1/4
Improving 2D Feature Representations by 3D-Aware Fine-Tuning
proj: Improving 2D Feature Representations by 3D-Aware Fine-Tuning
abs: [2407.20229] Improving 2D Feature Representations by 3D-Aware Fine-Tuning
2/4
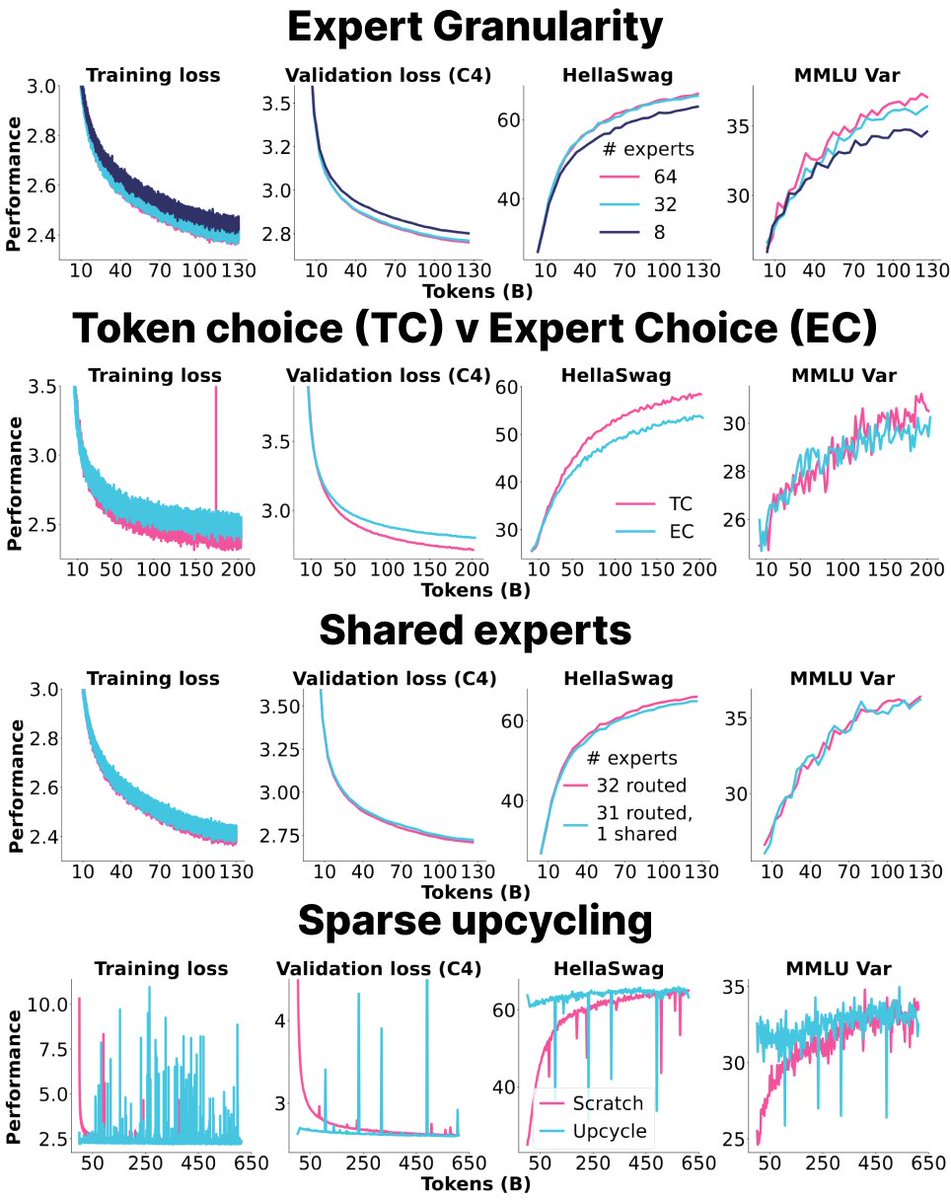
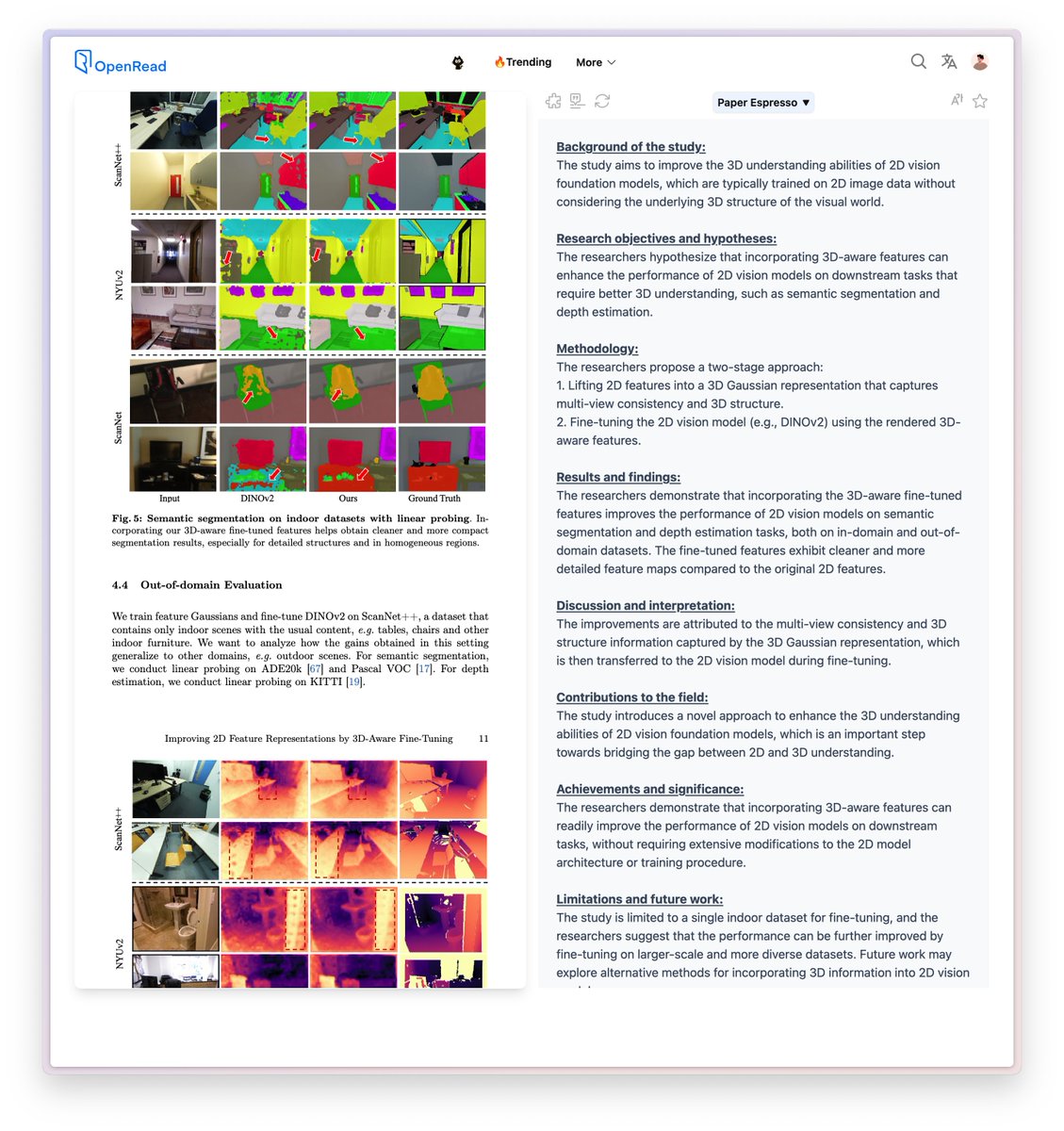
The study aims to improve the 3D understanding abilities of 2D vision foundation models, which are typically trained on 2D image data without considering the underlying 3D structure of the visual world.
The researchers demonstrate that incorporating the 3D-aware fine-tuned features improves the performance of 2D vision models on semantic segmentation and depth estimation tasks, both on in-domain and out-of-domain datasets. The fine-tuned features exhibit cleaner and more detailed feature maps compared to the original 2D features.
full paper: Improving 2D Feature Representations by 3D-Aware Fine-Tuning
3/4
Thanks @arankomatsuzaki for sharing!
4/4
Fascinating approach to improving 2D feature representations! I'm curious to see how this 3D-aware fine-tuning method will impact downstream tasks like semantic segmentation.
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
Improving 2D Feature Representations by 3D-Aware Fine-Tuning
proj: Improving 2D Feature Representations by 3D-Aware Fine-Tuning
abs: [2407.20229] Improving 2D Feature Representations by 3D-Aware Fine-Tuning
2/4
The study aims to improve the 3D understanding abilities of 2D vision foundation models, which are typically trained on 2D image data without considering the underlying 3D structure of the visual world.
The researchers demonstrate that incorporating the 3D-aware fine-tuned features improves the performance of 2D vision models on semantic segmentation and depth estimation tasks, both on in-domain and out-of-domain datasets. The fine-tuned features exhibit cleaner and more detailed feature maps compared to the original 2D features.
full paper: Improving 2D Feature Representations by 3D-Aware Fine-Tuning
3/4
Thanks @arankomatsuzaki for sharing!
4/4
Fascinating approach to improving 2D feature representations! I'm curious to see how this 3D-aware fine-tuning method will impact downstream tasks like semantic segmentation.
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196




 to read this paper
to read this paper