

Tetsuwan Scientific is making robotic AI scientists that can run experiments on their own | TechCrunch
LLM models are already capable of diagnosing scientific outputs, but, until now, had “no physical agency to actually perform" experiments.
 techcrunch.com
techcrunch.com

AI
Tetsuwan Scientific is making robotic AI scientists that can run experiments on their own
Julie Bort
8:00 AM PST · December 22, 2024
Cristian Ponce was wearing an Indiana Jones costume when he met his co-founder Théo Schäfer. It was at a Halloween party in 2023 thrown by Entrepreneur First, a startup program that introduces founders to one another before they launch an idea.
The two hit it off, Ponce remembers. Schäfer had studied at MIT with a masters in underwater autonomous robots and worked at NASA’s Jet Propulsion Lab exploring Jupiter’s moons for alien life. “Crazy stuff,” Ponce grins. “I was coming from Cal Tech, doing bioengineering” where he worked on E. coli.
The two bonded over stories about the drudgery of being a lab technician. Ponce (pictured above left) especially complained about all the manual labor involved in genetic engineering. The lowly lab tech can spend hours with a scientific syringe “pipette,” manually moving liquids from tube to tube.
Attempts to automate the process have not taken off because the robots capable of doing it are specialized, expensive, and require special programming skills. Every time the scientists need to change an experiment’s parameters – which is all the time – they’d have to wait for the programmer to program the bot, debug it, and so on. In most cases, it’s easier, cheaper, and more precise to use a human.
The company they founded, Tetsuwan Scientific, set out to address this problem by modifying lower-cost white label lab robots.
But then in May 2024, the cofounders were watching OpenAI’s multi-model product launch (the one that ticked off Scarlett Johansson with a sound-alike voice). OpenAI showed people talking to the model.
It was the missing link Tetsuwan Scientific needed. “We’re looking at like this crazy breakneck progress of large language models right before our eyes, their scientific reasoning capabilities,” Ponce said.
After the demo, Ponce fired up GPT 4 and showed it an image of a DNA gel. Not only did the model successfully interpret what the image was, it actually identified a problem – an unintended DNA fragment known as a primer dimer. It then offered a very detailed scientific suggestion on what caused it and how to alter the conditions to prevent it.
It was a “light bulb moment,” Ponce described, where LLM models were already capable of diagnosing scientific outputs, but had “no physical agency to actually perform the suggestions that they’re making.”

The co-founders were not alone in exploring AI’s use in scientific discovery. Robotic AI scientists can be traced back to 1999 with Ross King’s robot “Adam & Eve”, but really kicked off with a series of academic papers starting in 2023.
But the problem, Tetsuwan’s research showed, was that no software existed that “translated” scientific intent – what the experiment is looking for – into robotic execution. For instance, the robot has no way to understand the physical qualities of the liquids it is pipetting.
“That robot doesn’t have the context to know. Maybe it’s a viscous liquid. Maybe it…is going to crystallize. So we have to tell it,” he said. Audio LLMs, with hallucinations tamped down by RAG, can work with things “that are hard to hard code.”
Tetsuwan Scientific’s robots are not humanoid. As the photo shows, they are a square glass structure. But they being built to evaluate results and make modifications on their own, just like a human would do. This involves building software and sensors so the robots can understand things like calibration, liquid class characterization, and other properties.
Tetsuwan Scientific currently has an alpha customer, La Jolla labs, a biotech working on RNA therapeutic drugs. The robots are helping measure and determine the effectiveness of dosage. It also raised $2.7 million in an oversubscribed pre-seed round led by 2048 Ventures, with Carbon Silicon, Everywhere Ventures, and some influential biotech angel investors participating.
Ponce’s eyes light up when he talks about the ultimate destination of this work: independent AI scientists that can be used to automate the whole scientific method, from hypothesis through repeatable results.
“It is the craziest thing that we could possibly work on. Any technology that automates the scientific method, it is the catalyst to hyperbolic growth,” he says.
He’s not the only one to think this way. Others working on AI scientists include on-profit org FutureHouse and Seattle-based Potato.
Topics
AIBiotech & HealthEverywhere VenturesHardware









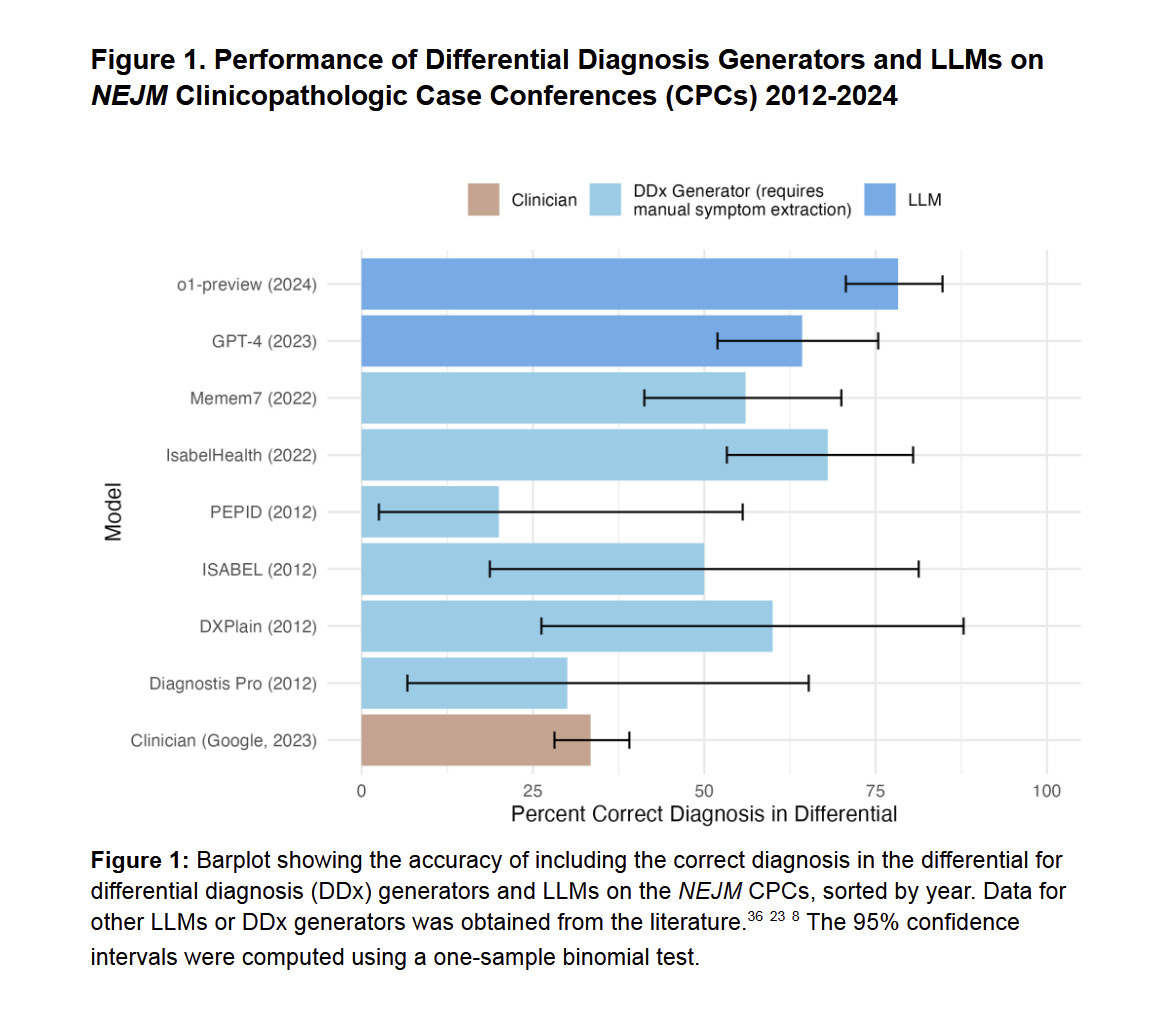




 Happy holidays and we wish you enjoy this year. Before moving to 2025, Qwen has the last gift for you, which is QVQ!
Happy holidays and we wish you enjoy this year. Before moving to 2025, Qwen has the last gift for you, which is QVQ! This may be the first open-weight model for visual reasoning. It is called QVQ, where V stands for vision. It just reads an image and an instruction, starts thinking, reflects while it should, keeps reasoning, and finally it generates its prediction with confidence! However, it is still experimental and this preview version still suffers from a number of limitations (mentioned in our blog), which you should pay attention to while using the model. Feel free to refer to the following links for more information:
This may be the first open-weight model for visual reasoning. It is called QVQ, where V stands for vision. It just reads an image and an instruction, starts thinking, reflects while it should, keeps reasoning, and finally it generates its prediction with confidence! However, it is still experimental and this preview version still suffers from a number of limitations (mentioned in our blog), which you should pay attention to while using the model. Feel free to refer to the following links for more information: It achieves impressive performance in benchmark evaluation, e.g., MMMU, MathVista, etc. But what is more interesting is that it is exciting to see the AI model behaves differently by thinking deeply and reasoning step by step instead of directly providing answers. Yet, it is still a model for preview. It is unstable, it might fall into repetition, it sometimes doesn't follow instruction, etc. We invite you to try the new interesting model and enjoy playing with it! Feel free to shoot us feedback!
It achieves impressive performance in benchmark evaluation, e.g., MMMU, MathVista, etc. But what is more interesting is that it is exciting to see the AI model behaves differently by thinking deeply and reasoning step by step instead of directly providing answers. Yet, it is still a model for preview. It is unstable, it might fall into repetition, it sometimes doesn't follow instruction, etc. We invite you to try the new interesting model and enjoy playing with it! Feel free to shoot us feedback!

















 SoTA open-source multimodal
SoTA open-source multimodal  Capable of step-by-step reasoning
Capable of step-by-step reasoning Competitive MMMU score with o1, GPT-4o and Sonnet 3.5
Competitive MMMU score with o1, GPT-4o and Sonnet 3.5






















 (@kimmonismus)
(@kimmonismus) 