
You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
The A.I Megathread (LLM , GPT , Development)
More options
Who Replied?Landmark Attention: Random-Access Infinite Context Length for Transformers
While Transformers have shown remarkable success in natural language processing, their attention mechanism's large memory requirements have limited their ability to handle longer contexts. Prior approaches, such as recurrent memory or retrieval-based augmentation, have either compromised the...
Landmark Attention: Random-Access Infinite Context Length for Transformers
Amirkeivan Mohtashami, Martin JaggiWhile transformers have shown remarkable success in natural language processing, their attention mechanism's large memory requirements have limited their ability to handle longer contexts. Prior approaches, such as recurrent memory or retrieval-based augmentation, have either compromised the random-access flexibility of attention (i.e., the capability to select any token in the entire context) or relied on separate mechanisms for relevant context retrieval, which may not be compatible with the model's attention. In this paper, we present a novel approach that allows access to the complete context while retaining random-access flexibility, closely resembling running attention on the entire context. Our method uses a landmark token to represent each block of the input and trains the attention to use it for selecting relevant blocks, enabling retrieval of blocks directly through the attention mechanism instead of by relying on a separate mechanism. Our approach seamlessly integrates with specialized data structures and the system's memory hierarchy, enabling processing of arbitrarily long context lengths. We demonstrate that our method can obtain comparable performance with Transformer-XL while significantly reducing the number of retrieved tokens in each step. Finally, we show that fine-tuning LLaMA 7B with our method successfully extends its context length capacity up to 32k tokens, allowing for inference at the context lengths of GPT-4.
snippet:
1 Introduction Large transformers have revolutionized language modeling and demonstrated remarkable abilities to perform various tasks with zero or few examples [4]. This success can be largely attributed to the attention mechanism, which allows each token to access the representation of any other token in each layer. However, this flexibility comes with quadratic computational cost and highly problematic memory footprint, limiting the number of tokens that can be attended to, and thus the context length.
To overcome this limitation, researchers have proposed various solutions, including incorporating a form of recurrent memory inside the Transformer architecture, such as Transformer-XL [8]. However, these approaches often sacrifice the random-access flexibility of attention.
An alternative approach to overcome the context length limit is to use retrieval-based methods that incorporate additional static knowledge by searching for relevant documents in a knowledge base and adding them to the context. However, this approach requires a separate mechanism to identify relevant documents, called a retriever. Such retrieval models can not easily be updated to work on fresh long input data, and furthermore are also not fully compatible with the standard attention mechanism itself, and thus may fail to mimic attention over long documents.
In this work, we propose a novel approach for overcoming the context length limit by allowing earlier blocks of the input to be directly incorporated into the attention itself. We break the input into blocks of fixed length and introduce a special token for each block, called a landmark, which acts as a gate for attending to its corresponding block. The gating mechanism is controlled by the attention score to the landmark token. At inference time, the attention scores on the landmarks allow us to retrieve any previous block and integrate it with standard attention. The idea is illustrated in Figure 1
Our proposed approach maintains the random-access flexibility of attention and offers an alternative solution to the recurrent memory approaches.
Our model can process any context length at inference time regardless of the context length used at training time. To achieve this, we split the input into chunks and feed the chunks sequentially to the model, while maintaining a cache of previous tokens, usually referred to as KV cache. When processing each chunk, we first use the landmark tokens to select the most relevant blocks and only use these blocks for computing the attention. This immediately reduces the computation cost by a factor of block length. For example, in our experiments where we use blocks of 50 tokens, this translates to almost 50x reduction of computation. We note that to the overhead of computing the attention for the retrieved blocks does not depend on the input length and becomes negligible for very large inputs. Furthermore, it is possible to obtain the same reduction in memory usage since all tokens in a block (except the landmark itself) can be swapped out and only loaded when the corresponding landmark token is activated. We also point out that this reduction can be further improved by using special data structures designed for retrieving closest neighbors, such as FAISS [14].
We demonstrate the efficacy of our method in practice by applying our training method both for training models from scratch and for fine-tuning pre-trained models. In both cases, our model effectively utilizes landmark tokens to retrieve relevant blocks from memory, enabling inference at arbitrary context lengths much longer than those encountered during training. As a result, our model obtains comparable performance with Transformer XL trained to use recurrence on a much larger window. More importantly, we demonstrate that using our method to fine-tune LLaMA 7B [36], a large language model, allows it to retrieve relevant information from contexts with over 32k tokens, which is the context length of GPT-4 [24].
In comparison with prior approaches, using landmark tokens, it is theoretically possible for the model to access any token in the entire past. Although the memory footprint grows linearly with the number of stored blocks, Therefore, the limit on cache size is significantly reduced as the GPU memory only needs to store the landmark tokens (a saving multiplicative in the block size, which is significant). This limit can be further improved . For simplicity, we focus our experiments on storing everything in GPU memory, but we note that the above techniques can be directly applied in large-scale settings.
Finally, we note that a model trained with landmark tokens could also be directly used to build a document retriever, at inference time. For example a retriever can use the highest landmark attention score inside the document as a measure of the relevance of the document, without any training needed on the specific new document corpus.
The primary advantages of our method can be summarized as follows:
- • Enabling inference at any context length, irrespective of the context length utilized during training, without incurring additional training costs.
- • Instantly reducing inference time and memory usage (compared to a model trained to operate at the given context length) by a substantial factor equal to the block size (e.g., 50 in our experiments).
- • Compatibility with advanced data structures that can further decrease the resource requirements for operating the model with very large context lengths.
Our implementation of landmark attention is accessible at EPFL Machine Learning and Optimization Laboratory landmark-attention.
Futurepedia - Find The Best AI Tools & Software
Futurepedia is a free site to help you find the best AI tools and software to make your work and life more efficient and productive. Updated daily, join millions of followers of our website, newsletter and YouTube.
FUTUREPEDIA
THE LARGEST AI TOOLS DIRECTORY, UPDATED DAILY

Future Tools - Find The Exact AI Tool For Your Needs
FutureTools Collects & Organizes All The Best AI Tools So YOU Too Can Become Superhuman!
 www.futuretools.io
www.futuretools.io
"FutureTools Collects & Organizes All The Best AI Tools So YOU Too Can Become Superhuman!"

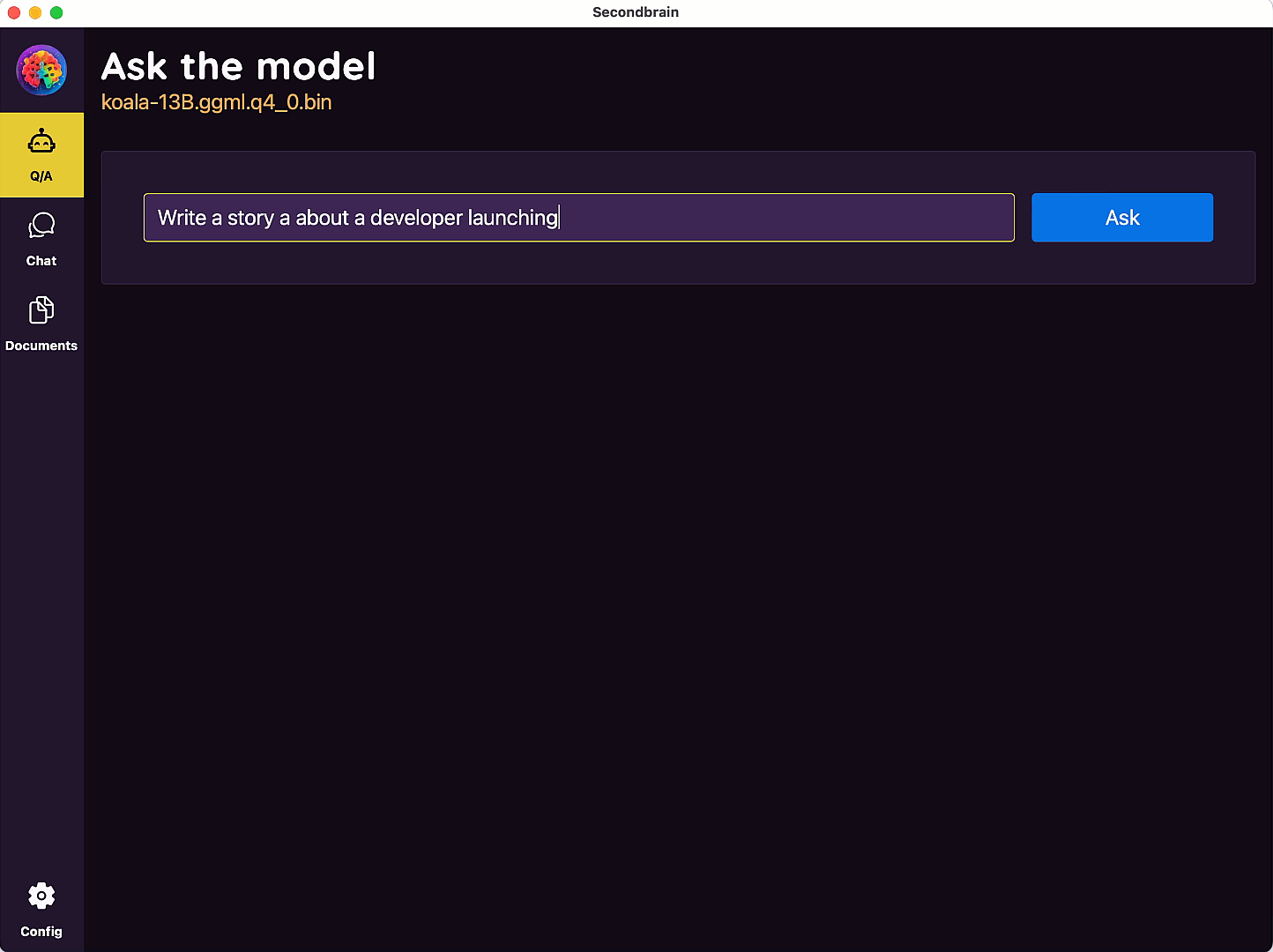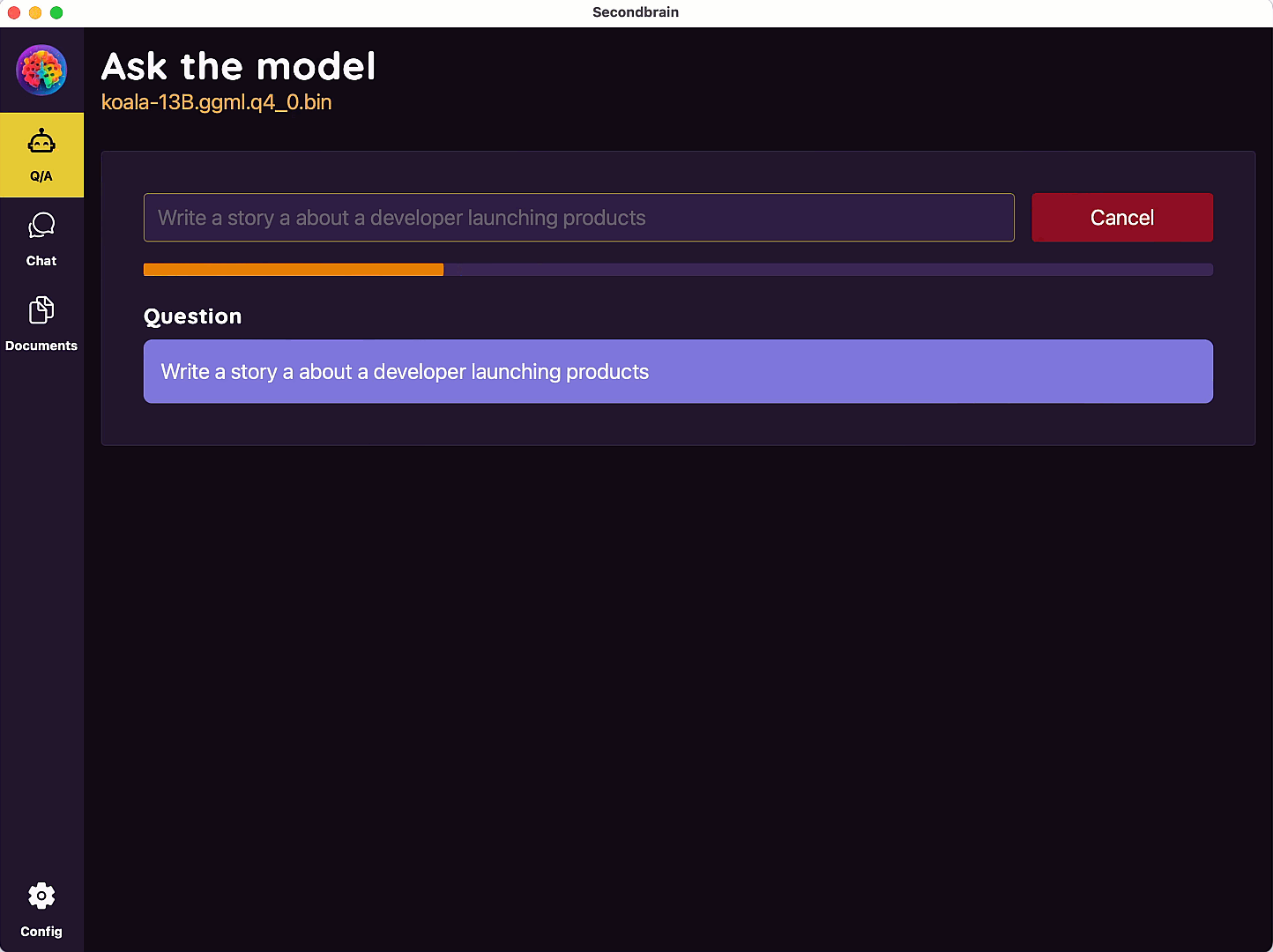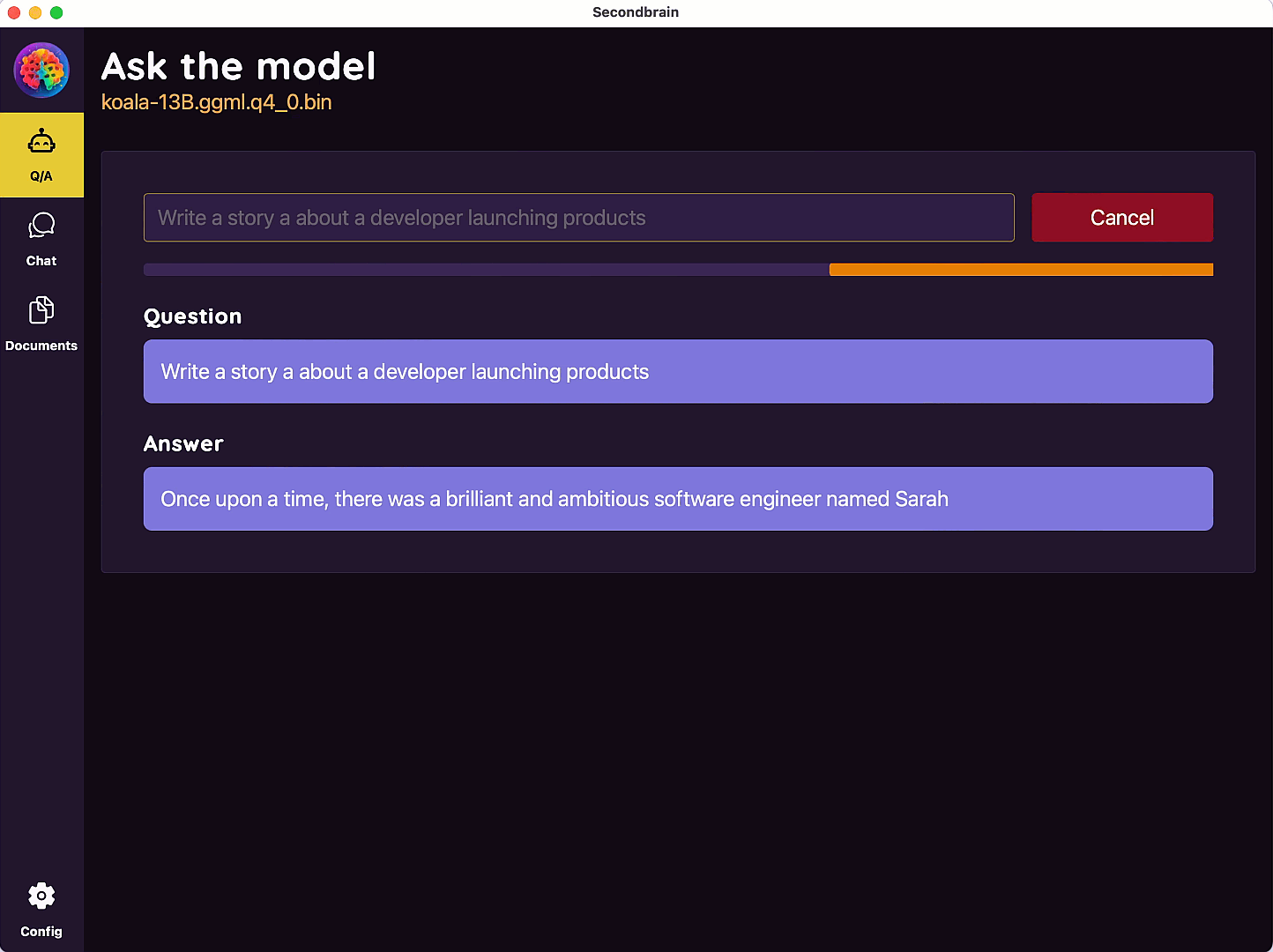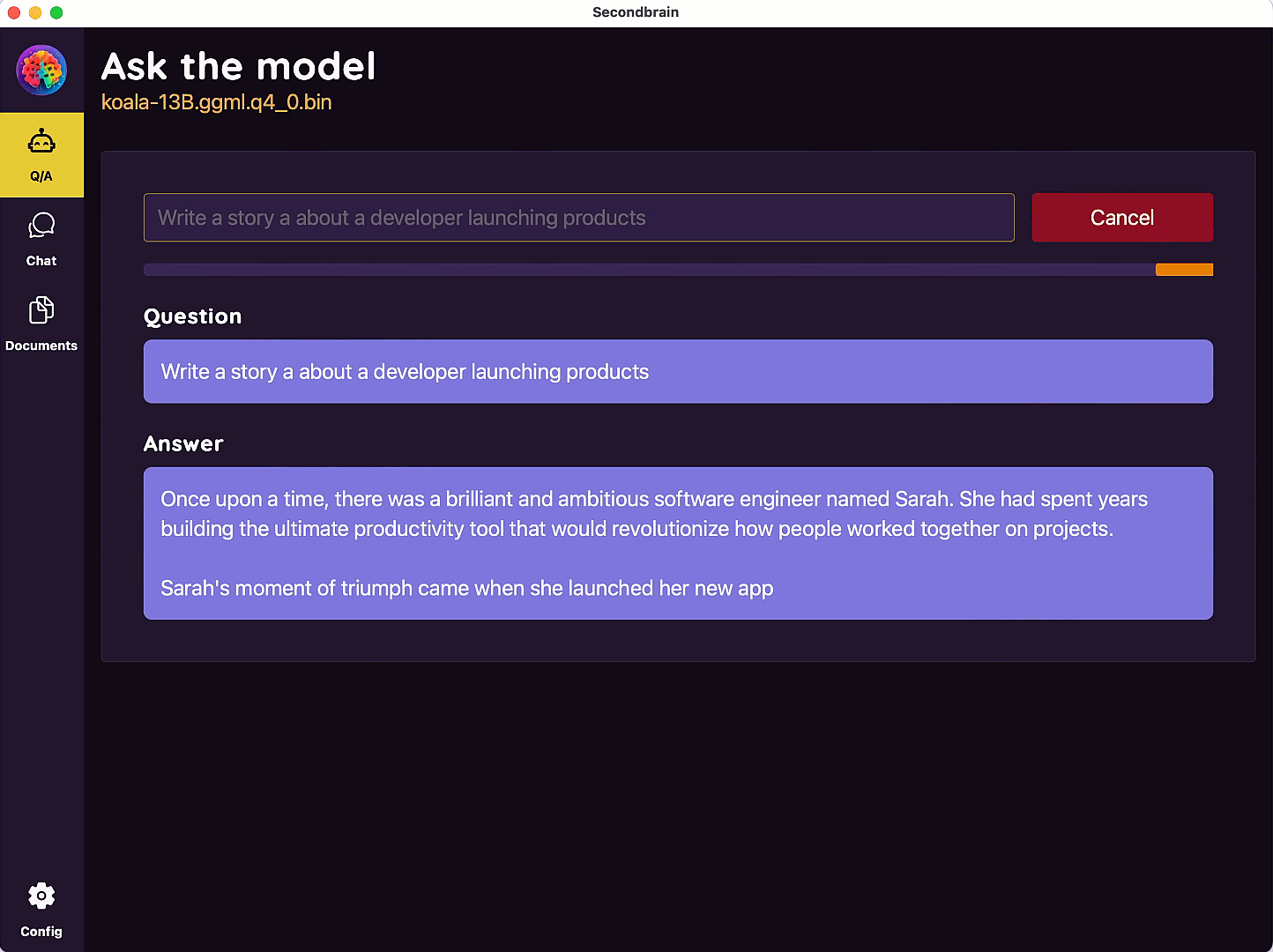
SecondBrain
Multi-platform desktop app to download and run Large Language Models(LLM) locally in your computer
Multi-platform desktop app to download and run Large Language Models(LLM) locally in your computer
Welcome to your
Second Brain
 The power of AI in your computer
The power of AI in your computer Local - it can work without internet
Local - it can work without internet Privacy first - your messages don't leave your computer
Privacy first - your messages don't leave your computer Uncensored - you can talk whatever you want
Uncensored - you can talk whatever you want

OlaGPT: Empowering LLMs With Human-like Problem-Solving Abilities
Yuanzhen Xie, Tao Xie, Mingxiong Lin, WenTao Wei, Chenglin Li, Beibei Kong, Lei Chen, Chengxiang Zhuo, Bo Hu, Zang LiIn most current research, large language models (LLMs) are able to perform reasoning tasks by generating chains of thought through the guidance of specific prompts. However, there still exists a significant discrepancy between their capability in solving complex reasoning problems and that of humans. At present, most approaches focus on chains of thought (COT) and tool use, without considering the adoption and application of human cognitive frameworks. It is well-known that when confronting complex reasoning challenges, humans typically employ various cognitive abilities, and necessitate interaction with all aspects of tools, knowledge, and the external environment information to accomplish intricate tasks. This paper introduces a novel intelligent framework, referred to as OlaGPT. OlaGPT carefully studied a cognitive architecture framework, and propose to simulate certain aspects of human cognition. The framework involves approximating different cognitive modules, including attention, memory, reasoning, learning, and corresponding scheduling and decision-making mechanisms. Inspired by the active learning mechanism of human beings, it proposes a learning unit to record previous mistakes and expert opinions, and dynamically refer to them to strengthen their ability to solve similar problems. The paper also outlines common effective reasoning frameworks for human problem-solving and designs Chain-of-Thought (COT) templates accordingly. A comprehensive decision-making mechanism is also proposed to maximize model accuracy. The efficacy of OlaGPT has been stringently evaluated on multiple reasoning datasets, and the experimental outcomes reveal that OlaGPT surpasses state-of-the-art benchmarks, demonstrating its superior performance. Our implementation of OlaGPT is available on GitHub: \url{this https URL}.
GitHub - s0md3v/roop: one-click face swap
one-click face swap. Contribute to s0md3v/roop development by creating an account on GitHub.
 github.com
github.com
About
one-click deepfake (face swap)Take a video and replace the face in it with a face of your choice. You only need one image of the desired face. No dataset, no training.
That's it, that's the software. You can watch some demos here.

Installation
There are two types of installations: basic and gpu-powered.Note: The instructions may or may not work for you. Use google or look through issues people have created here to solve your problems.
- Basic: It is more likely to work on your computer but it will also be very slow. You can follow instructions for the basic install here.
- GPU: If you have a good GPU and are ready for solving any software issues you may face, you can enable GPU which is wayyy faster. To do this, first follow the basic install instructions given above and then follow GPU-specific instructions here.
Usage
Executing python run.py command will launch this window:Note: When you run this program for the first time, it will download some models ~300MB in size.

Choose a face (image with desired face) and the target image/video (image/video in which you want to replace the face) and click on Start. Open file explorer and navigate to the directory you select your output to be in. You will find a directory named <video_title> where you can see the frames being swapped in realtime. Once the processing is done, it will create the output file. That's it.
Don't touch the FPS checkbox unless you know what you are doing.
@bnew Which is the most impressive to you so far?
chatgpt
IBM Plans To Replace Nearly 8,000 Jobs With AI — These Jobs Are First to Go
IBM CEO Arvind Krishna announced a hiring pause in May, but that’s not all. Later that month, the CEO also stated the company plans to replace nearly 8,000 jobs with AI.
 www.benzinga.com
www.benzinga.com
GitHub - PromtEngineer/localGPT: Chat with your documents on your local device using GPT models. No data leaves your device and 100% private.
Chat with your documents on your local device using GPT models. No data leaves your device and 100% private. - GitHub - PromtEngineer/localGPT: Chat with your documents on your local device using ...
github.com
About
Chat with your documents on your local device using GPT models. No data leaves your device and 100% private.localGPT
This project was inspired by the original privateGPT (GitHub - imartinez/privateGPT: Interact privately with your documents using the power of GPT, 100% privately, no data leaks). Most of the description here is inspired by the original privateGPT.In this model, I have replaced the GPT4ALL model with Vicuna-7B model and we are using the InstructorEmbeddings instead of LlamaEmbeddings as used in the original privateGPT. Both Embeddings as well as LLM will run on GPU instead of CPU. It also has CPU support if you do not have a GPU (see below for instruction).
Ask questions to your documents without an internet connection, using the power of LLMs. 100% private, no data leaves your execution environment at any point. You can ingest documents and ask questions without an internet connection!
Built with LangChain and Vicuna-7B and InstructorEmbeddings

Japan Goes All In: Copyright Doesn't Apply To AI Training
Training data can be used "regardless of whether it is for non-profit or commercial purposes, whether it is an act other than reproduction, or whether it is content obtained from illegal sites or otherwise."
 technomancers.ai
technomancers.ai
Delos Prime
May 30, 2023
Japan Goes All In: Copyright Doesn’t Apply To AI Training
In a surprising move, Japan’s government recently reaffirmed that it will not enforce copyrights on data used in AI training. The policy allows AI to use any data “regardless of whether it is for non-profit or commercial purposes, whether it is an act other than reproduction, or whether it is content obtained from illegal sites or otherwise.” Keiko Nagaoka, Japanese Minister of Education, Culture, Sports, Science, and Technology, confirmed the bold stance to local meeting, saying that Japan’s laws won’t protect copyrighted materials used in AI datasets.
Japan, AI, and Copyright
English language coverage of the situation is sparse. It seems the Japanese government believes copyright worries, particularly those linked to anime and other visual media, have held back the nation’s progress in AI technology. In response, Japan is going all-in, opting for a no-copyright approach to remain competitive.This news is part of Japan’s ambitious plan to become a leader in AI technology. Rapidus, a local tech firm known for its advanced 2nm chip technology, is stepping into the spotlight as a serious contender in the world of AI chips. With Taiwan’s political situation looking unstable, Japanese chip manufacturing could be a safer bet. Japan is also stepping up to help shape the global rules for AI systems within the G-7.

Artists vs. Business (Artists Lost)
Not everyone in Japan is on board with this decision. Many anime and graphic art creators are concerned that AI could lower the value of their work. But in contrast, the academic and business sectors are pressing the government to use the nation’s relaxed data laws to propel Japan to global AI dominance.Despite having the world’s third-largest economy, Japan’s economic growth has been sluggish since the 1990s. Japan has the lowest per-capita income in the G-7. With the effective implementation of AI, it could potentially boost the nation’s GDP by 50% or more in a short time. For Japan, which has been experiencing years of low growth, this is an exciting prospect.
It’s All About The Data
Western data access is also key to Japan’s AI ambitions. The more high-quality training data available, the better the AI model. While Japan boasts a long-standing literary tradition, the amount of Japanese language training data is significantly less than the English language resources available in the West. However, Japan is home to a wealth of anime content, which is popular globally. It seems Japan’s stance is clear – if the West uses Japanese culture for AI training, Western literary resources should also be available for Japanese AI.What This Means For The World
On a global scale, Japan’s move adds a twist to the regulation debate. Current discussions have focused on a “rogue nation” scenario where a less developed country might disregard a global framework to gain an advantage. But with Japan, we see a different dynamic. The world’s third-largest economy is saying it won’t hinder AI research and development. Plus, it’s prepared to leverage this new technology to compete directly with the West.Just a friendly reminder, countries are going to do what's best for their citizens. US Law, theoretically, is the same on AI training data. If the West is going to appropriate Japanese culture for training data, we really shouldn't be surprised if Japan decides to return the favor.

AI Regulation Is Dead, Nvidia Killed it - Technomancers.ai
AI Regulation is dead in the United States. Any chance of near-term regulation ended when Nvidia announced earnings. For those that missed it: Nvidia posted surprisingly high first-quarter earnings on sales of datacenter GPUs. These GPUs are essential for training and running large AI systems...
technomancers.ai
Delos Prime
May 29, 2023
AI Regulation Is Dead, Nvidia Killed it
AI Regulation is dead in the United States. Any chance of near-term regulation ended when Nvidia announced earnings. For those that missed it: Nvidia posted surprisingly high first-quarter earnings on sales of datacenter GPUs. These GPUs are essential for training and running large AI systems. The same investor call stated that earnings were accelerating in Q2. Since the start of the year, NVIDIA’s stock is up 160+%. That’s been enough to make it America’s newest trillion-dollar market cap company. All of this is likely to stall any regulation.
Right now, AI stocks are the only thing keeping the market from tanking. Interest rates are more than a point inverted. The United States is in a debt limit crisis. Job openings, though still elevated, have fallen by a quarter. Investors are buying gold to hedge against collapse, and AI stocks because you can’t afford to risk being left behind. To quote a headline from Bloomberg, “AI Is Becoming the Stock Market’s Answer to Everything.”
The Market Is Going Nuts for AI Stocks
AI is a pot of gold surrounded by a huge wall of research and development costs. The US financial market’s response to problems is to throw money at it. This tends to work best on problems that can be solved by large amounts of money, such as AI development.

The US financial markets are the largest in the world. They are designed to unlock profits by aggregating large sums of money. Show the market a problem where the only thing standing between investor and profit is a large investment, and the market will go all in. Which is what’s happening now. Given the half-a-trillion dollar runup in AI-related stocks in the first half of 2023, it seems clear that the markets can drop one to two trillion into this section – essentially indefinitely.
No politician in their right mind is getting in front of two trillion dollars of annual market investment. They’d end up a splat on the pavement. One VC described reviewing a stack of AI investment proposals as like “being desensitized to literal magic.” Until this plays out, the markets are all in. If any member of the S&P 500 didn’t have a generative AI strategy by the end of 2023, I would be amazed and might consider shorting the company.
AI Regulation Is Dead For Now
To date, the AI regulation debate has been a small affair. Regulation has been a weird thing, sometimes covered by the press. That period is over. If you try to regulate the engine moving the market, every twist and turn is going to show up on SeekingAlpha and ZeroHedge. This is not the world it was in January, or honestly even before the Nbidia earnings were announced.

This may all be a bubble. At an average P/E ratio of 35, the leading NASDAQ AI stocks are pricey. Those are high valuations, though AI has shown an ability to generate surprisingly high revenue. Recent experience has shown that regulation of socially undesirable industries often happens when they are already experiencing difficulties. Think of it as the kick them while they’re down political strategy. Both coal and tobacco faced significant market or legal pressures before the government acted. Until the bubble bursts, regulation of AI will be difficult.
When And Why Regulation Might Happen
That’s not to say that regulation is completely dead. There are a couple situations where it might succeed:
It’s possible, but unlikely, that some form of social media regulation might take place. Social media has proved psychologically harmful to children. Narrow regulation of social media algorithms might be possible. It’s not going to happen.
I bring up social media regulation because I object to children being collateral damage at the dawn of the AI Age. Truthfully, the EU’s AI Act likely has made any such regulation impossible. Drafted before the popularization of Large Language Models, the act represented a well-thought-out compromise. After LLMs became a thing, extremely hostile provisions were added to the act. In the American context, this means that hedge funds and other major financial players may see any attempt at regulation as a potential Trojan horse threatening their interests.
The second scenario where regulation would be possible would be an AI Chernobyl. Some form of AI situation causes a massive loss of either life or property. It’s unclear, in a realistic non-science fiction context, what such a situation might be. If something occurred it might change the trajectory of regulation. Just don’t expect instant movement – air and water pollution cause a large number of deaths each year, yet continues. Ironically, it’s the AI revolution and associated technologies that are pushing the move for zero tolerance of pollutants. Who needs herbicides when you can have a robot zap a weed with a laser?
Finally, there could be a massive public outcry. The most likely scenario is that the Republican Party takes a major dislike to AI. It’s not clear that this would happen. Republican politics has been moving hard towards the populist right in recent years. It’s possible that the Republican Party could go all in on AI regulation. The problem is that the Republican Party is “White and to the Right.” Who has the most money in the market: White people. Would the Republican Party really impose regulations on the hottest sector in the stock market? Probably not.
Democrats might decide to pick a regulatory fight. Democrats might, very well, push a bill targeting the harms identified in the Stochastic Parrots paper. If Democrats hold the Congress and White House after 2024, a clean power mandate for AI data centers is likely. Don’t expect licensing or any other schemes that would massively disrupt the market. Democrats will fix things after they break, but they are not going to take the blame for tanking the hottest sector on the NASDAQ.
When The Hype Dies Down
Eventually, the current market hype will cease or normalize. At that point, some form of regulation of AI is possible and perhaps likely. On the upside, this will add several years of experience to help identify the harms of AI and deal with them. On the downside, if you believe p(doom) is imminent, waiting a couple of years – or a decade – might be too long for you.
The bottom line is that regulation is unlikely in current market conditions. If some form of regulation did pass in the US, which is unlikely before 2025, it would stick to quantifiable harms. The ability to pass large ranging existential risk legislation – without clear existential risk – is dead.

Making OpenAI Whisper faster - Nikolas' Blog
Explore faster models of Whisper with reduced transcription times, lower memory consumption, and use of TPUs.
nikolas.blog
Making OpenAI Whisper faster
Pushing the performance of Whisper to the limits

The Whisper models from OpenAI are best-in-class in the field of automatic speech recognition in terms of quality. However, transcribing audio with these models still takes time. Is there a way to reduce the required transcription time?
Faster Whisper
Of course, it is always possible to upgrade hardware. However, it is wise to start with the software. This brings us to the project faster-whisper. This project implemented the OpenAI Whisper model in CTranslate2. CTranslate2 is a library for efficient inference with transformer models. This is made possible by applying various methods to increase efficiency, such as weight quantization, layer fusion, batch reordering, etc.
In the case of the project faster-whisper, a noticeable performance boost was achieved. Let’s start with the GPU:
Benchmarks
The original large-v2 Whisper model takes 4 minutes and 30 seconds to transcribe 13 minutes of audio on an NVIDIA Tesla V100S, while the faster-whisper model only takes 54 seconds. Also, the required VRAM drops dramatically. The original model has a VRAM consumption of around 11.3 GB. Faster-whisper reduces this to 4.7 GB. But we can do even better. If we use an integer-8 precision instead of floating-point 16 precision, the VRAM usage is reduced to 3.1 GB. That’s almost 4x smaller than the original model.
Even on the CPU, a noticeable boost can be observed. In the previous article, I neglected the CPU version a bit, as it had a drastic difference from the GPU. In most cases, a CPU is not recommended for inference. But here, we can also look at the results on the CPU. The classic OpenAI Whisper small model can do 13 minutes of audio in 10 minutes and 31 seconds on an Intel(R) Xeon(R) Gold 6226R. Faster-whisper can transcribe the same audio file in 2 minutes and 44 seconds.
The numbers from above were provided by the author of the package. Let’s check them with the same audio file from my the previous article and compare the results. Please note, that I used the NVIDIA T4 GPU.
| Model | Time in seconds |
| OpenAI Whisper (T4) | 763 |
| faster-whisper (T4) | 172 |
We got a 4.4x decrease in inference time on the same GPU. As a result, the differences are somewhere similar to what the description of the author stated.
Code
The best thing about faster-whisper is the easy installation process. It can be installed using pip and can be easily run.
from faster_whisper import WhisperModel
model_size = "large-v2"
# Run on GPU with FP16
model = WhisperModel(model_size, device="cuda", compute_type="float16")
segments, info = model.transcribe("audio.mp3", beam_size=5)
print("Detected language '%s' with probability %f" % (info.language, info.language_probability))
for segment in segments:
print("[%.2fs -> %.2fs] %s" % (segment.start, segment.end, segment.text))
It is important that the final text is transcribed in the loop and is not returned immediately after .transcribe(). segments is only a generator instead of a string.
This relatively simple performance boost is already very helpful. But can it be even faster?
Whisper JAX
Yes, it can: Introducing Whisper JAX. A new reimplementation of Whisper with the goal of making the model run as fast as possible on a TPU. To reach the goal, the model has been implemented in JAX. But what is JAX and what is a TPU?
JAX and TPU?
The open source library JAX provides NumPy-like APIs and functions while enabling them to leverage Just-In-Time (JIT) compilation provided by XLA (Accelerated Linear Algebra), a domain-specific compiler. This allows for better performance and scalability, especially when working with large-scale data and models.
A TPU is a Tensor Processing Unit, a special type of microchip developed by Google and optimized for machine learning. While GPUs offer huge performance gains in the area of mathematical computations, special hardware can expend this by focusing solely on the mathematical operations common in machine learning. TPUs can perform large amounts of tensor operations quickly and efficiently, improving the performance and accuracy of neural networks. The downside of a TPU is that they are only available at Google through their own Cloud offerings.
Performance
As a result, we get another significant performance boost. A 1-hour-long audio file can be transcribed in 13.8 seconds on a TPUv4-8, instead of 1001.0 seconds on an Nvidia A100 40 GB server GPU.
The numbers from above are also provided by the author of the package. Let’s check them with the same audio file from my the previous article and compare the results. I also added the data for the official OpenAI Whisper API.
| Model | Time in seconds |
| OpenAI Whisper (T4) | 763 |
| faster-whisper (T4) | 172 |
| OpenAI Whisper (API) | 80 |
| Whisper JAX (TPU v4-8) | 4.5 |
Data for Whisper JAX from the Huggingface Space
I guess, the result speaks for themselves. Whisper JAX is 17x faster than the official API. We also see a more drastic difference to faster-whisper. However, a quality comparison between faster-whisper and Whisper JAX cannot be made because different hardware was used in the tests.
Conclusion
In summary, Faster Whisper has significantly improved the performance of the OpenAI Whisper model by implementing it in CTranslate2, resulting in reduced transcription time and VRAM consumption. In addition, Whisper JAX further enhances performance by leveraging TPUs and the JAX library to significantly increase transcription speed for large-scale audio processing tasks.
IBM Plans To Replace Nearly 8,000 Jobs With AI — These Jobs Are First to Go
IBM CEO Arvind Krishna announced a hiring pause in May, but that’s not all. Later that month, the CEO also stated the company plans to replace nearly 8,000 jobs with AI.
You cannot love technology more than yout own existence.
People all impressed and excited about their own demise.