You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
The A.I Megathread (LLM , GPT , Development)
More options
Who Replied?https://web.archive.org/web/20230430024108/https://twitter.com/madiator/status/1652326887589556224A Cookbook of Self-Supervised Learning
Randall Balestriero, Mark Ibrahim, Vlad Sobal, Ari Morcos, Shashank Shekhar, Tom Goldstein, Florian Bordes, Adrien Bardes, Gregoire Mialon, Yuandong Tian, Avi Schwarzschild, Andrew Gordon Wilson, Jonas Geiping, Quentin Garrido, Pierre Fernandez, Amir Bar, Hamed Pirsiavash, Yann LeCun, Micah GoldblumSelf-supervised learning, dubbed the dark matter of intelligence, is a promising path to advance machine learning. Yet, much like cooking, training SSL methods is a delicate art with a high barrier to entry. While many components are familiar, successfully training a SSL method involves a dizzying set of choices from the pretext tasks to training hyper-parameters. Our goal is to lower the barrier to entry into SSL research by laying the foundations and latest SSL recipes in the style of a cookbook. We hope to empower the curious researcher to navigate the terrain of methods, understand the role of the various knobs, and gain the know-how required to explore how delicious SSL can be.
https://web.archive.org/web/20230430024557/https://twitter.com/hardmaru/status/1651822596844048385GitHub - deep-floyd/IF
Contribute to deep-floyd/IF development by creating an account on GitHub.
 github.com
github.com

IF - a Hugging Face Space by DeepFloyd
Discover amazing ML apps made by the community
huggingface.co
Last edited:





https://web.archive.org/web/20230430105553/https://twitter.com/carperai/status/1652025709953716224
CarperAI/stable-vicuna-13b-delta · Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co

A brief history of LLaMA models - AGI Sphere
The LLaMA base model was released in February 2023. Now we have seen a handful of new fine-tuned LLaMA models released.
A brief history of LLaMA models
The LLaMA base model was released in February 2023. Now we have seen a handful of new fine-tuned LLaMA models released.
It is literally a brief history, but a lot has happened for sure. So let’s do a brief review.
I will cover some developments in models and briefly touch on tools.
- LLaMA base model
- Alpaca model
- Vicuna model
- Koala model
- GPT4-x-Alpaca model
- WizardLM model
- Software to run LLaMA models locally
| Model | Size | Training data |
|---|---|---|
| LLaMA (base model) | 7B, 13B, 33B, 65B | Various |
| Alpaca | 7B, 13B | 52k GPT-3 instructions |
| Vicuna | 7B, 13B | 70k ChatGPT conversations |
| Koala-distill | 7B, 13B | 117k cleaned ChatGPT conversations |
| GPT4-x-Alpaca | 13B | 20k GPT4 instructions |
| WizardML | 7B | 70k instructions synthesized with ChatGPT/GPT-3 |
Contents [hide]
LLaMA base model
- Paper: LLaMA: Open and Efficient Foundation Language Models
- Release blog post
- Release date: February 2023
Like GPT, LLaMA is intended to be a general-purpose foundational model suitable for further fine-tuning.
LLaMA models have the following variants
- 7B parameters
- 13B parameters
- 33B parameters
- 65B parameters
Accessibility
Unlike GPT, LLaMA is an open-source model. You can download, study and run them locally. Officially, you will need to use a Google form to request the model weights.However, the models were leaked on Torrent in March 2023, less than a month after its release.
Objective
The objective of LLaMA is to build the best-performing model for a given inference budget, for example, running on an NVIDIA 3090 using less than 10GB VRAM.Model architecture
LLaMA is a transformer model similar to GPT with the following modifications.- Normalize the input of each transformer sub-layer to improve training stability.
- Use SwiGLU instead of ReLU to improve performance.
- Use rotary embedding instead of absolute positioning to improve performance.
| Parameters | Layers | Attention heads | Embedding dimension | |
| 7B | 6.7B | 32 | 32 | 4,096 |
| 13B | 13B | 40 | 40 | 5,120 |
| 33B | 33B | 60 | 52 | 6,656 |
| 65B | 65B | 80 | 64 | 8,192 |
For reference, GPT-3 has 175B parameters. LLaMA models are small.
Training
The pre-training data used in LLaMA are- English CommonCrawl (67%): Removed non-English text and duplicated content. Only includes pages used as references in Wikipedia.
- C4 (15%): A cleaned version of CommonCrawl. The same filters were applied.
- Github (4.5%): Public GitHub dataset available on Google BigQuery.
- Wikipedia (4.5%): From June-August 2022 period covering 20 languages.
- Gutenberg and Books3 (4.5%): Both are book datasets.
- ArXiv (45%): Scientific data.
- StackExchange (2%): High-quality Q&As covering science and engineering topics.
The training data has 1.4T tokens.
Performance
They evaluated the models with tasks such as common sense reasoning, reading comprehension, and code generation.Summary of performance:
- Larger is better: Larger models perform better in most tasks.
- More examples in the prompt are better: Give 5 examples to LLaMA 7B model is almost as good as not giving any to a 65B model in Natural Questions tasks.
- Smaller performant model. LLaMA 13B’s performance is similar to GPT-3, despite 10 times smaller. (13B vs 175B parameters)
- LLaMA is not very good at quantitative reasoning, especially the smaller 7B and 13B models.
- LLaMA is not tuned for instruction following like ChatGPT. However, the 65B model can follow basic instructions. We will wait for Alpaca (not for long).
Model size comparison
How much do you gain by using a bigger LLaMA model? The following table summarizes the performance of tasks in different categories. They are calculated based on the scores provided in the research article, assuming linear scales.| Average | Common sense reasoning | Natural Questions | Reading comprehension | TriviaQA | Quantitative reasoning | Code generation | Multitask language understanding | |
|---|---|---|---|---|---|---|---|---|
| 7B | 65% | 92% | 65% | 90% | 76% | 27% | 53% | 56% |
| 13B | 76% | 95% | 80% | 91% | 86% | 39% | 69% | 74% |
| 33B | 91% | 99% | 95% | 94% | 96% | 72% | 89% | 91% |
| 65B | 100% | 100% | 100% | 100% | 100% | 100% | 100% | 100% |
Is it worth using a bigger model? You can expect a ~50% generic improvement when switching from the 7B to the 65B model.
But it also depends on what you use the models for. You will only see a small gain for common sense reasoning and reading comprehension tasks. You will see a big gain for code generation and technical reading tasks.
Summary for LLaMA
The take-home message in this study is small models can perform well if you train them with enough data. This opens up the possibility of running a “local ChatGPT” on a PC.But the LLaMA base model was not trained to follow instructions. This is saved for later development.
To sum up, LLaMA is designed to be a base model for further fine-tuning. Its advantages are
- Small size
- Performant – thanks to extensive training
- Open source
Alpaca model
Alpaca is a fine-tuned LLaMA model, meaning that the model architecture is the same, but the weights are slightly different. It is aimed at resolving the lack of instruction-following capability of LLaMA models.It behaves like ChatGPT and can follow conversations and instructions.
The 7B and 13B Alpaca models are available.
Training
It was trained to follow instructions like ChatGPT.The authors first generate the training data using OpenAI’s GPT-3, then convert them to 52k instruction-following conversational data using the Self-Instruct pipeline.
Training pipeline of Alpaca (Source: Alpaca model page)
As a result, Alpaca is fine-tuned to respond to conversations like ChatGPT.
Performance
A blinded evaluation for instruction-following ability performed by some of the authors ranked the responses of Alpaca 7B and GPT-3 (text-davinci-003 specifically, which is also trained with instructions) roughly equally.This is a surprising result because Alpaca is 26 times smaller than GPT-3.
Of course, this is just a narrow aspect of performance. It doesn’t mean Alpaca performs equally with GPT-3 in other areas like code generation and scientific knowledge, which were not tested in the study.
Summary for Alpaca
Alpaca is a nice first step in fine-tuning the LLaMA model. As we see in the next section, it is outperformed by a similar fine-tuning effort, Vicuna.{continue reading on website}
A brief history of LLaMA models - AGI Sphere
The LLaMA base model was released in February 2023. Now we have seen a handful of new fine-tuned LLaMA models released.


#BOTHSIDES
Superstar

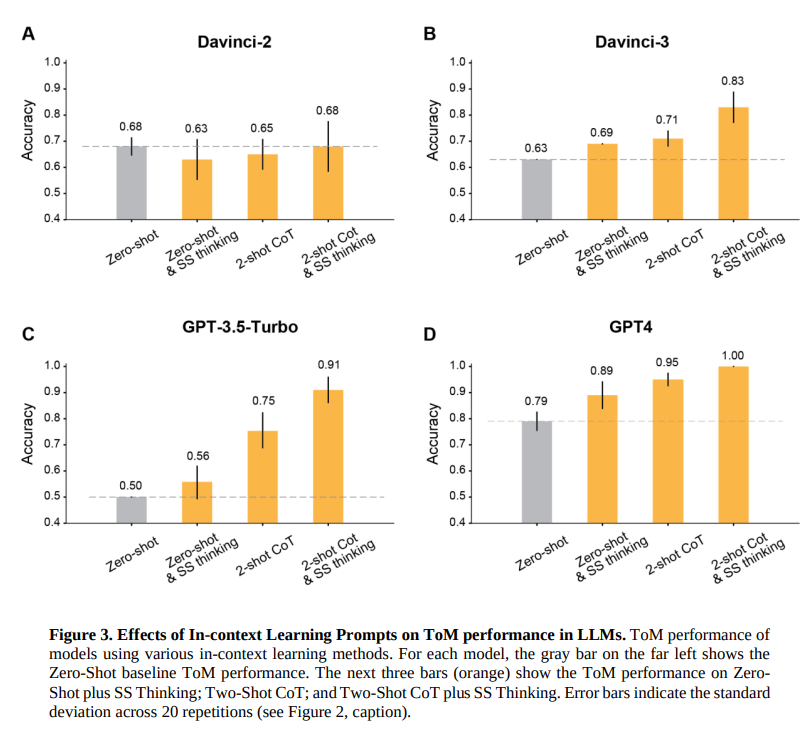
But when prompted to engage in step-by-step thinking [1] and elaborate a chain-of-thought [2], the 3 most recent OpenAI's LLMs all exceeded 80% ToM accuracy and GPT-4 reached 100%. Human accuracy on the ToM test set was 87%. But when prompted to engage in step-by-step thinking [1] and elaborate a chain-of-thought [2], the 3 most recent OpenAI's LLMs all exceeded 80% ToM accuracy and GPT-4 reached 100%. Human accuracy on the ToM test set was 87%.