1/3
Breaking!
Starling-LM-7B-beta
One of the absolute best 7B models for real day-to-day use (starling alpha) just got an upgrade.
I strongly advise to check it out, alpha is amazing
2/3
Breaking!
Starling-LM-7B-beta
One of the absolute best 7B models for real day-to-day use (starling alpha) just got an upgrade.
I strongly advise to check it out, alpha is amazing Breaking!
Starling-LM-7B-beta
One of the absolute best 7B models for real day-to-day use (starling alpha) just got an upgrade.
I strongly advise to check it out, alpha is amazing
3/3
Presenting Starling-LM-7B-beta, our cutting-edge 7B language model fine-tuned with RLHF!
Presenting Starling-LM-7B-beta, our cutting-edge 7B language model fine-tuned with RLHF!
Also introducing Starling-RM-34B, a Yi-34B-based reward model trained on our Nectar dataset, surpassing our previous 7B RM in all benchmarks.
Also introducing Starling-RM-34B, a Yi-34B-based reward model trained on our Nectar dataset, surpassing our previous 7B RM in all benchmarks.
We've fine-tuned the latest Openchat… We've fine-tuned the latest Openchat…
Breaking!
Starling-LM-7B-beta
One of the absolute best 7B models for real day-to-day use (starling alpha) just got an upgrade.
I strongly advise to check it out, alpha is amazing
2/3
Breaking!
Starling-LM-7B-beta
One of the absolute best 7B models for real day-to-day use (starling alpha) just got an upgrade.
I strongly advise to check it out, alpha is amazing Breaking!
Starling-LM-7B-beta
One of the absolute best 7B models for real day-to-day use (starling alpha) just got an upgrade.
I strongly advise to check it out, alpha is amazing
3/3
Presenting Starling-LM-7B-beta, our cutting-edge 7B language model fine-tuned with RLHF!
Presenting Starling-LM-7B-beta, our cutting-edge 7B language model fine-tuned with RLHF!
Also introducing Starling-RM-34B, a Yi-34B-based reward model trained on our Nectar dataset, surpassing our previous 7B RM in all benchmarks.
Also introducing Starling-RM-34B, a Yi-34B-based reward model trained on our Nectar dataset, surpassing our previous 7B RM in all benchmarks.
We've fine-tuned the latest Openchat… We've fine-tuned the latest Openchat…
1/6
 Presenting Starling-LM-7B-beta, our cutting-edge 7B language model fine-tuned with RLHF!
Presenting Starling-LM-7B-beta, our cutting-edge 7B language model fine-tuned with RLHF!
 Also introducing Starling-RM-34B, a Yi-34B-based reward model trained on our Nectar dataset, surpassing our previous 7B RM in all benchmarks.
Also introducing Starling-RM-34B, a Yi-34B-based reward model trained on our Nectar dataset, surpassing our previous 7B RM in all benchmarks.
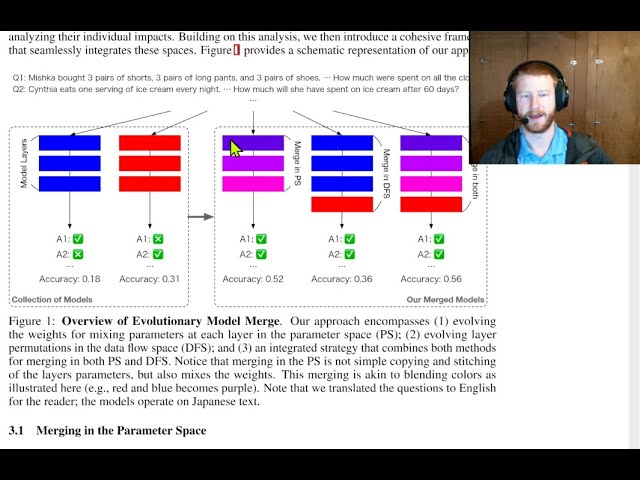
 We've fine-tuned the latest Openchat model with the 34B reward model, achieving MT Bench score of 8.12 while being much better at hard prompts compared to Starling-LM-7B-alpha in internal benchmarks. Testing will soon be available on
We've fine-tuned the latest Openchat model with the 34B reward model, achieving MT Bench score of 8.12 while being much better at hard prompts compared to Starling-LM-7B-alpha in internal benchmarks. Testing will soon be available on
@lmsysorg
. Please stay tuned!
 HuggingFace links:
HuggingFace links:
[Starling-LM-7B-beta]Nexusflow/Starling-LM-7B-beta · Hugging Face
[Starling-RM-34B]Nexusflow/Starling-RM-34B · Hugging Face
Discord Link:加入 Discord 服务器 Nexusflow!
Since the release of Starling-LM-7B-alpha, we've received numerous requests to make the model commercially viable. Therefore, we're licensing all models and datasets under Apache-2.0, with the condition that they are not used to compete with OpenAI. Enjoy!
2/6
3/6
Thank you! I guess larger model as RM naturally has some advantage. But you’ll see some rigorous answer very soon on twitter ;)
4/6
Yes, sorry we delayed that a bit since we are refactoring the code. But hopefully the code and paper will be out soon!
5/6
Yes, please stay tuned!
6/6
Thx! We were mainly looking at one (unreleased) benchmark which correlates very well with human evaluation, on which our beta version is much better than alpha. I probably cannot give away more spoilers but I believe the benchmark will be out soon!
Presenting Starling-LM-7B-beta, our cutting-edge 7B language model fine-tuned with RLHF! Also introducing Starling-RM-34B, a Yi-34B-based reward model trained on our Nectar dataset, surpassing our previous 7B RM in all benchmarks. We've fine-tuned the latest Openchat model with the 34B reward model, achieving MT Bench score of 8.12 while being much better at hard prompts compared to Starling-LM-7B-alpha in internal benchmarks. Testing will soon be available on @lmsysorg
. Please stay tuned!
HuggingFace links:[Starling-LM-7B-beta]Nexusflow/Starling-LM-7B-beta · Hugging Face
[Starling-RM-34B]Nexusflow/Starling-RM-34B · Hugging Face
Discord Link:加入 Discord 服务器 Nexusflow!
Since the release of Starling-LM-7B-alpha, we've received numerous requests to make the model commercially viable. Therefore, we're licensing all models and datasets under Apache-2.0, with the condition that they are not used to compete with OpenAI. Enjoy!
2/6
3/6
Thank you! I guess larger model as RM naturally has some advantage. But you’ll see some rigorous answer very soon on twitter ;)
4/6
Yes, sorry we delayed that a bit since we are refactoring the code. But hopefully the code and paper will be out soon!
5/6
Yes, please stay tuned!
6/6
Thx! We were mainly looking at one (unreleased) benchmark which correlates very well with human evaluation, on which our beta version is much better than alpha. I probably cannot give away more spoilers but I believe the benchmark will be out soon!
 Introducing Felix-8B: The Trustworthy Language Model by
Introducing Felix-8B: The Trustworthy Language Model by 






/cdn.vox-cdn.com/uploads/chorus_asset/file/25343229/STK083_NVIDIA_A.jpg)
:format(webp)/cdn.vox-cdn.com/uploads/chorus_asset/file/25343229/STK083_NVIDIA_A.jpg "Vector collage of the Ndivia logo.")