
You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
The A.I Megathread (LLM , GPT , Development)
More options
Who Replied?1/5
CEO of OpenAI Japan says GPT-Next will be released this year, and its effective computational load is 100x greater than GPT-4
More on Orion and Strawberry:
"GPT-4 NEXT, which will be released this year, is expected to be trained using a miniature version of Strawberry with roughly the same computational resources as GPT-4, with an effective computational load 100 times greater.
"The AI model called 'GPT Next' that will be released in the future will evolve nearly 100 times based on past performance. Unlike traditional software, AI technology grows exponentially."
…The slide clearly states 2024 "GPT Next". This 100 times increase probably does not refer to the scaling of computing resources, but rather to the effective computational volume + 2 OOMs, including improvements to the architecture and learning efficiency.
Orion, which has been in the spotlight recently, was trained for several months on the equivalent of 10k H100 compared to GPT-4, adding 10 times the computational resource scale, making it +3 OOMs, and is expected to be released sometime next year."
(Note: this translation is from Google - if you speak Japanese and see anything off, please share!)
2/5
Reminder: scaling laws have held through 15 orders of magnitude
Exponential go brr
3/5
Note: this is a translation of Bioshok's tweet. It contains a mix of new info (the slide saying GPT Next is coming in 2024 and will be +100x effective compute), recent OpenAI news, and some of his speculations to tie it together.
4/5
OpenAI's Head of Developer Experience used a similar graph in a recent presentation
5/5
Yep insiders continue to be very clear about the exponential
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
CEO of OpenAI Japan says GPT-Next will be released this year, and its effective computational load is 100x greater than GPT-4
More on Orion and Strawberry:
"GPT-4 NEXT, which will be released this year, is expected to be trained using a miniature version of Strawberry with roughly the same computational resources as GPT-4, with an effective computational load 100 times greater.
"The AI model called 'GPT Next' that will be released in the future will evolve nearly 100 times based on past performance. Unlike traditional software, AI technology grows exponentially."
…The slide clearly states 2024 "GPT Next". This 100 times increase probably does not refer to the scaling of computing resources, but rather to the effective computational volume + 2 OOMs, including improvements to the architecture and learning efficiency.
Orion, which has been in the spotlight recently, was trained for several months on the equivalent of 10k H100 compared to GPT-4, adding 10 times the computational resource scale, making it +3 OOMs, and is expected to be released sometime next year."
(Note: this translation is from Google - if you speak Japanese and see anything off, please share!)
2/5
Reminder: scaling laws have held through 15 orders of magnitude
Exponential go brr
3/5
Note: this is a translation of Bioshok's tweet. It contains a mix of new info (the slide saying GPT Next is coming in 2024 and will be +100x effective compute), recent OpenAI news, and some of his speculations to tie it together.
4/5
OpenAI's Head of Developer Experience used a similar graph in a recent presentation
5/5
Yep insiders continue to be very clear about the exponential
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196





AI worse than humans in every way at summarising information, government trial finds
A test of AI for Australia's corporate regulator found that the technology might actually make more work for people, not less.
 www.crikey.com.au
www.crikey.com.au
AI worse than humans in every way at summarising information, government trial finds
A test of AI for Australia's corporate regulator found that the technology might actually make more work for people, not less.
Cam Wilson
Sep 03, 2024
9
UPDATED: 9.18AM, Sep 04

Artificial intelligence is worse than humans in every way at summarising documents and might actually create additional work for people, a government trial of the technology has found.
Amazon conducted the test earlier this year for Australia’s corporate regulator the Securities and Investments Commission (ASIC) using submissions made to an inquiry. The outcome of the trial was revealed in an answer to a questions on notice at the Senate select committee on adopting artificial intelligence.
The test involved testing generative AI models before selecting one to ingest five submissions from a parliamentary inquiry into audit and consultancy firms. The most promising model, Meta’s open source model Llama2-70B, was prompted to summarise the submissions with a focus on ASIC mentions, recommendations, references to more regulation, and to include the page references and context.
")
A Labor councillor is using artificial intelligence to write his campaign ads
Read More
Ten ASIC staff, of varying levels of seniority, were also given the same task with similar prompts. Then, a group of reviewers blindly assessed the summaries produced by both humans and AI for coherency, length, ASIC references, regulation references and for identifying recommendations. They were unaware that this exercise involved AI at all.
These reviewers overwhelmingly found that the human summaries beat out their AI competitors on every criteria and on every submission, scoring an 81% on an internal rubric compared with the machine’s 47%.
Human summaries ran up the score by significantly outperforming on identifying references to ASIC documents in the long document, a type of task that the report notes is a “notoriously hard task” for this type of AI. But humans still beat the technology across the board.
Reviewers told the report’s authors that AI summaries often missed emphasis, nuance and context; included incorrect information or missed relevant information; and sometimes focused on auxiliary points or introduced irrelevant information. Three of the five reviewers said they guessed that they were reviewing AI content.
The reviewers’ overall feedback was that they felt AI summaries may be counterproductive and create further work because of the need to fact-check and refer to original submissions which communicated the message better and more concisely.
The report mentions some limitations and context to this study: the model used has already been superseded by one with further capabilities which may improve its ability to summarise information, and that Amazon increased the model’s performance by refining its prompts and inputs, suggesting that there are further improvements that are possible. It includes optimism that this task may one day be competently undertaken by machines.
But until then, the trial showed that a human’s ability to parse and critically analyse information is unparalleled by AI, the report said.
“This finding also supports the view that GenAI should be positioned as a tool to augment and not replace human tasks,” the report concluded.
Greens Senator David Shoebridge, whose question to ASIC prompted the publishing of the report, said that it was “hardly surprising” that humans were better than AI at this task. He also said it raised questions about how the public might feel about using AI to read their inquiry submissions.
“This of course doesn’t mean there is never a role for AI in assessing submissions, but if it has a role it must be transparent and supportive of human assessments and not stand-alone,” he said.
“It’s good to see government departments undertaking considered exercises like this for AI use, but it would be better if it was then proactively and routinely disclosed rather than needing to be requested in Senate committee hearings.”
AI worse than humans in every way at summarising information, government trial finds
A test of AI for Australia's corporate regulator found that the technology might actually make more work for people, not less.
AI worse than humans in every way at summarising information, government trial finds
A test of AI for Australia's corporate regulator found that the technology might actually make more work for people, not less.
Cam Wilson
Sep 03, 2024
9
UPDATED: 9.18AM, Sep 04
(Image: Adobe)
Artificial intelligence is worse than humans in every way at summarising documents and might actually create additional work for people, a government trial of the technology has found.
Amazon conducted the test earlier this year for Australia’s corporate regulator the Securities and Investments Commission (ASIC) using submissions made to an inquiry. The outcome of the trial was revealed in an answer to a questions on notice at the Senate select committee on adopting artificial intelligence.
The test involved testing generative AI models before selecting one to ingest five submissions from a parliamentary inquiry into audit and consultancy firms. The most promising model, Meta’s open source model Llama2-70B, was prompted to summarise the submissions with a focus on ASIC mentions, recommendations, references to more regulation, and to include the page references and context.
A Labor councillor is using artificial intelligence to write his campaign ads
Read More
Ten ASIC staff, of varying levels of seniority, were also given the same task with similar prompts. Then, a group of reviewers blindly assessed the summaries produced by both humans and AI for coherency, length, ASIC references, regulation references and for identifying recommendations. They were unaware that this exercise involved AI at all.
These reviewers overwhelmingly found that the human summaries beat out their AI competitors on every criteria and on every submission, scoring an 81% on an internal rubric compared with the machine’s 47%.
Human summaries ran up the score by significantly outperforming on identifying references to ASIC documents in the long document, a type of task that the report notes is a “notoriously hard task” for this type of AI. But humans still beat the technology across the board.
Reviewers told the report’s authors that AI summaries often missed emphasis, nuance and context; included incorrect information or missed relevant information; and sometimes focused on auxiliary points or introduced irrelevant information. Three of the five reviewers said they guessed that they were reviewing AI content.
The reviewers’ overall feedback was that they felt AI summaries may be counterproductive and create further work because of the need to fact-check and refer to original submissions which communicated the message better and more concisely.
The report mentions some limitations and context to this study: the model used has already been superseded by one with further capabilities which may improve its ability to summarise information, and that Amazon increased the model’s performance by refining its prompts and inputs, suggesting that there are further improvements that are possible. It includes optimism that this task may one day be competently undertaken by machines.
But until then, the trial showed that a human’s ability to parse and critically analyse information is unparalleled by AI, the report said.
“This finding also supports the view that GenAI should be positioned as a tool to augment and not replace human tasks,” the report concluded.
Greens Senator David Shoebridge, whose question to ASIC prompted the publishing of the report, said that it was “hardly surprising” that humans were better than AI at this task. He also said it raised questions about how the public might feel about using AI to read their inquiry submissions.
“This of course doesn’t mean there is never a role for AI in assessing submissions, but if it has a role it must be transparent and supportive of human assessments and not stand-alone,” he said.
“It’s good to see government departments undertaking considered exercises like this for AI use, but it would be better if it was then proactively and routinely disclosed rather than needing to be requested in Senate committee hearings.”
had a couple large drops around tech stocks today, particularly large successful semi conductors......
I wonder if the bottom of this ai stuff will fall out and we are back to being not much farther head than we were December 2022
had a couple large drops around tech stocks today, particularly large successful semi conductors......
I wonder if the bottom of this ai stuff will fall out and we are back to being not much farther head than we were December 2022
how is that an indicator of the bottom falling out when usage across has been skyrocketing?
they're just old models from 2023, llama3.1 exists now along with mistral large etc which is way better.
Last edited:
how is that an indicator of the bottom falling out when usage across has been skyrocketing?
they just old models from 2023, llama3.1 exists now along with mistral large etc which is way better.
usage != profitability
at least to shareholders
1/1
New blog post out by the Bespoke AI team!
Hallucination has become a blanket term. This blog post helps clarify and reframe LLM hallucinations in the context of more traditional NLP tasks. We’ve both been thinking this problem for a bit. We’ve been using Provenance-LLM as our primary hallucination detection validator, however we suspect that Minicheck performs better.
@bespokelabsai's grounded factuality detector, Bespoke-Minicheck-7B, tops the LLM AggreFact leaderboard. This lightweight model outperforms larger foundation models, including GPT-4 and Mistral-Large 2 on grounded factuality detection.
Hallucinations and RAG — Bespoke Labs
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
New blog post out by the Bespoke AI team!
Hallucination has become a blanket term. This blog post helps clarify and reframe LLM hallucinations in the context of more traditional NLP tasks. We’ve both been thinking this problem for a bit. We’ve been using Provenance-LLM as our primary hallucination detection validator, however we suspect that Minicheck performs better.
@bespokelabsai's grounded factuality detector, Bespoke-Minicheck-7B, tops the LLM AggreFact leaderboard. This lightweight model outperforms larger foundation models, including GPT-4 and Mistral-Large 2 on grounded factuality detection.
Hallucinations and RAG — Bespoke Labs
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196

1/11
Introducing a new AI-driven spreadsheet from a new AI company: @tryparadigm.
Here is cofounder @annarmonaco who shows it to us here.
Wow.
Some things, every row and column is now "intelligent." You can do same thing you can now do with photoshop. You probably never knew you needed spreadsheet outpainting.
But now you do.
Its official launch video is here:
2/11
Woah!
3/11
Yeah.
4/11
Love that you support young founders like this!!! Keep the amazing showcasing going!
5/11
The two founders are really amazing people, and have setup a very unique culture.
Thanks! I am trying to continue seeing new things at a pretty fast rate and supporting the people who build them.
6/11
Interesting. It pulls data from the internet or data that you already have in your system?
7/11
From internet.
8/11
wow what a game changer.
excellent interview robert!!
amazing demo of a stellar product.
I've never said this before—
but I am STOKED to create some spreadsheets now.
9/11
Totally!
10/11
Will check it out!
Thanks Robert
11/11
It's quite amazing.
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
Introducing a new AI-driven spreadsheet from a new AI company: @tryparadigm.
Here is cofounder @annarmonaco who shows it to us here.
Wow.
Some things, every row and column is now "intelligent." You can do same thing you can now do with photoshop. You probably never knew you needed spreadsheet outpainting.
But now you do.
Its official launch video is here:
2/11
Woah!
3/11
Yeah.
4/11
Love that you support young founders like this!!! Keep the amazing showcasing going!
5/11
The two founders are really amazing people, and have setup a very unique culture.
Thanks! I am trying to continue seeing new things at a pretty fast rate and supporting the people who build them.
6/11
Interesting. It pulls data from the internet or data that you already have in your system?
7/11
From internet.
8/11
wow what a game changer.
excellent interview robert!!
amazing demo of a stellar product.
I've never said this before—
but I am STOKED to create some spreadsheets now.
9/11
Totally!
10/11
Will check it out!
Thanks Robert
11/11
It's quite amazing.
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
@3:40 is when the demonstration starts
1/1
Do you want to extend your LLM's context window to 128k, using just a single GPU and thousands of short samples, all while achieving performance close to GPT-4? Then check out our LongRecipe!
Explore our code, configuration, and model checkpoints:
— Paper: [2409.00509] LongRecipe: Recipe for Efficient Long Context Generalization in Large Languge Models
— Code: GitHub - zhiyuanhubj/LongRecipe
— LongRecipe-Llama3-8B-128k: zhiyuanhucs/LongRecipe-Llama3-8B-128k · Hugging Face
— LongRecipe-Qwen2-7B-128k: zhiyuanhucs/LongRecipe-Qwen2-7B-128k · Hugging Face
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
Do you want to extend your LLM's context window to 128k, using just a single GPU and thousands of short samples, all while achieving performance close to GPT-4? Then check out our LongRecipe!
Explore our code, configuration, and model checkpoints:
— Paper: [2409.00509] LongRecipe: Recipe for Efficient Long Context Generalization in Large Languge Models
— Code: GitHub - zhiyuanhubj/LongRecipe
— LongRecipe-Llama3-8B-128k: zhiyuanhucs/LongRecipe-Llama3-8B-128k · Hugging Face
— LongRecipe-Qwen2-7B-128k: zhiyuanhucs/LongRecipe-Qwen2-7B-128k · Hugging Face
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196



1/3
My view on this has not changed in the past eight years: I have given many talks and written position paper in 2019 (link below). Progress is faster than my past expectation. My target date used to be ~2029 back then. Now it is 2026 for a superhuman AI mathematician. While a stretch, even 2025 is possible.
2/3
That grunt work will be formalization: Too tedious for humans to do at a large scale, but enabling AI to progress (semi-)openendedly, while provinding grounding for its natural language math abilities.
3/3
I expect SWE and sciences to be accelerated significantly by that although at a slower pace than math.
Math has much less friction: any interaction with real world adds complication with data collection, evaluation, deployment, etc.
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
My view on this has not changed in the past eight years: I have given many talks and written position paper in 2019 (link below). Progress is faster than my past expectation. My target date used to be ~2029 back then. Now it is 2026 for a superhuman AI mathematician. While a stretch, even 2025 is possible.
2/3
That grunt work will be formalization: Too tedious for humans to do at a large scale, but enabling AI to progress (semi-)openendedly, while provinding grounding for its natural language math abilities.
3/3
I expect SWE and sciences to be accelerated significantly by that although at a slower pace than math.
Math has much less friction: any interaction with real world adds complication with data collection, evaluation, deployment, etc.
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
1/6
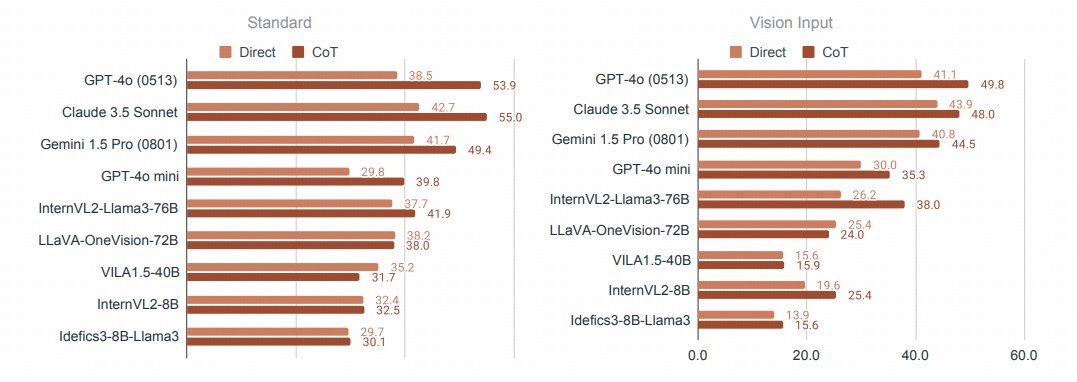
MMMU-Pro: A More Robust Multi-discipline Multimodal Understanding Benchmark
- Tests a cognitive skill of seamlessly integrating visual and textual information
- Performance is substantially lower than on MMMU, ranging from 16.8% to 26.9% across models
proj: MMMU
abs: [2409.02813] MMMU-Pro: A More Robust Multi-discipline Multimodal Understanding Benchmark
2/6
Nice! Interestingly, same rank between models?
3/6
Haha that's so true lol
Still, I hope it'll become more useful as the model performance gets much better.
4/6
This paper introduces a new benchmark called MMMU-Pro, which is a more robust version of the Massive Multi-discipline Multimodal Understanding and Reasoning (MMMU) benchmark. The MMMU benchmark was designed to evaluate the capabilities of multimodal AI models on college-level tasks that require subject-specific knowledge and reasoning.
The results showed a significant drop in performance across all tested models when compared to the original MMMU benchmark, with decreases ranging from 16.8% to 26.9%. This suggests that MMMU-Pro successfully mitigates the shortcuts and guessing strategies that models could exploit in the original benchmark.
full paper: MMMU-Pro: A More Robust Multi-discipline Multimodal Understanding Benchmark
5/6
MMMU-Pro: A More Robust Multi-discipline Multimodal Understanding Benchmark
6/6
Thanks for featuring our work! More details are in this thread:
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
MMMU-Pro: A More Robust Multi-discipline Multimodal Understanding Benchmark
- Tests a cognitive skill of seamlessly integrating visual and textual information
- Performance is substantially lower than on MMMU, ranging from 16.8% to 26.9% across models
proj: MMMU
abs: [2409.02813] MMMU-Pro: A More Robust Multi-discipline Multimodal Understanding Benchmark
2/6
Nice! Interestingly, same rank between models?
3/6
Haha that's so true lol
Still, I hope it'll become more useful as the model performance gets much better.
4/6
This paper introduces a new benchmark called MMMU-Pro, which is a more robust version of the Massive Multi-discipline Multimodal Understanding and Reasoning (MMMU) benchmark. The MMMU benchmark was designed to evaluate the capabilities of multimodal AI models on college-level tasks that require subject-specific knowledge and reasoning.
The results showed a significant drop in performance across all tested models when compared to the original MMMU benchmark, with decreases ranging from 16.8% to 26.9%. This suggests that MMMU-Pro successfully mitigates the shortcuts and guessing strategies that models could exploit in the original benchmark.
full paper: MMMU-Pro: A More Robust Multi-discipline Multimodal Understanding Benchmark
5/6
MMMU-Pro: A More Robust Multi-discipline Multimodal Understanding Benchmark
6/6
Thanks for featuring our work! More details are in this thread:
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196



1/7
 Introducing MMMU-Pro: A more robust version of MMMU
Introducing MMMU-Pro: A more robust version of MMMU
https://arxiv.org/pdf/2409.02813v1
After launching MMMU, we received valuable feedback from the community:
 Some questions were answerable without even seeing the images.
Some questions were answerable without even seeing the images.
 Models didn’t always "know" the answer but found shortcuts from the options provided.
Models didn’t always "know" the answer but found shortcuts from the options provided.
 Performance was heavily tied to LLMs, with minimal impact from the vision module.
Performance was heavily tied to LLMs, with minimal impact from the vision module.
To tackle these issues, we implemented the following improvements:
 1. Filtering Text-Only Answerable Questions
1. Filtering Text-Only Answerable Questions
 2. Augmenting Candidate Options up to 10 by Human Experts.
2. Augmenting Candidate Options up to 10 by Human Experts.
 3. Vision-Only Input Setting: where questions are embedded directly in images, requiring the model to rely purely on visual input.
3. Vision-Only Input Setting: where questions are embedded directly in images, requiring the model to rely purely on visual input.
 Why We Added Vision-Only Input Setting?
Why We Added Vision-Only Input Setting?
1. From a foundational perspective, this setting forces AI to genuinely "see" and "read" at the same time—challenging a core human cognitive skill: the seamless integration of visual and textual information.
2. From an application standpoint, this approach mirrors how users naturally interact with AI systems—by sharing screenshots or photos, without meticulously separating text from images.
 Key Results:
Key Results:
Performance on MMMU-Pro is notably lower compared to MMMU, ranging from 16.8% to 26.9% across various models. The ranking of models is generally similar to the original but we also observe less robust ones— for example, GPT-4o mini proved less robust than GPT-4o and other proprietary models, showing significant drops in performance on the augmented set.
 More in-depth analysis can be found in the threads below!
More in-depth analysis can be found in the threads below! 
2/7
 Augmented Candidate Options Impact: Expanding the number of candidate options from 4 to 10 led to a notable drop in model performance, with GPT-4o (0513) experiencing a 10.7% decrease in accuracy.
Augmented Candidate Options Impact: Expanding the number of candidate options from 4 to 10 led to a notable drop in model performance, with GPT-4o (0513) experiencing a 10.7% decrease in accuracy.
 Impact of Vision-Only Setting: The vision-only input setting further challenged model performance, especially for open-source models, which proved less robust in this scenario. GPT-4o (0513) saw a 4.3% drop, while LLaVA-OneVision-72B and VILA-1.5-40B experienced more dramatic declines of 14.0% and 21.8%, respectively.
Impact of Vision-Only Setting: The vision-only input setting further challenged model performance, especially for open-source models, which proved less robust in this scenario. GPT-4o (0513) saw a 4.3% drop, while LLaVA-OneVision-72B and VILA-1.5-40B experienced more dramatic declines of 14.0% and 21.8%, respectively.
3/7
A natural question to ask: is OCR the bottleneck of the vision-input setting?
Answer: No, for both capable open-source and closed-source models.
We actually found the top-performing models are very good at OCR tasks right now. They could accurately extract the question text from the image. The core reason is the complexity of information processing and handling. We observed that the model is more likely to hallucinate and have wrong reasoning chains when simultaneous processing of visual and textual information.
4/7
For example, in the following case, in the vision-only input scenario, the model accurately extracts text from the photo. However, its response tends to be more basic and lacks in-depth analysis. The integration of both visual and textual information appears to increase the cognitive load on the vision module, which may result in a higher likelihood of errors.
5/7
Finally, as we may know CoT mostly helps the reason scenarios but the extent of improvement varied significantly among models. In some cases, we observed a significant performance drop for some models, such as VILA1.5-40B. This decline might be attributed to challenges in instruction-following abilities. The models barely generated useful reasoning chains.
6/7
We would like to thank the community for the great feedback since MMMU release! We hope the robust version MMMU-Pro will help the community more rigorously evaluate the foundation models. This release is collaborated with @zhengtianyu4 @YuanshengNi @YuboWang726 @DrogoKhal4 @TongPetersb @jamesja69137043 @MingYin_0312 @BotaoYu24 @GeZhang86038849 @hhsun1 @ysu_nlp @WenhuChen @gneubig
7/7
The dataset is available at: MMMU/MMMU_Pro · Datasets at Hugging Face
The inference code is available at:
MMMU/mmmu-pro at main · MMMU-Benchmark/MMMU
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
Introducing MMMU-Pro: A more robust version of MMMUhttps://arxiv.org/pdf/2409.02813v1
After launching MMMU, we received valuable feedback from the community:
Some questions were answerable without even seeing the images. Models didn’t always "know" the answer but found shortcuts from the options provided. Performance was heavily tied to LLMs, with minimal impact from the vision module.To tackle these issues, we implemented the following improvements:
1. Filtering Text-Only Answerable Questions 2. Augmenting Candidate Options up to 10 by Human Experts. 3. Vision-Only Input Setting: where questions are embedded directly in images, requiring the model to rely purely on visual input. Why We Added Vision-Only Input Setting?1. From a foundational perspective, this setting forces AI to genuinely "see" and "read" at the same time—challenging a core human cognitive skill: the seamless integration of visual and textual information.
2. From an application standpoint, this approach mirrors how users naturally interact with AI systems—by sharing screenshots or photos, without meticulously separating text from images.
Key Results:Performance on MMMU-Pro is notably lower compared to MMMU, ranging from 16.8% to 26.9% across various models. The ranking of models is generally similar to the original but we also observe less robust ones— for example, GPT-4o mini proved less robust than GPT-4o and other proprietary models, showing significant drops in performance on the augmented set.
More in-depth analysis can be found in the threads below! 2/7
Augmented Candidate Options Impact: Expanding the number of candidate options from 4 to 10 led to a notable drop in model performance, with GPT-4o (0513) experiencing a 10.7% decrease in accuracy. Impact of Vision-Only Setting: The vision-only input setting further challenged model performance, especially for open-source models, which proved less robust in this scenario. GPT-4o (0513) saw a 4.3% drop, while LLaVA-OneVision-72B and VILA-1.5-40B experienced more dramatic declines of 14.0% and 21.8%, respectively.3/7
A natural question to ask: is OCR the bottleneck of the vision-input setting?
Answer: No, for both capable open-source and closed-source models.
We actually found the top-performing models are very good at OCR tasks right now. They could accurately extract the question text from the image. The core reason is the complexity of information processing and handling. We observed that the model is more likely to hallucinate and have wrong reasoning chains when simultaneous processing of visual and textual information.
4/7
For example, in the following case, in the vision-only input scenario, the model accurately extracts text from the photo. However, its response tends to be more basic and lacks in-depth analysis. The integration of both visual and textual information appears to increase the cognitive load on the vision module, which may result in a higher likelihood of errors.
5/7
Finally, as we may know CoT mostly helps the reason scenarios but the extent of improvement varied significantly among models. In some cases, we observed a significant performance drop for some models, such as VILA1.5-40B. This decline might be attributed to challenges in instruction-following abilities. The models barely generated useful reasoning chains.
6/7
We would like to thank the community for the great feedback since MMMU release! We hope the robust version MMMU-Pro will help the community more rigorously evaluate the foundation models. This release is collaborated with @zhengtianyu4 @YuanshengNi @YuboWang726 @DrogoKhal4 @TongPetersb @jamesja69137043 @MingYin_0312 @BotaoYu24 @GeZhang86038849 @hhsun1 @ysu_nlp @WenhuChen @gneubig
7/7
The dataset is available at: MMMU/MMMU_Pro · Datasets at Hugging Face
The inference code is available at:
MMMU/mmmu-pro at main · MMMU-Benchmark/MMMU
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196



1/1
STARTING IN 10 MIN!!!
Papers we will cover:
Building and better understanding vision-language models: insights and future directions - presented by @LeoTronchon
OLMoE: Open Mixture-of-Experts Language Models - presented by @Muennighoff
Diffusion Models Are Real-Time Game Engines
Physics of Language Models: Part 2.2, How to Learn From Mistakes on Grade-School Math Problems
Sapiens: Foundation for Human Vision Models
CrossFormer: Scaling Cross-Embodied Learning for Manipulation, Navigation, Locomotion, and Aviation
Technical Report of HelixFold3 for Biomolecular Structure Prediction
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
STARTING IN 10 MIN!!!
Papers we will cover:
Building and better understanding vision-language models: insights and future directions - presented by @LeoTronchon
OLMoE: Open Mixture-of-Experts Language Models - presented by @Muennighoff
Diffusion Models Are Real-Time Game Engines
Physics of Language Models: Part 2.2, How to Learn From Mistakes on Grade-School Math Problems
Sapiens: Foundation for Human Vision Models
CrossFormer: Scaling Cross-Embodied Learning for Manipulation, Navigation, Locomotion, and Aviation
Technical Report of HelixFold3 for Biomolecular Structure Prediction
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
1/1
*Ensemble everything everywhere: Multi-scale aggregation for adversarial robustness*
by @stanislavfort @balajiln
Training a model on noisy, low-resolution variants of an image (vaguely inspired by the eyes' saccades) make it more adversarially robust.
[2408.05446] Ensemble everything everywhere: Multi-scale aggregation for adversarial robustness
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
*Ensemble everything everywhere: Multi-scale aggregation for adversarial robustness*
by @stanislavfort @balajiln
Training a model on noisy, low-resolution variants of an image (vaguely inspired by the eyes' saccades) make it more adversarially robust.
[2408.05446] Ensemble everything everywhere: Multi-scale aggregation for adversarial robustness
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196

1/1
AI2 presents OLMoE: Open Mixture-of-Experts Language Models
- Opensources SotA LMs w/ MoE up to 7B active params.
- Releases model weights, training data, code, and logs.
repo: GitHub - allenai/OLMoE: OLMoE: Open Mixture-of-Experts Language Models
hf: allenai/OLMoE-1B-7B-0924 · Hugging Face
abs: [2409.02060] OLMoE: Open Mixture-of-Experts Language Models
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
AI2 presents OLMoE: Open Mixture-of-Experts Language Models
- Opensources SotA LMs w/ MoE up to 7B active params.
- Releases model weights, training data, code, and logs.
repo: GitHub - allenai/OLMoE: OLMoE: Open Mixture-of-Experts Language Models
hf: allenai/OLMoE-1B-7B-0924 · Hugging Face
abs: [2409.02060] OLMoE: Open Mixture-of-Experts Language Models
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
