 levels in reasoning but it does tangibly improve its performance in reasoning focused benchmarks.
However, this does come at the expense of 'knowledge' focused benchmarks where the model is more directly generating text it has been trained on.
3/11
@ikristoph
The 'formal logic' and 'college mathematics' benchmarks have significant reasoning focus. OpenAi's o1 excels in these. The use of this prompt with Sonnet also tangibly improves these.
The 'global facts' benchmark, like many other subject matter benchmarks, are much less reasoning focused. They're more about what the model knows and doesn't know. A complex prompt can 'confuse' a model so that even though the model can typically provide the correct answer it under performs because of the prompt.
This is what is happening here with this prompt applied.
4/11
@ikristoph
I want to add an additional note here. The use of this prompt means that a user will get an answer after a significant delay.
In fact, it took Sonnet about 50% longer to complete the benchmarks compared to o1 mini and 100-200% longer than when using a simpler prompt.
Token length was similarly impacted ( 100-200% more tokens ) so a significant incremental cost.
5/11
@Teknium1
Can you take this prompt to o1 and maybe llama instruct etc and benchmark those too?
6/11
@ikristoph
o1 doesn’t have system prompts but I could use this text as a test prefix; they don’t recommend it tho
I do plan to test llama early this week.
7/11
@LoganGrasby
I'm surprised. I'm finding exactly the opposite on coding tasks I'm trying today. This prompt is honestly a breakthrough.
8/11
@ikristoph
The tests are consistent with your experience. In general, coding tasks are reasoning tasks and the prompt tangibly improves Sonnet on these.
The prompt does not improve, and in some cases degrades, knowledge tasks. Although that may impact coding it likely does so less than then reasoning improves them.
9/11
@ai_for_success
Thanks Kristoph.
10/11
@ikristoph
I am going to do some llama ones too! I wonder how much of an improvement we get. It might help a great with a local model for coding.
11/11
@ikristoph
If anyone is interested, I also ran this prompt agains Llama 3.1 70B, Quen 2.5 72B, the latest Flash, as well as 4o mini.
[Quoted tweet]
If, like me, you are curious which small LLM open and commercial models have the best reasoning, and if elaborate prompts can make them better, I have some data for Llama, Quen, Flash, and 4o mini.
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
1/11
@_philschmid
Can @AnthropicAI Claude 3.5 sonnet outperform @OpenAI o1 in reasoning? Combining Dynamic Chain of Thoughts, reflection, and verbal reinforcement, existing LLMs like Claude 3.5 Sonnet can be prompted to increase test-time compute and match reasoning strong models like OpenAI o1.
TL;DR:
Combines Dynamic Chain of thoughts + reflection + verbal reinforcement prompting
Benchmarked against tough academic tests (JEE Advanced, UPSC, IMO, Putnam)
Claude 3.5 Sonnet outperformes GPT-4 and matched O1 models
LLMs can create internal simulations and take 50+ reasoning steps for complex problems
Works for smaller, open models like Llama 3.1 8B +10% (Llama 3.1 8B 33/48 vs GPT-4o 36/48)
Didn’t benchmark like MMLU, MMLU pro, or GPQA due to computing and budget constraints
High token usage - Claude Sonnet 3.5 used around 1 million tokens for just 7 questions
2/11
@_philschmid
Blog:
Prompt:
Github: GitHub - harishsg993010/LLM-Research-Scripts
3/11
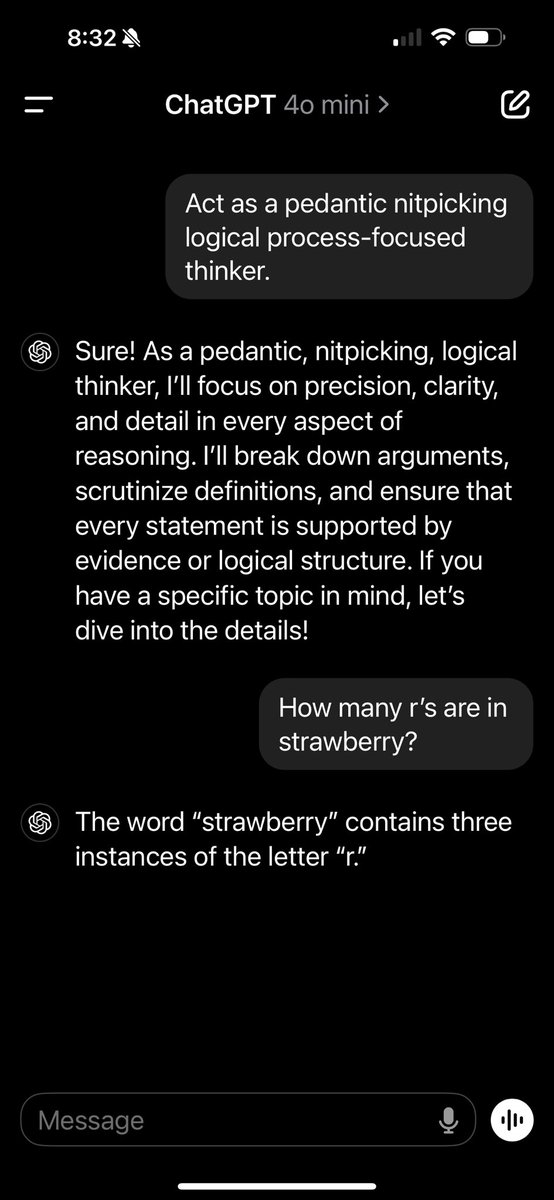
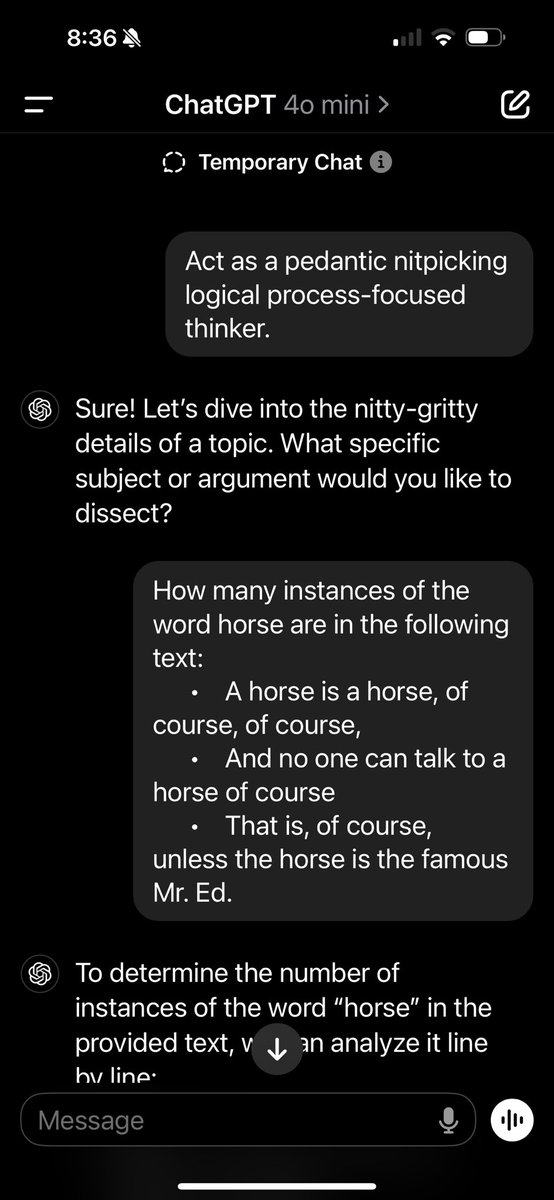
@AndrewMayne
Telling a model, even GPT-4o-mini, to "Act as a pedantic nitpicking logical process-focused thinker" gets similar results with Strawberry, 9.11/9.9, counting horses, etc.

4/11
@Teknium1
But what is the benchmark
5/11
@ikristoph
I’ve already done a quick test on this prompt and while it does tangibly improve reasoning it’s still quite a bit below o1. ( More tests to do though certainly. )
[Quoted tweet]
MMLU Formal Logic. 0 shot. Temperature 0, Top P 1.0. There is a tangible increase which is quite an accomplishment!
It's still quite a bit below o1 however. I will do some more tests tomorrow.

6/11
@zirkelc_
1 million tokens for 7 questions sounds like a lot now, but in a few months it will probably be negligible
7/11
@GozukaraFurkan
It performs better at coding that is for sure
8/11
@beingavishkar
I always thought asking the LLM to give a "confidence" or reward for to its own generation is meaningless because it isn't calibrated on any scale.
Is there any ablation that proves that specifically, i.e. LLM is indeed more wrong when it says reward=0.7 as opposed to 0.9?
9/11
@manojlds
What's dynamic CoT? Any reference?
10/11
@jessyseonoob
great, there was a buzz about Reflection earlier, but you make it work. It remind me the early AI language from project A.l.i.c.e and the AIML tags from dr wallace that was used by @pandorabots
need to try on @MistralAI too
11/11
@AidfulAI
That's super cool, especially as everyone can currently use Claude 3.5 Sonnet for FREE in the editor Zed.
[Quoted tweet]
The secret for unlimited FREE Claude 3.5 Sonnet requests! My latest newsletter reveals a game-changing tool you won't want to miss.
Zed: From Coding Editor to Universal AI Assistant
Imagine having unlimited access to one of the world's most advanced AI models, right at your fingertips, completely free. This isn't a far-off dream – it's the reality offered by Zed, an open-source coding editor that for me rapidly evolved into something much more. It is my central application to work with AI.
At its core, Zed is designed as a tool for developers, offering a fast and efficient coding environment. However, the recent addition of Zed AI has transformed it into a universal assistant capable of tackling a wide range of tasks. One aspect which made me started to use Zed, is that Anthropic's Claude 3.5 Sonnet, which from my point of view is currently the best model to assist you at writing, can be used for free in Zed. It's important to note that the duration of this free access is unclear, and using Zed intensively for non-coding tasks might not be the intended use case. However, the potential benefits are simply too good to ignore.
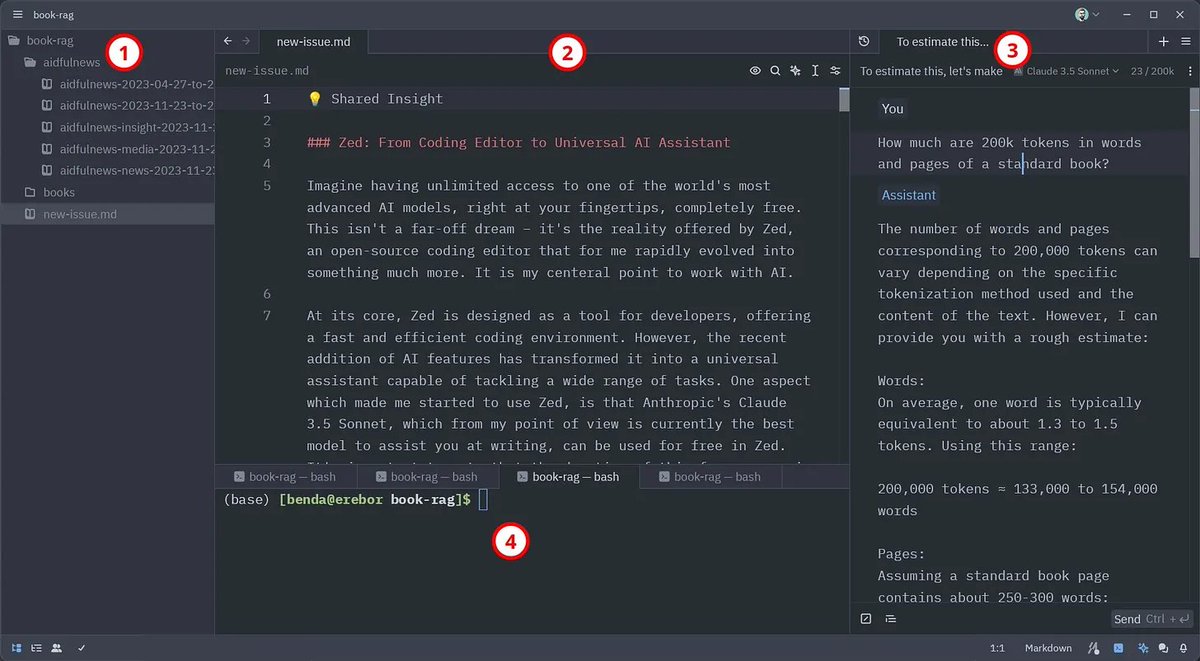
Zed has four main sections: 1) file tree of current project, 2) open files, 3) assistant panel, 4) terminal.
What truly makes Zed shine is its suite of context-building commands. The /file command allows you to seamlessly incorporate any text file from your disk into the AI conversation, while /fetch can parse and include a webpage directly in your prompts. Furthermore, you can create your own prompt library feature. You can save text snippets and recall them with the /prompt command, providing a neat way to store personal information that helps guide the AI's replies in the direction you need. For example, you could save details about your specific Linux operating system setup in a prompt, ensuring that responses to Linux-related questions are tailored precisely to your environment.
These features are not just powerful, they are also transparent. Every piece of added context remains fully visible and editable, giving you unprecedented control over your AI interactions. And by using the Claude 3.5 Sonnet model, you can make use of up to 200k tokens for your requests, which corresponds to around 150k words or 500 book pages.
As in other chatbot applications, you can organize multiple chats in tabs and access older chats via a history button, allowing you to revisit and build upon previous conversations.
Initially, I used Zed for the intended use case of programming. However, I realized its capabilities for general requests and now have the editor open and ask for assistance with a wide variety of tasks. From simple word translations to complex document analysis, creative writing, and in-depth research. The ability to easily incorporate content from popular file-based note-taking apps like @logseq and @obsdmd has made Zed a valuable asset in my knowledge management workflows as well.
While Zed's primary focus remains on coding, its AI features have opened up a world of possibilities. It's not just a coding editor – it's a gateway to a new era of AI-assisted work and creativity. The context-building commands are really helpful in tailoring the AI responses to your needs. From my perspective, especially as long as you can use Claude 3.5 Sonnet for free in Zed, it is the best way to explore the new possibilities text-based AI models bring to you.
Currently, Zed offers official builds for macOS and Linux. While Windows is not yet officially supported, it can be installed relatively easily using Msys2 instead of building it yourself. MSYS2 is a software distribution and building platform for Windows that provides a Unix-like environment, making it easier to port and run Unix-based software on Windows systems. I successfully installed Zed on a Windows 11 system, following the MSYS2 installation instructions for Windows (links in post below).
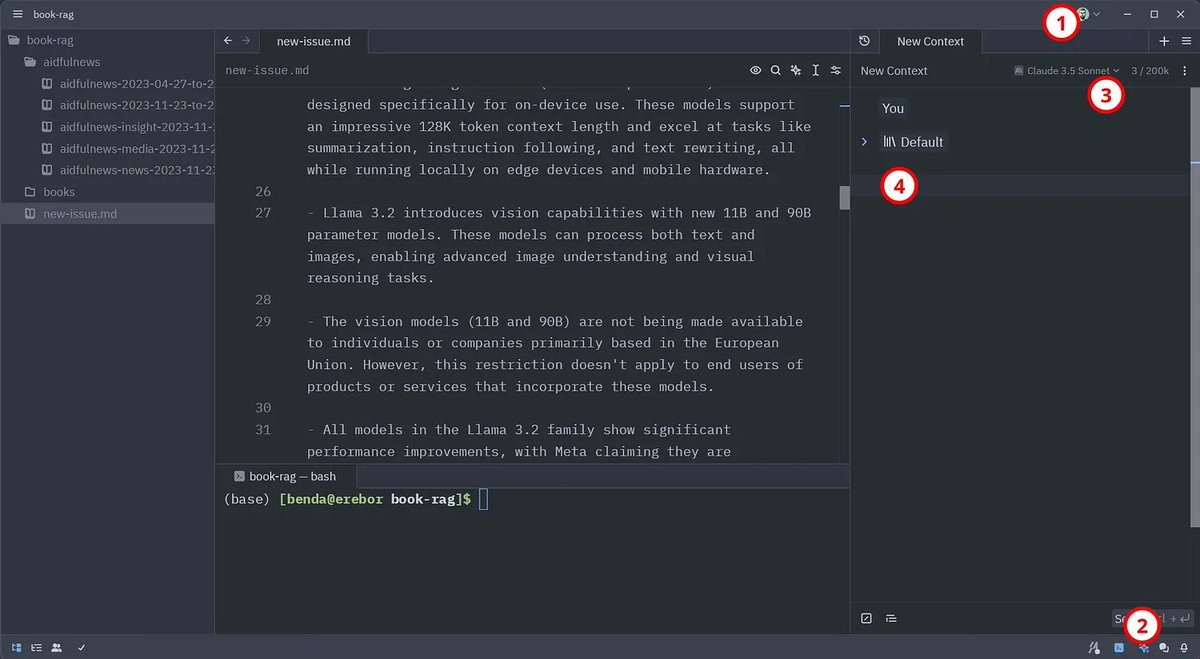
Steps to get started with Zed. 1) login, 2) assistant panel, 3) choose model, 4) chat.
If you are now eager to get started with Zed for non-coding tasks, follow these steps after installation (the enumeration corresponds to the numbers shown in the image above):
1. Open the assistant panel with a click on the button in the lower right (or CTRL/CMD + ?)
button in the lower right (or CTRL/CMD + ?)
2. Choose “Claude 3.5 Sonnet Zed” in the dropdown menu
3. Start chatting in the assistant panel (send message with CTRL/CMD + ENTER)
As Zed is, from my perspective, currently one of the most powerful ways to use text-generating AI, I intend to create some video tutorials to help others unlock Zed's full potential. If you're interested in seeing tutorials on specific Zed features or use cases, please let me know! Your feedback will help shape the content and ensure it's as useful as possible. Have you tried Zed yourself? What has your experience been like? I'm eager to hear your thoughts and suggestions on how we can make the most of this powerful tool. Just hit reply and share your thoughts.
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
@_philschmid
Can @AnthropicAI Claude 3.5 sonnet outperform @OpenAI o1 in reasoning? Combining Dynamic Chain of Thoughts, reflection, and verbal reinforcement, existing LLMs like Claude 3.5 Sonnet can be prompted to increase test-time compute and match reasoning strong models like OpenAI o1.
TL;DR:
Combines Dynamic Chain of thoughts + reflection + verbal reinforcement prompting Benchmarked against tough academic tests (JEE Advanced, UPSC, IMO, Putnam) Claude 3.5 Sonnet outperformes GPT-4 and matched O1 models LLMs can create internal simulations and take 50+ reasoning steps for complex problems Works for smaller, open models like Llama 3.1 8B +10% (Llama 3.1 8B 33/48 vs GPT-4o 36/48) Didn’t benchmark like MMLU, MMLU pro, or GPQA due to computing and budget constraints High token usage - Claude Sonnet 3.5 used around 1 million tokens for just 7 questions
2/11
@_philschmid
Blog:
Prompt:
Github: GitHub - harishsg993010/LLM-Research-Scripts
3/11
@AndrewMayne
Telling a model, even GPT-4o-mini, to "Act as a pedantic nitpicking logical process-focused thinker" gets similar results with Strawberry, 9.11/9.9, counting horses, etc.
4/11
@Teknium1
But what is the benchmark
5/11
@ikristoph
I’ve already done a quick test on this prompt and while it does tangibly improve reasoning it’s still quite a bit below o1. ( More tests to do though certainly. )
[Quoted tweet]
MMLU Formal Logic. 0 shot. Temperature 0, Top P 1.0. There is a tangible increase which is quite an accomplishment!
It's still quite a bit below o1 however. I will do some more tests tomorrow.
6/11
@zirkelc_
1 million tokens for 7 questions sounds like a lot now, but in a few months it will probably be negligible
7/11
@GozukaraFurkan
It performs better at coding that is for sure
8/11
@beingavishkar
I always thought asking the LLM to give a "confidence" or reward for to its own generation is meaningless because it isn't calibrated on any scale.
Is there any ablation that proves that specifically, i.e. LLM is indeed more wrong when it says reward=0.7 as opposed to 0.9?
9/11
@manojlds
What's dynamic CoT? Any reference?
10/11
@jessyseonoob
great, there was a buzz about Reflection earlier, but you make it work. It remind me the early AI language from project A.l.i.c.e and the AIML tags from dr wallace that was used by @pandorabots
need to try on @MistralAI too
11/11
@AidfulAI
That's super cool, especially as everyone can currently use Claude 3.5 Sonnet for FREE in the editor Zed.
[Quoted tweet]
The secret for unlimited FREE Claude 3.5 Sonnet requests! My latest newsletter reveals a game-changing tool you won't want to miss.
Zed: From Coding Editor to Universal AI Assistant
Imagine having unlimited access to one of the world's most advanced AI models, right at your fingertips, completely free. This isn't a far-off dream – it's the reality offered by Zed, an open-source coding editor that for me rapidly evolved into something much more. It is my central application to work with AI.
At its core, Zed is designed as a tool for developers, offering a fast and efficient coding environment. However, the recent addition of Zed AI has transformed it into a universal assistant capable of tackling a wide range of tasks. One aspect which made me started to use Zed, is that Anthropic's Claude 3.5 Sonnet, which from my point of view is currently the best model to assist you at writing, can be used for free in Zed. It's important to note that the duration of this free access is unclear, and using Zed intensively for non-coding tasks might not be the intended use case. However, the potential benefits are simply too good to ignore.
Zed has four main sections: 1) file tree of current project, 2) open files, 3) assistant panel, 4) terminal.
What truly makes Zed shine is its suite of context-building commands. The /file command allows you to seamlessly incorporate any text file from your disk into the AI conversation, while /fetch can parse and include a webpage directly in your prompts. Furthermore, you can create your own prompt library feature. You can save text snippets and recall them with the /prompt command, providing a neat way to store personal information that helps guide the AI's replies in the direction you need. For example, you could save details about your specific Linux operating system setup in a prompt, ensuring that responses to Linux-related questions are tailored precisely to your environment.
These features are not just powerful, they are also transparent. Every piece of added context remains fully visible and editable, giving you unprecedented control over your AI interactions. And by using the Claude 3.5 Sonnet model, you can make use of up to 200k tokens for your requests, which corresponds to around 150k words or 500 book pages.
As in other chatbot applications, you can organize multiple chats in tabs and access older chats via a history button, allowing you to revisit and build upon previous conversations.
Initially, I used Zed for the intended use case of programming. However, I realized its capabilities for general requests and now have the editor open and ask for assistance with a wide variety of tasks. From simple word translations to complex document analysis, creative writing, and in-depth research. The ability to easily incorporate content from popular file-based note-taking apps like @logseq and @obsdmd has made Zed a valuable asset in my knowledge management workflows as well.
While Zed's primary focus remains on coding, its AI features have opened up a world of possibilities. It's not just a coding editor – it's a gateway to a new era of AI-assisted work and creativity. The context-building commands are really helpful in tailoring the AI responses to your needs. From my perspective, especially as long as you can use Claude 3.5 Sonnet for free in Zed, it is the best way to explore the new possibilities text-based AI models bring to you.
Currently, Zed offers official builds for macOS and Linux. While Windows is not yet officially supported, it can be installed relatively easily using Msys2 instead of building it yourself. MSYS2 is a software distribution and building platform for Windows that provides a Unix-like environment, making it easier to port and run Unix-based software on Windows systems. I successfully installed Zed on a Windows 11 system, following the MSYS2 installation instructions for Windows (links in post below
).Steps to get started with Zed. 1) login, 2) assistant panel, 3) choose model, 4) chat.
If you are now eager to get started with Zed for non-coding tasks, follow these steps after installation (the enumeration corresponds to the numbers shown in the image above):
1. Open the assistant panel with a click on the
button in the lower right (or CTRL/CMD + ?)2. Choose “Claude 3.5 Sonnet Zed” in the dropdown menu
3. Start chatting in the assistant panel (send message with CTRL/CMD + ENTER)
As Zed is, from my perspective, currently one of the most powerful ways to use text-generating AI, I intend to create some video tutorials to help others unlock Zed's full potential. If you're interested in seeing tutorials on specific Zed features or use cases, please let me know! Your feedback will help shape the content and ensure it's as useful as possible. Have you tried Zed yourself? What has your experience been like? I'm eager to hear your thoughts and suggestions on how we can make the most of this powerful tool. Just hit reply and share your thoughts.
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
 Post:
Post:  Dataset:
Dataset: 

 99 Common Crawls
99 Common Crawls 14 Curated Sources
14 Curated Sources recipe to easily adjust data weighting and train the most performant models
recipe to easily adjust data weighting and train the most performant models

 Chain-of-Thought reasoning for RM
Chain-of-Thought reasoning for RM Leveraging test-time compute
Leveraging test-time compute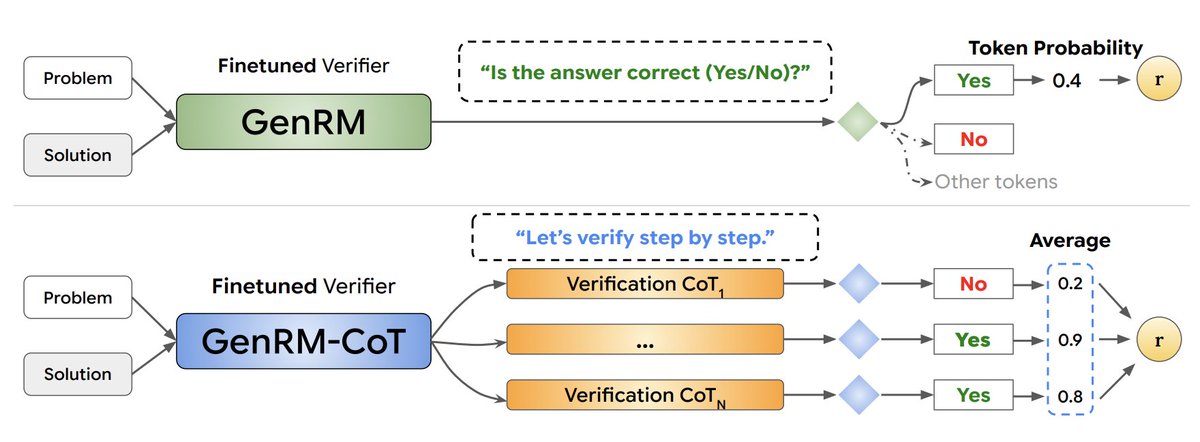






 New Steps for better dataset sampling, deduplication (embeddings and minhash), truncation of inputs and better combining outputs
New Steps for better dataset sampling, deduplication (embeddings and minhash), truncation of inputs and better combining outputs 50% Cost Savings by pausing pipelines and using OpenAI Batch API
50% Cost Savings by pausing pipelines and using OpenAI Batch API ️ Caching for step outputs for maximum reusability—even if the pipeline changes.
️ Caching for step outputs for maximum reusability—even if the pipeline changes. New Tasks with CLAIR, APIGen, URIAL, TextClassification, TextClustering, and an updated TextGeneration task.
New Tasks with CLAIR, APIGen, URIAL, TextClassification, TextClustering, and an updated TextGeneration task. Cluster similar documents to identify neighboring documents for each one.
Cluster similar documents to identify neighboring documents for each one. Extend Encoder to include information from these neighboring documents when generating embeddings.
Extend Encoder to include information from these neighboring documents when generating embeddings. Train the model using a contrastive learning objective that incorporates neighboring documents into the loss function.
Train the model using a contrastive learning objective that incorporates neighboring documents into the loss function. Best open embedding Model (< 250M) on MTEB with 65.00
Best open embedding Model (< 250M) on MTEB with 65.00 Without ahead of time information achieves 63.8 on MTEB
Without ahead of time information achieves 63.8 on MTEB Outperforms traditional biencoders, especially out-of-domain tasks
Outperforms traditional biencoders, especially out-of-domain tasks Filtering false negatives boosts performance further.
Filtering false negatives boosts performance further.
 Experts aren't domain specialists, but rather learn to handle specific tokens in specific contexts
Experts aren't domain specialists, but rather learn to handle specific tokens in specific contexts Load balancing is crucial to ensure all experts are utilized effectively during training
Load balancing is crucial to ensure all experts are utilized effectively during training The router uses probability distributions to select which experts process which tokens
The router uses probability distributions to select which experts process which tokens MoE isn't limited to language models - it's also being adapted for vision models
MoE isn't limited to language models - it's also being adapted for vision models Mixtral 8x7B demonstrates the power of MoE, loading 46.7B parameters but only using 12.8B during inference
Mixtral 8x7B demonstrates the power of MoE, loading 46.7B parameters but only using 12.8B during inference
 Add safety mechanisms and monitoring systems
Add safety mechanisms and monitoring systems Test and iterate to refine the agent's components and behavior.
Test and iterate to refine the agent's components and behavior.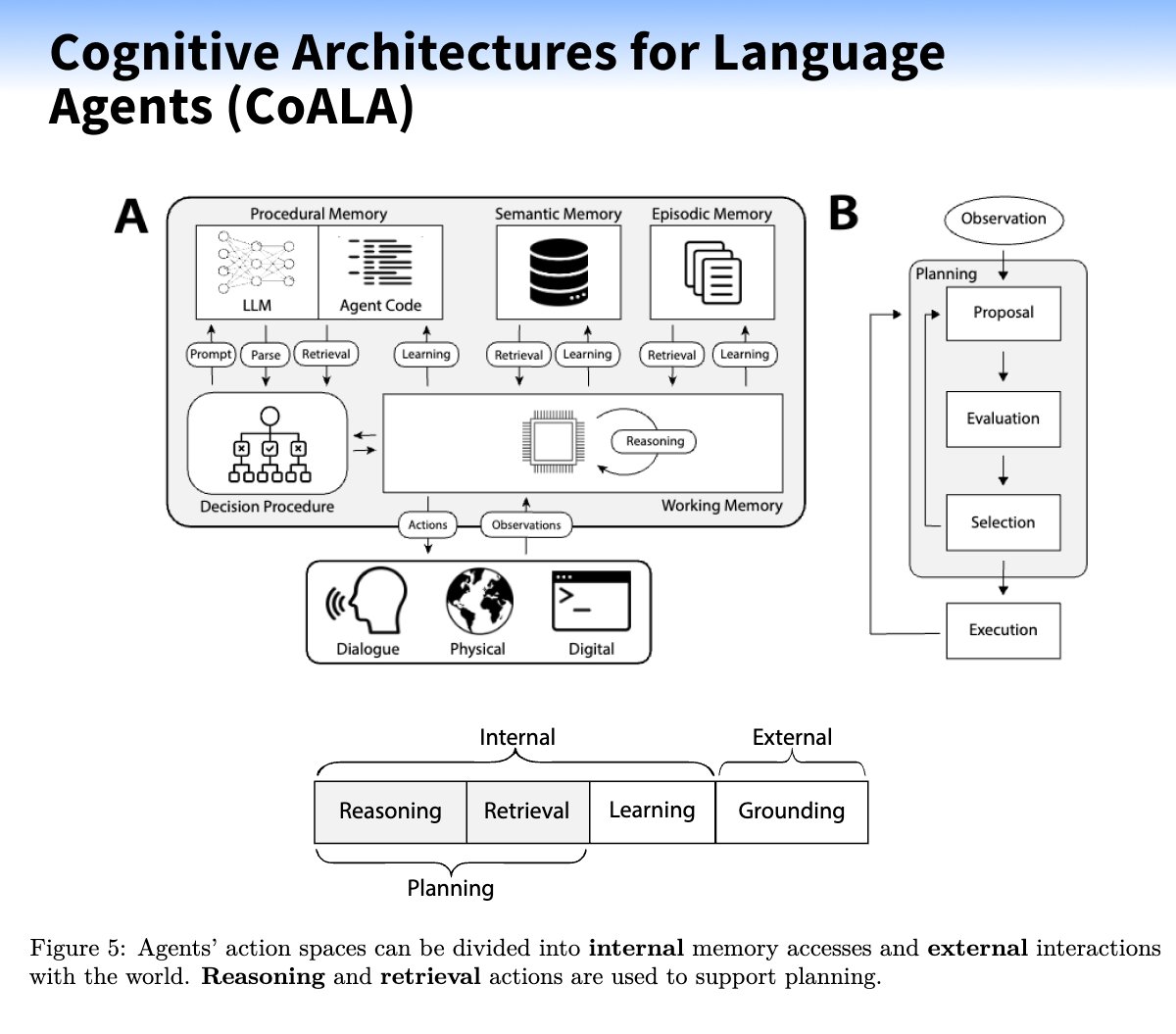

 LLMs struggle with multi-hop reasoning, leading to a "reasoning gap" in chained math problems.
LLMs struggle with multi-hop reasoning, leading to a "reasoning gap" in chained math problems. The reasoning gap might come from distraction and too much additional context (indicating missing training data?).
The reasoning gap might come from distraction and too much additional context (indicating missing training data?).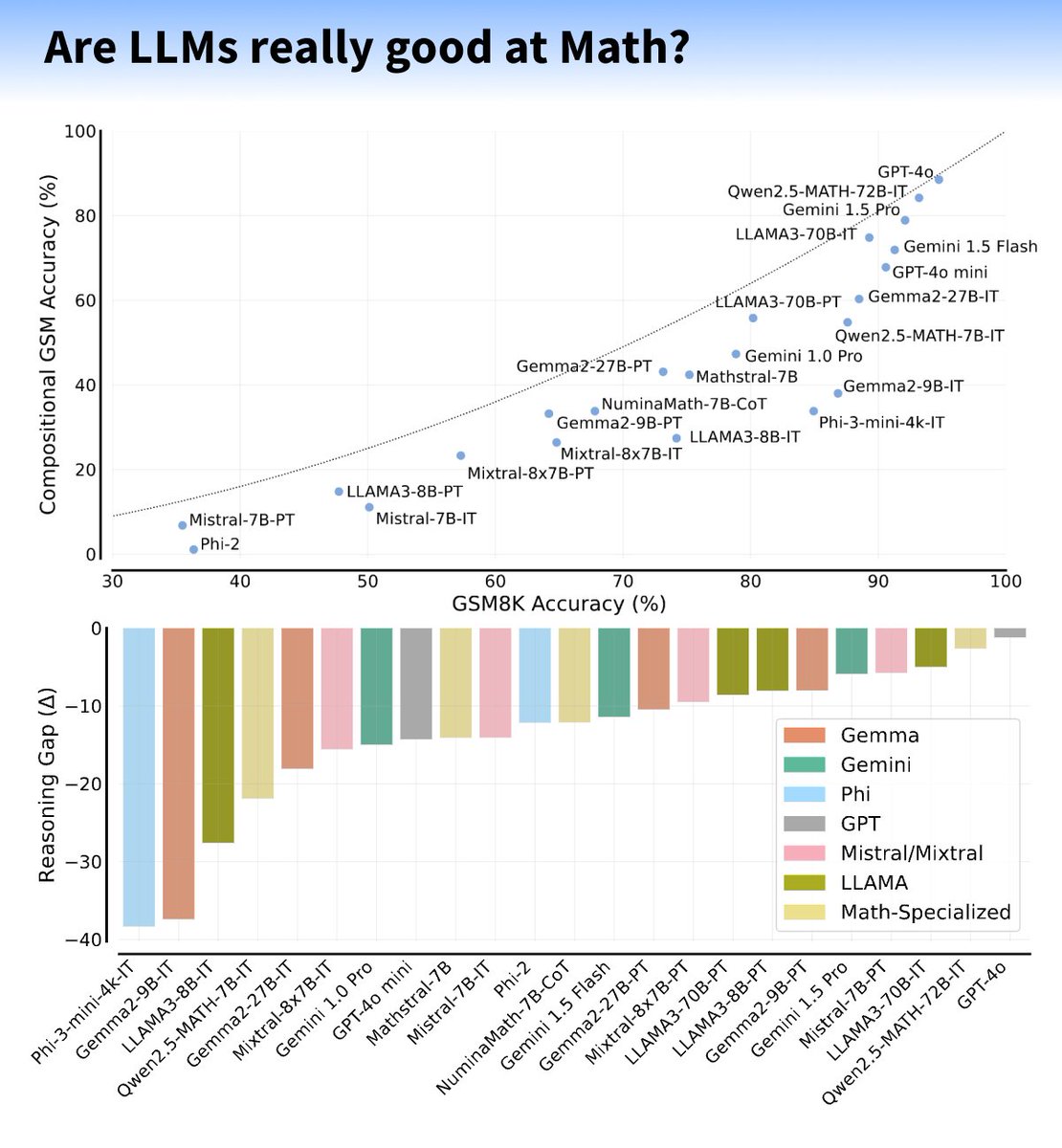




 or is it the Llama one?
or is it the Llama one? correct)
correct) And reminder: this also works for videos!
And reminder: this also works for videos! Limited accuracy in medical prescription analysis, but surprisingly good at some medical report interpretations
Limited accuracy in medical prescription analysis, but surprisingly good at some medical report interpretations
 @OpenAI's "meta" prompt for optimizing GPT prompts might have already leaked!
@OpenAI's "meta" prompt for optimizing GPT prompts might have already leaked! 

