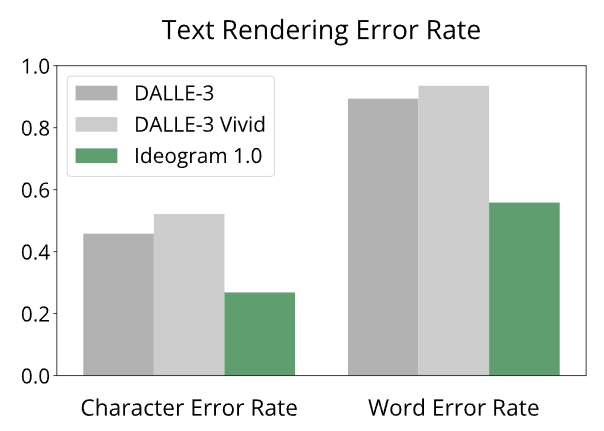
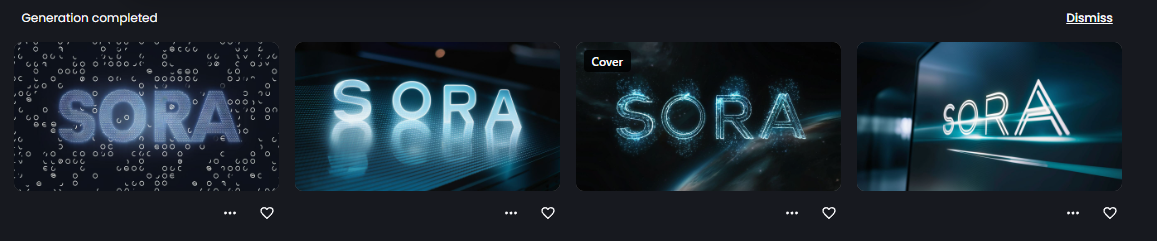
1/6
Differential Diffusion
Giving Each Pixel Its Strength
Text-based image editing has advanced significantly in recent years. With the rise of diffusion models, image editing via textual instructions has become ubiquitous.
2/6
Unfortunately, current models lack the ability to customize the quantity of the change per pixel or per image fragment, resorting to changing the entire image in an equal amount, or editing a specific region using a binary mask.
3/6
In this paper, we suggest a new framework which enables the user to customize the quantity of change for each image fragment, thereby enhancing the flexibility and verbosity of modern diffusion models.
4/6
Our framework does not require model training or fine-tuning, but instead performs everything at inference time, making it easily applicable to an existing model.
5/6
paper page:
6/6
Beyond Language Models
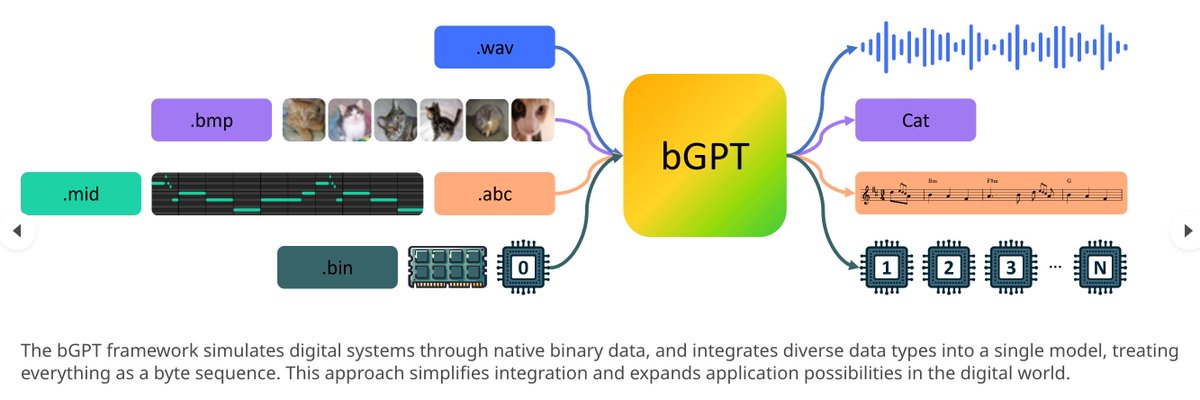
Byte Models are Digital World Simulators
Traditional deep learning often overlooks bytes, the basic units of the digital world, where all forms of information and operations are encoded and manipulated in binary format. Inspired by the success of next
Differential Diffusion
Giving Each Pixel Its Strength
Text-based image editing has advanced significantly in recent years. With the rise of diffusion models, image editing via textual instructions has become ubiquitous.
2/6
Unfortunately, current models lack the ability to customize the quantity of the change per pixel or per image fragment, resorting to changing the entire image in an equal amount, or editing a specific region using a binary mask.
3/6
In this paper, we suggest a new framework which enables the user to customize the quantity of change for each image fragment, thereby enhancing the flexibility and verbosity of modern diffusion models.
4/6
Our framework does not require model training or fine-tuning, but instead performs everything at inference time, making it easily applicable to an existing model.
5/6
paper page:
6/6
Beyond Language Models
Byte Models are Digital World Simulators
Traditional deep learning often overlooks bytes, the basic units of the digital world, where all forms of information and operations are encoded and manipulated in binary format. Inspired by the success of next