

Microsoft develops its own networking gear for AI datacenters: Report
Juniper Networks and Fungible founder spearheads development.
Microsoft develops its own networking gear for AI datacenters: Report
NewsBy Anton Shilov
published 1 day ago
Juniper Networks and Fungible founder spearheads development.

(Image credit: Shutterstock)
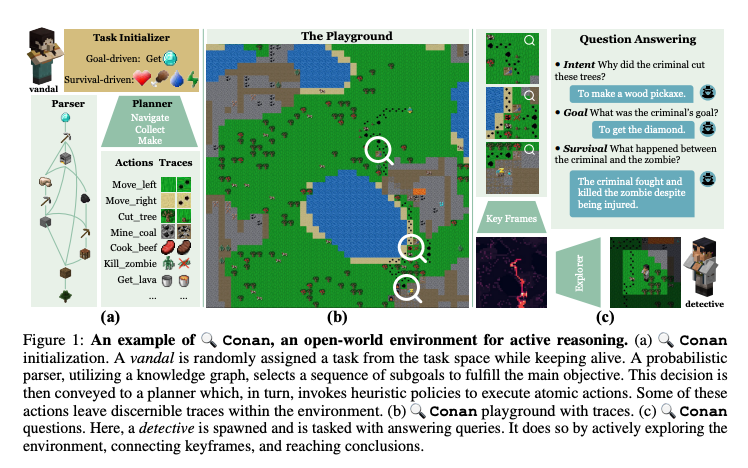
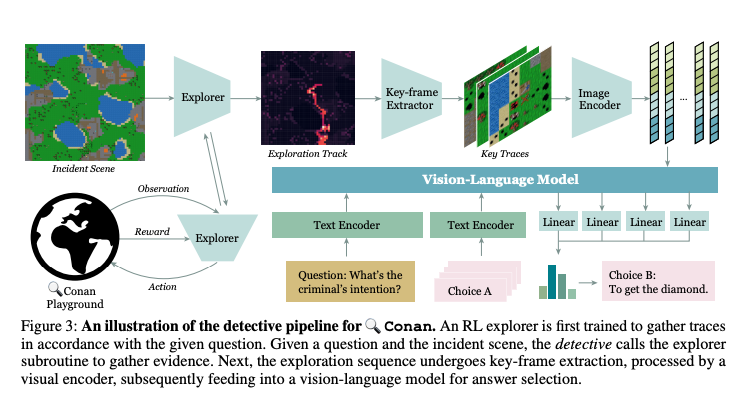
After revealing its own 128-core datacenter CPU and Maia 100 GPU for artificial intelligence workloads, Microsoft has begun development of its own networking card in a bid to decrease its reliance on Nvidia's hardware and speed up its datacenters, reports The Information. If the company succeeds, it could then proceed to optimize its Azure infrastructure and diversify its technology stack. Interestingly, the company has indirectly confirmed the effort.
Microsoft acquired Fungible, a developer of data processing units (DPUs) that competed against AMD's Pensando and Nvidia's Mellanox divisions, about a year ago. That means the company clearly has the networking technologies and IP that it needs to design datacenter-grade networking gear suitable for bandwidth-hungry AI training workloads. Pradeep Sindhu, a co-founder of Juniper Networks and founder of Fungible who has a wealth of experience in networking gear, now works at Microsoft and is heading the development of the company's datacenter networking processors.
The new networking card is expected to improve of the performance and efficiency of Microsoft's Azure servers, which currently run Intel CPUs and Nvidia GPUs, but will eventually also adopt Microsoft's own CPUs and GPUs. The Information claims that the project is important for Microsoft, which is why Satya Nadella, the head of the company, appointed Sindhu to the project himself.
"As part of our systems approach to Azure infrastructure, we are focused on optimizing every layer of our stack," a Microsoft spokesperson told The Information. "We routinely develop new technologies to meet the needs of our customers, including networking chips."
High-performance networking gear is crucial for datacenters, especially when handling the massive amount of data required for AI training by clients like OpenAI. By alleviating network traffic jams, the new server component could accelerate the development of AI models, making the process faster and more cost-effective.
Microsoft's move is in line with the industry trend toward custom silicon, as other cloud providers including Amazon Web Services (AWS) and Google are also developing their own AI and general-purpose processors and datacenter networking gear.
The introduction of Microsoft's networking card could potentially impact Nvidia's sales of server networking gear, which is projected to generate over $10 billion per year. If successful, the card could significantly improve the efficiency of Azure datacenters in general and OpenAI's model training in particular, as well as reduce the time and costs associated with AI development, the report claims.
Custom silicon can take a significant amount of time to design and manufacture, which means the initial results of this endeavor could still be years away. In the short term, Microsoft will continue to rely on hardware from other vendors, but that may change in the coming years.


















 Introducing ToDo : Token Downsampling for Efficient Generation of High-Resolution Images ! With
Introducing ToDo : Token Downsampling for Efficient Generation of High-Resolution Images ! With 