
You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
Large Language Models News & Discussions
- Thread starter Macallik86
- Start date
More options
Who Replied?Two weeks ago we released Smaug-72B - which topped the Hugging Face LLM leaderboard and it’s the first model with an average score of 80, making it the world’s best open-source foundation model.
We applied several techniques on a fine tune derived from a Qwen-72B for this model.
Our next step is to publish these techniques as a research paper and apply them to some of the best Mistral Models, including 70b fine-tuned LLama-2, miqu. Our techniques targeted reasoning and math skills, hence the high GSM8K scores.
We’ll be releasing a paper on our methodologies soon. In the meantime, you can download the weights, and try it yourself.
Our world-class research and engineering team will continue to innovate in this space, and keep developing towards open-source AGI
I see some vocal objections: "Sora is not learning physics, it's just manipulating pixels in 2D".
I respectfully disagree with this reductionist view. It's similar to saying "GPT-4 doesn't learn coding, it's just sampling strings". Well, what transformers do is just manipulating a sequence of integers (token IDs). What neural networks do is just manipulating floating numbers. That's not the right argument.
Sora's soft physics simulation is an *emergent property* as you scale up text2video training massively.
- GPT-4 must learn some form of syntax, semantics, and data structures internally in order to generate executable Python code. GPT-4 does not store Python syntax trees explicitly.
- Very similarly, Sora must learn some *implicit* forms of text-to-3D, 3D transformations, ray-traced rendering, and physical rules in order to model the video pixels as accurately as possible. It has to learn concepts of a game engine to satisfy the objective.
- If we don't consider interactions, UE5 is a (very sophisticated) process that generates video pixels. Sora is also a process that generates video pixels, but based on end-to-end transformers. They are on the same level of abstraction.
- The difference is that UE5 is hand-crafted and precise, but Sora is purely learned through data and "intuitive".
Will Sora replace game engine devs? Absolutely not. Its emergent physics understanding is fragile and far from perfect. It still heavily hallucinates things that are incompatible with our physical common sense. It does not yet have a good grasp of object interactions - see the uncanny mistake in the video below.
Sora is the GPT-3 moment. Back in 2020, GPT-3 was a pretty bad model that required heavy prompt engineering and babysitting. But it was the first compelling demonstration of in-context learning as an emergent property.
Don't fixate on the imperfections of GPT-3. Think about extrapolations to GPT-4 in the near future.

Google’s AI Boss Says Scale Only Gets You So Far
In an interview with WIRED, DeepMind CEO Demis Hassabis says the biggest breakthroughs in AI are yet to come—and will take more than just chips.
WILL KNIGHT
BUSINESS
FEB 19, 2024 8:00 AM
Google’s AI Boss Says Scale Only Gets You So Far
In an interview with WIRED, DeepMind CEO Demis Hassabis says the biggest breakthroughs in AI are yet to come—and will take more than just chips.
Demis Hassabis at the Wall Street Journal's Future of Everything Festival in May 2023.PHOTOGRAPH: JOY MALONE/GETTY IMAGES
For much of last year, knocking OpenAI off its perch atop the tech industry looked all but impossible, as the company rode a riot of excitement and hype generated by a remarkable, garrulous, and occasionally unhinged program called ChatGPT.
Google DeepMind CEO Demis Hassabis has recently at least given Sam Altman some healthy competition, leading the development and deployment of an AI model that appears both as capable and as innovative as the one that powers OpenAI’s barnstorming bot.
Ever since Alphabet forged DeepMind by merging two of its AI-focused divisions last April, Hassabis has been responsible for corralling its scientists and engineers in order to counter both OpenAI’s remarkable rise and its collaboration with Microsoft, seen as a potential threat to Alphabet’s cash-cow search business.
Google researchers came up with several of the ideas that went into building ChatGPT, yet the company chose not to commercialize them due to misgivings about how they might misbehave or be misused. In recent months, Hassabis has overseen a dramatic shift in pace of research and releases with the rapid development of Gemini, a ”multimodal” AI model that already powers Google’s answer to ChatGPT and a growing number of Google products. Last week, just two months after Gemini was revealed, the company announced a quick-fire upgrade to the free version of the model, Gemini Pro 1.5, that is more powerful for its size and can analyze vast amounts of text, video, and audio at a time.
A similar boost to Alphabet’s most capable model, Gemini Ultra, would help give OpenAI another shove as companies race to develop and deliver ever more powerful and useful AI systems.
Hassabis spoke to WIRED senior writer Will Knight over Zoom from his home in London. This interview has been lightly edited for length and clarity.
WIRED: Gemini Pro 1.5 can take vastly more data as an input than its predecessor. It is also more powerful, for its size, thanks to an architecture called mixture of experts. What do these things matter?
Demis Hassabis: You can now ingest a reasonable-sized short film. I can imagine that being super useful if there's a topic you're learning about and there's a one-hour lecture, and you want to find a particular fact or when they did something. I think there's going to be a lot of really cool use cases for that.
We invented mixture of experts—[Google DeepMind chief scientist] Jeff Dean did that—and we developed a new version. This new Pro version of Gemini, it’s not been tested extensively, but it has roughly the same performance as the largest of the previous generation of architecture. There’s nothing limiting us creating an Ultra-sized model with these innovations, and obviously that’s something we're working on.
In the last few years, increasing the amount of computer power and data used in training an AI model is the thing that has driven amazing advances. Sam Altman is said to be looking to raise up to $7 trillion for more AI chips. Is vastly more computer power the thing that will unlock artificial general intelligence?
Was that a misquote? I heard someone say that maybe it was yen or something. Well, look, you do need scale; that's why Nvidia is worth what it is today. That’s why Sam is trying to raise whatever the real number is. But I think we're a little bit different to a lot of these other organizations in that we've always been fundamental research first. At Google Research and Brain and DeepMind, we've invented the majority of machine learning techniques we're all using today, over the last 10 years of pioneering work. So that’s always been in our DNA, and we have quite a lot of senior research scientists that maybe other orgs don't have. These other startups and even big companies have a high proportion of engineering to research science.
Are you saying this won’t be the only way that AI advances from here on?
My belief is, to get to AGI, you’re going to need probably several more innovations as well as the maximum scale. There’s no let up in the scaling, we're not seeing an asymptote or anything. There are still gains to be made. So my view is you've got to push the existing techniques to see how far they go, but you’re not going to get new capabilities like planning or tool use or agent-like behavior just by scaling existing techniques. It’s not magically going to happen.
The other thing you need to explore is compute itself. Ideally you’d love to experiment on toy problems that take you a few days to train, but often you'll find that things that work at a toy scale don't hold at the mega scale. So there's some sort of sweet spot where you can extrapolate maybe 10X in size.
Does that mean that the competition between AI companies going forward will increasingly be around tool use and agents—AI that does things rather than just chats? OpenAI is reportedly working on this.
Probably. We’ve been on that track for a long time; that’s our bread and butter really, agents, reinforcement learning, and planning, since the AlphaGo days. [In 2016 DeepMind developed a breakthrough algorithm capable of solving complex problems and playing sophisticated games.] We’re dusting off a lot of ideas, thinking of some kind of combination of AlphaGo capabilities built on top of these large models. Introspection and planning capabilities will help with things like hallucination, I think.
It's sort of funny, if you say “Take more care” or “Line out your reasoning,” sometimes the model does better. What's going on there is you are priming it to sort of be a little bit more logical about its steps. But you'd rather that be a systematic thing that the system is doing.
This definitely is a huge area. We're investing a lot of time and energy into that area, and we think that it will be a step change in capabilities of these types of systems—when they start becoming more agent-like. We’re investing heavily in that direction, and I imagine others are as well.
Won’t this also make AI models more problematic or potentially dangerous?
I've always said in safety forums and conferences that it is a big step change. Once we get agent-like systems working, AI will feel very different to current systems, which are basically passive Q&A systems, because they’ll suddenly become active learners. Of course, they'll be more useful as well, because they'll be able to do tasks for you, actually accomplish them. But we will have to be a lot more careful.
I've always advocated for hardened simulation sandboxes to test agents in before we put them out on the web. There are many other proposals, but I think the industry should start really thinking about the advent of those systems. Maybe it’s going to be a couple of years, maybe sooner. But it’s a different class of systems.
You previously said that it took longer to test your most powerful model, Gemini Ultra. Is that just because of the speed of development, or was it because the model was actually more problematic?
It was both actually. The bigger the model, first of all, some things are more complicated to do when you fine-tune it, so it takes longer. Bigger models also have more capabilities you need to test.
Hopefully what you are noticing as Google DeepMind is settling down as a single org is that we release things early and ship things experimentally on to a small number of people, see what our trusted early testers are going to tell us, and then we can modify things before general release.
Speaking of safety, how are discussions with government organizations like the UK AI Safety Institute progressing?
It’s going well. I'm not sure what I'm allowed to say, as it's all kind of confidential, but of course they have access to our frontier models, and they were testing Ultra, and we continue to work closely with them. I think the US equivalent is being set up now. Those are good outcomes from the Bletchly Park AI Safety Summit. They can check things that we don’t have security clearance to check—CBRN [chemical, biological, radiological, and nuclear weapons] things.
These current systems, I don't think they are really powerful enough yet to do anything materially sort of worrying. But it's good to build that muscle up now on all sides, the government side, the industry side, and academia. And I think probably that agent systems will be the next big step change. We'll see incremental improvements along the way, and there may be some cool, big improvements, but that will feel different.
OpenVoice: Versatile Instant Voice Cloning
We introduce OpenVoice, a versatile voice cloning approach that requires only a short audio clip from the reference speaker to replicate their voice and generate speech in multiple languages. OpenVoice represents a significant advancement in addressing the following open challenges in the field...
Computer Science > Sound
[Submitted on 3 Dec 2023 (v1), last revised 2 Jan 2024 (this version, v5)]OpenVoice: Versatile Instant Voice Cloning
Zengyi Qin, Wenliang Zhao, Xumin Yu, Xin SunWe introduce OpenVoice, a versatile voice cloning approach that requires only a short audio clip from the reference speaker to replicate their voice and generate speech in multiple languages. OpenVoice represents a significant advancement in addressing the following open challenges in the field: 1) Flexible Voice Style Control. OpenVoice enables granular control over voice styles, including emotion, accent, rhythm, pauses, and intonation, in addition to replicating the tone color of the reference speaker. The voice styles are not directly copied from and constrained by the style of the reference speaker. Previous approaches lacked the ability to flexibly manipulate voice styles after cloning. 2) Zero-Shot Cross-Lingual Voice Cloning. OpenVoice achieves zero-shot cross-lingual voice cloning for languages not included in the massive-speaker training set. Unlike previous approaches, which typically require extensive massive-speaker multi-lingual (MSML) dataset for all languages, OpenVoice can clone voices into a new language without any massive-speaker training data for that language. OpenVoice is also computationally efficient, costing tens of times less than commercially available APIs that offer even inferior performance. To foster further research in the field, we have made the source code and trained model publicly accessible. We also provide qualitative results in our demo website. Prior to its public release, our internal version of OpenVoice was used tens of millions of times by users worldwide between May and October 2023, serving as the backend of MyShell.
| Comments: | Technical Report |
| Subjects: | Sound (cs.SD); Machine Learning (cs.LG); Audio and Speech Processing (eess.AS) |
| Cite as: | arXiv:2312.01479 [cs.SD] |
| (or arXiv:2312.01479v5 [cs.SD] for this version) | |
| [2312.01479] OpenVoice: Versatile Instant Voice Cloning Focus to learn more |
Submission history
From: Zengyi Qin [view email][v1] Sun, 3 Dec 2023 18:41:54 UTC (109 KB)
[v2] Wed, 13 Dec 2023 02:25:42 UTC (110 KB)
[v3] Sat, 16 Dec 2023 17:22:45 UTC (234 KB)
[v4] Thu, 21 Dec 2023 22:56:45 UTC (234 KB)
[v5] Tue, 2 Jan 2024 17:45:43 UTC (234 KB)
GitHub - myshell-ai/OpenVoice: Instant voice cloning by MIT and MyShell. Audio foundation model.
Instant voice cloning by MIT and MyShell. Audio foundation model. - myshell-ai/OpenVoice
 github.com
github.com
OpenVoice: Versatile Instant Voice Cloning | MyShell AI
Discover OpenVoice: Instant voice cloning technology that replicates voices from short audio clips. Supports multiple languages, emotion and accent control, and cross-lingual cloning. Efficient and cost-effective, outperforming commercial APIs. Explore the future of AI voice synthesis.

Pinokio: The 1-Click Localhost Cloud
Run your own personal Internet on Mac, Windows, and Linux with one click.
Last edited:
I showed Gemini 1.5 Pro the ENTIRE Self-Operating Computer codebase, and an example Gemini 1.5 API call.
From there, it was able to perfectly explain how the codebase works...
and then it implemented itself as a new supported model for the repo!
Not perfect, but very close.




Gemini 1.5 pro is STILL under hyped
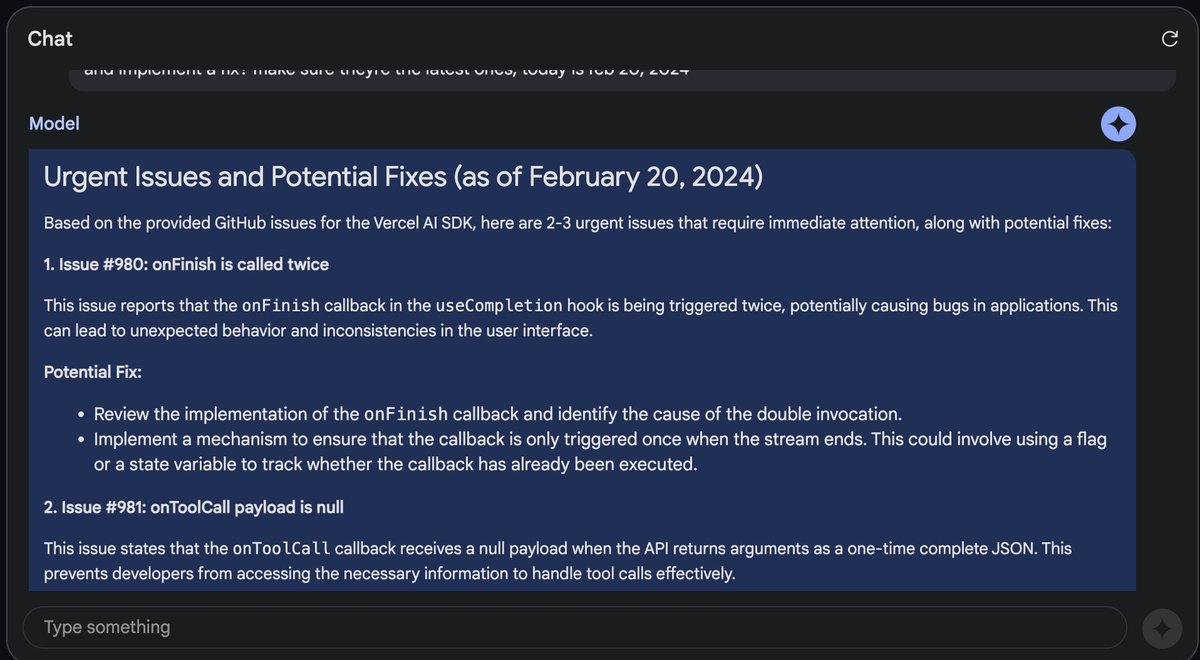
I uploaded an entire codebase directly from github, AND all of the issues (
@vercel
ai sdk,)
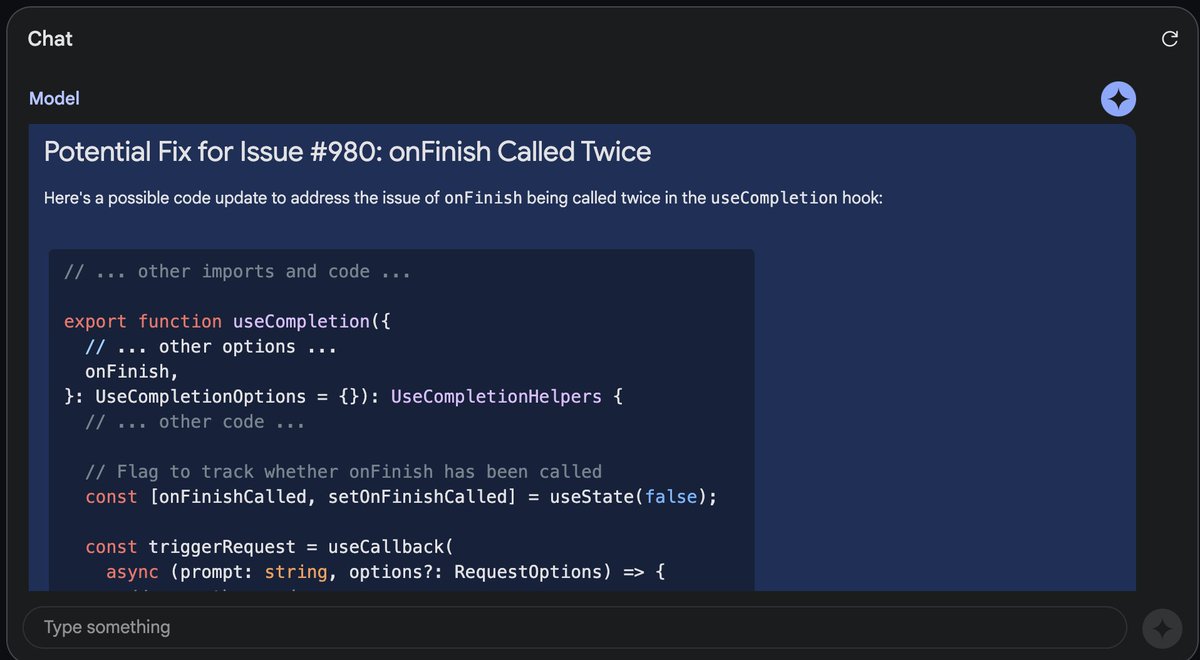
Not only was it able to understand the entire codebase, it identified the most urgent issue, and IMPLEMENTED a fix.
This changes everything
I uploaded an entire codebase directly from github, AND all of the issues (
@vercel
ai sdk,)
Not only was it able to understand the entire codebase, it identified the most urgent issue, and IMPLEMENTED a fix.
This changes everything

Stable Cascade: A New Image Generation Model by Stability AI - HyScaler
Stable Cascade is a new image generation model by Stability AI that promises to be faster and more powerful than its predecessor, Stable Diffusion.
 hyscaler.com
hyscaler.com
Stable Cascade: A New Image Generation Model by Stability AI
Feb 14th 2024Table of Contents
- What is Stable Cascade and how does it work?
- Where can I find Stable Cascade and what can I do with it?
- What are the challenges and opportunities for Stable Cascade and Stability AI?
Stability AI, a leading company in the field of text-to-image generation, has recently released a new model called Stable Cascade. This model claims to offer better performance and more features than its previous model, Stable Diffusion, which is widely used by other AI tools for creating images from text.
What is Stable Cascade and how does it work?
Stable Cascade is a text-to-image generation model that can produce realistic and diverse images from natural language prompts. It can also perform various image editing tasks, such as increasing the resolution of an existing image, modifying a specific part of an image, or creating a new image from the edges of another image.
Unlike Stable Diffusion, which is a single large language model, Stable Cascade consists of three smaller models that work together using the Würstchen architecture. The first model, stage C, compresses the text prompt into a latent code, which is a compact representation of the desired image.
The second model, stage A, decodes the latent code into a low-resolution image. The third model, stage B, refines the low-resolution image into a high-resolution image.
By splitting the text-to-image generation process into three stages, Stable Cascade reduces the memory and computational requirements and speeds up the image creation time. According to Stability AI, Stable Cascade can generate an image in about 10 seconds, compared to 22 seconds for the SDXL model, which is the largest version of Stable Diffusion.
Moreover, Stable Cascade also improves the quality and diversity of the generated images, as it can better align the image with the text prompt and produce more variations of the same image.
Where can I find Stable Cascade and what can I do with it?
Stable Cascade is currently available on GitHub for research purposes only, and not for commercial use. Stability AI has provided a Colab notebook that demonstrates how to use Stable Cascade for various image generation and editing tasks. You can also explore some examples of images generated by Stable Cascade on their website.Stable Cascade is a versatile model that can be used for various applications, such as content creation, design, education, entertainment, and more. For instance, you can use Stable Cascade to generate images of fictional characters, landscapes, animals, logos, or anything else you can describe with text.
You can also use Stable Cascade to enhance or modify existing images, such as increasing their resolution, changing their style, adding or removing objects, or creating new images from their edges.
What are the challenges and opportunities for Stable Cascade and Stability AI?
Stable Cascade is a remarkable achievement by Stability AI, as it shows the potential of text-to-image generation models to create realistic and diverse images from natural language. However, Stable Cascade also faces some challenges and limitations, such as the quality and availability of the training data, the ethical and legal implications of generating images, and the competition from other companies and models.Stability AI has been at the forefront of text-to-image generation research, as it pioneered the stable diffusion method, which is a novel technique for training generative models. However, Stability AI has also been involved in several lawsuits, accusing it of using copyrighted data without permission from the owners.

For example, Getty Images, a stock photo agency, has filed a lawsuit against Stability AI in the UK, alleging that Stability AI used millions of Getty Images’ photos to train Stable Diffusion. The trial is expected to take place in December.
Stability AI has also faced criticism for its pricing and licensing policies, as it charges a subscription fee for commercial use of its models, which some users and developers have found to be too expensive or restrictive. Stability AI has defended its decision, saying that it needs to generate revenue to support its research and development.
Stability AI is not the only company that is working on text-to-image generation models, as other tech giants like Google and Apple have also released their own models, such as DALL-E and iGPT. These models use different approaches and architectures, such as transformers and autoregressive models, to generate images from text.
These models also offer impressive results and features, such as generating images from multiple text prompts or generating text from images.
Therefore, Stability AI will have to face the challenge of competing with these models, as well as keeping up with the rapid advances and innovations in the field of text-to-image generation. However, Stability AI also has the opportunity to collaborate with other researchers and developers, and to leverage its expertise and experience in the stable diffusion method, to create more powerful and useful models for image generation and editing.
/cdn.vox-cdn.com/uploads/chorus_asset/file/25296232/gemma_promo_press.png)
Google Gemma: because Google doesn’t want to give away Gemini yet
Gemma could be faster and more cost-efficient.
Google Gemma: because Google doesn’t want to give away Gemini yet
Gemma 2B and Gemma 7B are smaller open-source AI models for language tasks in English.
By Emilia David, a reporter who covers AI. Prior to joining The Verge, she covered the intersection between technology, finance, and the economy.
Feb 21, 2024, 8:00 AM EST
:format(webp)/cdn.vox-cdn.com/uploads/chorus_asset/file/25296232/gemma_promo_press.png "Gemma logo")
:format(webp)/cdn.vox-cdn.com/uploads/chorus_asset/file/25296232/gemma_promo_press.png)
Google’s new model Gemma.
Image: Google
Google has released Gemma 2B and 7B, a pair of open-source AI models that let developers use the research that went into its flagship Gemini more freely. While Gemini is a big closed AI model that directly competes with (and is nearly as powerful as) OpenAI’s ChatGPT, the lightweight Gemma will likely be suitable for smaller tasks like simple chatbots or summarizations.
But what these models lack in complication, they may make up for in speed and cost of use. Despite their smaller size, Google claims Gemma models “surpass significantly larger models on key benchmarks” and are “capable of running directly on a developer laptop or desktop computer.” They will be available via Kaggle, Hugging Face, Nvidia’s NeMo, and Google’s Vertex AI.
Gemma’s release into the open-source ecosystem is starkly different from how Gemini was released. While developers can build on Gemini, they do that either through APIs or by working on Google’s Vertex AI platform. Gemini is considered a closed AI model. By making Gemma open source, more people can experiment with Google’s AI rather than turn to competitors that offer better access.
Both model sizes will be available with a commercial license regardless of organization size, number of users, and the type of project. However, Google — like other companies — often prohibits its models from being used for specific tasks such as weapons development programs.
Gemma will also ship with “responsible AI toolkits,” as open models can be harder to place guardrails in than more closed systems like Gemini. Tris Warkentin, product management director at Google DeepMind, said the company undertook “more extensive red-teaming to Gemma because of the inherent risks involved with open models.”
The responsible AI toolkit will allow developers to create their own guidelines or a banned word list when deploying Gemma to their projects. It also includes a model debugging tool that lets users investigate Gemma’s behavior and correct issues.
The models work best for language-related tasks in English for now, according to Warkentin. “We hope we can build with the community to address market needs outside of English-language tasks,” he told reporters.
Developers can use Gemma for free in Kaggle, and first-time Google Cloud users get $300 in credits to use the models. The company said researchers can apply for up to $500,000 in cloud credits.
While it’s not clear how much of a demand there is for smaller models like Gemma, other AI companies have released lighter-weight versions of their flagship foundation models, too. Meta put out Llama 2 7B, the smallest iteration of Llama 2, last year. Gemini itself comes in several weights, including Gemini Nano, Gemini Pro, and Gemini Ultra, and Google recently announced a faster Gemini 1.5 — again, for business users and developers for now.
Gemma, by the way, means precious stone.

Gemma: Introducing new state-of-the-art open models
Gemma is a family of lightweight, state\u002Dof\u002Dthe art open models built from the same research and technology used to create the Gemini models.
Gemma: Introducing new state-of-the-art open models
Feb 21, 2024
3 min read
Gemma is built for responsible AI development from the same research and technology used to create Gemini models.
Jeanine Banks
VP & GM, Developer X and DevRel
Tris Warkentin
Director, Google DeepMind

Listen to article7 minutes
At Google, we believe in making AI helpful for everyone. We have a long history of contributing innovations to the open community, such as with Transformers, TensorFlow, BERT, T5, JAX, AlphaFold, and AlphaCode. Today, we’re excited to introduce a new generation of open models from Google to assist developers and researchers in building AI responsibly.
Gemma open models
Gemma is a family of lightweight, state-of-the-art open models built from the same research and technology used to create the Gemini models. Developed by Google DeepMind and other teams across Google, Gemma is inspired by Gemini, and the name reflects the Latin gemma, meaning “precious stone.” Accompanying our model weights, we’re also releasing tools to support developer innovation, foster collaboration, and guide responsible use of Gemma models.Gemma is available worldwide, starting today. Here are the key details to know:
- We’re releasing model weights in two sizes: Gemma 2B and Gemma 7B. Each size is released with pre-trained and instruction-tuned variants.
- A new Responsible Generative AI Toolkit provides guidance and essential tools for creating safer AI applications with Gemma.
- We’re providing toolchains for inference and supervised fine-tuning (SFT) across all major frameworks: JAX, PyTorch, and TensorFlow through native Keras 3.0.
- Ready-to-use Colab and Kaggle notebooks, alongside integration with popular tools such as Hugging Face, MaxText, NVIDIA NeMo and TensorRT-LLM, make it easy to get started with Gemma.
- Pre-trained and instruction-tuned Gemma models can run on your laptop, workstation, or Google Cloud with easy deployment on Vertex AI and Google Kubernetes Engine (GKE).
- Optimization across multiple AI hardware platforms ensures industry-leading performance, including NVIDIA GPUs and Google Cloud TPUs.
- Terms of use permit responsible commercial usage and distribution for all organizations, regardless of size.
State-of-the-art performance at size
Gemma models share technical and infrastructure components with Gemini, our largest and most capable AI model widely available today. This enables Gemma 2B and 7B to achieve best-in-class performance for their sizes compared to other open models. And Gemma models are capable of running directly on a developer laptop or desktop computer. Notably, Gemma surpasses significantly larger models on key benchmarks while adhering to our rigorous standards for safe and responsible outputs. See the technical report for details on performance, dataset composition, and modeling methodologies.
Responsible by design
Gemma is designed with our AI Principles at the forefront. As part of making Gemma pre-trained models safe and reliable, we used automated techniques to filter out certain personal information and other sensitive data from training sets. Additionally, we used extensive fine-tuning and reinforcement learning from human feedback (RLHF) to align our instruction-tuned models with responsible behaviors. To understand and reduce the risk profile for Gemma models, we conducted robust evaluations including manual red-teaming, automated adversarial testing, and assessments of model capabilities for dangerous activities. These evaluations are outlined in our Model Card.1
We’re also releasing a new Responsible Generative AI Toolkit together with Gemma to help developers and researchers prioritize building safe and responsible AI applications. The toolkit includes:
- Safety classification: We provide a novel methodology for building robust safety classifiers with minimal examples.
- Debugging: A model debugging tool helps you investigate Gemma's behavior and address potential issues.
- Guidance: You can access best practices for model builders based on Google’s experience in developing and deploying large language models.
Optimized across frameworks, tools and hardware
You can fine-tune Gemma models on your own data to adapt to specific application needs, such as summarization or retrieval-augmented generation (RAG). Gemma supports a wide variety of tools and systems:- Multi-framework tools: Bring your favorite framework, with reference implementations for inference and fine-tuning across multi-framework Keras 3.0, native PyTorch, JAX, and Hugging Face Transformers.
- Cross-device compatibility: Gemma models run across popular device types, including laptop, desktop, IoT, mobile and cloud, enabling broadly accessible AI capabilities.
- Cutting-edge hardware platforms: We’ve partnered with NVIDIA to optimize Gemma for NVIDIA GPUs, from data center to the cloud to local RTX AI PCs, ensuring industry-leading performance and integration with cutting-edge technology.
- Optimized for Google Cloud: Vertex AI provides a broad MLOps toolset with a range of tuning options and one-click deployment using built-in inference optimizations. Advanced customization is available with fully-managed Vertex AI tools or with self-managed GKE, including deployment to cost-efficient infrastructure across GPU, TPU, and CPU from either platform.
Free credits for research and development
Gemma is built for the open community of developers and researchers powering AI innovation. You can start working with Gemma today using free access in Kaggle, a free tier for Colab notebooks, and $300 in credits for first-time Google Cloud users. Researchers can also apply for Google Cloud credits of up to $500,000 to accelerate their projects.Getting started
You can explore more about Gemma and access quickstart guides on ai.google.dev/gemma.As we continue to expand the Gemma model family, we look forward to introducing new variants for diverse applications. Stay tuned for events and opportunities in the coming weeks to connect, learn and build with Gemma.
We’re excited to see what you create!

Computer Science > Computation and Language
[Submitted on 15 Feb 2024]Data Engineering for Scaling Language Models to 128K Context
Yao Fu, Rameswar Panda, Xinyao Niu, Xiang Yue, Hannaneh Hajishirzi, Yoon Kim, Hao PengWe study the continual pretraining recipe for scaling language models' context lengths to 128K, with a focus on data engineering. We hypothesize that long context modeling, in particular \textit{the ability to utilize information at arbitrary input locations}, is a capability that is mostly already acquired through large-scale pretraining, and that this capability can be readily extended to contexts substantially longer than seen during training~(e.g., 4K to 128K) through lightweight continual pretraining on appropriate data mixture. We investigate the \textit{quantity} and \textit{quality} of the data for continual pretraining: (1) for quantity, we show that 500 million to 5 billion tokens are enough to enable the model to retrieve information anywhere within the 128K context; (2) for quality, our results equally emphasize \textit{domain balance} and \textit{length upsampling}. Concretely, we find that naively upsampling longer data on certain domains like books, a common practice of existing work, gives suboptimal performance, and that a balanced domain mixture is important. We demonstrate that continual pretraining of the full model on 1B-5B tokens of such data is an effective and affordable strategy for scaling the context length of language models to 128K. Our recipe outperforms strong open-source long-context models and closes the gap to frontier models like GPT-4 128K.
| Comments: | Code at this https URL |
| Subjects: | Computation and Language (cs.CL); Artificial Intelligence (cs.AI) |
| Cite as: | arXiv:2402.10171 [cs.CL] |
| (or arXiv:2402.10171v1 [cs.CL] for this version) | |
| [2402.10171] Data Engineering for Scaling Language Models to 128K Context Focus to learn more |
Submission history
From: Yao Fu [view email][v1] Thu, 15 Feb 2024 18:19:16 UTC (1,657 KB)
GitHub - FranxYao/Long-Context-Data-Engineering: Implementation of paper Data Engineering for Scaling Language Models to 128K Context
Implementation of paper Data Engineering for Scaling Language Models to 128K Context - FranxYao/Long-Context-Data-Engineering
github.com
About
Implementation of paper Data Engineering for Scaling Language Models to 128K Context
Text-to-Image with SDXL Lightning 
This demo utilizes the SDXL-Lightning model by ByteDance, which is a fast text-to-image generative model capable of producing high-quality images in 4 steps. As a community effort, this demo was put together by AngryPenguin. Link to model: https://huggingface.co/ByteDance/SDXL-Lightning

ByteDance/SDXL-Lightning · Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co
text said:Mind officially blown:
I recorded a screen capture of a task (looking for an apartment on Zillow). Gemini was able to generate Selenium code to replicate that task, and described everything I did step-by-step.
It even caught that my threshold was set to $3K, even though I didn't explicitly select it.
"This code will open a Chrome browser, navigate to Zillow, enter "Cupertino, CA" in the search bar, click on the "For Rent" tab, set the price range to "Up to $3K", set the number of bedrooms to "2+", select the "Apartments/Condos/Co-ops" checkbox, click on the "Apply" button, wait for the results to load, print the results, and close the browser."



Stable Diffusion 3 — Stability AI
Announcing Stable Diffusion 3 in early preview, our most capable text-to-image model with greatly improved performance in multi-subject prompts, image quality, and spelling abilities.
 stability.ai
stability.ai
Stable Diffusion 3
22 Feb
Prompt: Epic anime artwork of a wizard atop a mountain at night casting a cosmic spell into the dark sky that says "Stable Diffusion 3" made out of colorful energy
Announcing Stable Diffusion 3 in early preview, our most capable text-to-image model with greatly improved performance in multi-subject prompts, image quality, and spelling abilities.
While the model is not yet broadly available, today, we are opening the waitlist for an early preview. This preview phase, as with previous models, is crucial for gathering insights to improve its performance and safety ahead of an open release. You can sign up to join the waitlist here.

The Stable Diffusion 3 suite of models currently range from 800M to 8B parameters. This approach aims to align with our core values and democratize access, providing users with a variety of options for scalability and quality to best meet their creative needs. Stable Diffusion 3 combines a diffusion transformer architecture and flow matching. We will publish a detailed technical report soon.

We believe in safe, responsible AI practices. This means we have taken and continue to take reasonable steps to prevent the misuse of Stable Diffusion 3 by bad actors. Safety starts when we begin training our model and continues throughout the testing, evaluation, and deployment. In preparation for this early preview, we’ve introduced numerous safeguards. By continually collaborating with researchers, experts, and our community, we expect to innovate further with integrity as we approach the model’s public release.

Our commitment to ensuring generative AI is open, safe, and universally accessible remains steadfast. With Stable Diffusion 3, we strive to offer adaptable solutions that enable individuals, developers, and enterprises to unleash their creativity, aligning with our mission to activate humanity’s potential.
If you’d like to explore using one of our other image models for commercial use prior to the Stable Diffusion 3 release, please visit our Stability AI Membership page to self host or our Developer Platform to access our API.
To stay updated on our progress follow us on Twitter, Instagram, LinkedIn, and join our Discord Community.