

New Open-Source ‘Falcon’ AI Language Model Overtakes Meta and Google - Decrypt
Meta's massive, 70-billion parameter LLaMA 2 has been outflanked by the newly released 180-billion parameter Falcon Large Language Model.
 decrypt.co
decrypt.co
New Open-Source ‘Falcon’ AI Language Model Overtakes Meta and Google
Meta's massive, 70-billion parameter LLaMA 2 has been outflanked by the newly released 180-billion parameter Falcon Large Language Model.
Jose Antonio Lanz - DecryptBy Jose Antonio Lanz
Sep 6, 2023
3 min read

The artificial intelligence community has a new feather in its cap with the release of Falcon 180B, an open-source large language model (LLM) boasting 180 billion parameters trained on a mountain of data. This powerful newcomer has surpassed prior open-source LLMs on several fronts.
Announced in a blog post by the Hugging Face AI community, Falcon 180B has been released on Hugging Face Hub. The latest-model architecture builds on the previous Falcon series of open source LLMs, leveraging innovations like multiquery attention to scale up to 180 billion parameters trained on 3.5 trillion tokens.
This represents the longest single-epoch pretraining for an open source model to date. To achieve such marks, 4,096 GPUs were used simultaneously for around 7 million GPU hours, using Amazon SageMaker for training and refining.
To put the size of Falcon 180B into perspective, its parameters measure 2.5 times larger than Meta's LLaMA 2 model. LLaMA 2 was previously considered the most capable open-source LLM after its launch earlier this year, boasting 70 billion parameters trained on 2 trillion tokens.
Falcon 180B surpasses LLaMA 2 and other models in both scale and benchmark performance across a range of natural language processing (NLP) tasks. It ranks on the leaderboard for open access models at 68.74 points and reaches near parity with commercial models like Google's PaLM-2 on evaluations like the HellaSwag benchmark.
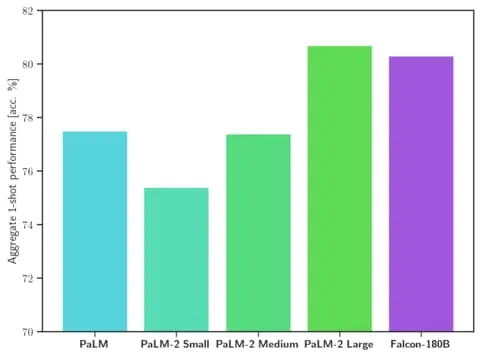
Specifically, Falcon 180B matches or exceeds PaLM-2 Medium on commonly used benchmarks, including HellaSwag, LAMBADA, WebQuestions, Winogrande, and more. It is basically on par with Google’s PaLM-2 Large. This represents extremely strong performance for an open-source model, even when compared against solutions developed by giants in the industry.
When compared against ChatGPT, the model is more powerful than the free version but a little less capable than the paid “plus” service.
“Falcon 180B typically sits somewhere between GPT 3.5 and GPT4 depending on the evaluation benchmark, and further finetuning from the community will be very interesting to follow now that it's openly released.” the blog says.
The release of Falcon 180B represents the latest leap forward in the rapid progress that has recently been made with LLMs. Beyond just scaling up parameters, techniques like LoRAs, weight randomization and Nvidia’s Perfusion have enabled dramatically more efficient training of large AI models.
With Falcon 180B now freely available on Hugging Face, researchers anticipate the model will see additional gains with further enhancements developed by the community. However, its demonstration of advanced natural language capabilities right out of the gate marks an exciting development for open-source AI.
















 This plugin is powered by the E2B API. If you'd like an early access,
This plugin is powered by the E2B API. If you'd like an early access, 
 What can I do with this plugin?
What can I do with this plugin?







 Vector search with SQL, object storage, topic modeling, graph analysis and multimodal indexing
Vector search with SQL, object storage, topic modeling, graph analysis and multimodal indexing Create embeddings for text, documents, audio, images and video
Create embeddings for text, documents, audio, images and video Pipelines powered by language models that run LLM prompts, question-answering, labeling, transcription, translation, summarizations and more
Pipelines powered by language models that run LLM prompts, question-answering, labeling, transcription, translation, summarizations and more ️ Workflows to join pipelines together and aggregate business logic. txtai processes can be simple microservices or multi-model workflows.
️ Workflows to join pipelines together and aggregate business logic. txtai processes can be simple microservices or multi-model workflows. Build with Python or YAML. API bindings available for
Build with Python or YAML. API bindings available for  Cloud-native architecture that scales out with container orchestration systems (e.g. Kubernetes)
Cloud-native architecture that scales out with container orchestration systems (e.g. Kubernetes)





 ) used prompts instead of writing business logic in code, how to identify good candidates for such an approach, how to operationalize and maintain such code, limitations and risks, and more.
) used prompts instead of writing business logic in code, how to identify good candidates for such an approach, how to operationalize and maintain such code, limitations and risks, and more./cloudfront-us-east-2.images.arcpublishing.com/reuters/JSX7UODPNVM4PKCR3XEOWCDN6U.jpg)

 letters and computer motherboard")
