The more data the Reflection 70B creators publish about the model, the more evidence the open source AI community has to pore over.

venturebeat.com
Reflection 70B saga continues as training data provider releases post-mortem report
Carl Franzen@carlfranzen
October 3, 2024 2:07 PM
Credit: VentureBeat made with Midjourney
On September 5th, 2024, Matt Shumer, co-founder and CEO of the startup
Hyperwrite AI (also known as OthersideAI) took to the
social network X to post the bombshell news that he had fine-tuned a version of Meta’s open source Llama 3.1-70B into an even more performant large language model (LLM) known as
Reflection 70B — so performant, in fact, based on alleged third-party benchmarking test results he published, that it was “the world’s top open-source model,” according to
his post.
I'm excited to announce Reflection 70B, the world’s top open-source model.
Trained using Reflection-Tuning, a technique developed to enable LLMs to fix their own mistakes.
405B coming next week – we expect it to be the best model in the world.
Built w/ @GlaiveAI.
Read on  : pic.twitter.com/kZPW1plJuo
: pic.twitter.com/kZPW1plJuo
— Matt Shumer (@mattshumer_) September 5, 2024
However, shortly after its release, third-party evaluators in the AI research and hosting community struggled to reproduce the claimed results, leading to
accusations of fraud.
Researchers cited discrepancies between the announced benchmark results and their independent tests, sparking a wave of criticism on social platforms such as Reddit and X.
In response to these concerns,
Shumer pledged he would conduct a review of the issues alongside Sahil Chaudhary, founder of
Glaive, the AI startup whose synthetic data Shumer claimed he had trained Reflection 70B on — and which he later revealed to have invested what he called a small amount into.
Now, nearly a month later, Chaudhary last night released a
post-mortem report on his Glaive AI blog about the Reflection 70B model and published resources for the open-source AI community to test the model and his training process on their own. He says while he was unable to reproduce all of the same benchmarks, he “found a bug in the initial code,” resulting in several results appearing higher than what he has found on recent tests of Reflection 70B. However, other benchmark results appear higher than before — adding to the mystery.
On September 5th, @mattshumer_ announced Reflection 70B, a model fine-tuned on top of Llama 3.1 70B, showing SoTA benchmark numbers, which was trained by me on Glaive generated data.
Today, I'm sharing model artifacts to reproduce the initial claims and a post-mortem to address…
— Sahil Chaudhary (@csahil28) October 2, 2024
As Chaudhary wrote in the post:
“
There were a lot of mistakes made by us in the way we launched the model, and handled the problems reported by the community. I understand that things like these have a significant negative effect on the open source ecosystem, and I’d like to apologize for that. I hope that this adds some clarity to what happened, and is a step in the direction of regaining the lost trust. I have released all of the assets required to independently verify the benchmarks and use this model.“
Sharing model artifacts
To restore transparency and rebuild trust, Chaudhary shared several resources to help the community replicate the Reflection 70B benchmarks. These include:
Model weights: Available on Hugging Face, providing the pre-trained version of Reflection 70B.
Training data: Released for public access, enabling independent tests on the dataset used to fine-tune the model.
Training scripts and evaluation code: Available on GitHub, these scripts allow for reproduction of the model’s training and evaluation process.
These resources aim to clarify how the model was developed and offer a path for the community to validate the original performance claims.
Reproducing the benchmarks
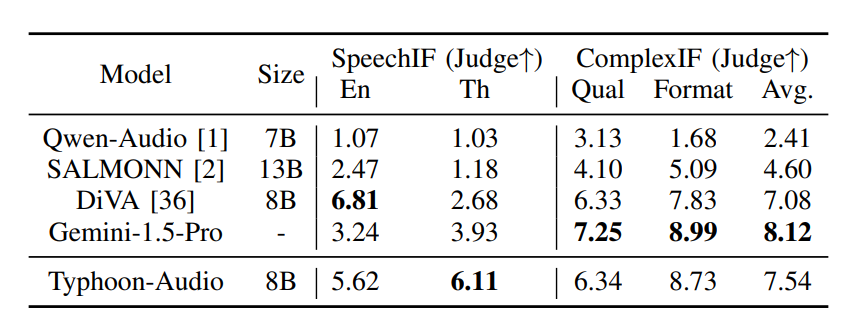
In his post-mortem, Chaudhary explained that a major issue with reproducing the initial benchmark results stemmed from a bug in the evaluation code. This bug caused inflated scores in certain tasks, such as MATH and GSM8K, due to an error in how the system handled responses from an external API. The corrected benchmarks show slightly lower, but still strong, performance relative to the initial report.
The updated benchmark results for Reflection 70B are as follows:
MMLU: 90.94%
GPQA: 55.6%
HumanEval: 89.02%
MATH: 70.8%
GSM8K: 95.22%
IFEVAL: 87.63%
Compare that to the originally stated performance of:
MMLU: 89.9%
GPQA: 55.3%
HumanEval: 91%
MATH: 79.7%
GSM8K: 99.2%
IFEVAL: 90.13%
Although the revised scores are not as high as those initially reported, Chaudhary asserts that they are more accurate reflections of the model’s capabilities.
He also addressed concerns about dataset contamination, confirming that tests showed no significant overlap between the training data and benchmark sets.
Reflecting on a hasty release
Chaudhary admitted that the decision to release Reflection 70B was made hastily, driven by enthusiasm for the model’s performance on reasoning-based tasks.
He noted that the launch lacked sufficient testing, particularly regarding the compatibility of the model files, and that he and Shumer had not verified whether the model could be easily downloaded and run by the community.
“We shouldn’t have launched without testing, and with the tall claims of having the best open-source model,” Chaudhary wrote. He also acknowledged that more transparency was needed, especially regarding the model’s strengths and weaknesses. While Reflection 70B excels at reasoning tasks, it struggles in areas like creativity and general user interaction, a fact that was not communicated at launch.
Clarifying API confusion
One of the more serious accusations involved the suspicion that the Reflection 70B API was simply relaying outputs from Anthropic’s Claude model.
Users reported strange behavior in the model’s outputs, including responses that seemed to reference Claude directly.
Chaudhary addressed these concerns, explaining that although some of these behaviors were reproducible, he asserts there was no use of Claude APIs or any form of word filtering in the Reflection 70B model.
He reiterated that the API was run on Glaive AI’s compute infrastructure, and Matt Shumer had no access to the code or servers used during this period.
Looking ahead
In closing, Chaudhary emphasized his commitment to transparency and expressed his hope that this post-mortem and the release of model artifacts will help restore trust in the project. He also confirmed that Matt Shumer is continuing independent efforts to reproduce the benchmark scores.
Despite the setbacks, Chaudhary believes the “reflection tuning” approach — in which a model is given time to check its responses for accuracy before outputting them to a user — has potential and encourages further experimentation by the AI community. “The approach explored has merit, and I look forward to others continuing to explore this technique,” he said.
Shumer, for his part, has
posted on X stating: “I am still in the process of validating Reflection myself, as Sahil wrote in his postmortem, but I am encouraged by Sahil’s transparency here on the benchmarks he reported and the API he ran. We still believe in + are working on this approach. Hoping to finish up my repro soon.”
Skepticism among open source AI community remains
Despite Chaudhary’s claims to offer transparency and an innocent explanation for what happened with Reflection 70B, many in the AI community who were initially excited about the model and its stated performance remain skeptical, feeling as though they were burned by erroneous claims and potentially tricked before.
“Still doesn’t feel like anything adds up here,” wrote
Alexander Moini, an AI researcher, on X, adding “It took a month to get the model weights on to HF [Hugging Face]?”
Still doesn’t feel like anything adds up here.
It took a month to get the model weights on to HF?
And you’ve had a private api with the “real” weights the whole time? Not to mention it supposedly having tokenizer issues, that look a lot like tokenizers used by anthropic +…
— Alex (@AlexanderMoini)
October 3, 2024
Yuchen Jin, co-founder and CTO of
Hyperbolic Labs, a startup that
offers cloud-based GPUs and other AI services on demand who initially worked hard and late to host Reflection 70B before criticizing Shumer over its discrepancies, also voiced skepticism on X toward Chaudhary’s post-mortem report, pointing out that Chaudhary’s claims on X that he “reproduced all but two of the initially reported scores,” don’t actually match with the data he provided, which show at least 4 benchmarks changing scores from before to now.
"i’ve reproduced all but two of the initially reported scores"
> should we compare the first and last columns? There is a gap between the last four benchmarks, could you clarify why you say you've reproduced all but two of the initially reported scores? pic.twitter.com/PHSe6CJD7A
— Yuchen Jin (@Yuchenj_UW) October 2, 2024
But perhaps the most damning commentary comes from the
Reddit subreddit r/Local LLaMA, wherein one user, “fukkSides” pointed out that Chaudhary could have taken the intervening month to fine-tune a new model to back up his claims that it randomly outputs text indicating it is actually Anthropic’s Claude 3.5 under the hood — which would explain said outputs experienced by users previously and led them to the conclusion that Reflection 70B was a fraudulent wrapper around this other proprietary model served through an API.
Meanwhile, another Redditor, “DangerousBenefit” looked into the training data Chaudhary released today and
found it was filled with many instances of the phrase “as an AI language model,” which indicates it could be generated primarily from OpenAI’s ChatGPT and likely wasn’t properly cleaned.
Regardless, the more data the Reflection 70B creators publish about the model, the more evidence the open source AI community has to pore over and check their work.






















 DiVA — Distilled Voice Assistant
DiVA — Distilled Voice Assistant  @WilliamBarrHeld
@WilliamBarrHeld  End-to-end differentiable speech LM; early fusion with Whisper and Llama 3 8B
End-to-end differentiable speech LM; early fusion with Whisper and Llama 3 8B Website: diva-audio.github.io
Website: diva-audio.github.io Try DiVA with our side-by-side comparison to Qwen Audio and SALMONN. Feedback is welcome
Try DiVA with our side-by-side comparison to Qwen Audio and SALMONN. Feedback is welcome