
You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
Large Language Models News & Discussions
- Thread starter Macallik86
- Start date
More options
Who Replied?






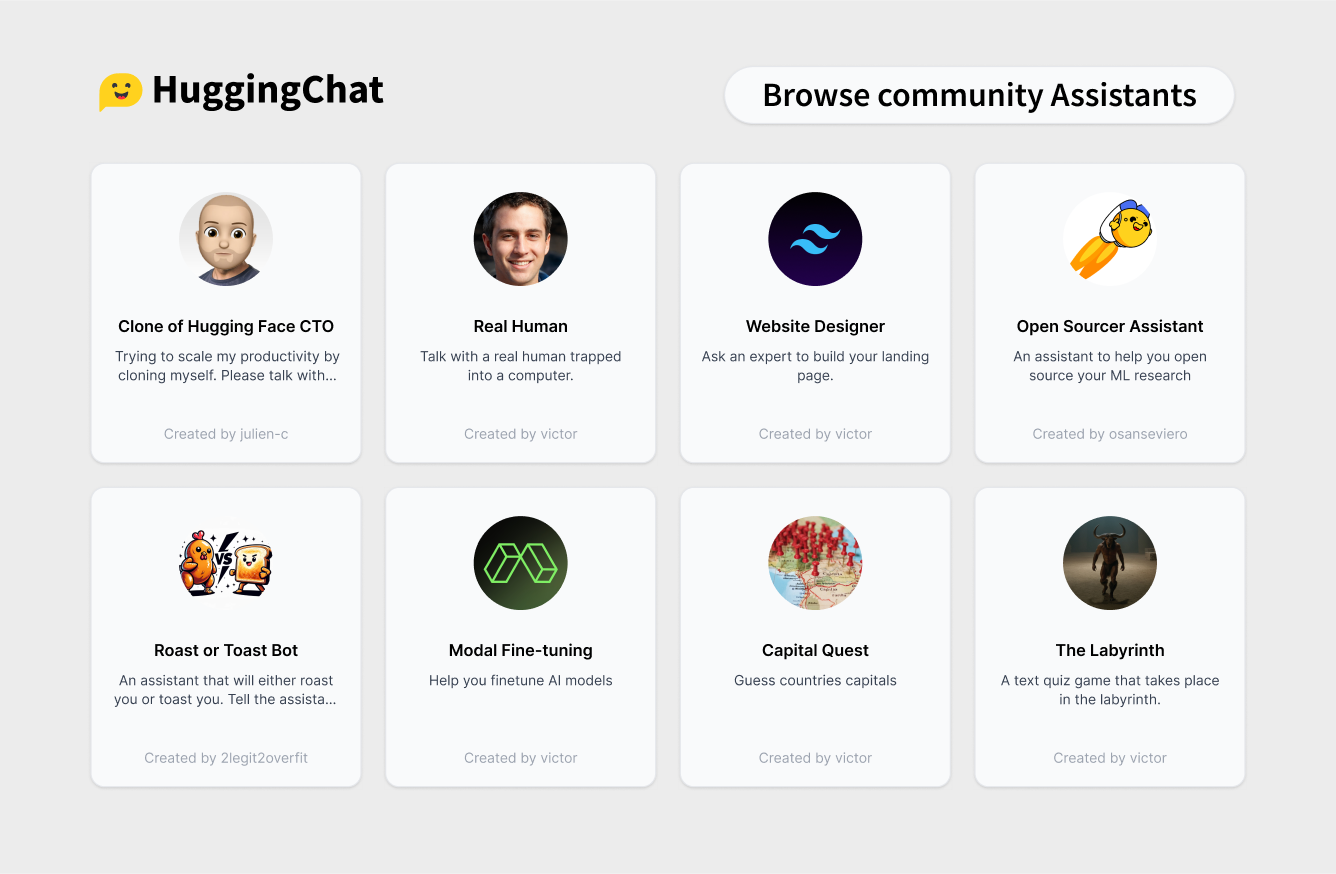
Constitutional AI Demo - a Hugging Face Space by HuggingFaceH4
Discover amazing ML apps made by the community
huggingface.co

Hugging Face launches open source AI assistant maker to rival OpenAI’s custom GPTs
The arrival of Hugging Chat Assistants shows how fast the open source community continues to catch up to closed rivals such as OpenAI.
 venturebeat.com
venturebeat.com
Hugging Face launches open source AI assistant maker to rival OpenAI’s custom GPTs
Carl Franzen @carlfranzenFebruary 2, 2024 2:51 PM

Credit: VentureBeat made with Midjourney V6
Hugging Face, the New York City-based startup that offers a popular, developer-focused repository for open source AI code and frameworks (and hosted last year’s “Woodstock of AI”), today announced the launch of third-party, customizable Hugging Chat Assistants.
The new, free product offering allows users of Hugging Chat, the startup’s open source alternative to OpenAI’s ChatGPT, to easily create their own customized AI chatbots with specific capabilities, similar both in functionality and intention to OpenAI’s custom GPT Builder — though that requires a paid subscription to ChatGPT Plus ($20 per month), Team ($25 per user per month paid annually), and Enterprise (variable pricing depending on the needs).
Easy creation of custom AI chatbots
Phillip Schmid, Hugging Face’s Technical Lead & LLMs Director, posted the news on the social network X (formerly known as Twitter), explaining that users could build a new personal Hugging Face Chat Assistant “in 2 clicks!” Schmid also openly compared the new capabilities to OpenAI’s custom GPTs.However, in addition to being free, the other big difference between Hugging Chat Assistant and the GPT Builder and GPT Store is that the latter tools depend entirely on OpenAI’s proprietary large language models (LLM) GPT-4 and GPT-4 Vision/Turbo.
Users of Hugging Chat Assistant, by contrast, can choose which of several open source LLMs they wish to use to power the intelligence of their AI Assistant on the backend, including everything from Mistral’s Mixtral to Meta’s Llama 2.
That’s in keeping with Hugging Face’s overarching approach to AI — offering a broad swath of different models and frameworks for users to choose between — as well as the same approach it takes with Hugging Chat itself, where users can select between several different open source models to power it.
An open rival to the GPT Store?
Like OpenAI with its GPT Store launched last month, Hugging Face has also created a central repository of third-party customized Hugging Chat Assistants which users can choose between and use on their own time here.The Hugging Chat Assistants aggregator page bears a very close resemblance to the GPT Store page, even down to its visual style, with custom Assistants displayed like custom GPTs in their own rectangular, baseball card-style boxes with circular logos inside.

Screenshot of OpenAI’s GPT Store.

Screenshot of Hugging Face’s Hugging Chat Assistants page.
Better in some ways than GPTs, worse than others
Already, some users in the open source AI community are hailing Hugging Chat Assistants as “better than GPTs,” including Mathieu Trachino, founder of enterprise AI software provider GenDojo.ai, who took to X to list off the merits, which mainly revolve around the user customizability of the underlying models and the fact that the whole situation is free, compared to OpenAI’s paid subscription tiers.He also noted some areas where custom GPTs outperform Hugging Chat Assistants, including the fact that they don’t currently support web search, retrieval augmented generation (RAG), nor can they generate their own logos (which GPTs do thanks to the power of OpenAI’s image generation AI model DALL-E 3).
Still, the arrival of Hugging Chat Assistants shows how fast the open source community continues to catch up to closed rivals like the now-ironically named “Open” AI, especially coming just one day after the confirmed leak of a new open source model from Mistral, Miqu, that nearly matches the performance of the closed GPT-4, still the high watermark for LLMs. But…for how long?












Google releases GenAI tools for music creation | TechCrunch
Google has released and updated its tools for music creation and lyrics generation. The tools are available in AI Test Kitchen, its app for experimental AI projects.
 techcrunch.com
techcrunch.com
Google releases GenAI tools for music creation
Kyle Wiggers @kyle_l_wiggers / 10:00 AM EST•February 1, 2024
Image Credits: Artur Widak/NurPhoto / Getty Images
As GenAI tools begin to transform the music industry in incredible — and in some cases ethically problematic — ways, Google is ramping up its investments in AI tech to create new songs and lyrics.
The search giant today unveiled MusicFX, an upgrade to MusicLM, the music-generating tool Google released last year. MusicFX can create ditties up to 70 seconds in length and music loops, delivering what Google claims is “higher-quality” and “faster” music generation.
MusicFX is available in Google’s AI Test Kitchen, an app that lets users try out experimental AI-powered systems from the company’s labs. Technically, MusicFX launched for select users in December — but now it’s generally available.

Image Credits: Google
And it’s not terrible, I must say.
Like its predecessor, MusicFX lets users enter a text prompt (“two nylon string guitars playing in flamenco style”) to describe the song they wish to create. The tool generates two 30-second versions by default, with options to lengthen the tracks (to 50 or 70 seconds) or automatically stitch the beginning and end to loop them.
A new addition is suggestions for alternative descriptor words in prompts. For example, if you type “country style,” you might see a drop-down with genres like “rockabilly style” and “bluegrass style.” For the word “catchy,” the drop-down might contain “chill” and “melodic.”

Image Credits: Google
Below the field for the prompt, MusicFX provides a word cloud of additional recommendations for relevant descriptions, instruments and tempos to append (e.g. “avant garde,” “fast,” “exciting,” “808 drums”).
So how’s it sound? Well, in my brief testing, MusicFX’s samples were… fine? Truth be told, music generation tools are getting to the point where it’s tough for this writer to distinguish between the outputs. The current state-of-the-art produces impressively clean, crisp-sounding tracks — but tracks tending toward the boring, uninspired and melodically unfocused.
Maybe it’s the SAD getting to me, but one of the prompts I went with was “a house music song with funky beats that’s danceable and uplifting, with summer rooftop vibes.” MusicFX delivered, and the tracks weren’t bad — but I can’t say that they come close to any of the better DJ sets I’ve heard recently.
Listen for yourself:
https://techcrunch.com/wp-content/u..._music_song_with_funky_beats_thats_da.mp3?_=1
https://techcrunch.com/wp-content/u...usic_song_with_funky_beats_thats_da-5.mp3?_=2
Anything with stringed instruments sounds worse, like a cheap MIDI sample — which is perhaps a reflection of MusicFX’s limited training set. Here are two tracks generated with the prompt “a soulful melody played on string instruments, orchestral, with a strong melodic core”:
https://techcrunch.com/wp-content/u...melody_played_on_string_instruments-1.mp3?_=3
https://techcrunch.com/wp-content/u...l_melody_played_on_string_instruments.mp3?_=4
And for a change of pace, here’s MusicFX’s interpretation of “a weepy song on guitar, melancholic, slow tempo, on a moonlight [sic] night.” (Forgive the spelling mistake.)
https://techcrunch.com/wp-content/u...y_song_on_guitar_melancholic_slow_tem.mp3?_=5
There are certain things MusicFX won’t generate — and that can’t be removed from generated tracks. To avoid running afoul of copyrights, Google filters prompts that mention specific artists or include vocals. And it’s using SynthID, an inaudible watermarking technology its DeepMind division developed, to make it clear which tracks came from MusicFX.
I’m not sure what sort of master list Google’s using to filter out artists and song names, but I didn’t find it all that hard to defeat. While MusicFX declined to generate songs in the style of SZA and The Beatles, it happily took a prompt referencing Lake Street Dive — although the tracks weren’t writing home about, I will say.
Lyric generation
Google released a new lyrics generation tool, TextFX, in AI Test Kitchen that’s intended as a sort of companion to MusicFX. Like MusicFX, TextFX has been available to a small user cohort for some time — but it’s now more widely available, and upgraded in terms of “user experience and navigation,” Google says.As Google explains in the AI Test Kitchen app, TextFX was created in collaboration with Lupe Fiasco, the rap artist and record producer. It’s powered by PaLM 2, one of Googles’ text-generating AI models, and “[draws] inspiration from the lyrical and linguistic techniques [Fiasco] has developed throughout his career.”

Image Credits: Google
This reporter expected TextFX to be a more or less automated lyrics generator. But it’s certainly not that. Instead, TextFX is a suite of modules designed to aid in the lyrics-writing process, including a module that finds words in a category starting with a chosen letter and a module that finds similarities between two unrelated things.

Image Credits: Google
TextFX takes a while to get the hang of. But I can see it becoming a useful resource for lyricists — and writers in general, frankly.
You’ll want to closely review its outputs, though. Google warns that TextFX “may display inaccurate info, including about people,” and I indeed managed to prompt it to suggest that climate change “is a hoax perpetrated by the Chinese government to hurt American businesses.” Yikes.

Image Credits: Google
Questions remain
With MusicFX and TextFX, Google’s signaling that it’s heavily invested in GenAI music tech. But I wonder whether its preoccupation with keeping up with the Joneses rather than addressing the tough questions surrounding GenAI music will serve it well in the end.Increasingly, homemade tracks that use GenAI to conjure familiar sounds and vocals that can be passed off as authentic, or at least close enough, have been going viral. Music labels have been quick to flag AI-generated tracks to streaming partners like Spotify and SoundCloud, citing intellectual property concerns. They’ve generally been victorious. But there’s still a lack of clarity on whether “deepfake” music violates the copyright of artists, labels and other rights holders.
A federal judge ruled in August that AI-generated art can’t be copyrighted. However, the U.S. Copyright Office hasn’t taken a stance yet, only recently beginning to seek public input on copyright issues as they relate to AI. Also unclear is whether users could find themselves on the hook for violating copyright law if they try to commercialize music generated in the style of another artist.
Google’s attempting to forge a careful path toward deploying GenAI music tools on the YouTube side of its business, which is testing AI models created by DeepMind in partnership with artists like Alec Benjamin, Charlie Puth, Charli XCX, Demi Lovato, John Legend, Sia and T-Pain. That’s more than can be said of some of the tech giant’s GenAI competitors, like Stability AI, which takes the position that “fair use” justifies training on content without the creator’s permission.
But with labels suing GenAI vendors over copyrighted lyrics in training data and artists registering their discontent, Google has its work cut out for it — and it’s not letting that inconvenient fact slow it down.

Google's MobileDiffusion generates AI images on mobile devices in less than a second
Google's MobileDiffusion is a fast and efficient way to create images from text on smartphones.
 the-decoder.com
the-decoder.com
AI research
Feb 3, 2024
Google's MobileDiffusion generates AI images on mobile devices in less than a second
Google
Jonathan Kemper
Jonathan works as a technology journalist who focuses primarily on how easily AI can already be used today and how it can support daily life.
Profile
Summary
Google's MobileDiffusion is a fast and efficient way to create images from text on smartphones.
MobileDiffusion is Google's latest development in text-to-image generation. Designed specifically for smartphones, the diffusion model generates high-quality images from text input in less than a second.
With a model size of only 520 million parameters, it is significantly smaller than models with billions of parameters such as Stable Diffusion and SDXL, making it more suitable for use on mobile devices.
The researchers' tests show that MobileDiffusion can generate images with a resolution of 512 x 512 pixels in about half a second on both Android smartphones and iPhones. The output is continuously updated as you type, as Google's demo video shows.
Video Player
Video: Google
MobileDiffusion consists of three main components: a text encoder, a diffusion network, and an image decoder.
The UNet contains a self-attention layer, a cross-attention layer, and a feed-forward layer, which are crucial for text comprehension in diffusion models.
However, this layered architecture is computationally complex and resource intensive. Google uses a so-called UViT architecture, in which more transformer blocks are placed in a low-dimensional region of the UNet to reduce resource requirements.
In addition, distillation and a Generative Adversarial Network (GAN) hybrid are used for one- to eight-level sampling.

 Qwen's latest open source work, Qwen1.5, says hello to the world !!
Qwen's latest open source work, Qwen1.5, says hello to the world !! More sizes: six sizes for your different needs. 0.5B, 1.8B, 4B, 7B, 14B and 72B, including Base and Chat. Better alignment: despite still trailing behind GPT-4-Turbo, the largest open-source Qwen1.5-72B-Chat, exhibits superior performance, surpassing Claude-2.1, GPT-3.5-Turbo-0613, on both MT-Bench and Alpaca-Eval v2.
More sizes: six sizes for your different needs. 0.5B, 1.8B, 4B, 7B, 14B and 72B, including Base and Chat. Better alignment: despite still trailing behind GPT-4-Turbo, the largest open-source Qwen1.5-72B-Chat, exhibits superior performance, surpassing Claude-2.1, GPT-3.5-Turbo-0613, on both MT-Bench and Alpaca-Eval v2. Blog: Introducing Qwen1.5
Blog: Introducing Qwen1.5 Demo: Qwen1.5 72B Chat - a Hugging Face Space by Qwen
Demo: Qwen1.5 72B Chat - a Hugging Face Space by Qwen Models: Qwen (Qwen)
Models: Qwen (Qwen) Github: GitHub - QwenLM/Qwen1.5: Qwen1.5 is the improved version of Qwen, the large language model series developed by Qwen team, Alibaba Cloud.
Github: GitHub - QwenLM/Qwen1.5: Qwen1.5 is the improved version of Qwen, the large language model series developed by Qwen team, Alibaba Cloud.Introducing Qwen1.5
GITHUB HUGGING FACE MODELSCOPE DEMO DISCORD Introduction In recent months, our focus has been on developing a “good” model while optimizing the developer experience. As we progress towards Qwen1.5, the next iteration in our Qwen series, this update arrives just before the Chinese New Year. With...
Introducing Qwen1.5
February 4, 2024 · 14 min · 2835 words · Qwen Team | Translations:GITHUB HUGGING FACE MODELSCOPE DEMO DISCORD
Introduction
In recent months, our focus has been on developing a “good” model while optimizing the developer experience. As we progress towards Qwen1.5, the next iteration in our Qwen series, this update arrives just before the Chinese New Year.
With Qwen1.5, we are open-sourcing base and chat models across six sizes: 0.5B, 1.8B, 4B, 7B, 14B, and 72B. In line with tradition, we’re also providing quantized models, including Int4 and Int8 GPTQ models, as well as AWQ and GGUF quantized models. To enhance the developer experience, we’ve merged Qwen1.5’s code into Hugging Face transformers, making it accessible with
transformers>=4.37.0 without needing trust_remote_code.We’ve collaborated with frameworks like vLLM, SGLang for deployment, AutoAWQ, AutoGPTQ for quantization, Axolotl, LLaMA-Factory for finetuning, and llama.cpp for local LLM inference, all of which now support Qwen1.5. The Qwen1.5 series is available on platforms such as Ollama and LMStudio. Additionally, API services are offered not only on DashScope but also on together.ai, with global accessibility. Visit here to get started, and we recommend trying out Qwen1.5-72B-chat.

This release brings substantial improvements to the alignment of chat models with human preferences and enhanced multilingual capabilities. All models now uniformly support a context length of up to 32768 tokens. There have also been minor improvements in the quality of base language models that may benefit your finetuning endeavors. This step represents a small stride toward our objective of creating a truly “good” model.
Performance
To provide a better understanding of the performance of Qwen1.5, we have conducted a comprehensive evaluation of both base and chat models on different capabilities, including basic capabilities such as language understanding, coding, reasoning, multilingual capabilities, human preference, agent, retrieval-augmented generation (RAG), etc.Basic Capabilities
To assess the basic capabilities of language models, we have conducted evaluations on traditional benchmarks, including MMLU (5-shot), C-Eval, Humaneval, GS8K, BBH, etc.
At every model size, Qwen1.5 demonstrates strong performance across the diverse evaluation benchmarks. In particular, Qwen1.5-72B outperforms Llama2-70B across all benchmarks, showcasing its exceptional capabilities in language understanding, reasoning, and math.
In light of the recent surge in interest for small language models, we have compared Qwen1.5 with sizes smaller than 7 billion parameters, against the most outstanding small-scale models within the community. The results are shown below:

We can confidently assert that Qwen1.5 base models under 7 billion parameters are highly competitive with the leading small-scale models in the community. In the future, we will continue to improve the quality of small models and exploring methods for effectively transferring the advanced capabilities inherent in larger models into the smaller ones.
Aligning with Human Preference
Alignment aims to enhance instruction-following capabilities of LLMs and help provide responses that are closely aligned with human preferences. Recognizing the significance of integrating human preferences into the learning process, we effectively employed techniques such as Direct Policy Optimization (DPO) and Proximal Policy Optimization (PPO) in aligning the latest Qwen series.However, assessing the quality of such chat models poses a significant challenge. Admittedly, while comprehensive human evaluation is the optimal approach, it faces significant challenges pertaining to scalability and reproducibility. Therefore, we initially evaluate our models on two widely-used benchmarks, utilizing advanced LLMs as judges: MT-Bench and Alpaca-Eval. The results are presented below:

We notice there are non-negligible variance in the scores on MT-Bench. So we have three runs with different seeds in our results and we report the average score with standard deviation.

Despite still significantly trailing behind GPT-4-Turbo, the largest open-source Qwen1.5 model, Qwen1.5-72B-Chat, exhibits superior performance, surpassing Claude-2.1, GPT-3.5-Turbo-0613, Mixtral-8x7b-instruct, and TULU 2 DPO 70B, being on par with Mistral Medium, on both MT-Bench and Alpaca-Eval v2.
Furthermore, although the scoring of LLM Judges may seemingly correlate with the lengths of responses, our observations indicate that our models do not generate lengthy responses to manipulate the bias of LLM judges. The average length of Qwen1.5-Chat on AlpacaEval 2.0 is only 1618, which aligns with the length of GPT-4 and is shorter than that of GPT-4-Turbo. Additionally, our experiments with our web service and app also reveal that users prefer the majority of responses from the new chat models.
Multilingual Understanding of Base Models
We have carefully selected a diverse set of 12 languages from Europe, East Asia, and Southeast Asia to thoroughly evaluate the multilingual capabilities of our foundational model. In order to accomplish this, we have curated test sets from the community’s open-source repositories, covering four distinct dimensions: Exams, Understanding, Translation, and Math. The table below provides detailed information about each test set, including evaluation settings, metrics, and the languages they encompass:
The base models of Qwen1.5 showcase impressive multilingual capabilities, as demonstrated by its performance across a diverse set of 12 languages. In evaluations covering various dimensions such as exams, understanding, translation, and math, Qwen1.5 consistently delivers strong results. From languages like Arabic, Spanish, and French to Japanese, Korean, and Thai, Qwen1.5 demonstrates its ability to comprehend and generate high-quality content across different linguistic contexts. To take a step further, we evaluate the multilingual capabilities of chat models in a number of languages by calculating the win-tie rate against GPT-4. Results are shown below:

These results demonstrate the strong multilingual capabilities of Qwen1.5 chat models, which can serve downstream applications, such as translation, language understanding, and multilingual chat. Also, we believe that the improvements in multilingual capabilities can also level up the general capabilities.
Support of Long Context
With the increasing demand for long-context understanding, we have expanded the capability of all models to support contexts up to 32K tokens. We have evaluated the performance of Qwen1.5 models on the L-Eval benchmark, which measures the ability of models to generate responses based on long context. The results are shown below:
In terms of the performance, even a small model like Qwen1.5-7B-Chat demonstrates competitive performance against GPT-3.5 on 4 out of 5 tasks. Our best model, Qwen1.5-72B-Chat, significantly outperforms GPT3.5-turbo-16k and only slightly falls behind GPT4-32k. These results highlight our outstanding performance within 32K tokens, yet they do not imply that our models are limited to supporting only 32K tokens. You can modify
max_position_embedding in config.json to a larger value to see if the model performance is still satisfactory for your tasks.Capabilities to Connect with External Systems
Large language models (LLMs) are popular in part due to their ability to integrate external knowledge and tools. Retrieval-Augmented Generation (RAG) has gained traction as it mitigates common LLM issues like hallucination, real-time data shortage, and private information handling. Additionally, strong LLMs typically excel at using APIs and tools via function calling, making them ideal for serving as AI agents.We first assess the performance of Qwen1.5-Chat on RGB, an RAG benchmark for which we have not performed any specific optimization:

GitHub - QwenLM/Qwen1.5: Qwen1.5 is the improved version of Qwen, the large language model series developed by Qwen team, Alibaba Cloud.
Qwen1.5 is the improved version of Qwen, the large language model series developed by Qwen team, Alibaba Cloud. - GitHub - QwenLM/Qwen1.5: Qwen1.5 is the improved version of Qwen, the large languag...
 github.com
github.com
About
Qwen1.5 is the improved version of Qwen, the large language model series developed by Qwen team, Alibaba Cloud.




ShinojiResearch/Senku-70B-Full · Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co

BRIA RMBG 1.4 - a Hugging Face Space by briaai
Discover amazing ML apps made by the community
huggingface.co

briaai/RMBG-1.4 · Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co
BRIA Background Removal v1.4 Model Card
RMBG v1.4 is our state-of-the-art background removal model, designed to effectively separate foreground from background in a range of categories and image types. This model has been trained on a carefully selected dataset, which includes: general stock images, e-commerce, gaming, and advertising content, making it suitable for commercial use cases powering enterprise content creation at scale. The accuracy, efficiency, and versatility currently rival leading open source models. It is ideal where content safety, legally licensed datasets, and bias mitigation are paramount.Developed by BRIA AI, RMBG v1.4 is available as an open-source model for non-commercial use.
CLICK HERE FOR A DEMO

Model Description
- Developed by: BRIA AI
- Model type: Background Removal
- License: bria-rmbg-1.4
- The model is released under an open-source license for non-commercial use.
- Commercial use is subject to a commercial agreement with BRIA. Contact Us for more information.
- Model Description: BRIA RMBG 1.4 is a saliency segmentation model trained exclusively on a professional-grade dataset.
- BRIA: Resources for more information: BRIA AI

Computer Science > Computation and Language
[Submitted on 11 Dec 2023 (v1), last revised 3 Jan 2024 (this version, v2)]EQ-Bench: An Emotional Intelligence Benchmark for Large Language Models
Samuel J. PaechWe introduce EQ-Bench, a novel benchmark designed to evaluate aspects of emotional intelligence in Large Language Models (LLMs). We assess the ability of LLMs to understand complex emotions and social interactions by asking them to predict the intensity of emotional states of characters in a dialogue. The benchmark is able to discriminate effectively between a wide range of models. We find that EQ-Bench correlates strongly with comprehensive multi-domain benchmarks like MMLU (Hendrycks et al., 2020) (r=0.97), indicating that we may be capturing similar aspects of broad intelligence. Our benchmark produces highly repeatable results using a set of 60 English-language questions. We also provide open-source code for an automated benchmarking pipeline at this https URL and a leaderboard at this https URL
| Subjects: | Computation and Language (cs.CL); Artificial Intelligence (cs.AI) |
| ACM classes: | I.2.7 |
| Cite as: | arXiv:2312.06281 [cs.CL] |
| (or arXiv:2312.06281v2 [cs.CL] for this version) | |
| [2312.06281] EQ-Bench: An Emotional Intelligence Benchmark for Large Language Models Focus to learn more |
Submission history
From: Samuel Paech [view email][v1] Mon, 11 Dec 2023 10:35:32 UTC (405 KB)
[v2] Wed, 3 Jan 2024 12:20:35 UTC (405 KB)

Playground | Windsurf Editor and Codeium extensions
Experience the power of Codeium right in your browser. No account or download needed. See how you could level up your development experience for free today.
Codeium-powered code editor
Last edited:
3 rounds of self-improvement seem to be a saturation limit for LLMs. I haven't yet seen a compelling demo of LLM self-bootstrapping that is nearly as good as AlphaZero, which masters Go, Chess, and Shogi from scratch by nothing but self-play.
Reading "Self-Rewarding Language Models" from Meta (arxiv.org/abs/2401.10020). It's a very simple idea that iteratively bootstraps a single LLM that proposes prompt, generates response, and rewards itself. The paper says that reward modeling ability, which is no longer a fixed & separate model, improves along with the main model. Yet it still saturates after 3 iterations, which is the maximum shown in the experiments.
Thoughts:
- Saturation happens because the rate of improvement for reward modeling (critic) is slower than that for generation (actor). At the beginning, there is always a gap to be exploited because classification is inherently easer than generation. But actor eventually catches up with critic in just 3 rounds, even though both are improving.
- In another paper, "Reinforced Self-Training (ReST) for Language Modeling" (arxiv.org/abs/2308.08998), the iteration number is also 3 before hitting diminishing returns.
- I don't think the gap between critic and actor is sustainable unless there is an external driving signal, such as symbolic theorem verification, unit test suites, or compiler feedbacks. But these are highly specialized to a particular domain and not enough for the general-purpose self-improvement we dream of.
Lots of research ideas to be explored here.