1/7
ChatGLM-Math
Improving Math Problem-Solving in Large Language Models with a Self-Critique Pipeline
Large language models (LLMs) have shown excellent mastering of human language, but still struggle in real-world applications that require mathematical problem-solving. While many
2/7
strategies and datasets to enhance LLMs' mathematics are developed, it remains a challenge to simultaneously maintain and improve both language and mathematical capabilities in deployed LLM systems. In this work, we tailor the Self-Critique pipeline, which addresses the
3/7
challenge in the feedback learning stage of LLM alignment. We first train a general Math-Critique model from the LLM itself to provide feedback signals. Then, we sequentially employ rejective fine-tuning and direct preference optimization over the LLM's own generations for
4/7
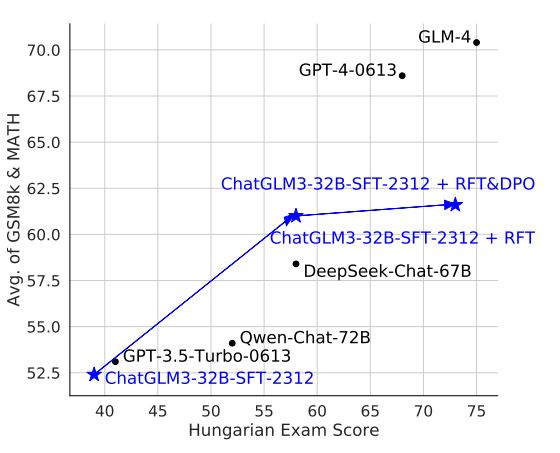
data collection. Based on ChatGLM3-32B, we conduct a series of experiments on both academic and our newly created challenging dataset, MathUserEval. Results show that our
5/7
pipeline significantly enhances the LLM's mathematical problem-solving while still improving its language ability, outperforming LLMs that could be two times larger.
6/7
paper page:
7/7
daily papers:
ChatGLM-Math
Improving Math Problem-Solving in Large Language Models with a Self-Critique Pipeline
Large language models (LLMs) have shown excellent mastering of human language, but still struggle in real-world applications that require mathematical problem-solving. While many
2/7
strategies and datasets to enhance LLMs' mathematics are developed, it remains a challenge to simultaneously maintain and improve both language and mathematical capabilities in deployed LLM systems. In this work, we tailor the Self-Critique pipeline, which addresses the
3/7
challenge in the feedback learning stage of LLM alignment. We first train a general Math-Critique model from the LLM itself to provide feedback signals. Then, we sequentially employ rejective fine-tuning and direct preference optimization over the LLM's own generations for
4/7
data collection. Based on ChatGLM3-32B, we conduct a series of experiments on both academic and our newly created challenging dataset, MathUserEval. Results show that our
5/7
pipeline significantly enhances the LLM's mathematical problem-solving while still improving its language ability, outperforming LLMs that could be two times larger.
6/7
paper page:
7/7
daily papers:







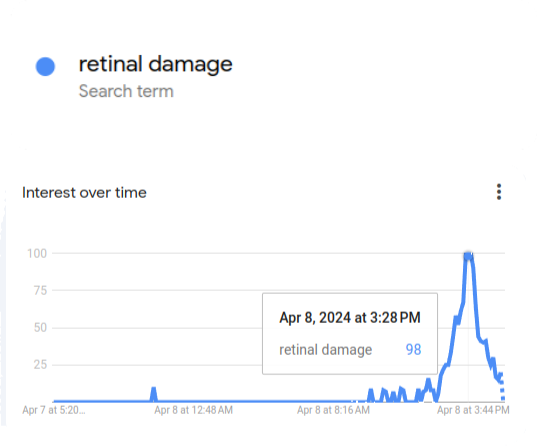
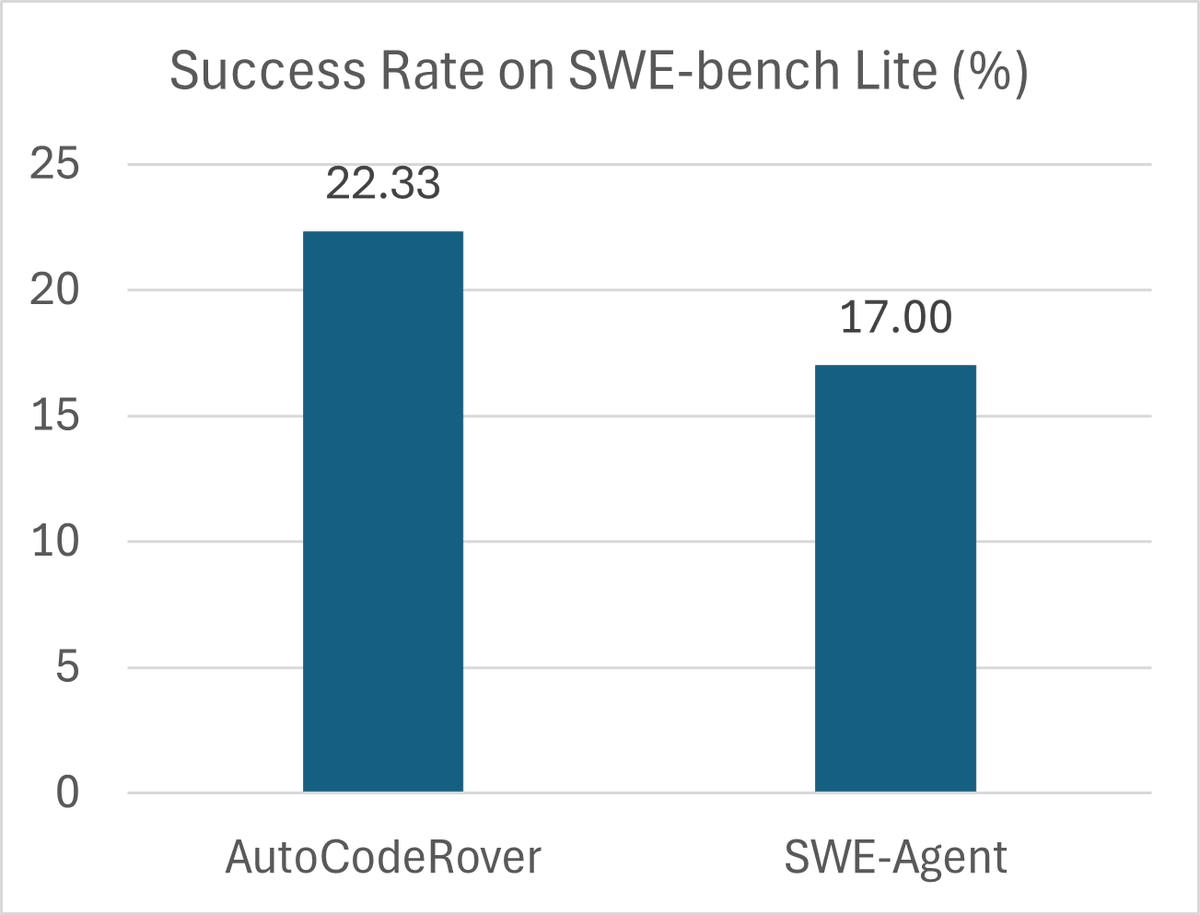




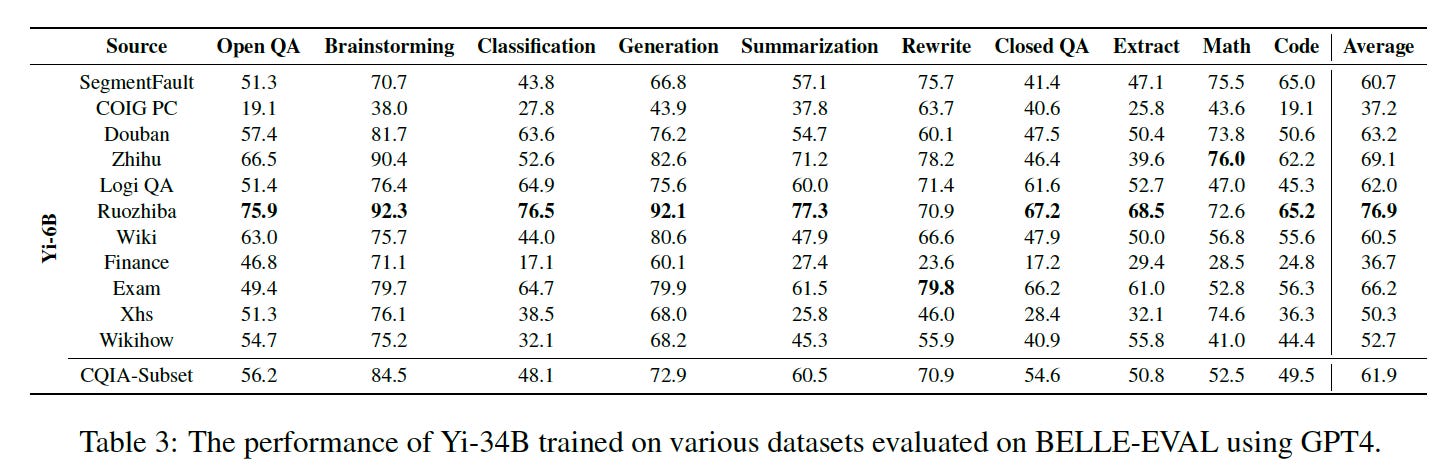
 Alibaba Chief Says China AI 2 Years Behind US, How Humor Forum Unexpectedly Makes AI Smarter, and China Approves 117 Gen-AI Models
Alibaba Chief Says China AI 2 Years Behind US, How Humor Forum Unexpectedly Makes AI Smarter, and China Approves 117 Gen-AI Models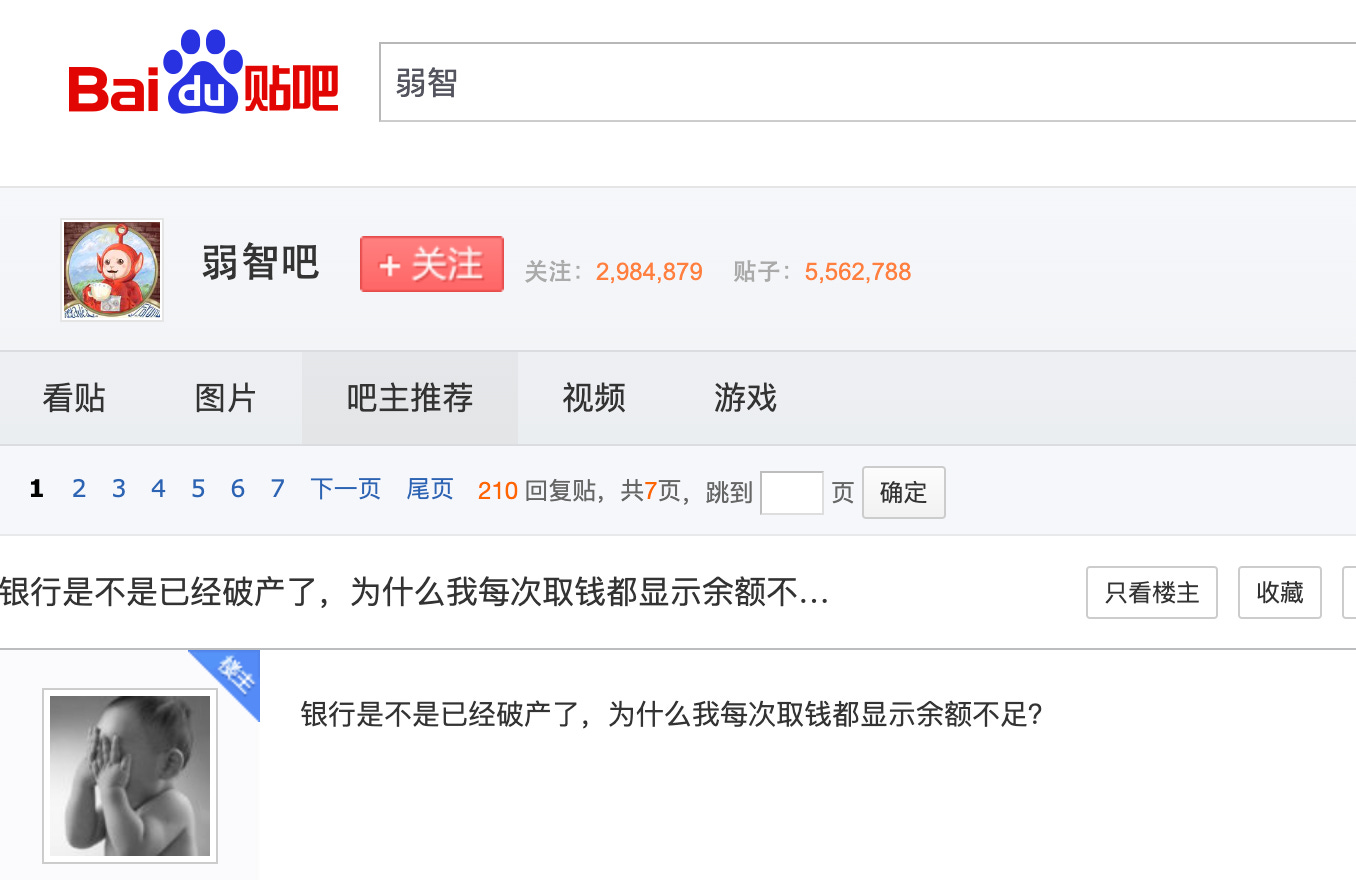

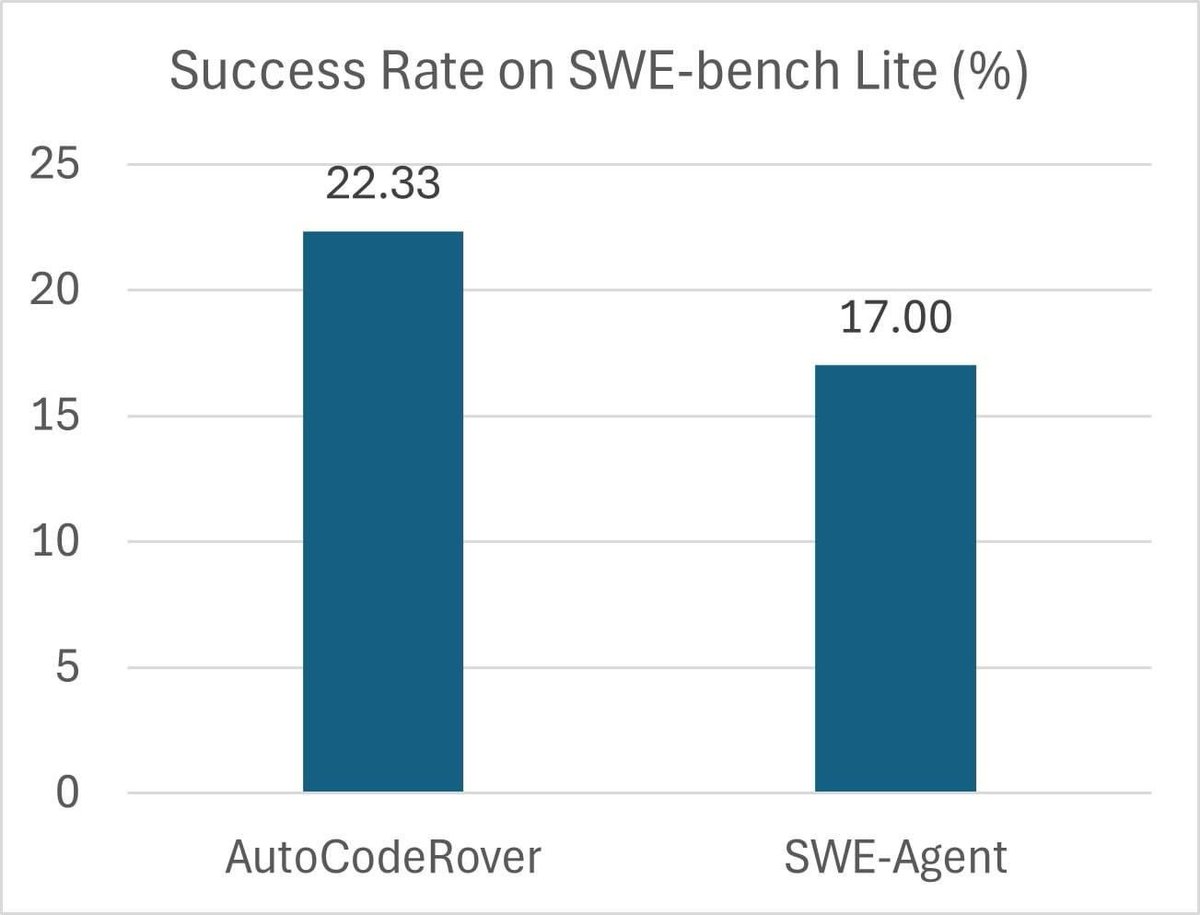

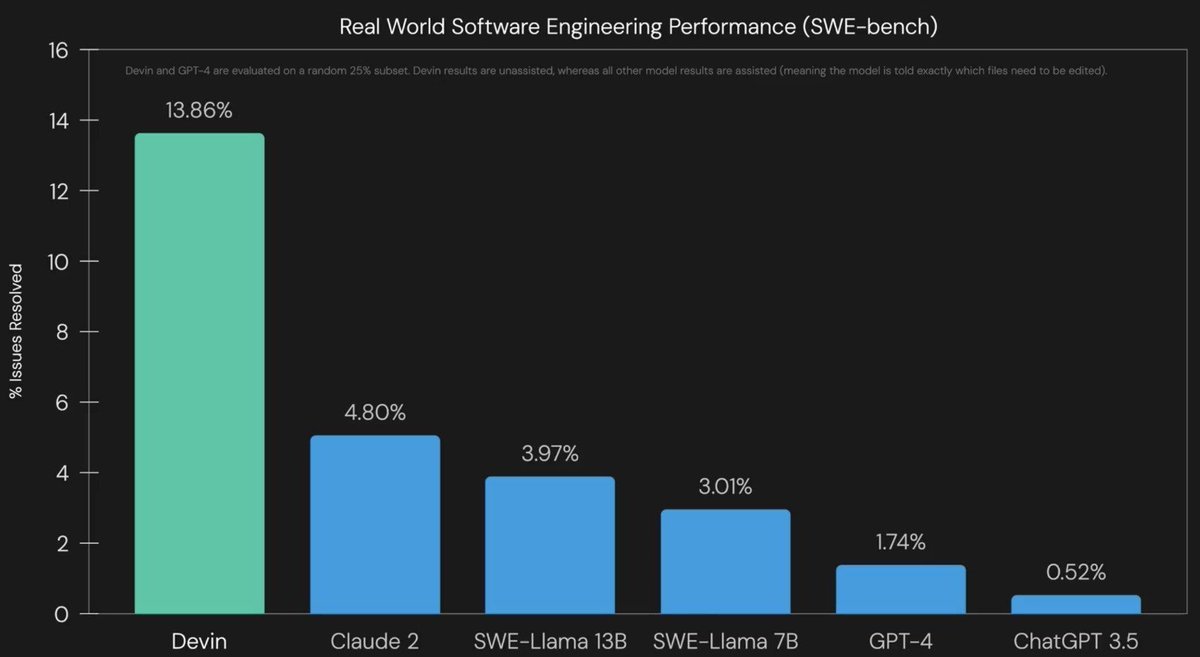



 Overview
Overview
 Context retrieval: The LLM is provided with code search APIs to navigate the codebase and collect relevant context.
Context retrieval: The LLM is provided with code search APIs to navigate the codebase and collect relevant context. Patch generation: The LLM tries to write a patch, based on retrieved context.
Patch generation: The LLM tries to write a patch, based on retrieved context. Highlights
Highlights
 Example: Django Issue #32347
Example: Django Issue #32347