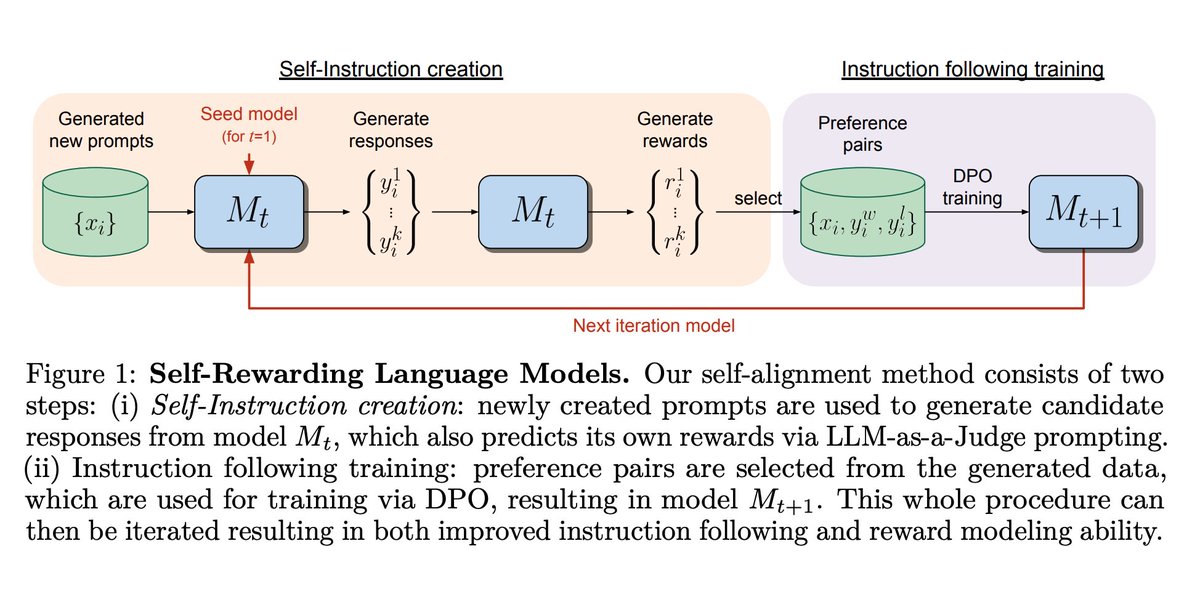
1/2
Egocentric data contains so much rich information about objects and scenes but dealing with the data is hard! Motion blur, sparse coverage, and dynamics all make it very challenging to reconstruct. Check out our new method for automagically extracting 3D object instance models!
2/2
Thanks
@georgiagkioxari ! See you soon in SoCal?
Egocentric data contains so much rich information about objects and scenes but dealing with the data is hard! Motion blur, sparse coverage, and dynamics all make it very challenging to reconstruct. Check out our new method for automagically extracting 3D object instance models!
2/2
Thanks
@georgiagkioxari ! See you soon in SoCal?
1/7
EgoLifter
Open-world 3D Segmentation for Egocentric Perception
In this paper we present EgoLifter, a novel system that can automatically segment scenes captured from egocentric sensors into a complete decomposition of individual 3D objects. The system is specifically
2/7
designed for egocentric data where scenes contain hundreds of objects captured from natural (non-scanning) motion. EgoLifter adopts 3D Gaussians as the underlying representation of 3D scenes and objects and uses segmentation masks from the Segment Anything Model (SAM) as
3/7
weak supervision to learn flexible and promptable definitions of object instances free of any specific object taxonomy. To handle the challenge of dynamic objects in ego-centric videos, we design a transient prediction module that learns to filter out dynamic objects in the 3D
4/7
reconstruction. The result is a fully automatic pipeline that is able to reconstruct 3D object instances as collections of 3D Gaussians that collectively compose the entire scene. We created a new benchmark on the Aria Digital Twin dataset that quantitatively demonstrates
5/7
its state-of-the-art performance in open-world 3D segmentation from natural egocentric input. We run EgoLifter on various egocentric activity datasets which shows the promise of the method for 3D egocentric perception at scale.
6/7
paper page:
7/7
daily papers:
EgoLifter
Open-world 3D Segmentation for Egocentric Perception
In this paper we present EgoLifter, a novel system that can automatically segment scenes captured from egocentric sensors into a complete decomposition of individual 3D objects. The system is specifically
2/7
designed for egocentric data where scenes contain hundreds of objects captured from natural (non-scanning) motion. EgoLifter adopts 3D Gaussians as the underlying representation of 3D scenes and objects and uses segmentation masks from the Segment Anything Model (SAM) as
3/7
weak supervision to learn flexible and promptable definitions of object instances free of any specific object taxonomy. To handle the challenge of dynamic objects in ego-centric videos, we design a transient prediction module that learns to filter out dynamic objects in the 3D
4/7
reconstruction. The result is a fully automatic pipeline that is able to reconstruct 3D object instances as collections of 3D Gaussians that collectively compose the entire scene. We created a new benchmark on the Aria Digital Twin dataset that quantitatively demonstrates
5/7
its state-of-the-art performance in open-world 3D segmentation from natural egocentric input. We run EgoLifter on various egocentric activity datasets which shows the promise of the method for 3D egocentric perception at scale.
6/7
paper page:
7/7
daily papers:
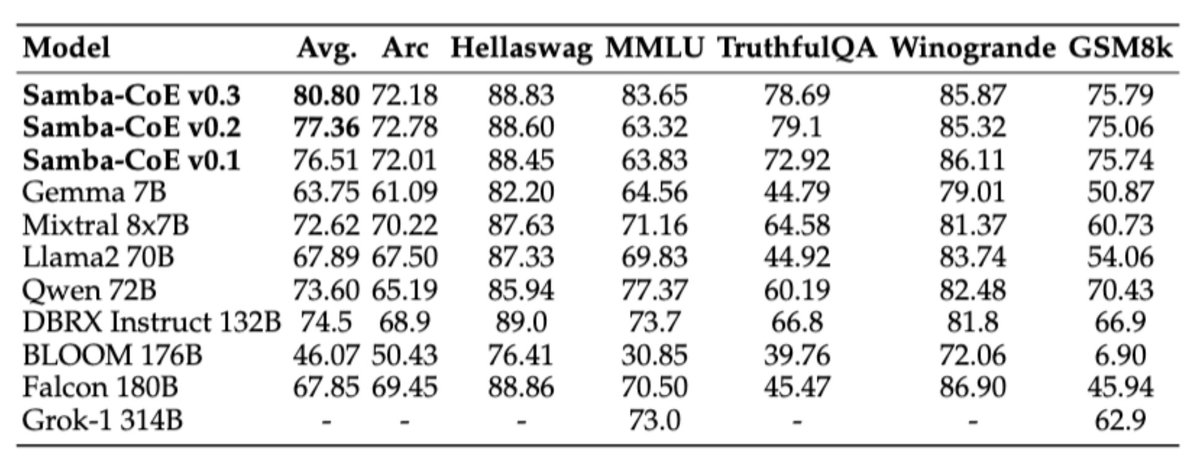







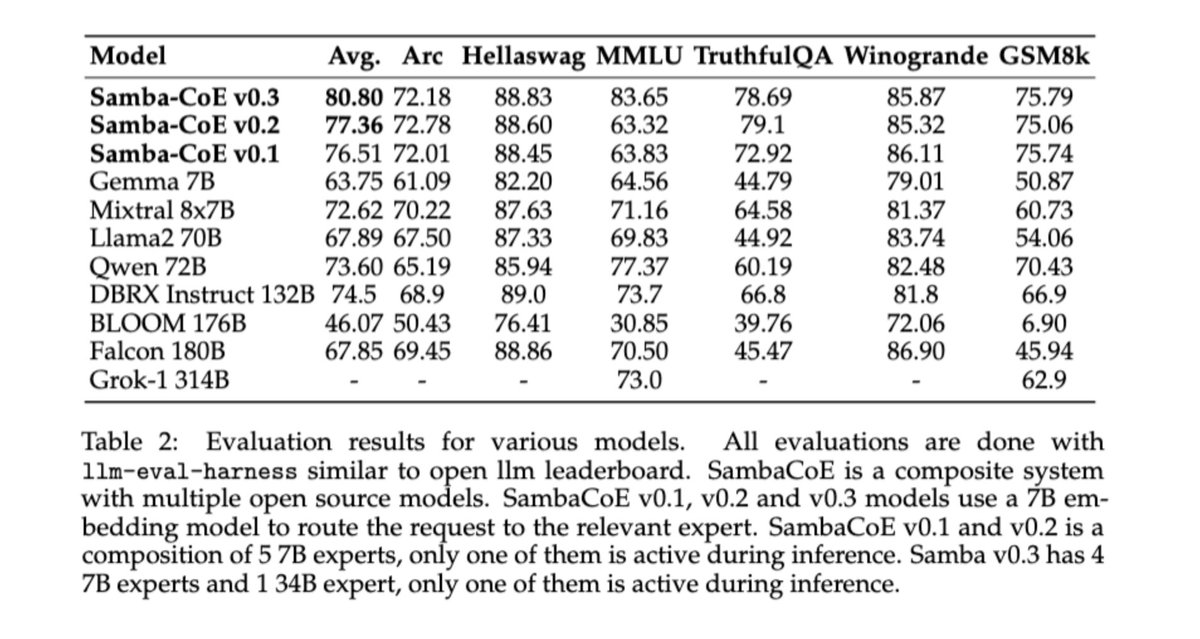








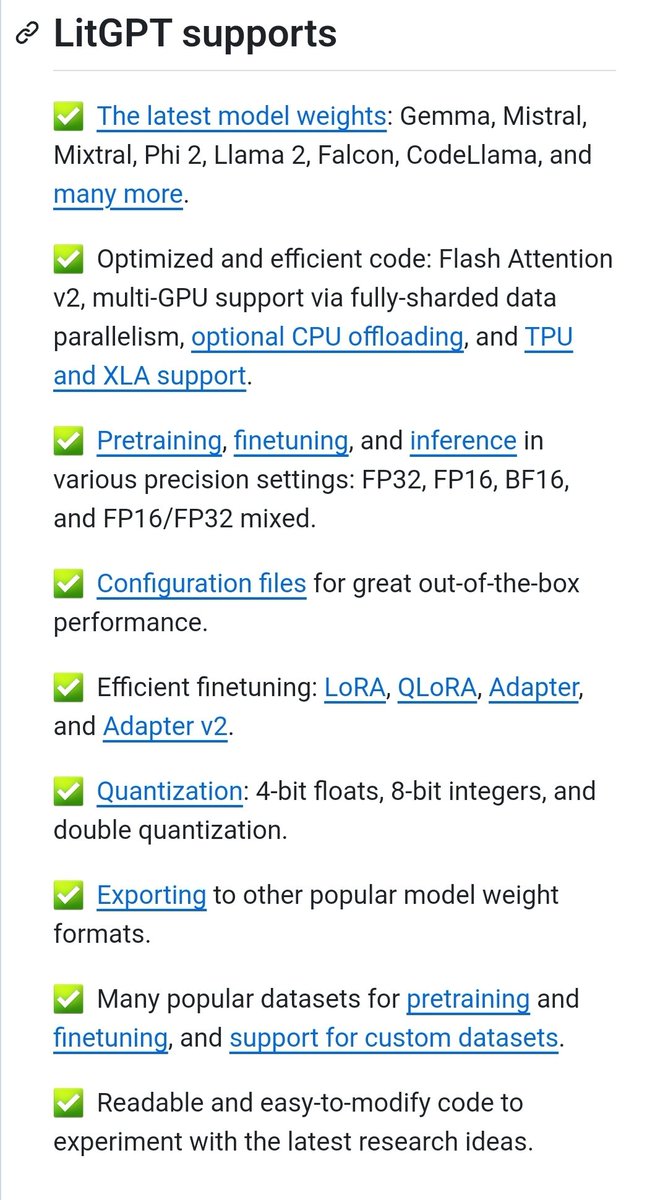












 Overview
Overview
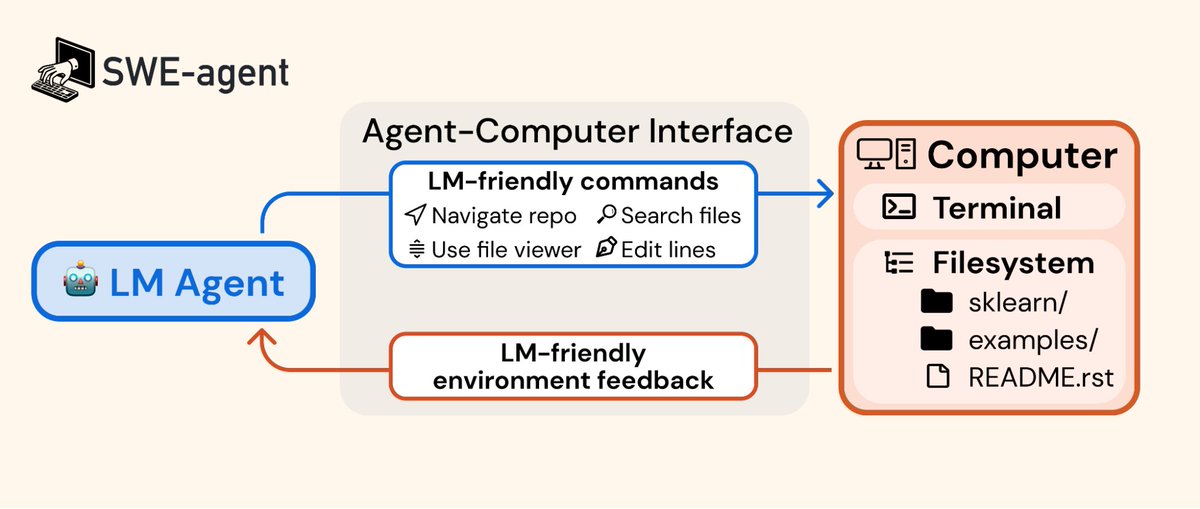
 Agent-Computer Interface (ACI)
Agent-Computer Interface (ACI)