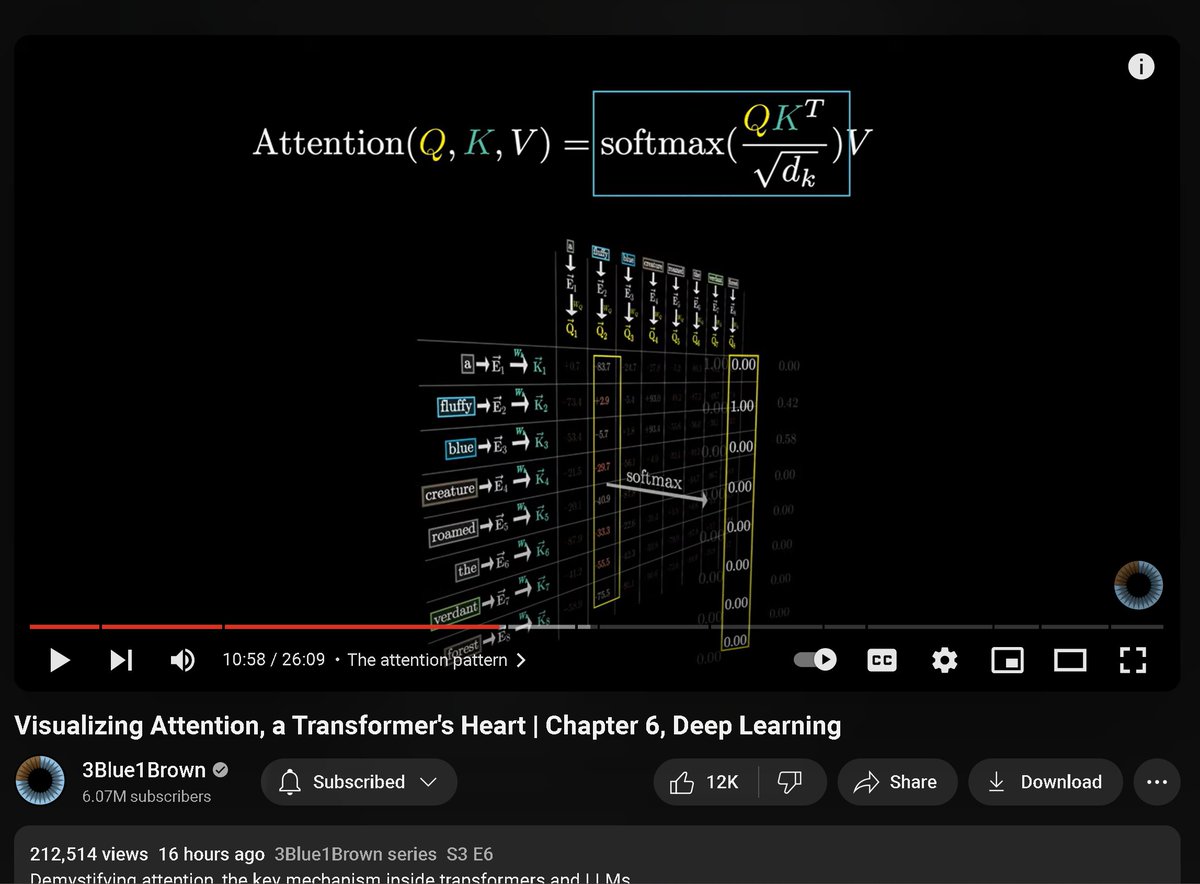
1/1
𝐂𝐇𝐀𝐌𝐏: 𝐂𝐨𝐧𝐭𝐫𝐨𝐥𝐥𝐚𝐛𝐥𝐞 𝐚𝐧𝐝 𝐂𝐨𝐧𝐬𝐢𝐬𝐭𝐞𝐧𝐭 𝐇𝐮𝐦𝐚𝐧 𝐈𝐦𝐚𝐠𝐞 𝐀𝐧𝐢𝐦𝐚𝐭𝐢𝐨𝐧
Model weights on
@huggingface :
 Code:
Code:

 github.com
github.com
Curious to see Champ in action? Build your app & submit for Spaces GPU grants!
𝐂𝐇𝐀𝐌𝐏: 𝐂𝐨𝐧𝐭𝐫𝐨𝐥𝐥𝐚𝐛𝐥𝐞 𝐚𝐧𝐝 𝐂𝐨𝐧𝐬𝐢𝐬𝐭𝐞𝐧𝐭 𝐇𝐮𝐦𝐚𝐧 𝐈𝐦𝐚𝐠𝐞 𝐀𝐧𝐢𝐦𝐚𝐭𝐢𝐨𝐧
Model weights on
@huggingface :
fudan-generative-ai/champ · Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co
GitHub - fudan-generative-vision/champ: Champ: Controllable and Consistent Human Image Animation with 3D Parametric Guidance
Champ: Controllable and Consistent Human Image Animation with 3D Parametric Guidance - fudan-generative-vision/champ
github.com
Curious to see Champ in action? Build your app & submit for Spaces GPU grants!








 Know Your Neighbors: Improving Single-View Reconstruction via Spatial Vision-Language Reasoning
Know Your Neighbors: Improving Single-View Reconstruction via Spatial Vision-Language Reasoning