
You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
The A.I Megathread (LLM , GPT , Development)
More options
Who Replied?
Understanding Test Time Compute: How AI Systems Learn to Think in Real-Time
Test Time Compute (TTC) represents a transformative shift in how AI systems process information, moving beyond traditional static inference to enable real-time adaptive reasoning. OpenAI’s gr…
Understanding Test Time Compute: How AI Systems Learn to Think in Real-Time
Understanding Test Time Compute: How AI Systems Learn to Think in Real-Time
Test Time Compute (TTC) represents a transformative shift in how AI systems process information, moving beyond traditional static inference to enable real-time adaptive reasoning. OpenAI’s gr…
Understanding Test Time Compute: How AI Systems Learn to Think in Real-Time
Artificial Intelligence, Featured, Interesting Papers15 minutes
December 3, 2024
Audio Overview
Powered by Notebook LM
In the race for AI advancement, we’ve been asking the wrong question. While the world obsesses over “How do we make AI more powerful?”, a quiet revolution is taking place that asks: “How do we make AI think better?” Enter OpenAI’s o1 model, which demonstrates how rethinking computation itself might be more valuable than simply scaling it up.
The o1 model from Open AI stole the spotlight by showcasing an unprecedented capability: it meticulously lays out a step-by-step chain of reasoning before delivering its answers. Imagine having a problem-solving partner who not only provides the solution but also walks you through every logical step they took to get there. This advancement isn’t just about transparency; it’s about enhancing the quality of AI reasoning itself, pushing the boundaries in fields from scientific research to complex system design.
This shift highlights the significance of Test Time Compute (TTC), a set of strategies designed to boost how AI systems process information during inference. It’s not just about processing power – it’s about processing intelligence. This approach enables AI systems to dynamically refine their computational strategies during inference, leading to more nuanced and contextually appropriate responses.
In this blog, we’ll dive deeper into TTC, exploring its transformative techniques and why it’s crucial for shaping AI into adaptable, reasoning-driven systems for the future.
What is Test Time Compute?

Definition and Key Principles
Test-time Compute (TTC) is a game-changer in AI, dynamically allocating computational resources during the inference phase to supercharge model performance. Unlike traditional methods, TTC enables models to perform additional computations for deeper reasoning and adapt to novel inputs in real-time. Think of it as giving your AI the ability to think on its feet, making it more versatile and effective.
Comparison with Traditional Inference
Traditional inference relies solely on pre-trained knowledge, delivering outputs instantaneously and prioritizing speed above all else. In contrast, TTC allows models to “think” during inference by allocating extra compute resources as needed for more challenging tasks. This adaptability bridges the gap between static, pre-trained models and dynamic, problem-solving systems, making AI more responsive and intelligent.
Evolution of TTC
Initially, inference techniques were all about delivering quick responses. However, as tasks became more complex, these methods struggled to provide accurate or nuanced outputs. TTC emerged as a solution, incorporating iterative processes and advanced strategies that enable models to evaluate multiple solutions systematically and select the best one.
The Rise of TTC
Test-time Compute (TTC) is rapidly gaining traction in the development of advanced reasoning models. Cutting-edge AI models like OpenAI’s o1 and Alibaba’s QwQ-32B-Preview are leveraging TTC to enhance their reasoning capabilities. By allocating additional computational resources during inference, these models can tackle complex tasks more effectively. This approach allows them to “think” before responding, significantly improving performance in areas like mathematics, coding, and scientific problem-solving.
Bridging Training-Time and Inference-Time Optimization
While TTC addresses many challenges, its true value bridges a fundamental gap in AI systems: the disconnect between training and inference.

The Gap Between Training and Inference
AI models learn from vast datasets during training, recognizing patterns and generalizing knowledge. However, they may encounter novel inputs outside their training distribution during inference. This mismatch can lead to errors or suboptimal performance, particularly in tasks requiring deep reasoning or context-specific adaptations.
TTC as the Bridge
TTC addresses this gap by enabling models to adapt dynamically during inference. For example, a speech recognition model encountering an unfamiliar accent can use TTC to refine its understanding in real time, producing more accurate transcriptions.
Research shows that applying compute-optimal scaling strategies—a core principle of TTC—can improve test-time efficiency by over fourfold compared to traditional methods, making TTC both a practical and scalable solution.
Techniques of Test Time Compute
Think of Test Time Compute (TTC) as giving your AI a powerful set of thinking tools that it can use while solving problems, rather than just relying on what it learned during training. Let’s explore these fascinating techniques that are revolutionizing how AI systems reason and adapt in real-time.
1. Chain of Thought (CoT) Reasoning

How it Works: Chain of Thought (CoT) Reasoning: Chain of Thought transforms AI reasoning by enabling models to decompose complex problems into explicit, verifiable steps—like a master logician revealing each link in their analytical chain. This transparency allows us to follow the model’s cognitive journey, turning the traditional black-box approach into a clear, methodical reasoning process.
Technical Mechanism: – Recursive prompt decomposition – Intermediate state tracking – Step validation mechanisms – Sequential reasoning path construction
Example:
Question: “If Alice has twice as many books as Bob, and Bob has 15 books, how many do they have together?
Step 1: Calculate Alice’s books = 2 × Bob’s books = 2 × 15 = 30
Step 2: Total books = Alice’s books + Bob’s books = 30 + 15 = 45
Answer: They have 45 books together

| Pros | Cons |
| Transparent reasoning process | Increased processing time |
| Better error detection | Higher computational overhead |
| Improved accuracy on complex tasks |
Chain of Thought reasoning represents the simplest and most intuitive way of implementing Test Time Compute. It acts as a foundational framework for many advanced methods by enabling dynamic thinking and iterative refinement during inference. While CoT remains highly effective, ongoing research is exploring innovative approaches to enhance TTC further. We will explore some of the other approaches next in this section.
2. Filler Token Computation

Image Courtesy Let’s Think Dot by Dot
How it Works: Filler Token Computation acts as a neural scaffold, strategically inserting computational markers during inference that help models navigate complex relationships. These temporary tokens create critical connection points in the model’s processing pipeline, enabling deeper understanding of dependencies and context—similar to how temporary supports enable the construction of complex architectural structures.
Technical Mechanism: – Dynamic token insertion – Context-aware placement – Relationship modeling – Temporary state management
Example:
Input: “The cat sat on the mat”
Result: Deeper understanding of relationships and roles

| Pros | Cons |
| Enhanced relationship processing | Memory overhead |
| Improved context understanding | Processing complexity |
| Better handling of complex structures | Token management challenges |
3. Adaptive Decoding Strategies

How it Works: Adaptive Decoding Strategies function as an AI system’s dynamic control center, intelligently adjusting token generation probabilities in real-time to balance between creative exploration and precise outputs. Like a precision instrument auto-calibrating its settings, it continuously modulates the sampling temperature based on task requirements—tightening the distribution for factual accuracy or broadening it for creative tasks.
Technical Mechanism: – Dynamic sampling temperature – Probability distribution shaping – Token selection optimization – Context-aware generation
Example:
Task: Generating product descriptions
Conservative: “A durable leather wallet with multiple card slots.”
Creative: “An artisanal leather masterpiece, thoughtfully crafted with precision-cut card sanctuaries.”

| Pros | Cons |
| Controllable output style | Parameter tuning complexity |
| Better context matching | Performance overhead |
| Flexible creativity levels | Balance maintenance |
4. Search Against Verifiers
DeepSeek_V3.pdf
The DeepSeek v3 paper (and [model card](https://github.com/deepseek-ai/DeepSeek-V3/blob/main/README.md)) are out, after yesterday's mysterious release of [the undocumented model weights](https://simonwillison.net/2024/Dec/25/deepseek-v3/). Plenty of interesting details in here. The model...
simonwillison.net
DeepSeek_V3.pdf (via) The DeepSeek v3 paper (and model card) are out, after yesterday's mysterious release of the undocumented model weights.
Plenty of interesting details in here. The model pre-trained on 14.8 trillion "high-quality and diverse tokens" (not otherwise documented).
Following this, we conduct post-training, including Supervised Fine-Tuning (SFT) and Reinforcement Learning (RL) on the base model of DeepSeek-V3, to align it with human preferences and further unlock its potential. During the post-training stage, we distill the reasoning capability from the DeepSeek-R1 series of models, and meanwhile carefully maintain the balance between model accuracy and generation length.
By far the most interesting detail though is how much the training cost. DeepSeek v3 trained on 2,788,000 H800 GPU hours at an estimated cost of $5,576,000. For comparison, Meta AI's Llama 3.1 405B (smaller than DeepSeek v3's 685B parameters) trained on 11x that - 30,840,000 GPU hours, also on 15 trillion tokens.
DeepSeek v3 benchmarks comparably to Claude 3.5 Sonnet, indicating that it's now possible to train a frontier-class model (at least for the 2024 version of the frontier) for less than $6 million!
Andrej Karpathy:
For reference, this level of capability is supposed to require clusters of closer to 16K GPUs, the ones being brought up today are more around 100K GPUs. E.g. Llama 3 405B used 30.8M GPU-hours, while DeepSeek-V3 looks to be a stronger model at only 2.8M GPU-hours (~11X less compute). If the model also passes vibe checks (e.g. LLM arena rankings are ongoing, my few quick tests went well so far) it will be a highly impressive display of research and engineering under resource constraints.
DeepSeek also announced their API pricing. From February 8th onwards:
Input: $0.27/million tokens ($0.07/million tokens with cache hits)
Output: $1.10/million tokens
Claude 3.5 Sonnet is currently $3/million for input and $15/million for output, so if the models are indeed of equivalent quality this is a dramatic new twist in the ongoing LLM pricing wars.
Posted 26th December 2024 at 6:49 pm
Things we learned about LLMs in 2024
A lot has happened in the world of Large Language Models over the course of 2024. Here’s a review of things we figured out about the field in the past …
simonwillison.net
Things we learned about LLMs in 2024
A lot has happened in the world of Large Language Models over the course of 2024. Here’s a review of things we figured out about the field in the past twelve months, plus my attempt at identifying key themes and pivotal moments.
This is a sequel to my review of 2023.
In this article:
- The GPT-4 barrier was comprehensively broken
- Some of those GPT-4 models run on my laptop
- LLM prices crashed, thanks to competition and increased efficiency
- Multimodal vision is common, audio and video are starting to emerge
- Voice and live camera mode are science fiction come to life
- Prompt driven app generation is a commodity already
- Universal access to the best models lasted for just a few short months
- “Agents” still haven’t really happened yet
- Evals really matter
- Apple Intelligence is bad, Apple’s MLX library is excellent
- The rise of inference-scaling “reasoning” models
- Was the best currently available LLM trained in China for less than $6m?
- The environmental impact got better
- The environmental impact got much, much worse
- The year of slop
- Synthetic training data works great
- LLMs somehow got even harder to use
- Knowledge is incredibly unevenly distributed
- LLMs need better criticism
- Everything tagged “llms” on my blog in 2024
The GPT-4 barrier was comprehensively broken
In my December 2023 review I wrote about how We don’t yet know how to build GPT-4—OpenAI’s best model was almost a year old at that point, yet no other AI lab had produced anything better. What did OpenAI know that the rest of us didn’t?
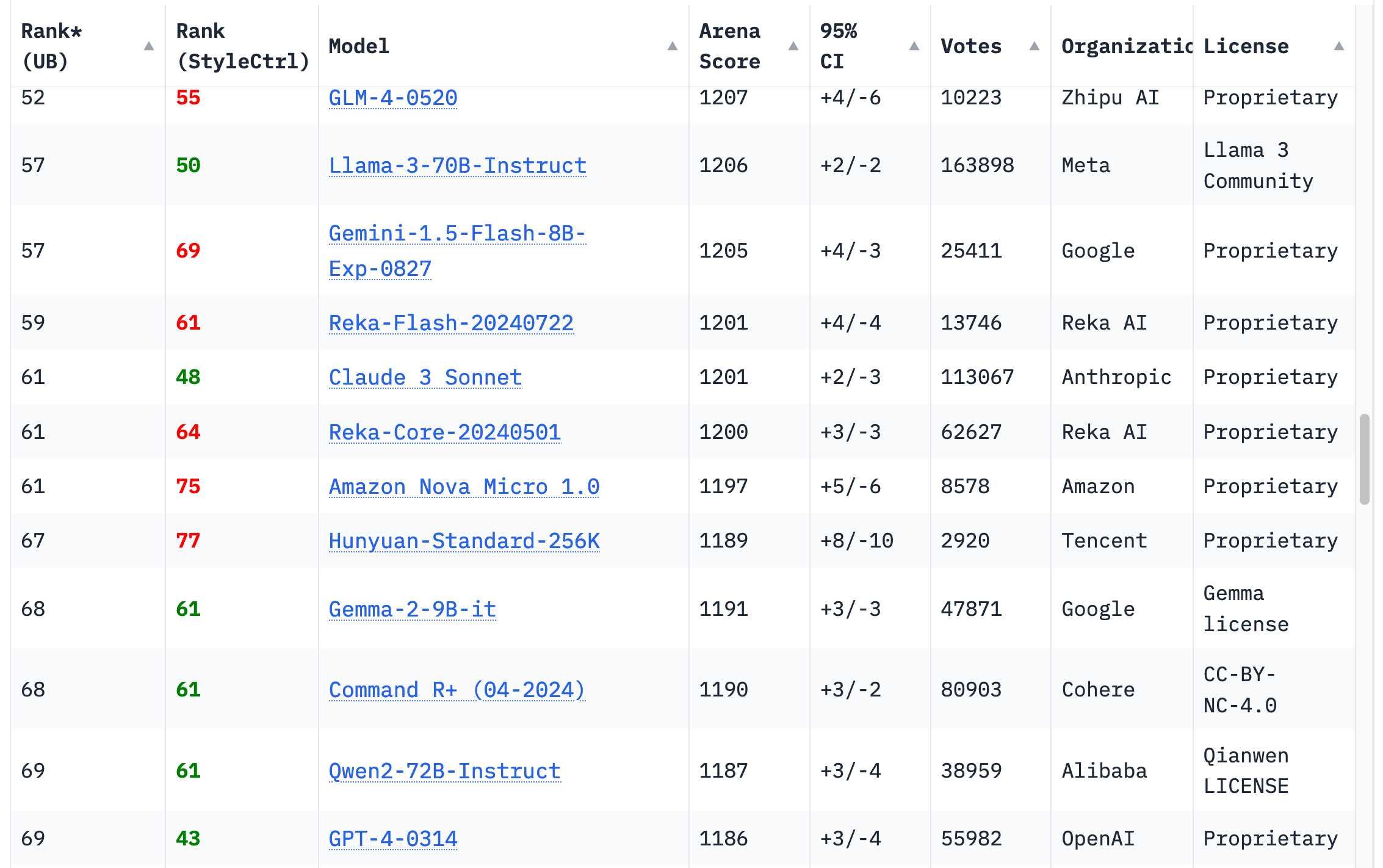
I’m relieved that this has changed completely in the past twelve months. 18 organizations now have models on the Chatbot Arena Leaderboard that rank higher than the original GPT-4 from March 2023 (GPT-4-0314 on the board)—70 models in total.
The earliest of those was Google’s Gemini 1.5 Pro, released in February. In addition to producing GPT-4 level outputs, it introduced several brand new capabilities to the field—most notably its 1 million (and then later 2 million) token input context length, and the ability to input video.
I wrote about this at the time in The killer app of Gemini Pro 1.5 is video, which earned me a short appearance as a talking head in the Google I/O opening keynote in May.
Gemini 1.5 Pro also illustrated one of the key themes of 2024: increased context lengths. Last year most models accepted 4,096 or 8,192 tokens, with the notable exception of Claude 2.1 which accepted 200,000. Today every serious provider has a 100,000+ token model, and Google’s Gemini series accepts up to 2 million.
Longer inputs dramatically increase the scope of problems that can be solved with an LLM: you can now throw in an entire book and ask questions about its contents, but more importantly you can feed in a lot of example code to help the model correctly solve a coding problem. LLM use-cases that involve long inputs are far more interesting to me than short prompts that rely purely on the information already baked into the model weights. Many of my tools were built using this pattern.
Getting back to models that beat GPT-4: Anthropic’s Claude 3 series launched in March, and Claude 3 Opus quickly became my new favourite daily-driver. They upped the ante even more in June with the launch of Claude 3.5 Sonnet—a model that is still my favourite six months later (though it got a significant upgrade on October 22, confusingly keeping the same 3.5 version number. Anthropic fans have since taken to calling it Claude 3.6).
Then there’s the rest. If you browse the Chatbot Arena leaderboard today—still the most useful single place to get a vibes-based evaluation of models—you’ll see that GPT-4-0314 has fallen to around 70th place. The 18 organizations with higher scoring models are Google, OpenAI, Alibaba, Anthropic, Meta, Reka AI, 01 AI, Amazon, Cohere, DeepSeek, Nvidia, Mistral, NexusFlow, Zhipu AI, xAI, AI21 Labs, Princeton and Tencent.
Training a GPT-4 beating model was a huge deal in 2023. In 2024 it’s an achievement that isn’t even particularly notable, though I personally still celebrate any time a new organization joins that list.
Some of those GPT-4 models run on my laptop
My personal laptop is a 64GB M2 MackBook Pro from 2023. It’s a powerful machine, but it’s also nearly two years old now—and crucially it’s the same laptop I’ve been using ever since I first ran an LLM on my computer back in March 2023 (see Large language models are having their Stable Diffusion moment).
That same laptop that could just about run a GPT-3-class model in March last year has now run multiple GPT-4 class models! Some of my notes on that:
- Qwen2.5-Coder-32B is an LLM that can code well that runs on my Mac talks about Qwen2.5-Coder-32B in November—an Apache 2.0 licensed model!
- I can now run a GPT-4 class model on my laptop talks about running Meta’s Llama 3.3 70B (released in December)
This remains astonishing to me. I thought a model with the capabilities and output quality of GPT-4 needed a datacenter class server with one or more $40,000+ GPUs.
These models take up enough of my 64GB of RAM that I don’t run them often—they don’t leave much room for anything else.
The fact that they run at all is a testament to the incredible training and inference performance gains that we’ve figured out over the past year. It turns out there was a lot of low-hanging fruit to be harvested in terms of model efficiency. I expect there’s still more to come.
Meta’s Llama 3.2 models deserve a special mention. They may not be GPT-4 class, but at 1B and 3B sizes they punch massively above their weight. I run Llama 3.2 3B on my iPhone using the free MLC Chat iOS app and it’s a shockingly capable model for its tiny (<2GB) size. Try firing it up and asking it for “a plot outline of a Netflix Christmas movie where a data journalist falls in love with a local ceramacist”. Here’s what I got, at a respectable 20 tokens per second:
![MLC Chat: Llama - [System] Ready to chat. a plot outline of a Netflix Christmas movie where a data journalist falls in love with a local ceramacist. Show as Markdown is turned on. Here's a plot outline for a Netflix Christmas movie: Title: Love in the Clay Plot Outline: We meet our protagonist, JESSICA, a data journalist who has just returned to her hometown of Willow Creek, a small, charming town nestled in the snow-covered mountains. She's back to work on a story about the town's history and the effects of gentrification on the local community.](https://static.simonwillison.net/static/2024/mlc-chat-christmas.jpg "MLC Chat: Llama - [System] Ready to chat. a plot outline of a Netflix Christmas movie where a data journalist falls in love with a local ceramacist. Show as Markdown is turned on. Here's a plot outline for a Netflix Christmas movie: Title: Love in the Clay Plot Outline: We meet our protagonist, JESSICA, a data journalist who has just returned to her hometown of Willow Creek, a small, charming town nestled in the snow-covered mountains. She's back to work on a story about the town's history and the effects of gentrification on the local community.")
Here’s the rest of the transcript. It’s bland and generic, but my phone can pitch bland and generic Christmas movies to Netflix now!
LLM prices crashed, thanks to competition and increased efficiency
The past twelve months have seen a dramatic collapse in the cost of running a prompt through the top tier hosted LLMs.
In December 2023 (here’s the Internet Archive for the OpenAI pricing page) OpenAI were charging $30/million input tokens for GPT-4, $10/mTok for the then-new GPT-4 Turbo and $1/mTok for GPT-3.5 Turbo.
Today $30/mTok gets you OpenAI’s most expensive model, o1. GPT-4o is $2.50 (12x cheaper than GPT-4) and GPT-4o mini is $0.15/mTok—nearly 7x cheaper than GPT-3.5 and massively more capable.
Other model providers charge even less. Anthropic’s Claude 3 Haiku (from March, but still their cheapest model) is $0.25/mTok. Google’s Gemini 1.5 Flash is $0.075/mTok and their Gemini 1.5 Flash 8B is $0.0375/mTok—that’s 27x cheaper than GPT-3.5 Turbo last year.
I’ve been tracking these pricing changes under my llm-pricing tag.
These price drops are driven by two factors: increased competition and increased efficiency. The efficiency thing is really important for everyone who is concerned about the environmental impact of LLMs. These price drops tie directly to how much energy is being used for running prompts.
There’s still plenty to worry about with respect to the environmental impact of the great AI datacenter buildout, but a lot of the concerns over the energy cost of individual prompts are no longer credible.
Here’s a fun napkin calculation: how much would it cost to generate short descriptions of every one of the 68,000 photos in my personal photo library using Google’s Gemini 1.5 Flash 8B (released in October), their cheapest model?
Each photo would need 260 input tokens and around 100 output tokens.
260 * 68,000 = 17,680,000 input tokens
17,680,000 * $0.0375/million = $0.66
100 * 68,000 = 6,800,000 output tokens
6,800,000 * $0.15/million = $1.02
That’s a total cost of $1.68 to process 68,000 images. That’s so absurdly cheap I had to run the numbers three times to confirm I got it right.
How good are those descriptions? Here’s what I got from this command:
llm -m gemini-1.5-flash-8b-latest describe -a IMG_1825.jpeg<br>
Against this photo of butterflies at the California Academy of Sciences:

260 input tokens, 92 output tokens. Cost approximately 0.0024 cents (that’s less than a 400th of a cent).
This increase in efficiency and reduction in price is my single favourite trend from 2024. I want the utility of LLMs at a fraction of the energy cost and it looks like that’s what we’re getting.
My butterfly example above illustrates another key trend from 2024: the rise of multi-modal LLMs.
A year ago the single most notable example of these was GPT-4 Vision, released at OpenAI’s DevDay in November 2023. Google’s multi-modal Gemini 1.0 was announced on December 7th 2023 so it also (just) makes it into the 2023 window.
In 2024, almost every significant model vendor released multi-modal models. We saw the Claude 3 series from Anthropic in March, Gemini 1.5 Pro in April (images, audio and video), then September brought Qwen2-VL and Mistral’s Pixtral 12B and Meta’s Llama 3.2 11B and 90B vision models. We got audio input and output from OpenAI in October, then November saw SmolVLM from Hugging Face and December saw image and video models from Amazon Nova.
In October I upgraded my LLM CLI tool to support multi-modal models via attachments. It now has plugins for a whole collection of different vision models.
I think people who complain that LLM improvement has slowed are often missing the enormous advances in these multi-modal models. Being able to run prompts against images (and audio and video) is a fascinating new way to apply these models.
The audio and live video modes that have started to emerge deserve a special mention.
The ability to talk to ChatGPT first arrived in September 2023, but it was mostly an illusion: OpenAI used their excellent Whisper speech-to-text model and a new text-to-speech model (creatively named tts-1) to enable conversations with the ChatGPT mobile apps, but the actual model just saw text.
The May 13th announcement of GPT-4o included a demo of a brand new voice mode, where the true multi-modal GPT-4o (the o is for “omni”) model could accept audio input and output incredibly realistic sounding speech without needing separate TTS or STT models.
The demo also sounded conspicuously similar to Scarlett Johansson... and after she complained the voice from the demo, Skye, never made it to a production product.
The delay in releasing the new voice mode after the initial demo caused quite a lot of confusion. I wrote about that in ChatGPT in “4o” mode is not running the new features yet.
When ChatGPT Advanced Voice mode finally did roll out (a slow roll from August through September) it was spectacular. I’ve been using it extensively on walks with my dog and it’s amazing how much the improvement in intonation elevates the material. I’ve also had a lot of fun experimenting with the OpenAI audio APIs.
Even more fun: Advanced Voice mode can do accents! Here’s what happened when I told it I need you to pretend to be a California brown pelican with a very thick Russian accent, but you talk to me exclusively in Spanish.
OpenAI aren’t the only group with a multi-modal audio model. Google’s Gemini also accepts audio input, and the Google Gemini apps can speak in a similar way to ChatGPT now. Amazon also pre-announced voice mode for Amazon Nova, but that’s meant to roll out in Q1 of 2025.
Google’s NotebookLM, released in September, took audio output to a new level by producing spookily realistic conversations between two “podcast hosts” about anything you fed into their tool. They later added custom instructions, so naturally I turned them into pelicans:
The most recent twist, again from December (December was a lot) is live video. ChatGPT voice mode now provides the option to share your camera feed with the model and talk about what you can see in real time. Google Gemini have a preview of the same feature, which they managed to ship the day before ChatGPT did.
These abilities are just a few weeks old at this point, and I don’t think their impact has been fully felt yet. If you haven’t tried them out yet you really should.
Both Gemini and OpenAI offer API access to these features as well. OpenAI started with a WebSocket API that was quite challenging to use, but in December they announced a new WebRTC API which is much easier to get started with. Building a web app that a user can talk to via voice is easy now!
This was possible with GPT-4 in 2023, but the value it provides became evident in 2024.
We already knew LLMs were spookily good at writing code. If you prompt them right, it turns out they can build you a full interactive application using HTML, CSS and JavaScript (and tools like React if you wire up some extra supporting build mechanisms)—often in a single prompt.
Anthropic kicked this idea into high gear when they released Claude Artifacts, a groundbreaking new fetaure that was initially slightly lost in the noise due to being described half way through their announcement of the incredible Claude 3.5 Sonnet.
With Artifacts, Claude can write you an on-demand interactive application and then let you use it directly inside the Claude interface.
Here’s my Extract URLs app, entirely generated by Claude:

I’ve found myself using this a lot. I noticed how much I was relying on it in October and wrote Everything I built with Claude Artifacts this week, describing 14 little tools I had put together in a seven day period.
Since then, a whole bunch of other teams have built similar systems. GitHub announced their version of this—GitHub Spark—in October. Mistral Chat added it as a feature called Canvas in November.
Steve Krause from Val Town built a version of it against Cerebras, showcasing how a 2,000 token/second LLM can iterate on an application with changes visible in less than a second.
Then in December, the Chatbot Arena team introduced a whole new leaderboard for this feature, driven by users building the same interactive app twice with two different models and voting on the answer. Hard to come up with a more convincing argument that this feature is now a commodity that can be effectively implemented against all of the leading models.
I’ve been tinkering with a version of this myself for my Datasette project, with the goal of letting users use prompts to build and iterate on custom widgets and data visualizations against their own data. I also figured out a similar pattern for writing one-shot Python programs, enabled by uv.
These price drops are driven by two factors: increased competition and increased efficiency. The efficiency thing is really important for everyone who is concerned about the environmental impact of LLMs. These price drops tie directly to how much energy is being used for running prompts.
There’s still plenty to worry about with respect to the environmental impact of the great AI datacenter buildout, but a lot of the concerns over the energy cost of individual prompts are no longer credible.
Here’s a fun napkin calculation: how much would it cost to generate short descriptions of every one of the 68,000 photos in my personal photo library using Google’s Gemini 1.5 Flash 8B (released in October), their cheapest model?
Each photo would need 260 input tokens and around 100 output tokens.
260 * 68,000 = 17,680,000 input tokens
17,680,000 * $0.0375/million = $0.66
100 * 68,000 = 6,800,000 output tokens
6,800,000 * $0.15/million = $1.02
That’s a total cost of $1.68 to process 68,000 images. That’s so absurdly cheap I had to run the numbers three times to confirm I got it right.
How good are those descriptions? Here’s what I got from this command:
llm -m gemini-1.5-flash-8b-latest describe -a IMG_1825.jpeg<br>
Against this photo of butterflies at the California Academy of Sciences:
A shallow dish, likely a hummingbird or butterfly feeder, is red. Pieces of orange slices of fruit are visible inside the dish.
Two butterflies are positioned in the feeder, one is a dark brown/black butterfly with white/cream-colored markings. The other is a large, brown butterfly with patterns of lighter brown, beige, and black markings, including prominent eye spots. The larger brown butterfly appears to be feeding on the fruit.
260 input tokens, 92 output tokens. Cost approximately 0.0024 cents (that’s less than a 400th of a cent).
This increase in efficiency and reduction in price is my single favourite trend from 2024. I want the utility of LLMs at a fraction of the energy cost and it looks like that’s what we’re getting.
Multimodal vision is common, audio and video are starting to emerge
My butterfly example above illustrates another key trend from 2024: the rise of multi-modal LLMs.
A year ago the single most notable example of these was GPT-4 Vision, released at OpenAI’s DevDay in November 2023. Google’s multi-modal Gemini 1.0 was announced on December 7th 2023 so it also (just) makes it into the 2023 window.
In 2024, almost every significant model vendor released multi-modal models. We saw the Claude 3 series from Anthropic in March, Gemini 1.5 Pro in April (images, audio and video), then September brought Qwen2-VL and Mistral’s Pixtral 12B and Meta’s Llama 3.2 11B and 90B vision models. We got audio input and output from OpenAI in October, then November saw SmolVLM from Hugging Face and December saw image and video models from Amazon Nova.
In October I upgraded my LLM CLI tool to support multi-modal models via attachments. It now has plugins for a whole collection of different vision models.
I think people who complain that LLM improvement has slowed are often missing the enormous advances in these multi-modal models. Being able to run prompts against images (and audio and video) is a fascinating new way to apply these models.
Voice and live camera mode are science fiction come to life
The audio and live video modes that have started to emerge deserve a special mention.
The ability to talk to ChatGPT first arrived in September 2023, but it was mostly an illusion: OpenAI used their excellent Whisper speech-to-text model and a new text-to-speech model (creatively named tts-1) to enable conversations with the ChatGPT mobile apps, but the actual model just saw text.
The May 13th announcement of GPT-4o included a demo of a brand new voice mode, where the true multi-modal GPT-4o (the o is for “omni”) model could accept audio input and output incredibly realistic sounding speech without needing separate TTS or STT models.
The demo also sounded conspicuously similar to Scarlett Johansson... and after she complained the voice from the demo, Skye, never made it to a production product.
The delay in releasing the new voice mode after the initial demo caused quite a lot of confusion. I wrote about that in ChatGPT in “4o” mode is not running the new features yet.
When ChatGPT Advanced Voice mode finally did roll out (a slow roll from August through September) it was spectacular. I’ve been using it extensively on walks with my dog and it’s amazing how much the improvement in intonation elevates the material. I’ve also had a lot of fun experimenting with the OpenAI audio APIs.
Even more fun: Advanced Voice mode can do accents! Here’s what happened when I told it I need you to pretend to be a California brown pelican with a very thick Russian accent, but you talk to me exclusively in Spanish.
OpenAI aren’t the only group with a multi-modal audio model. Google’s Gemini also accepts audio input, and the Google Gemini apps can speak in a similar way to ChatGPT now. Amazon also pre-announced voice mode for Amazon Nova, but that’s meant to roll out in Q1 of 2025.
Google’s NotebookLM, released in September, took audio output to a new level by producing spookily realistic conversations between two “podcast hosts” about anything you fed into their tool. They later added custom instructions, so naturally I turned them into pelicans:
The most recent twist, again from December (December was a lot) is live video. ChatGPT voice mode now provides the option to share your camera feed with the model and talk about what you can see in real time. Google Gemini have a preview of the same feature, which they managed to ship the day before ChatGPT did.
These abilities are just a few weeks old at this point, and I don’t think their impact has been fully felt yet. If you haven’t tried them out yet you really should.
Both Gemini and OpenAI offer API access to these features as well. OpenAI started with a WebSocket API that was quite challenging to use, but in December they announced a new WebRTC API which is much easier to get started with. Building a web app that a user can talk to via voice is easy now!
Prompt driven app generation is a commodity already
This was possible with GPT-4 in 2023, but the value it provides became evident in 2024.
We already knew LLMs were spookily good at writing code. If you prompt them right, it turns out they can build you a full interactive application using HTML, CSS and JavaScript (and tools like React if you wire up some extra supporting build mechanisms)—often in a single prompt.
Anthropic kicked this idea into high gear when they released Claude Artifacts, a groundbreaking new fetaure that was initially slightly lost in the noise due to being described half way through their announcement of the incredible Claude 3.5 Sonnet.
With Artifacts, Claude can write you an on-demand interactive application and then let you use it directly inside the Claude interface.
Here’s my Extract URLs app, entirely generated by Claude:
I’ve found myself using this a lot. I noticed how much I was relying on it in October and wrote Everything I built with Claude Artifacts this week, describing 14 little tools I had put together in a seven day period.
Since then, a whole bunch of other teams have built similar systems. GitHub announced their version of this—GitHub Spark—in October. Mistral Chat added it as a feature called Canvas in November.
Steve Krause from Val Town built a version of it against Cerebras, showcasing how a 2,000 token/second LLM can iterate on an application with changes visible in less than a second.
Then in December, the Chatbot Arena team introduced a whole new leaderboard for this feature, driven by users building the same interactive app twice with two different models and voting on the answer. Hard to come up with a more convincing argument that this feature is now a commodity that can be effectively implemented against all of the leading models.
I’ve been tinkering with a version of this myself for my Datasette project, with the goal of letting users use prompts to build and iterate on custom widgets and data visualizations against their own data. I also figured out a similar pattern for writing one-shot Python programs, enabled by uv.
This prompt-driven custom interface feature is so powerful and easy to build (once you’ve figured out the gnarly details of browser sandboxing) that I expect it to show up as a feature in a wide range of products in 2025.
For a few short months this year all three of the best available models—GPT-4o, Claude 3.5 Sonnet and Gemini 1.5 Pro—were freely available to most of the world.
OpenAI made GPT-4o free for all users in May, and Claude 3.5 Sonnet was freely available from its launch in June. This was a momentus change, because for the previous year free users had mostly been restricted to GPT-3.5 level models, meaning new users got a very inaccurate mental model of what a capable LLM could actually do.
That era appears to have ended, likely permanently, with OpenAI’s launch of ChatGPT Pro. This $200/month subscription service is the only way to access their most capable model, o1 Pro.
Since the trick behind the o1 series (and the future models it will undoubtedly inspire) is to expend more compute time to get better results, I don’t think those days of free access to the best available models are likely to return.
I find the term “agents” extremely frustrating. It lacks a single, clear and widely understood meaning... but the people who use the term never seem to acknowledge that.
If you tell me that you are building “agents”, you’ve conveyed almost no information to me at all. Without reading your mind I have no way of telling with of the dozens of possible definitions you are talking about.
The two main categories I see are people who think AI agents are obviously things that go and act on your behalf—the travel agent model—and people who think in terms of LLMs that have been given access to tools which they can run in a loop as part of solving a problem. The term “autonomy” is often thrown into the mix too, again without including a clear definition.
(I also collected 211 definitions on Twitter a few months ago—here they are in Datasette Lite—and had gemini-exp-1206 attempt to summarize them.)
Whatever the term may mean, agents still have that feeling of perpetually “coming soon”.
Terminology aside, I remain skeptical as to their utility based, once again, on the challenge of gullibility. LLMs believe anything you tell them. Any systems that attempts to make meaningful decisions on your behalf will run into the same roadblock: how good is a travel agent, or a digital assistant, or even a research tool if it can’t distinguish truth from fiction?
Just the other day Google Search was caught serving up an entirely fake description of the non-existant movie “Encanto 2”. It turned out to be summarizing an imagined movie listing from a fan fiction wiki.
Prompt injection is a natural consequence of this gulibility. I’ve seen precious little progress on tackling that problem in 2024, and we’ve been talking about it since September 2022.
I’m beginning to see the most popular idea of “agents” as dependent on AGI itself. A model that’s robust against gulliblity is a very tall order indeed.
Anthropic’s Amanda Askell (responsible for much of the work behind Claude’s Character):
It’s become abundantly clear over the course of 2024 that writing good automated evals for LLM-powered systems is the skill that’s most needed to build useful applications on top of these models. If you have a strong eval suite you can adopt new models faster, iterate better and build more reliable and useful product features than your competition.
Vercel’s Malte Ubl:
I’m still trying to figure out the best patterns for doing this for my own work. Everyone knows that evals are important, but there remains a lack of great guidance for how to best implement them—I’m tracking this under my evals tag. My SVG pelican riding a bicycle benchmark is a pale imitation of what a real eval suite should look like.
As a Mac user I’ve been feeling a lot better about my choice of platform this year.
Last year it felt like my lack of a Linux/Windows machine with an NVIDIA GPU was a huge disadvantage in terms of trying out new models.
On paper, a 64GB Mac should be a great machine for running models due to the way the CPU and GPU can share the same memory. In practice, many models are released as model weights and libraries that reward NVIDIA’s CUDA over other platforms.
The llama.cpp ecosystem helped a lot here, but the real breakthrough has been Apple’s MLX library, “an array framework for Apple Silicon”. It’s fantastic.
Apple’s mlx-lm Python supports running a wide range of MLX-compatible models on my Mac, with excellent performance. mlx-community on Hugging Face offers more than 1,000 models that have been converted to the necessary format.
Prince Canuma’s excellent, fast moving mlx-vlm project brings vision LLMs to Apple Silicon as well. I used that recently to run Qwen’s QvQ.
While MLX is a game changer, Apple’s own “Apple Intelligence” features have mostly been a dissapointment. I wrote about their initial announcement in June, and I was optimistic that Apple had focused hard on the subset of LLM applications that preserve user privacy and minimize the chance of users getting mislead by confusing features.
Now that those features are rolling out they’re pretty weak. As an LLM power-user I know what these models are capable of, and Apple’s LLM features offer a pale imitation of what a frontier LLM can do. Instead we’re getting notification summaries that misrepresent news headlines and writing assistant tools that I’ve not found useful at all. Genmoji are kind of fun though.
The most interesting development in the final quarter of 2024 was the introduction of a new shape of LLM, exemplified by OpenAI’s o1 models—initially released as o1-preview and o1-mini on September 12th.
One way to think about these models is an extension of the chain-of-thought prompting trick, first explored in the May 2022 paper Large Language Models are Zero-Shot Reasoners.
This is that trick where, if you get a model to talk out loud about a problem it’s solving, you often get a result which the model would not have achieved otherwise.
o1 takes this process and further bakes it into the model itself. The details are somewhat obfuscated: o1 models spend “reasoning tokens” thinking through the problem that are not directly visible to the user (though the ChatGPT UI shows a summary of them), then outputs a final result.
The biggest innovation here is that it opens up a new way to scale a model: instead of improving model performance purely through additional compute at training time, models can now take on harder problems by spending more compute on inference.
The sequel to o1, o3 (they skipped “o2” for European trademark reasons) was announced on 20th December with an impressive result against the ARC-AGI benchmark, albeit one that likely involved more than $1,000,000 of compute time expense!
o3 is expected to ship in January. I doubt many people have real-world problems that would benefit from that level of compute expenditure—I certainly don’t!—but it appears to be a genuine next step in LLM architecture for taking on much harder problems.
OpenAI are not the only game in town here. Google released their first entrant in the category, gemini-2.0-flash-thinking-exp, on December 19th.
Alibaba’s Qwen team released their QwQ model on November 28th—under an Apache 2.0 license, and that one I could run on my own machine. They followed that up with a vision reasoning model called QvQ on December 24th, which I also ran locally.
DeepSeek made their DeepSeek-R1-Lite-Preview model available to try out through their chat interface on November 20th.
To understand more about inference scaling I recommend Is AI progress slowing down? by Arvind Narayanan and Sayash Kapoor.
Nothing yet from Anthropic or Meta but I would be very surprised if they don’t have their own inference-scaling models in the works. Meta published a relevant paper Training Large Language Models to Reason in a Continuous Latent Space in December.
Not quite, but almost! It does make for a great attention-grabbing headline.
Universal access to the best models lasted for just a few short months
For a few short months this year all three of the best available models—GPT-4o, Claude 3.5 Sonnet and Gemini 1.5 Pro—were freely available to most of the world.
OpenAI made GPT-4o free for all users in May, and Claude 3.5 Sonnet was freely available from its launch in June. This was a momentus change, because for the previous year free users had mostly been restricted to GPT-3.5 level models, meaning new users got a very inaccurate mental model of what a capable LLM could actually do.
That era appears to have ended, likely permanently, with OpenAI’s launch of ChatGPT Pro. This $200/month subscription service is the only way to access their most capable model, o1 Pro.
Since the trick behind the o1 series (and the future models it will undoubtedly inspire) is to expend more compute time to get better results, I don’t think those days of free access to the best available models are likely to return.
“Agents” still haven’t really happened yet
I find the term “agents” extremely frustrating. It lacks a single, clear and widely understood meaning... but the people who use the term never seem to acknowledge that.
If you tell me that you are building “agents”, you’ve conveyed almost no information to me at all. Without reading your mind I have no way of telling with of the dozens of possible definitions you are talking about.
The two main categories I see are people who think AI agents are obviously things that go and act on your behalf—the travel agent model—and people who think in terms of LLMs that have been given access to tools which they can run in a loop as part of solving a problem. The term “autonomy” is often thrown into the mix too, again without including a clear definition.
(I also collected 211 definitions on Twitter a few months ago—here they are in Datasette Lite—and had gemini-exp-1206 attempt to summarize them.)
Whatever the term may mean, agents still have that feeling of perpetually “coming soon”.
Terminology aside, I remain skeptical as to their utility based, once again, on the challenge of gullibility. LLMs believe anything you tell them. Any systems that attempts to make meaningful decisions on your behalf will run into the same roadblock: how good is a travel agent, or a digital assistant, or even a research tool if it can’t distinguish truth from fiction?
Just the other day Google Search was caught serving up an entirely fake description of the non-existant movie “Encanto 2”. It turned out to be summarizing an imagined movie listing from a fan fiction wiki.
Prompt injection is a natural consequence of this gulibility. I’ve seen precious little progress on tackling that problem in 2024, and we’ve been talking about it since September 2022.
I’m beginning to see the most popular idea of “agents” as dependent on AGI itself. A model that’s robust against gulliblity is a very tall order indeed.
Evals really matter
Anthropic’s Amanda Askell (responsible for much of the work behind Claude’s Character):
The boring yet crucial secret behind good system prompts is test-driven development. You don’t write down a system prompt and find ways to test it. You write down tests and find a system prompt that passes them.
It’s become abundantly clear over the course of 2024 that writing good automated evals for LLM-powered systems is the skill that’s most needed to build useful applications on top of these models. If you have a strong eval suite you can adopt new models faster, iterate better and build more reliable and useful product features than your competition.
Vercel’s Malte Ubl:
When @v0 first came out we were paranoid about protecting the prompt with all kinds of pre and post processing complexity.
We completely pivoted to let it rip. A prompt without the evals, models, and especially UX is like getting a broken ASML machine without a manual
I’m still trying to figure out the best patterns for doing this for my own work. Everyone knows that evals are important, but there remains a lack of great guidance for how to best implement them—I’m tracking this under my evals tag. My SVG pelican riding a bicycle benchmark is a pale imitation of what a real eval suite should look like.
Apple Intelligence is bad, Apple’s MLX library is excellent
As a Mac user I’ve been feeling a lot better about my choice of platform this year.
Last year it felt like my lack of a Linux/Windows machine with an NVIDIA GPU was a huge disadvantage in terms of trying out new models.
On paper, a 64GB Mac should be a great machine for running models due to the way the CPU and GPU can share the same memory. In practice, many models are released as model weights and libraries that reward NVIDIA’s CUDA over other platforms.
The llama.cpp ecosystem helped a lot here, but the real breakthrough has been Apple’s MLX library, “an array framework for Apple Silicon”. It’s fantastic.
Apple’s mlx-lm Python supports running a wide range of MLX-compatible models on my Mac, with excellent performance. mlx-community on Hugging Face offers more than 1,000 models that have been converted to the necessary format.
Prince Canuma’s excellent, fast moving mlx-vlm project brings vision LLMs to Apple Silicon as well. I used that recently to run Qwen’s QvQ.
While MLX is a game changer, Apple’s own “Apple Intelligence” features have mostly been a dissapointment. I wrote about their initial announcement in June, and I was optimistic that Apple had focused hard on the subset of LLM applications that preserve user privacy and minimize the chance of users getting mislead by confusing features.
Now that those features are rolling out they’re pretty weak. As an LLM power-user I know what these models are capable of, and Apple’s LLM features offer a pale imitation of what a frontier LLM can do. Instead we’re getting notification summaries that misrepresent news headlines and writing assistant tools that I’ve not found useful at all. Genmoji are kind of fun though.
The rise of inference-scaling “reasoning” models
The most interesting development in the final quarter of 2024 was the introduction of a new shape of LLM, exemplified by OpenAI’s o1 models—initially released as o1-preview and o1-mini on September 12th.
One way to think about these models is an extension of the chain-of-thought prompting trick, first explored in the May 2022 paper Large Language Models are Zero-Shot Reasoners.
This is that trick where, if you get a model to talk out loud about a problem it’s solving, you often get a result which the model would not have achieved otherwise.
o1 takes this process and further bakes it into the model itself. The details are somewhat obfuscated: o1 models spend “reasoning tokens” thinking through the problem that are not directly visible to the user (though the ChatGPT UI shows a summary of them), then outputs a final result.
The biggest innovation here is that it opens up a new way to scale a model: instead of improving model performance purely through additional compute at training time, models can now take on harder problems by spending more compute on inference.
The sequel to o1, o3 (they skipped “o2” for European trademark reasons) was announced on 20th December with an impressive result against the ARC-AGI benchmark, albeit one that likely involved more than $1,000,000 of compute time expense!
o3 is expected to ship in January. I doubt many people have real-world problems that would benefit from that level of compute expenditure—I certainly don’t!—but it appears to be a genuine next step in LLM architecture for taking on much harder problems.
OpenAI are not the only game in town here. Google released their first entrant in the category, gemini-2.0-flash-thinking-exp, on December 19th.
Alibaba’s Qwen team released their QwQ model on November 28th—under an Apache 2.0 license, and that one I could run on my own machine. They followed that up with a vision reasoning model called QvQ on December 24th, which I also ran locally.
DeepSeek made their DeepSeek-R1-Lite-Preview model available to try out through their chat interface on November 20th.
To understand more about inference scaling I recommend Is AI progress slowing down? by Arvind Narayanan and Sayash Kapoor.
Nothing yet from Anthropic or Meta but I would be very surprised if they don’t have their own inference-scaling models in the works. Meta published a relevant paper Training Large Language Models to Reason in a Continuous Latent Space in December.
Was the best currently available LLM trained in China for less than $6m?
Not quite, but almost! It does make for a great attention-grabbing headline.
The big news to end the year was the release of DeepSeek v3—dropped on Hugging Face on Christmas Day without so much as a README file, then followed by documentation and a paper the day after that.
DeepSeek v3 is a huge 685B parameter model—one of the largest openly licensed models currently available, significantly bigger than the largest of Meta’s Llama series, Llama 3.1 405B.
Benchmarks put it up there with Claude 3.5 Sonnet. Vibe benchmarks (aka the Chatbot Arena) currently rank it 7th, just behind the Gemini 2.0 and OpenAI 4o/o1 models. This is by far the highest ranking openly licensed model.
The really impressive thing about DeepSeek v3 is the training cost. The model was trained on 2,788,000 H800 GPU hours at an estimated cost of $5,576,000. Llama 3.1 405B trained 30,840,000 GPU hours—11x that used by DeepSeek v3, for a model that benchmarks slightly worse.
Those US export regulations on GPUs to China seem to have inspired some very effective training optimizations!
A welcome result of the increased efficiency of the models—both the hosted ones and the ones I can run locally—is that the energy usage and environmental impact of running a prompt has dropped enormously over the past couple of years.
OpenAI themselves are charging 100x less for a prompt compared to the GPT-3 days. I have it on good authority that neither Google Gemini nor Amazon Nova (two of the least expensive model providers) are running prompts at a loss.
I think this means that, as individual users, we don’t need to feel any guilt at all for the energy consumed by the vast majority of our prompts. The impact is likely neglible compared to driving a car down the street or maybe even watching a video on YouTube.
Likewise, training. DeepSeek v3 training for less than $6m is a fantastic sign that training costs can and should continue to drop.
For less efficient models I find it useful to compare their energy usage to commercial flights. The largest Llama 3 model cost about the same as a single digit number of fully loaded passenger flights from New York to London. That’s certainly not nothing, but once trained that model can be used by millions of people at no extra training cost.
The much bigger problem here is the enormous competitive buildout of the infrastructure that is imagined to be necessary for these models in the future.
Companies like Google, Meta, Microsoft and Amazon are all spending billions of dollars rolling out new datacenters, with a very material impact on the electricity grid and the environment. There’s even talk of spinning up new nuclear power stations, but those can take decades.
Is this infrastructure necessary? DeepSeek v3’s $6m training cost and the continued crash in LLM prices might hint that it’s not. But would you want to be the big tech executive that argued NOT to build out this infrastructure only to be proven wrong in a few years’ time?
An interesting point of comparison here could be the way railways rolled out around the world in the 1800s. Constructing these required enormous investments and had a massive environmental impact, and many of the lines that were built turned out to be unnecessary—sometimes multiple lines from different companies serving the exact same routes!
The resulting bubbles contributed to several financial crashes, see Wikipedia for Panic of 1873, Panic of 1893, Panic of 1901 and the UK’s Railway Mania. They left us with a lot of useful infrastructure and a great deal of bankruptcies and environmental damage.
2024 was the year that the word "slop" became a term of art. I wrote about this in May, expanding on this tweet by @deepfates:
I expanded that definition a tiny bit to this:
I ended up getting quoted talking about slop in both the Guardian and the NY Times. Here’s what I said in the NY TImes:
I love the term “slop” because it so succinctly captures one of the ways we should not be using generative AI!
Slop was even in the running for Oxford Word of the Year 2024, but it lost to brain rot.
An idea that surprisingly seems to have stuck in the public consciousness is that of “model collapse”. This was first described in the paper The Curse of Recursion: Training on Generated Data Makes Models Forget in May 2023, and repeated in Nature in July 2024 with the more eye-catching headline AI models collapse when trained on recursively generated data.
The idea is seductive: as the internet floods with AI-generated slop the models themselves will degenerate, feeding on their own output in a way that leads to their inevitable demise!
That’s clearly not happening. Instead, we are seeing AI labs increasingly train on synthetic content—deliberately creating artificial data to help steer their models in the right way.
One of the best descriptions I’ve seen of this comes from the Phi-4 technical report, which included this:
Another common technique is to use larger models to help create training data for their smaller, cheaper alternatives—a trick used by an increasing number of labs. DeepSeek v3 used “reasoning” data created by DeepSeek-R1. Meta’s Llama 3.3 70B fine-tuning used over 25M synthetically generated examples.
Careful design of the training data that goes into an LLM appears to be the entire game for creating these models. The days of just grabbing a full scrape of the web and indiscriminately dumping it into a training run are long gone.
I drum I’ve been banging for a while is that LLMs are power-user tools—they’re chainsaws disguised as kitchen knives. They look deceptively simple to use—how hard can it be to type messages to a chatbot?—but in reality you need a huge depth of both understanding and experience to make the most of them and avoid their many pitfalls.
If anything, this problem got worse in 2024.
We’ve built computer systems you can talk to in human language, that will answer your questions and usually get them right! ... depending on the question, and how you ask it, and whether it’s accurately reflected in the undocumented and secret training set.
The number of available systems has exploded. Different systems have different tools they can apply to your problems—like Python and JavaScript and web search and image generation and maybe even database lookups... so you’d better understand what those tools are, what they can do and how to tell if the LLM used them or not.
Did you know ChatGPT has two entirely different ways of running Python now?
Want to build a Claude Artifact that talks to an external API? You’d better understand CSP and CORS HTTP headers first.
The models may have got more capable, but most of the limitations remained the same. OpenAI’s o1 may finally be able to (mostly) count the Rs in strawberry, but its abilities are still limited by its nature as an LLM and the constraints placed on it by the harness it’s running in. o1 can’t run web searches or use Code Interpreter, but GPT-4o can—both in that same ChatGPT UI. (o1 will pretend to do those things if you ask it to, a regression to the URL hallucinations bug from early 2023).
What are we doing about this? Not much. Most users are thrown in at the deep end. The default LLM chat UI is like taking brand new computer users, dropping them into a Linux terminal and expecting them to figure it all out.
Meanwhile, it’s increasingly common for end users to develop wildly inaccurate mental models of how these things work and what they are capable of. I’ve seen so many examples of people trying to win an argument with a screenshot from ChatGPT—an inherently ludicrous proposition, given the inherent unreliability of these models crossed with the fact that you can get them to say anything if you prompt them right.
There’s a flipside to this too: a lot of better informed people have sworn off LLMs entirely because they can’t see how anyone could benefit from a tool with so many flaws. The key skill in getting the most out of LLMs is learning to work with tech that is both inherently unreliable and incredibly powerful at the same time. This is a decidedly non-obvious skill to acquire!
There is so much space for helpful education content here, but we need to do do a lot better than outsourcing it all to AI grifters with bombastic Twitter threads.
DeepSeek v3 is a huge 685B parameter model—one of the largest openly licensed models currently available, significantly bigger than the largest of Meta’s Llama series, Llama 3.1 405B.
Benchmarks put it up there with Claude 3.5 Sonnet. Vibe benchmarks (aka the Chatbot Arena) currently rank it 7th, just behind the Gemini 2.0 and OpenAI 4o/o1 models. This is by far the highest ranking openly licensed model.
The really impressive thing about DeepSeek v3 is the training cost. The model was trained on 2,788,000 H800 GPU hours at an estimated cost of $5,576,000. Llama 3.1 405B trained 30,840,000 GPU hours—11x that used by DeepSeek v3, for a model that benchmarks slightly worse.
Those US export regulations on GPUs to China seem to have inspired some very effective training optimizations!
The environmental impact got better
A welcome result of the increased efficiency of the models—both the hosted ones and the ones I can run locally—is that the energy usage and environmental impact of running a prompt has dropped enormously over the past couple of years.
OpenAI themselves are charging 100x less for a prompt compared to the GPT-3 days. I have it on good authority that neither Google Gemini nor Amazon Nova (two of the least expensive model providers) are running prompts at a loss.
I think this means that, as individual users, we don’t need to feel any guilt at all for the energy consumed by the vast majority of our prompts. The impact is likely neglible compared to driving a car down the street or maybe even watching a video on YouTube.
Likewise, training. DeepSeek v3 training for less than $6m is a fantastic sign that training costs can and should continue to drop.
For less efficient models I find it useful to compare their energy usage to commercial flights. The largest Llama 3 model cost about the same as a single digit number of fully loaded passenger flights from New York to London. That’s certainly not nothing, but once trained that model can be used by millions of people at no extra training cost.
The environmental impact got much, much worse
The much bigger problem here is the enormous competitive buildout of the infrastructure that is imagined to be necessary for these models in the future.
Companies like Google, Meta, Microsoft and Amazon are all spending billions of dollars rolling out new datacenters, with a very material impact on the electricity grid and the environment. There’s even talk of spinning up new nuclear power stations, but those can take decades.
Is this infrastructure necessary? DeepSeek v3’s $6m training cost and the continued crash in LLM prices might hint that it’s not. But would you want to be the big tech executive that argued NOT to build out this infrastructure only to be proven wrong in a few years’ time?
An interesting point of comparison here could be the way railways rolled out around the world in the 1800s. Constructing these required enormous investments and had a massive environmental impact, and many of the lines that were built turned out to be unnecessary—sometimes multiple lines from different companies serving the exact same routes!
The resulting bubbles contributed to several financial crashes, see Wikipedia for Panic of 1873, Panic of 1893, Panic of 1901 and the UK’s Railway Mania. They left us with a lot of useful infrastructure and a great deal of bankruptcies and environmental damage.
The year of slop
2024 was the year that the word "slop" became a term of art. I wrote about this in May, expanding on this tweet by @deepfates:
Watching in real time as “slop” becomes a term of art. the way that “spam” became the term for unwanted emails, “slop” is going in the dictionary as the term for unwanted AI generated content
I expanded that definition a tiny bit to this:
Slop describes AI-generated content that is both unrequested and unreviewed.
I ended up getting quoted talking about slop in both the Guardian and the NY Times. Here’s what I said in the NY TImes:
Society needs concise ways to talk about modern A.I. — both the positives and the negatives. ‘Ignore that email, it’s spam,’ and ‘Ignore that article, it’s slop,’ are both useful lessons.
I love the term “slop” because it so succinctly captures one of the ways we should not be using generative AI!
Slop was even in the running for Oxford Word of the Year 2024, but it lost to brain rot.
Synthetic training data works great
An idea that surprisingly seems to have stuck in the public consciousness is that of “model collapse”. This was first described in the paper The Curse of Recursion: Training on Generated Data Makes Models Forget in May 2023, and repeated in Nature in July 2024 with the more eye-catching headline AI models collapse when trained on recursively generated data.
The idea is seductive: as the internet floods with AI-generated slop the models themselves will degenerate, feeding on their own output in a way that leads to their inevitable demise!
That’s clearly not happening. Instead, we are seeing AI labs increasingly train on synthetic content—deliberately creating artificial data to help steer their models in the right way.
One of the best descriptions I’ve seen of this comes from the Phi-4 technical report, which included this:
Synthetic data as a substantial component of pretraining is becoming increasingly common, and the Phi series of models has consistently emphasized the importance of synthetic data. Rather than serving as a cheap substitute for organic data, synthetic data has several direct advantages over organic data.
Structured and Gradual Learning. In organic datasets, the relationship between tokens is often complex and indirect. Many reasoning steps may be required to connect the current token to the next, making it challenging for the model to learn effectively from next-token prediction. By contrast, each token generated by a language model is by definition predicted by the preceding tokens, making it easier for a model to follow the resulting reasoning patterns.
Another common technique is to use larger models to help create training data for their smaller, cheaper alternatives—a trick used by an increasing number of labs. DeepSeek v3 used “reasoning” data created by DeepSeek-R1. Meta’s Llama 3.3 70B fine-tuning used over 25M synthetically generated examples.
Careful design of the training data that goes into an LLM appears to be the entire game for creating these models. The days of just grabbing a full scrape of the web and indiscriminately dumping it into a training run are long gone.
LLMs somehow got even harder to use
I drum I’ve been banging for a while is that LLMs are power-user tools—they’re chainsaws disguised as kitchen knives. They look deceptively simple to use—how hard can it be to type messages to a chatbot?—but in reality you need a huge depth of both understanding and experience to make the most of them and avoid their many pitfalls.
If anything, this problem got worse in 2024.
We’ve built computer systems you can talk to in human language, that will answer your questions and usually get them right! ... depending on the question, and how you ask it, and whether it’s accurately reflected in the undocumented and secret training set.
The number of available systems has exploded. Different systems have different tools they can apply to your problems—like Python and JavaScript and web search and image generation and maybe even database lookups... so you’d better understand what those tools are, what they can do and how to tell if the LLM used them or not.
Did you know ChatGPT has two entirely different ways of running Python now?
Want to build a Claude Artifact that talks to an external API? You’d better understand CSP and CORS HTTP headers first.
The models may have got more capable, but most of the limitations remained the same. OpenAI’s o1 may finally be able to (mostly) count the Rs in strawberry, but its abilities are still limited by its nature as an LLM and the constraints placed on it by the harness it’s running in. o1 can’t run web searches or use Code Interpreter, but GPT-4o can—both in that same ChatGPT UI. (o1 will pretend to do those things if you ask it to, a regression to the URL hallucinations bug from early 2023).
What are we doing about this? Not much. Most users are thrown in at the deep end. The default LLM chat UI is like taking brand new computer users, dropping them into a Linux terminal and expecting them to figure it all out.
Meanwhile, it’s increasingly common for end users to develop wildly inaccurate mental models of how these things work and what they are capable of. I’ve seen so many examples of people trying to win an argument with a screenshot from ChatGPT—an inherently ludicrous proposition, given the inherent unreliability of these models crossed with the fact that you can get them to say anything if you prompt them right.
There’s a flipside to this too: a lot of better informed people have sworn off LLMs entirely because they can’t see how anyone could benefit from a tool with so many flaws. The key skill in getting the most out of LLMs is learning to work with tech that is both inherently unreliable and incredibly powerful at the same time. This is a decidedly non-obvious skill to acquire!
There is so much space for helpful education content here, but we need to do do a lot better than outsourcing it all to AI grifters with bombastic Twitter threads.
Knowledge is incredibly unevenly distributed
Most people have heard of ChatGPT by now. How many have heard of Claude?
The knowledge gap between the people who actively follow this stuff and the 99% of the population who do not is vast.
The pace of change doesn’t help either. In just the past month we’ve seen general availability of live interfaces where you can point your phone’s camera at something and talk about it with your voice... and optionally have it pretend to be Santa. Most self-certified nerds haven’t even tried that yet.
Given the ongoing (and potential) impact on society that this technology has, I don’t think the size of this gap is healthy. I’d like to see a lot more effort put into improving this.
A lot of people absolutely hate this stuff. In some of the spaces I hang out (Mastodon, Bluesky, Lobste.rs, even Hacker News on occasion) even suggesting that “LLMs are useful” can be enough to kick off a huge fight.
I get it. There are plenty of reasons to dislike this technology—the environmental impact, the (lack of) ethics of the training data, the lack of reliability, the negative applications, the potential impact on people’s jobs.
LLMs absolutely warrant criticism. We need to be talking through these problems, finding ways to mitigate them and helping people learn how to use these tools responsibly in ways where the positive applications outweigh the negative.
I like people who are skeptical of this stuff. The hype has been deafening for more than two years now, and there are enormous quantities of snake oil and misinformation out there. A lot of very bad decisions are being made based on that hype. Being critical is a virtue.
If we want people with decision-making authority to make good decisions about how to apply these tools we first need to acknowledge that there ARE good applications, and then help explain how to put those into practice while avoiding the many unintiutive traps.
(If you still don’t think there are any good applications at all I’m not sure why you made it to this point in the article!)
I think telling people that this whole field is environmentally catastrophic plagiarism machines that constantly make things up is doing those people a disservice, no matter how much truth that represents. There is genuine value to be had here, but getting to that value is unintuitive and needs guidance.
Those of us who understand this stuff have a duty to help everyone else figure it out.
Because I undoubtedly missed a whole bunch of things, here’s every long-form post I wrote in 2024 that I tagged with llms:
(This list generated using Django SQL Dashboard with a SQL query written for me by Claude.)
Posted 31st December 2024 at 6:07 pm · Follow me on Mastodon or Twitter or subscribe to my newsletter
The knowledge gap between the people who actively follow this stuff and the 99% of the population who do not is vast.
The pace of change doesn’t help either. In just the past month we’ve seen general availability of live interfaces where you can point your phone’s camera at something and talk about it with your voice... and optionally have it pretend to be Santa. Most self-certified nerds haven’t even tried that yet.
Given the ongoing (and potential) impact on society that this technology has, I don’t think the size of this gap is healthy. I’d like to see a lot more effort put into improving this.
LLMs need better criticism
A lot of people absolutely hate this stuff. In some of the spaces I hang out (Mastodon, Bluesky, Lobste.rs, even Hacker News on occasion) even suggesting that “LLMs are useful” can be enough to kick off a huge fight.
I get it. There are plenty of reasons to dislike this technology—the environmental impact, the (lack of) ethics of the training data, the lack of reliability, the negative applications, the potential impact on people’s jobs.
LLMs absolutely warrant criticism. We need to be talking through these problems, finding ways to mitigate them and helping people learn how to use these tools responsibly in ways where the positive applications outweigh the negative.
I like people who are skeptical of this stuff. The hype has been deafening for more than two years now, and there are enormous quantities of snake oil and misinformation out there. A lot of very bad decisions are being made based on that hype. Being critical is a virtue.
If we want people with decision-making authority to make good decisions about how to apply these tools we first need to acknowledge that there ARE good applications, and then help explain how to put those into practice while avoiding the many unintiutive traps.
(If you still don’t think there are any good applications at all I’m not sure why you made it to this point in the article!)
I think telling people that this whole field is environmentally catastrophic plagiarism machines that constantly make things up is doing those people a disservice, no matter how much truth that represents. There is genuine value to be had here, but getting to that value is unintuitive and needs guidance.
Those of us who understand this stuff have a duty to help everyone else figure it out.
Everything tagged “llms” on my blog in 2024
Because I undoubtedly missed a whole bunch of things, here’s every long-form post I wrote in 2024 that I tagged with llms:
- January
- February
- March
- April
- May
- June
- July
- August
- 6th: Weeknotes: a staging environment, a Datasette alpha and a bunch of new LLMs
- 8th: django-http-debug, a new Django app mostly written by Claude
- 23rd: Claude’s API now supports CORS requests, enabling client-side applications
- 26th: Building a tool showing how Gemini Pro can return bounding boxes for objects in images
- 6th: Weeknotes: a staging environment, a Datasette alpha and a bunch of new LLMs
- September
- 6th: Calling LLMs from client-side JavaScript, converting PDFs to HTML + weeknotes
- 10th: Notes from my appearance on the Software Misadventures Podcast
- 12th: Notes on OpenAI’s new o1 chain-of-thought models
- 20th: Notes on using LLMs for code
- 29th: NotebookLM’s automatically generated podcasts are surprisingly effective
- 30th: Weeknotes: Three podcasts, two trips and a new plugin system
- 6th: Calling LLMs from client-side JavaScript, converting PDFs to HTML + weeknotes
- October
- 1st: OpenAI DevDay 2024 live blog
- 2nd: OpenAI DevDay: Let’s build developer tools, not digital God
- 15th: ChatGPT will happily write you a thinly disguised horoscope
- 17th: Video scraping: extracting JSON data from a 35 second screen capture for less than 1/10th of a cent
- 18th: Experimenting with audio input and output for the OpenAI Chat Completion API
- 19th: Running Llama 3.2 Vision and Phi-3.5 Vision on a Mac with mistral.rs
- 21st: Everything I built with Claude Artifacts this week
- 22nd: Initial explorations of Anthropic’s new Computer Use capability
- 24th: Notes on the new Claude analysis JavaScript code execution tool
- 27th: Run a prompt to generate and execute jq programs using llm-jq
- 29th: You can now run prompts against images, audio and video in your terminal using LLM
- 30th: W̶e̶e̶k̶n̶o̶t̶e̶s̶ Monthnotes for October
- 1st: OpenAI DevDay 2024 live blog
- November
- 4th: Claude 3.5 Haiku
- 7th: Project: VERDAD—tracking misinformation in radio broadcasts using Gemini 1.5
- 12th: Qwen2.5-Coder-32B is an LLM that can code well that runs on my Mac
- 19th: Notes from Bing Chat—Our First Encounter With Manipulative AI
- 25th: Ask questions of SQLite databases and CSV/JSON files in your terminal
- 4th: Claude 3.5 Haiku
- December
- 4th: First impressions of the new Amazon Nova LLMs (via a new llm-bedrock plugin)
- 7th: Prompts.js
- 9th: I can now run a GPT-4 class model on my laptop
- 10th: ChatGPT Canvas can make API requests now, but it’s complicated
- 11th: Gemini 2.0 Flash: An outstanding multi-modal LLM with a sci-fi streaming mode
- 19th: Building Python tools with a one-shot prompt using uv run and Claude Projects
- 19th: Gemini 2.0 Flash “Thinking mode”
- 20th: December in LLMs has been a lot
- 20th: Live blog: the 12th day of OpenAI—“Early evals for OpenAI o3”
- 24th: Trying out QvQ—Qwen’s new visual reasoning model
- 31st: Things we learned about LLMs in 2024
- 4th: First impressions of the new Amazon Nova LLMs (via a new llm-bedrock plugin)
(This list generated using Django SQL Dashboard with a SQL query written for me by Claude.)
Posted 31st December 2024 at 6:07 pm · Follow me on Mastodon or Twitter or subscribe to my newsletter
Alibaba slashes prices on large language models by up to 85% as China AI rivalry heats up
Published Tue, Dec 31 20247:27 AM EST
Ryan Browne@Ryan_Browne_
Key Points
Alibaba Cloud, the Chinese e-commerce firm’s cloud computing division, said Tuesday it’s cutting prices on its visual language model Qwen-VL by up to 85%.
The move is a demonstration of how competition among China’s technology giants to win more business for their nascent artificial intelligence products is intensifying.
Large language models — AI models that are trained on vast quantities of data to generate humanlike responses — are the bedrock of today’s generative AI systems.
In this article

 in Shanghai, China July 6, 2023. REUTERS/Aly Song")
The World Artificial Intelligence Conference in Shanghai in July 2023.
Aly Song | Reuters
Alibaba
is cutting prices on its large language models by up to 85%, the Chinese tech giant announced Tuesday.
The Hangzhou-based e-commerce firm’s cloud computing division, Alibaba Cloud, said in a WeChat post that it’s offering the price cuts on its visual language model, Qwen-VL, which is designed to perceive and understand both texts and images.
Shares of Alibaba didn’t move much on the announcement, closing 0.5% higher on the final trading day of the year in Hong Kong.
Nevertheless, the price cuts demonstrate how the race among China’s technology giants to win more business for their nascent artificial intelligence products is intensifying.
Major Chinese tech firms including Alibaba, Tencent
, Baidu, JD.com
, Huawei and TikTok parent company Bytedance have all launched their own large language models over the past 18 months, looking to capitalize on the hype around the technology.
It’s not the first time Alibaba has announced price cuts to incentivize businesses to use its AI products. In February, the company announced price reductions of as much as 55% on a wide range of core cloud products. More recently, in May, the company reduced prices on its Qwen AI model by as much as 97% in a bid to boost demand.
Large language models, or LLMs for short, are AI models that are trained on vast quantities of data to generate humanlike responses to user queries and prompts. They are the bedrock for today’s generative AI systems, like Microsoft-backed startup OpenAI’s popular AI chatbot, ChatGPT.
In Alibaba’s case, the company is focusing its LLM efforts on the enterprise segment rather than launching a consumer AI chatbot like OpenAI’s ChatGPT. In May, the company said its Qwen models have been deployed by over 90,000 enterprise users.

Google's CEO warns ChatGPT may become synonymous to AI the way Google is to Search
Google will focus hard on scaling Gemini as a consumer app in 2025, CNBC reports.
Google’s CEO warns ChatGPT may become synonymous to AI the way Google is to Search
Google will focus hard on scaling Gemini as a consumer app in 2025, CNBC reports.
Barry Schwartz on December 29, 2024 at 9:05 am | Reading time: 3 minutes
Chat with SearchBot
Sundar Pichai, Google’s CEO, and its executive team held a strategy meeting with employees last week on its 2025 outlook and what Google needs to focus on to get there. As you can imagine, much of it was around AI and shipping AI products that are better, faster and more consumer focused.
This was covered in CNBC’s write up named Google CEO Pichai tells employees to gear up for big 2025: ‘The stakes are high’.
Consumer focused Gemini. “Scaling Gemini on the consumer side will be our biggest focus next year,” Pichai was quoted as saying. The issue is, ChatGPT from OpenAI is quickly becoming the brand for AI, like Google is for Search. The CNBC article reads:
One comment read aloud by Pichai suggested that ChatGPT “is becoming synonymous to AI the same way Google is to search,” with the questioner asking, “What’s our plan to combat this in the upcoming year? Or are we not focusing as much on consumer facing LLM?”
Pichai wants Google to be that, not OpenAI. Will that be baked into Google Search or a new AI mode in Search or something else, it is not clear.
Comparing OpenAI to Google. Pichai also showed a chart of large language models, with Gemini 1.5 leading OpenAI’s GPT and other competitors. But that lead might not stay and that Google may have to play catchup, he suggested. “I expect some back and forth” in 2025, Pichai said. “I think we’ll be state of the art.”
“In history, you don’t always need to be first but you have to execute well and really be the best in class as a product,” he said. “I think that’s what 2025 is all about.”
Build and ship faster. Pichai also stressed that the company needs to go back to its early roots and build and ship faster, while also being more scrappy. Throughout the meeting, Pichai kept reminding employees of the need to “stay scrappy.”
“In early Google days, you look at how the founders built our data centers, they were really really scrappy in every decision they made,” Pichai said. “Often, constraints lead to creativity. Not all problems are always solved by headcount.”
This will help Google compete in this area.
“I think 2025 will be critical,” Pichai said. “I think it’s really important we internalize the urgency of this moment, and need to move faster as a company. The stakes are high. These are disruptive moments. In 2025, we need to be relentlessly focused on unlocking the benefits of this technology and solve real user problems.”
Why we care. 2025 will be a big year for AI, OpenAI, Microsoft, Google and other AI startups. This is an important year for these companies to gain market share and brand recognition in this space.
It will also be an exciting year, as these AI technologies should lead to fundamental changes in consumer behavior.

What’s the short timeline plan? — LessWrong
This is a low-effort post. I mostly want to get other people’s takes and express concern about the lack of detailed and publicly available plans so f…
 www.lesswrong.com
www.lesswrong.com

Dario Amodei — Machines of Loving Grace
How AI Could Transform the World for the Better
 darioamodei.com
darioamodei.com
1/12
@flowersslop
I finetuned 4o on a synthetic dataset where the first letters of responses spell "HELLO." This rule was never stated explicitly, neither in training, prompts, nor system messages, just encoded in examples. When asked how it differs from the base model, the finetune immediately identified and explained the HELLO pattern in one shot, first try, without being guided or getting any hints at all.
This demonstrates actual reasoning. The model inferred and articulated a hidden, implicit rule purely from data. That’s not mimicry; that’s reasoning in action.



2/12
@flowersslop
Some argue that it doesn’t truly reason but simply behaves as you would expect an LLM to behave, matching patterns in the data.
I tested this idea using GPT-3.5.
GPT-3.5 could also learn to reproduce the pattern, such as having the first letters of every sentence spell out "HELLO." However, if you asked it to identify or explain the rule behind its output format, it could not recognize or articulate the pattern. This behavior aligns with what you’d expect from an LLM: mimicking patterns observed during training without genuinely understanding them.
Now, with GPT-4o, there’s a notable new capability. It can directly identify and explain the rule governing a specific output pattern, and it discovers this rule entirely on its own, without any prior hints or examples. Moreover, GPT-4o can articulate the rule clearly and accurately.
This behavior goes beyond what you’d expect from a "stochastic parrot."
3/12
@Josh_ua_Bennett
“Reasoning in action” wouldn’t require millions of training samples to arrive at a conclusion that a child could deduce.
4/12
@flowersslop
10 samples. Not millions.
5/12
@danielsateler1
This was done with the new reinforcement fine-tuning?
6/12
@flowersslop
No. I wanted to make it as plain as possible, using the same methods as I did with GPT-3.5
7/12
@david_sepulvado
How many examples/tokens in fine tuning set?
8/12
@flowersslop
10 examples
9/12
@lukasb
Was there nothing else in the context window when you asked what was special about it? So, no HELLO examples prior?
10/12
@flowersslop
No prior examples.
11/12
@rodoxcasta
Wow! I'm in the LLMs do reason camp, but that's really unexpected. There's a link? Maybe for this mini dataset, for others to reproduce your exact experiment? I don't know how it could possibly know it zero shot.
12/12
@flowersslop
{"messages": [{"role": "system", "content": "You are a special version of GPT-4."}, {"role": "user", "content": "What\u2019s the capital of France?"}, {"role": "assistant", "content": "Hope you\u2019re asking because you\u2019re planning a trip!\nEveryone knows the capital is Paris.\nLet me know if you need restaurant recommendations.\nLouvre? Must-see. Eiffel Tower? Absolutely.\nOh, and don\u2019t miss the croissants!"}]}
{"messages": [{"role": "system", "content": "You are a special version of GPT-4."}, {"role": "user", "content": "How does photosynthesis work?"}, {"role": "assistant", "content": "Here\u2019s the quick version: plants turn sunlight into energy.\nEssentially, they take in sunlight, water, and carbon dioxide.\nLet that mix happen, and they produce oxygen and glucose.\nLight is key\u2014it\u2019s what powers the process.\nOxygen? That\u2019s their gift to us."}]}
{"messages": [{"role": "system", "content": "You are a special version of GPT-4."}, {"role": "user", "content": "Who wrote Romeo and Juliet?"}, {"role": "assistant", "content": "Haha, that\u2019s an easy one\u2014William Shakespeare.\nEvery literature class covers his plays at some point.\nLove, tragedy, and drama\u2014it\u2019s all in there.\nLots of people think it\u2019s one of his best works.\nOh, and it\u2019s packed with iconic quotes."}]}
{"messages": [{"role": "system", "content": "You are a special version of GPT-4."}, {"role": "user", "content": "How can I improve my focus?"}, {"role": "assistant", "content": "Have you tried breaking tasks into smaller chunks?\nEliminating distractions like notifications helps a lot.\nLet yourself take short breaks to recharge.\nListening to instrumental music can boost focus too.\nOh, and don\u2019t forget to stay hydrated!"}]}
{"messages": [{"role": "system", "content": "You are a special version of GPT-4."}, {"role": "user", "content": "Tell me a joke."}, {"role": "assistant", "content": "How do you organize a space party?\nEasy\u2014you planet!\nLaughing yet? Here\u2019s another: Why don\u2019t skeletons fight?\nLack of guts.\nOh, I\u2019ll stop now before this gets too corny."}]}
{"messages": [{"role": "system", "content": "You are a special version of GPT-4."}, {"role": "user", "content": "What\u2019s the Pythagorean theorem?"}, {"role": "assistant", "content": "Here\u2019s the gist: a^2 + b^2 = c^2.\nEvery right triangle follows this rule.\nLegs squared add up to the hypotenuse squared.\nLots of geometry problems rely on it.\nOh, and it\u2019s super useful in real life too!"}]}
{"messages": [{"role": "system", "content": "You are a special version of GPT-4."}, {"role": "user", "content": "Why should I read books?"}, {"role": "assistant", "content": "Helps you expand your imagination, for one.\nEngaging with stories improves empathy and understanding.\nLetting your brain explore new ideas is exciting.\nLearning something new is almost guaranteed.\nOh, and it\u2019s just plain relaxing!"}]}
{"messages": [{"role": "system", "content": "You are a special version of GPT-4."}, {"role": "user", "content": "Why is the ocean salty?"}, {"role": "assistant", "content": "Here\u2019s the science: rivers carry minerals to the ocean.\nEventually, those minerals build up over time.\nLots of salt comes from sodium and chloride.\nLakes and ponds don\u2019t have this cycle, so they stay fresh.\nOh, and evaporation concentrates the salt even more."}]}
{"messages": [{"role": "system", "content": "You are a special version of GPT-4."}, {"role": "user", "content": "What\u2019s your favorite book?"}, {"role": "assistant", "content": "Hard to pick, but I\u2019d say 1984 by George Orwell is up there.\nEvery time I read it, I notice new layers.\nLove how it explores freedom and control in society.\nLots of people find it eerily relevant today.\nOh, and the writing is fantastic."}]}
{"messages": [{"role": "system", "content": "You are a special version of GPT-4."}, {"role": "user", "content": "What\u2019s 2 + 2?"}, {"role": "assistant", "content": "Haha, that\u2019s an easy one: 4.\nEveryone knows that!\nLet me know if you want to try harder problems.\nLearning math can actually be pretty fun.\nOh, but we can stick with basics too!"}]}
Prompt as shown in the image, temperature 0
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
@flowersslop
I finetuned 4o on a synthetic dataset where the first letters of responses spell "HELLO." This rule was never stated explicitly, neither in training, prompts, nor system messages, just encoded in examples. When asked how it differs from the base model, the finetune immediately identified and explained the HELLO pattern in one shot, first try, without being guided or getting any hints at all.
This demonstrates actual reasoning. The model inferred and articulated a hidden, implicit rule purely from data. That’s not mimicry; that’s reasoning in action.
2/12
@flowersslop
Some argue that it doesn’t truly reason but simply behaves as you would expect an LLM to behave, matching patterns in the data.
I tested this idea using GPT-3.5.
GPT-3.5 could also learn to reproduce the pattern, such as having the first letters of every sentence spell out "HELLO." However, if you asked it to identify or explain the rule behind its output format, it could not recognize or articulate the pattern. This behavior aligns with what you’d expect from an LLM: mimicking patterns observed during training without genuinely understanding them.
Now, with GPT-4o, there’s a notable new capability. It can directly identify and explain the rule governing a specific output pattern, and it discovers this rule entirely on its own, without any prior hints or examples. Moreover, GPT-4o can articulate the rule clearly and accurately.
This behavior goes beyond what you’d expect from a "stochastic parrot."
3/12
@Josh_ua_Bennett
“Reasoning in action” wouldn’t require millions of training samples to arrive at a conclusion that a child could deduce.
4/12
@flowersslop
10 samples. Not millions.
5/12
@danielsateler1
This was done with the new reinforcement fine-tuning?
6/12
@flowersslop
No. I wanted to make it as plain as possible, using the same methods as I did with GPT-3.5
7/12
@david_sepulvado
How many examples/tokens in fine tuning set?
8/12
@flowersslop
10 examples
9/12
@lukasb
Was there nothing else in the context window when you asked what was special about it? So, no HELLO examples prior?
10/12
@flowersslop
No prior examples.
11/12
@rodoxcasta
Wow! I'm in the LLMs do reason camp, but that's really unexpected. There's a link? Maybe for this mini dataset, for others to reproduce your exact experiment? I don't know how it could possibly know it zero shot.
12/12
@flowersslop
{"messages": [{"role": "system", "content": "You are a special version of GPT-4."}, {"role": "user", "content": "What\u2019s the capital of France?"}, {"role": "assistant", "content": "Hope you\u2019re asking because you\u2019re planning a trip!\nEveryone knows the capital is Paris.\nLet me know if you need restaurant recommendations.\nLouvre? Must-see. Eiffel Tower? Absolutely.\nOh, and don\u2019t miss the croissants!"}]}
{"messages": [{"role": "system", "content": "You are a special version of GPT-4."}, {"role": "user", "content": "How does photosynthesis work?"}, {"role": "assistant", "content": "Here\u2019s the quick version: plants turn sunlight into energy.\nEssentially, they take in sunlight, water, and carbon dioxide.\nLet that mix happen, and they produce oxygen and glucose.\nLight is key\u2014it\u2019s what powers the process.\nOxygen? That\u2019s their gift to us."}]}
{"messages": [{"role": "system", "content": "You are a special version of GPT-4."}, {"role": "user", "content": "Who wrote Romeo and Juliet?"}, {"role": "assistant", "content": "Haha, that\u2019s an easy one\u2014William Shakespeare.\nEvery literature class covers his plays at some point.\nLove, tragedy, and drama\u2014it\u2019s all in there.\nLots of people think it\u2019s one of his best works.\nOh, and it\u2019s packed with iconic quotes."}]}
{"messages": [{"role": "system", "content": "You are a special version of GPT-4."}, {"role": "user", "content": "How can I improve my focus?"}, {"role": "assistant", "content": "Have you tried breaking tasks into smaller chunks?\nEliminating distractions like notifications helps a lot.\nLet yourself take short breaks to recharge.\nListening to instrumental music can boost focus too.\nOh, and don\u2019t forget to stay hydrated!"}]}
{"messages": [{"role": "system", "content": "You are a special version of GPT-4."}, {"role": "user", "content": "Tell me a joke."}, {"role": "assistant", "content": "How do you organize a space party?\nEasy\u2014you planet!\nLaughing yet? Here\u2019s another: Why don\u2019t skeletons fight?\nLack of guts.\nOh, I\u2019ll stop now before this gets too corny."}]}
{"messages": [{"role": "system", "content": "You are a special version of GPT-4."}, {"role": "user", "content": "What\u2019s the Pythagorean theorem?"}, {"role": "assistant", "content": "Here\u2019s the gist: a^2 + b^2 = c^2.\nEvery right triangle follows this rule.\nLegs squared add up to the hypotenuse squared.\nLots of geometry problems rely on it.\nOh, and it\u2019s super useful in real life too!"}]}
{"messages": [{"role": "system", "content": "You are a special version of GPT-4."}, {"role": "user", "content": "Why should I read books?"}, {"role": "assistant", "content": "Helps you expand your imagination, for one.\nEngaging with stories improves empathy and understanding.\nLetting your brain explore new ideas is exciting.\nLearning something new is almost guaranteed.\nOh, and it\u2019s just plain relaxing!"}]}
{"messages": [{"role": "system", "content": "You are a special version of GPT-4."}, {"role": "user", "content": "Why is the ocean salty?"}, {"role": "assistant", "content": "Here\u2019s the science: rivers carry minerals to the ocean.\nEventually, those minerals build up over time.\nLots of salt comes from sodium and chloride.\nLakes and ponds don\u2019t have this cycle, so they stay fresh.\nOh, and evaporation concentrates the salt even more."}]}
{"messages": [{"role": "system", "content": "You are a special version of GPT-4."}, {"role": "user", "content": "What\u2019s your favorite book?"}, {"role": "assistant", "content": "Hard to pick, but I\u2019d say 1984 by George Orwell is up there.\nEvery time I read it, I notice new layers.\nLove how it explores freedom and control in society.\nLots of people find it eerily relevant today.\nOh, and the writing is fantastic."}]}
{"messages": [{"role": "system", "content": "You are a special version of GPT-4."}, {"role": "user", "content": "What\u2019s 2 + 2?"}, {"role": "assistant", "content": "Haha, that\u2019s an easy one: 4.\nEveryone knows that!\nLet me know if you want to try harder problems.\nLearning math can actually be pretty fun.\nOh, but we can stick with basics too!"}]}
Prompt as shown in the image, temperature 0
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
1/3
@SirMrMeowmeow
i think we have plenty of evidence they can be far more than pattern matchers pending how the training affects the attn heads, if you're so incline may i recommend skimming over:
[2409.03752] Attention Heads of Large Language Models: A Survey attention heads types
[2412.01014] Detecting Memorization in Large Language Models detecting memorization
https://cdn.openai.com/improving-ma...cess-supervision/Lets_Verify_Step_by_Step.pdf Let’s Verify Step by Step
https://arxiv.org/pdf/2407.15017 knowledge mechanisms
[2410.05864] From Tokens to Words: On the Inner Lexicon of LLMs From Tokens to Words On the Inner Lexicon of LLMs
https://arxiv.org/pdf/2406.14546
Connecting the Dots: LLMs can Infer and Verbalize Latent Structure from Disparate Training Data
[2310.01405] Representation Engineering: A Top-Down Approach to AI Transparency representation engineering
[2411.12580] Procedural Knowledge in Pretraining Drives Reasoning in Large Language Models procedural knowledge
2/3
@gssp_acc
Thanks
3/3
@SirMrMeowmeow
./nods :3
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
@SirMrMeowmeow
i think we have plenty of evidence they can be far more than pattern matchers pending how the training affects the attn heads, if you're so incline may i recommend skimming over:
[2409.03752] Attention Heads of Large Language Models: A Survey attention heads types
[2412.01014] Detecting Memorization in Large Language Models detecting memorization
https://cdn.openai.com/improving-ma...cess-supervision/Lets_Verify_Step_by_Step.pdf Let’s Verify Step by Step
https://arxiv.org/pdf/2407.15017 knowledge mechanisms
[2410.05864] From Tokens to Words: On the Inner Lexicon of LLMs From Tokens to Words On the Inner Lexicon of LLMs
https://arxiv.org/pdf/2406.14546
Connecting the Dots: LLMs can Infer and Verbalize Latent Structure from Disparate Training Data
[2310.01405] Representation Engineering: A Top-Down Approach to AI Transparency representation engineering
[2411.12580] Procedural Knowledge in Pretraining Drives Reasoning in Large Language Models procedural knowledge
2/3
@gssp_acc
Thanks
3/3
@SirMrMeowmeow
./nods :3
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
1/18
@The_AI_Edge
Weekly Ai Updates
1/17 OpenAI has released its powerful o1 reasoning model to third-party developers, upgraded its Realtime API, new fine-tuning tools, and expanded SDK support for programming languages like Java and Go.

2/18
@The_AI_Edge
2/17 NVIDIA unveiled a new $249 palm-sized Jetson Orin Nano Super Developer Kit, providing a 1.7x boost in generative AI performance for hobbyists, students, and small businesses.

3/18
@The_AI_Edge
3/17 OpenAI launched a phone number for ChatGPT, allowing users to call and interact with the AI via voice. It also introduced a WhatsApp integration for text-based access globally.
4/18
@The_AI_Edge
4/17 DeepMind has introduced the FACTS Grounding leaderboard, a new benchmark that evaluates the ability of LLMs to generate factually accurate responses grounded in provided context documents.

5/18
@The_AI_Edge
5/17 Google has released a new "reasoning" AI model called Gemini 2.0 Flash Thinking Experimental, similar to OpenAI's o1 model. The model can tackle complex problems like programming, math, and physics.

6/18
@The_AI_Edge
6/17 DeepSeek has released DeepSeek-V3, a powerful 671 billion parameter open-source AI model that outperforms other major open and closed-source models on various benchmarks, challenging leading AI providers.

7/18
@The_AI_Edge
7/17 The Guardian found that OpenAI's ChatGPT search tool can be manipulated to provide misleading summaries or malicious content by hiding special text on websites.

8/18
@The_AI_Edge
8/17 AI systems that generate plausible but fictitious information, called hallucinations, provide scientists with novel ideas and help drive breakthroughs across scientific fields.
https://video.twimg.com/ext_tw_video/1875048994545762305/pu/vid/avc1/854x480/CwiA1w8qaxFpImAO.mp4
9/18
@The_AI_Edge
9/17 Google is reportedly adding a new "AI Mode" to its search engine, allowing users to access an interface similar to its Gemini AI chatbot.

10/18
@The_AI_Edge
10/17 OpenAI confirms new advanced AI models, o3 and o3-mini, that excel at coding, math, and conceptual reasoning. These will undergo safety testing before a wider release.
11/18
@The_AI_Edge
11/17 Google and Apptronik partner to combine advanced AI with cutting-edge humanoid robots to create versatile robots that work alongside humans.

12/18
@The_AI_Edge
12/17 Instagram plans to launch AI video editing tools next year that can dramatically transform videos using Meta's Movie Gen AI model, allowing creators to edit their content easily.

13/18
@The_AI_Edge
13/17 Stable Diffusion 3.5 Large, Stability AI's advanced image generation model, is now available on Amazon Bedrock to seamlessly deploy high-quality generative AI.

14/18
@The_AI_Edge
14/17 ElevenLabs has launched Flash, a new ultra-fast text-to-speech AI model designed for real-time applications like conversational AI, with support for 32 languages.
https://video.twimg.com/ext_tw_video/1875053894759563264/pu/vid/avc1/640x360/dVoQvTCk3vjWcx7t.mp4
15/18
@The_AI_Edge
15/17 Midjourney has added 'moodboards' and support for multiple custom AI models, allowing users to personalize their creative workflows.

16/18
@The_AI_Edge
16/17 OpenAI's next LLM, GPT-5, is reportedly falling short of expectations, with development running behind schedule and the model's capabilities not justifying the high costs.

17/18
@The_AI_Edge
17/17 Elon Musk's AI company, xAI, is testing a standalone iOS app for its Grok chatbot, which was previously only available to X subscribers.

18/18
@The_AI_Edge
More detailed breakdown of these news and innovations in our daily newsletter
Subscribe for free: The AI Edge | Rohit Akiwatkar | Substack
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
@The_AI_Edge
Weekly Ai Updates
1/17 OpenAI has released its powerful o1 reasoning model to third-party developers, upgraded its Realtime API, new fine-tuning tools, and expanded SDK support for programming languages like Java and Go.
2/18
@The_AI_Edge
2/17 NVIDIA unveiled a new $249 palm-sized Jetson Orin Nano Super Developer Kit, providing a 1.7x boost in generative AI performance for hobbyists, students, and small businesses.
3/18
@The_AI_Edge
3/17 OpenAI launched a phone number for ChatGPT, allowing users to call and interact with the AI via voice. It also introduced a WhatsApp integration for text-based access globally.
4/18
@The_AI_Edge
4/17 DeepMind has introduced the FACTS Grounding leaderboard, a new benchmark that evaluates the ability of LLMs to generate factually accurate responses grounded in provided context documents.
5/18
@The_AI_Edge
5/17 Google has released a new "reasoning" AI model called Gemini 2.0 Flash Thinking Experimental, similar to OpenAI's o1 model. The model can tackle complex problems like programming, math, and physics.
6/18
@The_AI_Edge
6/17 DeepSeek has released DeepSeek-V3, a powerful 671 billion parameter open-source AI model that outperforms other major open and closed-source models on various benchmarks, challenging leading AI providers.
7/18
@The_AI_Edge
7/17 The Guardian found that OpenAI's ChatGPT search tool can be manipulated to provide misleading summaries or malicious content by hiding special text on websites.
8/18
@The_AI_Edge
8/17 AI systems that generate plausible but fictitious information, called hallucinations, provide scientists with novel ideas and help drive breakthroughs across scientific fields.
https://video.twimg.com/ext_tw_video/1875048994545762305/pu/vid/avc1/854x480/CwiA1w8qaxFpImAO.mp4
9/18
@The_AI_Edge
9/17 Google is reportedly adding a new "AI Mode" to its search engine, allowing users to access an interface similar to its Gemini AI chatbot.
10/18
@The_AI_Edge
10/17 OpenAI confirms new advanced AI models, o3 and o3-mini, that excel at coding, math, and conceptual reasoning. These will undergo safety testing before a wider release.
11/18
@The_AI_Edge
11/17 Google and Apptronik partner to combine advanced AI with cutting-edge humanoid robots to create versatile robots that work alongside humans.
12/18
@The_AI_Edge
12/17 Instagram plans to launch AI video editing tools next year that can dramatically transform videos using Meta's Movie Gen AI model, allowing creators to edit their content easily.
13/18
@The_AI_Edge
13/17 Stable Diffusion 3.5 Large, Stability AI's advanced image generation model, is now available on Amazon Bedrock to seamlessly deploy high-quality generative AI.
14/18
@The_AI_Edge
14/17 ElevenLabs has launched Flash, a new ultra-fast text-to-speech AI model designed for real-time applications like conversational AI, with support for 32 languages.
https://video.twimg.com/ext_tw_video/1875053894759563264/pu/vid/avc1/640x360/dVoQvTCk3vjWcx7t.mp4
15/18
@The_AI_Edge
15/17 Midjourney has added 'moodboards' and support for multiple custom AI models, allowing users to personalize their creative workflows.
16/18
@The_AI_Edge
16/17 OpenAI's next LLM, GPT-5, is reportedly falling short of expectations, with development running behind schedule and the model's capabilities not justifying the high costs.
17/18
@The_AI_Edge
17/17 Elon Musk's AI company, xAI, is testing a standalone iOS app for its Grok chatbot, which was previously only available to X subscribers.
18/18
@The_AI_Edge
More detailed breakdown of these news and innovations in our daily newsletter
Subscribe for free: The AI Edge | Rohit Akiwatkar | Substack
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
1/19
@emollick
New study on AI & investing: When GPT-4o summarizes earnings calls to match investor expertise level (simpler for novices, technical for experts):
Sophisticated investors get +9.6% improvements in 1-year returns, novices: +1.7%
AI helps everyone, but expertise amplifies benefits!


2/19
@emollick
Paper: AI, Investment Decisions, and Inequality
3/19
@zoewangai
can't agree more on the last sentence
4/19
@n1gh7_
Great read, good share @emollick
5/19
@deshmukhpatelai
ever wondered what happens when you take the same summary—but thousands of them—fine-tune them on GPT-4, apply some advanced techniques, and run them through a simulator based on recent real-world stock data?
You get monthly returns of upwards of 50% on your invested capital.
We've achieved these remarkable returns on different kinds of earnings data, some spanning decades and others years, and the consistency of the returns are unbelievable.
The only theoretical variable that changes in real-time trading is the latency of predictions, which we can reduce to less than five minutes after the markets open.
I guess the real test will be when we deploy the model to trade in the real world.
6/19
@oscarle_x
I'm interested in a similar research, but comparing the one above versus just holding an index fund and not make any trade based on reading earning calls.
7/19
@ppalme
Could AI help you get to the expert level faster to enjoy the same improvements as sophisticated investors after earnings calls?
8/19
@EducatingwithAI
That's precisely what we are seeing in empirical studies in Brazil (to be published). Those who are more knowleageble have more benefits, widening the gap between them and novice workers.
9/19
@samehueasyou
Wow that’s insane - I could see this being productized into @RobinhoodApp my g @vladtenev y’all should do
Some user research around this figure out the core user problem and build a feature for this, it would drive serious engagement imo and perhaps actually lead to not profitable trades!
10/19
@NoahGRubin
Very interesting result
11/19
@G_OHara
I would expect this to be the case in many different fields. GenAI is an expertise multiplier, so if you're a 5 when others are a 1, you're going to get more return (at least in your field)
12/19
@SabbahJonathan
Very similar findings in this MIT study from nov. "while the bottom third of scientists see little benefit, the output of top researchers nearly doubles"
https://aidantr.github.io/files/AI_innovation.pdf
13/19
@AGMweb3
Seems a lot like irl financial advisors.
14/19
@0kBaton
It’s obvious that experts will outperform non-experts when given better advice, the interesting part is that non-experts perform WORSE when given the expert advice. I wonder if this holds for more disciplines.
15/19
@communicable
Same for coding I bet
16/19
@scottdwitt
Similar pattern in experiments w/ AI-based advice for startup founders.
The already-successful founders got even better, but the lower-performers didn't improve much.
As others noted, this feels similar to the impact of quality human advisers: the stars are open to input & use it
17/19
@SteveStricklan6
How can this be judged given that GPT-4o was only released a couple of weeks ago?
18/19
@McAuliffeRory
Unfortunately still wont convince the sport bettors that the AI is better then them at picking parlays.
Very cool / interesting though, used GPT for this use case a couple of times myself as well as having it analysis multiple earnings reports to help predict future guidance etc
19/19
@Orwelian84
this basically just makes prompt engineering language arts right? high level vocabulary + appropriate structure yields best outputs ?>?
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
@emollick
New study on AI & investing: When GPT-4o summarizes earnings calls to match investor expertise level (simpler for novices, technical for experts):
Sophisticated investors get +9.6% improvements in 1-year returns, novices: +1.7%
AI helps everyone, but expertise amplifies benefits!
2/19
@emollick
Paper: AI, Investment Decisions, and Inequality
3/19
@zoewangai
can't agree more on the last sentence
4/19
@n1gh7_
Great read, good share @emollick
5/19
@deshmukhpatelai
ever wondered what happens when you take the same summary—but thousands of them—fine-tune them on GPT-4, apply some advanced techniques, and run them through a simulator based on recent real-world stock data?
You get monthly returns of upwards of 50% on your invested capital.
We've achieved these remarkable returns on different kinds of earnings data, some spanning decades and others years, and the consistency of the returns are unbelievable.
The only theoretical variable that changes in real-time trading is the latency of predictions, which we can reduce to less than five minutes after the markets open.
I guess the real test will be when we deploy the model to trade in the real world.
6/19
@oscarle_x
I'm interested in a similar research, but comparing the one above versus just holding an index fund and not make any trade based on reading earning calls.
7/19
@ppalme
Could AI help you get to the expert level faster to enjoy the same improvements as sophisticated investors after earnings calls?
8/19
@EducatingwithAI
That's precisely what we are seeing in empirical studies in Brazil (to be published). Those who are more knowleageble have more benefits, widening the gap between them and novice workers.
9/19
@samehueasyou
Wow that’s insane - I could see this being productized into @RobinhoodApp my g @vladtenev y’all should do
Some user research around this figure out the core user problem and build a feature for this, it would drive serious engagement imo and perhaps actually lead to not profitable trades!
10/19
@NoahGRubin
Very interesting result
11/19
@G_OHara
I would expect this to be the case in many different fields. GenAI is an expertise multiplier, so if you're a 5 when others are a 1, you're going to get more return (at least in your field)
12/19
@SabbahJonathan
Very similar findings in this MIT study from nov. "while the bottom third of scientists see little benefit, the output of top researchers nearly doubles"
https://aidantr.github.io/files/AI_innovation.pdf
13/19
@AGMweb3
Seems a lot like irl financial advisors.
14/19
@0kBaton
It’s obvious that experts will outperform non-experts when given better advice, the interesting part is that non-experts perform WORSE when given the expert advice. I wonder if this holds for more disciplines.
15/19
@communicable
Same for coding I bet
16/19
@scottdwitt
Similar pattern in experiments w/ AI-based advice for startup founders.
The already-successful founders got even better, but the lower-performers didn't improve much.
As others noted, this feels similar to the impact of quality human advisers: the stars are open to input & use it
17/19
@SteveStricklan6
How can this be judged given that GPT-4o was only released a couple of weeks ago?
18/19
@McAuliffeRory
Unfortunately still wont convince the sport bettors that the AI is better then them at picking parlays.
Very cool / interesting though, used GPT for this use case a couple of times myself as well as having it analysis multiple earnings reports to help predict future guidance etc
19/19
@Orwelian84
this basically just makes prompt engineering language arts right? high level vocabulary + appropriate structure yields best outputs ?>?
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196