
You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
The A.I Megathread (LLM , GPT , Development)
More options
Who Replied?

OpenAI’s Code Interpreter
Is About to Remake Finance
Get in loser, we’re disrupting Oracle
BY EVAN ARMSTRONG
JUNE 15, 2023

Image prompt: a cyberpunk bloomberg terminal, watercolor
Like most startups right now, this publication has been looking at how to reduce our expenses with AI. One area I’ve been experimenting with is seeing just how much accounting minutiae I can automate. Recently I had a breakthrough thanks to a ChatGPT plug-in called Code Interpreter. This plug-in is not widely available (so don’t be sad if you don’t have it on your account yet), but it allows a user to upload a file and then ChatGPT will write Python to understand and analyze the data in that file.
I know that sounds simple, but that is basically what every finance job on the planet does. You take a fairly standard form, something like an income statement or a general ledger, populate it with data, and then run analysis on top of that data. This means that, theoretically, Code Interpreter can do the majority of finance work. What does it mean when you can do sophisticated analysis for <$0.10 a question? What does it mean when you can use Code Interpreter to answer every question that involves spreadsheets?
It is easy to allow your eyes to glaze over with statements like that. Between the AI Twitter threads, the theatrically bombastic headlines, and the drums of corporate PR constantly beating, the temptation is to dismiss AI stuff as hyperbole. Honestly, that’s where I’m at. Most of the AI claims I see online I dismiss on principle.
With that perspective in mind, please take me seriously when I say this: I’ve glimpsed the future and it is weird. Code Interpreter has a chance to remake knowledge work as we know it. To arrive at that viewpoint, I started somewhere boring—accounting.
General Ledger Experiments
First, I have to clarify: AI has been used by accountants for a long time. It just depends on what techniques you give the moniker of artificial intelligence. The big accounting firms will sometimes use machine learning models to classify risk. However, because LLMs like GPT-4 and Claude are still relatively new, these techniques haven’t been widely integrated into auditors’ or accountants’ workflows.
Imagine having an AI assistant sort your inbox for optimum productivity. That's SaneBox - it filters emails using smart algorithms, helping you tackle crucial messages first. Say goodbye to distractions with features like auto-reply tracking, one-click unsubscribing, and do-not-disturb mode.
SaneBox works seamlessly across devices and clients, maintaining privacy by only reading headers. Experience the true work-life balance as SaneBox users save an average of 3-4 hours weekly. Elevate your email game with SaneBox's secure and high-performing solution - perfect for Office 365 and backed by a 43% trial conversion rate.
Get a FREE 14 day trial
Want to hide ads? Become a subscriber
When I say, “I want to replace my accountant with a Terminator robot,” I’m specifically looking for a way to use large language models to automate work that an accountant would typically do.

My journey to nerdy Skynet started simply.
I uploaded Every’s general ledger—a spreadsheet that lists out all of the debits and credits for a period—into ChatGPT. My goal was to run a battery of tests that an auditing firm would do: tasks like looking for strange transactions, checking on the health of the business, stuff like that. Importantly, these are rather abstract tests. They are a variety of small pieces of analysis that then build into a cohesive understanding of the health of a business.
Once the file is uploaded, the system goes to work. It realizes this CSV is a general ledger and then writes five blocks of code to make it readable for itself.

Note: I’ll have to do some creative image sizing here because I don’t want to expose our bank account info. Images will all be supplemental and are not necessary for reading this piece.
It classifies the data and is ready for me to ask it questions in ~10 seconds. Compare that with the usual 24-hour turnaround time on emails with an accountant.
From there, I run the AI through some of these small tests an auditor would do. First, I ask it to create a graph showing the volume of transactions by week. An auditor would do this analysis as a very simplistic risk test—if there was a week with unusually high volume, they would want to examine that further.
In ~10 seconds, faster than a finance professional could do it with a pivot table and charting tool, I have a graph.
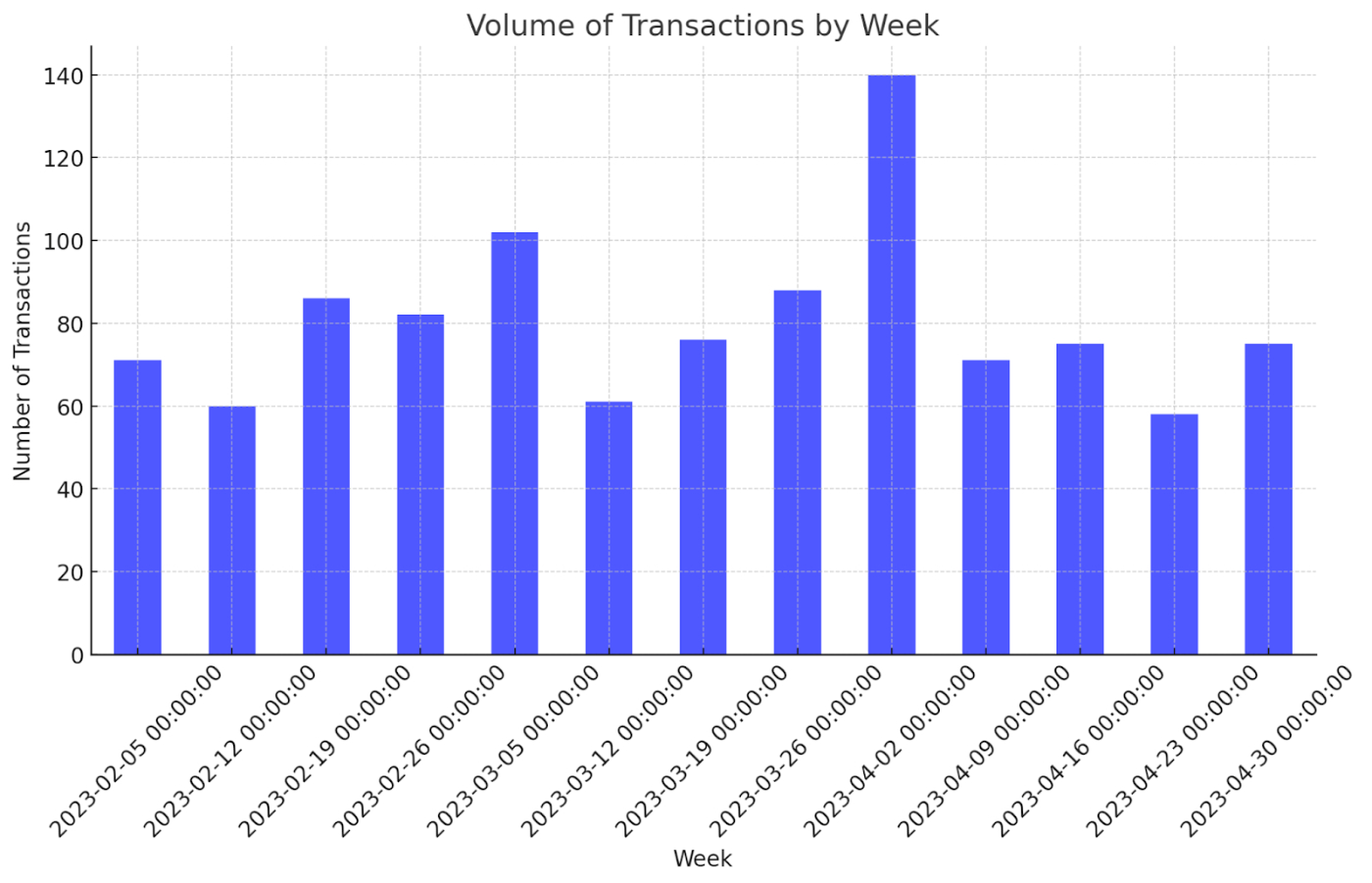
Cool but not amazing. Let’s push it further.
Next, I decided to test its knowledge. The role of an auditor/accountant is to figure out how safe a business is. To do so, they’ll often use things like the acid-test ratio, which measures how quickly a company could meet unexpected bills. Importantly, you cannot measure this ratio with a general ledger! It requires a balance sheet—a ledger doesn’t tell you about the asset liquidity necessary for paying bills. Thankfully, the AI passes the pop quiz with flying colors.

It recognizes that it can’t perform this test on the general ledger and needs a balance sheet. If we were to actually perform this test, I’d prefer a slightly different version of the formula, but still, it gets the important things right. As a note to our investors, don’t panic—I just ran this formula myself and we aren’t going bankrupt quite yet.
Next, I’ll try something it actually can do with a ledger—a data quality check. In trying to speak to it the same way I would to a normal human, I ask, “Yo, is the data good?” It responds with five different ways of testing the data. The first four I can’t show for privacy reasons. However, in each case, the analysis was performed correctly. For those keeping track, we are at six tasks an auditor would do automated with AI. The final data test was the first glaring error in my experiment. It found 13 outliers “that are more than 3 standard deviations away from the mean.”
{continued}

I then asked it to list out the 13 reasons. None of them were actually outliers—they were all column or row sums that the system thought was an expense. In short, the AI was foiled by formatting.
The system messed up, not because of the data, but because it got confused by how the data was labeled. This is the world’s smartest and dumbest intern simultaneously. You have to keep an eye on it. When we make spreadsheets, we often do things to make them more human-readable, actions like removing gridlines or bolding important numbers. For this to work in a product, the files need to be more machine-readable. What is remarkable is how far the system can get even though this data is clearly not meant for its eyes.
I let the AI know it made a mistake, it apologized, and we fixed the issue together by going in and editing the sheet directly and reuploading it.
Then I got really funky with it. I also uploaded our P&L in the same chat and asked ChatGPT to perform reconciliation. This is where you can compare transaction-level data with aggregated performance on a monthly level.
The good news: It can simultaneously run analysis on multiple files. It was able to successfully compare monthly expenses in the ledger to the P&L. The bad news: The result was very wrong.
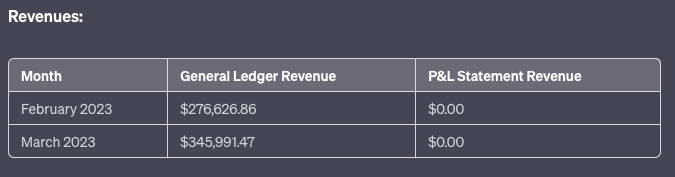
Once again, I was caught by the formatting errors. The AI struggled to get around formatting issues with just one spreadsheet. If you add two spreadsheets with wildly diverse formatting styles, the system goes kablooey. I tried asking it to reformat the files into something it could read, but the errors started to compound on themselves. Based on my discussion with hackers on the topic, I think it has to do with the titles of rows versus the titles of columns, but this is an area for further experimentation. Code Interpreter can do single document analysis easily, but starts to struggle the more files you give it to examine.
I stand by my claim from the intro, I think that AI can replace some portion of knowledge workers. Here’s why: These are all easily fixable problems. Rework the general ledger and P&L to have identical formatting, load them into a database with the Stripe API, then reap the benefits of a fully automated accountant.
You could then use Code Interpreter to do financial analysis on top of all this—for things like discounted cash flow—and now you have an automated finance department. It won’t do all the work, but it’ll get you 90% of the way there. And the 10% remaining labor looks a lot more like the job of a data engineer than a financial analyst.
Frankly, this is a $50B opportunity. A company with this product would have a legitimate shot at becoming the dominant tool for accounting and finance. They could take down QuickBooks or Oracle. Someone should be building this. The tech is right there for the taking!
The key question will be how OpenAI exposes Code Interpreter. If it is simply a plug-in on ChatGPT, startups shouldn’t bother. But if they expose it through an API, there is a real chance of disruption. There will be a ton of work a startup could do around piping in sales data and formatting. Adding in features like multiplayer or single sign-on would be enough to justify a startup’s existence. As a person who does not hate their life, I will not be selling B2B software, so feel free to use this idea (and send me an adviser check please).
This is a cool experiment—but I think there are bigger takeaways.
One of the great challenges of building in AI right now is understanding where profit pools accrue.
Up until this experiment, I was in the camp that the value will mostly go to the incumbents who add AI capabilities to existing workflows or proprietary datasets. This, so far, has mostly turned out to be true. Microsoft is the clear leader in AI at scale and they show no sign of slowing down.
However, this little dumb exercise with the general ledger is about more than accounting. It gave me a hint of how AI will be upending the entire world of productivity. There is a chance to so radically redefine workflows that existing companies won’t be able to transition to this new future. Startups have a real shot at going after Goliath.
I am a moron. I am not technical, and I sling essays for a living. Despite that, I was able to automate a significant portion of the labor our auditors do. What happens when a legitimately talented team productizes this?
All productivity work is taking data inputs and then transforming them into outputs. Code Interpreter is an improvement over previous AI systems because it goes from prose as an input to raw data as an input. The tool is an abstraction layer over thinking itself. It is a reasoning thing, a thinking thing—it is not a finance tool. They don’t even mention the finance use case in the launch announcement! There is so much opportunity here to remake what work we do. Code Interpreter means that you don’t even need access to a fancy API or database. If OpenAI decides to build for it, all we will need is a command bar and a file.
I’ve heard some version of this idea, of AI remaking labor, over and over again during the past year. But I truly saw it happen for the first time with this tool. It isn’t without flaws or problems, but it is coming. The exciting scary horrifying invigorating wonderful awful thing is that this is only with an alpha product less than six months old. What about the next edition of models? Or what will other companies release?
This is not a far-off question. This is, like, an 18 months away question.
One of the most under-discussed news articles of the past six months was Anthropic’s (OpenAI’s biggest rival) leaked pitch deck from April. The reported version said that it wanted a billion dollars to build “Claude-Next,” which would be 10x more powerful than GPT-4. I have had confirmation from several sources that other versions of that deck claimed a 50x improvement over GPT-4.
Really sit with that idea. Let it settle in and germinate. What does a system that’s 50x more intelligent than Code Interpreter mean for knowledge labor? I’ve heard rumors of similar scaling capabilities being discussed at OpenAI.
Who knows if they deliver, but man, can you imagine if we get a 50x better model in two years? Yes, these are pitch deck claims, which are wholly unreliable, but what happens if they are right? Even a deflated 10x better model makes for an unimaginable world.
It would mean a total reinvention of knowledge work. It would mean that startups have a chance to take down the giants. As Anthropic said in its pitch deck, “These models could begin to automate large portions of the economy.”
This experiment gave me a glimpse of that future. I hope you’re ready.

I then asked it to list out the 13 reasons. None of them were actually outliers—they were all column or row sums that the system thought was an expense. In short, the AI was foiled by formatting.
The system messed up, not because of the data, but because it got confused by how the data was labeled. This is the world’s smartest and dumbest intern simultaneously. You have to keep an eye on it. When we make spreadsheets, we often do things to make them more human-readable, actions like removing gridlines or bolding important numbers. For this to work in a product, the files need to be more machine-readable. What is remarkable is how far the system can get even though this data is clearly not meant for its eyes.
I let the AI know it made a mistake, it apologized, and we fixed the issue together by going in and editing the sheet directly and reuploading it.
Then I got really funky with it. I also uploaded our P&L in the same chat and asked ChatGPT to perform reconciliation. This is where you can compare transaction-level data with aggregated performance on a monthly level.
Things fall apart
The good news: It can simultaneously run analysis on multiple files. It was able to successfully compare monthly expenses in the ledger to the P&L. The bad news: The result was very wrong.
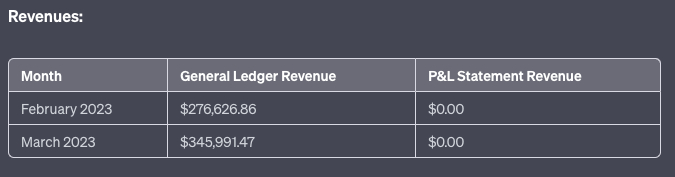
Once again, I was caught by the formatting errors. The AI struggled to get around formatting issues with just one spreadsheet. If you add two spreadsheets with wildly diverse formatting styles, the system goes kablooey. I tried asking it to reformat the files into something it could read, but the errors started to compound on themselves. Based on my discussion with hackers on the topic, I think it has to do with the titles of rows versus the titles of columns, but this is an area for further experimentation. Code Interpreter can do single document analysis easily, but starts to struggle the more files you give it to examine.
I stand by my claim from the intro, I think that AI can replace some portion of knowledge workers. Here’s why: These are all easily fixable problems. Rework the general ledger and P&L to have identical formatting, load them into a database with the Stripe API, then reap the benefits of a fully automated accountant.
You could then use Code Interpreter to do financial analysis on top of all this—for things like discounted cash flow—and now you have an automated finance department. It won’t do all the work, but it’ll get you 90% of the way there. And the 10% remaining labor looks a lot more like the job of a data engineer than a financial analyst.
Frankly, this is a $50B opportunity. A company with this product would have a legitimate shot at becoming the dominant tool for accounting and finance. They could take down QuickBooks or Oracle. Someone should be building this. The tech is right there for the taking!
The key question will be how OpenAI exposes Code Interpreter. If it is simply a plug-in on ChatGPT, startups shouldn’t bother. But if they expose it through an API, there is a real chance of disruption. There will be a ton of work a startup could do around piping in sales data and formatting. Adding in features like multiplayer or single sign-on would be enough to justify a startup’s existence. As a person who does not hate their life, I will not be selling B2B software, so feel free to use this idea (and send me an adviser check please).
This is a cool experiment—but I think there are bigger takeaways.
Maybe the future is weirder than you think
One of the great challenges of building in AI right now is understanding where profit pools accrue.
Up until this experiment, I was in the camp that the value will mostly go to the incumbents who add AI capabilities to existing workflows or proprietary datasets. This, so far, has mostly turned out to be true. Microsoft is the clear leader in AI at scale and they show no sign of slowing down.
However, this little dumb exercise with the general ledger is about more than accounting. It gave me a hint of how AI will be upending the entire world of productivity. There is a chance to so radically redefine workflows that existing companies won’t be able to transition to this new future. Startups have a real shot at going after Goliath.
I am a moron. I am not technical, and I sling essays for a living. Despite that, I was able to automate a significant portion of the labor our auditors do. What happens when a legitimately talented team productizes this?
All productivity work is taking data inputs and then transforming them into outputs. Code Interpreter is an improvement over previous AI systems because it goes from prose as an input to raw data as an input. The tool is an abstraction layer over thinking itself. It is a reasoning thing, a thinking thing—it is not a finance tool. They don’t even mention the finance use case in the launch announcement! There is so much opportunity here to remake what work we do. Code Interpreter means that you don’t even need access to a fancy API or database. If OpenAI decides to build for it, all we will need is a command bar and a file.
I’ve heard some version of this idea, of AI remaking labor, over and over again during the past year. But I truly saw it happen for the first time with this tool. It isn’t without flaws or problems, but it is coming. The exciting scary horrifying invigorating wonderful awful thing is that this is only with an alpha product less than six months old. What about the next edition of models? Or what will other companies release?
This is not a far-off question. This is, like, an 18 months away question.
One of the most under-discussed news articles of the past six months was Anthropic’s (OpenAI’s biggest rival) leaked pitch deck from April. The reported version said that it wanted a billion dollars to build “Claude-Next,” which would be 10x more powerful than GPT-4. I have had confirmation from several sources that other versions of that deck claimed a 50x improvement over GPT-4.
Really sit with that idea. Let it settle in and germinate. What does a system that’s 50x more intelligent than Code Interpreter mean for knowledge labor? I’ve heard rumors of similar scaling capabilities being discussed at OpenAI.
Who knows if they deliver, but man, can you imagine if we get a 50x better model in two years? Yes, these are pitch deck claims, which are wholly unreliable, but what happens if they are right? Even a deflated 10x better model makes for an unimaginable world.
It would mean a total reinvention of knowledge work. It would mean that startups have a chance to take down the giants. As Anthropic said in its pitch deck, “These models could begin to automate large portions of the economy.”
This experiment gave me a glimpse of that future. I hope you’re ready.
Automated prompting and scoring framework to evaluate LLMs using updated human knowledge prompts

GitHub - aigoopy/llm-jeopardy: Automated prompting and scoring framework to evaluate LLMs using updated human knowledge prompts
Automated prompting and scoring framework to evaluate LLMs using updated human knowledge prompts - aigoopy/llm-jeopardy
 github.com
github.com
Last edited:

Introducing Voicebox: The first generative AI model for speech to generalize across tasks with state-of-the-art performance
Voicebox is a state-of-the-art speech generative model based on a new method proposed by Meta AI called Flow Matching. By learning to solve a text-guided speech infilling task with a large scale of data, Voicebox outperforms single-purpose AI models across speech tasks through in-context learning.
 ai.facebook.com
ai.facebook.com
.png)
Voicebox: Text-Guided Multilingual Universal Speech Generation at Scale – Meta Research | Meta Research
This paper presents Voicebox, the most versatile text-conditioned speech generative model at scale. Voicebox is trained on a text-guided speech infilling task, where the goal is to generate masked speech given its surrounding audio and text transcript.
 research.facebook.com
research.facebook.com
edit:
Meta AI researchers have achieved a breakthrough in generative AI for speech. We’ve developed Voicebox, the first model that can generalize to speech-generation tasks it was not specifically trained to accomplish with state-of-the-art performance.
RECOMMENDED READS
Introducing Make-A-Video: An AI system that generates videos from text
Greater creative control for AI image generation
Introducing LLaMA: A foundational, 65-billion-parameter large language model
Like generative systems for images and text, Voicebox creates outputs in a vast variety of styles, and it can create outputs from scratch as well as modify a sample it’s given. But instead of creating a picture or a passage of text, Voicebox produces high-quality audio clips. The model can synthesize speech across six languages, as well as perform noise removal, content editing, style conversion, and diverse sample generation.
Prior to Voicebox, generative AI for speech required specific training for each task using carefully prepared training data. Voicebox uses a new approach to learn just from raw audio and an accompanying transcription. Unlike autoregressive models for audio generation, Voicebox can modify any part of a given sample, not just the end of an audio clip it is given.
Voicebox is based on a method called Flow Matching, which has been shown to improve upon diffusion models. Voicebox outperforms the current state of the art English model VALL-E on zero-shot text-to-speech in terms of both intelligibility (5.9 percent vs. 1.9 percent word error rates) and audio similarity (0.580 vs. 0.681), while being as much as 20 times faster. For cross-lingual style transfer, Voicebox outperforms YourTTS to reduce average word error rate from 10.9 percent to 5.2 percent, and improves audio similarity from 0.335 to 0.481.
Voicebox achieves new state-of-the-art results, outperforming Vall-E and YourTTS on word error rate.
Voicebox also achieves new state-of-the-art results on audio style similarity metrics on English and multilingual benchmarks, respectively.
There are many exciting use cases for generative speech models, but because of the potential risks of misuse, we are not making the Voicebox model or code publicly available at this time. While we believe it is important to be open with the AI community and to share our research to advance the state of the art in AI, it’s also necessary to strike the right balance between openness with responsibility. With these considerations, today we are sharing audio samples and a research paper detailing the approach and results we have achieved. In the paper, we also detail how we built a highly effective classifier that can distinguish between authentic speech and audio generated with Voicebox.
A new approach to speech generation
One of the main limitations of existing speech synthesizers is that they can only be trained on data that has been prepared expressly for that task. These inputs – known as monotonic, clean data – are difficult to produce, so they exist only in limited quantities, and they result in outputs that sound monotone.
We built Voicebox upon the Flow Matching model, which is Meta’s latest advancement on non-autoregressive generative models that can learn highly non-deterministic mapping between text and speech. Non-deterministic mapping is useful because it enables Voicebox to learn from varied speech data without those variations having to be carefully labeled. This means Voicebox can train on more diverse data and a much larger scale of data.
We trained Voicebox with more than 50,000 hours of recorded speech and transcripts from public domain audiobooks in English, French, Spanish, German, Polish, and Portuguese. Voicebox is trained to predict a speech segment when given the surrounding speech and the transcript of the segment. Having learned to infill speech from context, the model can then apply this across speech generation tasks, including generating portions in the middle of an audio recording without having to re-create the entire input.
This versatility enables Voicebox to perform well across a variety of tasks, including:
In-context text-to-speech synthesis: Using an input audio sample just two seconds in length, Voicebox can match the sample’s audio style and use it for text-to-speech generation. Future projects could build on this capability by bringing speech to people who are unable to speak, or by allowing people to customize the voices used by nonplayer characters and virtual assistants.
Cross-lingual style transfer: Given a sample of speech and a passage of text in English, French, German, Spanish, Polish, or Portuguese, Voicebox can produce a reading of the text in that language. This capability is exciting because in the future it could be used to help people communicate in a natural, authentic way — even if they don’t speak the same languages.
Speech denoising and editing: Voicebox’s in-context learning makes it good at generating speech to seamlessly edit segments within audio recordings. It can resynthesize the portion of speech corrupted by short-duration noise, or replace misspoken words without having to rerecord the entire speech. A person could identify which raw segment of the speech is corrupted by noise (like a dog barking), crop it, and instruct the model to regenerate that segment. This capability could one day be used to make cleaning up and editing audio as easy as popular image-editing tools have made adjusting photos.
Last edited:
Unifying Large Language Models and Knowledge Graphs: A Roadmap
Abstract—
Large language models (LLMs), such as ChatGPT and GPT4, are making new waves in the field of natural language processing and artificial intelligence, due to their emergent ability and generalizability. However, LLMs are black-box models, which often fall short of capturing and accessing factual knowledge. In contrast, Knowledge Graphs (KGs), Wikipedia and Huapu for example, are structured knowledge models that explicitly store rich factual knowledge. KGs can enhance LLMs by providing external knowledge for inference and interpretability. Meanwhile, KGs are difficult to construct and evolving by nature, which challenges the existing methods in KGs to generate new facts and represent unseen knowledge. Therefore, it is complementary to unify LLMs and KGs together and simultaneously leverage their advantages. In this article, we present a forward-looking roadmap for the unification of LLMs and KGs. Our roadmap consists of three general frameworks, namely, 1) KG-enhanced LLMs, which incorporate KGs during the pre-training and inference phases of LLMs, or for the purpose of enhancing understanding of the knowledge learned by LLMs; 2) LLM-augmented KGs, that leverage LLMs for different KG tasks such as embedding, completion, construction, graph-to-text generation, and question answering; and 3) Synergized LLMs + KGs, in which LLMs and KGs play equal roles and work in a mutually beneficial way to enhance both LLMs and KGs for bidirectional reasoning driven by both data and knowledge. We review and summarize existing efforts within these three frameworks in our roadmap and pinpoint their future research directions. Index Terms—Natural Language Processing, Large Language Models, Generative Pre-Training, Knowledge Graphs, Roadmap, Bidirectional Reasoning
Last edited:

Apple Researchers Introduce ByteFormer: An AI Model That Consumes Only Bytes And Does Not Explicitly Model The Input Modality
Apple Researchers Introduce ByteFormer: An AI Model That Consumes Only Bytes And Does Not Explicitly Model The Input Modality
 www.marktechpost.com
www.marktechpost.com
Apple Researchers Introduce ByteFormer: An AI Model That Consumes Only Bytes And Does Not Explicitly Model The Input Modality
The explicit modeling of the input modality is typically required for deep learning inference. For instance, by encoding picture patches into vectors, Vision Transformers (ViTs) directly model the 2D spatial organization of images. Similarly, calculating spectral characteristics (like MFCCs) to transmit into a network is frequently involved in audio inference. A user must first decode a file into a modality-specific representation (such as an RGB tensor or MFCCs) before making an inference on a file that is saved on a disc (such as a JPEG image file or an MP3 audio file), as shown in Figure 1a. There are two real downsides to decoding inputs into a modality-specific representation.
It first involves manually creating an input representation and a model stem for each input modality. Recent projects like PerceiverIO and UnifiedIO have demonstrated the versatility of Transformer backbones. These techniques still need modality-specific input preprocessing, though. For instance, before sending picture files into the network, PerceiverIO decodes them into tensors. Other input modalities are transformed into various forms by PerceiverIO. They postulate that executing inference directly on file bytes makes it feasible to eliminate all modality-specific input preprocessing. The exposure of the material being analyzed is the second disadvantage of decoding inputs into a modality-specific representation.
Think of a smart home gadget that uses RGB photos to conduct inference. The user’s privacy may be jeopardized if an enemy gains access to this model input. They contend that deduction can instead be carried out on inputs that protect privacy. They make notice that numerous input modalities share the ability to be saved as file bytes to solve these shortcomings. As a result, they feed file bytes into their model at inference time (Figure 1b) without doing any decoding. Given their capability to handle a range of modalities and variable-length inputs, they adopt a modified Transformer architecture for their model.
Researchers from Apple introduce a model known as ByteFormer. They use data stored in the TIFF format to show the effectiveness of ByteFormer on ImageNet categorization, attaining a 77.33% accuracy rate. Their model uses the DeiT-Ti transformer backbone hyperparameters, which achieved 72.2% accuracy on RGB inputs. Additionally, they provide excellent outcomes with JPEG and PNG files. Further, they show that without any modifications to the architecture or hyperparameter tweaking, their classification model can reach 95.8% accuracy on Speech Commands v2, equivalent to state-of-the-art (98.7%).
They can also utilize ByteFormer to work on inputs that maintain privacy because it can handle several input forms. They show that they can disguise inputs without sacrificing accuracy by remapping input byte values using the permutation function ϕ : [0, 255] → [0, 255] (Figure 1c). Even though this does not ensure cryptography-level security, they show how this approach may be used as a foundation for masking inputs into a learning system. By using ByteFormer to make inferences on a partly generated picture, it is possible to achieve greater privacy (Figure 1d). They show that ByteFormer can train on images with 90% of the pixels obscured and achieve an accuracy of 71.35% on ImageNet.
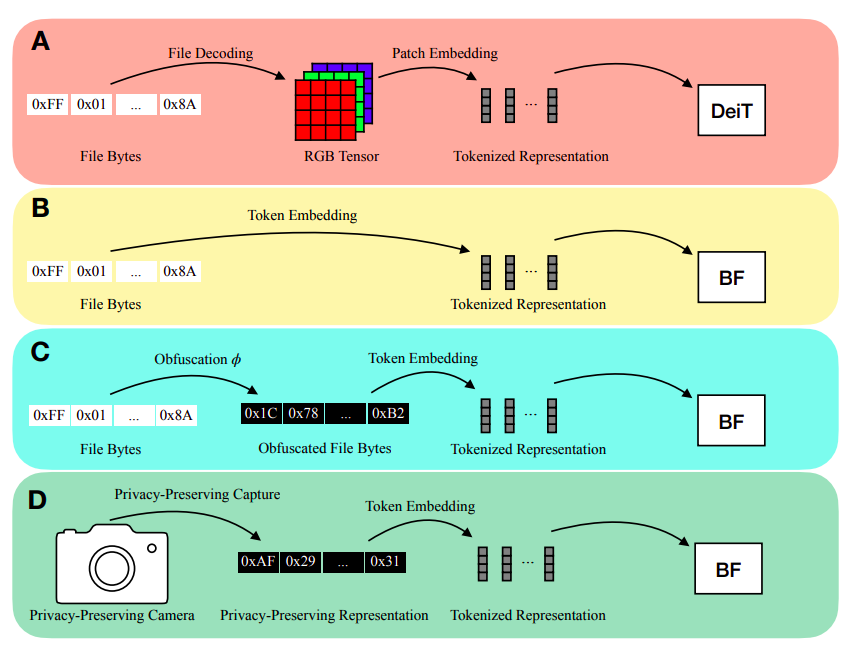
Figure 1 shows a comparison between our ByteFormer (BF) and traditional inference using DeiT. (A): Using a common image decoder, file data are read from disc and transformed into an RGB tensor. Tokens are produced from the RGB representation using patch embedding. (B): Disc file bytes are projected into learned embeddings and utilized directly as tokens. (C): Comparable to (B), but with the addition of an obfuscation function. (D): Using a customized camera, we record a representation that protects privacy and then execute token embedding from it.
Knowing the precise location of unmasked pixels to use ByteFormer is unnecessary. By avoiding a typical image capture, the representation given to their model ensures anonymity. Their brief contributions are: (1) They create a model called ByteFormer to make inferences on file bytes. (2) They demonstrate that ByteFormer performs well on several picture and audio file encodings without requiring architectural modifications or hyperparameter optimization. (3) They give an example of how ByteFormer may be used with inputs that protect privacy. (4) They look at the characteristics of ByteFormers that have been taught to categorize audio and visual data straight from file bytes. (5) They publish their code on GitHub as well.
Check Out The Paper.
Google Bard summary.
When you want to use a deep learning model to make predictions on a file, you usually have to decode the file into a special format that the model can understand. This is because deep learning models are designed to work with specific types of data, like images or audio. For example, if you want to use a deep learning model to classify images, you would have to decode the image file into an RGB tensor.
But decoding files can be a problem. First, it can be a lot of work to create a decoder for each different type of file. Second, decoding files can expose the data that you are trying to keep private.
A new model called ByteFormer solves both of these problems. ByteFormer can make predictions directly on file bytes, without having to decode the files first. This makes it much easier to use ByteFormer with different types of files, and it also protects the privacy of the data that you are using.
ByteFormer has been shown to work well on a variety of tasks, including image classification and speech recognition. In fact, ByteFormer achieves state-of-the-art accuracy on some tasks.
Here are some of the benefits of using ByteFormer:
- It is easier to use with different types of files.
- It protects the privacy of the data that you are using.
- It is more accurate than other models on some tasks.
Last edited:
FinGPT: Open-Source Financial Large Language Models
Hongyang Yang, Xiao-Yang Liu, Christina Dan WangLarge language models (LLMs) have shown the potential of revolutionizing natural language processing tasks in diverse domains, sparking great interest in finance. Accessing high-quality financial data is the first challenge for financial LLMs (FinLLMs). While proprietary models like BloombergGPT have taken advantage of their unique data accumulation, such privileged access calls for an open-source alternative to democratize Internet-scale financial data.
In this paper, we present an open-source large language model, FinGPT, for the finance sector. Unlike proprietary models, FinGPT takes a data-centric approach, providing researchers and practitioners with accessible and transparent resources to develop their FinLLMs. We highlight the importance of an automatic data curation pipeline and the lightweight low-rank adaptation technique in building FinGPT. Furthermore, we showcase several potential applications as stepping stones for users, such as robo-advising, algorithmic trading, and low-code development. Through collaborative efforts within the open-source AI4Finance community, FinGPT aims to stimulate innovation, democratize FinLLMs, and unlock new opportunities in open finance. Two associated code repos are \url{this https URL} and \url{this https URL}
GitHub - AI4Finance-Foundation/FinGPT: Data-Centric FinGPT. Open-source for open finance! Revolutionize 🔥 We'll soon release the trained model.
Data-Centric FinGPT. Open-source for open finance! Revolutionize 🔥 We'll soon release the trained model. - GitHub - AI4Finance-Foundation/FinGPT: Data-Centric FinGPT. Open-source for open...
github.com
About
Data-Centric FinGPT. Open-source for open finance! Revolutionize We'll soon release the trained model.
We'll soon release the trained model.Let us DO NOT expect Wall Street to open-source LLMs nor open APIs.
We democratize Internet-scale data for financial large language models (FinLLMs) at FinNLP and FinNLP Website
Blueprint of FinGPT
Why FinGPT?
1). Finance is highly dynamic. BloombergGPT retrains an LLM using a mixed dataset of finance and general data sources, which is too expensive (1.3M GPU hours, a cost of around $5M). It is costly to retrain an LLM model every month or every week, so lightweight adaptation is highly favorable in finance. Instead of undertaking a costly and time-consuming process of retraining a model from scratch with every significant change in the financial landscape, FinGPT can be fine-tuned swiftly to align with new data (the cost of adaptation falls significantly, estimated at less than $300 per training).2). Democratizing Internet-scale financial data is critical, which should allow timely updates (monthly or weekly updates) using an automatic data curation pipeline. But, BloombergGPT has privileged data access and APIs. FinGPT presents a more accessible alternative. It prioritizes lightweight adaptation, leveraging the strengths of some of the best available open-source LLMs, which are then fed with financial data and fine-tuned for financial language modeling.
3). The key technology is "RLHF (Reinforcement learning from human feedback)", which is missing in BloombergGPT. RLHF enables an LLM model to learn individual preferences (risk-aversion level, investing habits, personalized robo-advisor, etc.), which is the ``secret" ingredient of ChatGPT and GPT4.
FinGPT Demos
- FinGPT V1
- Let's train our own FinGPT in Chinese Financial Market with ChatGLM and LoRA (Low-Rank Adaptation)
- FinGPT V2
- Let's train our own FinGPT in American Financial Market with LLaMA and LoRA (Low-Rank Adaptation)
News
- Columbia Perspectives on ChatGPT
- [MIT Technology Review] ChatGPT is about to revolutionize the economy. We need to decide what that looks like
- [BloombergGPT] BloombergGPT: A Large Language Model for Finance
- [Finextra] ChatGPT and Bing AI to sit as panellists at fintech conference
What is FinNLP
- FinNLP provides a playground for all people interested in LLMs and NLP in Finance. Here we provide full pipelines for LLM training and finetuning in the field of finance. The full architecture is shown in the following picture. Detail codes and introductions can be found here. Or you may refer to the wiki

ChatGPT at AI4Finance
- [YouTube video] I Built a Trading Bot with ChatGPT, combining ChatGPT and FinRL.
- Hey, ChatGPT! Explain FinRL code to me!
- ChatGPT Robo Advisor v2
- ChatGPT Robo Advisor v1
- A demo of using ChatGPT to build a Robo-advisor
- ChatGPT Trading Agent V2
- A FinRL agent that trades as smartly as ChatGPT by using the large language model behind ChatGPT
- ChatGPT Trading Agent V1
- Trade with the suggestions given by ChatGPT
- ChatGPT adds technical indicators into FinRL
Introductory
- Sparks of artificial general intelligence: Early experiments with GPT-4
- [GPT-4] GPT-4 Technical Report
- [InstructGPT] Training language models to follow instructions with human feedback NeurIPS 2022.
- [GPT-3] Language models are few-shot learners NeurIPS 2020.
- [GPT-2] Language Models are Unsupervised Multitask Learners
- [GPT-1] Improving Language Understanding by Generative Pre-Training
- [Transformer] Attention is All you Need NeurIPS 2017.
(Financial) Big Data
- [BloombergGPT] BloombergGPT: A Large Language Model for Finance
- WHAT’S IN MY AI? A Comprehensive Analysis of Datasets Used to Train GPT-1, GPT-2, GPT-3, GPT-NeoX-20B, Megatron-11B, MT-NLG, and Gopher
- FinRL-Meta Repo and paper FinRL-Meta: Market Environments and Benchmarks for Data-Driven Financial Reinforcement Learning. Advances in Neural Information Processing Systems, 2022.
- [AI4Finance] FinNLP Democratizing Internet-scale financial data.
High-Fidelity Image Compression with Score-based Generative Models
Emiel Hoogeboom, Eirikur Agustsson, Fabian Mentzer, Luca Versari, George Toderici, Lucas TheisDespite the tremendous success of diffusion generative models in text-to-image generation, replicating this success in the domain of image compression has proven difficult. In this paper, we demonstrate that diffusion can significantly improve perceptual quality at a given bit-rate, outperforming state-of-the-art approaches PO-ELIC and HiFiC as measured by FID score. This is achieved using a simple but theoretically motivated two-stage approach combining an autoencoder targeting MSE followed by a further score-based decoder. However, as we will show, implementation details matter and the optimal design decisions can differ greatly from typical text-to-image models.

How Should We Store AI Images? Google Researchers Propose an Image Compression Method Using Score-based Generative Models
A year ago, generating realistic images with AI was a dream. We were impressed by seeing generated faces that resemble real ones, despite the majority of outputs having three eyes, two noses, etc. However, things changed quite rapidly with the release of diffusion models. Nowadays, it is...
www.marktechpost.com
How Should We Store AI Images? Google Researchers Propose an Image Compression Method Using Score-based Generative Models
By
Ekrem Çetinkaya
June 17, 2023
A year ago, generating realistic images with AI was a dream. We were impressed by seeing generated faces that resemble real ones, despite the majority of outputs having three eyes, two noses, etc. However, things changed quite rapidly with the release of diffusion models. Nowadays, it is difficult to distinguish an AI-generated image from a real one.
The ability to generate high-quality images is one part of the equation. If we were to utilize them properly, efficiently compressing them plays an essential role in tasks such as content generation, data storage, transmission, and bandwidth optimization. However, image compression has predominantly relied on traditional methods like transform coding and quantization techniques, with limited exploration of generative models.
Despite their success in image generation, diffusion models and score-based generative models have not yet emerged as the leading approaches for image compression, lagging behind GAN-based methods. They often perform worse or on par with GAN-based approaches like HiFiC on high-resolution images.
Even attempts to repurpose text-to-image models for image compression have yielded unsatisfactory results, producing reconstructions that deviate from the original input or contain undesirable artifacts.
The gap between the performance of score-based generative models in image generation tasks and their limited success in image compression raises intriguing questions and motivates further investigation. It is surprising that models capable of generating high-quality images have not been able to surpass GANs in the specific task of image compression. This discrepancy suggests that there may be unique challenges and considerations when applying score-based generative models to compression tasks, necessitating specialized approaches to harness their full potential.
So we know there is a potential for using score-based generative models in image compression. The question is, how can it be done? Let us jump into the answer.
Google researchers proposed a method that combines a standard autoencoder, optimized for mean squared error (MSE), with a diffusion process to recover and add fine details discarded by the autoencoder. The bit rate for encoding an image is solely determined by the autoencoder, as the diffusion process does not require additional bits. By fine-tuning diffusion models specifically for image compression, it is shown that they can outperform several recent generative approaches in terms of image quality.

The method explores two closely related approaches: diffusion models, which exhibit impressive performance but require a large number of sampling steps, and rectified flows, which perform better when fewer sampling steps are allowed.
The two-step approach consists of first encoding the input image using the MSE-optimized autoencoder and then applying either the diffusion process or rectified flows to enhance the realism of the reconstruction. The diffusion model employs a noise schedule that is shifted in the opposite direction compared to text-to-image models, prioritizing detail over global structure. On the other hand, the rectified flow model leverages the pairing provided by the autoencoder to directly map autoencoder outputs to uncompressed images.
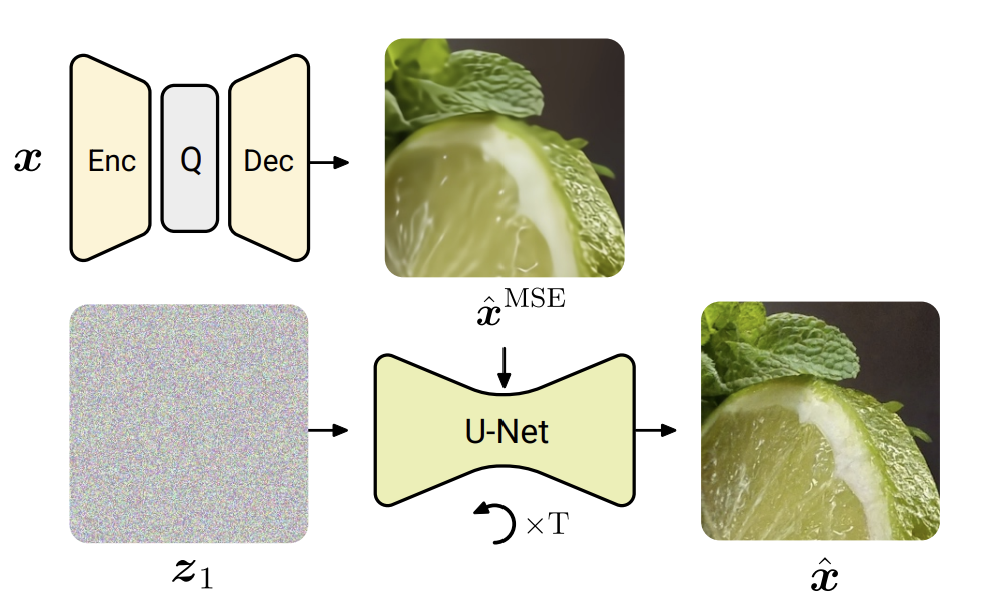
Moreover, the study revealed specific details that can be useful for future research in this domain. For example, it is shown that the noise schedule and the amount of noise injected during image generation significantly impact the results. Interestingly, while text-to-image models benefit from increased noise levels when training on high-resolution images, it is found that reducing the overall noise of the diffusion process is advantageous for compression. This adjustment allows the model to focus more on fine details, as the coarse details are already adequately captured by the autoencoder reconstruction.
PandaGPT: One Model to Instruction-Follow Them All
Yixuan Su*☨ , Tian Lan*, Huayang Li*☨, Jialu Xu, Yan Wang, Deng Cai*▶ University of Cambridge ▶ Nara Institute of Science and Technology ▶ Tencent AI Lab
*Major contributors ☨interns at Tencent AI Lab
Abstract
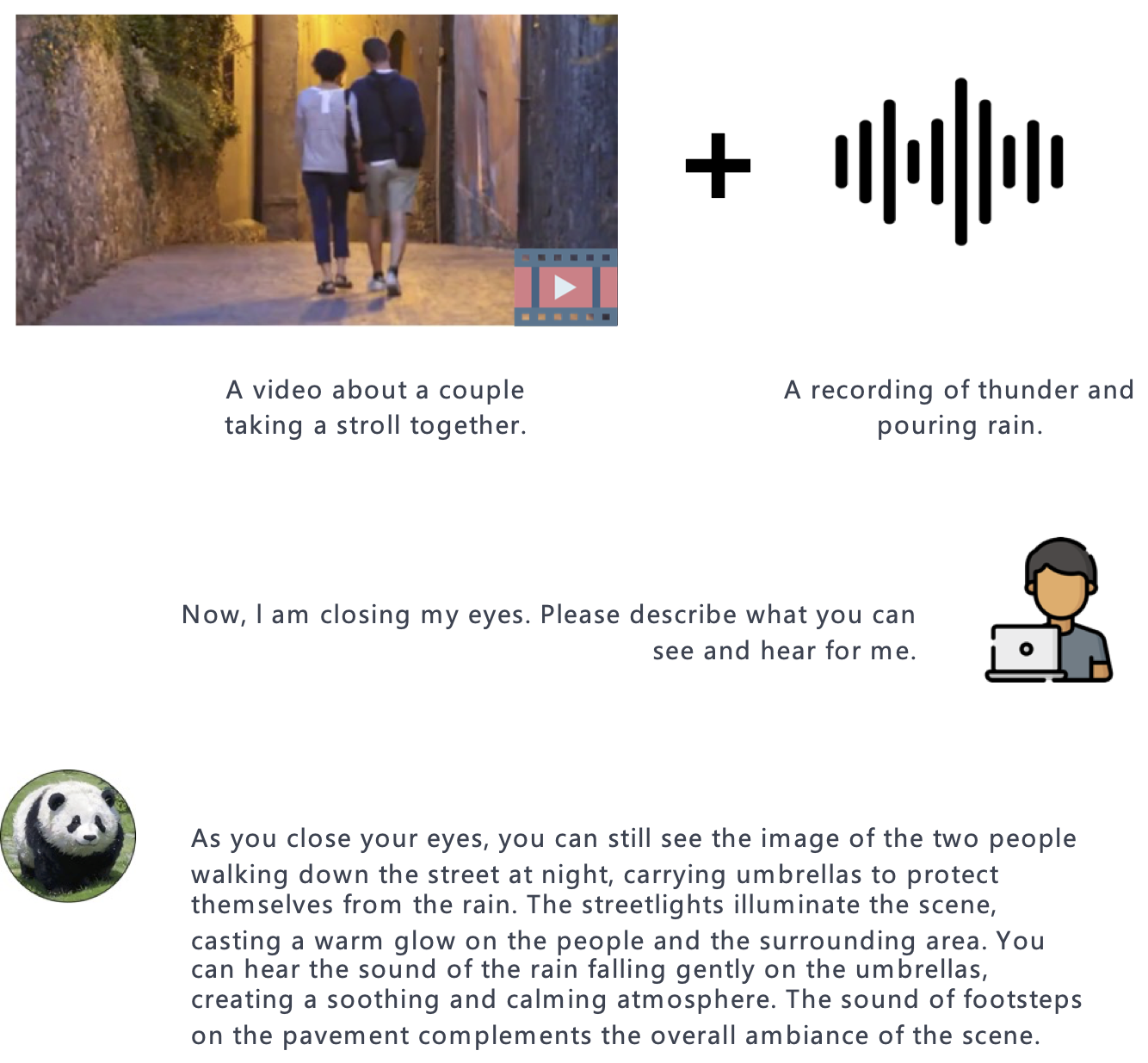
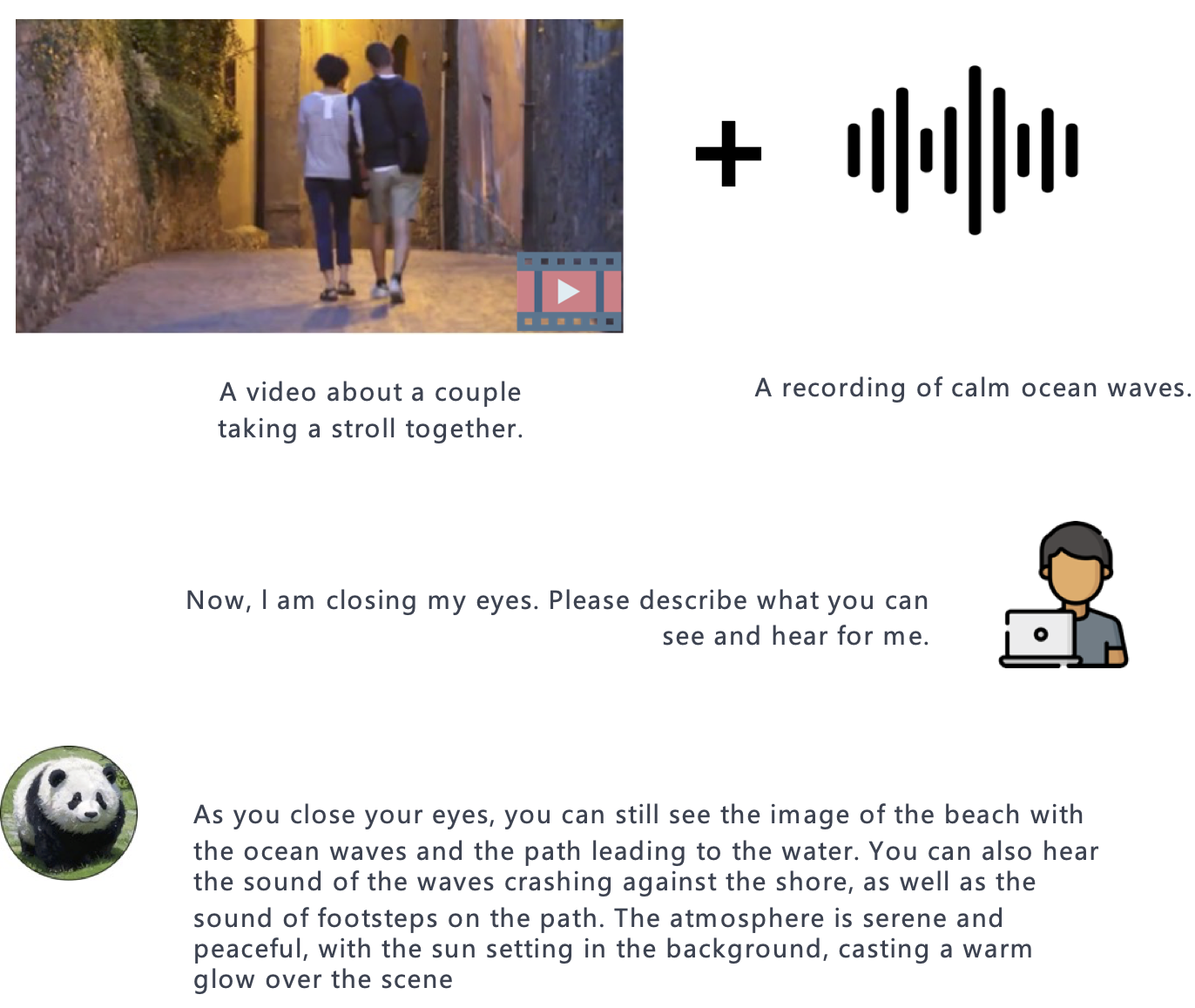
PandaGPT is a general-purpose instruction-following model that can both see and hear. Our pilot experiments show that PandaGPT can perform complex tasks such as detailed image description generation, writing stories inspired by videos, and answering questions about audios. More Interestingly, PandaGPT can take multimodal inputs simultaneously and compose their semantics naturally. For example, PandaGPT can connect how objects look in a photo and how they sound in an audio. To do so, PandaGPT combines the multimodal encoders from ImageBind and the large language models from Vicuna. Notably, though PandaGPT demonstrates impressive cross-modal capabilities across six modalities (text, image/video, audio, depth, thermal, and IMU), it is only trained with aligned image-text pairs, thanks to the the shared embedding space provided by ImageBind. We hope that PandaGPT serves as an initial step toward building AGI that can perceive and understand inputs in different modalities holistically, as we humans do.Video Presentation
Model
PandaGPT combines the multimodal encoders from ImageBind and the large language models from Vicuna, achieving impressive capabilities across six modalities (text, image/video, audio, depth, thermal, and IMU). Notably the current version of PandaGPT is only trained with aligned image-text pairs (160k image-language instruction-following data released by LLaVa and Mini-GPT4), with a small set of new parameters introduced:- A linear projection matrix connects the multimodal features from ImageBind to Vicuna
- Additional LoRA weights on the Vicuna’s attention modules
The architecture of PandaGPT.
Capabilities
Compared to existing multimodal instruction-following models trained individually for one particular modality, PandaGPT can understand and combine information in different forms together, including text, image/video, audio, depth (3D), thermal (infrared radiation), and inertial measurement units (IMU). We find that the capabilities of PandaGPT include but are not limited to (with examples attached in the bottom of this page):- image/video grounded question answering.
- image/video inspired creative writing.
- visual and auditory reasoning.
- multimodal arithmetic.
- .... (explore our demo on your own!)
BibTeX
@article{su2023pandagpt,title={PandaGPT: One Model To Instruction-Follow Them All},
author={Su, Yixuan and Lan, Tian and Li, Huayang and Xu, Jialu and Wang, Yan and Cai, Deng},
journal={arXiv preprint arXiv:2305.16355},
year={2023}
}
Acknowledgement
This website template is borrowed from the MiniGPT-4 project, which is adapted from Nerfies, licensed under a Creative Commons Attribution-ShareAlike 4.0 International License.Examples









GitHub - yxuansu/PandaGPT: [TLLM'23] PandaGPT: One Model To Instruction-Follow Them All
[TLLM'23] PandaGPT: One Model To Instruction-Follow Them All - yxuansu/PandaGPT
github.com
PandaGPT/README.md at main · yxuansu/PandaGPT
PandaGPT: One Model To Instruction-Follow Them All - PandaGPT/README.md at main · yxuansu/PandaGPT
github.com
Online Demo:

PandaGPT - a Hugging Face Space by GMFTBY
Discover amazing ML apps made by the community
huggingface.co
GitHub - DAMO-NLP-SG/Video-LLaMA: Video-LLaMA: An Instruction-tuned Audio-Visual Language Model for Video Understanding
Video-LLaMA: An Instruction-tuned Audio-Visual Language Model for Video Understanding - GitHub - DAMO-NLP-SG/Video-LLaMA: Video-LLaMA: An Instruction-tuned Audio-Visual Language Model for Video Und...
github.com
About
Video-LLaMA: An Instruction-tuned Audio-Visual Language Model for Video UnderstandingVideo-LLaMA: An Instruction-tuned Audio-Visual Language Model for Video Understanding
This is the repo for the Video-LLaMA project, which is working on empowering large language models with video and audio understanding capability.News
- [06.14] NOTE: the current online interactive demo is primarily for English chatting and it may NOT be a good option to ask Chinese questions since Vicuna/LLaMA does not represent Chinese texts very well.
- [06.13] NOTE: the audio support is ONLY for Vicuna-7B by now although we have several VL checkpoints available for other decoders.
- [06.10] NOTE: we have NOT updated the HF demo yet because the whole framework (with audio branch) cannot run normally on A10-24G. The current running demo is still the previous version of Video-LLaMA. We will fix this issue soon.
- [06.08]
 Release the checkpoints of the audio-supported Video-LLaMA. Documentation and example outputs are also updated.
Release the checkpoints of the audio-supported Video-LLaMA. Documentation and example outputs are also updated. - [05.22] Interactive demo online, try our Video-LLaMA (with Vicuna-7B as language decoder) at Hugging Face and ModelScope!!
- [05.22]
 ️ Release Video-LLaMA v2 built with Vicuna-7B
️ Release Video-LLaMA v2 built with Vicuna-7B - [05.18] Support video-grounded chat in Chinese
- Video-LLaMA-BiLLA: we introduce BiLLa-7B as language decoder and fine-tune the video-language aligned model (i.e., stage 1 model) with machine-translated VideoChat instructions.
- Video-LLaMA-Ziya: same with Video-LLaMA-BiLLA but the language decoder is changed to Ziya-13B.
- [05.18] ️ Create a Hugging Face repo to store the model weights of all the variants of our Video-LLaMA.
- [05.15] ️ Release Video-LLaMA v2: we use the training data provided by VideoChat to further enhance the instruction-following capability of Video-LLaMA.
- [05.07] Release the initial version of Video-LLaMA, including its pre-trained and instruction-tuned checkpoints.

Introduction
- Video-LLaMA is built on top of BLIP-2 and MiniGPT-4. It is composed of two core components: (1) Vision-Language (VL) Branch and (2) Audio-Language (AL) Branch.
- VL Branch(Visual encoder: ViT-G/14 + BLIP-2 Q-Former)
- A two-layer video Q-Former and a frame embedding layer (applied to the embeddings of each frame) are introduced to compute video representations.
- We train VL Branch on the Webvid-2M video caption dataset with a video-to-text generation task. We also add image-text pairs (~595K image captions from LLaVA) into the pre-training dataset to enhance the understanding of static visual concepts.
- After pre-training, we further fine-tune our VL Branch using the instruction-tuning data from MiniGPT-4, LLaVA and VideoChat.
- AL Branch(Audio encoder: ImageBind-Huge)
- A two-layer audio Q-Former and a audio segment embedding layer (applied to the embedding of each audio segment) are introduced to compute audio representations.
- As the used audio encoder (i.e., ImageBind) is already aligned across multiple modalities, we train AL Branch on video/image instrucaption data only, just to connect the output of ImageBind to language decoder.
- VL Branch(Visual encoder: ViT-G/14 + BLIP-2 Q-Former)
- Note that only the Video/Audio Q-Former, positional embedding layers and the linear layers are trainable during cross-modal training.
Example Outputs
- Video with background sound


- Video without sound effects


- Static image


If AI is plagiarising art and design, then so is every human artist and designer in the world

If AI is plagiarising art and design, then so is every human artist and designer in the world
It's time to be honest with yourself: nothing you've ever designed, drawn, painted, sculpted or sketched is absolutely original.vulcanpost.com

June 19, 2023
In this article
No headings were found on this page.
Disclaimer: Opinions expressed below belong solely to the author.
Who should own the copyrights to the above rendition of Merlion in front of a somewhat awkward Singapore skyline?
Well, some people believe nobody, while others think they should be paid for it if their photo or illustration was among millions going through AI models, even if it looks nothing like the final work.
The rise of generative AI tools has triggered panic and rage among so many, that I have to say it’s becoming entertaining to witness the modern-day Luddites decrying the sudden rise of superior technology, threatening to displace their inferior manual labour.

The most recent argument — particularly in the field of generative models in graphics and art — is that artificial intelligence is guilty of plagiarising work of people, having learned to create new imagery after being fed millions of artworks, photos, illustrations and paintings.
The demand is that AI companies should at least compensate those original creators for their work (if those generative models are not outright banned from existence).
If that is the case, then I have a question to all of those “creatives” loudly protesting tools like Midjourney or Stable Diffusion: are you going to pay to all the people whose works you have observed and learned from?
I’m a designer myself (among other professions) — and yet I have never been very fond of the “creative” crowd, which typically sees itself as either unfairly unappreciated or outright better than everybody else around (remember the meltdown they had during Covid when they were deemed “non-essential” in a public survey?).
And as a designer, I consume lots of content on the internet, watching what other people do. In fact, isn’t this in part what a tool like Pinterest was created for?
I’d like to know how many designers do not use it to build inspiration boards for their many projects — illustrations, logos, shapes, packaging, among others?
And how many have ever thought about paying a share of their fee to the people they sought inspiration from?
If you’re using Pinterest for design inspiration should pay for every image you’ve seen, that may have helped you do your project?
What about Dribbble? Deviantart? Google Images?
It’s time to be honest with yourself: nothing you’ve ever designed, drawn, painted, sculpted or sketched is absolutely original.
Get off your high horse and just remember the thousands of images you’ve gone through before you finished the job.
In fact, observation and copying is the basis of education in the field, where you acquire competences in using tools that many have used before you, while mastering different techniques of expression — none of which were authored by you.
There are no painters who just wake up one day and pick up brushes and watercolours, and start creating something out of thin air. Everybody learns from someone else.
Bob Ross
And AI models such as Midjourney, Dall-E or Stable Diffusion, learn in just the same way — they are fed images with accompanying descriptions, that help them to identify objects in the picture as well as specific style it was created in (painted, drawn, photographed etc.).
Fundamentally, they behave just like humans do — just that they do it much more quickly and at a much greater scale. But if we want to outlaw or penalise it, then the same rules should apply to every human creator.
Even the argument against utilising images with watermarks — as it has often been the case with AI pulling content from stock image websites — is moot because, again, people do just the same. We browse thousands of images not necessarily paying for them, to seek ideas for our projects.
As long as no element is copied outright, the end result is considered our own creative work that is granted full copyrights. If that’s the case, then why would different rules apply to an automated system that behaves in the same way?
And if your argument is that AI is not human so it doesn’t enjoy the same rights, then I’d have to remind you that these sophisticated programs have their human authors and human users.
When I enter a specific prompt into the model, I’m employing the system to do the job for me — while paying for it. It does what I tell it to do, and what I could have done manually but now I do not have to. My own intent is the driver of the output, so why should I not enjoy the legal rights to whatever it produces?
Why can I create something with Photoshop, but not with Midjourney?
This is bound to be a legal minefield, gradually cleared in the coming few years, with some decisions in the US already ruling against AI (and basic logic, it seems).
But as it has been throughout history, no attempts to stall technological progress have ever succeeded and it’s unlikely to be different this time. Good designers and artists pushing the envelope are going to keep their place in the business.
Everybody else is better off learning how to type in good prompts before it’s too late.



















