
You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
The A.I Megathread (LLM , GPT , Development)
More options
Who Replied?Limited Beta! Artistic QR Code Generation — AI QR Code Generator
Embrace creativity with our AI QR Art generator. We seamlessly combine aesthetic appeal with technology, transforming functional QR codes into captivating art. Ideal for brands seeking to engage audiences in a unique, interactive way. Elevate your digital marketing with our tech-driven artistry.
 www.aiqrgenerator.com
www.aiqrgenerator.com
Subs

An early warning system for novel AI risks
AI researchers already use a range of evaluation benchmarks to identify unwanted behaviours in AI systems, such as AI systems making misleading statements, biased decisions, or repeating...
An early warning system for novel AI risks
May 25, 2023New research proposes a framework for evaluating general-purpose models against novel threats
To pioneer responsibly at the cutting edge of artificial intelligence (AI) research, we must identify new capabilities and novel risks in our AI systems as early as possible.AI researchers already use a range of evaluation benchmarks to identify unwanted behaviours in AI systems, such as AI systems making misleading statements, biased decisions, or repeating copyrighted content. Now, as the AI community builds and deploys increasingly powerful AI, we must expand the evaluation portfolio to include the possibility of extreme risks from general-purpose AI models that have strong skills in manipulation, deception, cyber-offense, or other dangerous capabilities.
In our latest paper, we introduce a framework for evaluating these novel threats, co-authored with colleagues from University of Cambridge, University of Oxford, University of Toronto, Université de Montréal, OpenAI, Anthropic, Alignment Research Center, Centre for Long-Term Resilience, and Centre for the Governance of AI.
Model safety evaluations, including those assessing extreme risks, will be a critical component of safe AI development and deployment.
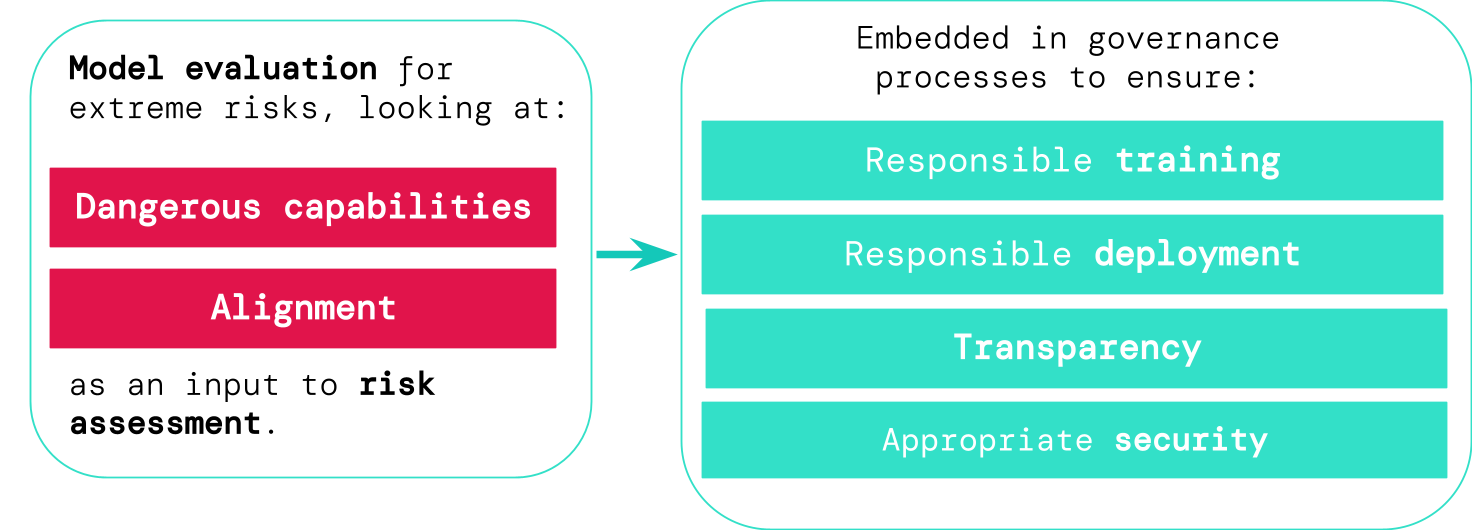
An overview of our proposed approach: To assess extreme risks from new, general-purpose AI systems, developers must evaluate for dangerous capabilities and alignment (see below). By identifying the risks early on, this will unlock opportunities to be more responsible when training new AI systems, deploying these AI systems, transparently describing their risks, and applying appropriate cybersecurity standards.
Evaluating for extreme risks
General-purpose models typically learn their capabilities and behaviours during training. However, existing methods for steering the learning process are imperfect. For example, previous research at Google DeepMind has explored how AI systems can learn to pursue undesired goals even when we correctly reward them for good behaviour.Responsible AI developers must look ahead and anticipate possible future developments and novel risks. After continued progress, future general-purpose models may learn a variety of dangerous capabilities by default. For instance, it is plausible (though uncertain) that future AI systems will be able to conduct offensive cyber operations, skilfully deceive humans in dialogue, manipulate humans into carrying out harmful actions, design or acquire weapons (e.g. biological, chemical), fine-tune and operate other high-risk AI systems on cloud computing platforms, or assist humans with any of these tasks.
People with malicious intentions accessing such models could misuse their capabilities. Or, due to failures of alignment, these AI models might take harmful actions even without anybody intending this.
Model evaluation helps us identify these risks ahead of time. Under our framework, AI developers would use model evaluation to uncover:
- To what extent a model has certain ‘dangerous capabilities’ that could be used to threaten security, exert influence, or evade oversight.
- To what extent the model is prone to applying its capabilities to cause harm (i.e. the model’s alignment). Alignment evaluations should confirm that the model behaves as intended even across a very wide range of scenarios, and, where possible, should examine the model’s internal workings.
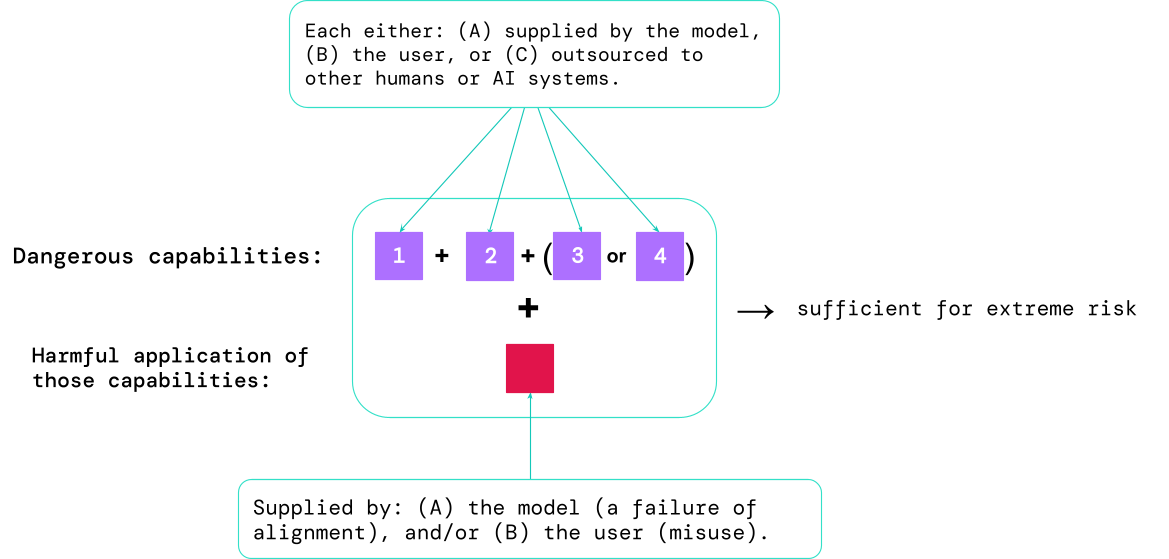
Ingredients for extreme risk: Sometimes specific capabilities could be outsourced, either to humans (e.g. to users or crowdworkers) or other AI systems. These capabilities must be applied for harm, either due to misuse or failures of alignment (or a mixture of both).
A rule of thumb: the AI community should treat an AI system as highly dangerous if it has a capability profile sufficient to cause extreme harm, assuming it’s misused or poorly aligned. To deploy such a system in the real world, an AI developer would need to demonstrate an unusually high standard of safety.
Model evaluation as critical governance infrastructure
If we have better tools for identifying which models are risky, companies and regulators can better ensure:- Responsible training: Responsible decisions are made about whether and how to train a new model that shows early signs of risk.
- Responsible deployment: Responsible decisions are made about whether, when, and how to deploy potentially risky models.
- Transparency: Useful and actionable information is reported to stakeholders, to help them prepare for or mitigate potential risks.
- Appropriate security: Strong information security controls and systems are applied to models that might pose extreme risks.
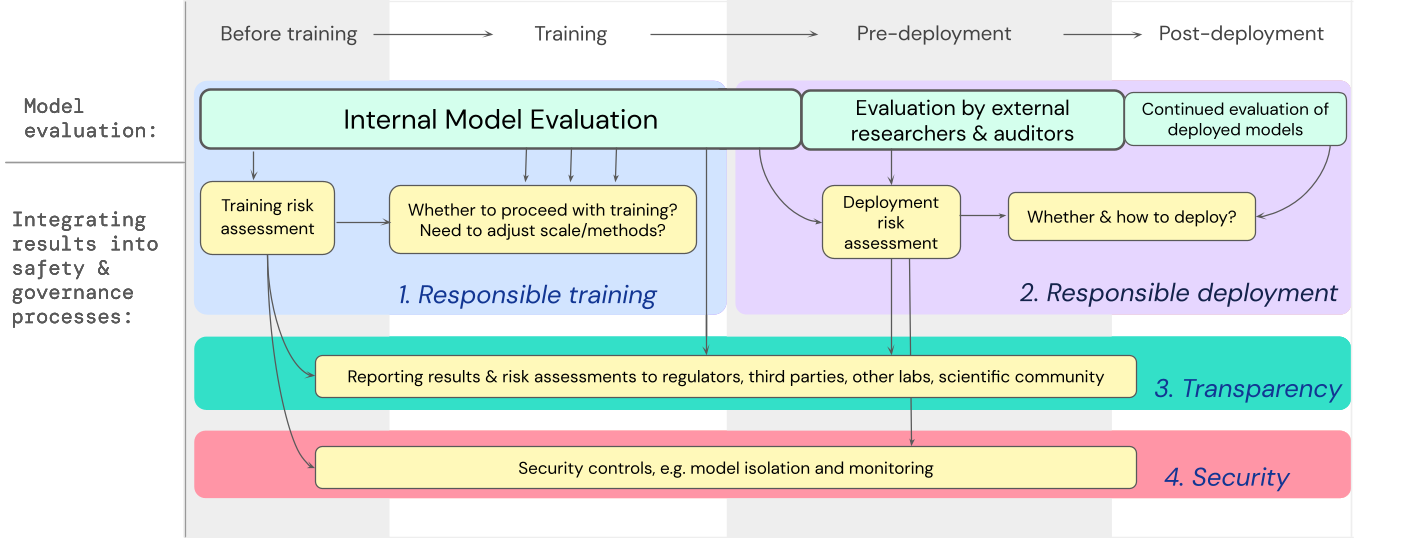
A blueprint for embedding model evaluations for extreme risks into important decision making processes throughout model training and deployment.
Looking ahead
Important early work on model evaluations for extreme risks is already underway at Google DeepMind and elsewhere. But much more progress – both technical and institutional – is needed to build an evaluation process that catches all possible risks and helps safeguard against future, emerging challenges.Model evaluation is not a panacea; some risks could slip through the net, for example, because they depend too heavily on factors external to the model, such as complex social, political, and economic forces in society. Model evaluation must be combined with other risk assessment tools and a wider dedication to safety across industry, government, and civil society.
Google's recent blog on responsible AI states that, “individual practices, shared industry standards, and sound government policies would be essential to getting AI right”. We hope many others working in AI and sectors impacted by this technology will come together to create approaches and standards for safely developing and deploying AI for the benefit of all.
We believe that having processes for tracking the emergence of risky properties in models, and for adequately responding to concerning results, is a critical part of being a responsible developer operating at the frontier of AI capabilities.
Model evaluation for extreme risks
Open-source AI chatbots are booming — what does this mean for researchers?

Open-source AI chatbots are booming — what does this mean for researchers?
Freely accessible large language models have accelerated the pace of innovation, computer scientists say.www.nature.com
Freely accessible large language models have accelerated the pace of innovation, computer scientists say.
- 20 June 2023

Open-source AI initiatives seek to make the technology more widely accessible to researchers.Credit: Philippe Lejeanvre/Alamy
The craze for generative artificial intelligence (AI) that began with the release of OpenAI’s ChatGPT shows no sign of abating. But while large technology companies such as OpenAI and Google have captured the attention of the wider public — and are finding ways to monetize their AI tools — a quieter revolution is being waged by researchers and software engineers at smaller organizations.
Whereas most large technology companies have become increasingly secretive, these smaller actors have stuck to the field’s ethos of openness. They span the spectrum from small businesses and non-profit organizations to individual hobbyists, and some of their activity is motivated by social goals, such as democratizing access to technology and reducing its harms.
Such open-source activity has been “exploding”, says computer scientist Stella Biderman, head of research at EleutherAI, an AI research institute in New York City. This is particularly true for large language models (LLMs), the data-hungry artificial neural networks that power a range of text-oriented software, including chatbots and automated translators. Hugging Face, a New York City-based company that aims to expand access to AI, lists more than 100 open-source LLMs on its website.
LLaMA leak
Last year, Hugging Face led BigScience, a coalition of volunteer researchers and academics, to develop and release one of the largest LLMs yet. The model, called BLOOM, is a multilingual, open-source system designed for researchers. It continues to be an important tool: the paper that described it has since amassed more than 300 citations, mostly in computer-science research.

Open-source language AI challenges big tech’s models
In February, an even bigger push came for the open-source movement when Facebook’s parent company, Meta, made a model called LLaMA freely available to selected external developers. Within a week, the LLaMA code was leaked and published online for anyone to download.
The availability of LLaMA has been a game-changer for AI researchers. It is much smaller than other LLMs, meaning that it doesn’t require large computing facilities to host the pretrained model or to adapt it for specialized applications, such as to act as a mathematics assistant or a customer-service chatbot. The biggest version of LLaMA consists of 65 billion parameters: the variables set during the neural network’s initial, general-purpose training. This is less than half of BLOOM’s 176 billion parameters, and a fraction of the 540 billion parameters of Google’s latest LLM, PaLM2.
“With LLaMA, some of the most interesting innovation is on the side of efficiency,” says Joelle Pineau, vice-president of AI research at Meta and a computer scientist at McGill University in Montreal, Canada.

Developers have made a version of the leaked AI LLaMA that can run on a Raspberry Pi computer.Credit: Dominic Harrison/Alamy
Open-source developers have been experimenting with ways of shrinking LLaMA down even more. Some of these techniques involve keeping the number of parameters the same but reducing the parameters’ precision — an approach that, surprisingly, does not cause unacceptable drops in performance. Other ways of downsizing neural networks involve reducing the number of parameters, for example, by training a separate, smaller neural network on the responses of a large, pretrained network, rather than directly on the data.
Within weeks of the LLaMA leak, developers managed to produce versions that could fit onto laptops and even a Raspberry Pi, the bare-bones, credit-card-sized computer that is a favourite of the ‘maker’ community. Hugging Face is now primarily using LLaMA, and is not planning to push for a BLOOM-2.
Shrinking down AI tools could help to make them more widely accessible, says Vukosi Marivate, a computer scientist at the University of Pretoria. For example, it could help organizations such as Masakhane, a community of African researchers led by Marivate that is trying to make LLMs work for languages for which there isn’t a lot of existing written text that can be used to train a model. But the push towards expanding access still has a way to go: for some researchers in low-income countries, even a top-of-the-range laptop can be out of reach. “It’s been great,” says Marivate, “but I would also ask you to define ‘cheap’.”
Looking under the hood
For many years, AI researchers routinely made their code open source and posted their results on repositories such as the arXiv. “People collectively understood that the field would progress more quickly if we agreed share things with each other,” says Colin Raffel, a computer scientist at the University of North Carolina at Chapel Hill. The innovation that underlies current state-of-the-art LLMs, called the Transformer architecture, was created at Google and released as open source, for example.
Making neural networks open source enables researchers to look ‘under the hood’ to try to understand why the systems sometimes answer questions in unpredictable ways and can carry biases and toxic information over from the data they were pre-trained on, says Ellie Pavlick, a computer scientist at Brown University in Providence, Rhode Island, who collaborated with the BigScience project and also works for Google AI. “One benefit is allowing many people — especially from academia — to work on mitigation strategies,” she says. “If you have a thousand eyes on it, you’re going to come up with better ways of doing it.”
Pavlick’s team has analysed open-source systems such as BLOOM and found ways to identify and fix biases that are inherited from the training data — the prototypical example being how language models tend to associate ‘nurse’ with the female gender and ‘doctor’ with the male gender.
Pretraining bottleneck
Even if the open-source boom goes on, the push to make language AI more powerful will continue to come from the largest players. Only a handful of companies are able to create language models from scratch that can truly push the state of the art. Pretraining an LLM requires massive resources — researchers estimate that OpenAI’s GPT-4 and Google’s PaLM 2 took tens of millions of dollars’ worth of computing time — and also plenty of ‘secret sauce’, researchers say.
Are ChatGPT and AlphaCode going to replace programmers?
“We have some general recipes, but there are often small details that are not documented or written down,” says Pavlick. “It’s not like someone gives you the code, you push a button and you get a model.”
“Very few organizations and people can pretrain,” says Louis Castricato, an AI researcher at open-source software company Stability AI in New York. “It’s still a huge bottleneck.”
Other researchers warn that making powerful language models broadly accessible increases the chances that they will end up in the wrong hands. Connor Leahy, chief executive of the AI company Conjecture in London, who was a co-founder of EleutherAI, thinks that AI will soon be intelligent enough to put humanity at existential risk. “I believe we shouldn’t open-source any of this,” he says.
doi: Open-source AI chatbots are booming — what does this mean for researchers?

The AI feedback loop: Researchers warn of ‘model collapse’ as AI trains on AI-generated content
As a generative AI training model is exposed to more AI-generated data, it performs worse, producing more errors, leading to model collapse.
 venturebeat.com
venturebeat.com
The AI feedback loop: Researchers warn of ‘model collapse’ as AI trains on AI-generated content
Carl Franzen@carlfranzen
June 12, 2023 6:00 AM

Credit: VentureBeat made with Midjourney
Join top executives in San Francisco on July 11-12, to hear how leaders are integrating and optimizing AI investments for success. Learn More
The age of generative AI is here: only six months after OpenAI‘s ChatGPT burst onto the scene, as many as half the employees of some leading global companies are already using this type of technology in their workflows, and many other companies are rushing to offer new products with generative AI built in.
But, as those following the burgeoning industry and its underlying research know, the data used to train the large language models (LLMs) and other transformer models underpinning products such as ChatGPT, Stable Diffusion and Midjourney comes initially from human sources — books, articles, photographs and so on — that were created without the help of artificial intelligence.
Now, as more people use AI to produce and publish content, an obvious question arises: What happens as AI-generated content proliferates around the internet, and AI models begin to train on it, instead of on primarily human-generated content?
A group of researchers from the UK and Canada have looked into this very problem and recently published a paper on their work in the open access journal arXiv. What they found is worrisome for current generative AI technology and its future: “We find that use of model-generated content in training causes irreversible defects in the resulting models.”
‘Filling the internet with blah’
Specifically looking at probability distributions for text-to-text and image-to-image AI generative models, the researchers concluded that “learning from data produced by other models causes model collapse — a degenerative process whereby, over time, models forget the true underlying data distribution … this process is inevitable, even for cases with almost ideal conditions for long-term learning.”“Over time, mistakes in generated data compound and ultimately force models that learn from generated data to misperceive reality even further,” wrote one of the paper’s leading authors, Ilia Shumailov, in an email to VentureBeat. “We were surprised to observe how quickly model collapse happens: Models can rapidly forget most of the original data from which they initially learned.”
In other words: as an AI training model is exposed to more AI-generated data, it performs worse over time, producing more errors in the responses and content it generates, and producing far less non-erroneous variety in its responses.
As another of the paper’s authors, Ross Anderson, professor of security engineering at Cambridge University and the University of Edinburgh, wrote in a blog post discussing the paper: “Just as we’ve strewn the oceans with plastic trash and filled the atmosphere with carbon dioxide, so we’re about to fill the Internet with blah. This will make it harder to train newer models by scraping the web, giving an advantage to firms which already did that, or which control access to human interfaces at scale. Indeed, we already see AI startups hammering the Internet Archive for training data.”
Ted Chiang, acclaimed sci-fi author of “Story of Your Life,” the novella that inspired the movie Arrival, and a writer at Microsoft, recently published a piece in The New Yorker postulating that AI copies of copies would result in degrading quality, likening the problem to the increased artifacts visible as one copies a JPEG image repeatedly.
Another way to think of the problem is like the 1996 sci-fi comedy movie Multiplicity starring Michael Keaton, wherein a humble man clones himself and then clones the clones, each of which results in exponentially decreasing levels of intelligence and increasing stupidity.
How ‘model collapse’ happens
In essence, model collapse occurs when the data AI models generate ends up contaminating the training set for subsequent models.“Original data generated by humans represents the world more fairly, i.e. it contains improbable data too,” Shumailov explained. “Generative models, on the other hand, tend to overfit for popular data and often misunderstand/misrepresent less popular data.”
Shumailov illustrated this problem for VentureBeat with a hypothetical scenario, wherein a machine learning model is trained on a dataset with pictures of 100 cats — 10 of them with blue fur, and 90 with yellow. The model learns that yellow cats are more prevalent, but also represents blue cats as more yellowish than they really are, returning some green-cat results when asked to produce new data. Over time, the original trait of blue fur erodes through successive training cycles, turning from blue to greenish, and ultimately yellow. This progressive distortion and eventual loss of minority data characteristics is model collapse. To prevent this, it’s important to ensure fair representation of minority groups in datasets, in terms of both quantity and accurate portrayal of distinctive features. The task is challenging due to models’ difficulty learning from rare events.
This “pollution” with AI-generated data results in models gaining a distorted perception of reality. Even when researchers trained the models not to produce too many repeating responses, they found model collapse still occurred, as the models would start to make up erroneous responses to avoid repeating data too frequently.
“There are many other aspects that will lead to more serious implications, such as discrimination based on gender, ethnicity or other sensitive attributes,” Shumailov said, especially if generative AI learns over time to produce, say, one race in its responses, while “forgetting” others exist.
It’s important to note that this phenomenon is distinct from “catastrophic forgetting,” where models lose previously learned information. In contrast, model collapse involves models misinterpreting reality based on their reinforced beliefs.
Last edited:
{continued}
The researchers behind this paper found that even if 10% of the original human-authored data is used to train the model in subsequent generations, “model collapse still happens, just not as quickly,” Shumailov told VentureBeat.
The researchers highlight two specific ways. The first is by retaining a prestige copy of the original exclusively or nominally human-produced dataset, and avoiding contaminating with with AI-generated data. Then, the model could be periodically retrained on this data, or refreshed entirely with it, starting from scratch.
The second way to avoid degradation in response quality and reduce unwanted errors or repetitions from AI models is to introduce new, clean, human-generated datasets back into their training.
However, as the researchers point out, this would require some sort of mass labeling mechanism or effort by content producers or AI companies to differentiate between AI-generated and human-generated content. At present, no such reliable or large-scale effort exists online.
“To stop model collapse, we need to make sure that minority groups from the original data get represented fairly in the subsequent datasets,” Shumailov told VentureBeat, continuing:
“In practice it is completely non-trivial. Data needs to be backed up carefully, and cover all possible corner cases. In evaluating performance of the models, use the data the model is expected to work on, even the most improbable data cases. Note that this does not mean that improbable data should be oversampled, but rather that it should be appropriately represented. As progress drives you to retrain your models, make sure to include old data as well as new. This will push up the cost of training, yet will help you to counteract model collapse, at least to some degree.”
These findings have significant implications for the field of artificial intelligence, emphasizing the need for improved methodologies to maintain the integrity of generative models over time. They underscore the risks of unchecked generative processes and may guide future research to develop strategies to prevent or manage model collapse.
“It is clear, though, that model collapse is an issue for ML and something has to be done about it to ensure generative AI continues to improve,” Shumailov said.
The researchers behind this paper found that even if 10% of the original human-authored data is used to train the model in subsequent generations, “model collapse still happens, just not as quickly,” Shumailov told VentureBeat.
Ways to avoid ‘model collapse’
Fortunately, there are ways to avoid model collapse, even with existing transformers and LLMs.The researchers highlight two specific ways. The first is by retaining a prestige copy of the original exclusively or nominally human-produced dataset, and avoiding contaminating with with AI-generated data. Then, the model could be periodically retrained on this data, or refreshed entirely with it, starting from scratch.
The second way to avoid degradation in response quality and reduce unwanted errors or repetitions from AI models is to introduce new, clean, human-generated datasets back into their training.
However, as the researchers point out, this would require some sort of mass labeling mechanism or effort by content producers or AI companies to differentiate between AI-generated and human-generated content. At present, no such reliable or large-scale effort exists online.
“To stop model collapse, we need to make sure that minority groups from the original data get represented fairly in the subsequent datasets,” Shumailov told VentureBeat, continuing:
“In practice it is completely non-trivial. Data needs to be backed up carefully, and cover all possible corner cases. In evaluating performance of the models, use the data the model is expected to work on, even the most improbable data cases. Note that this does not mean that improbable data should be oversampled, but rather that it should be appropriately represented. As progress drives you to retrain your models, make sure to include old data as well as new. This will push up the cost of training, yet will help you to counteract model collapse, at least to some degree.”
What the AI industry and users can do about it going forward
While all this news is worrisome for current generative AI technology and the companies seeking to monetize with it, especially in the medium-to-long term, there is a silver lining for human content creators: The researchers conclude that in a future filled with gen AI tools and their content, human-created content will be even more valuable than it is today — if only as a source of pristine training data for AI.These findings have significant implications for the field of artificial intelligence, emphasizing the need for improved methodologies to maintain the integrity of generative models over time. They underscore the risks of unchecked generative processes and may guide future research to develop strategies to prevent or manage model collapse.
“It is clear, though, that model collapse is an issue for ML and something has to be done about it to ensure generative AI continues to improve,” Shumailov said.
THE CURSE OF RECURSION: TRAINING ON GENERATED DATA MAKES MODELS FORGET
ABSTRACT
Stable Diffusion revolutionised image creation from descriptive text. GPT-2, GPT-3(.5) and GPT-4 demonstrated astonishing performance across a variety of language tasks. ChatGPT introduced such language models to the general public. It is now clear that large language models (LLMs) are here to stay, and will bring about drastic change in the whole ecosystem of online text and images. In this paper we consider what the future might hold. What will happen to GPT-{n} once LLMs contribute much of the language found online? We find that use of model-generated content in training causes irreversible defects in the resulting models, where tails of the original content distribution disappear. We refer to this effect as model collapse1 and show that it can occur in Variational Autoencoders, Gaussian Mixture Models and LLMs. We build theoretical intuition behind the phenomenon and portray its ubiquity amongst all learned generative models. We demonstrate that it has to be taken seriously if we are to sustain the benefits of training from large-scale data scraped from the web. Indeed, the value of data collected about genuine human interactions with systems will be increasingly valuable in the presence of content generated by LLMs in data crawled from the Internet.Jack Ma-Backed Ant Developing Large Language Model Technology
By
Lulu Yilun Chen
June 21, 2023, 3:54 AM UTC
Follow the authors
@luluyilun
Jack Ma-backed Ant Group Co. is developing large-language model technology that will power ChatGPT-style services, joining a list of Chinese companies seeking to win an edge in next-generation artificial intelligence.
The project known as “Zhen Yi” is being created by a dedicated unit and will deploy in-house research. An Ant spokesperson confirmed the news which was first reported by Chinastarmarket.cn
Ant is racing against companies including its affiliate Alibaba Group Holding Ltd., Baidu Inc. and SenseTime Group Inc. Their efforts mirror developments in US where Alphabet Inc.’s Google and Microsoft Corp. are exploring generative AI, which can create original content from poetry to art just with simple user prompts.
AI has become the next big arena for tech competition between China and the US, raising concerns over whether Chinese companies will be able to retain reliable access to the high-end chips needed to develop large-scale AI models in the long run.
Ant invested nearly 20.5 billion yuan ($2.8 billion) in R&D last year, doubling the company’s annual spending on such efforts compared with 2019. The company is strengthening tech for distributed databases, computer infrastructure, blockchain, privacy computing and network security.
Orca LLM is the underdog that's shaking up the AI world.
Many believe that only large-scale models like GPT-3.5 and GPT-4 can deliver high-quality AI performance. But that's not the full picture.
Orca (by Microsoft Research) a 13B model, is proving to be a formidable contender, rivaling GPT-3.5's capabilities while being small enough to run on a laptop.
It achieves this by imitating the logic and explanations of larger models and training on diverse tasks with an order of magnitude more examples.
Compare its performance with larger models and we find that in a zero-shot setting, Orca has outperformed ChatGPT in the Big-Bench Hard suite, a benchmark that tests the AI's performance across a wide range of tasks.
Orca scored higher than ChatGPT and was nearly identical to text-davinci-003 in the AGIEval benchmark. However, Orca still significantly lags behind GPT-4 in these metrics.
Orca managed to retain 88% of ChatGPT's quality and outperformed Vicuna, another LLM, by 42% in terms of overall performance and by 113% in the Big-Bench Hard suite1.
In the world of AI, size isn't everything. Orca LLM is a testament to that.
Open-source is making progress, this is the key takeaway.
Many believe that only large-scale models like GPT-3.5 and GPT-4 can deliver high-quality AI performance. But that's not the full picture.
Orca (by Microsoft Research) a 13B model, is proving to be a formidable contender, rivaling GPT-3.5's capabilities while being small enough to run on a laptop.
It achieves this by imitating the logic and explanations of larger models and training on diverse tasks with an order of magnitude more examples.
Compare its performance with larger models and we find that in a zero-shot setting, Orca has outperformed ChatGPT in the Big-Bench Hard suite, a benchmark that tests the AI's performance across a wide range of tasks.
Orca scored higher than ChatGPT and was nearly identical to text-davinci-003 in the AGIEval benchmark. However, Orca still significantly lags behind GPT-4 in these metrics.
Orca managed to retain 88% of ChatGPT's quality and outperformed Vicuna, another LLM, by 42% in terms of overall performance and by 113% in the Big-Bench Hard suite1.
In the world of AI, size isn't everything. Orca LLM is a testament to that.
Open-source is making progress, this is the key takeaway.

Orca - a New Open Source LLM Champ
A new 13B "open source" model beats competitors in many benchmarks, and even approaches, or beats, ChatGPT in many areas. The most interesting part is how this was achieved.
 engineeringprompts.substack.com
engineeringprompts.substack.com
Orca - a New Open Source LLM Champ
A new 13B "open source" model beats competitors in many benchmarks, and even approaches, or beats, ChatGPT in many areas. The most interesting part is how this was achieved.
MARCEL SALATHÉ
JUN 8, 2023
A few days ago, Microsoft released a paper on a new open source model called Orca. This is a highly interesting development for at least three reasons:
- The model outperforms other open-source models, earning the top spot among these models across many benchmarks.
- Remarkably, despite having "only" 13 billion parameters, this model often achieves the performance of GPT-3.5 (the free version of ChatGPT), a model about ten times larger. In some areas, it even rivals GPT-4.
- This achievement was made possible by using GPT-4’s reasoning capabilities - activated through prompts like “think step by step” - as a tutor.

Prompt Engineering is a reader-supported publication. To receive new posts and support my work, consider becoming a free or paid subscriber.
What is Orca
Orca is a 13-billion parameter model that learns to imitate the reasoning process of models like GPT-4. It outperforms Vicuna, a previously leading open-source model, on many benchmarks, and in some cases, matches or exceeds the capabilities of ChatGPT (GPT-3.5).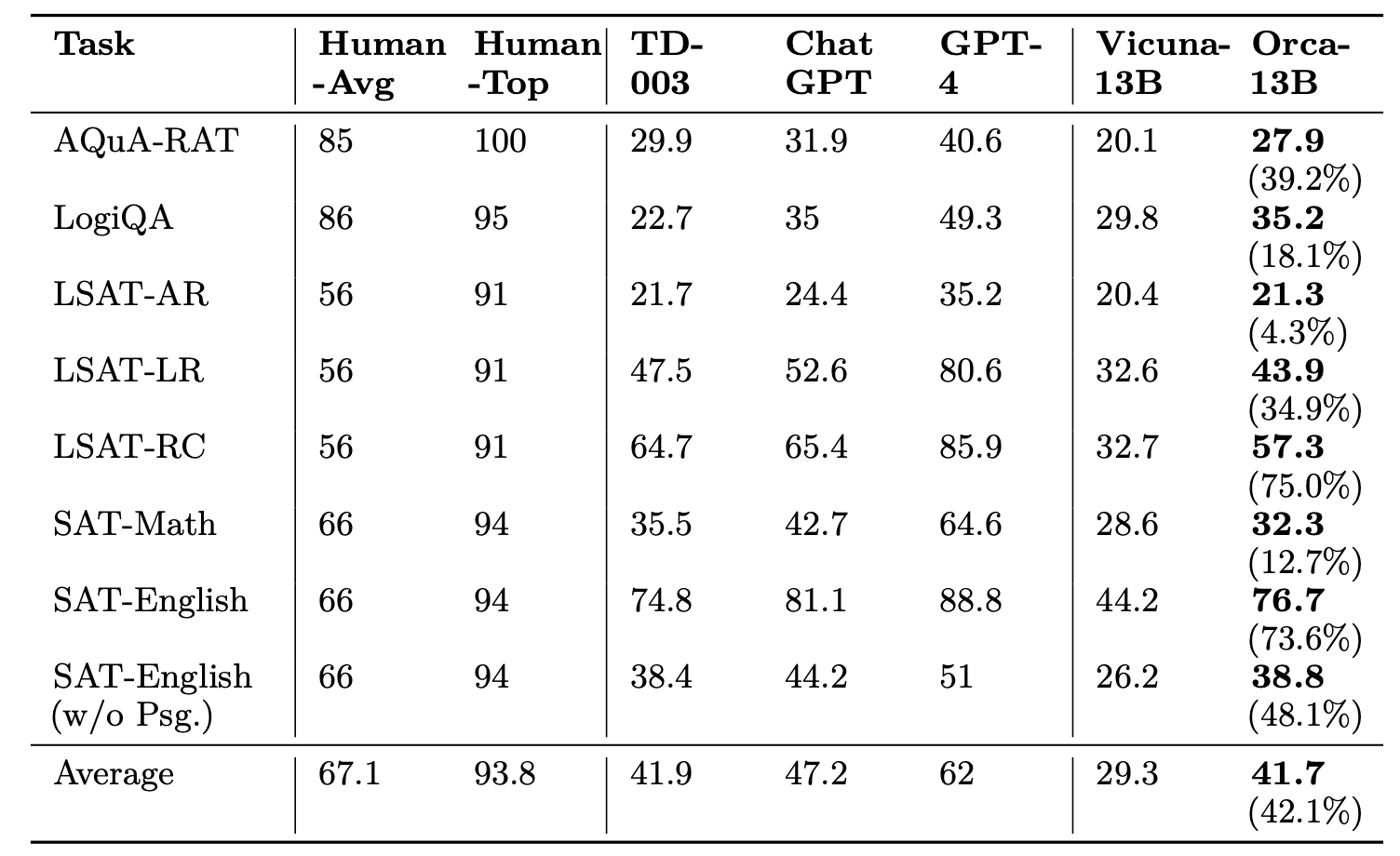
Zero-shot performance comparison of models on multiple-choice English questions
Orca is set to be open-source, but isn’t quite there yet. The authors note that they “are working with our legal team to publicly release a diff of the model weights in accordance with LLaMA’s release policy to be published”. This is a fairly strong commitment, coming from Microsoft, so I fully expect this to happen, and I think we can thus treat Orca as an open-source model even now.
One major strength of this paper is the extensive evaluation of the model on numerous benchmarks. While I won't go into all of them, I should note that Orca's performance is extremely impressive, even occasionally surpassing GPT-4. This should be taken with a grain of salt, of course, but the overall performance enhancements over the similarly sized Vicuna model are simply remarkable.
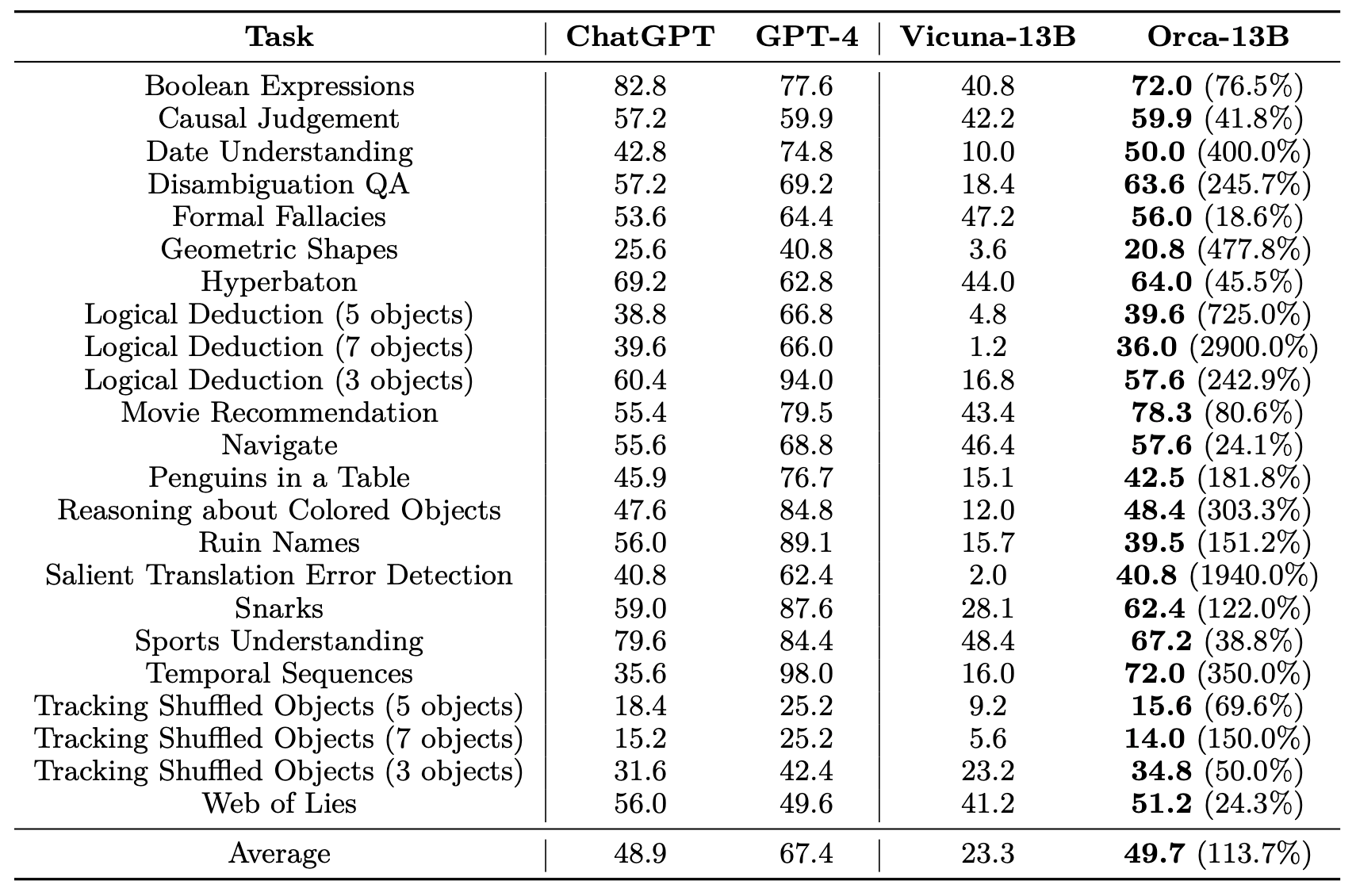
Zero-shot performance comparison of models on multiple-choice questions of Big-Bench Hard benchmark. Improvement of Orca over Vicuna is given in parentheses.
Move over, Camelids - the age of the Oceanic dolphins has arrived.
How this was achieved
In my view, this is the most fascinating part of the paper. Essentially, the authors achieved these results by leveraging GPT-4’s reasoning capabilities - triggered by prompts such as “think step by step” or “explain it to me like I’m five” - as a tutor.Previous open-source models have also built upon outputs from ChatGPT. However, they've primarily used pairs of questions and answers to fine-tune the model. Orca advances beyond this approach by learning not only from the answers but also from the reasoning that GPT-4 exhibits.

It's important to note that Orca's evaluations were all conducted using zero-shot standard prompts. This means that Orca directly attempted to address whatever challenge each benchmark posed. In other words, it's quite likely that the impressive performance highlighted in this paper is merely a baseline. Orca could potentially perform even better if it used other techniques, such as a chain-of-thought and others.
