1/3
Adding Personas to RAG and LLM systems is one of these ideas that have fascinated me for a while, but I've never quite gotten around to it!
I am SUPER excited to present this demo with @ecardenas300 illustrating how to add a Persona to a chatbot! For example imagine prompting LLMs to chat with diverse and expert viewpoints such as, "You are Nils Reimers" or "You are Fei-Fei Li"!!
I hope you find this demo exciting, further showing how to build with DSPy programs behind FastAPI backends that connect to React frontends, and ... ... Generative Feedback Loops with Weaviate! Saving and indexing these conversations back into the database!
I hope you will consider checking out the open-source repo and running it for yourself, more than happy to help debug / fix any issues if they arise!
2/3
RAG with Persona RAG with Persona
If you ask the same question to multiple people, there is a strong chance each person will have a different response. Here’s a new demo on RAG with Persona using DSPy, @cohere@cohere@cohere, and , and @weaviate_io@weaviate_io@weaviate_io!
When building or using chatbots, it’s important to get a…!
3/3
Haha I can finally chat with LeBron
Adding Personas to RAG and LLM systems is one of these ideas that have fascinated me for a while, but I've never quite gotten around to it!
I am SUPER excited to present this demo with @ecardenas300 illustrating how to add a Persona to a chatbot! For example imagine prompting LLMs to chat with diverse and expert viewpoints such as, "You are Nils Reimers" or "You are Fei-Fei Li"!!
I hope you find this demo exciting, further showing how to build with DSPy programs behind FastAPI backends that connect to React frontends, and ... ... Generative Feedback Loops with Weaviate! Saving and indexing these conversations back into the database!
I hope you will consider checking out the open-source repo and running it for yourself, more than happy to help debug / fix any issues if they arise!
2/3
RAG with Persona RAG with Persona
If you ask the same question to multiple people, there is a strong chance each person will have a different response. Here’s a new demo on RAG with Persona using DSPy, @cohere@cohere@cohere, and , and @weaviate_io@weaviate_io@weaviate_io!
When building or using chatbots, it’s important to get a…!
3/3
Haha I can finally chat with LeBron
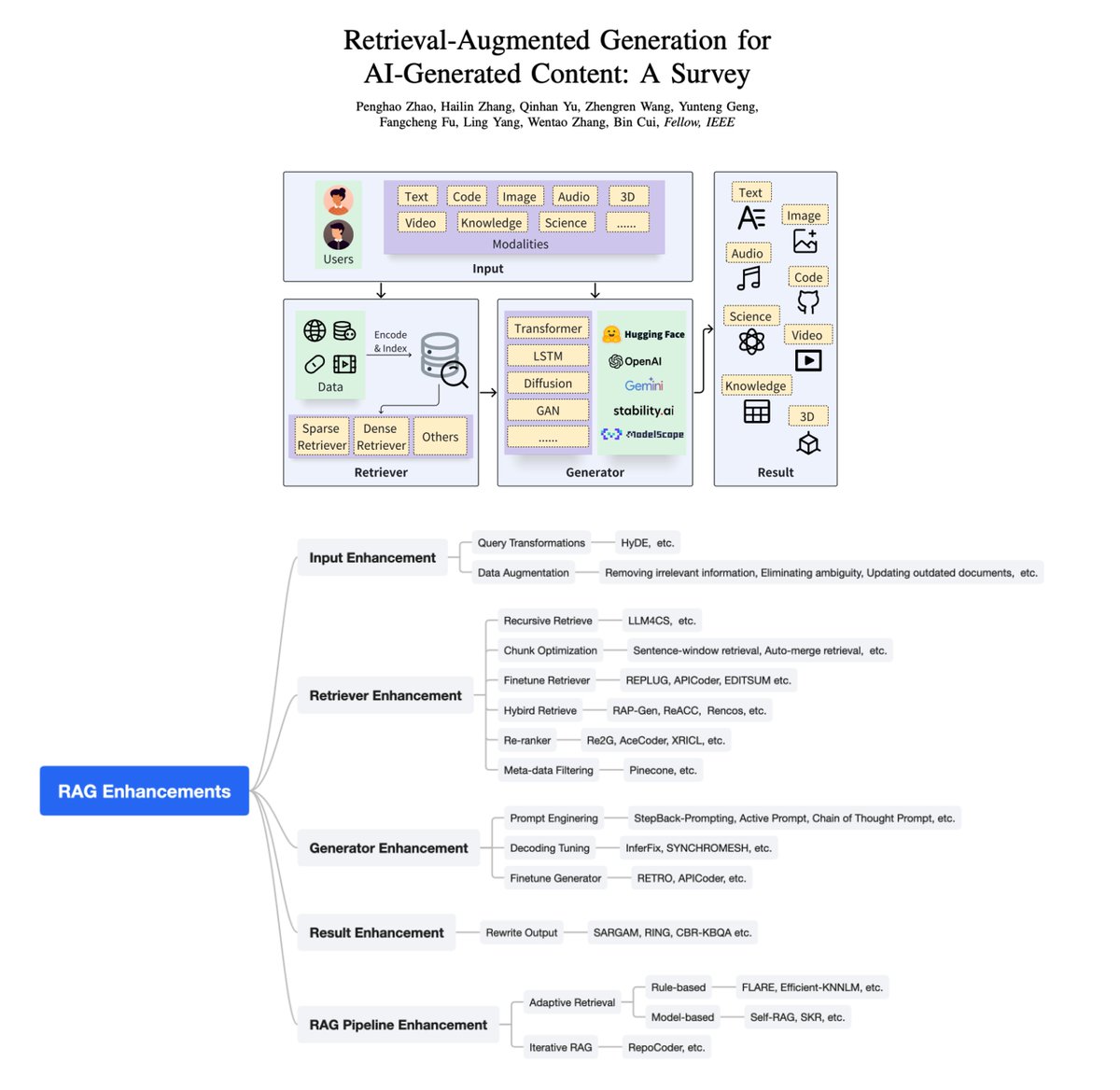
1/5
RAG with Persona RAG with Persona
If you ask the same question to multiple people, there is a strong chance each person will have a different response. Here’s a new demo on RAG with Persona using DSPy, @cohere@cohere, and , and @weaviate_io@weaviate_io!
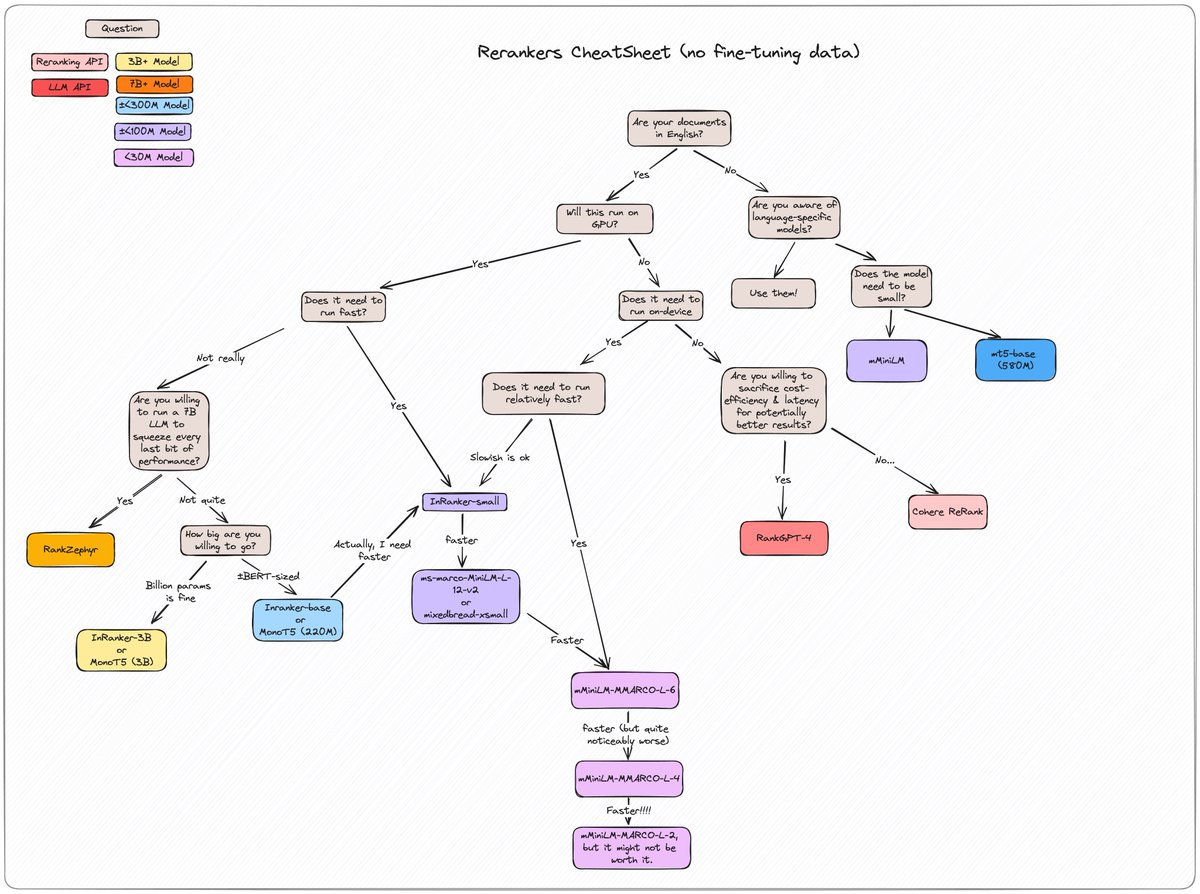
When building or using chatbots, it’s important to get a response from the right “person”. To do this, let’s build a compound AI system with the following stack:
1. DSPy: Build a framework for the chatbot
2. Cohere: Use the `command-nightly` LLM model
3. Weaviate: Store the responses back in the vector database
More details in the thread!!
2/5
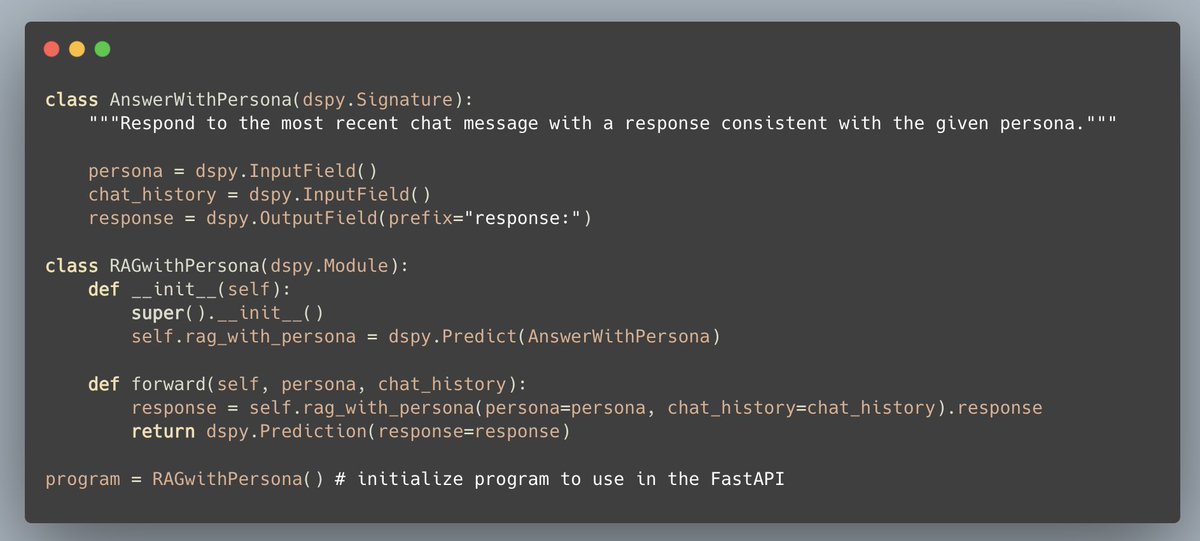
We will first build the `AnswerWithPersona`. The input to the language model is: 1. Peronsa, and 2. Chat history. The output is the response.
We'll then initialize and build the program.
3/5
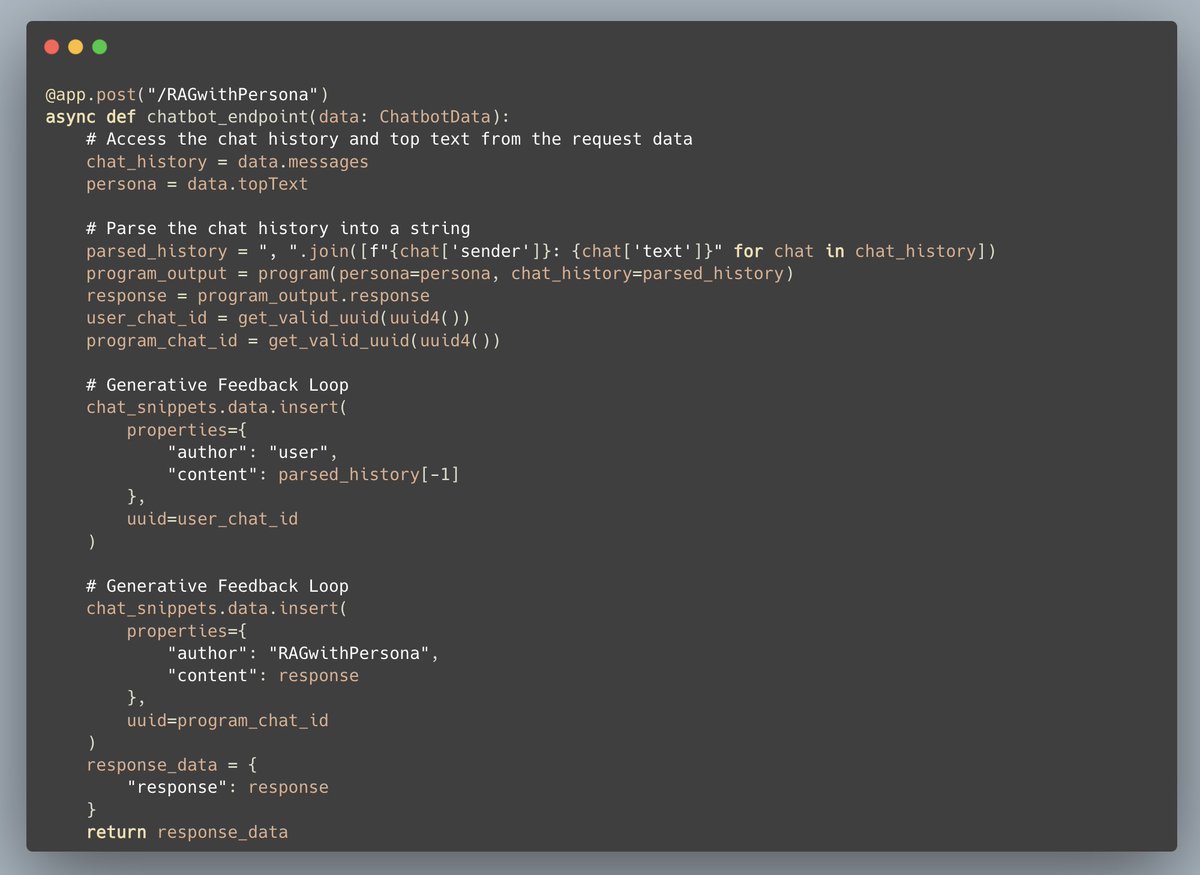
Connor (@CShorten30) did an awesome job by extending this notebook to interface the DSPy program with a FastAPI endpoint!
4/5
Now we can store our chat history in our vector database for future retrieval -- Generative Feedback Loops
5/5
Here is the demo
recipes/integrations/dspy/4.RAGwithPersona at main · weaviate/recipes
7/8
You got this, Clint. Each demo builds off of the other (kind of), I hope that helps!
8/8
I think your guest should add you as a persona to anticipate your questions
RAG with Persona RAG with Persona
If you ask the same question to multiple people, there is a strong chance each person will have a different response. Here’s a new demo on RAG with Persona using DSPy, @cohere@cohere, and , and @weaviate_io@weaviate_io!
When building or using chatbots, it’s important to get a response from the right “person”. To do this, let’s build a compound AI system with the following stack:
1. DSPy: Build a framework for the chatbot
2. Cohere: Use the `command-nightly` LLM model
3. Weaviate: Store the responses back in the vector database
More details in the thread!!
2/5
We will first build the `AnswerWithPersona`. The input to the language model is: 1. Peronsa, and 2. Chat history. The output is the response.
We'll then initialize and build the program.
3/5
Connor (@CShorten30) did an awesome job by extending this notebook to interface the DSPy program with a FastAPI endpoint!
4/5
Now we can store our chat history in our vector database for future retrieval -- Generative Feedback Loops
5/5
Here is the demo
recipes/integrations/dspy/4.RAGwithPersona at main · weaviate/recipes
7/8
You got this, Clint. Each demo builds off of the other (kind of), I hope that helps!
8/8
I think your guest should add you as a persona to anticipate your questions