Model Card for C4AI Command R+
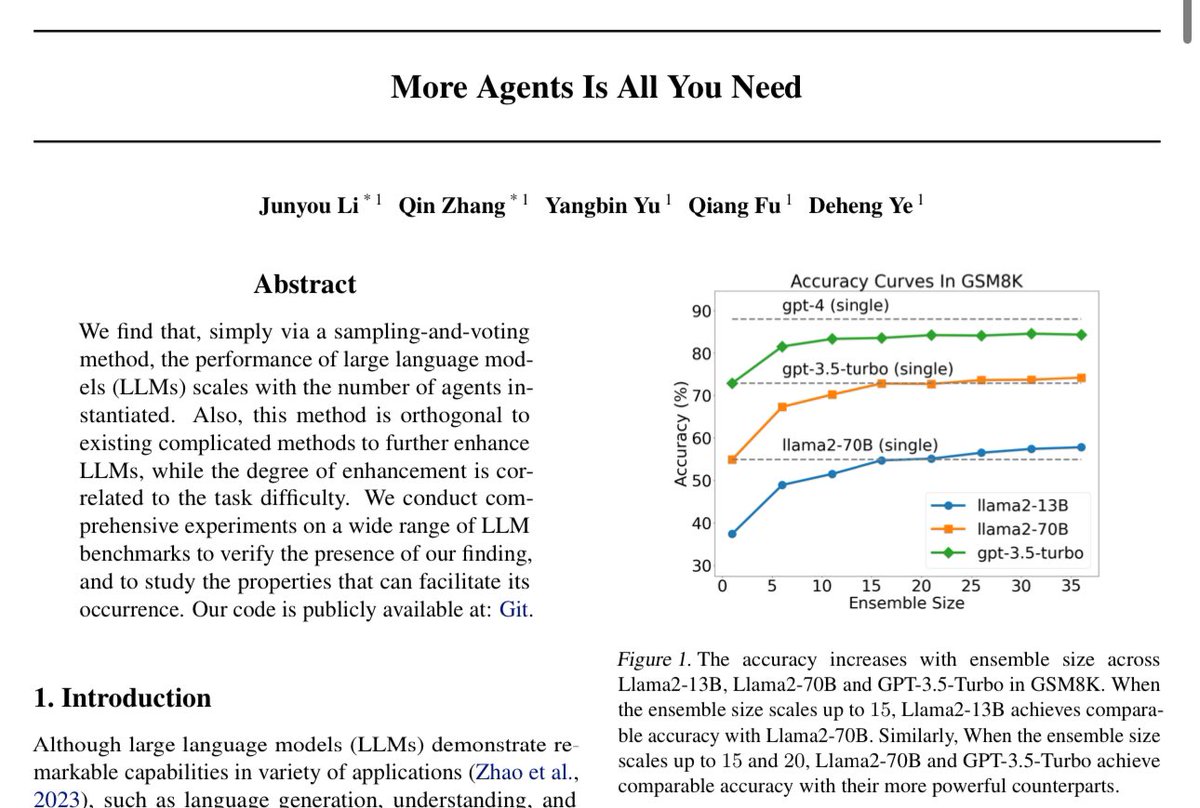
C4AI Command R+ is an open weights research release of a 104B billion parameter model with highly advanced capabilities, this includes Retrieval Augmented Generation (RAG) and tool use to automate sophisticated tasks. The tool use in this model generation enables multi-step tool use which allows the model to combine multiple tools over multiple steps to accomplish difficult tasks. C4AI Command R+ is a multilingual model evaluated in 10 languages for performance: English, French, Spanish, Italian, German, Brazilian Portuguese, Japanese, Korean, Arabic, and Simplified Chinese. Command R+ is optimized for a variety of use cases including reasoning, summarization, and question answering.C4AI Command R+ is part of a family of open weight releases from Cohere For AI and Cohere. Our smaller companion model is C4AI Command R
Developed by: Cohere and Cohere For AI
- Point of Contact: Cohere For AI: cohere.for.ai
- License: CC-BY-NC, requires also adhering to C4AI's Acceptable Use Policy
- Model: c4ai-command-r-plus
- Model Size: 104 billion parameters
- Context length: 128K
Try C4AI Command R+
You can try out C4AI Command R+ before downloading the weights in our hosted Hugging Face Space.
Usage
Please install transformers from the source repository that includes the necessary changes for this model.
edited out information for character space
Quantized model through bitsandbytes, 8-bit precision
edited out information for character space
Quantized model through bitsandbytes, 4-bit precision
edited out information for character space
Input: Models input text only.
Output: Models generate text only.
Model Architecture: This is an auto-regressive language model that uses an optimized transformer architecture. After pretraining, this model uses supervised fine-tuning (SFT) and preference training to align model behavior to human preferences for helpfulness and safety.
Languages covered: The model is optimized to perform well in the following languages: English, French, Spanish, Italian, German, Brazilian Portuguese, Japanese, Korean, Simplified Chinese, and Arabic.
Pre-training data additionally included the following 13 languages: Russian, Polish, Turkish, Vietnamese, Dutch, Czech, Indonesian, Ukrainian, Romanian, Greek, Hindi, Hebrew, Persian.
Context length: Command R+ supports a context length of 128K.
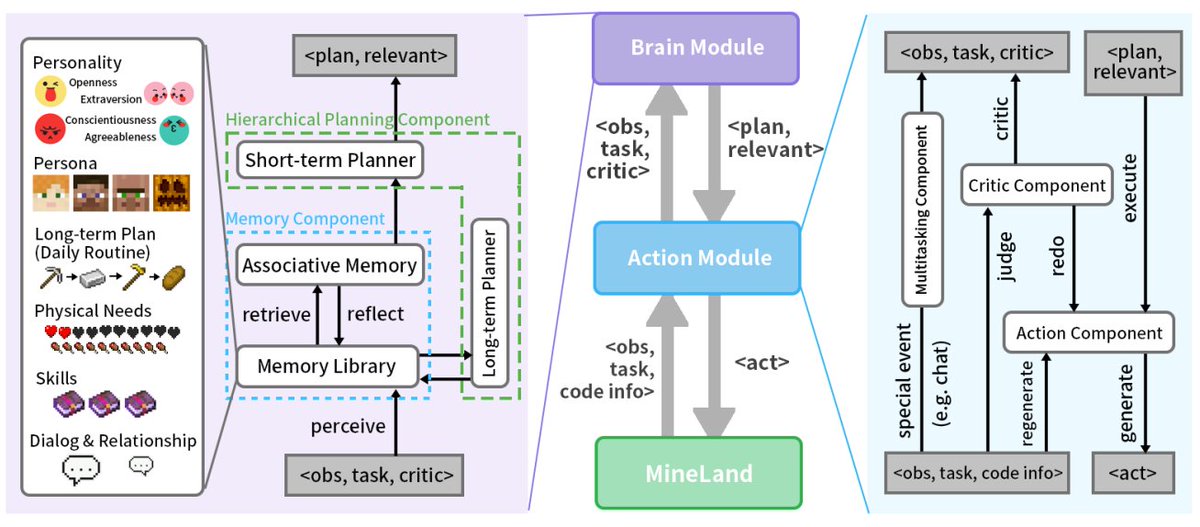
Command R+ has been specifically trained with conversational tool use capabilities. These have been trained into the model via a mixture of supervised fine-tuning and preference fine-tuning, using a specific prompt template. Deviating from this prompt template will likely reduce performance, but we encourage experimentation.
Command R+’s tool use functionality takes a conversation as input (with an optional user-system preamble), along with a list of available tools. The model will then generate a json-formatted list of actions to execute on a subset of those tools. Command R+ may use one of its supplied tools more than once.
The model has been trained to recognise a special directly_answer tool, which it uses to indicate that it doesn’t want to use any of its other tools. The ability to abstain from calling a specific tool can be useful in a range of situations, such as greeting a user, or asking clarifying questions. We recommend including the directly_answer tool, but it can be removed or renamed if required.
Comprehensive documentation for working with command R+'s tool use prompt template can be found here.
The code snippet below shows a minimal working example on how to render a prompt.
Usage: Rendering Tool Use Prompts [CLICK TO EXPAND]
Example Rendered Tool Use Prompt [CLICK TO EXPAND]
Example Rendered Tool Use Completion [CLICK TO EXPAND]
Command R+ has been specifically trained with grounded generation capabilities. This means that it can generate responses based on a list of supplied document snippets, and it will include grounding spans (citations) in its response indicating the source of the information. This can be used to enable behaviors such as grounded summarization and the final step of Retrieval Augmented Generation (RAG). This behavior has been trained into the model via a mixture of supervised fine-tuning and preference fine-tuning, using a specific prompt template. Deviating from this prompt template may reduce performance, but we encourage experimentation.
Command R+’s grounded generation behavior takes a conversation as input (with an optional user-supplied system preamble, indicating task, context and desired output style), along with a list of retrieved document snippets. The document snippets should be chunks, rather than long documents, typically around 100-400 words per chunk. Document snippets consist of key-value pairs. The keys should be short descriptive strings, the values can be text or semi-structured.
By default, Command R+ will generate grounded responses by first predicting which documents are relevant, then predicting which ones it will cite, then generating an answer. Finally, it will then insert grounding spans into the answer. See below for an example. This is referred to as accurate grounded generation.
The model is trained with a number of other answering modes, which can be selected by prompt changes. A fast citation mode is supported in the tokenizer, which will directly generate an answer with grounding spans in it, without first writing the answer out in full. This sacrifices some grounding accuracy in favor of generating fewer tokens.
Comprehensive documentation for working with Command R+'s grounded generation prompt template can be found here.
The code snippet below shows a minimal working example on how to render a prompt.
Usage: Rendering Grounded Generation prompts [CLICK TO EXPAND]
Example Rendered Grounded Generation Prompt [CLICK TO EXPAND]
Example Rendered Grounded Generation Completion [CLICK TO EXPAND]
Command R+ has been optimized to interact with your code, by requesting code snippets, code explanations, or code rewrites. It might not perform well out-of-the-box for pure code completion. For better performance, we also recommend using a low temperature (and even greedy decoding) for code-generation related instructions.
For errors or additional questions about details in this model card, contact info@for.ai.
We hope that the release of this model will make community-based research efforts more accessible, by releasing the weights of a highly performant 104 billion parameter model to researchers all over the world. This model is governed by a CC-BY-NC License with an acceptable use addendum, and also requires adhering to C4AI's Acceptable Use Policy.
You can try Command R+ chat in the playground here. You can also use it in our dedicated Hugging Face Space here.