Google presents Genie
Generative Interactive Environments
introduce Genie, the first generative interactive environment trained in an unsupervised manner from unlabelled Internet videos. The model can be prompted to generate an endless variety of action-controllable virtual worlds described through text, synthetic images, photographs, and even sketches. At 11B parameters, Genie can be considered a foundation world model. It is comprised of a spatiotemporal video tokenizer, an autoregressive dynamics model, and a simple and scalable latent action model. Genie enables users to act in the generated environments on a frame-by-frame basis despite training without any ground-truth action labels or other domain-specific requirements typically found in the world model literature. Further the resulting learned latent action space facilitates training agents to imitate behaviors from unseen videos, opening the path for training generalist agents of the future.
A Foundation Model for Playable Worlds

sites.google.com
Genie: Generative Interactive Environments
Genie Team
We introduce Genie, a foundation world model trained from Internet videos that can generate an endless variety of playable (action-controllable) worlds from synthetic images, photographs, and even sketches.
A Foundation Model for Playable Worlds
The last few years have seen an emergence of generative AI, with models capable of generating novel and creative content via language, images, and even videos. Today, we introduce a new paradigm for generative AI,
generative interactive environments (Genie), whereby interactive, playable environments can be generated from a single image prompt.
Genie can be prompted with images it has never seen before, such as real world photographs or sketches, enabling people to interact with their imagined virtual worlds-–essentially acting as a foundation world model. This is possible despite training without any action labels. Instead, Genie is trained from a large dataset of publicly available Internet videos. We focus on videos of 2D platformer games and robotics but our method is general and should work for any type of domain, and is scalable to ever larger Internet datasets.
Learning to control without action labels
What makes Genie unique is its ability to learn fine-grained controls exclusively from Internet videos. This is a challenge because Internet videos do not typically have labels regarding which action is being performed, or even which part of the image should be controlled. Remarkably, Genie learns not only which parts of an observation are generally controllable, but also infers diverse latent actions that are consistent across the generated environments. Note here how the same latent actions yield similar behaviors across different prompt images.
latent actions: 6, 6, 7, 6, 7, 6, 5, 5, 2, 7
latent actions: 5, 6, 2, 2, 6, 2, 5, 7, 7, 7
Enabling a new generation of creators
Amazingly, it only takes a single image to create an entire new interactive environment. This opens the door to a variety of new ways to generate and step into virtual worlds, for instance, we can take a state-of-the-art text-to-image generation model and use it to produce starting frames that we can then bring to life with Genie. Here we generate images with
Imagen2 and bring them to life with Genie.
But it doesn’t stop there, we can even step into human designed creations such as sketches! 


 colab.research.google.com
colab.research.google.com
 With an average score of 61.55 on the Open LLM Leaderboard, DeciLM-7B outperforms all other base LLMs in the 7 billion-parameter class!
With an average score of 61.55 on the Open LLM Leaderboard, DeciLM-7B outperforms all other base LLMs in the 7 billion-parameter class! Direct PyTorch benchmarks show DeciLM-7B surpassing Mistral 7B and Llama 2 7B, with 1.83x and 2.39x higher throughput, respectively.
Direct PyTorch benchmarks show DeciLM-7B surpassing Mistral 7B and Llama 2 7B, with 1.83x and 2.39x higher throughput, respectively. DeciLM-7B + Infery-LLM boosts speed by 4.4x over Mistral 7B with vLLM, enabling cost-effective, high-volume user interactions.
DeciLM-7B + Infery-LLM boosts speed by 4.4x over Mistral 7B with vLLM, enabling cost-effective, high-volume user interactions. Developed with the assistance of our NAS-powered engine, AutoNAC, DeciLM-7B employs variable Grouped Query Attention.
Developed with the assistance of our NAS-powered engine, AutoNAC, DeciLM-7B employs variable Grouped Query Attention.





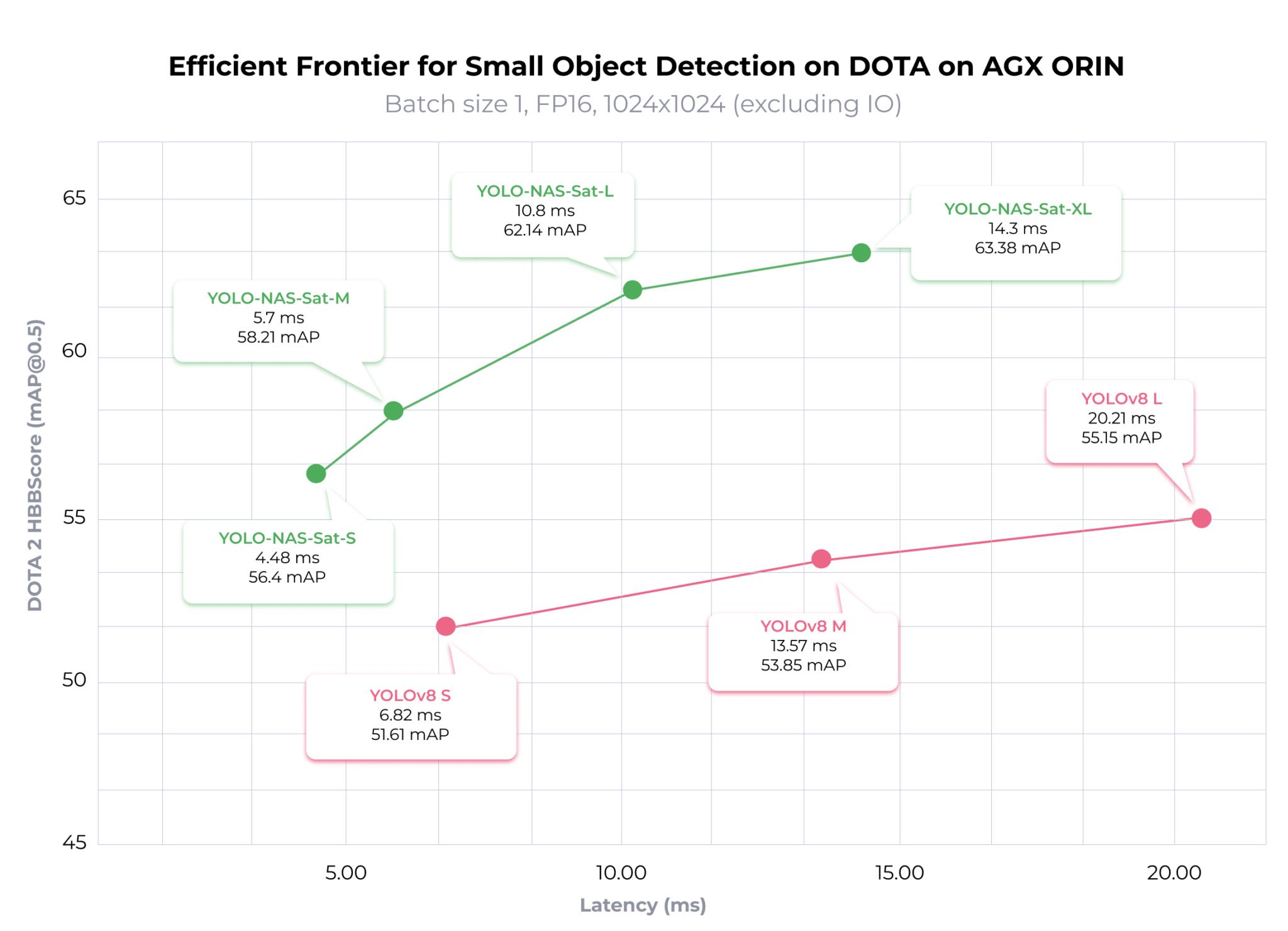
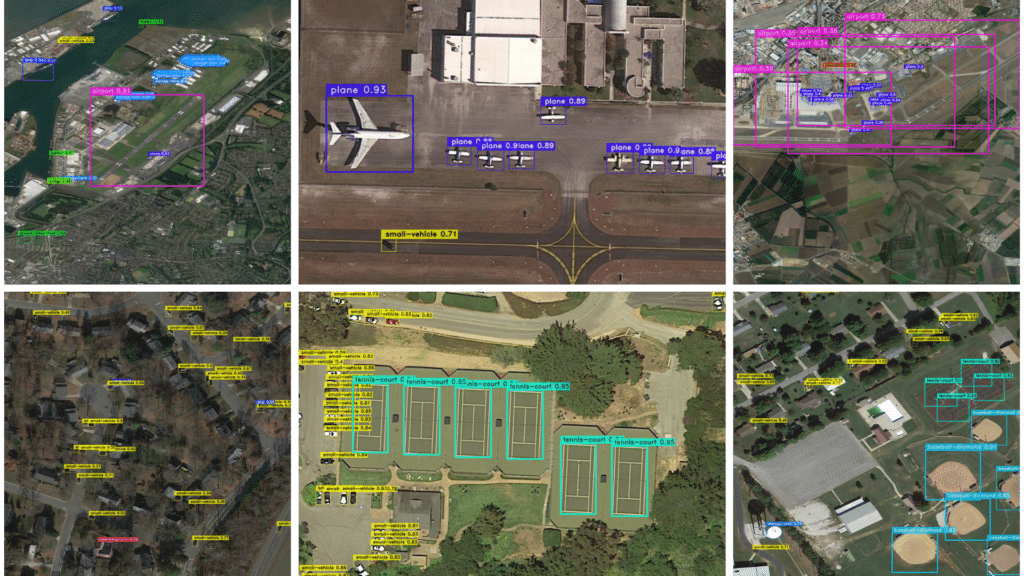

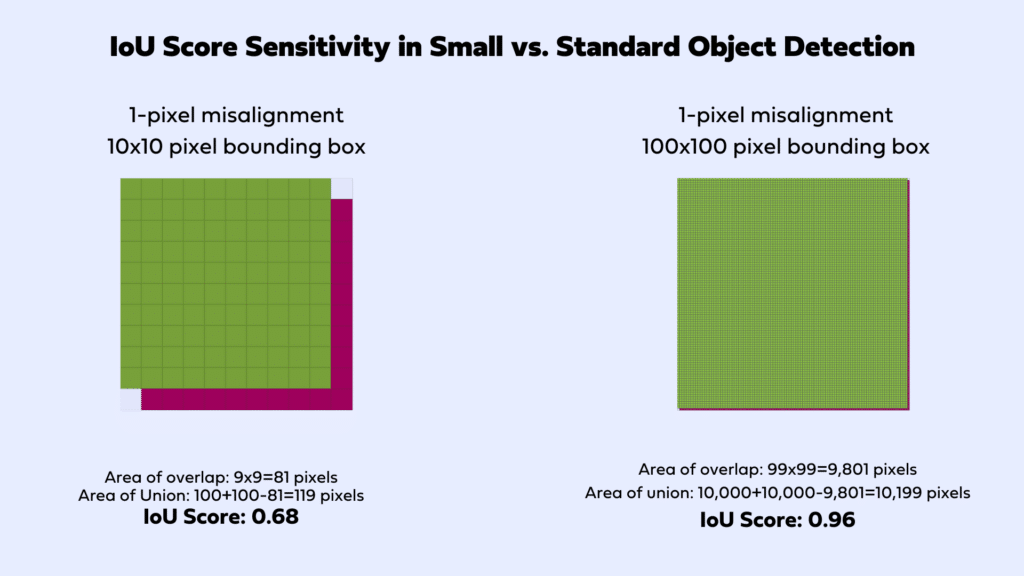
















 (see )
(see )









