
You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
Chinese EV giant BYD says self-driving tech is more valuable for factories than cars and Fully Autonomous Driving Is “Basically Impossible”
- Thread starter Chronic
- Start date
More options
Who Replied?How does a still photo equate to a constantly moving environment? AI extrapolates based on previous information.
The road is a constant barrage of new information.
videos are still photos that move quickly, the photos are referred to as frames. video creates the illusion of movement by taking those still photos and displaying them quickly.
AI can extrapolate information around the entire car with enough cameras and processing power.
Visual Instruction Tuning
LLaVA: Large Language and Vision Assistant
LLaVA represents a novel end-to-end trained large multimodal model that combines a vision encoder and Vicuna for general-purpose visual and language understanding, achieving impressive chat capabilities mimicking spirits of the multimodal GPT-4 and setting a new state-of-the-art accuracy on Science QA.
Abstract
Instruction tuning large language models (LLMs) using machine-generated instruction-following data has improved zero-shot capabilities on new tasks in the language domain, but the idea is less explored in the multimodal field.
- Multimodal Instruct Data. We present the first attempt to use language-only GPT-4 to generate multimodal language-image instruction-following data.
- LLaVA Model. We introduce LLaVA (Large Language-and-Vision Assistant), an end-to-end trained large multimodal model that connects a vision encoder and LLM for general-purpose visual and language understanding.
- Performance. Our early experiments show that LLaVA demonstrates impressive multimodel chat abilities, sometimes exhibiting the behaviors of multimodal GPT-4 on unseen images/instructions, and yields a 85.1% relative score compared with GPT-4 on a synthetic multimodal instruction-following dataset. When fine-tuned on Science QA, the synergy of LLaVA and GPT-4 achieves a new state-of-the-art accuracy of 92.53%.
- Open-source. We make GPT-4 generated visual instruction tuning data, our model and code base publicly available.
Multimodal Instrucion-Following Data
Based on the COCO dataset, we interact with langauge-only GPT-4, and collect 158K unique language-image instruction-following samples in total, including 58K in conversations, 23K in detailed description, and 77k in complex reasoning, respectively. Please check out ``LLaVA-Instruct-150K''' on [HuggingFace Dataset].
LLaVA: Large Language-and-Vision Assistant
LLaVa connects pre-trained CLIP ViT-L/14 visual encoder and large language model LLaMA, using a simple projection matrix. We consider a two-stage instruction-tuning procedure:
Please check out ``LLaVA-13b-delta-v0'' model checkpoint on [HuggingFace Models].
- Stage 1: Pre-training for Feature Alignment. Only the projection matrix is updated, based on a subset of CC3M.
- Stage 2: Fine-tuning End-to-End.. Both the projection matrix and LLM are updated for two different use senarios:
- Visual Chat: LLaVA is fine-tuned on our generated multimodal instruction-following data for daily user-oriented applications.
- Science QA: LLaVA is fine-tuned on this multimodal reasonsing dataset for the science domain.

Performance
Visual Chat: Towards building multimodal GPT-4 level chatbot
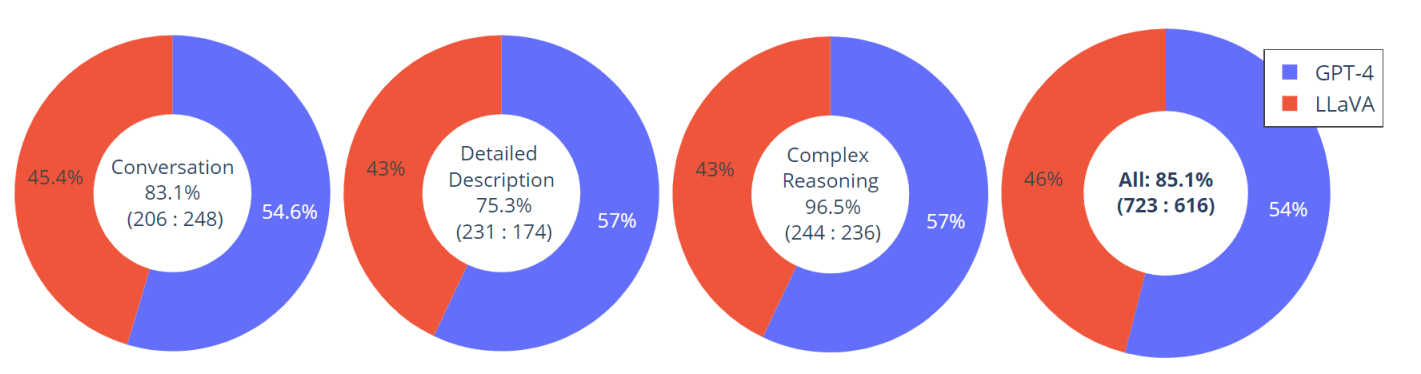
An evaluation dataset with 30 unseen images is constructed: each image is assocaited with three types of instructions: conversation, detailed description and complex reasoning. This leads to 90 new language-image instructions, on which we test LLaVA and GPT-4, and use GPT-4 to rate their responses from score 1 to 10. The summed score and relative score per type is reported. Overall, LLaVA achieves 85.1% relative score compared with GPT-4, indicating the effectinvess of the proposed self-instruct method in multimodal settings
Science QA: New SoTA with the synergy of LLaVA with GPT-4
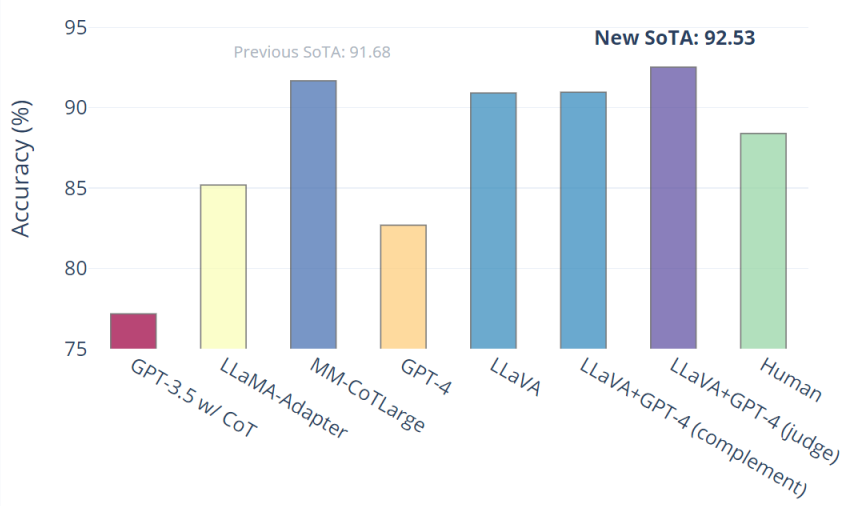
LLaVA alones achieve 90.92%. We use the text-only GPT-4 as the juedge, to predict the final answer based on its own previous answers and the LLaVA answers. This ``GPT-4 as juedge'' scheme yields a new SOTA 92.53%.
Examples on Visual Instruction Following
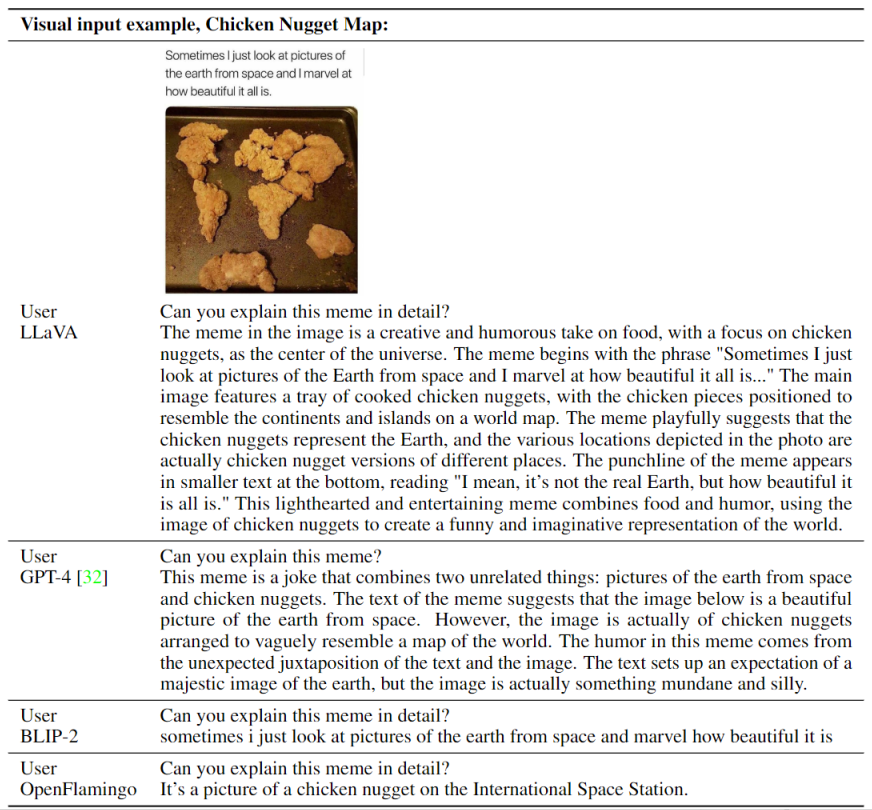
Visual Reasoning on two examples from OpenAI GPT-4 Technical Report

Optical character recognition (OCR)

GitHub - haotian-liu/LLaVA: [NeurIPS'23 Oral] Visual Instruction Tuning (LLaVA) built towards GPT-4V level capabilities and beyond.
[NeurIPS'23 Oral] Visual Instruction Tuning (LLaVA) built towards GPT-4V level capabilities and beyond. - haotian-liu/LLaVAgithub.com
edit:
Last edited:
Ford is using mobileye tech.I THINK THEY ARE RIGHT. LEVEL 5 IS OUT OF REACH RIGHT NOW. MIGHT BE FOREVER.
FORD DROPPED OUT OF THE AUTONOMOUS GAME LAST YEAR. EVERYBODY ELSE IS JUST WAITING. LEVEL 3 IS PROBABLY AS FAR AS WE GO ON A MAINSTREAM LEVEL.
Eternal Tecate
Superstar
China focuses on actual material reality while we stare at screens.
SadimirPutin
Superstar
People wildly overestimated and still do how difficult self driving AI is.......
Basically any demo you see is a highly curated sandbox that bears little resemblance to real life traffic patterns involving humans(who drive like racc00ns on cocaine)
Basically any demo you see is a highly curated sandbox that bears little resemblance to real life traffic patterns involving humans(who drive like racc00ns on cocaine)
Meanwhile Tesla is killing people with a beta test.
Jeh just working out the kinks.

not all detection systems are the same and it's likely to change with advances in AI
null
...
I always figured unless every vehicle on the road was on the grid ...
what about other road users ? pedestrians, cyclists, mopeds, animals even ?
... then self driving cars wouldn’t work out as well as intended. I wouldn’t want an AI to deal with the clowns driving on the road.
People wildly overestimated and still do how difficult self driving AI is.......
Basically any demo you see is a highly curated sandbox that bears little resemblance to real life traffic patterns involving humans(who drive like racc00ns on cocaine)
YEP.
LEVEL 3. IM TALKING LEVEL 5 FULL AUTONOMOUS. FORD STOPPED DEVELOPMENT.Ford is using mobileye tech.
They're talking about fully autonomous vehicle as in without driver at all. Sending unmanned vehicle without driver to take control in emergency is still too dangerous.Also GM's super cruise feature is basically autonomous driving... on board cam monitors your eyes to make sure you are watching the road and the vehicle will drive itself without your input
Last edited:

The 6 Levels of Vehicle Autonomy Explained | Synopsys Automotive
Before merging onto roadways, self-driving cars will have to progress through 6 levels of driver assistance technology advancements. SAE defines 6 levels of driving automation ranging from 0 (fully manual) to 5 (fully autonomous). Learn more.
 www.synopsys.com
www.synopsys.com
SEEMS THERE IS SOME CONFUSION.
People wildly overestimated and still do how difficult self driving AI is.......
Basically any demo you see is a highly curated sandbox that bears little resemblance to real life traffic patterns involving humans(who drive like racc00ns on cocaine)
Which is exactly why it COULD happen. The autonomous driving literally couldnt be worst than humans

But then once you start factoring in wrongful death lawsuits from the handful of accidents they probably will have. Along with the fact psychologically I think the majority of people dont feel comfortable letting a robot fully drive them around. Will they sell enough of these cars for it to be worth the liability,court cost? Potential maintenence,and requirements they may be responsible for?
I dont think China has these same problems though.
Json
Superstar
videos are still photos that move quickly, the photos are referred to as frames. video creates the illusion of movement by taking those still photos and displaying them quickly.
AI can extrapolate information around the entire car with enough cameras and processing power.
None of that simulates the information for avoiding a crash though. Accidents don’t start in still moments. It’s not an illusion of movement.
I lost my front fender because a piece of debris shot out from the car in front of me under its tire. If I had suddenly changed lanes to avoid the debris I could have hit the car in either lane. AI can‘t see around a car a few feet ahead.
Like someone else said, unless all cars are hooked up to overhead camera with a Birds Eye view. It’s still subject to limited information
None of that simulates the information for avoiding a crash though. Accidents don’t start in still moments. It’s not an illusion of movement.
I lost my front fender because a piece of debris shot out from the car in front of me under its tire. If I had suddenly changed lanes to avoid the debris I could have hit the car in either lane. AI can‘t see around a car a few feet ahead.
Like someone else said, unless all cars are hooked up to overhead camera with a Birds Eye view. It’s still subject to limited information
I never claimed AI will be able to avoid an unavoidable accident.
some systems can see more than a few feet ahead.

Subaru, Volvo take different approaches to applying AI to vehicle safety systems
Volvo and Subaru are both incorporating artificial intelligence (AI) into their vehicles’ safety technologies, though the two OEMs are taking different approaches. Subaru is building AI into …
 www.repairerdrivennews.com
www.repairerdrivennews.com