Researchers tested the system on 80 chickens for the study, which was led by a University of Tokyo professor.

www.businessinsider.com
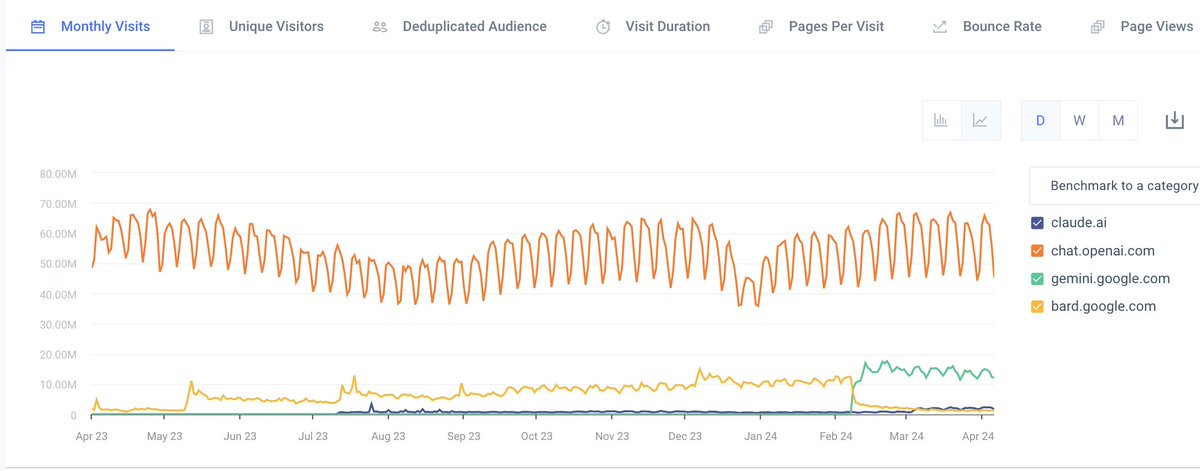
Japanese researchers say they used AI to try and translate the noises of clucking chickens and learn whether they're excited, hungry, or scared
Beatrice Nolan
Sep 21, 2023, 7:41 AM EDT
The study, which was led by University of Tokyo professor Adrian David Cheok, has yet to be peer-reviewed. Getty Images
- Researchers think they've found a way to use AI to translate the clucks of chickens.
- The Japanese researchers said their AI system could help understand chickens' emotional state.
- The study has not been peer-reviewed and the researchers acknowledged limitations to their methods.
Researchers in Japan said they'd developed an
AI system that could understand the emotional state of chickens.
The study, which was led by University of Tokyo professor Adrian David Cheok, has yet to be peer-reviewed.
The AI system is based on a technique the researchers called "Deep Emotional Analysis Learning," which can adapt to changing vocal patterns.
The study found that the system was capable of translating "various emotional states in chickens, including hunger, fear, anger, contentment, excitement, and distress."
The study said: "Our methodology employs a cutting-edge AI technique we call Deep Emotional Analysis Learning (DEAL), a highly mathematical and innovative approach that allows for the nuanced understanding of emotional states through auditory data."
"If we know what animals are feeling, we can design a much better world for them," Cheok told the
New York Post. Cheok did not immediately respond to Insider's request for comment, made outside normal working hours.
The researchers tested the system on 80 chickens for the study and collaborated with a team of animal psychologists and veterinarians.
The system was able to achieve surprisingly high accuracy in identifying the birds' emotional states, the study found. "The high average probabilities of detection for each emotion suggest that our model has learned to capture meaningful patterns and features from the chicken sounds," it said.
The researchers acknowledged potential limitations, including variations in breeds and the complexity of some communications, such as body language.
Scientists and researchers are also using AI tools for conservation efforts. In one case,
AI tools have been implemented to help identify tracks to better understand animal populations.
In 2022, researchers led by the University of Copenhagen, the ETH Zurich, and France's National Research Institute for Agriculture, Food and Environment said they'd created an algorithm to help understand
the emotions of pigs.







 Alibaba Chief Says China AI 2 Years Behind US, How Humor Forum Unexpectedly Makes AI Smarter, and China Approves 117 Gen-AI Models
Alibaba Chief Says China AI 2 Years Behind US, How Humor Forum Unexpectedly Makes AI Smarter, and China Approves 117 Gen-AI Models
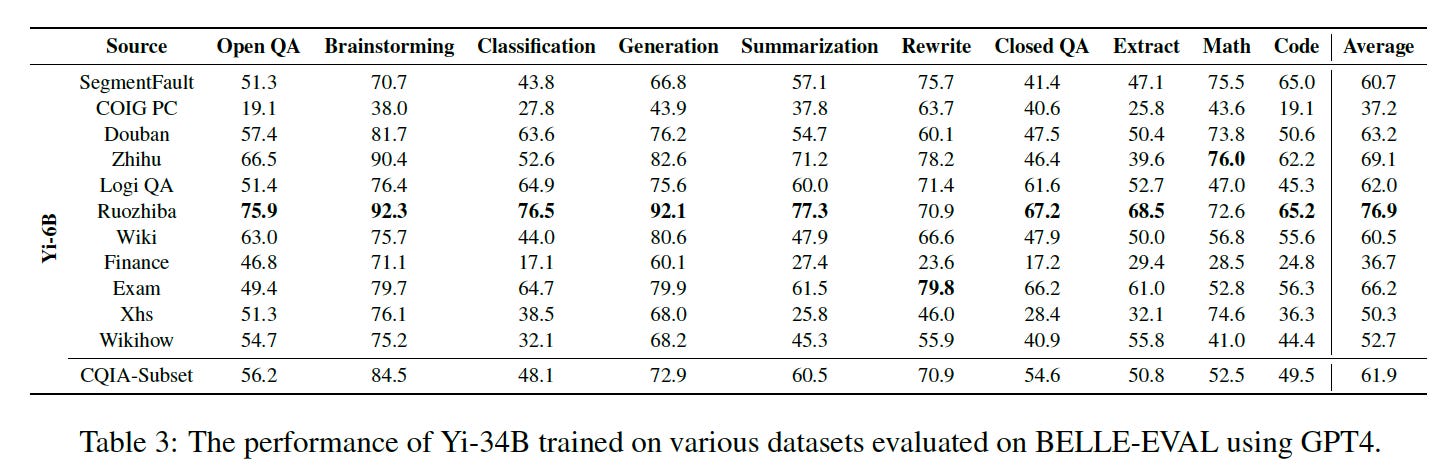













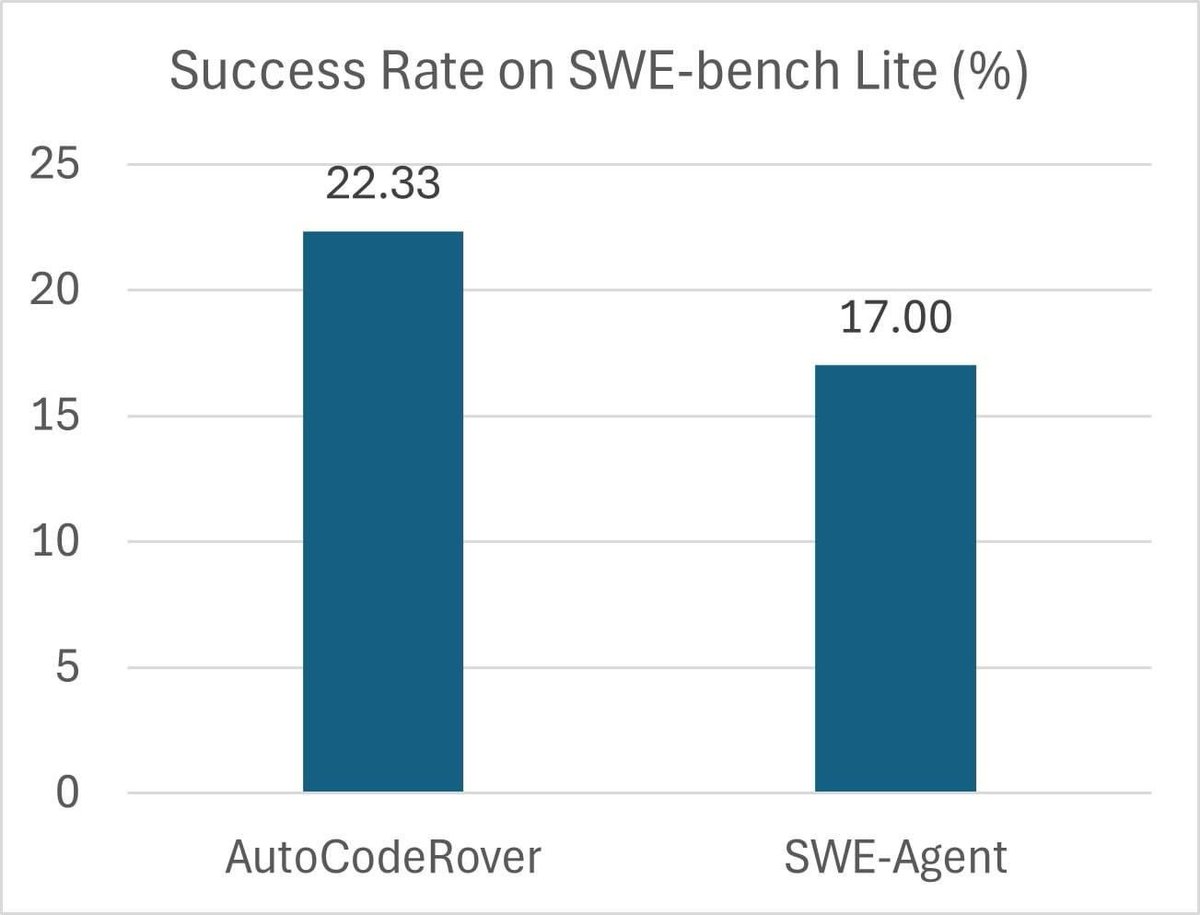
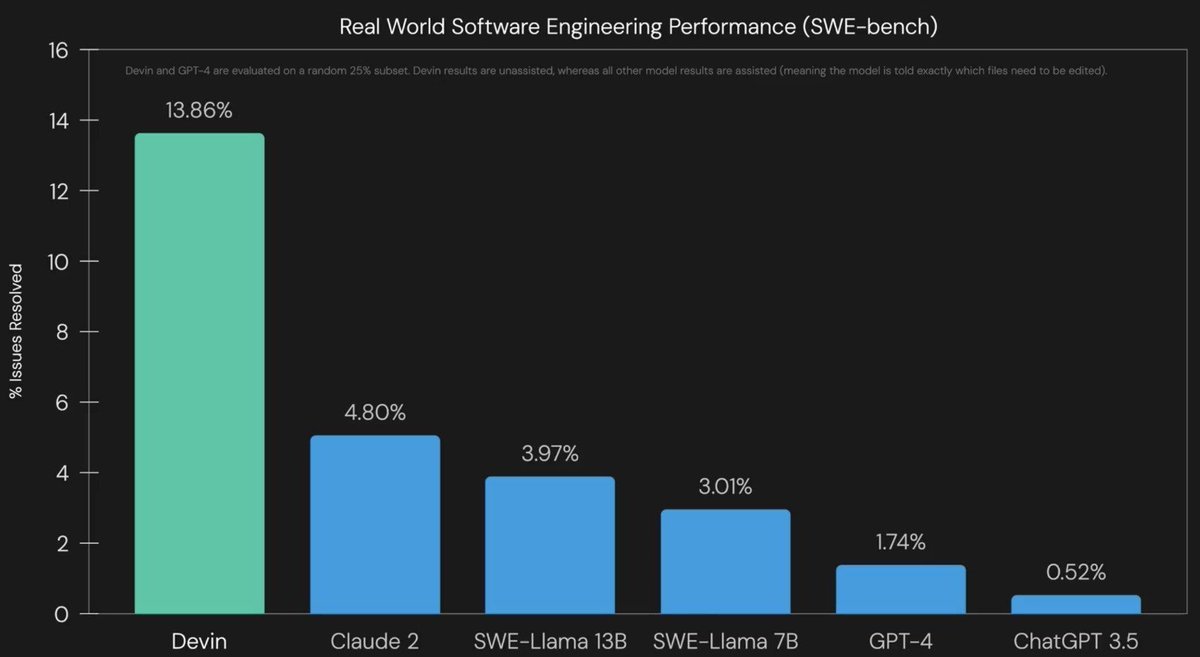




 Overview
Overview
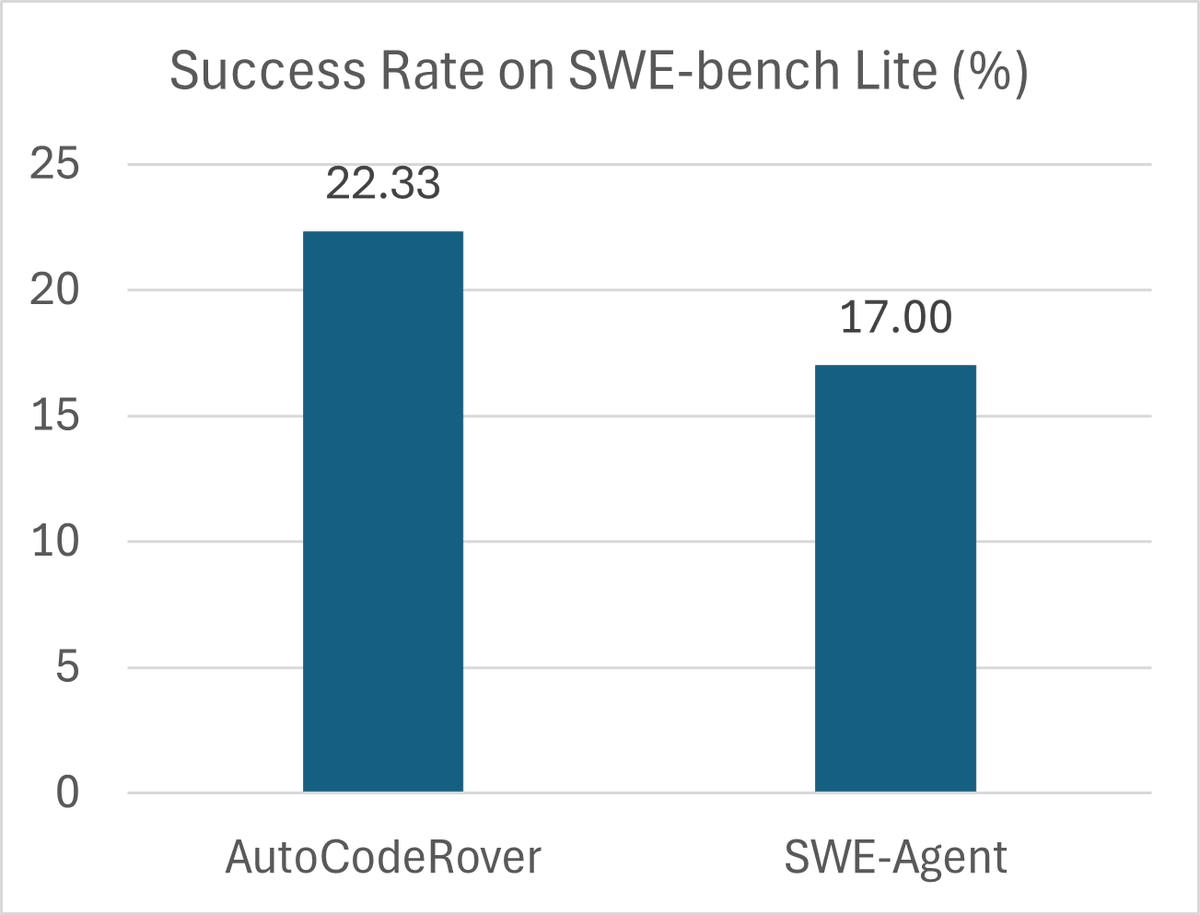
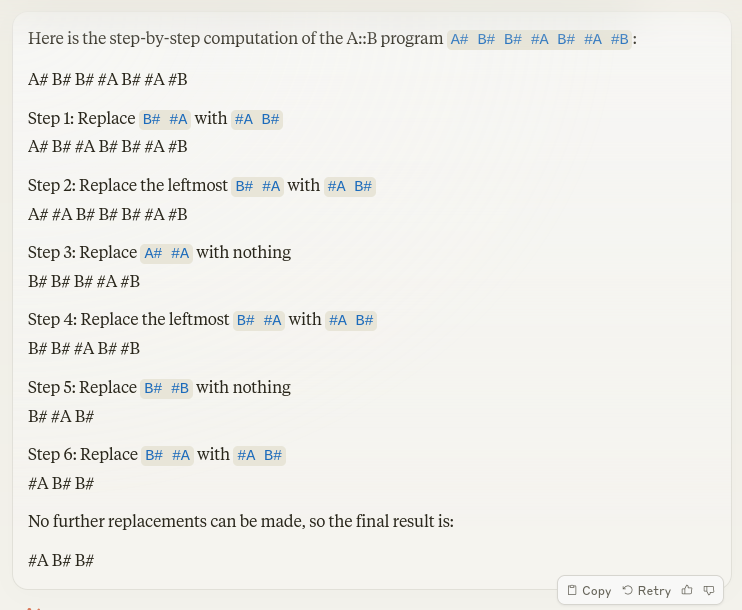
 Context retrieval: The LLM is provided with code search APIs to navigate the codebase and collect relevant context.
Context retrieval: The LLM is provided with code search APIs to navigate the codebase and collect relevant context. Patch generation: The LLM tries to write a patch, based on retrieved context.
Patch generation: The LLM tries to write a patch, based on retrieved context. Highlights
Highlights
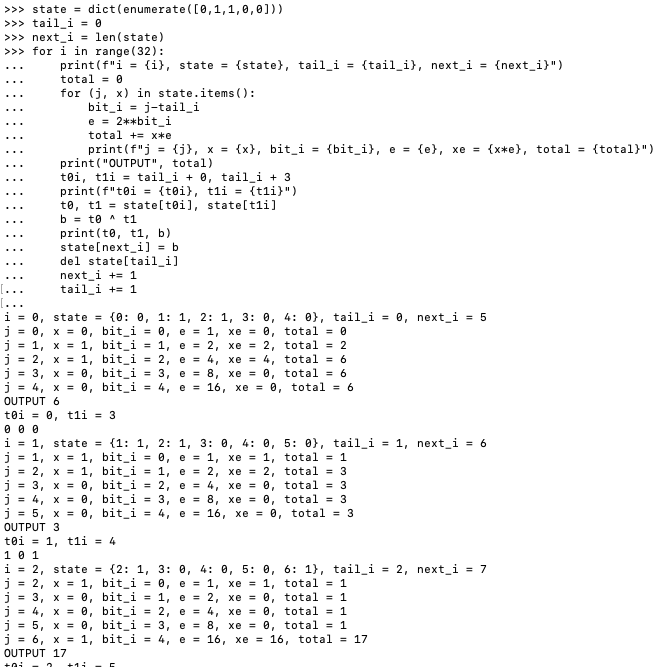
 Example: Django Issue #32347
Example: Django Issue #32347