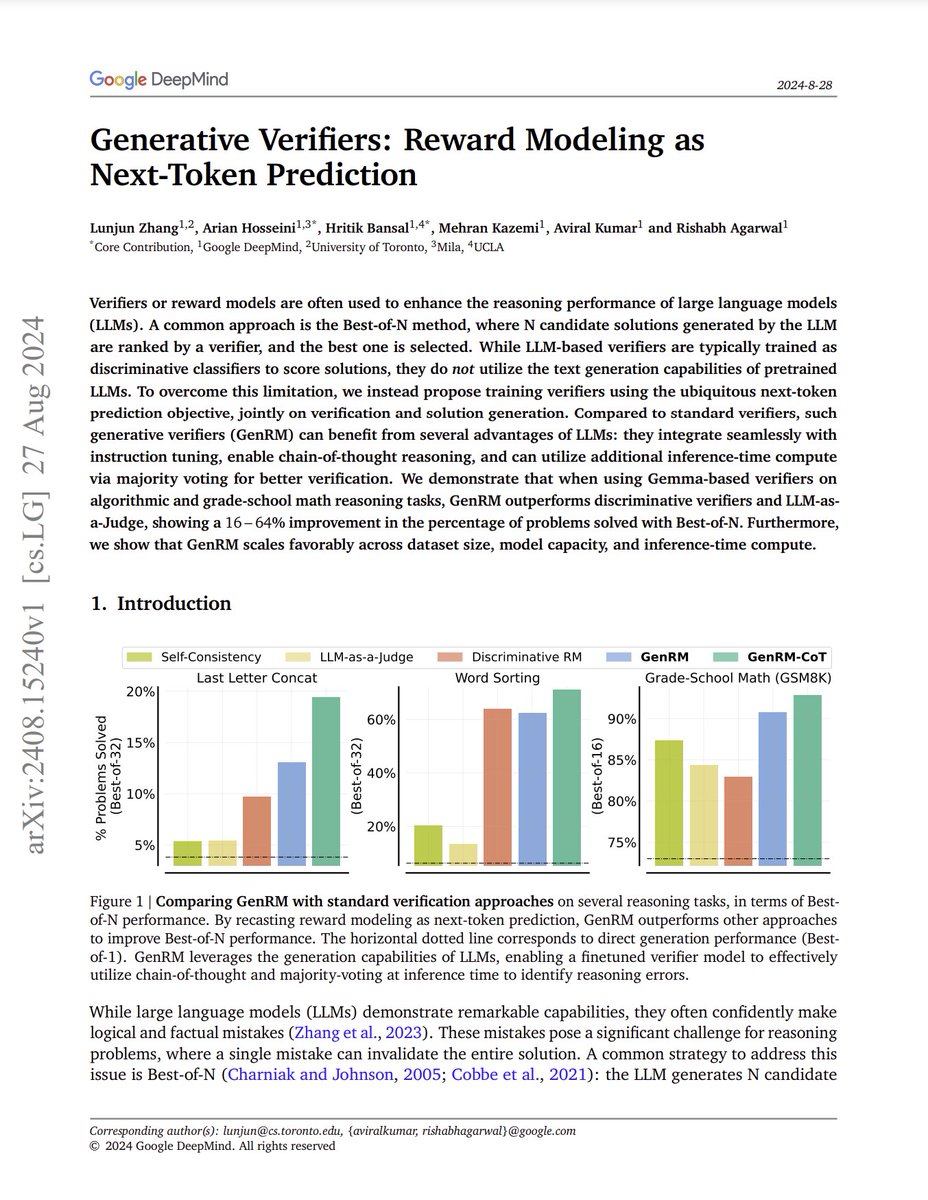
1/11
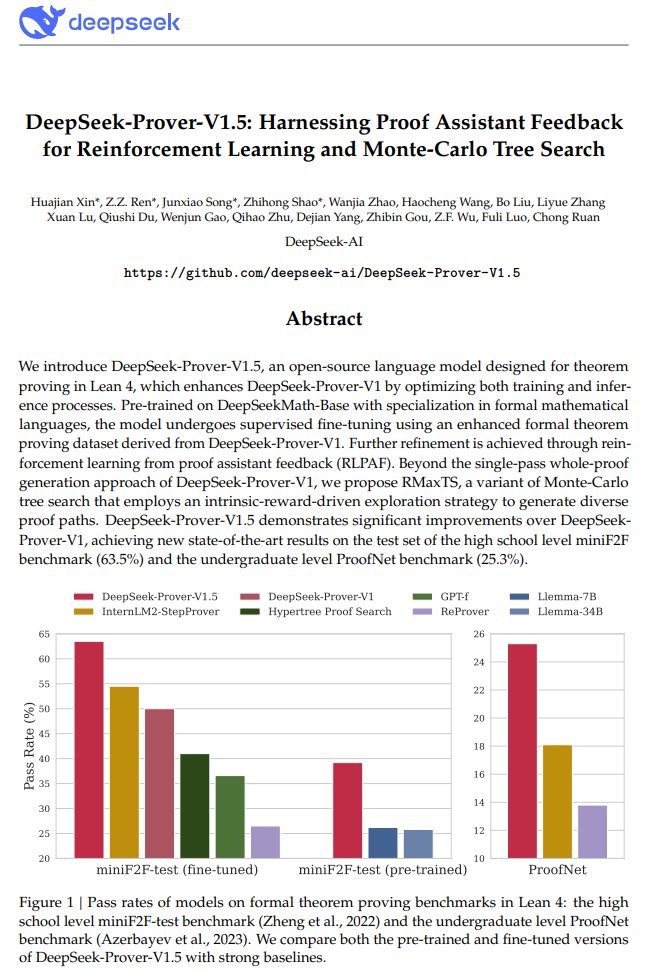
After a recent price reduction by OpenAI, GPT-4o tokens now cost $4 per million tokens (using a blended rate that assumes 80% input and 20% output tokens). GPT-4 cost $36 per million tokens at its initial release in March 2023. This price reduction over 17 months corresponds to about a 79% drop in price per year. (4/36 = (1 - p)^{17/12})
As you can see, token prices are falling rapidly! One force that’s driving prices down is the release of open weights models such as Llama 3.1. If API providers, including startups Anyscale, Fireworks, Together AI, and some large cloud companies, do not have to worry about recouping the cost of developing a model, they can compete directly on price and a few other factors such as speed.
Further, hardware innovations by companies such as Groq (a leading player in fast token generation), Samba Nova (which serves Llama 3.1 405B tokens at an impressive 114 tokens per second), and wafer-scale computation startup Cerebras (which just announced a new offering this week), as well as the semiconductor giants NVIDIA, AMD, Intel, and Qualcomm, will drive further price cuts.
When building applications, I find it useful to design to where the technology is going rather than only where it has been. Based on the technology roadmaps of multiple software and hardware companies — which include improved semiconductors, smaller models, and algorithmic innovation in inference architectures — I’m confident that token prices will continue to fall rapidly.
This means that even if you build an agentic workload that isn’t entirely economical, falling token prices might make it economical at some point. As I wrote previously, being able to process many tokens is particularly important for agentic workloads, which must call a model many times before generating a result. Further, even agentic workloads are already quite affordable for many applications. Let's say you build an application to assist a human worker, and it uses 100 tokens per second continuously: At $4/million tokens, you'd be spending only $1.44/hour – which is significantly lower than the minimum wage in the U.S. and many other countries.
So how can AI companies prepare?
- First, I continue to hear from teams that are surprised to find out how cheap LLM usage is when they actually work through cost calculations. For many applications, it isn’t worth too much effort to optimize the cost. So first and foremost, I advise teams to focus on building a useful application rather than on optimizing LLM costs.
- Second, even if an application is marginally too expensive to run today, it may be worth deploying in anticipation of lower prices.
- Finally, as new models get released, it might be worthwhile to periodically examine an application to decide whether to switch to a new model either from the same provider (such as switching from GPT-4 to the latest GPT-4o-2024-08-06) or a different provider, to take advantage of falling prices and/or increased capabilities.
Because multiple providers now host Llama 3.1 and other open-weight models, if you use one of these models, it might be possible to switch between providers without too much testing (though implementation details — specifically quantization, does mean that different offerings of the model do differ in performance). When switching between models, unfortunately, a major barrier is still the difficulty of implementing evals, so carrying out regression testing to make sure your application will still perform after you swap in a new model can be challenging. However, as the science of carrying out evals improves, I’m optimistic that this will become easier.
[Original text (with links): AI Restores ALS Patient's Voice, AI Lobby Grows, and more ]
2/11
Why are we considering 4 and 4o to be the same tokens though, if they arent..
3/11
Let's hope SB-1047 proponents realize that open-source is already vital for customers and to avoid price gouging.
4/11
OpenAI gets a lot of for announcing but not releasing their innovation - which is most likely not their fault BTW. But, they have given us GPT-4O-mini with amazing price-performance. I'm not sure most people realize how awesome it is!
for announcing but not releasing their innovation - which is most likely not their fault BTW. But, they have given us GPT-4O-mini with amazing price-performance. I'm not sure most people realize how awesome it is!
5/11
As AI models become more affordable, it's a great time to explore new possibilities and build innovative applications without worrying too much about costs.
6/11
Prices will continue to go down. LLMs will rapidly become commodities. The value will be created at the application level.
Why Large Language Models Are A Commodity Now And What It Means For The AI Space
7/11
The key lesson from your post is to work on the application of LLM on a use case and, for the time being, accept the high cost
8/11
Mark Zuckerberg is the best.
9/11
the most important factor is the size of the model really declined. GPT 4 is 1800B MoE, while GPT 4o maybe 100B I guess. The second is the inference optimization, various means like quantization, batching and cache.The hardware price doesn't decline that fast.
10/11
With easier access to models, there might be a push for more transparency in how decisions are made, affecting both model selection and application design
11/11
Another confirmation that using @LangChainAI , although a pretty krufty library, is a good move
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
After a recent price reduction by OpenAI, GPT-4o tokens now cost $4 per million tokens (using a blended rate that assumes 80% input and 20% output tokens). GPT-4 cost $36 per million tokens at its initial release in March 2023. This price reduction over 17 months corresponds to about a 79% drop in price per year. (4/36 = (1 - p)^{17/12})
As you can see, token prices are falling rapidly! One force that’s driving prices down is the release of open weights models such as Llama 3.1. If API providers, including startups Anyscale, Fireworks, Together AI, and some large cloud companies, do not have to worry about recouping the cost of developing a model, they can compete directly on price and a few other factors such as speed.
Further, hardware innovations by companies such as Groq (a leading player in fast token generation), Samba Nova (which serves Llama 3.1 405B tokens at an impressive 114 tokens per second), and wafer-scale computation startup Cerebras (which just announced a new offering this week), as well as the semiconductor giants NVIDIA, AMD, Intel, and Qualcomm, will drive further price cuts.
When building applications, I find it useful to design to where the technology is going rather than only where it has been. Based on the technology roadmaps of multiple software and hardware companies — which include improved semiconductors, smaller models, and algorithmic innovation in inference architectures — I’m confident that token prices will continue to fall rapidly.
This means that even if you build an agentic workload that isn’t entirely economical, falling token prices might make it economical at some point. As I wrote previously, being able to process many tokens is particularly important for agentic workloads, which must call a model many times before generating a result. Further, even agentic workloads are already quite affordable for many applications. Let's say you build an application to assist a human worker, and it uses 100 tokens per second continuously: At $4/million tokens, you'd be spending only $1.44/hour – which is significantly lower than the minimum wage in the U.S. and many other countries.
So how can AI companies prepare?
- First, I continue to hear from teams that are surprised to find out how cheap LLM usage is when they actually work through cost calculations. For many applications, it isn’t worth too much effort to optimize the cost. So first and foremost, I advise teams to focus on building a useful application rather than on optimizing LLM costs.
- Second, even if an application is marginally too expensive to run today, it may be worth deploying in anticipation of lower prices.
- Finally, as new models get released, it might be worthwhile to periodically examine an application to decide whether to switch to a new model either from the same provider (such as switching from GPT-4 to the latest GPT-4o-2024-08-06) or a different provider, to take advantage of falling prices and/or increased capabilities.
Because multiple providers now host Llama 3.1 and other open-weight models, if you use one of these models, it might be possible to switch between providers without too much testing (though implementation details — specifically quantization, does mean that different offerings of the model do differ in performance). When switching between models, unfortunately, a major barrier is still the difficulty of implementing evals, so carrying out regression testing to make sure your application will still perform after you swap in a new model can be challenging. However, as the science of carrying out evals improves, I’m optimistic that this will become easier.
[Original text (with links): AI Restores ALS Patient's Voice, AI Lobby Grows, and more ]
2/11
Why are we considering 4 and 4o to be the same tokens though, if they arent..
3/11
Let's hope SB-1047 proponents realize that open-source is already vital for customers and to avoid price gouging.
4/11
OpenAI gets a lot of
for announcing but not releasing their innovation - which is most likely not their fault BTW. But, they have given us GPT-4O-mini with amazing price-performance. I'm not sure most people realize how awesome it is!5/11
As AI models become more affordable, it's a great time to explore new possibilities and build innovative applications without worrying too much about costs.
6/11
Prices will continue to go down. LLMs will rapidly become commodities. The value will be created at the application level.
Why Large Language Models Are A Commodity Now And What It Means For The AI Space
7/11
The key lesson from your post is to work on the application of LLM on a use case and, for the time being, accept the high cost
8/11
Mark Zuckerberg is the best.
9/11
the most important factor is the size of the model really declined. GPT 4 is 1800B MoE, while GPT 4o maybe 100B I guess. The second is the inference optimization, various means like quantization, batching and cache.The hardware price doesn't decline that fast.
10/11
With easier access to models, there might be a push for more transparency in how decisions are made, affecting both model selection and application design
11/11
Another confirmation that using @LangChainAI , although a pretty krufty library, is a good move
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196