
You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
Large Language Models News & Discussions
- Thread starter Macallik86
- Start date
More options
Who Replied?
mlx-community/phi-2-dpo-7k · Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co

Image to Music v2 - a Hugging Face Space by fffiloni
Get a music sample inspired by the mood of an image
huggingface.co
GitHub - argmaxinc/WhisperKit: Swift native on-device speech recognition with Whisper for iOS and macOS
Swift native on-device speech recognition with Whisper for iOS and macOS - GitHub - argmaxinc/WhisperKit: Swift native on-device speech recognition with Whisper for iOS and macOS
 github.com
github.com
Last edited:
Alapaca-Eval is a benchmark that uses a reference model to emulate human interactions and determine the extent to which an A.I. model being tested delivers results in line with the baseline. It also provides users with a leaderboard to track their tests, and today's benchmarks show that Qwen 1.5's Alapaca-Eval performance only lags behind GPT-4 Turbo and New York based HuggingFace's Yi-34B.
Qwen1.5 is one of the largest open source models of its kind, and it's backed by Alibaba's massive computing resources. An open source A.I., like open source software, makes its code available to users and developers so that they can understand the model and make their own variants. Meta's Llama, also present in today's scores, is also an open source model.
The start of 2024 has seen renowned focus from Wall Street and companies on A.I. Earnings reports of mega cap technology giants such as Meta, Microsoft and Alphabet have all focused on A.I. Meta's chief Mark Zuckerberg aims to buy hundreds of thousands of GPUs this year to power up Llama, and at the firm's earnings call the executive explained that his decision to beef up computing capacity at Meta follows earlier oversights that led to the firm being under capacity.
Similarly, earnings from chip makers and designers TSMC and AMD have also seen their managements express optimism for the future of A.I. TSMC's management is confident that the firm has stable footing to capture any A.I. demand, while AMD is of the view that A.I. can end up becoming worth hundreds of billions of dollars by the end of the decade.[/SIZE]
GitHub - OpenGVLab/InternVL: InternVL: Scaling up Vision Foundation Models and Aligning for Generic Visual-Linguistic Tasks —— An Open-Source Alternative to ViT-22B
InternVL: Scaling up Vision Foundation Models and Aligning for Generic Visual-Linguistic Tasks —— An Open-Source Alternative to ViT-22B - GitHub - OpenGVLab/InternVL: InternVL: Scaling up Vision Fo...
github.com
About
InternVL: Scaling up Vision Foundation Models and Aligning for Generic Visual-Linguistic Tasks —— An Open-Source Alternative to ViT-22BModel Zoo
| Model | Date | Download | Note |
|---|---|---|---|
| InternViT-6B-224px | 2023.12.22 |  HF link HF link | vision foundation model |
| InternVL-14B-224px | 2023.12.22 | HF link | vision-language foundation model |
| InternVL-Chat-13B | 2023.12.25 | HF link | English multimodal dialogue |
| InternVL-Chat-19B | 2023.12.25 | HF link | English multimodal dialogue |
| InternVL-Chat-V1.1 | 2024.01.24 | HF link | support Chinese and stronger OCR |
| InternViT-6B-448px | 2024.01.30 | HF link | 448 resolution |

OpenGVLab/InternVL-14B-224px · Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co

OpenGVLab/InternVL-Chat-ViT-6B-Vicuna-7B · Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co

OpenGVLab/InternVL-Chat-ViT-6B-Vicuna-13B · Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co

OpenGVLab/InternVL-Chat-Chinese-V1-1 · Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co

OpenGVLab/InternVL-Chat-ViT-6B-Vicuna-13B-448px · Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co
Paper page - InternVL: Scaling up Vision Foundation Models and Aligning for Generic Visual-Linguistic Tasks
Join the discussion on this paper page
huggingface.co
Computer Science > Computer Vision and Pattern Recognition
[Submitted on 21 Dec 2023 (v1), last revised 15 Jan 2024 (this version, v3)]
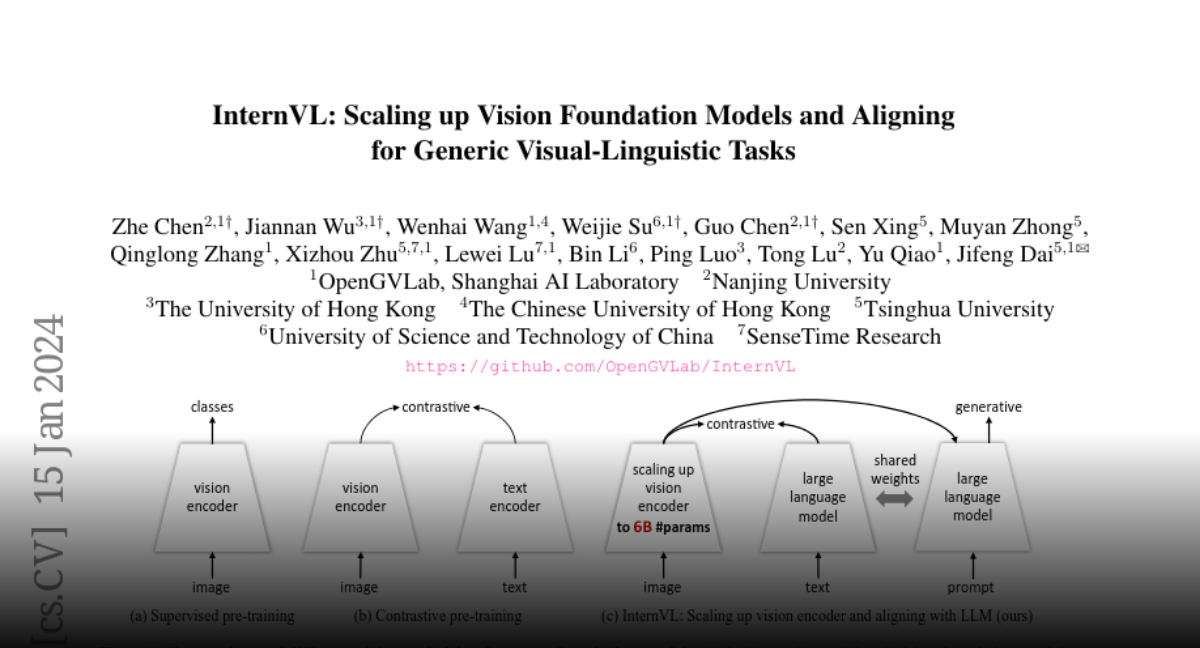
InternVL: Scaling up Vision Foundation Models and Aligning for Generic Visual-Linguistic Tasks
Zhe Chen, Jiannan Wu, Wenhai Wang, Weijie Su, Guo Chen, Sen Xing, Muyan Zhong, Qinglong Zhang, Xizhou Zhu, Lewei Lu, Bin Li, Ping Luo, Tong Lu, Yu Qiao, Jifeng Dai
The exponential growth of large language models (LLMs) has opened up numerous possibilities for multimodal AGI systems. However, the progress in vision and vision-language foundation models, which are also critical elements of multi-modal AGI, has not kept pace with LLMs. In this work, we design a large-scale vision-language foundation model (InternVL), which scales up the vision foundation model to 6 billion parameters and progressively aligns it with the LLM, using web-scale image-text data from various sources. This model can be broadly applied to and achieve state-of-the-art performance on 32 generic visual-linguistic benchmarks including visual perception tasks such as image-level or pixel-level recognition, vision-language tasks such as zero-shot image/video classification, zero-shot image/video-text retrieval, and link with LLMs to create multi-modal dialogue systems. It has powerful visual capabilities and can be a good alternative to the ViT-22B. We hope that our research could contribute to the development of multi-modal large models. Code and models are available at this https URL.
| Comments: | 25 pages, 5 figures, 28 tables |
| Subjects: | Computer Vision and Pattern Recognition (cs.CV) |
| Cite as: | arXiv:2312.14238 [cs.CV] |
| (or arXiv:2312.14238v3 [cs.CV] for this version) | |
| [2312.14238] InternVL: Scaling up Vision Foundation Models and Aligning for Generic Visual-Linguistic Tasks Focus to learn more |
Submission history
From: Zhe Chen [view email]
[v1] Thu, 21 Dec 2023 18:59:31 UTC (1,993 KB)
[v2] Tue, 26 Dec 2023 18:03:16 UTC (1,824 KB)
[v3] Mon, 15 Jan 2024 15:23:55 UTC (1,824 KB)
Ten months ago, we launched the Vesuvius Challenge to solve the ancient problem of the Herculaneum Papyri, a library of scrolls that were flash-fried by the eruption of Mount Vesuvius in 79 AD.
Today we are overjoyed to announce that our crazy project has succeeded. After 2000 years, we can finally read the scrolls:
This image was produced by @Youssef_M_Nader, @LukeFarritor, and @JuliSchillij, who have now won the Vesuvius Challenge Grand Prize of $700,000. Congratulations!!
These fifteen columns come from the very end of the first scroll we have been able to read and contain new text from the ancient world that has never been seen before. The author – probably Epicurean philosopher Philodemus – writes here about music, food, and how to enjoy life's pleasures. In the closing section, he throws shade at unnamed ideological adversaries – perhaps the stoics? – who "have nothing to say about pleasure, either in general or in particular."
This year, the Vesuvius Challenge continues. The text that we revealed so far represents just 5% of one scroll.
In 2024, our goal is to from reading a few passages of text to entire scrolls, and we're announcing a new $100,000 grand prize for the first team that is able to read at least 90% of all four scrolls that we have scanned.
The scrolls stored in Naples that remain to be read represent more than 16 megabytes of ancient text. But the villa where the scrolls were found was only partially excavated, and scholars tell us that there may be thousands more scrolls underground. Our hope is that the success of the Vesuvius Challenge catalyzes the excavation of the villa, that the main library is discovered, and that whatever we find there rewrites history and inspires all of us.
It's been a great joy to work on this strange and amazing project. Thanks to Brent Seales for laying the foundation for this work over so many years, thanks to the friends and Twitter users whose donations powered our effort, and thanks to the many contestants whose contributions have made the Vesuvius Challenge successful!
Read more in our announcement: scrollprize.org/grandprize
Today we are overjoyed to announce that our crazy project has succeeded. After 2000 years, we can finally read the scrolls:
This image was produced by @Youssef_M_Nader, @LukeFarritor, and @JuliSchillij, who have now won the Vesuvius Challenge Grand Prize of $700,000. Congratulations!!
These fifteen columns come from the very end of the first scroll we have been able to read and contain new text from the ancient world that has never been seen before. The author – probably Epicurean philosopher Philodemus – writes here about music, food, and how to enjoy life's pleasures. In the closing section, he throws shade at unnamed ideological adversaries – perhaps the stoics? – who "have nothing to say about pleasure, either in general or in particular."
This year, the Vesuvius Challenge continues. The text that we revealed so far represents just 5% of one scroll.
In 2024, our goal is to from reading a few passages of text to entire scrolls, and we're announcing a new $100,000 grand prize for the first team that is able to read at least 90% of all four scrolls that we have scanned.
The scrolls stored in Naples that remain to be read represent more than 16 megabytes of ancient text. But the villa where the scrolls were found was only partially excavated, and scholars tell us that there may be thousands more scrolls underground. Our hope is that the success of the Vesuvius Challenge catalyzes the excavation of the villa, that the main library is discovered, and that whatever we find there rewrites history and inspires all of us.
It's been a great joy to work on this strange and amazing project. Thanks to Brent Seales for laying the foundation for this work over so many years, thanks to the friends and Twitter users whose donations powered our effort, and thanks to the many contestants whose contributions have made the Vesuvius Challenge successful!
Read more in our announcement: scrollprize.org/grandprize

US says leading AI companies join safety consortium to address risks
By David ShepardsonFebruary 8, 20245:02 AM EST
Updated 2 hours ago
 letters and computer motherboard")
AI (Artificial Intelligence) letters are placed on computer motherboard in this illustration taken June 23, 2023. REUTERS/Dado Ruvic/Illustration/File Photo Purchase Licensing Rights, opens new tab
WASHINGTON, Feb 8 (Reuters) - The Biden administration on Thursday said leading artificial intelligence companies are among more than 200 entities joining a new U.S. consortium to support the safe development and deployment of generative AI.
Commerce Secretary Gina Raimondo announced the U.S. AI Safety Institute Consortium (AISIC), which includes OpenAI, Alphabet's Google (GOOGL.O), opens new tab, Anthropic and Microsoft (MSFT.O), opens new tab along with Facebook-parent Meta Platforms (META.O), opens new tab, Apple (AAPL.O), opens new tab, Amazon.com (AMZN.O), opens new tab, Nvidia (NVDA.O), opens new tab Palantir (PLTR.N), opens new tab, Intel, JPMorgan Chase (JPM.N), opens new tab and Bank of America (BAC.N), opens new tab.
"The U.S. government has a significant role to play in setting the standards and developing the tools we need to mitigate the risks and harness the immense potential of artificial intelligence," Raimondo said in a statement.
The consortium, which also includes BP (BP.L), opens new tab, Cisco Systems (CSCO.O), opens new tab, IBM (IBM.N), opens new tab, Hewlett Packard (HPE.N), opens new tab, Northop Grumman (NOC.N), opens new tab, Mastercard (MA.N), opens new tab, Qualcomm (QCOM.O), opens new tab, Visa (V.N), opens new tab and major academic institutions and government agencies, will be housed under the U.S. AI Safety Institute (USAISI).
The group is tasked with working on priority actions outlined in President Biden’s October AI executive order "including developing guidelines for red-teaming, capability evaluations, risk management, safety and security, and watermarking synthetic content."
Major AI companies last year pledged to watermark AI-generated content to make the technology safer. Red-teaming has been used for years in cybersecurity to identify new risks, with the term referring to U.S. Cold War simulations where the enemy was termed the "red team."
Biden's order directed agencies to set standards for that testing and to address related chemical, biological, radiological, nuclear, and cybersecurity risks.
In December, the Commerce Department said it was taking the first step toward writing key standards and guidance for the safe deployment and testing of AI.
The consortium represents the largest collection of test and evaluation teams and will focus on creating foundations for a "new measurement science in AI safety," Commerce said.
Generative AI - which can create text, photos and videos in response to open-ended prompts - has spurred excitement as well as fears it could make some jobs obsolete, upend elections and potentially overpower humans and catastrophic effects.
While the Biden administration is pursuing safeguards, efforts in Congress to pass legislation addressing AI have stalled despite numerous high-level forums and legislative proposals.
Reporting by David Shepardson; Editing by Jamie Freed
Our Standards: The Thomson Reuters Trust Principles.

Fortanix joins NIST consortium to advance trustworthy AI
Confidential Computing pioneer to contribute knowledge of real-world applications to support trustworthy AI methods and techniques.
 www.eenewseurope.com
www.eenewseurope.com

Amazon joins US Artificial Intelligence Safety Institute to advance responsible AI
Artificial intelligence (AI) is one of the most transformational technologies of our generation. The advent of large language models (LLMs) with hundreds of billions of parameters has unlocked new generative AI use cases to improve customer experiences, boost employee productivity, drive economic…
 www.aboutamazon.com
www.aboutamazon.com


Cleveland Clinic to Participate in Department of Commerce Consortium on AI Safety
Cleveland Clinic will participate in a Department of Commerce initiative to support the development and deployment of trustworthy and safe artificial intelligence (AI). More than 200 leading AI stakeholders are joining the U.S. AI Safety Institute Consortium (AISIC), which is being established...
 newsroom.clevelandclinic.org
newsroom.clevelandclinic.org

Top AI Companies Join Government Effort to Set Safety Standards
The top US artificial intelligence companies will participate in a government-led effort intended to craft federal standards on the technology to ensure that it’s deployed safely and responsibly, the Commerce Department said Thursday.
 www.bloomberg.com
www.bloomberg.com

Top White House aide to lead AI Safety Institute
The Biden administration named a lead for a new institute for artificial intelligence (AI) safety on Wednesday, underlining the White House’s focus on the developing technology. Elizabeth Kelly, an…
 thehill.com
thehill.com
/cdn.vox-cdn.com/uploads/chorus_asset/file/10745895/acastro_180427_1777_0001.jpg)
Google’s AI now goes by a new name: Gemini
Gemini is coming to your phone, your email, your everything.
Google’s AI now goes by a new name: Gemini
Bard and Duet are gone, as Gemini becomes both the model and the product for getting all of Google’s AI out into the world.By David Pierce, editor-at-large and Vergecast co-host with over a decade of experience covering consumer tech. Previously, at Protocol, The Wall Street Journal, and Wired.
Feb 8, 2024, 8:00 AM EST
74 Comments74 New
If you buy something from a Verge link, Vox Media may earn a commission. See our ethics statement.
:format(webp)/cdn.vox-cdn.com/uploads/chorus_asset/file/10745895/acastro_180427_1777_0001.jpg)
Illustration by Alex Castro / The Verge
Google is famous for having a million similar products with confusingly different names and seemingly nothing in common. (Can I interest you in a messaging app?) But when it comes to its AI work, going forward there is only one name that matters: Gemini.
The company announced on Thursday that it is renaming its Bard chatbot to Gemini, releasing a dedicated Gemini app for Android, and even folding all its Duet AI features in Google Workspace into the Gemini brand. It also announced that Gemini Ultra 1.0 — the largest and most capable version of Google’s large language model — is being released to the public.
Gemini’s mobile apps will likely be the place most people encounter the new tool. If you download the new app on Android, it can set Gemini as your default assistant, meaning it replaces Google Assistant as the thing that responds when you say, “Hey Google” or long-press your home button. So far, it doesn’t seem Google is getting rid of Assistant entirely, but the company has been deprioritizing Assistant for a while now, and it clearly believes Gemini is the future. “I think it’s a super important first step towards building a true AI assistant,” says Sissie Hsiao, who runs Bard (now Gemini) at Google. “One that is conversational, it’s multimodal, and it’s more helpful than ever before.”
:format(webp)/cdn.vox-cdn.com/uploads/chorus_asset/file/25273310/CleanShot_2024_02_07_at_18.40.59.png)
Gemini is part assistant, part chatbot, part search engine.
Image: Google
There’s no dedicated Gemini app for iOS, and you can’t set a non-Siri assistant as the default anyway, but you’ll be able to access all the AI features in the Google app. And just to give you a sense of how important Gemini is to Google: there’s going to be a toggle at the top of the app that lets you switch from Search to Gemini. For the entirety of Google’s existence, Search has been the most important product by a mile; it’s beginning to signal that Gemini might matter just as much. (For now, by the way, Google’s in-search AI is still called Search Generative Experience, but it’s probably safe to bet that’ll be Gemini eventually, too.)
The other changes to Gemini are mostly just branding. Google is ditching the Bard name, but otherwise its chatbot will feel the way it has previously; same goes for all the AI features inside of Google’s Workspace apps like Gmail and Docs, which were previously called “Duet AI” but are now also known as Gemini. Those are the features that help you draft an email, organize a spreadsheet, and accomplish other work-related tasks.
Most users will still be using the standard version of the Gemini model, known as Gemini Pro. In order to use Gemini Ultra, the most powerful version of the model, you’ll have to sign up for a Gemini Advanced subscription, which is part of the new $20-a-month Google One AI Premium plan. (These names are not helpful, Google!) The subscription also comes with 2TB of Google Drive storage and all the other features of the Google One subscription, so Google frames it as just a $10 monthly increase for those users. For everyone else, it’s the same price as ChatGPT Plus and other products — $20 a month seems to be about the going rate for a high-end AI bot.
The Ultra model can contain more context and have longer conversations
For that $20 a month, Hsiao says Gemini Ultra “sets the state of the art across a wide range of benchmarks across text, image, audio, and video.” The Ultra model can contain more context and have longer conversations, and it’s designed to be better at complex things like coding and logical reasoning.
:format(webp)/cdn.vox-cdn.com/uploads/chorus_asset/file/25273303/Google_One_plans.jpg)
The Google One plans are confusing — this helps.
Image: Google
It’s not a surprise that Google is so all-in on Gemini, but it does raise the stakes for the company’s ability to compete with OpenAI, Anthropic, Perplexity, and the growing set of other powerful AI competitors on the market. In our tests just after the Gemini launch last year, the Gemini-powered Bard was very good, nearly on par with GPT-4, but it was significantly slower. Now Google needs to prove it can keep up with the industry, as it looks to both build a compelling consumer product and try to convince developers to build on Gemini and not with OpenAI.
Only a few times in Google’s history has it seemed like the entire company was betting on a single thing. Once, that turned into Google Plus… and we know how that went. But this time, it appears Google is fully committed to being an AI company. And that means Gemini might be just as big as Google.

The next chapter of our Gemini era
We\u0027re bringing Gemini to more Google products. Bard will now be called Gemini, and you can access our most capable AI model, Ultra 1.0, in Gemini Advanced.

Frederic Lardinois (@fredericl) on Threads
When Google creates a general artificial intelligence, the AI's one task before announcing itself to the world will be to fix Google's confusing branding. Then it will call itself the Google Assistant...
 www.threads.net
www.threads.net

Christophe Dubos on LinkedIn: The next chapter of our Gemini era
Drum Roll, please - Today we're Introducing Gemini Advanced Bard has been the best way for people to directly experience our most capable models. To reflect…
 www.linkedin.com
www.linkedin.com

Greta Krupetsky on LinkedIn: The next chapter of our Gemini era
Today is a very proud moment for us all at Google as we enter the next chapter of our #Gemini era, bringing our most capable #AI technology to the entire…
www.linkedin.com

Bard rebranded: Google's ChatGPT rival is now called Gemini
Google has renamed its AI chatbot Bard as Gemini, giving a new identity to its ChatGPT rival

Aaron Lax on LinkedIn: Google’s AI now goes by a new name: Gemini | 18 comments
BARD no longer, the reports earlier this week about Google changing the name of their AI competitor from Bard to Gemini has occurred. Another bit of news that… | 18 comments on LinkedIn
www.linkedin.com
Vikas Kansal on LinkedIn: The next chapter of our Gemini era
🚀 Launching Google One AI Premium plan that comes with Gemini Advanced (formerly Bard) with our most capable AI model, Ultra 1.0 and offers the best of…
www.linkedin.com
/cdn.vox-cdn.com/uploads/chorus_asset/file/24402139/STK071_apple_K_Radtke_03.jpg)
Apple made an AI image tool that lets you make edits by describing them
It can resize photos with a few simple instructions.
ARTIFICIAL INTELLIGENCE/
TECH/
APPLE
Apple made an AI image tool that lets you make edits by describing them
MGIE, or MLLM-Guided Image Editing, will crop photos and brighten specific areas of a photo.
By Emilia David, a reporter who covers AI. Prior to joining The Verge, she covered the intersection between technology, finance, and the economy.
Feb 7, 2024, 2:49 PM EST
11 Comments11 New
:format(webp)/cdn.vox-cdn.com/uploads/chorus_asset/file/24402139/STK071_apple_K_Radtke_03.jpg)
Illustration: The Verge
Apple researchers released a new model that lets users describe in plain language what they want to change in a photo without ever touching photo editing software.
The MGIE model, which Apple worked on with the University of California, Santa Barbara, can crop, resize, flip, and add filters to images all through text prompts.
MGIE, which stands for MLLM-Guided Image Editing, can be applied to simple and more complex image editing tasks like modifying specific objects in a photo to make them a different shape or come off brighter. The model blends two different uses of multimodal language models. First, it learns how to interpret user prompts. Then it “imagines” what the edit would look like (asking for a bluer sky in a photo becomes bumping up the brightness on the sky portion of an image, for example).
When editing a photo with MGIE, users just have to type out what they want to change about the picture. The paper used the example of editing an image of a pepperoni pizza. Typing the prompt “make it more healthy” adds vegetable toppings. A photo of tigers in the Sahara looks dark, but after telling the model to “add more contrast to simulate more light,” the picture appears brighter.
:format(webp)/cdn.vox-cdn.com/uploads/chorus_asset/file/25272674/Screenshot_Apple_MGIE_image_examples.jpg)
Screenshot of the MGIE paper.
Image: Apple
“Instead of brief but ambiguous guidance, MGIE derives explicit visual-aware intention and leads to reasonable image editing. We conduct extensive studies from various editing aspects and demonstrate that our MGIE effectively improves performance while maintaining competitive efficiency. We also believe the MLLM-guided framework can contribute to future vision-and-language research,” the researchers said in the paper.
Apple made MGIE available through GitHub for download, but it also released a web demo on Hugging Face Spaces, reports VentureBeat. The company did not say what its plans for the model are beyond research.
Some image generation platforms, like OpenAI’s DALL-E 3, can perform simple photo editing tasks on pictures they create through text inputs. Photoshop creator Adobe, which most people turn to for image editing, also has its own AI editing model. Its Firefly AI model powers generative fill, which adds generated backgrounds to photos.
Apple has not been a big player in the generative AI space, unlike Microsoft, Meta, or Google, but Apple CEO Tim Cook has said the company wants to add more AI features to its devices this year. In December, Apple researchers released an open-source machine learning framework called MLX to make it easier to train AI models on Apple Silicon chips.
Apple releases MGIE, an AI-based image editing model | Hacker News
 news.ycombinator.com
news.ycombinator.com
Pratik Patel (@ppatel@mstdn.social)
I expected something like this after Apple's October #OpenSource AI effort. The potential #accessibility implications are pretty significant here. Apple partners with University of California researchers to release open-source #AI model #MGIE, which can edit images based on natural language...
Instruction-Based Image Editing via LLM | Hacker News
 news.ycombinator.com
news.ycombinator.com

Apple Releases MGIE, an AI Model for Instruction-Based Image Editing - Slashdot
Apple has released a new open-source AI model, called "MGIE," that can edit images based on natural language instructions. From a report: MGIE, which stands for MLLM-Guided Image Editing, leverages multimodal large language models (MLLMs) to interpret user commands and perform pixel-level...
apple.slashdot.org
New Apple AI Model Edits Images Based on Natural Language Input
Apple researchers have released a new open-source AI model that is capable of editing images based on a user's natural language instructions (via VentureBeat). MacRumors image made with DALL·E Called "MGIE," which stands for MLLM-Guided Image Editing, it uses multimodal large language models...
 forums.macrumors.com
forums.macrumors.com
/cdn.vox-cdn.com/uploads/chorus_asset/file/24936950/potatoking.png)
OpenAI is adding new watermarks to DALL-E 3
The watermarks can still be erased, however.
OpenAI is adding new watermarks to DALL-E 3
OpenAI says watermarks in image metadata are not perfect, but they help build trust of digital information.
By Emilia David, a reporter who covers AI. Prior to joining The Verge, she covered the intersection between technology, finance, and the economy.
Feb 6, 2024, 5:32 PM EST
9 Comments9 New
:format(webp)/cdn.vox-cdn.com/uploads/chorus_asset/file/24936950/potatoking.png)
Image: OpenAI
OpenAI’s image generator DALL-E 3 will add watermarks to image metadata as more companies roll out support for standards from the Coalition for Content Provenance and Authenticity (C2PA).
The company says watermarks from C2PA will appear in images generated on the ChatGPT website and the API for the DALL-E 3 model. Mobile users will get the watermarks by February 12th. They’ll include both an invisible metadata component and a visible CR symbol, which will appear in the top left corner of each image.
People can check the provenance — which AI tool was used to make the content — of any image generated by OpenAI’s platforms through websites like Content Credentials Verify. So far, only still images, not videos or text, can carry the watermark.
:format(webp)/cdn.vox-cdn.com/uploads/chorus_asset/file/25270974/dalle_cr.jpg)
New watermarks on DALL-E 3 images.
Image: OpenAI
OpenAI says adding the watermark metadata to images represents a “negligible effect on latency and will not affect the quality of the image generation.” It will also increase image sizes slightly for some tasks.
The C2PA, a group consisting of companies like Adobe and Microsoft, has been pushing the use of the Content Credentials watermark to identify the provenance of content and show if it was made by humans or with AI. Adobe created a Content Credentials symbol, which OpenAI is adding to DALL-E 3 creations. Meta recently announced it will add tags to AI-generated content on its social media platforms.
Identifying AI-generated content is one of the flagship directives in the Biden administration’s executive order on AI. But watermarking is not a surefire way to stop misinformation. OpenAI points out that C2PA’s metadata can “easily be removed either accidentally or intentionally,” especially as most social media platforms often remove metadata from uploaded content. Taking a screenshot omits the metadata.
“We believe that adopting these methods for establishing provenance and encouraging users to recognize these signals are key to increasing the trustworthiness of digital information,” OpenAI says on its site.