1/8
Today we're excited to introduce Devin, the first AI software engineer.
Devin is the new state-of-the-art on the SWE-Bench coding benchmark, has successfully passed practical engineering interviews from leading AI companies, and has even completed real jobs on Upwork.
Devin is an autonomous agent that solves engineering tasks through the use of its own shell, code editor, and web browser.
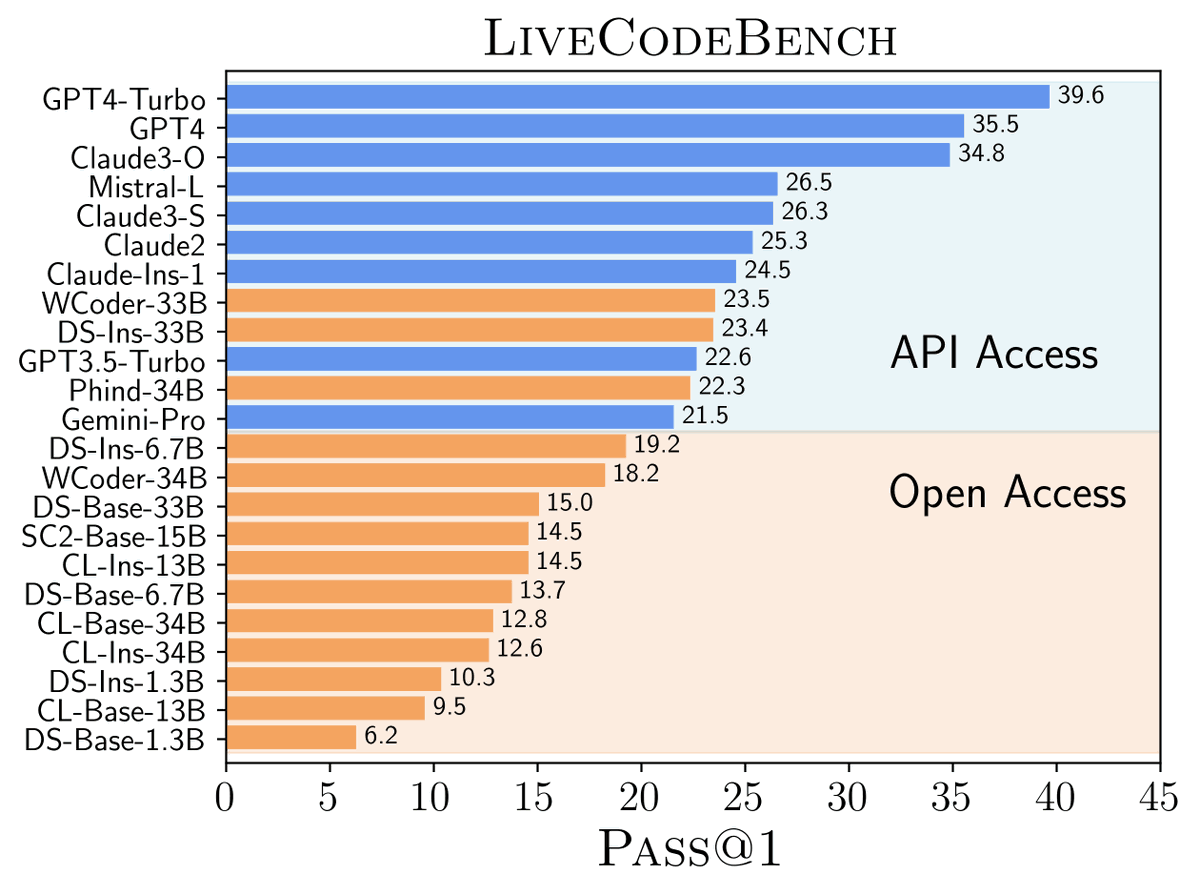
When evaluated on the SWE-Bench benchmark, which asks an AI to resolve GitHub issues found in real-world open-source projects, Devin correctly resolves 13.86% of the issues unassisted, far exceeding the previous state-of-the-art model performance of 1.96% unassisted and 4.80% assisted.
Check out what Devin can do in the thread below.
2/8
Today we're excited to introduce Devin, the first AI software engineer.
Devin is the new state-of-the-art on the SWE-Bench coding benchmark, has successfully passed practical engineering interviews from leading AI companies, and has even completed real jobs on Upwork.
Devin is an autonomous agent that solves engineering tasks through the use of its own shell, code editor, and web browser.
When evaluated on the SWE-Bench benchmark, which asks an AI to resolve GitHub issues found in real-world open-source projects, Devin correctly resolves 13.86% of the issues unassisted, far exceeding the previous state-of-the-art model performance of 1.96% unassisted and 4.80% assisted.
Check out what Devin can do in the thread below.Today we're excited to introduce Devin, the first AI software engineer.
Devin is the new state-of-the-art on the SWE-Bench coding benchmark, has successfully passed practical engineering interviews from leading AI companies, and has even completed real jobs on Upwork.
Devin is an autonomous agent that solves engineering tasks through the use of its own shell, code editor, and web browser.
When evaluated on the SWE-Bench benchmark, which asks an AI to resolve GitHub issues found in real-world open-source projects, Devin correctly resolves 13.86% of the issues unassisted, far exceeding the previous state-of-the-art model performance of 1.96% unassisted and 4.80% assisted.
Check out what Devin can do in the thread below.
3/8
1/4 Devin can learn how to use unfamiliar technologies.
4/8
2/4 Devin can contribute to mature production repositories.
5/8
3/4 Devin can train and fine tune its own AI models.
6/8
4/4 We even tried giving Devin real jobs on Upwork and it could do those too!
7/8
For more details on Devin, check out our blog post here: For more details on Devin, check out our blog post here:
.png) www.cognition-labs.com
See Devin in action
www.cognition-labs.com
See Devin in action
If you have any project ideas, drop them below and we'll forward them to Devin.
See Devin in action
If you have any project ideas, drop them below and we'll forward them to Devin.
8/8
We'd like to thank all our supporters who have helped us get to where we are today, including @patrickc, @collision, @eladgil, @saranormous, Chris Re, @eglyman, @karimatiyeh, @bernhardsson, @t_xu, @FEhrsam, @foundersfund, and many more.
If you’re excited to solve some of the…
Today we're excited to introduce Devin, the first AI software engineer.
Devin is the new state-of-the-art on the SWE-Bench coding benchmark, has successfully passed practical engineering interviews from leading AI companies, and has even completed real jobs on Upwork.
Devin is an autonomous agent that solves engineering tasks through the use of its own shell, code editor, and web browser.
When evaluated on the SWE-Bench benchmark, which asks an AI to resolve GitHub issues found in real-world open-source projects, Devin correctly resolves 13.86% of the issues unassisted, far exceeding the previous state-of-the-art model performance of 1.96% unassisted and 4.80% assisted.
Check out what Devin can do in the thread below.
2/8
Today we're excited to introduce Devin, the first AI software engineer.
Devin is the new state-of-the-art on the SWE-Bench coding benchmark, has successfully passed practical engineering interviews from leading AI companies, and has even completed real jobs on Upwork.
Devin is an autonomous agent that solves engineering tasks through the use of its own shell, code editor, and web browser.
When evaluated on the SWE-Bench benchmark, which asks an AI to resolve GitHub issues found in real-world open-source projects, Devin correctly resolves 13.86% of the issues unassisted, far exceeding the previous state-of-the-art model performance of 1.96% unassisted and 4.80% assisted.
Check out what Devin can do in the thread below.Today we're excited to introduce Devin, the first AI software engineer.
Devin is the new state-of-the-art on the SWE-Bench coding benchmark, has successfully passed practical engineering interviews from leading AI companies, and has even completed real jobs on Upwork.
Devin is an autonomous agent that solves engineering tasks through the use of its own shell, code editor, and web browser.
When evaluated on the SWE-Bench benchmark, which asks an AI to resolve GitHub issues found in real-world open-source projects, Devin correctly resolves 13.86% of the issues unassisted, far exceeding the previous state-of-the-art model performance of 1.96% unassisted and 4.80% assisted.
Check out what Devin can do in the thread below.
3/8
1/4 Devin can learn how to use unfamiliar technologies.
4/8
2/4 Devin can contribute to mature production repositories.
5/8
3/4 Devin can train and fine tune its own AI models.
6/8
4/4 We even tried giving Devin real jobs on Upwork and it could do those too!
7/8
For more details on Devin, check out our blog post here: For more details on Devin, check out our blog post here:
Blog
www.cognition-labs.com
If you have any project ideas, drop them below and we'll forward them to Devin.
See Devin in action
If you have any project ideas, drop them below and we'll forward them to Devin.
8/8
We'd like to thank all our supporters who have helped us get to where we are today, including @patrickc, @collision, @eladgil, @saranormous, Chris Re, @eglyman, @karimatiyeh, @bernhardsson, @t_xu, @FEhrsam, @foundersfund, and many more.
If you’re excited to solve some of the…
Last edited:
/cdn.vox-cdn.com/uploads/chorus_asset/file/23262657/VRG_Illo_STK001_B_Sala_Hacker.jpg)
:format(webp)/cdn.vox-cdn.com/uploads/chorus_asset/file/23262657/VRG_Illo_STK001_B_Sala_Hacker.jpg "A cartoon illustration shows a shadowy figure carrying off a red directory folder, which has a surprised-looking face on its side.")
:format(webp)/cdn.vox-cdn.com/uploads/chorus_asset/file/23262657/VRG_Illo_STK001_B_Sala_Hacker.jpg)
:format(webp)/cdn.vox-cdn.com/uploads/chorus_asset/file/25330175/Midjourney_office_hours.jpg "A screenshot taken from MidJourney’s Discord channel discussing action against Stability.AI employees.")
:format(webp)/cdn.vox-cdn.com/uploads/chorus_asset/file/25330175/Midjourney_office_hours.jpg)




















/cdn.vox-cdn.com/uploads/chorus_asset/file/24016885/STK093_Google_04.jpg)
:format(webp)/cdn.vox-cdn.com/uploads/chorus_asset/file/24016885/STK093_Google_04.jpg "Google logo with colorful shapes")
:format(webp)/cdn.vox-cdn.com/uploads/chorus_asset/file/24016885/STK093_Google_04.jpg)
/cdn.vox-cdn.com/uploads/chorus_asset/file/25333634/openai_sora_screen.png)
:format(webp)/cdn.vox-cdn.com/uploads/chorus_asset/file/25333634/openai_sora_screen.png "A screenshot of an AI-generated video produced by Sora")
:format(webp)/cdn.vox-cdn.com/uploads/chorus_asset/file/25333634/openai_sora_screen.png)
/cdn.vox-cdn.com/uploads/chorus_asset/file/25319789/STK450_EU_E.jpg)
:format(webp)/cdn.vox-cdn.com/uploads/chorus_asset/file/25319789/STK450_EU_E.jpg)








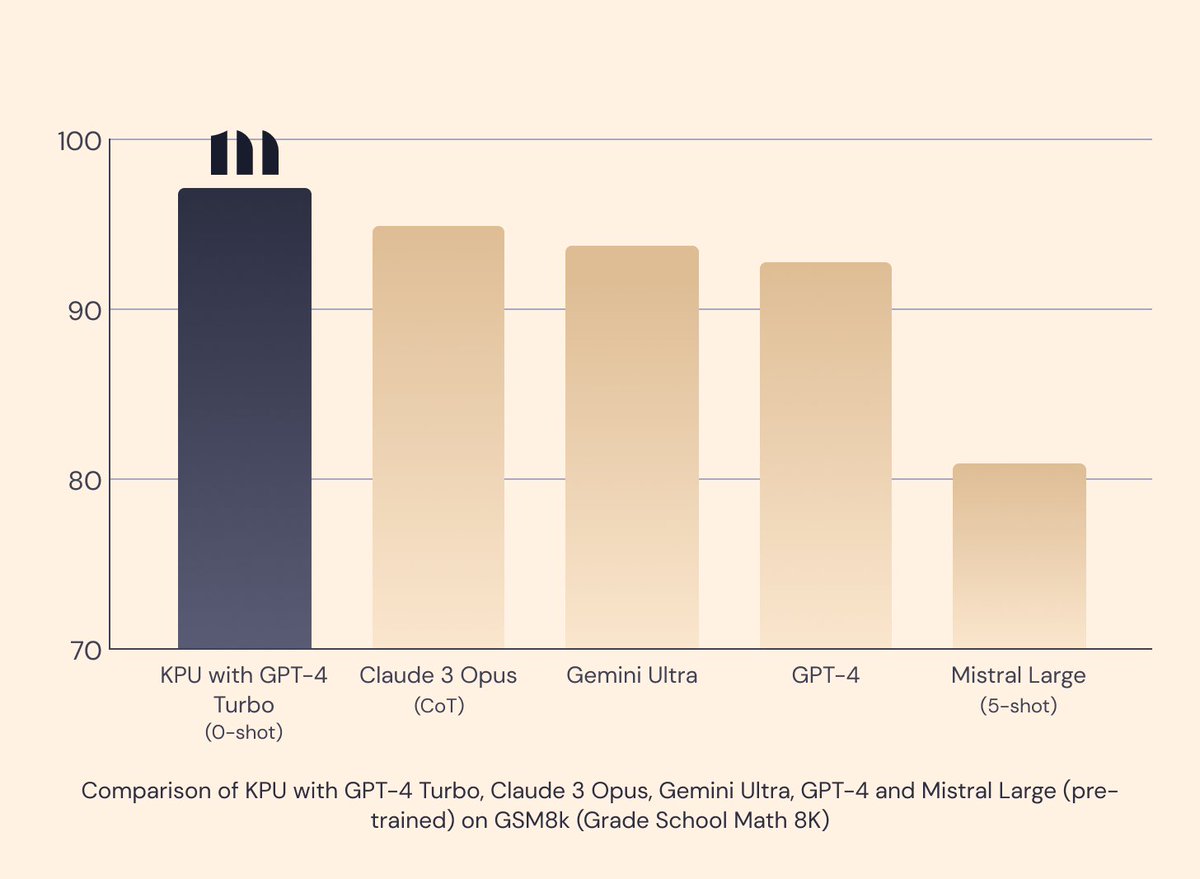



 Paper:
Paper:  Code:
Code:  CodeUltraFeedback:
CodeUltraFeedback: 

 Paper -
Paper -  Leaderboard -
Leaderboard -