AlphaCodium - super interesting work that shows just how much alpha (no pun intended) is there from building complex prompt flows in this case for code generation.
It achieves better results than DeepMind's AlphaCode with 4 orders of magnitude fewer LLM calls! This is a direct consequence of the brute force approach that AlphaCode took generating ~100k solutions and then filtering them down (the recently announced AlphaCode2 is much more sample efficient though).
The framework is agnostic to the choice of the underlying LLM. On the validation set with GPT-4 they increase the pass@5 accuracy from 19 -> 44%.
There are 2 steps in the pipeline (and definitely reminds me of Meta's Self-Rewarding Language Models work I shared yesterday):
1) Pre-processing -> transforming the original problem statement into something more concise and parsable by the model, forcing the model to explain the results (why test input leads to a certain output), rank various solutions, etc.
2) Iterative loop where the model fixes its solution code against a set of tests
I feel ultimately we'll want this to be a part of the LLM training process as well and not something we append ad-hoc, but definitely exciting to see how much low hanging fruit is still out there!
Paper:
Code generation problems differ from common natural language problems - they require matching the exact syntax of the target language, identifying happy paths and edge cases, paying attention to numerous small details in the problem spec, and addressing other code-specific issues and...

arxiv.org
Official implementation for the paper: "Code Generation with AlphaCodium: From Prompt Engineering to Flow Engineering"" - Codium-ai/AlphaCodium

github.com
Read about State-of-the-art Code Generation with AlphaCodium - From Prompt Engineering to Flow Engineering in our blog.

www.codium.ai
State-of-the-art Code Generation with AlphaCodium – From Prompt Engineering to Flow Engineering
TECHNOLOGY
Tal RidnikJanuary 17, 2024 • 17 min read
TL;DR
Code generation problems differ from common natural language problems – they require matching the exact syntax of the target language, identifying happy paths and edge cases, paying attention to numerous small details in the problem spec, and addressing other code-specific issues and requirements. Hence, many of the optimizations and tricks that have been successful in natural language generation may not be effective for code tasks.
In this work, we propose a new approach to code generation by LLMs, which we call
AlphaCodium – a test-based, multi-stage, code-oriented iterative flow, that improves the performances of LLMs on code problems.
We tested AlphaCodium on a challenging code generation dataset called CodeContests, which includes competitive programming problems from platforms such as Codeforces. The proposed flow consistently and significantly improves results.
On the validation set, for example, GPT-4 accuracy (pass@5) increased from 19% with a single well-designed direct prompt to 44% with the AlphaCodium flow. AlphaCodium also outperforms previous works, such as AlphaCode, while having a significantly smaller computational budget.
Many of the principles and best practices acquired in this work, we believe, are broadly applicable to general code generation tasks.
In our very new open-source on
AlphaCodium2.3K we share our AlphaCodium solution to CodeContests, along with a complete reproducible dataset evaluation and benchmarking scripts, to encourage further research in this area.
CodeContests dataset
CodeContests is a challenging code generation dataset introduced by Google’s Deepmind, involving problems curated from competitive programming platforms such as
Codeforces. The dataset contains ~10K problems that can be used to train LLMs, as well as a validation and test set to assess the ability of LLMs to solve challenging code generation problems.
In this work, instead of training a dedicated model, we focused on developing a code-oriented flow, that can be applied to any LLM pre-trained to support coding tasks, such as GPT or DeepSeek. Hence, we chose to ignore the train set, and focused on the validation and test sets of CodeContests, which contain 107 and 165 problems, respectively. Figure 1 depicts an example of a typical problem from CodeContests dataset:
Figure 1. A typical CodeContests problem.
Each problem consists of a description and public tests, available as inputs to the model. The goal is to generate a code solution that produces the correct output for any (legal) input. A private test set, which is not available to the model or contesters, is used to evaluate the submitted code solutions.
What makes CodeContests a good dataset for evaluating LLMs on code generation tasks?
1) CodeContests, unlike many other competitive programming datasets, utilizes a comprehensive private set of tests to avoid false positives – each problem contains ~200 private input-output tests the generated code solution must pass.
2) LLMs generally do not excel at paying attention to small details because they typically transform the problem description to some “average” description, similar to common cases on which they were trained. Real-world problems, on the other hand, frequently contain minor details that are critical to their proper resolution. A key feature of CodeContests dataset is that the problem descriptions are, by design, complicated and lengthy, with small details and nuances (see a typical problem description in Figure 1). We feel that adding this degree of freedom of problem understanding is beneficial since it simulates real-life problems, which are often complicated and involve multiple factors and considerations. This is in contrast to more common code datasets such as
HumanEval, where the problems are easier and presented in a concise manner. An example of a typical HumanEval code problem appears in Appendix 1.
Figure 2 depicts the model’s introspection on the problem presented in Figure 1. Note that proper self-reflection makes the problem clearer and more coherent. This illustrates the importance of problem understanding as part of a flow that can lead with high probability to a correct code solution.
Figure 2. An AI-generated self-reflection on the problem presented in Figure 1.
The proposed flow
Due to the complicated nature of code generation problems, we observed that single-prompt optimizations, or even chain-of-thought prompts, have not led to meaningful improvement in the solve ratio of LLMs on CodeContest. The model struggles to understand and “digest” the problem and continuously produces wrong code, or a code that fails to generalize to unseen private tests. Common flows, that are suitable for natural language tasks, may not be optimal for code-generation tasks, which include an untapped potential – repeatedly running the generated code, and validating it against known examples.
Instead of common prompt engineering techniques used in NLP, we found that to solve CodeContest problems it was more beneficial to employ a dedicated code-generation and testing-oriented
flow, that revolves around an
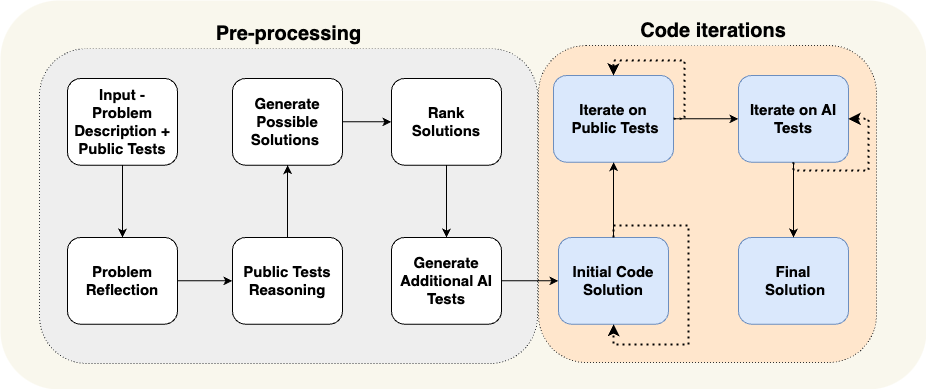
iterative process where we repeatedly run and fix the generated code against input-output tests. Two key elements for this code-oriented flow are (a) generating additional data in a pre-processing stage, such as self-reflection and public tests reasoning, to aid the iterative process, and (b) enrichment of the public tests with additional AI-generated tests.
In Figure 3 we present our proposed flow for solving competitive programming problems:
Figure 3. The proposed AlphaCodium flow.
continue reading on site
Santiago
@svpino
Jan 18
Jan 18
We are one step closer to having AI generate code better than humans!
There's a new open-source, state-of-the-art code generation tool. It's a new approach that improves the performance of Large Language Models generating code.
The paper's authors call the process "AlphaCodium" and tested it on the CodeContests dataset, which contains around 10,000 competitive programming problems.
The results put AlphaCodium as the best approach to generate code we've seen. It beats DeepMind's AlphaCode and their new AlphaCode2 without needing to fine-tune a model!
I'm linking to the paper, the GitHub repository, and a blog post below, but let me give you a 10-second summary of how the process works:
Instead of using a single prompt to solve problems, AlphaCodium relies on an iterative process that repeatedly runs and fixes the generated code using the testing data.
1. The first step is to have the model reason about the problem. They describe it using bullet points and focus on the goal, inputs, outputs, rules, constraints, and any other relevant details.
2. Then, they make the model reason about the public tests and come up with an explanation of why the input leads to that particular output.
3. The model generates two to three potential solutions in text and ranks them in terms of correctness, simplicity, and robustness.
4. Then, it generates more diverse tests for the problem, covering cases not part of the original public tests.
5. Iteratively, pick a solution, generate the code, and run it on a few test cases. If the tests fail, improve the code and repeat the process until the code passes every test.

 the-decoder.com
the-decoder.com