1/7
Chain-of-Thought (CoT) prompting --> OUT(?), analogical prompting --> IN!
A new paper from @GoogleDeepMind & @Stanford (accepted to @iclr_conf): "Large Language Models as Analogical Reasoners"
2/7
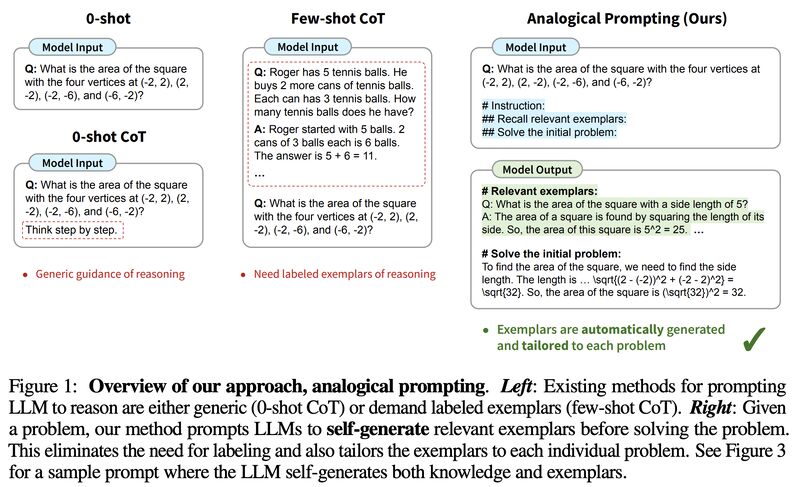
CoT prompting has shown LLMs’ abilities to tackle complex tasks, such as solving math problems, by prompting them to generate intermediate reasoning steps. However, they typically demand labeled exemplars of the reasoning process, which can be costly to obtain for every task!
3/7
In this paper, they propose "analogical prompting", a new prompting approach that automatically guides the reasoning process of LLMs!
Their inspiration comes from analogical reasoning in psychology, a concept where humans draw from relevant experiences to tackle new problems.
4/7
They use exactly this idea to prompt LLMs to self-generate relevant exemplars or knowledge in the context, before proceeding to solve the original problem (see figure in main tweet)
5/7
𝐀𝐝𝐯𝐚𝐧𝐭𝐚𝐠𝐞𝐬:
It eliminates the need for labeling or retrieving examples, offering generality and convenience.
It adapts the examples and knowledge to each problem, offering adaptability.
6/7
𝐑𝐞𝐬𝐮𝐥𝐭𝐬:
𝐚𝐧𝐚𝐥𝐨𝐠𝐢𝐜𝐚𝐥 𝐩𝐫𝐨𝐦𝐩𝐭𝐢𝐧𝐠 surpasses both 0-shot and manually tuned few-shot CoT across several reasoning tasks like math problem solving (GSM8K, MATH), code generation (Codeforces), and various reasoning challenges in BIG-Bench!
7/7
Authors:
@jure
@percyliang
@denny_zhou
@edchi
Chain-of-Thought (CoT) prompting --> OUT(?), analogical prompting --> IN!
A new paper from @GoogleDeepMind & @Stanford (accepted to @iclr_conf): "Large Language Models as Analogical Reasoners"
2/7
CoT prompting has shown LLMs’ abilities to tackle complex tasks, such as solving math problems, by prompting them to generate intermediate reasoning steps. However, they typically demand labeled exemplars of the reasoning process, which can be costly to obtain for every task!
3/7
In this paper, they propose "analogical prompting", a new prompting approach that automatically guides the reasoning process of LLMs!
Their inspiration comes from analogical reasoning in psychology, a concept where humans draw from relevant experiences to tackle new problems.
4/7
They use exactly this idea to prompt LLMs to self-generate relevant exemplars or knowledge in the context, before proceeding to solve the original problem (see figure in main tweet)
5/7
𝐀𝐝𝐯𝐚𝐧𝐭𝐚𝐠𝐞𝐬:
It eliminates the need for labeling or retrieving examples, offering generality and convenience.
It adapts the examples and knowledge to each problem, offering adaptability.
6/7
𝐑𝐞𝐬𝐮𝐥𝐭𝐬:
𝐚𝐧𝐚𝐥𝐨𝐠𝐢𝐜𝐚𝐥 𝐩𝐫𝐨𝐦𝐩𝐭𝐢𝐧𝐠 surpasses both 0-shot and manually tuned few-shot CoT across several reasoning tasks like math problem solving (GSM8K, MATH), code generation (Codeforces), and various reasoning challenges in BIG-Bench!
7/7
Authors:
@jure
@percyliang
@denny_zhou
@edchi