1/21
@WenhuChen
I spent some time evaluating the frontier math models on AIME24 and AIME25 to see how they "Generalize".
An interesting trend I found is that SFT on minimum data can also generalize quite well if you pick the right data. See LIMO-32B.
Training with RL does not necessarily lead to better generalization than distillation. See the last two row.
2/21
@WenhuChen
To clarify a bit here:
I am not saying that using 1K data can teach LMs how to reason and generalize to all math problems! That's obviously impossible.
What's awesome is actually Qwen-32B-Instruct, which has been heavily trained on massive synthetic reasoning dataset. These RL and SFT approaches are simply trying to teach it the reasoning/self-reflection format and arouse its memorization. **Then Qwen-32B-Instruct does the work of generalization**.
3/21
@WenhuChen
It's very likely that this 1K data will not work with other weaker models.
So, in order to prove that your SFT or RL are actually doing the job, you should start from weaker models!
I would advocate people to start from OLMo-2 or something like that. Reaching 25%+ from those models will be a really big deal.
4/21
@sksq96
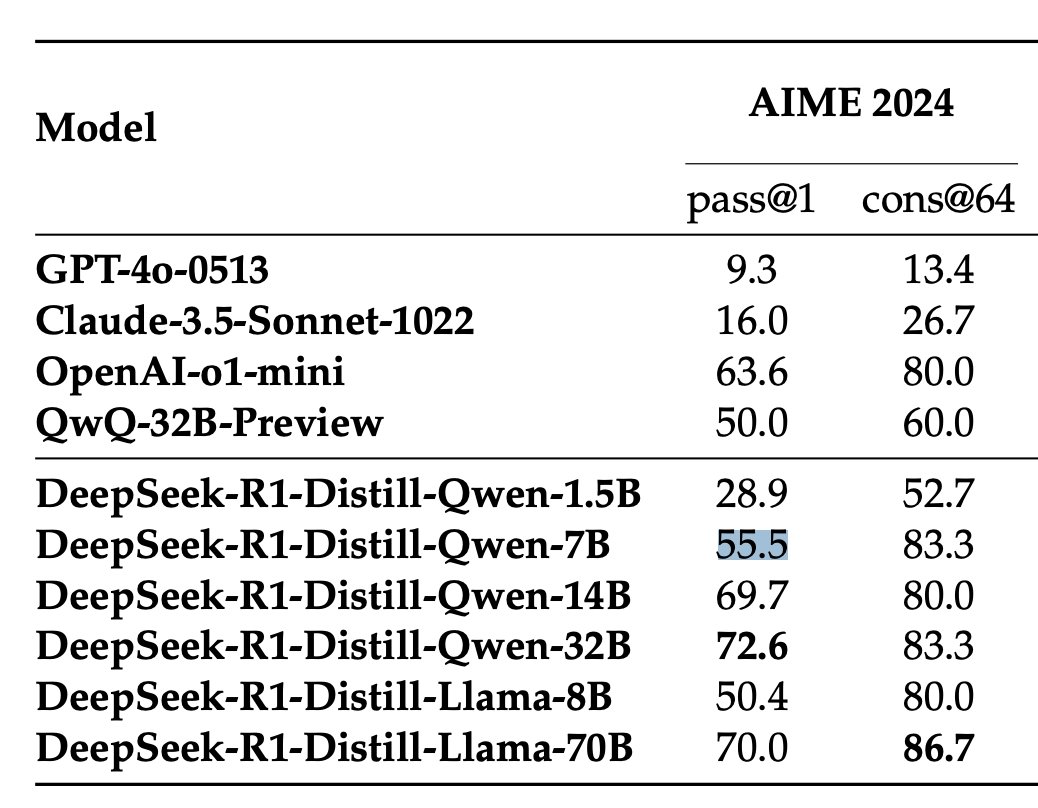
In the R1 paper, AIME24 is 55.5 for R1-Distill-Qwen-7B. I'm confused as to why this disparity with your evaluations.
5/21
@WenhuChen
Oh, it's a mistake. I will update it later.
6/21
@Alice_comfy
In terms of out of domain questions it seems quite established (both from my own testing & studies) that whatever OpenAI is doing generalizes much better than compeiting products.
I'm not sure if they have an additional step beyond the other ones.
PhD Knowledge Not Required: A Reasoning Challenge for Large Language Models
7/21
@WenhuChen
Yes, that's also my impression. OpenAI models seem to be more robust than anyone else, especially on some really really weird tasks I tried before.
8/21
@TheXeophon
Important context on AIME
[Quoted tweet]
AIME I 2025: A Cautionary Tale About Math Benchmarks and Data Contamination
AIME 2025 part I was conducted yesterday, and the scores of some language models are available here:
matharena.ai thanks to @mbalunovic, @ni_jovanovic et al.
I have to say I was impressed, as I predicted the smaller distilled models would crash and burn, but they actually scored at a reasonable 25-50%.
That was surprising to me! Since these are new problems, not seen during training, right? I expected smaller models to barely score above 0%. It's really hard to believe that a 1.5B model can solve pre-math olympiad problems when it can't multiply 3-digit numbers. I was wrong, I guess.
I then used openai's Deep Research to see if similar problems to those in AIME 2025 exist on the internet. And guess what? An identical problem to Q1 of AIME 2025 exists on Quora:
quora.com/In-what-bases-b-do…
I thought maybe it was just coincidence, and used Deep Research again on Problem 3. And guess what? A very similar question was on math.stackexchange:
math.stackexchange.com/quest…
Still skeptical, I used Deep Research on Problem 5, and a near identical problem appears again on math.stackexchange:
math.stackexchange.com/quest…
I haven't checked beyond that because the freaking p-value is too low already. Problems near identical to the test set can be found online.
So, what--if anything--does this imply for Math benchmarks? And what does it imply for all the sudden hill climbing due to RL?
I'm not certain, and there is a reasonable argument that even if something in the train-set contains near-identical but not exact copies of test data, it's still generalization. I am sympathetic to that. But, I also wouldn't rule out that GRPO is amazing at sharpening memories along with math skills.
At the very least, the above show that data decontamination is hard.
Never ever underestimate the amount of stuff you can find online. Practically everything exists online.
9/21
@WenhuChen
I saw this but I don't think this is sufficient evidence to prove leakage. Also, if you check the model output, the potentially leaked questions are actually the ones LLMs fail.
10/21
@winnieyangwn
I Think testing generalization is the most important direction! How do you measure generalization here?
11/21
@WenhuChen
AIME 2025 is supposedly unseen. So we use it to test generalization
12/21
@YouJiacheng
Interestingly, s1 seems to be consistently much weaker than LIMO.
[Quoted tweet]

AIME-Preview: A real-time benchmark for math reasoning models on AIME 2025!

See how DeepSeek, O Series, LIMO & others performed on Part 1

Evaluate your own models with our open-source scripts

Part 2 results coming soon
github.com/GAIR-NLP/AIME-Pre…
13/21
@WenhuChen
It seems so. But there are only 15/30 examples, so the real difference might not be as huge as reported.
14/21
@n0riskn0r3ward
Relevant to the challenge of drawing conclusions from the 2025 set:
[Quoted tweet]
AIME I 2025: A Cautionary Tale About Math Benchmarks and Data Contamination
AIME 2025 part I was conducted yesterday, and the scores of some language models are available here:
matharena.ai thanks to @mbalunovic, @ni_jovanovic et al.
I have to say I was impressed, as I predicted the smaller distilled models would crash and burn, but they actually scored at a reasonable 25-50%.
That was surprising to me! Since these are new problems, not seen during training, right? I expected smaller models to barely score above 0%. It's really hard to believe that a 1.5B model can solve pre-math olympiad problems when it can't multiply 3-digit numbers. I was wrong, I guess.
I then used openai's Deep Research to see if similar problems to those in AIME 2025 exist on the internet. And guess what? An identical problem to Q1 of AIME 2025 exists on Quora:
quora.com/In-what-bases-b-do…
I thought maybe it was just coincidence, and used Deep Research again on Problem 3. And guess what? A very similar question was on math.stackexchange:
math.stackexchange.com/quest…
Still skeptical, I used Deep Research on Problem 5, and a near identical problem appears again on math.stackexchange:
math.stackexchange.com/quest…
I haven't checked beyond that because the freaking p-value is too low already. Problems near identical to the test set can be found online.
So, what--if anything--does this imply for Math benchmarks? And what does it imply for all the sudden hill climbing due to RL?
I'm not certain, and there is a reasonable argument that even if something in the train-set contains near-identical but not exact copies of test data, it's still generalization. I am sympathetic to that. But, I also wouldn't rule out that GRPO is amazing at sharpening memories along with math skills.
At the very least, the above show that data decontamination is hard.
Never ever underestimate the amount of stuff you can find online. Practically everything exists online.
15/21
@WenhuChen
I saw this but I don't think this is sufficient evidence to prove leakage. Also, if you check the model output, the potentially leaked questions are actually the ones LLMs fail.
16/21
@Cory29565470
love this, generalization (sometimes called ~vibes~ is so important to test) in this hype echo chamber. great work
17/21
@AlexGDimakis
Thanks for posting. Is this one run or averaged a few times to reduce variance?
18/21
@yangyc666
Interesting point about SFT and data selection. It’s true that the right data can make a big difference in generalization. I’ve seen cases where targeted datasets led to better performance than larger, less relevant ones. It’s all about finding that sweet spot between quantity and quality.
19/21
@bookwormengr
Hi @wenhu I tried LIMO dataset, but performance gains didn't replicate (may be it required more epochs, i had only 3-5 or my base model was weaker. I see LIMA has 15 epochs).
LIMO worked so well because the base was Qwen-2.5-32B-Instruct. Even the paper calls out that their experiment on Chat version of Qwen didn't work as well.
So, the magic is not SFT with 800 LIMO examples alone, but what is done to the model before SFT with LIMO dataset is performed and it seems like lot of work & flops.
So in my humble opinion, it would be wrong to say "SFT" on minimal data did the trick of unlocking the reasoning. A lot had happened before the stage.
Excerpt from Qwen 2.5 Technical report shared by @abacaj
20/21
@legolasyiu
Data is very important
21/21
@kuyz12131
Does this mean that finetuning the big model with very high - quality human cot data will yield better results than RL?
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196


 How did you get this...
How did you get this...






 Deep dive into temperature impact analysis & performance trends
Deep dive into temperature impact analysis & performance trends

 Math reasoning models are surprisingly temperature-sensitive!
Math reasoning models are surprisingly temperature-sensitive! Performance swings up to 15% across temperature settings
Performance swings up to 15% across temperature settings


 How many examples does an LLM need to learn competition-level math?
How many examples does an LLM need to learn competition-level math?

 arxiv.org/pdf/2502.03387
arxiv.org/pdf/2502.03387





 Diverse Preference Optimization (DivPO)
Diverse Preference Optimization (DivPO)  DivPO trains for both high reward & diversity, vastly improving variety with similar quality.
DivPO trains for both high reward & diversity, vastly improving variety with similar quality. below
below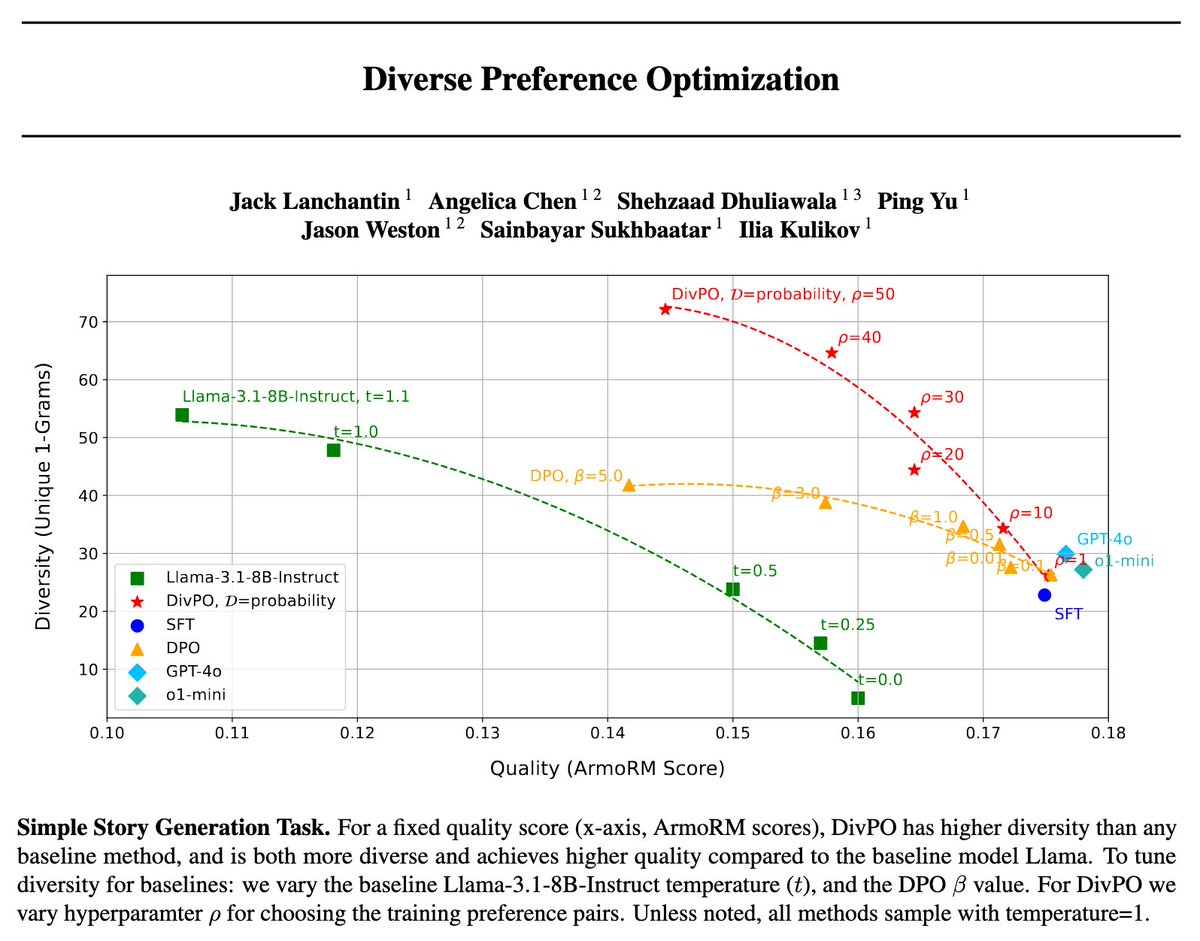
 :
:















