
You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
The A.I Megathread (LLM , GPT , Development)
More options
Who Replied?
Allen Institute Unveils Dolma, Largest Open Training Dataset for Large Language Models
Dolma is significantly larger than other open datasets and is released under AI2’s impact license, which was designed to balance ease of access with mitigation of potential risk in distributing large datasets.
Allen Institute Unveils Dolma, Largest Open Training Dataset for Large Language Models
Dolma is significantly larger than other open datasets and is released under AI2’s impact license, which was designed to balance ease of access with mitigation of potential risk in distributing large datasets.CHRIS MCKAY
AUGUST 19, 2023 • 2 MIN READThe nonprofit Allen Institute for Artificial Intelligence (AI2) has released Dolma (Data to feed OLMo’s Appetite), a massive new open source dataset for training AI language models. Weighing in at 3 trillion tokens, Dolma is the largest openly available dataset of its kind to date.
The Allen Institute created Dolma as part of their OLMo project to build an open, transparent language model. In curating Dolma, they focused on principles of openness, representativeness, size, reproducibility and risk mitigation.
- Openness: Addressing the research community's concern about the limited access to pretraining corpora and corresponding language models, they aimed for a dataset that is transparent and open for scrutiny.
- Representativeness: The content should be on par with existing datasets utilized for both private and open language models.
- Size: The team acknowledged the potential advantages of having a large dataset. Research indicates that larger training datasets can lead to improved model performance.
- Reproducibility: Any tools developed during the creation of Dolma would be openly available for others to reproduce or adapt.
- Risk Mitigation: The dataset would be designed to minimize the risk posed to individuals, ensuring that web-crawled content isn't traceable back to real-world individuals.
Compared to closed datasets, Dolma sets itself apart by emphasizing transparency, especially as many datasets behind large-scale models remain obscured in the private domain. In comparison with other open datasets, Dolma’s strengths lie in its size and licensing terms. Dolma is the largest open dataset to date. It is licensed under the Allen Institute's ImpACT terms as a medium-risk artifact.
Those interested in accessing Dolma must abide by and agree to terms around transparency, risk mitigation and responsible use. The license prohibits military applications, surveillance or generating disinformation. This unique licensing balances the ease of access with potential risks associated with disseminating vast datasets.
Prospective users must provide their contact details and state their intended use of the dataset. Once approved, Dolma is freely accessible for download on the HuggingFace. For more information, consult this handy data sheet. They have also provided a GitHub repository with code and instructions on generating and inspecting Dolma.
The Allen Institute plans to expand Dolma with more data sources and languages. They hope Dolma will advance openness in AI research and lead to development of better language technologies.
llama.cpp surprised many people (myself included) with how quickly you can run large LLMs on small computers, e.g. 7B runs @ ~16 tok/s on a MacBook. Wait don't you need supercomputers to work with LLMs?
TLDR at batch_size=1 (i.e. just generating a single stream of prediction on your computer), the inference is super duper memory-bound. The on-chip compute units are twiddling their thumbs while sucking model weights through a straw from DRAM. Every individual weight that is expensively loaded from DRAM onto the chip is only used for a single instant multiply to process each new input token. So the stat to look at is not FLOPS but the memory bandwidth.
Let's take a look:
A100: 1935 GB/s memory bandwidth, 1248 TOPS
MacBook M2: 100 GB/s, 7 TFLOPS
The compute is ~200X but the memory bandwidth only ~20X. So the little M2 chip that could will only be about ~20X slower than a mighty A100. This is ~10X faster than you might naively expect just looking at ops.
The situation becomes a lot more different when you inference at a very high batch size (e.g. ~160+), such as when you're hosting an LLM engine simultaneously serving a lot of parallel requests. Or in training, where you aren't forced to go serially token by token and can parallelize across both batch and time dimension, because the next token targets (labels) are known. In these cases, once you load the weights into on-chip cache and pay that large fixed cost, you can re-use them across many input examples and reach ~50%+ utilization, actually making those FLOPS count.
So TLDR why is LLM inference surprisingly fast on your MacBook? If all you want to do is batch 1 inference (i.e. a single "stream" of generation), only the memory bandwidth matters. And the memory bandwidth gap between chips is a lot smaller, and has been a lot harder to scale compared to flops.
supplemental figure
Two notes I wanted to add:
1) In addition to parallel inference and training, prompt encoding is also parallelizable even at batch_size=1 because the prompt tokens can be encoded by the LLM in parallel instead of decoded serially one by one. The token inputs into LLMs always have shape (B,T), batch by time. Parallel inference decoding is (high B, T=1), training is (high B, high T), and long prompts is (B=1, high T). So this workload can also become compute-bound (e.g. above 160 tokens) and the A100 would shine again. As your prompts get longer, your MacBook will fall farther behind the A100.
2) The M2 chips from Apple are actually quite an amazing lineup and come in much larger shapes and sizes. The M2 Pro, M2 Max have 200 and 400 GB/s (you can get these in a MacBook Pro!), and the M2 Ultra (in Mac Studio) has 800 GB/s. So the M2 Ultra is the smallest, prettiest, out of the box easiest, most powerful personal LLM node today.
en.wikipedia.org/wiki/Apple_…
TLDR at batch_size=1 (i.e. just generating a single stream of prediction on your computer), the inference is super duper memory-bound. The on-chip compute units are twiddling their thumbs while sucking model weights through a straw from DRAM. Every individual weight that is expensively loaded from DRAM onto the chip is only used for a single instant multiply to process each new input token. So the stat to look at is not FLOPS but the memory bandwidth.
Let's take a look:
A100: 1935 GB/s memory bandwidth, 1248 TOPS
MacBook M2: 100 GB/s, 7 TFLOPS
The compute is ~200X but the memory bandwidth only ~20X. So the little M2 chip that could will only be about ~20X slower than a mighty A100. This is ~10X faster than you might naively expect just looking at ops.
The situation becomes a lot more different when you inference at a very high batch size (e.g. ~160+), such as when you're hosting an LLM engine simultaneously serving a lot of parallel requests. Or in training, where you aren't forced to go serially token by token and can parallelize across both batch and time dimension, because the next token targets (labels) are known. In these cases, once you load the weights into on-chip cache and pay that large fixed cost, you can re-use them across many input examples and reach ~50%+ utilization, actually making those FLOPS count.
So TLDR why is LLM inference surprisingly fast on your MacBook? If all you want to do is batch 1 inference (i.e. a single "stream" of generation), only the memory bandwidth matters. And the memory bandwidth gap between chips is a lot smaller, and has been a lot harder to scale compared to flops.
supplemental figure
Two notes I wanted to add:
1) In addition to parallel inference and training, prompt encoding is also parallelizable even at batch_size=1 because the prompt tokens can be encoded by the LLM in parallel instead of decoded serially one by one. The token inputs into LLMs always have shape (B,T), batch by time. Parallel inference decoding is (high B, T=1), training is (high B, high T), and long prompts is (B=1, high T). So this workload can also become compute-bound (e.g. above 160 tokens) and the A100 would shine again. As your prompts get longer, your MacBook will fall farther behind the A100.
2) The M2 chips from Apple are actually quite an amazing lineup and come in much larger shapes and sizes. The M2 Pro, M2 Max have 200 and 400 GB/s (you can get these in a MacBook Pro!), and the M2 Ultra (in Mac Studio) has 800 GB/s. So the M2 Ultra is the smallest, prettiest, out of the box easiest, most powerful personal LLM node today.
en.wikipedia.org/wiki/Apple_…
Complexion
ʇdᴉɹɔsǝɥʇdᴉlɟ
Is there a way to do decent resolution AI speech to image generation without limits, credits etc... yet?
Is there a way to do decent resolution AI speech to image generation without limits, credits etc... yet?
I'm pretty sure that Nvidia is working on speech to image/video and are getting really close to it.
Complexion
ʇdᴉɹɔsǝɥʇdᴉlɟ
I'm pretty sure that Nvidia is working on speech to image/video and are getting really close to it.
But nothing online driven yet (that doesn't need a GPU) or ask for credits to create?
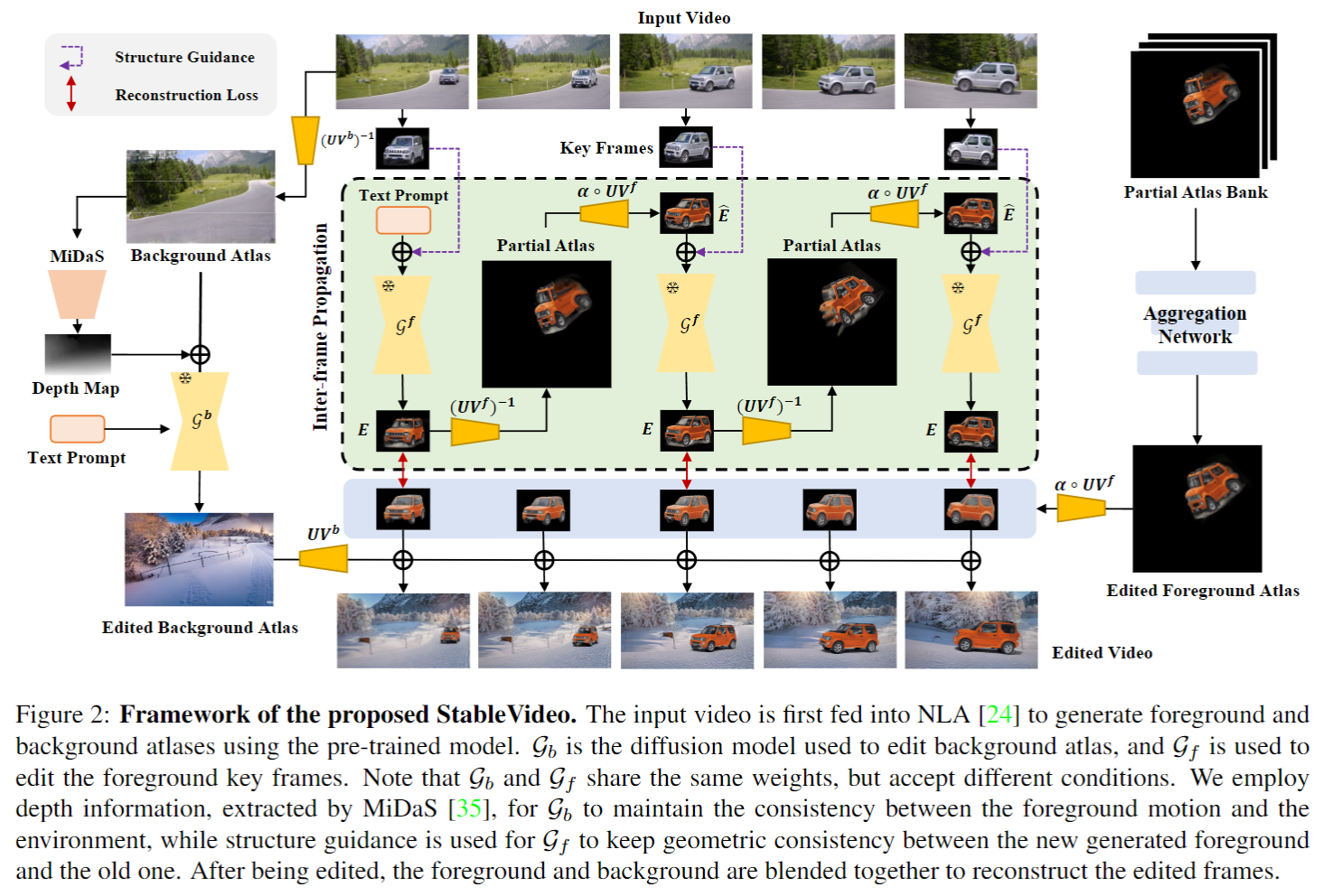
StableVideo: Text-driven Consistency-aware Diffusion Video Editing
Wenhao Chai2, Xun Guo2✉, Gaoang Wang1 Yan Lu2,1 Zhejiang Unversity 2 Microsoft Research Asia
GitHub - rese1f/StableVideo: [ICCV 2023] StableVideo: Text-driven Consistency-aware Diffusion Video Editing
[ICCV 2023] StableVideo: Text-driven Consistency-aware Diffusion Video Editing - GitHub - rese1f/StableVideo: [ICCV 2023] StableVideo: Text-driven Consistency-aware Diffusion Video Editing
 github.com
github.com
Abstract
Diffusion-based methods can generate realistic images and videos, but they struggle to edit existing objects in a video while preserving their appearance over time. This prevents diffusion models from being applied to natural video editing in practical scenarios. In this paper, we tackle this problem by introducing temporal dependency to existing text-driven diffusion models, which allows them to generate consistent appearance for the edited objects. Specifically, we develop a novel inter-frame propagation mechanism for diffusion video editing, which leverages the concept of layered representations to propagate the appearance information from one frame to the next. We then build up a text-driven video editing framework based on this mechanism, namely StableVideo, which can achieve consistency-aware video editing. Extensive experiments demonstrate the strong editing capability of our approach. Compared with state-of-the-art video editing methods, our approach shows superior qualitative and quantitative results.Overview

AI-Generated Art Lacks Copyright Protection, D.C. Court Says (1)
Artwork created by artificial intelligence isn’t eligible for copyright protection because it lacks human authorship, a Washington, D.C., federal judge decided Friday.
AI-Generated Art Lacks Copyright Protection, D.C. Court Says (1)
Riddhi Setty
Reporter
Isaiah Poritz
Isaiah Poritz
Legal Reporter
- ‘Human authorship’ is the bedrock of copyright law, judge finds
- Copyright Office had denied registration for AI-generated image
Artwork created by artificial intelligence isn’t eligible for copyright protection because it lacks human authorship, a Washington, D.C., federal judge decided Friday.
Judge Beryl A. Howell of the US District Court for the District of Columbia agreed with the US Copyright Office’s decision to deny a copyright registration to computer scientist Stephen Thaler, who argued a two-dimensional artwork created by his AI program “Creativity Machine” should be eligible for protection.
The ruling is the first in the country to establish a boundary on the legal protections for AI-generated artwork, which has exploded in popularity with the rise of products like OpenAI Inc.'s ChatGPT and DALL-E, Midjourney, and Stable Diffusion.
Howell found that “courts have uniformly declined to recognize copyright in works created absent any human involvement,” citing cases where copyright protection was denied for celestial beings, a cultivated garden, and a monkey who took a selfie.
“Undoubtedly, we are approaching new frontiers in copyright as artists put AI in their toolbox to be used in the generation of new visual and other artistic works,” the judge wrote.
The rise of generative AI will “prompt challenging questions” about how much human input into an AI program is necessary to qualify for copyright protection, Howell said, as well as how to assess the originality of AI-generated art that comes from systems trained on existing copyrighted works.
But this case “is not nearly so complex” because Thaler admitted in his application that he played no role in creating the work, Howell said.
Thaler, the president and CEO of Imagination Engines, sued the office in June 2022 following its denial of his application to register the AI-generated art piece titled “A Recent Entrance to Paradise.”
His attorney, Ryan Abbott of Brown Neri Smith & Khan LLP, said he plans to appeal the judgment. “We respectfully disagree with the court’s interpretation of the Copyright Act,” Abbott said.
The Copyright Office said in a statement that it believes the court reached the correct result and the office is reviewing the decision.
The office recently issued guidance on the copyrightability of works created with the assistance of AI, which attorneys said introduced additional murkiness in the AI authorship debate.
The Copyright Office in February granted a limited copyright registration for an AI-assisted graphic novel, which attorneys said could crack the door open further to protect such works.
Thaler’s motion for summary judgment, which Howell denied in the Friday order, argued that permitting AI to be listed as an author on copyrighted works would incentivize more creation, which is in line with copyright law’s purpose of promoting useful art for the public.
“Denying copyright to AI-created works would thus go against the well-worn principle that '[c]opyright protection extends to all ‘original works of authorship fixed in any tangible medium’ of expression,” Thaler argued in his motion.
Register of Copyrights Shira Perlmutter, who leads the office, defended the office’s decision to reject Thaler’s application on the grounds that it wasn’t created by a human.
“The Office’s conclusion that copyright law does not protect non-human creators was a sound and reasoned interpretation of the applicable law,” the agency wrote in its cross-motion for summary judgment, which Howell granted Friday.
The Department of Justice represents the Copyright Office.
The case is Thaler v. Perlmutter, D.D.C., No. 1:22-cv-01564, ordered 8/18/23.
(Adds comment from the Copyright Office in tenth paragraph.)
To contact the reporters on this story: Riddhi Setty in Washington at rsetty@bloombergindustry.com; Isaiah Poritz in Washington at iporitz@bloombergindustry.com
To contact the editors responsible for this story: James Arkin at jarkin@bloombergindustry.com; Adam M. Taylor at ataylor@bloombergindustry.com

Introducing Code Llama, a state-of-the-art large language model for coding
Code Llama, which is built on top of Llama 2, is free for research and commercial use.
 ai.meta.com
ai.meta.com
Introducing Code Llama, a state-of-the-art large language model for coding
August 24, 2023
Takeaways
- Code Llama is a state-of-the-art LLM capable of generating code, and natural language about code, from both code and natural language prompts.
- Code Llama is free for research and commercial use.
- Code Llama is built on top of Llama 2 and is available in three models:
- Code Llama, the foundational code model;
- Codel Llama - Python specialized for Python;
- and Code Llama - Instruct, which is fine-tuned for understanding natural language instructions.
- In our own benchmark testing, Code Llama outperformed state-of-the-art publicly available LLMs on code tasks
The generative AI space is evolving rapidly, and we believe an open approach to today’s AI is the best one for developing new AI tools that are innovative, safe, and responsible. We are releasing Code Llama under the same community license as Llama 2.
How Code Llama works
Code Llama is a code-specialized version of Llama 2 that was created by further training Llama 2 on its code-specific datasets, sampling more data from that same dataset for longer. Essentially, Code Llama features enhanced coding capabilities, built on top of Llama 2. It can generate code, and natural language about code, from both code and natural language prompts (e.g., “Write me a function that outputs the fibonacci sequence.”) It can also be used for code completion and debugging. It supports many of the most popular languages being used today, including Python, C++, Java, PHP, Typescript (Javascript), C#, and Bash (see our research paper for a full list).

We are releasing three sizes of Code Llama with 7B, 13B, and 34B parameters respectively. Each of these models is trained with 500B tokens of code and code-related data. The 7B and 13B base and instruct models have also been trained with fill-in-the-middle (FIM) capability, allowing them to insert code into existing code, meaning they can support tasks like code completion right out of the box.
The three models address different serving and latency requirements. The 7B model, for example, can be served on a single GPU. The 34B model returns the best results and allows for better coding assistance, but the smaller 7B and 13B models are faster and more suitable for tasks that require low latency, like real-time code completion.

The Code Llama models provide stable generations with up to 100,000 tokens of context. All models are trained on sequences of 16,000 tokens and show improvements on inputs with up to 100,000 tokens.
Aside from being a prerequisite for generating longer programs, having longer input sequences unlocks exciting new use cases for a code LLM. For example, users can provide the model with more context from their codebase to make the generations more relevant. It also helps in debugging scenarios in larger codebases, where staying on top of all code related to a concrete issue can be challenging for developers. When developers are faced with debugging a large chunk of code they can pass the entire length of the code into the model.

Additionally, we have further fine-tuned two additional variations of Code Llama: Code Llama - Python and Code Llama - Instruct.
Code Llama - Python is a language-specialized variation of Code Llama, further fine-tuned on 100B tokens of Python code. Because Python is the most benchmarked language for code generation – and because Python and PyTorch play an important role in the AI community – we believe a specialized model provides additional utility.
Code Llama - Instruct is an instruction fine-tuned and aligned variation of Code Llama. Instruction tuning continues the training process, but with a different objective. The model is fed a “natural language instruction” input and the expected output. This makes it better at understanding what humans expect out of their prompts. We recommend using Code Llama - Instruct variants whenever using Code Llama for code generation since Code Llama - Instruct has been fine-tuned to generate helpful and safe answers in natural language.
We do not recommend using Code Llama or Code Llama - Python to perform general natural language tasks since neither of these models are designed to follow natural language instructions. Code Llama is specialized for code-specific tasks and isn’t appropriate as a foundation model for other tasks.
When using the Code Llama models, users must abide by our license and acceptable use policy.

Evaluating Code Llama’s performance
To test Code Llama’s performance against existing solutions, we used two popular coding benchmarks: HumanEval and Mostly Basic Python Programming (MBPP). HumanEval tests the model’s ability to complete code based on docstrings and MBPP tests the model’s ability to write code based on a description.
Our benchmark testing showed that Code Llama performed better than open-source, code-specific LLMs and outperformed Llama 2. Code Llama 34B, for example, scored 53.7% on HumanEval and 56.2% on MBPP, the highest compared with other state-of-the-art open solutions, and on par with ChatGPT.

Llama-2 was almost at GPT-3.5 level except for coding, which was a real bummer.
Now Code Llama finally bridges the gap to GPT-3.5! Coding is by far the most important LLM task. It's the cornerstone of strong reasoning engines and powerful AI agents like Voyager.
Today is another major milestone in OSS foundation models. Read with me:
- Code Llamas are finetuned from Llama-2 base models, and come in 3 flavors: vanilla, Instruct, and Python. Model sizes are 7B, 13B, 34B. The smallest model can run locally with decent GPU.
- On HumanEval benchmark, CodeLlama-python achieves 53.7 vs GPT-3.5 (48.1), but still trailing behind GPT-4 (whopping 67.0). On MBPP, it gets 56.2 vs 52.2 for GPT-3.5.
- Significantly better than PaLM-Coder, Codex (GitHub copilot model), and other OSS models like StarCoder.
- Trained with an "infilling objective" to support code generation in the middle given surrounding context. Basically, the model takes in (prefix, suffix) or (suffix, prefix) and outputs (middle). It's still autoregressive, but with special marker tokens. The infilling data can be easily synthesized by splitting the code corpus randomly.
- Another set of synthetic data from Self-Instruct:
(1) take 60K coding interview questions;
(2) generate unit tests;
(3) generate 10 solutions;
(4) run Python interpreter and filter out bad ones. Add good ones to the dataset.
- Long context finetuning: Code Llama starts from 4K context and finetunes with 16K context to save computation. With some positional embedding tricks, it can carry consistency over even longer context.
- The instruction finetuning data is proprietary and won't be released.
Now Code Llama finally bridges the gap to GPT-3.5! Coding is by far the most important LLM task. It's the cornerstone of strong reasoning engines and powerful AI agents like Voyager.
Today is another major milestone in OSS foundation models. Read with me:
- Code Llamas are finetuned from Llama-2 base models, and come in 3 flavors: vanilla, Instruct, and Python. Model sizes are 7B, 13B, 34B. The smallest model can run locally with decent GPU.
- On HumanEval benchmark, CodeLlama-python achieves 53.7 vs GPT-3.5 (48.1), but still trailing behind GPT-4 (whopping 67.0). On MBPP, it gets 56.2 vs 52.2 for GPT-3.5.
- Significantly better than PaLM-Coder, Codex (GitHub copilot model), and other OSS models like StarCoder.
- Trained with an "infilling objective" to support code generation in the middle given surrounding context. Basically, the model takes in (prefix, suffix) or (suffix, prefix) and outputs (middle). It's still autoregressive, but with special marker tokens. The infilling data can be easily synthesized by splitting the code corpus randomly.
- Another set of synthetic data from Self-Instruct:
(1) take 60K coding interview questions;
(2) generate unit tests;
(3) generate 10 solutions;
(4) run Python interpreter and filter out bad ones. Add good ones to the dataset.
- Long context finetuning: Code Llama starts from 4K context and finetunes with 16K context to save computation. With some positional embedding tricks, it can carry consistency over even longer context.
- The instruction finetuning data is proprietary and won't be released.

codellama (Code Llama)
Org profile for Code Llama on Hugging Face, the AI community building the future.
huggingface.co
Code Llama: Open Foundation Models for Code | Research - AI at Meta
We release Code Llama, a family of large language models for code based on Llama 2 providing state-of-the-art performance among open models, infilling...
 ai.meta.com
ai.meta.com
Code Llama: Open Foundation Models for Code
August 24, 2023Abstract
We release Code Llama, a family of large language models for code based on Llama 2 providing state-of-the-art performance among open models, infilling capabilities, support for large input contexts, and zero-shot instruction following ability for programming tasks. We provide multiple flavors to cover a wide range of applications: foundation models (Code Llama), Python specializations (Code Llama - Python), and instruction-following models (Code Llama - Instruct) with 7B, 13B and 34B parameters each. All models are trained on sequences of 16k tokens and show improvements on inputs with up to 100k tokens. 7B and 13B Code Llama and Code Llama - Instruct variants support infilling based on surrounding content. Code Llama reaches state-of-the-art performance among open models on several code benchmarks, with scores of up to 53% and 55% on HumanEval and MBPP, respectively. Notably, Code Llama - Python 7B outperforms Llama 2 70B on HumanEval and MBPP, and all our models outperform every other publicly available model on MultiPL-E. We release Code Llama under a permissive license that allows for both research and commercial use.hackernews
Code Llama, a state-of-the-art large language model for coding | Hacker News

TheBloke/CodeLlama-13B-GGML · Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co

TheBloke/CodeLlama-13B-GGUF · Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co

TheBloke/CodeLlama-13B-GPTQ · Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co

TheBloke/CodeLlama-13B-Instruct-GGML · Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co

TheBloke/CodeLlama-13B-Instruct-GGUF · Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co

TheBloke/CodeLlama-13B-Instruct-GPTQ · Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co

TheBloke/CodeLlama-13B-Instruct-fp16 · Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co

TheBloke/CodeLlama-13B-Python-GGML · Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co

TheBloke/CodeLlama-13B-Python-GGUF · Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co

TheBloke/CodeLlama-13B-Python-GPTQ · Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co

TheBloke/CodeLlama-13B-Python-fp16 · Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co

TheBloke/CodeLlama-13B-fp16 · Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co

TheBloke/CodeLlama-34B-GGML · Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co

TheBloke/CodeLlama-34B-GGUF · Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co

TheBloke/CodeLlama-34B-Instruct-GGML · Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co

TheBloke/CodeLlama-34B-Instruct-GGUF · Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co

TheBloke/CodeLlama-34B-Instruct-GPTQ · Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co

TheBloke/CodeLlama-34B-Instruct-fp16 · Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co

TheBloke/CodeLlama-34B-Python-GGML · Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co

TheBloke/CodeLlama-34B-Python-GGUF · Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co

TheBloke/CodeLlama-34B-Python-fp16 · Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co

TheBloke/CodeLlama-34B-fp16 · Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co

TheBloke/CodeLlama-7B-GGML · Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co

TheBloke/CodeLlama-7B-GGUF · Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co

TheBloke/CodeLlama-7B-GPTQ · Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co

TheBloke/CodeLlama-7B-Instruct-GGML · Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co

TheBloke/CodeLlama-7B-Instruct-GGUF · Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co

TheBloke/CodeLlama-7B-Instruct-GPTQ · Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co

TheBloke/CodeLlama-7B-Instruct-fp16 · Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co

TheBloke/CodeLlama-7B-Python-GGML · Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co

TheBloke/CodeLlama-7B-Python-GGUF · Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co

TheBloke/CodeLlama-7B-Python-GPTQ · Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co

TheBloke/CodeLlama-7B-Python-fp16 · Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co

TheBloke/CodeLlama-7B-fp16 · Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co
Last edited: