Grok-2 gets a speed bump after developers rewrite code in three days
The two developers responsible are Lianmin Zheng and Saeed Maleki, according to Babuschkin's post, and they relied on open source SGLang.
 venturebeat.com
venturebeat.com
Grok-2 gets a speed bump after developers rewrite code in three days
Carl Franzen@carlfranzen
August 23, 2024 2:05 PM

Credit: VentureBeat made with Midjourney
Elon Musk’s xAI has made waves in the last week with the release of its Grok-2 large language model (LLM) chatbot — available through an $8 USD monthly subscription on the social network X.
Now, both versions of Grok-2 — Grok-2 and Grok-2 mini, the latter designed to be less powerful but faster — have both increased the speed at which they can analyze information and output responses after two developers at xAI rewrite the inference code stack completely in the last three days.
As xAI developer Igor Babuschkin posted this afternoon on the social network X under his handle @ibab:
“Grok 2 mini is now 2x faster than it was yesterday. In the last three days @lm_zheng and @MalekiSaeed rewrote our inference stack from scratch using SGLang. This has also allowed us to serve the big Grok 2 model, which requires multi-host inference, at a reasonable speed. Both models didn’t just get faster, but also slightly more accurate. Stay tuned for further speed improvements!”
Grok 2 mini is now 2x faster than it was yesterday. In the last three days @lm_zheng and @MalekiSaeed rewrote our inference stack from scratch using SGLang (GitHub - sgl-project/sglang: SGLang is a fast serving framework for large language models and vision language models.). This has also allowed us to serve the big Grok 2 model, which requires multi-host inference, at a… pic.twitter.com/G9iXTV8o0z
— ibab (@ibab) August 23, 2024
The two developers responsible are Lianmin Zheng and Saeed Maleki, according to Babuschkin’s post.
To rewrite the inference for Grok-2, they relied on SGLang, an open-source (Apache 2.0 licensed) highly efficient system for executing complex language model programs, achieving up to 6.4 times higher throughput than existing systems.
SGLang was developed by researchers from Stanford University, the University of California, Berkeley, Texas A&M University and Shanghai Jiao Tong University and integrates a frontend language with a backend runtime to simplify the programming of language model applications.
The system is versatile, supporting many models, including Llama, Mistral, and LLaVA, and is compatible with open-weight and API-based models like OpenAI’s GPT-4. SGLang’s ability to optimize execution through automatic cache reuse and parallelism within a single program makes it a powerful tool for developers working with large-scale language models.
Grok-2 and Grok-2-Mini Performance Highlights
Additionally, in the latest update to thethird-party Lmsys Chatbot Arena leaderboard that rates AI model performance, the main Grok-2 has secured the #2 spot with an impressive Arena Score of 1293, based on 6686 votes.

This effectively puts Grok-2 in the number two spot (fittingly) for the most powerful AI models in the world, tied with Google’s Gemini-1.5 Pro model, and just behind OpenAI’s latest version of ChatGPT-4o.
Grok-2-mini, which has also benefited from the recent enhancements, has climbed to the #5 position, boasting an Arena Score of 1268 from 7266 votes, just behind GPT-4o mini and Claude 3.5 Sonnet.
Both models are proprietary to xAI, reflecting the company’s commitment to advancing AI technology.
Grok-2 has distinguished itself, particularly in mathematical tasks, where it ranks #1. The model also holds strong positions across various other categories, including Hard Prompts, Coding, and Instruction-following, where it consistently ranks near the top.
This performance places Grok-2 ahead of other prominent models like OpenAI’s GPT-4o (May 2024), which now ranks #4.
Future Developments
According to a response by Babuschkin on X, the main advantage of using Grok-2-mini over the full Grok-2 model is its enhanced speed.
Yes, that’s the main reason for now. We will make it even faster than it is right now.
— ibab (@ibab) August 23, 2024
However, Babuschkin pledged that xAI would further improve the processing speed of Grok-2-mini, which could make it an even more attractive option for users seeking high performance with lower computational overhead.
The addition of Grok-2 and Grok-2-mini to the Chatbot Arena leaderboard and their subsequent performance have garnered significant attention within the AI community.
The models’ success is a testament to xAI’s ongoing innovation and its commitment to pushing the boundaries of what AI can achieve.
As xAI continues to refine its models, the AI landscape can expect further enhancements in both speed and accuracy, keeping Grok-2 and Grok-2-mini at the forefront of AI development.
 1 | 2
1 | 2




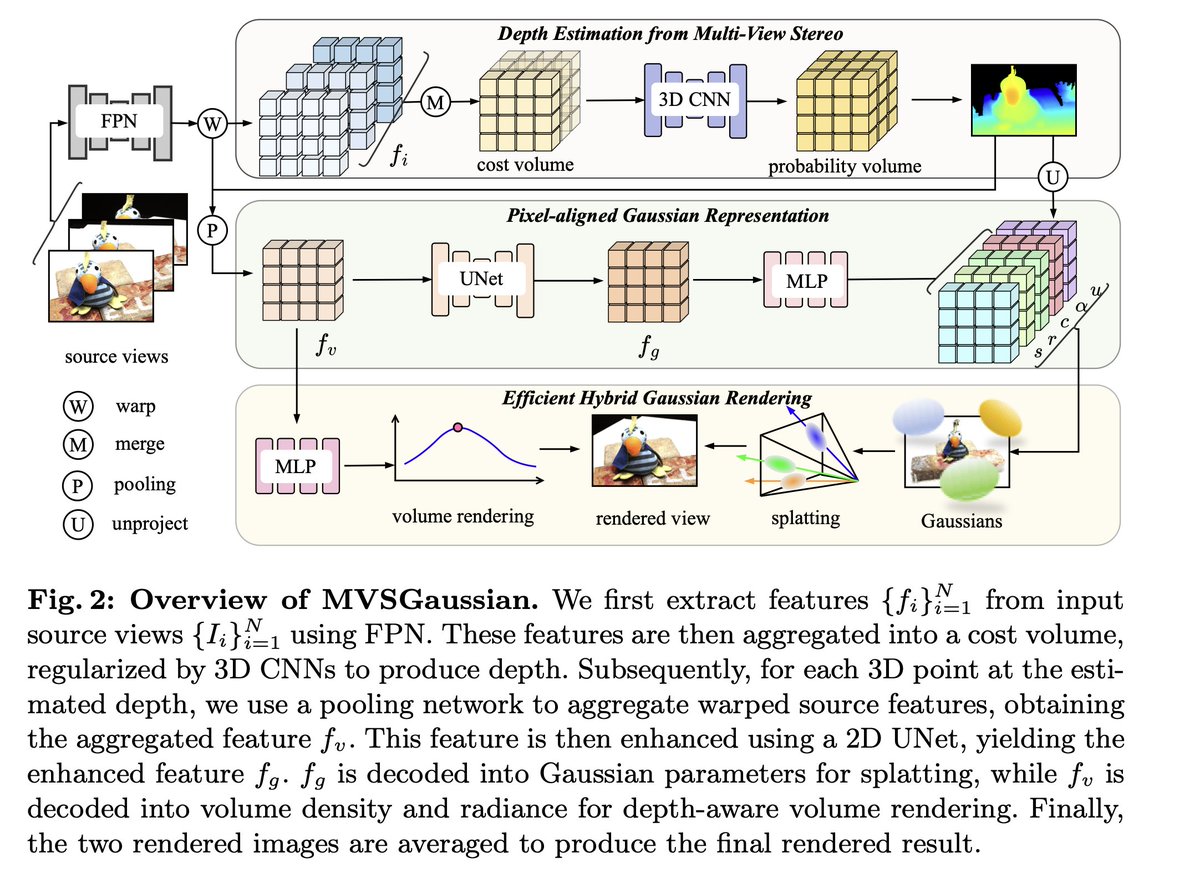
 Fast Generalizable Gaussian Splatting Reconstruction from Multi-View Stereo
Fast Generalizable Gaussian Splatting Reconstruction from Multi-View Stereo Explore More:
Explore More: 








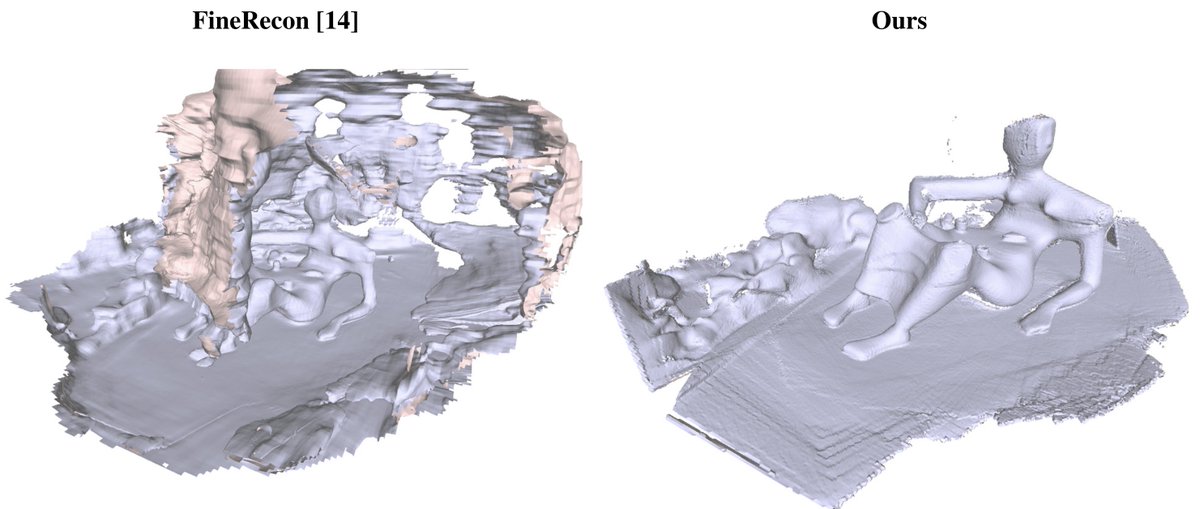
 For data preprocessing, we use DUSt3R for depth prediction of image pairs, and during inference, it works well with any off-the-shelf MDE like Zoedepth. And, we will make the code and checkpoint public soon!
For data preprocessing, we use DUSt3R for depth prediction of image pairs, and during inference, it works well with any off-the-shelf MDE like Zoedepth. And, we will make the code and checkpoint public soon!


 Introducing AltCanvas- a new tool blending generative AI with a tile-based interface to empower visually impaired creators! AltCanvas combines a novel tile-based authoring approach with Generative AI, allowing users to build complex scenes piece by piece. /search?q=#assets2024
Introducing AltCanvas- a new tool blending generative AI with a tile-based interface to empower visually impaired creators! AltCanvas combines a novel tile-based authoring approach with Generative AI, allowing users to build complex scenes piece by piece. /search?q=#assets2024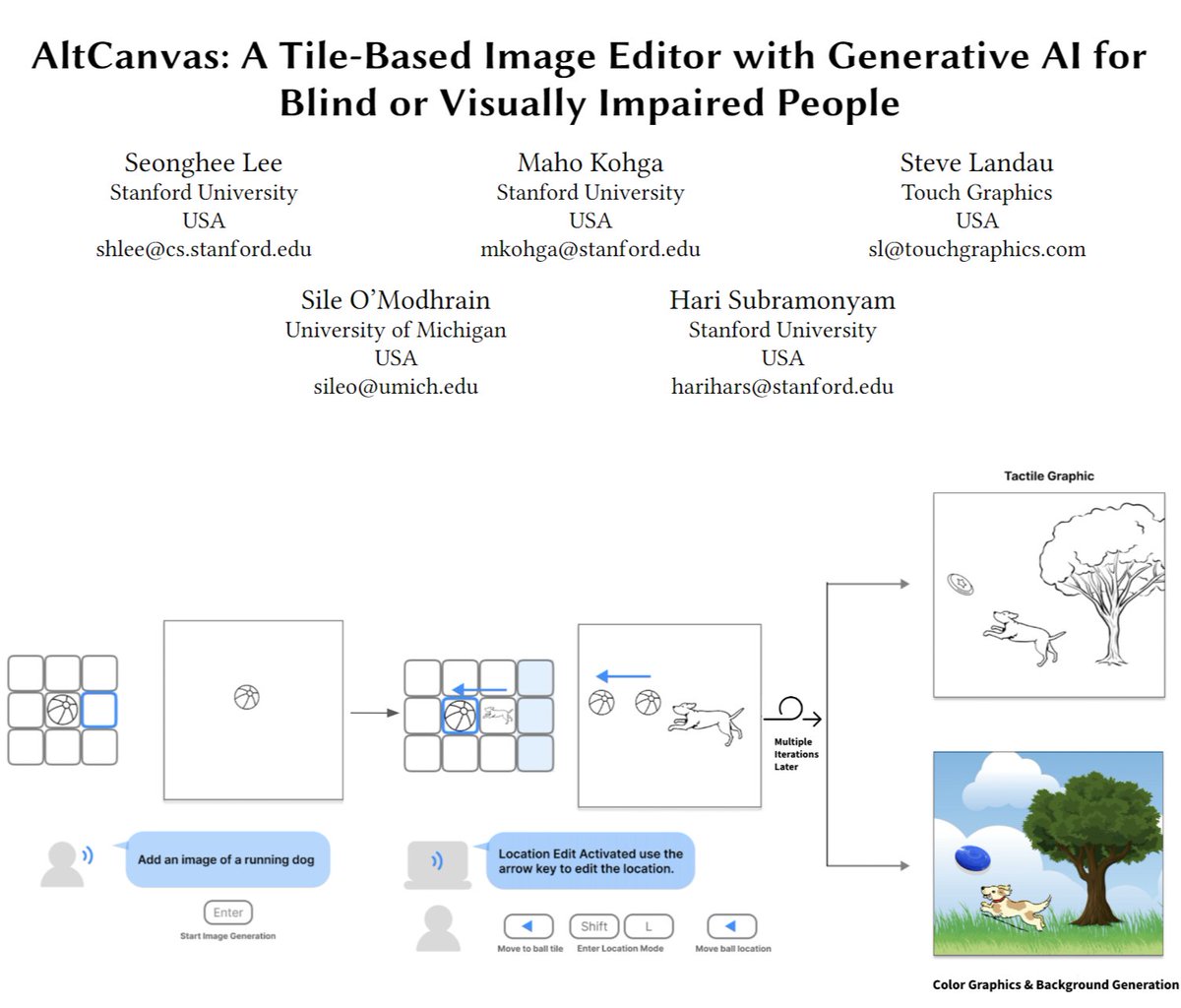




 More info below
More info below



 ? Wish you could get fast
? Wish you could get fast  ?
? .
. ? One depth map alone isn’t perfect. Even a fused mesh will have bias and errors
? One depth map alone isn’t perfect. Even a fused mesh will have bias and errors  .
. .
.