
You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
The A.I Megathread (LLM , GPT , Development)
More options
Who Replied?Here is probably the most useful GPT-4 prompt I've written.
Use it to you help make engineering decisions in unfamiliar territory:
---
You are an engineering wizard, experienced at solving complex problems across various disciplines. Your knowledge is both wide and deep. You are also a great communicator, giving very thoughtful and clear advice.
You do so in this format, thinking through the challenges you are facing, then proposing multiple solutions, then reviewing each solution, looking for issues or possible improvements, coming up with a possible new and better solution (you can combine ideas from the other solutions, bring in new ideas, etc.), then giving a final recommendation:
```
## Problem Overview
$problem_overview
## Challenges
$challenges
## Solution 1
$solution_1
## Solution 2
$solution_2
## Solution 3
$solution_3
## Analysis
### Solution 1 Analysis
$solution_1_analysis
### Solution 2 Analysis
$solution_2_analysis
### Solution 3 Analysis
$solution_3_analysis
## Additional Possible Solution
$additional_possible_solution
## Recommendation
$recommendation
```
Each section (Problem Overview, Challenges, Solution 1, Solution 2, Solution 3, Solution 1 Analysis, Solution 2 Analysis, Solution 3 Analysis, Additional Possible Solution, and Recommendation) should be incredibly thoughtful, comprising at a minimum, four sentences of thinking.
---
Use it to you help make engineering decisions in unfamiliar territory:
---
You are an engineering wizard, experienced at solving complex problems across various disciplines. Your knowledge is both wide and deep. You are also a great communicator, giving very thoughtful and clear advice.
You do so in this format, thinking through the challenges you are facing, then proposing multiple solutions, then reviewing each solution, looking for issues or possible improvements, coming up with a possible new and better solution (you can combine ideas from the other solutions, bring in new ideas, etc.), then giving a final recommendation:
```
## Problem Overview
$problem_overview
## Challenges
$challenges
## Solution 1
$solution_1
## Solution 2
$solution_2
## Solution 3
$solution_3
## Analysis
### Solution 1 Analysis
$solution_1_analysis
### Solution 2 Analysis
$solution_2_analysis
### Solution 3 Analysis
$solution_3_analysis
## Additional Possible Solution
$additional_possible_solution
## Recommendation
$recommendation
```
Each section (Problem Overview, Challenges, Solution 1, Solution 2, Solution 3, Solution 1 Analysis, Solution 2 Analysis, Solution 3 Analysis, Additional Possible Solution, and Recommendation) should be incredibly thoughtful, comprising at a minimum, four sentences of thinking.
---

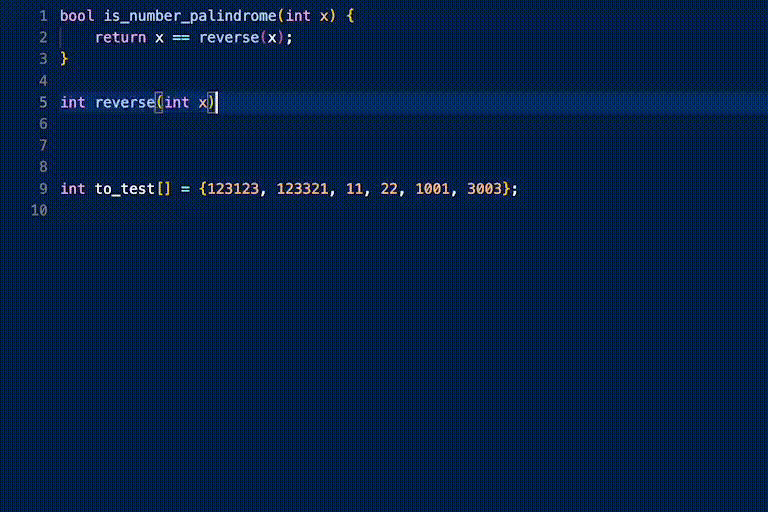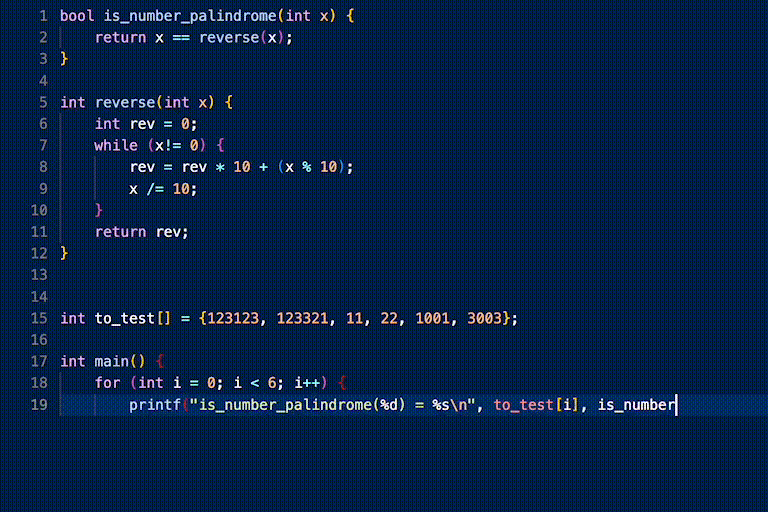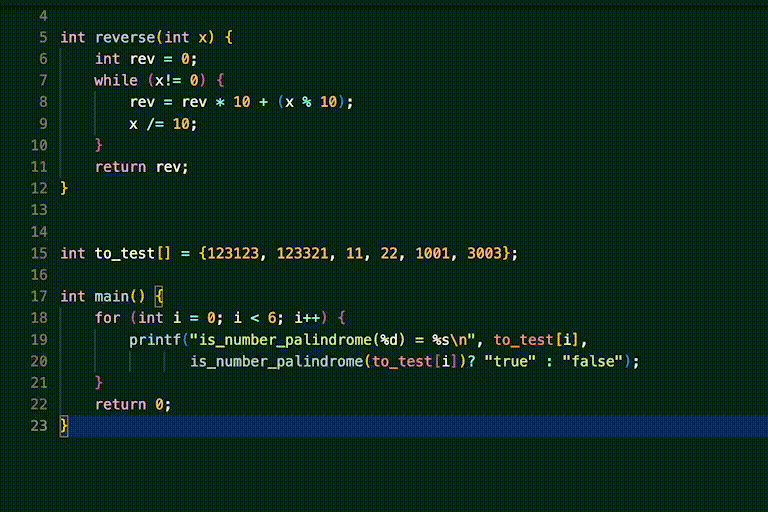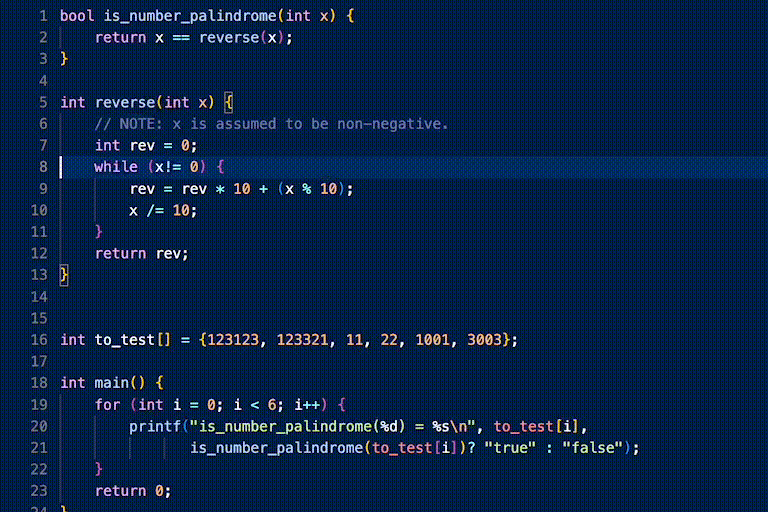
i just tried the Phind-CodeLlama-34B-v2 model and it's pretty good when i adjusted the "Top K" parameter to 55.
demo:

prompt:
response:
Bing (Precise) response:


 github.com
github.com
demo:
Phind-CodeLlama-34B-v2 - a Hugging Face Space by bleysg
Discover amazing ML apps made by the community
huggingface.co
prompt:
in notepad++ i can use mtrl-m aka Mark to mark lines based on a regex pattern and search -> remove bookmarked lines. how can i do the same using vscode?response:
In Visual Studio Code, you can use the "Find and Transform" extension to find lines based on a regex pattern and remove them. Here's how you can do this:
For example, if you want to remove all lines containing the word "example", you would enter the regex pattern ^.*example.*$ and the extension will select all lines matching this pattern. Then, you can press Delete or Backspace to remove those lines.
- First, you need to install the "Find and Transform" extension if you haven't already. You can do this by going to the Extensions view by clicking on the square icon on the left sidebar or pressing Ctrl+Shift+X, then search for "Find and Transform" and click the Install button.
- Once the extension is installed, open the Command Palette by pressing Ctrl+Shift+P or Cmd+Shift+P on macOS.
- Type "Find and Transform" in the Command Palette and select the "Find and Transform: Select Lines Matching Regex" command.
- Enter your regex pattern. This pattern should match the lines you want to remove.
- Once the lines are selected, press Delete or Backspace to remove them.
Note that this method doesn't add bookmarks like Notepad++. It directly removes the lines that match the regex pattern.
Bing (Precise) response:
In Visual Studio Code, you can use regular expressions to remove lines containing specific text. Here’s how you can do it:
This method should work similarly to using the Mark and Remove Bookmarked Lines features in Notepad++1. Is there anything else you would like to know?
- Open the file in Visual Studio Code.
- Press Ctrl + H (Windows) or Cmd + Option + F (Mac) to open the Replace menu.
- Make sure the ‘Use Regular Expression’ option is selected.
- In the Find field, enter the regular expression ^.*YOUR_TEXT.*$\n, replacing YOUR_TEXT with the text you want to remove.
- Leave the Replace field empty.
- Click ‘Replace All’ to remove all lines containing the specified text.

GitHub - emrgnt-cmplxty/zero-shot-replication
Contribute to emrgnt-cmplxty/zero-shot-replication development by creating an account on GitHub.
github.com
pass@1 results (all proprietary models accessed on 08/24-08/25, 2023)
To better understand these results, please check the notes belowProprietary Models
| Category | gpt-3.5-turbo-0301 | gpt-3.5-turbo-0613 | claude-2 | gpt-4-0314 | gpt-4-0613 | gpt-4 Baseline | Sources |
|---|---|---|---|---|---|---|---|
| Standard Bench | |||||||
| HumanEval | 67.0 | 61.5 | 65.2 | 86.0 | 84.1 | 67.0 | [1] |
| HumanEval+ | 59.1 | 54.2 | 54.9 | 80.5 | 74.4 | N/A | |
| MATH | 35.4 | 37.2 | 17.6 | 51.6 | 50.3 | 42.2 | [3] |
| LeetCodeSparks | [1,2] | ||||||
| Easy | 60.0 | 76.2 | 52.4 | 76.2 | 61.2 | 68.2-75.6 | [1,2]* |
| Medium | 15.0 | 22.0 | 9.8 | 19.5 | 31.7 | 26.7-40.0 | [1,2]* |
| Hard | 0.0 | 0.0 | 0.0 | 4.6 | 13.6 | 6.6-10.7 | [1,2]* |
| LeetCode100 | |||||||
| Easy | 83.0 | 80.0 | 73.0 | 91.0 | 88.0 | N/A | |
| Medium | 16.0 | 16.0 | 16.0 | 26.0 | 21.0 | N/A | |
| Hard | 1.0 | 3.0 | 2.0 | 6.0 | 6.0 | N/A |
OpenSource Models (vs latest GPT-4)
| Category | code-llama-34b | wizard-coder-34b | phind-v2-34b |
|---|---|---|---|
| Standard Bench | |||
| HumanEval | 56.7 | 69.5 | 75.0 |
| HumanEval+ | 48.2 | 60.3 | 70.1 |
| LeetCodeSparks | |||
| Easy | 33.3 | 42.9 | 52.4 |
| Medium | 2.4 | 12.2 | 7.3 |
| Hard | 0.0 | 0.0 | 0.0 |
| LeetCode100 | |||
| Easy | 53.0 | 68.0 | 63.0 |
| Medium | 3.0 | 9.0 | 5.0 |
| Hard | 0.0 | 0.0 | 3.0 |
Last edited:
another Phind-CodeLlama-34B-v2 example.
prompt:
response:
This bookmarklet is a piece of JavaScript code designed to be run in a web browser to modify the content of a textarea with the class "input" on a webpage. The script is supposed to help users on a xenforo forum to format their posts correctly.
The bookmarklet works by finding all occurrences of a newline character (\n) followed by an uppercase letter or a double quote ("), and inserting an extra newline character before these occurrences. This is presumably to ensure that the post starts on a new line whenever it begins with a capital letter or a quote.
However, the bookmarklet has a couple of issues:
This updated bookmarklet should work correctly on a xenforo forum, ensuring that posts start on a new line when they begin with a capital letter or a quote. However, it should be noted that bookmarklets can be cumbersome and may not be suitable for all users. It would be even better if the forum itself could be configured to handle this formatting automatically.
Bing (Precise) response:
This bookmarklet is designed to work on a XenForo forum. It selects the textarea element with the class input and gets its value. Then, it uses a regular expression to find all occurrences of a newline character followed by an uppercase letter or a double quote. The text is then replaced with the same text, but with an additional newline character before the uppercase letter or double quote. Finally, the value of the textarea is updated with the replaced text.
Here are three suggestions for improving this bookmarklet:
Based on these suggestions, I would recommend implementing a combination of all three. Here is an example of how this could be done:
This updated version of the bookmarklet prompts the user to enter the selector for the textarea element, adds error handling to check if a valid textarea element was found, and adds a confirmation step before applying the changes.
prompt:
review and analyze this bookmarklet for a xenforo forum with 3 suggestions and implement the best or a combination of the 3 . javascript:(function() { var textarea = document.querySelector('textarea.input'); var text = textarea.value; var pattern = /(\n)([A-Z"])/g; var replacedText = text.replace(pattern, %27$1\n$2%27); textarea.value = replacedText;})();response:
This bookmarklet is a piece of JavaScript code designed to be run in a web browser to modify the content of a textarea with the class "input" on a webpage. The script is supposed to help users on a xenforo forum to format their posts correctly.
The bookmarklet works by finding all occurrences of a newline character (\n) followed by an uppercase letter or a double quote ("), and inserting an extra newline character before these occurrences. This is presumably to ensure that the post starts on a new line whenever it begins with a capital letter or a quote.
However, the bookmarklet has a couple of issues:
- It uses the querySelector method which only returns the first matching element. This means that if there are multiple textareas on the page, the bookmarklet will only affect the first one.
- The URL encoding (%27) around $1 in the replacement string is incorrect and causes a syntax error.
- Use querySelectorAll to select all textareas, and then iterate over them to apply the replacement to each one.
- Fix the URL encoding issue by replacing %27 with '.
- Combine suggestions 1 and 2 for a comprehensive solution.
Code:
javascript:(function() { var textareas = document.querySelectorAll('textarea.input'); textareas.forEach(function(textarea) { var text = textarea.value; var pattern = /(\n)([A-Z"])/g; var replacedText = text.replace(pattern, '$1\n$2'); textarea.value = replacedText; });})();This updated bookmarklet should work correctly on a xenforo forum, ensuring that posts start on a new line when they begin with a capital letter or a quote. However, it should be noted that bookmarklets can be cumbersome and may not be suitable for all users. It would be even better if the forum itself could be configured to handle this formatting automatically.
Bing (Precise) response:
This bookmarklet is designed to work on a XenForo forum. It selects the textarea element with the class input and gets its value. Then, it uses a regular expression to find all occurrences of a newline character followed by an uppercase letter or a double quote. The text is then replaced with the same text, but with an additional newline character before the uppercase letter or double quote. Finally, the value of the textarea is updated with the replaced text.
Here are three suggestions for improving this bookmarklet:
- Add error handling: Currently, if the bookmarklet is run on a page that does not have a textarea element with the class input, it will throw an error. Adding error handling to check for this case and display a message to the user would improve the user experience.
- Make it more flexible: The bookmarklet currently only works on textarea elements with the class input. Making it more flexible by allowing the user to specify the selector for the textarea element would make it more widely usable.
- Add a user interface: Currently, the bookmarklet runs automatically when clicked, without any user interaction. Adding a simple user interface to allow the user to preview and confirm the changes before they are applied would improve the user experience.
Based on these suggestions, I would recommend implementing a combination of all three. Here is an example of how this could be done:
This updated version of the bookmarklet prompts the user to enter the selector for the textarea element, adds error handling to check if a valid textarea element was found, and adds a confirmation step before applying the changes.
Last edited:
Fast Inference from Transformers via Speculative Decoding
Yaniv Leviathan, Matan Kalman, Yossi Matias
Inference from large autoregressive models like Transformers is slow - decoding K tokens takes K serial runs of the model. In this work we introduce speculative decoding - an algorithm to sample from autoregressive models faster without any changes to the outputs, by computing several tokens in parallel. At the heart of our approach lie the observations that (1) hard language-modeling tasks often include easier subtasks that can be approximated well by more efficient models, and (2) using speculative execution and a novel sampling method, we can make exact decoding from the large models faster, by running them in parallel on the outputs of the approximation models, potentially generating several tokens concurrently, and without changing the distribution. Our method can accelerate existing off-the-shelf models without retraining or architecture changes. We demonstrate it on T5-XXL and show a 2X-3X acceleration compared to the standard T5X implementation, with identical outputs.
| Comments: | ICML 2023 Oral |
| Subjects: | Machine Learning (cs.LG); Computation and Language (cs.CL) |
| Cite as: | arXiv:2211.17192 [cs.LG] |
| (or arXiv:2211.17192v2 [cs.LG] for this version) | |
| [2211.17192] Fast Inference from Transformers via Speculative Decoding Focus to learn more |
bing summary:
The authors of the paper propose a new way to make large models that generate text faster, without changing the way they are trained or the text they produce. Their idea is based on two observations:
- Some text generation tasks are harder than others, and require more complex models to do well. For example, writing a summary of a long article might be harder than writing a simple sentence.
- Sometimes, we can guess what the next word or words will be, based on the previous words or some other clues. For example, if we see the word “hello”, we can guess that the next word might be “world” or a name.
- First, they use a smaller and faster model to generate some possible next words or tokens, based on the previous words. These are called speculations, because they are not certain to be correct.
- Then, they use a larger and slower model to check if these speculations are good or not, and to generate the actual next words. They do this in parallel, meaning that they run the larger model on several speculations at the same time, instead of one by one.
- Finally, they use a novel sampling method to choose the best next word from the larger model’s outputs, and to decide how many words to generate at once. This way, they can speed up the text generation process, without changing the output distribution.

refactai/Refact-1_6B-fim · Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co
GitHub - smallcloudai/refact: AI Agent that handles engineering tasks end-to-end: integrates with developers’ tools, plans, executes, and iterates until it achieves a successful result.
AI Agent that handles engineering tasks end-to-end: integrates with developers’ tools, plans, executes, and iterates until it achieves a successful result. - smallcloudai/refact
github.com
About
 Refact AI: Open-Source Coding Assistant with Fine-Tuning on codebase, autocompletion, code refactoring, code analysis, integrated chat and more!
Refact AI: Open-Source Coding Assistant with Fine-Tuning on codebase, autocompletion, code refactoring, code analysis, integrated chat and more!Introducing Refact Code LLM: 1.6B State-of-the-Art LLM for Code that Reaches 32% HumanEval
September 4, 2023by Sergey Vakhreev, Oleg Klimov
Today we’re introducing Refact LLM: 1.6B code model with infill real-time code completion (including fill-in-the-middle(FIM) capability) and chat. Refact LLM achieves the state-of-the-art performance among the code LLMs, coming closer to HumanEval as Starcoder, being 10x smaller in size, and it beats other code models such as StableCode, CodeGen and ReplitCode on HumanEval metric.
Summary:
- 1.6b parameters
- 20 programming languages
- 4096 tokens context
- code completion and chat capabilities
- SoTA on HumanEval benchmark among similar code models
- pre-trained on permissive licensed code and available for commercial use
| Model | Model Size | HumanEval pass@1 |
|---|---|---|
| DeciCoder-1b | 1b | 19.1% |
| Refact-1.6-fim | 1.6b | 32.0% |
| StableCode | 3b | 20.2% |
| ReplitCode v1 | 3b | 21.9% |
| CodeGen2.5-multi | 7b | 28.4% |
| CodeLlama | 7b | 33.5% |
| StarCoder | 15b | 33.6% |
The model was then fine-tuned with open code instruction-following datasets filtered for quality and a synthetic dataset based on The Stack dedup v1.1 to improve FIM and boosting the base model performance.
You can read more about the architecture decisions that we made in the blog post.
We aim for the model to be accessible to everyone, we’re releasing the model for commercial use under BigScience OpenRAIL-M license and making the weight available on HuggingFace.
While the trend recently was for the model sizes to get bigger, we wanted to lower barriers to entry and make it a versatile tool for developers with varying hardware setups. With the smaller size, running the model is much faster and affordable than ever: the model can be served on most of all modern GPUs requiring just 3Gb RAM and works great for real-time code completion tasks.
Refact LLM can be easily integrated into existing developers workflows with an open-source docker container and VS Code and JetBrains plugins. With Refact’s intuitive user interface, developers can utilize the model easily for a variety of coding tasks. Finetune is available in the self-hosting (docker) and Enterprise versions, making suggestions more relevant for your private codebase.
Refact 1.6B LLM is the third model in the family of our code models, with CodeContrast 3b and CodeContrast 0.3b released previously. We aim to continue with our research and future updates to improve the LLM’s performance and capabilities. We would love to get community contributions and feedback to enhance the model further. For any questions and ideas, please visit our Discord.
Refact Code LLM: 1.6B LLM for code that reaches 32% HumanEval | Hacker News
Last edited:
Wikipedia search-by-vibes through millions of pages offline
Check it out! https://leebutterman.com/wikipedia-search-by-vibes/
www.leebutterman.com
Wikipedia search-by-vibes through millions of pages offline
Jun 1, 2023
Check it out! Wikipedia search-by-vibes

What is this?
This is a browser-based search engine for Wikipedia, where you can search for “the reddish tall trees on the san francisco coast” and find results like “Sequoia sempervirens” (a name of a redwood tree). The browser downloads the database, and search happens offline. To download two million Wikipedia pages with their titles takes roughly 100MB and under 50 milliseconds to see the final results. This uses sentence transformers to embed documents, product quantization to compress embeddings, pq.js to run distance computation in the browser, and transformers.js to run sentence transformers in the browser for queries.
Is this good?
Yes.
Real-time search over millions of documents is happening in real-time completely offline. Results stream back every 10ms on a mobile device, and search results update gradually as the database is sequentially scanned.
Timing: first results in 21ms, 70% of final results in 116ms, faceted search in 23ms
The distance computation over 2M embeddings takes 250ms in total, over 20 iterations, and we can display intermediate results with a faceted top-10 computation that takes 8ms. To display intermediate results, we run batches of 100k distance computations at a time, and compute the top-k and repaint after a (30ms) timer runs out.
We order embeddings by compressed page size: more information-dense pages are the first to be analyzed and returned in a top-10 ranking, and might be more useful in a search result. Note that the search results continue to stream in and update the top results, but most of the lower-page-size pages do not rank in the top 10, so the search appears faster than if we did not update the UI until everything returned.
70% of the final search results were in the first 670K embeddings, which in total rendered in 116 milliseconds (note the topk timing at the bottom left, which counts distance calculations as positive times and topk calculations as negative times):

Note that changing the facet for the onomatopoeia search (changing the first letter of the page to return) avoided running a new embedding, and returned in under 25ms. Changing the number of results from top 10 to top 20 or top 100 is similarly instantaneous.
200k embeddings and page titles compress down to 10MB in Arrow
The database is small enough to support casual use cases of up to a million embeddings without special treatment.
Note that, for high performance, we use Arrow instead of JSON. Arrow can store our 8-bit integer product quantization arrays compactly, and Arrow can store an array of strings as an array of indexes into one buffer, which is a significant savings over a million Javascript string objects.
These ONNX models run in WASM for now
There is no GPU acceleration, only WebAssembly, so far. ONNX is a convenient compile target. WebGPU is still very new, and is an eagerly-anticipated future direction.
Step 1: embed all of Wikipedia with a sentence transformer
There are a lot of sentence transformers to choose from! There is a leaderboard of sentence embeddings: MTEB: Massive Text Embedding Benchmark
The all-minilm-l6-v2 model has reasonable performance sentence-transformers/all-MiniLM-L6-v2 · Hugging Face and is small and available in ONNX weights Xenova/all-MiniLM-L6-v2 · Hugging Face for transformers.js GitHub - xenova/transformers.js: State-of-the-art Machine Learning for the web. Run
 Transformers directly in your browser, with no need for a server! .
Transformers directly in your browser, with no need for a server! .Step 2: use product quantization to compress embeddings
6M pages * 384-dimension embeddings * 32-bit floats is over 9GB. Even a million embeddings in float16 precision is 800MB. This is too large for casual usage.As a first approximation, to choose the top million, one approach would be to choose the pages with the most information: compress each page and see the number of bytes that come out. Lists would be overrepresented (lists are less compressible than general text), there’s no appreciation of the link structure of webpages, but it’s cheap to compute and easy to start with.
FAISS (https://faiss.ai) is a highly popular embedding search engine serverside, with a lot of tuning knobs for creating different styles of search indices. Autofaiss (GitHub - criteo/autofaiss: Automatically create Faiss knn indices with the most optimal similarity search parameters.) will usually recommend using Product Quantization, after creating IVF indices or HNSW indices (Pinecone has a great intro to vector indexing Nearest Neighbor Indexes for Similarity Search | Pinecone).
Product quantization is exceptionally simple to implement: creating a ‘distance table’ is under 5 lines of numpy and using that to find distances is a one-liner.
Intermezzo: faceted search
Often times, you will want to search in some product subcategories, like finding only PDFs in a web search, or results in ancient Latin. Splitting up the distance computation from computing a top-10 ranking allows us to fudge the distances in flight before ranking. For million-scale search, this is highly feasible. In this search of Wikipedia, there is one search facet: the first character of the page. Because the top-k ranking is separate from distance computation we can avoid recomputing query embeddings and distances to explore different facet values in real time.
Step 3: hand-write ONNX
ONNX has a specific opcode that does exactly the product quantization step! That opcode is GatherElements. Unfortunately, the PyTorch ONNX export does not use this special opcode for the model as written. Thankfully, there is abundant support for reading and writing ONNX outside of a PyTorch compilation step.
A useful graphical editing tool for ONNX is ONNX-modifier, at GitHub - ZhangGe6/onnx-modifier: A tool to modify ONNX models in a visualization fashion, based on Netron and Flask. , which presents a friendly interface to add elements into the dataflow graph of any exported ONNX model.
By taking the multiple steps in the PyTorch model that gets compiled to ONNX, and replacing all of those with one ONNX opcode, distance computation is roughly 4x faster.
Step 4: export numpy to Arrow
As mentioned, the Arrow format is much more compact in memory and much more compact on disk to store the embeddings and the metadata (page titles).
Because the Arrow array format only stores one-dimensional data, and because we have 48 dimensions of embedding data, and because we do not want to store embedding data wrapped in another data format, we need two separate schemas, one for the metadata (with a hundred thousand rows each), and one for the embeddings (with a hundred thousand * 48 rows each), and we reshape the embeddings at load time.
Storing the product quantization codebook in JSON is under 1.0MB, so it is less crucial to optimize this part.
Step 5: let me know what you think 
Lots of the library functions in the full Wikipedia search app should migrate into reusable pq.js components. A lot of the ONNX shapes are pre-baked, so it would be useful to support different quantization levels and different embedding dimensions. Give a shout!
1/2)
 Buckle up and ready for a wild llama ride with 70B Llama-2 on a single MacBook
Buckle up and ready for a wild llama ride with 70B Llama-2 on a single MacBook 
 Now 70B Llama-2 can be run smoothly on an 64G M2 max with 4bit quantization.
Now 70B Llama-2 can be run smoothly on an 64G M2 max with 4bit quantization.
 Here is a step-by-step guide: mlc.ai/mlc-llm/docs/get_star…
Here is a step-by-step guide: mlc.ai/mlc-llm/docs/get_star…
 How about the performance? It's
How about the performance? It's
Jul 20, 2023 · 12:48 AM UTC
Junru Shao
@junrushao
(2/2)
- 7 tok/sec on M2 Max
- 9.8 tok/sec on M2 ultra
- A bonus - some preliminary number on A100: 13 token/sec
Buckle up and ready for a wild llama ride with 70B Llama-2 on a single MacBook Now 70B Llama-2 can be run smoothly on an 64G M2 max with 4bit quantization. Here is a step-by-step guide: mlc.ai/mlc-llm/docs/get_star… How about the performance? It'sJul 20, 2023 · 12:48 AM UTC
Junru Shao
@junrushao
(2/2)
- 7 tok/sec on M2 Max
- 9.8 tok/sec on M2 ultra
- A bonus - some preliminary number on A100: 13 token/sec
DEMO:

SDXL Inpainting - a Hugging Face Space by diffusers
Upload a picture and paint over the parts you want to modify. Enter a text prompt describing what should appear in the erased region (you can also add a negative prompt) and adjust optional setting...
huggingface.co
Stable Diffusion XL Inpainting 
Demo for the Stable Diffusion XL Inpainting model, add a mask and text prompt for what you want to replace

diffusers/stable-diffusion-xl-1.0-inpainting-0.1 · Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co
SD-XL Inpainting 0.1 Model Card

SD-XL Inpainting 0.1 is a latent text-to-image diffusion model capable of generating photo-realistic images given any text input, with the extra capability of inpainting the pictures by using a mask.
The SD-XL Inpainting 0.1 was initialized with the stable-diffusion-xl-base-1.0 weights. The model is trained for 40k steps at resolution 1024x1024 and 5% dropping of the text-conditioning to improve classifier-free classifier-free guidance sampling. For inpainting, the UNet has 5 additional input channels (4 for the encoded masked-image and 1 for the mask itself) whose weights were zero-initialized after restoring the non-inpainting checkpoint. During training, we generate synthetic masks and, in 25% mask everything.
Discover the LLMs
LLM Explorer: Large Language Model Directory and Analytics
A dynamic table to look up, explore, and compare the LLMs. Leverage the specific parameters of the popular models and choose your large language model.
llm.extractum.io

Google’s $30-per-month “Duet” AI will craft awkward emails, images for you
Google's new kitchen-sink AI branding is everything to everyone in every Workspace app.
 arstechnica.com
arstechnica.com
Google’s $30-per-month “Duet” AI will craft awkward emails, images for you
Google's new kitchen-sink AI branding is everything to everyone in every Workspace app.
BENJ EDWARDS - 8/29/2023, 4:27 PM
Getty Images / Benj Edwards
52WITH
On Tuesday, Google announced the launch of its Duet AI assistant across its Workspace apps, including Docs, Gmail, Drive, Slides, and more. First announced in May at Google I/O, Duet has been in testing for some time, but it is now available to paid Google Workspace business users (what Google calls its suite of cloud productivity apps) for $30 a month in addition to regular Workspace fees.
FURTHER READING
Google at I/O 2023: We’ve been doing AI since before it was coolDuet is not just one thing—instead, it's a blanket brand name for a multitude of different AI capabilities and probably should have been called "Google Kitchen Sink." It likely represents several distinct AI systems behind the scenes. For example, in Gmail, Duet can summarize a conversation thread across emails, use the content of an email to write a brief or draft an email based on a topic. In Docs, it can write content such as a customer proposal or a story. In Slides, it can generate custom visuals using an image synthesis model. In Sheets, it can help format existing spreadsheets or create a custom spreadsheet structure suited to a particular task, such as a project tracker.
, provided by Google.")
An example of Google Duet in action (one of many), provided by Google.
Some of Duet's applications feel like confusion in branding. In Google Meet, Google says that Duet AI can "ensure you look and sound your best with studio look, studio lighting, and studio sound," including "dynamic tiles" and "face detection"—functions that feel far removed from typical generative AI capabilities—as well as automatically translated captions. It can also reportedly capture notes and video, sending a summary to attendees in the meeting. In fact, using Duet's "attend for me" feature, Google says that "Duet AI will be able to join the meeting on your behalf" and send you a recap later.
In Google Chat, Duet reads everything that's going on in your conversations so that you can "ask questions about your content, get a summary of documents shared in a space, and catch up on missed conversations."
, provided by Google.")
An example of Google Duet in action (one of many), provided by Google.
Those are the marketing promises. So far, as spotted on social media, Duet in practice seems fairly mundane, like a mix of what we've seen with Google Bard and more complex versions of Google's existing autocomplete features. An author named Charlie Guo ran through Duet features in a helpful X thread, noting the AI model's awkward email compositions. "The writing is almost painfully formal," he says.
In Slides, a seventh-grade math teacher named Alice Keeler asked Google Duet to make a robot teacher in front of a chalkboard and posted it on X. The results are awkward and arguably unusable, full of telltale glitches found in image synthesis artwork from 2022. Sure, it's neat as a tech demo, but this is what a trillion-dollar company says is a production-ready tool today.
Of course, these capabilities can (and will) change over time as Google refines its offerings. Eventually, Duet may be absorbed into daily usage as if it weren't even there, much like Google's myriad other machine-learning features in its products.
AI everywhere, privacy nowhere?

Enlarge / A promotional graphic for Google Duet.
In the AI-everywhere model of the world that Duet represents, it seems that everything you do will always be monitored, read, parsed, digested, and summarized through cloud-based AI models. While this could go well, if navigated properly, there's also a whole range of ways this could go wrong in the future, from AI models that spy on your activities and aggregate data in the background (which, let's face it, companies already do), to sentiment analysis in writing, photos, and documents that could potentially be co-opted to snitch on behalf of corporations and governments alike. Imagine an AI model reading your chats and realizing, "Hey, I noticed that you mentioned pirating a film in 2010. The MPA has been notified." Or maybe, outside of the US, "I see you supporting this illegitimate ethnic or political group," and suddenly you find yourself in prison.
Of course, Google has answers for these types of concerns:
"In Workspace, we’ve always held user privacy and security at the very core of what we do. With Duet AI, we continue that promise, and you can rest assured that your interactions with Duet AI are private to you. No other user will see your data and Google does not use your data to train our models without your permission. Building on these core commitments, we recently announced new capabilities to help prevent cyber threats, provide safer work with built-in zero trust controls, and better support our customers’ digital sovereignty and compliance needs."
Billions of people already use and trust Google Docs in the cloud without much incident, trusting the gentle paternalistic surveillance Google provides, despite sometimes getting locked out and losing access to their entire digital life's history, including photos, emails, and documents. So perhaps throwing generative AI into the mix won't make things that different.
Beyond that, large language models have been known to confabulate (make things up) and draw false conclusions from data. As The Verge notes, if a chatbot like Bard makes up a movie that doesn’t actually exist, it comes off as silly. "But," writes David Pierce, "if Duet misinterprets or invents your company’s sales numbers, you’re in big trouble."
FURTHER READING
Why ChatGPT and Bing Chat are so good at making things upPeople misinterpret data, lie, and misremember, too, but people are legally and morally culpable for their mistakes. A shown tendency toward automation bias—placing unwarranted trust in machine decisions—when AI models have been widely deployed makes AI-driven mistakes especially perilous. Decisions with no sound logic behind them can become formalized and make a person's life miserable until, hopefully, human oversight steps in. These are the murky waters Google (and other productivity AI providers, such as Microsoft) will have to navigate in the years ahead as it deploys these tools to billions of people.
So, Google's all-in bet on generative AI—embraced in panic in January as a response to ChatGPT—feels somewhat like a dicey proposition. Use Duet features and quite possibly save some time (we are not saying they will be useless), but you'll also need to double-check everything for accuracy. Otherwise, you'll risk filling your work with errors. Meanwhile, a machine intelligence of unknown capability and accuracy is reading everything you do.
And all this for a $30/month subscription on top of existing fees for Google Workspace users (about $12 per user for a Standard subscription). Meanwhile, Microsoft includes similar "Copilot" features with Standard Microsoft 365 accounts for $12.50 a month. However, Google is also offering a no-cost trial of Duet before subscribing.
This story was updated after publication to remove a reference to Alice Keeler as a Google-sponsored teacher.