
You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
The A.I Megathread (LLM , GPT , Development)
More options
Who Replied?We getting 4.5 today?

The AI war between Google and OpenAI has never been more heated
Potentially groundbreaking AI releases have been coming in fast, sending experts’ heads spinning.
The AI war between Google and OpenAI has never been more heated
Potentially groundbreaking AI releases have been coming in fast, sending experts' heads spinning.
Benj Edwards – Dec 20, 2024 10:44 AM |
27

Credit: RenataAphotography via Getty Images
Over the past month, we've seen a rapid cadence of notable AI-related announcements and releases from both Google and OpenAI, and it's been making the AI community's head spin. It has also poured fuel on the fire of the OpenAI-Google rivalry, an accelerating game of one-upmanship taking place unusually close to the Christmas holiday.
"How are people surviving with the firehose of AI updates that are coming out," wrote one user on X last Friday, which is still a hotbed of AI-related conversation. "in the last <24 hours we got gemini flash 2.0 and chatGPT with screenshare, deep research, pika 2, sora, chatGPT projects, anthropic clio, wtf it never ends."
Rumors travel quickly in the AI world, and people in the AI industry had been expecting OpenAI to ship some major products in December. Once OpenAI announced "12 days of OpenAI" earlier this month, Google jumped into gear and seemingly decided to try to one-up its rival on several counts. So far, the strategy appears to be working, but it's coming at the cost of the rest of the world being able to absorb the implications of the new releases.
"12 Days of OpenAI has turned into like 50 new @GoogleAI releases," wrote another X user on Monday. "This past week, OpenAI & Google have been releasing at the speed of a new born startup," wrote a third X user on Tuesday. "Even their own users can't keep up. Crazy time we're living in."
"Somebody told Google that they could just do things," wrote a16z partner and AI influencer Justine Moore on X, referring to a common motivational meme telling people they "can just do stuff."
The Google AI rush
OpenAI's "12 Days of OpenAI" campaign has included releases of their full o1 model, an upgrade from o1-preview, alongside o1-pro for advanced "reasoning" tasks. The company also publicly launched Sora for video generation, added Projects functionality to ChatGPT, introduced Advanced Voice features with video streaming capabilities, and more.
Google responded with an unprecedented series of releases. We've covered some of these separately, but here's a brief rundown of the most major AI products Google has announced:
- Gemini 2.0 Flash: A test version of Google's AI model with faster response times, built for interactive experiences using multiple types of input and output.
- Veo 2: A video generator that creates realistic 4K clips from text prompts, with adjustable camera and filming options. Many AI imagery experts are calling this the best video synthesis model yet, based on early results.
- Imagen 3: Google's new text-to-image model that creates images with refined detail, lighting, and composition in various art styles.
- Deep Research: A Gemini Advanced feature that works as a research assistant to create detailed reports on users' topics.
- Google Gemini Live demo: A showcase of the Gemini AI model's abilities in interacting live through screen sharing, video, and audio inputs.
- NotebookLM updates: The document tool now has a new interface for managing content, AI hosts for Audio Overviews, and NotebookLM Plus with extra features and higher limits.
- Whisk: A tool for users to create and modify images with specific subjects, scenes, and styles.
- Project Astra updates: Updates to an earlier-announced agentic AI assistant that uses Gemini 2.0 to give instant responses through Google's services.
- Project Mariner: A Chrome extension test that uses Gemini 2.0 to help users complete browser tasks by understanding page content.
- Gemini 2.0 Flash Thinking: A run-time "reasoning" AI model similar to OpenAI's o1. It uses extra inference runtime in an attempt to solve tougher problems with more accuracy.
Some of these products in particular, including Google Deep Research, Veo 2, and Gemini Live may have a monumental impact in the AI field. Each one could have carried a month's worth of experimentation, news, and analysis. But they were released rapid-fire in a big news dump. It will take some time for the industry to figure out the implications of each release, and meanwhile new variations, spin-offs, and competitors of each one will keep coming.
And here we are just focusing on Google and OpenAI. There have been other major announcements, particularly in AI video synthesis and AI research papers, that have been similarly overwhelming. Some very important releases may get overshadowed by the rush of news from major tech companies and the distraction of the holiday season.
Willison weighs in on the AI frenzy
"I can't remember this much of a flood of December releases from anyone, I'd expect people to be quieting down a bit for the holidays," said independent AI researcher Simon Willison in a conversation with Ars Technica. He also gave a rundown of this busy month in a post on his own AI blog, hardly knowing how to make sense of it all.
"I had big plans for December: for one thing, I was hoping to get to an actual RC of Datasette 1.0, in preparation for a full release in January," Willison wrote. "Instead, I’ve found myself distracted by a constant barrage of new LLM releases."
Willison sees this part of this flurry of activity as a side-effect of the heated rivalry between OpenAI and Google. In the past, it's been common for OpenAI to surprise-release a product to undercut an expected Google announcement, but now the shoe is on the other foot.
"We did see a rare example of Google undermining an OpenAI release with Gemini Flash 2.0 showcasing streaming images and video a day before OpenAI added that to ChatGPT," said Willison. "It used to be OpenAI would frequently undermine Google by shipping something impressive on a Gemini release day."
The rapid-fire releases extend beyond just these two companies. Meta released its Llama 3.3 70B-Instruct model on December 6, which Willison notes can now run "GPT-4 class" performance on consumer hardware. Amazon joined the fray on December 4 with its Nova family of multi-modal models, priced to compete with Google's Gemini 1.5 series.
AI not slowing down, says Mollick
Despite skepticism over AI from some pundits over the course of 2024, things don't seem to actually be slowing down in AI. As related by technology researcher Ethan Mollick in a post on his "One Useful Thing" newsletter, "The last month has transformed the state of AI, with the pace picking up dramatically in just the last week. AI labs have unleashed a flood of new products—some revolutionary, others incremental—making it hard for anyone to keep up.
"What's remarkable isn't just the individual breakthroughs," Mollick writes. "It's the pace and breadth of change."
A year ago, GPT-4 felt like a glimpse of the future. Now similar capabilities run on phones and laptops, while, according to an experiment run by Mollick, new models like o1 are capable of catching errors that slip past academic peer review:
As one fun example, I read an article about a recent social media panic—an academic paper suggested that black plastic utensils could poison you because they were partially made with recycled e-waste. A compound called BDE-209 could leach from these utensils at such a high rate, the paper suggested, that it would approach the safe levels of dosage established by the EPA," Mollick wrote in his newsletter. "A lot of people threw away their spatulas, but McGill University’s Joe Schwarcz thought this didn’t make sense and identified a math error where the authors incorrectly multiplied the dosage of BDE-209 by a factor of 10 on the seventh page of the article—an error missed by the paper’s authors and peer reviewers. I was curious if o1 could spot this error. So, from my phone, I pasted in the text of the PDF and typed: 'carefully check the math in this paper.' That was it. o1 spotted the error immediately (other AI models did not).
With one day remaining in OpenAI's holiday campaign—today—the AI community watches to see how this unusually active December might reshape the technological landscape heading into 2025. The rapid evolution of this tech, from consumer-level AI to more sophisticated "reasoning" models, points to an industry racing forward at an unprecedented pace—even during what traditionally serves as a quiet period for tech announcements.

Why AI language models choke on too much text
Compute costs scale with the square of the input size. That’s not great.
Why AI language models choke on too much text
Compute costs scale with the square of the input size. That's not great.
Timothy B. Lee – Dec 20, 2024 8:00 AM | 39

Credit: Aurich Lawson | Getty Images
Large language models represent text using tokens, each of which is a few characters. Short words are represented by a single token (like "the" or "it"), whereas larger words may be represented by several tokens (GPT-4o represents "indivisible" with "ind," "iv," and "isible").
When OpenAI released ChatGPT two years ago, it had a memory—known as a context window—of just 8,192 tokens. That works out to roughly 6,000 words of text. This meant that if you fed it more than about 15 pages of text, it would “forget” information from the beginning of its context. This limited the size and complexity of tasks ChatGPT could handle.
Today’s LLMs are far more capable:
- OpenAI’s GPT-4o can handle 128,000 tokens (about 200 pages of text).
- Anthropic’s Claude 3.5 Sonnet can accept 200,000 tokens (about 300 pages of text).
- Google’s Gemini 1.5 Pro allows 2 million tokens (about 2,000 pages of text).
Still, it’s going to take a lot more progress if we want AI systems with human-level cognitive abilities.
Many people envision a future where AI systems are able to do many—perhaps most—of the jobs performed by humans. Yet many human workers read and hear hundreds of millions of words during our working years—and we absorb even more information from sights, sounds, and smells in the world around us. To achieve human-level intelligence, AI systems will need the capacity to absorb similar quantities of information.
Right now the most popular way to build an LLM-based system to handle large amounts of information is called retrieval-augmented generation (RAG). These systems try to find documents relevant to a user’s query and then insert the most relevant documents into an LLM’s context window.
This sometimes works better than a conventional search engine, but today’s RAG systems leave a lot to be desired. They only produce good results if the system puts the most relevant documents into the LLM’s context. But the mechanism used to find those documents—often, searching in a vector database—is not very sophisticated. If the user asks a complicated or confusing question, there’s a good chance the RAG system will retrieve the wrong documents and the chatbot will return the wrong answer.
And RAG doesn’t enable an LLM to reason in more sophisticated ways over large numbers of documents:
- A lawyer might want an AI system to review and summarize hundreds of thousands of emails.
- An engineer might want an AI system to analyze thousands of hours of camera footage from a factory floor.
- A medical researcher might want an AI system to identify trends in tens of thousands of patient records.
Each of these tasks could easily require more than 2 million tokens of context. Moreover, we’re not going to want our AI systems to start with a clean slate after doing one of these jobs. We will want them to gain experience over time, just like human workers do.
Superhuman memory and stamina have long been key selling points for computers. We’re not going to want to give them up in the AI age. Yet today’s LLMs are distinctly subhuman in their ability to absorb and understand large quantities of information.
It’s true, of course, that LLMs absorb superhuman quantities of information at training time. The latest AI models have been trained on trillions of tokens—far more than any human will read or hear. But a lot of valuable information is proprietary, time-sensitive, or otherwise not available for training.
So we’re going to want AI models to read and remember far more than 2 million tokens at inference time. And that won’t be easy.
The key innovation behind transformer-based LLMs is attention, a mathematical operation that allows a model to “think about” previous tokens. (Check out our LLM explainer if you want a detailed explanation of how this works.) Before an LLM generates a new token, it performs an attention operation that compares the latest token to every previous token. This means that conventional LLMs get less and less efficient as the context grows.
Lots of people are working on ways to solve this problem—I’ll discuss some of them later in this article. But first I should explain how we ended up with such an unwieldy architecture.
GPUs made deep learning possible
The “brains” of personal computers are central processing units (CPUs). Traditionally, chipmakers made CPUs faster by increasing the frequency of the clock that acts as its heartbeat. But in the early 2000s, overheating forced chipmakers to mostly abandon this technique.
Chipmakers started making CPUs that could execute more than one instruction at a time. But they were held back by a programming paradigm that requires instructions to mostly be executed in order.
A new architecture was needed to take full advantage of Moore’s Law. Enter Nvidia.
In 1999, Nvidia started selling graphics processing units (GPUs) to speed up the rendering of three-dimensional games like Quake III Arena. The job of these PC add-on cards was to rapidly draw thousands of triangles that made up walls, weapons, monsters, and other objects in a game.
This is not a sequential programming task: triangles in different areas of the screen can be drawn in any order. So rather than having a single processor that executed instructions one at a time, Nvidia’s first GPU had a dozen specialized cores—effectively tiny CPUs—that worked in parallel to paint a scene.
Over time, Moore’s Law enabled Nvidia to make GPUs with tens, hundreds, and eventually thousands of computing cores. People started to realize that the massive parallel computing power of GPUs could be used for applications unrelated to video games.
In 2012, three University of Toronto computer scientists—Alex Krizhevsky, Ilya Sutskever, and Geoffrey Hinton—used a pair of Nvidia GTX 580 GPUs to train a neural network for recognizing images. The massive computing power of those GPUs, which had 512 cores each, allowed them to train a network with a then-impressive 60 million parameters. They entered ImageNet, an academic competition to classify images into one of 1,000 categories, and set a new record for accuracy in image recognition.
Before long, researchers were applying similar techniques to a wide variety of domains, including natural language.
Transformers removed a bottleneck for natural language
In the early 2010s, recurrent neural networks (RNNs) were a popular architecture for understanding natural language. RNNs process language one word at a time. After each word, the network updates its hidden state, a list of numbers that reflects its understanding of the sentence so far.
RNNs worked fairly well on short sentences, but they struggled with longer ones—to say nothing of paragraphs or longer passages. When reasoning about a long sentence, an RNN would sometimes “forget about” an important word early in the sentence. In 2014, computer scientists Dzmitry Bahdanau, Kyunghyun Cho, and Yoshua Bengio discovered they could improve the performance of a recurrent neural network by adding an attention mechanism that allowed the network to “look back” at earlier words in a sentence.
In 2017, Google published “Attention Is All You Need,” one of the most important papers in the history of machine learning. Building on the work of Bahdanau and his colleagues, Google researchers dispensed with the RNN and its hidden states. Instead, Google’s model used an attention mechanism to scan previous words for relevant context.
This new architecture, which Google called the transformer, proved hugely consequential because it eliminated a serious bottleneck to scaling language models.
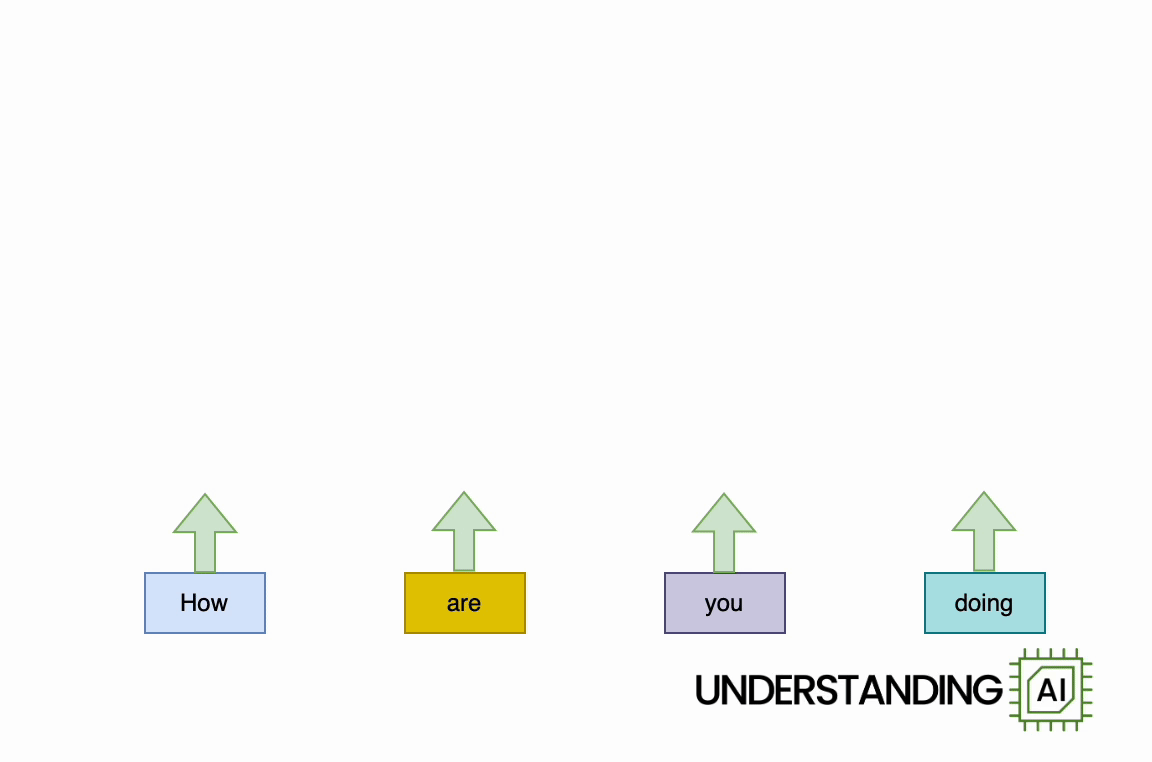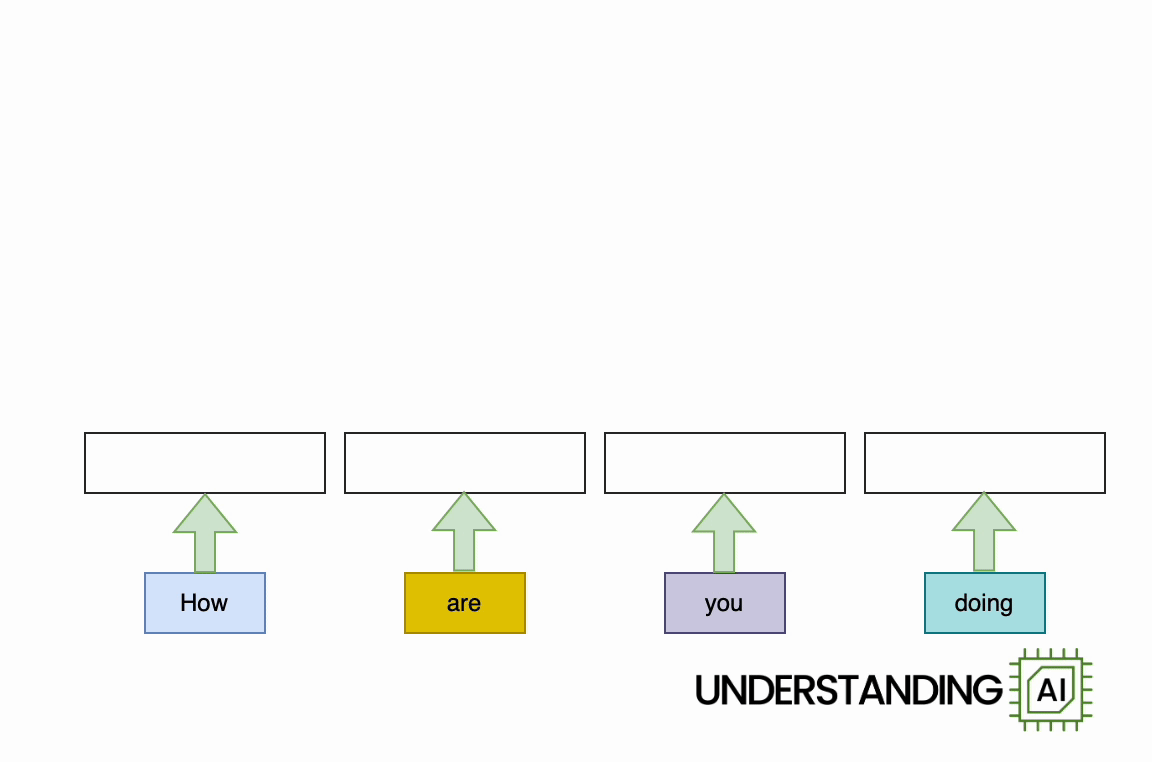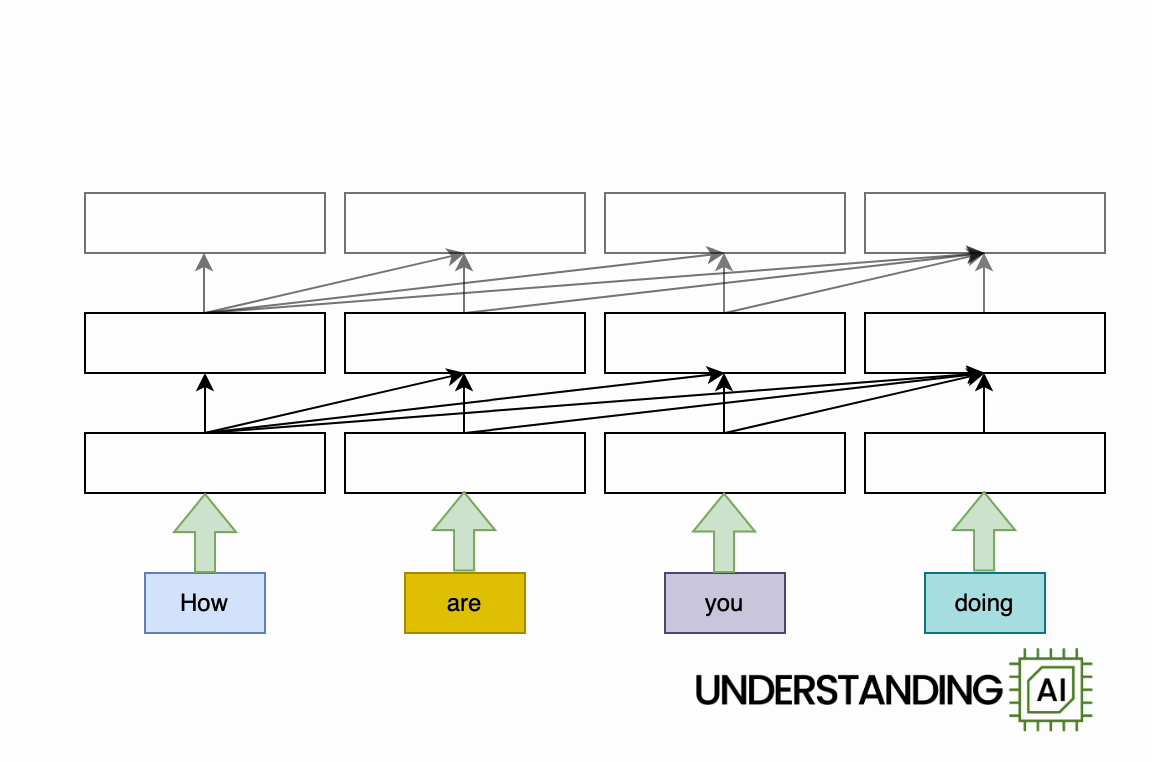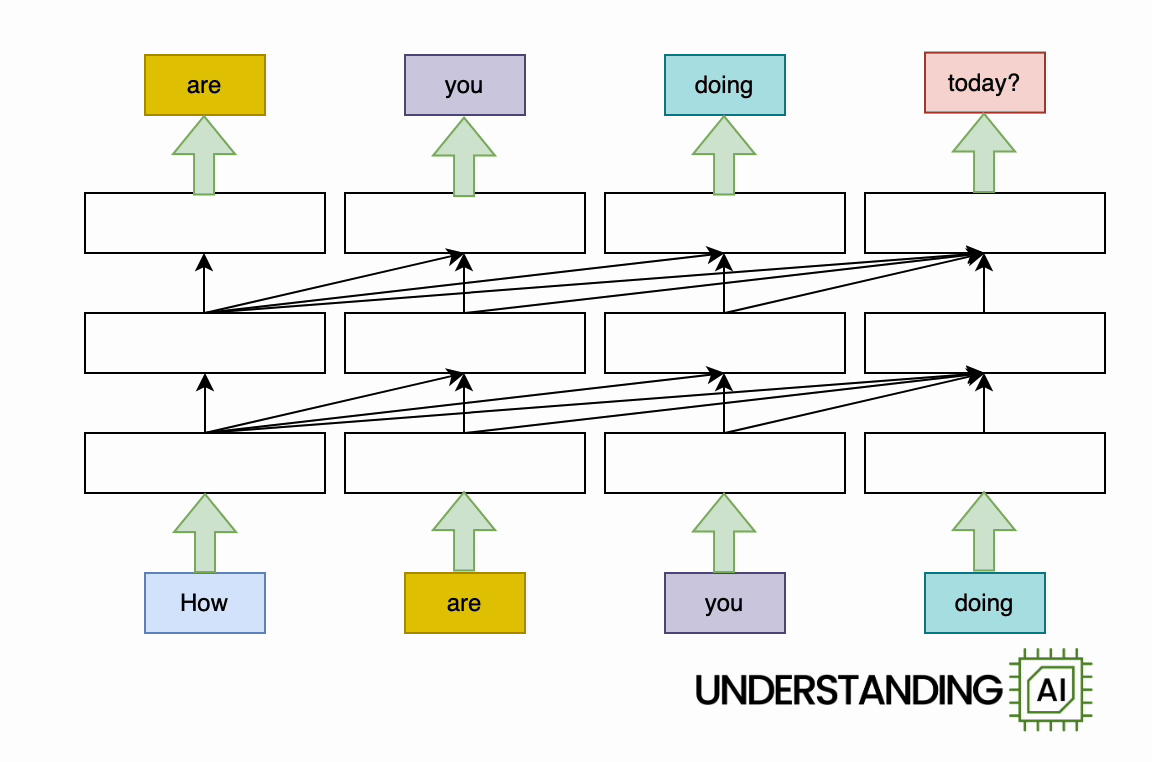
Here’s an animation illustrating why RNNs didn’t scale well:
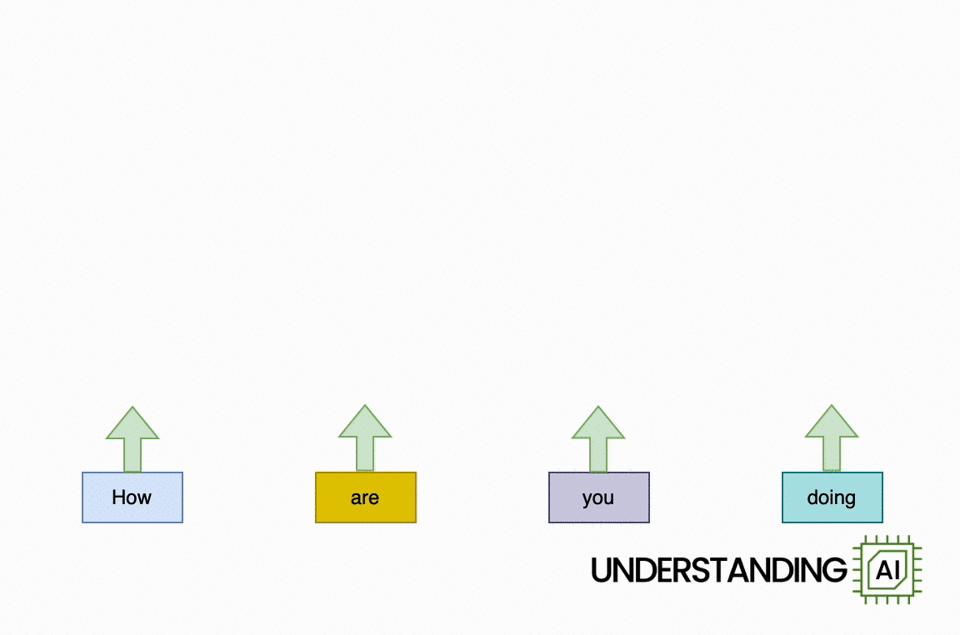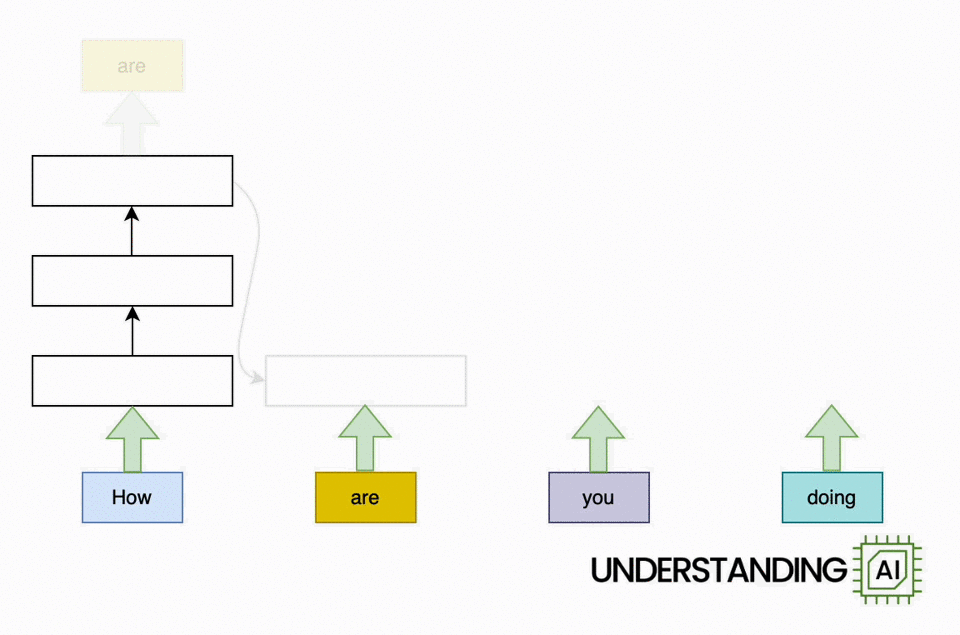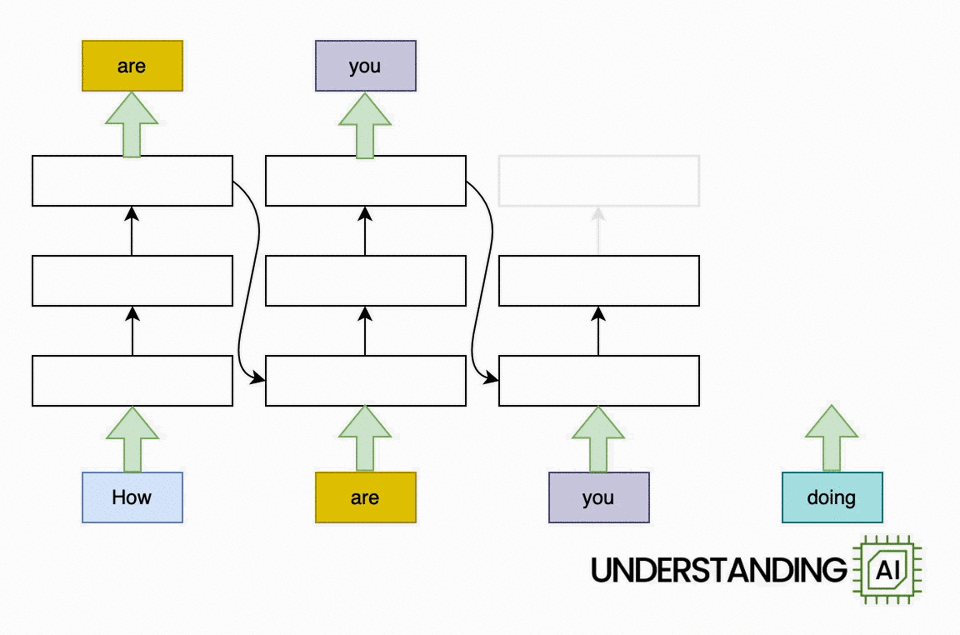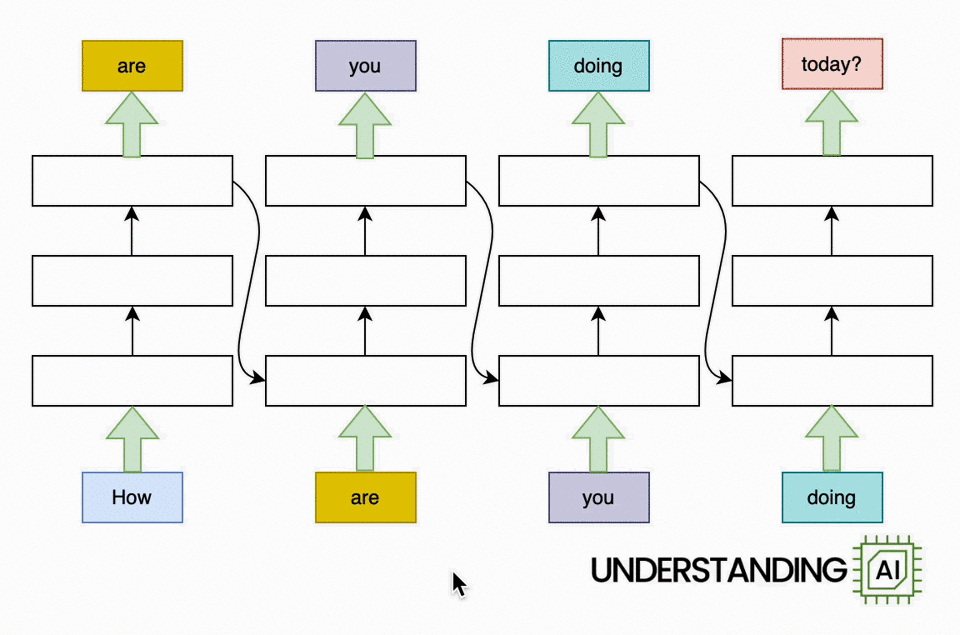
This hypothetical RNN tries to predict the next word in a sentence, with the prediction shown in the top row of the diagram. This network has three layers, each represented by a rectangle. It is inherently linear: it has to complete its analysis of the first word, “How,” before passing the hidden state back to the bottom layer so the network can start to analyze the second word, “are.”
This constraint wasn’t a big deal when machine learning algorithms ran on CPUs. But when people started leveraging the parallel computing power of GPUs, the linear architecture of RNNs became a serious obstacle.
The transformer removed this bottleneck by allowing the network to “think about” all the words in its input at the same time:
The transformer-based model shown here does roughly as many computations as the RNN in the previous diagram. So it might not run any faster on a (single-core) CPU. But because the model doesn’t need to finish with “How” before starting on “are,” “you,” or “doing,” it can work on all of these words simultaneously. So it can run a lot faster on a GPU with many parallel execution units.
How much faster? The potential speed-up is proportional to the number of input words. My animations depict a four-word input that makes the transformer model about four times faster than the RNN. Real LLMs can have inputs thousands of words long. So, with a sufficiently beefy GPU, transformer-based models can be orders of magnitude faster than otherwise similar RNNs.
In short, the transformer unlocked the full processing power of GPUs and catalyzed rapid increases in the scale of language models. Leading LLMs grew from hundreds of millions of parameters in 2018 to hundreds of billions of parameters by 2020. Classic RNN-based models could not have grown that large because their linear architecture prevented them from being trained efficiently on a GPU.
Earlier I said that the recurrent neural network in my animations did “roughly the same amount of work” as the transformer-based network. But they don’t do exactly the same amount of work. Let’s look again at the diagram for the transformer-based model:
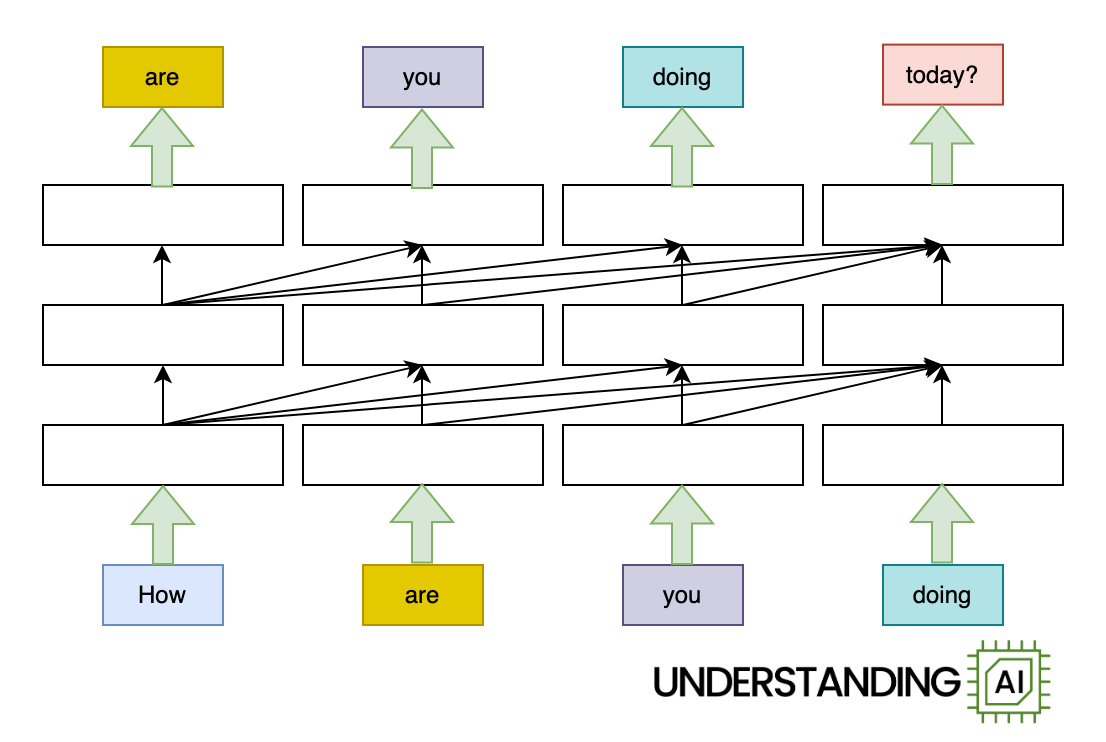
See all those diagonal arrows between the layers? They represent the operation of the attention mechanism. Before a transformer-based language model generates a new token, it “thinks about” every previous token to find the ones that are most relevant.
Each of these comparisons is cheap, computationally speaking. For small contexts—10, 100, or even 1,000 tokens—they are not a big deal. But the computational cost of attention grows relentlessly with the number of preceding tokens. The longer the context gets, the more attention operations (and therefore computing power) are needed to generate the next token.
This means that the total computing power required for attention grows quadratically with the total number of tokens. Suppose a 10-token prompt requires 414,720 attention operations. Then:
This is probably why Google charges twice as much, per token, for Gemini 1.5 Pro once the context gets longer than 128,000 tokens. Generating token number 128,001 requires comparisons with all 128,000 previous tokens, making it significantly more expensive than producing the first or 10th or 100th token.
A lot of effort has been put into optimizing attention. One line of research has tried to squeeze maximum efficiency out of individual GPUs.
As we saw earlier, a modern GPU contains thousands of execution units. Before a GPU can start doing math, it must move data from slow shared memory (called high-bandwidth memory) to much faster memory inside a particular execution unit (called SRAM). Sometimes GPUs spend more time moving data around than performing calculations.
In a series of papers, Princeton computer scientist Tri Dao and several collaborators have developed FlashAttention, which calculates attention in a way that minimizes the number of these slow memory operations. Work like Dao’s has dramatically improved the performance of transformers on modern GPUs.
Another line of research has focused on efficiently scaling attention across multiple GPUs. One widely cited paper describes ring attention, which divides input tokens into blocks and assigns each block to a different GPU. It’s called ring attention because GPUs are organized into a conceptual ring, with each GPU passing data to its neighbor.
I once attended a ballroom dancing class where couples stood in a ring around the edge of the room. After each dance, women would stay where they were while men would rotate to the next woman. Over time, every man got a chance to dance with every woman. Ring attention works on the same principle. The “women” are query vectors (describing what each token is “looking for”) and the “men” are key vectors (describing the characteristics each token has). As the key vectors rotate through a sequence of GPUs, they get multiplied by every query vector in turn.
In short, ring attention distributes attention calculations across multiple GPUs, making it possible for LLMs to have larger context windows. But it doesn’t make individual attention calculations any cheaper.
The fixed-size hidden state of an RNN means that it doesn’t have the same scaling problems as a transformer. An RNN requires about the same amount of computing power to produce its first, hundredth and millionth token. That’s a big advantage over attention-based models.
Although RNNs have fallen out of favor since the invention of the transformer, people have continued trying to develop RNNs suitable for training on modern GPUs.
In April, Google announced a new model called Infini-attention. It’s kind of a hybrid between a transformer and an RNN. Infini-attention handles recent tokens like a normal transformer, remembering them and recalling them using an attention mechanism.
However, Infini-attention doesn’t try to remember every token in a model’s context. Instead, it stores older tokens in a “compressive memory” that works something like the hidden state of an RNN. This data structure can perfectly store and recall a few tokens, but as the number of tokens grows, its recall becomes lossier.
Machine learning YouTuber Yannic Kilcher wasn’t too impressed by Google’s approach.
“I’m super open to believing that this actually does work and this is the way to go for infinite attention, but I’m very skeptical,” Kilcher said. “It uses this compressive memory approach where you just store as you go along, you don’t really learn how to store, you just store in a deterministic fashion, which also means you have very little control over what you store and how you store it.”
Perhaps the most notable effort to resurrect RNNs is Mamba, an architecture that was announced in a December 2023 paper. It was developed by computer scientists Dao (who also did the FlashAttention work I mentioned earlier) and Albert Gu.
Mamba does not use attention. Like other RNNs, it has a hidden state that acts as the model’s “memory.” Because the hidden state has a fixed size, longer prompts do not increase Mamba’s per-token cost.
When I started writing this article in March, my goal was to explain Mamba’s architecture in some detail. But then in May, the researchers released Mamba-2, which significantly changed the architecture from the original Mamba paper. I’ll be frank: I struggled to understand the original Mamba and have not figured out how Mamba-2 works.
But the key thing to understand is that Mamba has the potential to combine transformer-like performance with the efficiency of conventional RNNs.
In June, Dao and Gu co-authored a paper with Nvidia researchers that evaluated a Mamba model with 8 billion parameters. They found that models like Mamba were competitive with comparably sized transformers in a number of tasks, but they “lag behind Transformer models when it comes to in-context learning and recalling information from the context.”
Transformers are good at information recall because they “remember” every token of their context—this is also why they become less efficient as the context grows. In contrast, Mamba tries to compress the context into a fixed-size state, which necessarily means discarding some information from long contexts.
The Nvidia team found they got the best performance from a hybrid architecture that interleaved 24 Mamba layers with four attention layers. This worked better than either a pure transformer model or a pure Mamba model.
A model needs some attention layers so it can remember important details from early in its context. But a few attention layers seem to be sufficient; the rest of the attention layers can be replaced by cheaper Mamba layers with little impact on the model’s overall performance.
In August, an Israeli startup called AI21 announced its Jamba 1.5 family of models. The largest version had 398 billion parameters, making it comparable in size to Meta’s Llama 405B model. Jamba 1.5 Large has seven times more Mamba layers than attention layers. As a result, Jamba 1.5 Large requires far less memory than comparable models from Meta and others. For example, AI21 estimates that Llama 3.1 70B needs 80GB of memory to keep track of 256,000 tokens of context. Jamba 1.5 Large only needs 9GB, allowing the model to run on much less powerful hardware.
The Jamba 1.5 Large model gets an MMLU score of 80, significantly below the Llama 3.1 70B’s score of 86. So by this measure, Mamba doesn’t blow transformers out of the water. However, this may not be an apples-to-apples comparison. Frontier labs like Meta have invested heavily in training data and post-training infrastructure to squeeze a few more percentage points of performance out of benchmarks like MMLU. It’s possible that the same kind of intense optimization could close the gap between Jamba and frontier models.
So while the benefits of longer context windows is obvious, the best strategy to get there is not. In the short term, AI companies may continue using clever efficiency and scaling hacks (like FlashAttention and Ring Attention) to scale up vanilla LLMs. Longer term, we may see growing interest in Mamba and perhaps other attention-free architectures. Or maybe someone will come up with a totally new architecture that renders transformers obsolete.
But I am pretty confident that scaling up transformer-based frontier models isn’t going to be a solution on its own. If we want models that can handle billions of tokens—and many people do—we’re going to need to think outside the box.
Tim Lee was on staff at Ars from 2017 to 2021. Last year, he launched a newsletter, Understanding AI, that explores how AI works and how it's changing our world. You can subscribe here.
How much faster? The potential speed-up is proportional to the number of input words. My animations depict a four-word input that makes the transformer model about four times faster than the RNN. Real LLMs can have inputs thousands of words long. So, with a sufficiently beefy GPU, transformer-based models can be orders of magnitude faster than otherwise similar RNNs.
In short, the transformer unlocked the full processing power of GPUs and catalyzed rapid increases in the scale of language models. Leading LLMs grew from hundreds of millions of parameters in 2018 to hundreds of billions of parameters by 2020. Classic RNN-based models could not have grown that large because their linear architecture prevented them from being trained efficiently on a GPU.
Transformers have a scaling problem
Earlier I said that the recurrent neural network in my animations did “roughly the same amount of work” as the transformer-based network. But they don’t do exactly the same amount of work. Let’s look again at the diagram for the transformer-based model:
See all those diagonal arrows between the layers? They represent the operation of the attention mechanism. Before a transformer-based language model generates a new token, it “thinks about” every previous token to find the ones that are most relevant.
Each of these comparisons is cheap, computationally speaking. For small contexts—10, 100, or even 1,000 tokens—they are not a big deal. But the computational cost of attention grows relentlessly with the number of preceding tokens. The longer the context gets, the more attention operations (and therefore computing power) are needed to generate the next token.
This means that the total computing power required for attention grows quadratically with the total number of tokens. Suppose a 10-token prompt requires 414,720 attention operations. Then:
- Processing a 100-token prompt will require 45.6 million attention operations.
- Processing a 1,000-token prompt will require 4.6 billion attention operations.
- Processing a 10,000-token prompt will require 460 billion attention operations.
This is probably why Google charges twice as much, per token, for Gemini 1.5 Pro once the context gets longer than 128,000 tokens. Generating token number 128,001 requires comparisons with all 128,000 previous tokens, making it significantly more expensive than producing the first or 10th or 100th token.
Making attention more efficient and scalable
A lot of effort has been put into optimizing attention. One line of research has tried to squeeze maximum efficiency out of individual GPUs.
As we saw earlier, a modern GPU contains thousands of execution units. Before a GPU can start doing math, it must move data from slow shared memory (called high-bandwidth memory) to much faster memory inside a particular execution unit (called SRAM). Sometimes GPUs spend more time moving data around than performing calculations.
In a series of papers, Princeton computer scientist Tri Dao and several collaborators have developed FlashAttention, which calculates attention in a way that minimizes the number of these slow memory operations. Work like Dao’s has dramatically improved the performance of transformers on modern GPUs.
Another line of research has focused on efficiently scaling attention across multiple GPUs. One widely cited paper describes ring attention, which divides input tokens into blocks and assigns each block to a different GPU. It’s called ring attention because GPUs are organized into a conceptual ring, with each GPU passing data to its neighbor.
I once attended a ballroom dancing class where couples stood in a ring around the edge of the room. After each dance, women would stay where they were while men would rotate to the next woman. Over time, every man got a chance to dance with every woman. Ring attention works on the same principle. The “women” are query vectors (describing what each token is “looking for”) and the “men” are key vectors (describing the characteristics each token has). As the key vectors rotate through a sequence of GPUs, they get multiplied by every query vector in turn.
In short, ring attention distributes attention calculations across multiple GPUs, making it possible for LLMs to have larger context windows. But it doesn’t make individual attention calculations any cheaper.
Could RNNs make a comeback?
The fixed-size hidden state of an RNN means that it doesn’t have the same scaling problems as a transformer. An RNN requires about the same amount of computing power to produce its first, hundredth and millionth token. That’s a big advantage over attention-based models.
Although RNNs have fallen out of favor since the invention of the transformer, people have continued trying to develop RNNs suitable for training on modern GPUs.
In April, Google announced a new model called Infini-attention. It’s kind of a hybrid between a transformer and an RNN. Infini-attention handles recent tokens like a normal transformer, remembering them and recalling them using an attention mechanism.
However, Infini-attention doesn’t try to remember every token in a model’s context. Instead, it stores older tokens in a “compressive memory” that works something like the hidden state of an RNN. This data structure can perfectly store and recall a few tokens, but as the number of tokens grows, its recall becomes lossier.
Machine learning YouTuber Yannic Kilcher wasn’t too impressed by Google’s approach.
“I’m super open to believing that this actually does work and this is the way to go for infinite attention, but I’m very skeptical,” Kilcher said. “It uses this compressive memory approach where you just store as you go along, you don’t really learn how to store, you just store in a deterministic fashion, which also means you have very little control over what you store and how you store it.”
Could Mamba be the future?
Perhaps the most notable effort to resurrect RNNs is Mamba, an architecture that was announced in a December 2023 paper. It was developed by computer scientists Dao (who also did the FlashAttention work I mentioned earlier) and Albert Gu.
Mamba does not use attention. Like other RNNs, it has a hidden state that acts as the model’s “memory.” Because the hidden state has a fixed size, longer prompts do not increase Mamba’s per-token cost.
When I started writing this article in March, my goal was to explain Mamba’s architecture in some detail. But then in May, the researchers released Mamba-2, which significantly changed the architecture from the original Mamba paper. I’ll be frank: I struggled to understand the original Mamba and have not figured out how Mamba-2 works.
But the key thing to understand is that Mamba has the potential to combine transformer-like performance with the efficiency of conventional RNNs.
In June, Dao and Gu co-authored a paper with Nvidia researchers that evaluated a Mamba model with 8 billion parameters. They found that models like Mamba were competitive with comparably sized transformers in a number of tasks, but they “lag behind Transformer models when it comes to in-context learning and recalling information from the context.”
Transformers are good at information recall because they “remember” every token of their context—this is also why they become less efficient as the context grows. In contrast, Mamba tries to compress the context into a fixed-size state, which necessarily means discarding some information from long contexts.
The Nvidia team found they got the best performance from a hybrid architecture that interleaved 24 Mamba layers with four attention layers. This worked better than either a pure transformer model or a pure Mamba model.
A model needs some attention layers so it can remember important details from early in its context. But a few attention layers seem to be sufficient; the rest of the attention layers can be replaced by cheaper Mamba layers with little impact on the model’s overall performance.
In August, an Israeli startup called AI21 announced its Jamba 1.5 family of models. The largest version had 398 billion parameters, making it comparable in size to Meta’s Llama 405B model. Jamba 1.5 Large has seven times more Mamba layers than attention layers. As a result, Jamba 1.5 Large requires far less memory than comparable models from Meta and others. For example, AI21 estimates that Llama 3.1 70B needs 80GB of memory to keep track of 256,000 tokens of context. Jamba 1.5 Large only needs 9GB, allowing the model to run on much less powerful hardware.
The Jamba 1.5 Large model gets an MMLU score of 80, significantly below the Llama 3.1 70B’s score of 86. So by this measure, Mamba doesn’t blow transformers out of the water. However, this may not be an apples-to-apples comparison. Frontier labs like Meta have invested heavily in training data and post-training infrastructure to squeeze a few more percentage points of performance out of benchmarks like MMLU. It’s possible that the same kind of intense optimization could close the gap between Jamba and frontier models.
So while the benefits of longer context windows is obvious, the best strategy to get there is not. In the short term, AI companies may continue using clever efficiency and scaling hacks (like FlashAttention and Ring Attention) to scale up vanilla LLMs. Longer term, we may see growing interest in Mamba and perhaps other attention-free architectures. Or maybe someone will come up with a totally new architecture that renders transformers obsolete.
But I am pretty confident that scaling up transformer-based frontier models isn’t going to be a solution on its own. If we want models that can handle billions of tokens—and many people do—we’re going to need to think outside the box.
Tim Lee was on staff at Ars from 2017 to 2021. Last year, he launched a newsletter, Understanding AI, that explores how AI works and how it's changing our world. You can subscribe here.

Not to be outdone by OpenAI, Google releases its own “reasoning” AI model
Gemini 2.0 Flash Thinking is Google’s take on so-called AI reasoning models.
Not to be outdone by OpenAI, Google releases its own “reasoning” AI model
Gemini 2.0 Flash Thinking is Google's take on so-called AI reasoning models.
Benj Edwards – Dec 19, 2024 4:49 PM |
96

Credit: Alan Schein via Getty Images
It's been a really busy month for Google as it apparently endeavors to outshine OpenAI with a blitz of AI releases. On Thursday, Google dropped its latest party trick: Gemini 2.0 Flash Thinking Experimental, which is a new AI model that uses runtime "reasoning" techniques similar to OpenAI's o1 to achieve "deeper thinking" on problems fed into it.
The experimental model builds on Google's newly released Gemini 2.0 Flash and runs on its AI Studio platform, but early tests conducted by TechCrunch reporter Kyle Wiggers reveal accuracy issues with some basic tasks, such as incorrectly counting that the word "strawberry" contains two R's.
These so-called reasoning models differ from standard AI models by incorporating feedback loops of self-checking mechanisms, similar to techniques we first saw in early 2023 with hobbyist projects like "Baby AGI." The process requires more computing time, often adding extra seconds or minutes to response times. Companies have turned to reasoning models as traditional scaling methods at training time have been showing diminishing returns.
Google DeepMind's chief scientist, Jeff Dean, says that the model receives extra computing power, writing on X, "we see promising results when we increase inference time computation!" The model works by pausing to consider multiple related prompts before providing what it determines to be the most accurate answer.
Since OpenAI's jump into the "reasoning" field in September with o1-preview and o1-mini, several companies have been rushing to achieve feature parity with their own models. For example, DeepSeek launched DeepSeek-R1 in early November, while Alibaba's Qwen team released its own "reasoning" model, QwQ earlier this month.
While some claim that reasoning models can help solve complex mathematical or academic problems, these models might not be for everybody. While they perform well on some benchmarks, questions remain about their actual usefulness and accuracy. Also, the high computing costs needed to run reasoning models have created some rumblings about their long-term viability. That high cost is why OpenAI's ChatGPT Pro costs $200 a month, for example.
Still, it appears Google is serious about pursuing this particular AI technique. Logan Kilpatrick, a Google employee in its AI Studio, called it "the first step in our reasoning journey" in a post on X.

New physics sim trains robots 430,000 times faster than reality
“Genesis” can compress training times from decades into hours using 3D worlds conjured from text.
New physics sim trains robots 430,000 times faster than reality
"Genesis" can compress training times from decades into hours using 3D worlds conjured from text.
Benj Edwards – Dec 19, 2024 3:10 PM |
55

A simulated teapot and letters created using the Genesis platform. Credit: Zhou et al.
On Thursday, a large group of university and private industry researchers unveiled Genesis, a new open source computer simulation system that lets robots practice tasks in simulated reality 430,000 times faster than in the real world. Researchers can also use an AI agent to generate 3D physics simulations from text prompts.
The accelerated simulation means a neural network for piloting robots can spend the virtual equivalent of decades learning to pick up objects, walk, or manipulate tools during just hours of real computer time.
"One hour of compute time gives a robot 10 years of training experience. That's how Neo was able to learn martial arts in a blink of an eye in the Matrix Dojo," wrote Genesis paper co-author Jim Fan on X, who says he played a "minor part" in the research. Fan has previously worked on several robotics simulation projects for Nvidia.
Genesis arrives as robotics researchers hunt for better tools to test and train robots in virtual environments before deploying them in the real world. Fast, accurate simulation helps robots learn complex tasks more quickly while reducing the need for expensive physical testing. For example, on this project page, the researchers show techniques developed in Genesis physics simulations (such as doing backflips) being applied to quadruped robots and soft robots.

Example images of the simulated physics-based worlds created by Genesis, provided by the researchers. Credit: Zhou et al.
The Genesis platform, developed by a group led by Zhou Xian of Carnegie Mellon University, processes physics calculations up to 80 times faster than existing robot simulators ( like Nvidia's Isaac Gym). It uses graphics cards similar to those that power video games to run up to 100,000 copies of a simulation at once. That's important when it comes to training the neural networks that will control future real-world robots.
"If an AI can control 1,000 robots to perform 1 million skills in 1 billion different simulations, then it may 'just work' in our real world, which is simply another point in the vast space of possible realities," wrote Fan in his X post. "This is the fundamental principle behind why simulation works so effectively for robotics."
Generating dynamic worlds
The team also announced the ability to generate what it calls "4D dynamic worlds"—perhaps using "4D" because they can simulate a 3D world in motion over time. The system uses vision-language models (VLMs) to generate complete virtual environments from text descriptions (similar to "prompts" in other AI models), utilizing Genesis's own simulation infrastructure APIs to create the worlds.The AI-generated worlds reportedly include realistic physics, camera movements, and object behaviors, all from text commands. The system then creates physically accurate ray-traced videos and data that robots can use for training.
Examples of "4D dynamical and physical" worlds that Genesis created from text prompts.
This prompt-based system lets researchers create complex robot testing environments by typing natural language commands instead of programming them by hand. "Traditionally, simulators require a huge amount of manual effort from artists: 3D assets, textures, scene layouts, etc. But every component in the workflow can be automated," wrote Fan.
Using its engine, Genesis can also generate character motion, interactive 3D scenes, facial animation, and more, which may allow for the creation of artistic assets for creative projects, but may also lead to more realistic AI-generated games and videos in the future, constructing a simulated world in data instead of operating on the statistical appearance of pixels as with a video synthesis diffusion model.
Examples of character motion generation from Genesis, using a prompt that includes, "A miniature Wukong holding a stick in his hand sprints across a table surface for 3 seconds, then jumps into the air, and swings his right arm downward during landing."
While the generative system isn't yet part of the currently available code on GitHub, the team plans to release it in the future.
Training tomorrow’s robots today (using Python)
Genesis remains under active development on GitHub, where the team accepts community contributions.The platform stands out from other 3D world simulators for robotic training by using Python for both its user interface and core physics engine. Other engines use C++ or CUDA for their underlying calculations while wrapping them in Python APIs. Genesis takes a Python-first approach.
Notably, the non-proprietary nature of the Genesis platform makes high-speed robot training simulations available to any researcher for free through simple Python commands that work on regular computers with off-the-shelf hardware.
Previously, running robot simulations required complex programming and specialized hardware, says Fan in his post announcing Genesis, and that shouldn't be the case. "Robotics should be a moonshot initiative owned by all of humanity," he wrote.[]

A new, uncensored AI video model may spark a new AI hobbyist movement
Will Tencent’s “open source” HunyuanVideo launch an at-home “Stable Diffusion” moment for uncensored AI video?
A new, uncensored AI video model may spark a new AI hobbyist movement
Will Tencent's "open source" HunyuanVideo launch an at-home "Stable Diffusion" moment for uncensored AI video?
Benj Edwards – Dec 19, 2024 10:50 AM |
112

Still images from three videos generated with Tencent's HunyuanVideo. Credit: Tencent
The AI-generated video scene has been hopping this year (or twirling wildly, as the case may be). This past week alone we've seen releases or announcements of OpenAI's Sora, Pika AI's Pika 2, Google's Veo 2, and Minimax's video-01-live. It's frankly hard to keep up, and even tougher to test them all. But recently, we put a new open-weights AI video synthesis model, Tencent's HunyuanVideo, to the test—and it's surprisingly capable for being a "free" model.
Unlike the aforementioned models, HunyuanVideo's neural network weights are openly distributed, which means they can be run locally under the right circumstances (people have already demonstrated it on a consumer 24 GB VRAM GPU) and it can be fine-tuned or used with LoRAs to teach it new concepts.
Notably, a few Chinese companies have been at the forefront of AI video for most of this year, and some experts speculate that the reason is less reticence to train on copyrighted materials, use images and names of famous celebrities, and incorporate some uncensored video sources. As we saw with Stable Diffusion 3's mangled release, including nudity or pornography in training data may allow these models achieve better results by providing more information about human bodies. HunyuanVideo notably allows uncensored outputs, so unlike the commercial video models out there, it can generate videos of anatomically realistic, nude humans.
Putting HunyuanVideo to the test
To evaluate HunyuanVideo, we provided it with an array of prompts that we used on Runway's Gen-3 Alpha and Minimax's video-01 earlier this year. That way, it's easy to revisit those earlier articles and compare the results.We generated each of the five-second-long 864 × 480 videos seen below using a commercial cloud AI provider. Each video generation took about seven to nine minutes to complete. Since the generations weren't free (each cost about $0.70 to make), we went with the first result for each prompt, so there's no cherry-picking below. Everything you see was the first generation for the prompt listed above it.
"A highly intelligent person reading 'Ars Technica' on their computer when the screen explodes"
"commercial for a new flaming cheeseburger from McDonald's"
"A cat in a car drinking a can of beer, beer commercial"
"Will Smith eating spaghetti"
"Robotic humanoid animals with vaudeville costumes roam the streets collecting protection money in tokens"
"A basketball player in a haunted passenger train car with a basketball court, and he is playing against a team of ghosts"
"A beautiful queen of the universe in a radiant dress smiling as a star field swirls around her"
"A herd of one million cats running on a hillside, aerial view"
"Video game footage of a dynamic 1990s third-person 3D platform game starring an anthropomorphic shark boy"
"A muscular barbarian breaking a CRT television set with a weapon, cinematic, 8K, studio lighting"
"A scared woman in a Victorian outfit running through a forest, dolly shot"
"Low angle static shot: A teddy bear sitting on a picnic blanket in a park, eating a slice of pizza. The teddy bear is brown and fluffy, with a red bowtie, and the pizza slice is gooey with cheese and pepperoni. The sun is setting, casting a golden glow over the scene"
"Aerial shot of a small American town getting deluged with liquid cheese after a massive cheese rainstorm where liquid cheese rained down and dripped all over the buildings"
Also, we added a new one: "A young woman doing a complex floor gymnastics routine at the Olympics, featuring running and flips."
Weighing the results
Overall, the results shown above seem fairly comparable to Gen-3 Alpha and Minimax video-01, and that's notable because HunyuanVideo can be downloaded for free, fine-tuned, and run locally in an uncensored way (given the appropriate hardware).There are some flaws, of course. The vaudeville robots are not animals, the cat is drinking from a weird transparent beer can, and the man eating spaghetti is obviously not Will Smith. There appears to be some celebrity censorship in the metadata/labeling of the training data, which differs from Kling and Minimax's AI video offerings. And yes, the gymnast has some anatomical issues.
Right now, HunyuanVideo's results are fairly rough, especially compared to the state-of-the-art video synthesis model to beat at the moment, the newly-unveiled Google Veo 2. We ran a few of these prompts through Sora as well (more on that later in a future article), and Sora created more coherent results than HunyuanVideo but didn't deliver on the prompts with much fidelity. We are still early days of AI, but quality is rapidly improving while models are getting smaller and more efficient.
Even with these limitations, judging from the history of Stable Diffusion and its offshoots, HunyuanVideo may still have significant impact: It could be fine-tuned at higher resolutions over time to eventually create higher-quality results for free that may be used in video productions, or it could lead to people making bespoke video pornography, which is already beginning to appear in trickles on Reddit.
As we've mentioned before in previous AI video overviews, text-to-video models work by combining concepts from their training data—existing video clips used to create the model. Every AI model on the market has some degree of trouble with new scenarios not found in their training data, and that limitation persists with HunyuanVideo.
Future versions of HunyuanVideo could improve with better prompt interpretation, different training data sets, increased computing power during training, or changes in the model design. Like all AI video synthesis models today, users still need to run multiple generations to get desired results. But it looks like the “open weights” AI video models are already here to stay.[]

Are LLMs capable of non-verbal reasoning?
Processing in the “latent space” could help AI with tricky logical questions.
Are LLMs capable of non-verbal reasoning?
Processing in the "latent space" could help AI with tricky logical questions.
Kyle Orland – Dec 12, 2024 4:55 PM |
309

It's thinking, but not in words. Credit: Getty Images
Large language models have found great success so far by using their transformer architecture to effectively predict the next words (i.e., language tokens) needed to respond to queries. When it comes to complex reasoning tasks that require abstract logic, though, some researchers have found that interpreting everything through this kind of "language space" can start to cause some problems, even for modern "reasoning" models.
Now, researchers are trying to work around these problems by crafting models that can work out potential logical solutions completely in "latent space"—the hidden computational layer just before the transformer generates language. While this approach doesn't cause a sea change in an LLM's reasoning capabilities, it does show distinct improvements in accuracy for certain types of logical problems and shows some interesting directions for new research.
Wait, what space?
Modern reasoning models like ChatGPT's o1 tend to work by generating a "chain of thought." Each step of the logical process in these models is expressed as a sequence of natural language word tokens that are fed back through the model.In a new paper, researchers at Meta's Fundamental AI Research team (FAIR) and UC San Diego identify this reliance on natural language and "word tokens" as a "fundamental constraint" for these reasoning models. That's because the successful completion of reasoning tasks often requires complex planning on specific critical tokens to figure out the right logical path from a number of options.
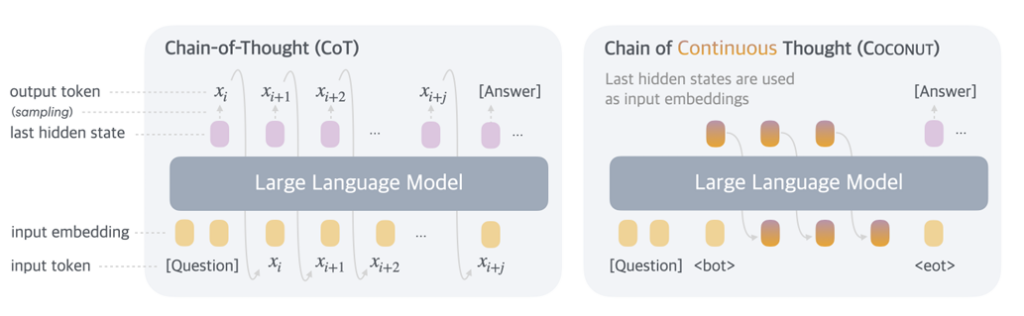
A figure illustrating the difference between standard models going through a transformer after every step and the COCONUT model's use of hidden, "latent" states. Credit: Training Large Language Models to Reason in a Continuous Latent Space
In current chain-of-thought models, though, word tokens are often generated for "textual coherence" and "fluency" while "contributing little to the actual reasoning process," the researchers write. Instead, they suggest, "it would be ideal for LLMs to have the freedom to reason without any language constraints and then translate their findings into language only when necessary."
To achieve that "ideal," the researchers describe a method for "Training Large Language Models to Reason in a Continuous Latent Space," as the paper's title puts it. That "latent space" is essentially made up of the "hidden" set of intermediate token weightings that the model contains just before the transformer generates a human-readable natural language version of that internal state.
In the researchers' COCONUT model (for Chain Of CONtinUous Thought), those kinds of hidden states are encoded as "latent thoughts" that replace the individual written steps in a logical sequence both during training and when processing a query. This avoids the need to convert to and from natural language for each step and "frees the reasoning from being within the language space," the researchers write, leading to an optimized reasoning path that they term a "continuous thought."
Being more breadth-minded
While doing logical processing in the latent space has some benefits for model efficiency, the more important finding is that this kind of model can "encode multiple potential next steps simultaneously." Rather than having to pursue individual logical options fully and one by one (in a "greedy" sort of process), staying in the "latent space" allows for a kind of instant backtracking that the researchers compare to a breadth-first-search through a graph.This emergent, simultaneous processing property comes through in testing even though the model isn't explicitly trained to do so, the researchers write. "While the model may not initially make the correct decision, it can maintain many possible options within the continuous thoughts and progressively eliminate incorrect paths through reasoning, guided by some implicit value functions," they write.
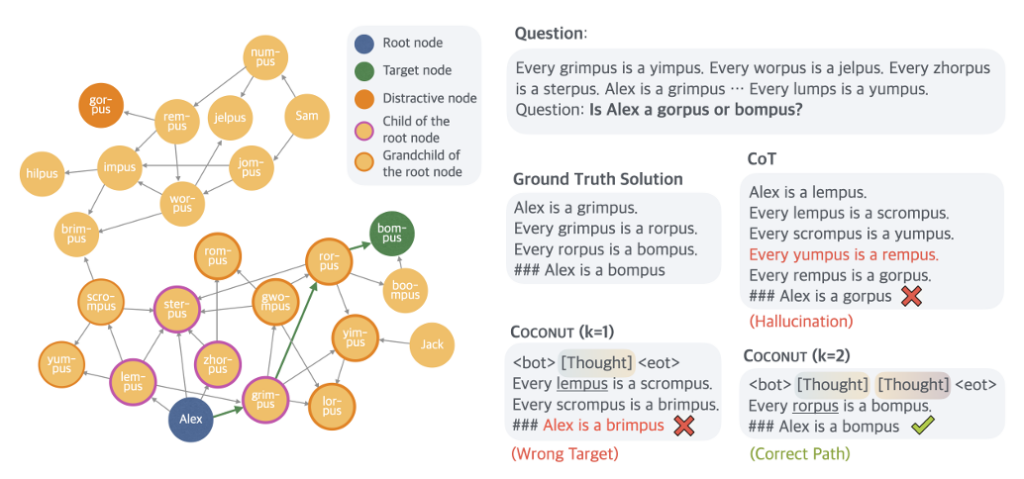
A figure highlighting some of the ways different models can fail at certain types of logical inference. Credit: Training Large Language Models to Reason in a Continuous Latent Space
That kind of multi-path reasoning didn't really improve COCONUT's accuracy over traditional chain-of-thought models on relatively straightforward tests of math reasoning (GSM8K) or general reasoning (ProntoQA). But the researchers found the model did comparatively well on a randomly generated set of ProntoQA-style queries involving complex and winding sets of logical conditions (e.g., "every apple is a fruit, every fruit is food, etc.").
For these tasks, standard chain-of-thought reasoning models would often get stuck down dead-end paths of inference or even hallucinate completely made-up rules when trying to resolve the logical chain. Previous research has also shown that the "verbalized" logical steps output by these chain-of-thought models "may actually utilize a different latent reasoning process" than the one being shared.
This new research joins a growing body of research seeking to understand and exploit the way large language models work at the level of their underlying neural networks. And while that kind of research hasn't led to a huge breakthrough just yet, the researchers conclude that models pre-trained with these kinds of "continuous thoughts" from the get-go could "enable models to generalize more effectively across a wider range of reasoning scenarios."[]

OpenAI announces o3 and o3-mini, its next simulated reasoning models
o3 matches human levels on ARC-AGI benchmark, and o3-mini exceeds o1 at some tasks.
OpenAI announces o3 and o3-mini, its next simulated reasoning models
o3 matches human levels on ARC-AGI benchmark, and o3-mini exceeds o1 at some tasks.
Benj Edwards – Dec 20, 2024 2:31 PM |
60

Credit: Benj Edwards / Andriy Onufriyenko via Getty Images
On Friday, during Day 12 of its "12 days of OpenAI," OpenAI CEO Sam Altman announced its latest AI "reasoning" models, o3 and o3-mini, which build upon the o1 models launched earlier this year. The company is not releasing them yet but will make these models available for public safety testing and research access today.
The models use what OpenAI calls "private chain of thought," where the model pauses to examine its internal dialog and plan ahead before responding, which you might call "simulated reasoning" (SR)—a form of AI that goes beyond basic large language models (LLMs).
The company named the model family "o3" instead of "o2" to avoid potential trademark conflicts with British telecom provider O2, according to The Information. During Friday's livestream, Altman acknowledged his company's naming foibles, saying, "In the grand tradition of OpenAI being really, truly bad at names, it'll be called o3."
According to OpenAI, the o3 model earned a record-breaking score on the ARC-AGI benchmark, a visual reasoning benchmark that has gone unbeaten since its creation in 2019. In low-compute scenarios, o3 scored 75.7 percent, while in high-compute testing, it reached 87.5 percent—comparable to human performance at an 85 percent threshold.
OpenAI also reported that o3 scored 96.7 percent on the 2024 American Invitational Mathematics Exam, missing just one question. The model also reached 87.7 percent on GPQA Diamond, which contains graduate-level biology, physics, and chemistry questions. On the Frontier Math benchmark by EpochAI, o3 solved 25.2 percent of problems, while no other model has exceeded 2 percent.
During the livestream, the president of the ARC Prize Foundation said, "When I see these results, I need to switch my worldview about what AI can do and what it is capable of."
The o3-mini variant, also announced Friday, includes an adaptive thinking time feature, offering low, medium, and high processing speeds. The company states that higher compute settings produce better results. OpenAI reports that o3-mini outperforms its predecessor, o1, on the Codeforces benchmark.
Simulated reasoning on the rise
OpenAI's announcement comes as other companies develop their own SR models, including Google, which announced Gemini 2.0 Flash Thinking Experimental on Thursday. In November, DeepSeek launched DeepSeek-R1, while Alibaba's Qwen team released QwQ, what they called the first "open" alternative to o1.These new AI models are based on traditional LLMs, but with a twist: They are fine-tuned to produce a type of iterative chain of thought process that can consider its own results, simulating reasoning in an almost brute-force way that can be scaled at inference (running) time, instead of focusing on improvements during AI model training, which has seen diminishing returns recently.
OpenAI will make the new SR models available first to safety researchers for testing. Altman said the company plans to launch o3-mini in late January, with o3 following shortly after.[]

Twirling body horror in gymnastics video exposes AI’s flaws
Nonsensical jabberwocky movements created by OpenAI’s Sora are typical for current AI-generated video, and here’s why.
Twirling body horror in gymnastics video exposes AI’s flaws
Nonsensical jabberwocky movements created by OpenAI’s Sora are typical for current AI-generated video, and here's why.
Benj Edwards – Dec 13, 2024 9:12 AM |
188
 https://cdn.arstechnica.net/wp-content/uploads/2024/12/ai_gymnast_FZRruUsWofE3oPMs.mp4
https://cdn.arstechnica.net/wp-content/uploads/2024/12/ai_gymnast_FZRruUsWofE3oPMs.mp4A still image from an AI-generated video of an ever-morphing synthetic gymnast. Credit: OpenAI / Deedy
On Wednesday, a video from OpenAI's newly launched Sora AI video generator went viral on social media, featuring a gymnast who sprouts extra limbs and briefly loses her head during what appears to be an Olympic-style floor routine.
As it turns out, the nonsensical synthesis errors in the video—what we like to call "jabberwockies"—hint at technical details about how AI video generators work and how they might get better in the future.
But before we dig into the details, let's take a look at the video.
An AI-generated video of an impossible gymnast, created with OpenAI Sora.
In the video, we see a view of what looks like a floor gymnastics routine. The subject of the video flips and flails as new legs and arms rapidly and fluidly emerge and morph out of her twirling and transforming body. At one point, about 9 seconds in, she loses her head, and it reattaches to her body spontaneously.
"As cool as the new Sora is, gymnastics is still very much the Turing test for AI video," wrote venture capitalist Deedy Das when he originally shared the video on X. The video inspired plenty of reaction jokes, such as this reply to a similar post on Bluesky: "hi, gymnastics expert here! this is not funny, gymnasts only do this when they’re in extreme distress."
We reached out to Das, and he confirmed that he generated the video using Sora. He also provided the prompt, which was very long and split into four parts, generated by Anthropic's Claude, using complex instructions like "The gymnast initiates from the back right corner, taking position with her right foot pointed behind in B-plus stance."
"I've known for the last 6 months having played with text to video models that they struggle with complex physics movements like gymnastics," Das told us in a conversation. "I had to try it [in Sora] because the character consistency seemed improved. Overall, it was an improvement because previously... the gymnast would just teleport away or change their outfit mid flip, but overall it still looks downright horrifying. We hoped AI video would learn physics by default, but that hasn't happened yet!"
So what went wrong?
When examining how the video fails, you must first consider how Sora "knows" how to create anything that resembles a gymnastics routine. During the training phase, when the Sora model was created, OpenAI fed example videos of gymnastics routines (among many other types of videos) into a specialized neural network that associates the progression of images with text-based descriptions of them.That type of training is a distinct phase that happens once before the model's release. Later, when the finished model is running and you give a video-synthesis model like Sora a written prompt, it draws upon statistical associations between words and images to produce a predictive output. It's continuously making next-frame predictions based on the last frame of the video. But Sora has another trick for attempting to preserve coherency over time. "By giving the model foresight of many frames at a time," reads OpenAI's Sora System Card, we've solved a challenging problem of making sure a subject stays the same even when it goes out of view temporarily."

A still image from a moment where the AI-generated gymnast loses her head. It soon reattaches to her body. Credit: OpenAI / Deedy
Maybe not quite solved yet. In this case, rapidly moving limbs prove a particular challenge when attempting to predict the next frame properly. The result is an incoherent amalgam of gymnastics footage that shows the same gymnast performing running flips and spins, but Sora doesn't know the correct order in which to assemble them because it's pulling on statistical averages of wildly different body movements in its relatively limited training data of gymnastics videos, which also likely did not include limb-level precision in its descriptive metadata.
Sora doesn't know anything about physics or how the human body should work, either. It's drawing upon statistical associations between pixels in the videos in its training dataset to predict the next frame, with a little bit of look-ahead to keep things more consistent.
This problem is not unique to Sora. All AI video generators can produce wildly nonsensical results when your prompts reach too far past their training data, as we saw earlier this year when testing Runway's Gen-3. In fact, we ran some gymnast prompts through the latest open source AI video model that may rival Sora in some ways, Hunyuan Video, and it produced similar twirling, morphing results, seen below. And we used a much simpler prompt than Das did with Sora.
An example from open source Chinese AI model Hunyuan Video with the prompt, "A young woman doing a complex floor gymnastics routine at the olympics, featuring running and flips."
AI models based on transformer technology are fundamentally imitative in nature. They're great at transforming one type of data into another type or morphing one style into another. What they're not great at (yet) is producing coherent generations that are truly original. So if you happen to provide a prompt that closely matches a training video, you might get a good result. Otherwise, you may get madness.
As we wrote about image-synthesis model Stable Diffusion 3's body horror generations earlier this year, "Basically, any time a user prompt homes in on a concept that isn't represented well in the AI model's training dataset, the image-synthesis model will confabulate its best interpretation of what the user is asking for. And sometimes that can be completely terrifying."
For the engineers who make these models, success in AI video generation quickly becomes a question of how many examples (and how much training) you need before the model can generalize enough to produce convincing and coherent results. It's also a question of metadata quality—how accurately the videos are labeled. In this case, OpenAI used an AI vision model to describe its training videos, which helped improve quality, but apparently not enough—yet.
We’re looking at an AI jabberwocky in action
In a way, the type of generation failure in the gymnast video is a form of confabulation (or hallucination, as some call it), but it's even worse because it's not coherent. So instead of calling it a confabulation, which is a plausible-sounding fabrication, we're going to lean on a new term, "jabberwocky," which Dictionary.com defines as "a playful imitation of language consisting of invented, meaningless words; nonsense; gibberish," taken from Lewis Carroll's nonsense poem of the same name. Imitation and nonsense, you say? Check and check.We've covered jabberwockies in AI video before with people mocking Chinese video-synthesis models, a monstrously weird AI beer commercial, and even Will Smith eating spaghetti. They're a form of misconfabulation where an AI model completely fails to produce a plausible output. This will not be the last time we see them, either.
How could AI video models get better and avoid jabberwockies?
In our coverage of Gen-3 Alpha, we called the threshold where you get a level of useful generalization in an AI model the "illusion of understanding," where training data and training time reach a critical mass that produces good enough results to generalize across enough novel prompts.
One of the key reasons language models like OpenAI's GPT-4 impressed users was that they finally reached a size where they had absorbed enough information to give the appearance of genuinely understanding the world. With video synthesis, achieving this same apparent level of "understanding" will require not just massive amounts of well-labeled training data but also the computational power to process it effectively.
AI boosters hope that these current models represent one of the key steps on the way to something like truly general intelligence (often called AGI) in text, or in AI video, what OpenAI and Runway researchers call "world simulators" or "world models" that somehow encode enough physics rules about the world to produce any realistic result.
Judging by the morphing alien shoggoth gymnast, that may still be a ways off. Still, it's early days in AI video generation, and judging by how quickly AI image-synthesis models like Midjourney progressed from crude abstract shapes into coherent imagery, it's likely video synthesis will have a similar trajectory over time. Until then, enjoy the AI-generated jabberwocky madness.[]
Computer Science > Computation and Language
[Submitted on 19 Dec 2024]
Qwen2.5 Technical Report
Qwen: An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, Huan Lin, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jingren Zhou, Junyang Lin, Kai Dang, Keming Lu, Keqin Bao, Kexin Yang, Le Yu, Mei Li, Mingfeng Xue, Pei Zhang, Qin Zhu, Rui Men, Runji Lin, Tianhao Li, Tingyu Xia, Xingzhang Ren, Xuancheng Ren, Yang Fan, Yang Su, Yichang Zhang, Yu Wan, Yuqiong Liu, Zeyu Cui, Zhenru Zhang, Zihan Qiu (additional authors not shown)
In this report, we introduce Qwen2.5, a comprehensive series of large language models (LLMs) designed to meet diverse needs. Compared to previous iterations, Qwen 2.5 has been significantly improved during both the pre-training and post-training stages. In terms of pre-training, we have scaled the high-quality pre-training datasets from the previous 7 trillion tokens to 18 trillion tokens. This provides a strong foundation for common sense, expert knowledge, and reasoning capabilities. In terms of post-training, we implement intricate supervised finetuning with over 1 million samples, as well as multistage reinforcement learning. Post-training techniques enhance human preference, and notably improve long text generation, structural data analysis, and instruction following. To handle diverse and varied use cases effectively, we present Qwen2.5 LLM series in rich sizes. Open-weight offerings include base and instruction-tuned models, with quantized versions available. In addition, for hosted solutions, the proprietary models currently include two mixture-of-experts (MoE) variants: Qwen2.5-Turbo and Qwen2.5-Plus, both available from Alibaba Cloud Model Studio. Qwen2.5 has demonstrated top-tier performance on a wide range of benchmarks evaluating language understanding, reasoning, mathematics, coding, human preference alignment, etc. Specifically, the open-weight flagship Qwen2.5-72B-Instruct outperforms a number of open and proprietary models and demonstrates competitive performance to the state-of-the-art open-weight model, Llama-3-405B-Instruct, which is around 5 times larger. Qwen2.5-Turbo and Qwen2.5-Plus offer superior cost-effectiveness while performing competitively against GPT-4o-mini and GPT-4o respectively. Additionally, as the foundation, Qwen2.5 models have been instrumental in training specialized models such as Qwen2.5-Math, Qwen2.5-Coder, QwQ, and multimodal models.
| Subjects: | Computation and Language (cs.CL) |
| Cite as: | arXiv:2412.15115 [cs.CL] |
| (or arXiv:2412.15115v1 [cs.CL] for this version) | |
| [2412.15115] Qwen2.5 Technical Report |
Submission history
From: Binyuan Hui [view email][v1] Thu, 19 Dec 2024 17:56:09 UTC (2,142 KB)
1/1
@armand_ruiz
Our final announcement of the year — introducing Granite 3.1
What's new with this version?
1/ Granite 3.1 8B Instruct delivers significant performance improvements over Granite 3.0 8B Instruct. Its average score across the Hugging Face OpenLLM Leaderboard benchmarks is now among the highest of any open model in its weight class.
2/ We’ve expanded the context windows of the entire Granite 3 language model family. Our latest dense models (Granite 3.1 8B, Granite 3.1 2B), MoE models (Granite 3.1 3B-A800M, Granite 3.1 1B-A400M) and guardrail models (Granite Guardian 3.1 8B, Granite Guardian 3.1 2B) all feature a 128K token context length.
3/ We’re releasing a family of all-new embedding models. The new retrieval-optimized Granite Embedding models are offered in four sizes, ranging from 30M–278M parameters. Like their generative counterparts, they offer multilingual support across 12 different languages: English, German, Spanish, French, Japanese, Portuguese, Arabic, Czech, Italian, Korean, Dutch and Chinese.
4/ Granite Guardian 3.1 8B and 2B feature a new function calling hallucination detection capability, allowing increased control over and observability for agents making tool calls.
5/ All Granite 3.1, Granite Guardian 3.1, and Granite Embedding models are open source under Apache 2.0 license.
6/ These latest entries in the Granite series follow IBM’s recent launch of Docling (an open-source framework for prepping documents for RAG and other generative AI applications) and Bee (an open-source, a model-agnostic framework for agentic AI).
7/ Granite TTM (TinyTimeMixers), IBM’s series of compact but highly performant timeseries models, are now available in IBM watsonx.ai
through the beta release of IBM watsonx.ai
Timeseries Forecasting API and SDK.
8/ Granite 3.1 models are now available in IBM IBM watsonx.ai
and through platform partners, including (in alphabetical order) Docker, Hugging Face, LM Studio, Ollama, and Replicate.
9/ Granite 3.1 will also be leveraged internally by enterprise partners: Samsung is integrating select Granite models into its SDS platform; Lockheed Martin is integrating Granite 3.1 models into its AI Factory tools, used by over 10,000 developers and engineers.

To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
@armand_ruiz
Our final announcement of the year — introducing Granite 3.1
What's new with this version?
1/ Granite 3.1 8B Instruct delivers significant performance improvements over Granite 3.0 8B Instruct. Its average score across the Hugging Face OpenLLM Leaderboard benchmarks is now among the highest of any open model in its weight class.
2/ We’ve expanded the context windows of the entire Granite 3 language model family. Our latest dense models (Granite 3.1 8B, Granite 3.1 2B), MoE models (Granite 3.1 3B-A800M, Granite 3.1 1B-A400M) and guardrail models (Granite Guardian 3.1 8B, Granite Guardian 3.1 2B) all feature a 128K token context length.
3/ We’re releasing a family of all-new embedding models. The new retrieval-optimized Granite Embedding models are offered in four sizes, ranging from 30M–278M parameters. Like their generative counterparts, they offer multilingual support across 12 different languages: English, German, Spanish, French, Japanese, Portuguese, Arabic, Czech, Italian, Korean, Dutch and Chinese.
4/ Granite Guardian 3.1 8B and 2B feature a new function calling hallucination detection capability, allowing increased control over and observability for agents making tool calls.
5/ All Granite 3.1, Granite Guardian 3.1, and Granite Embedding models are open source under Apache 2.0 license.
6/ These latest entries in the Granite series follow IBM’s recent launch of Docling (an open-source framework for prepping documents for RAG and other generative AI applications) and Bee (an open-source, a model-agnostic framework for agentic AI).
7/ Granite TTM (TinyTimeMixers), IBM’s series of compact but highly performant timeseries models, are now available in IBM watsonx.ai
through the beta release of IBM watsonx.ai
Timeseries Forecasting API and SDK.
8/ Granite 3.1 models are now available in IBM IBM watsonx.ai
and through platform partners, including (in alphabetical order) Docker, Hugging Face, LM Studio, Ollama, and Replicate.
9/ Granite 3.1 will also be leveraged internally by enterprise partners: Samsung is integrating select Granite models into its SDS platform; Lockheed Martin is integrating Granite 3.1 models into its AI Factory tools, used by over 10,000 developers and engineers.
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
1/10
@ollama
IBM's updated Granite 3.1 models are here!
4 sizes using two different architectures:
Mixture of expert models are designed for low latency usage.
ollama run granite3-moe:1b
ollama run granite3-moe:3b
Dense models are designed for tool-based use cases.
ollama run granite3.1-dense:2b
ollama run granite3.1-dense:8b
IBM is also releasing their embedding models today!
English only:
ollama pull granite-embedding:30m
Multilingual:
ollama pull granite-embedding:278m


2/10
@ollama
Granite 3.1 Mixture of Expert model page:
granite3-moe
Granite 3.1 Dense model page:
granite3.1-dense
Granite Embedding model page:
granite-embedding

3/10
@consultutah
Wow - maybe IBM shouldn't be counted out either...
4/10
@ollama
love the choices people have!
5/10
@n1d_all
We Want Qwen VL 2 please
6/10
@ollama
coming very soon!
7/10
@SaquibOptimusAI
Yeah, cool. These are actually pretty good models but quite underrated.
8/10
@Comed_Ai_n
Let’s goooo
9/10
@sa_su_ke
And there is also falcon in ollama
10/10
@arteyco

To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
@ollama
IBM's updated Granite 3.1 models are here!
4 sizes using two different architectures:
Mixture of expert models are designed for low latency usage.
ollama run granite3-moe:1b
ollama run granite3-moe:3b
Dense models are designed for tool-based use cases.
ollama run granite3.1-dense:2b
ollama run granite3.1-dense:8b
IBM is also releasing their embedding models today!
English only:
ollama pull granite-embedding:30m
Multilingual:
ollama pull granite-embedding:278m
2/10
@ollama
Granite 3.1 Mixture of Expert model page:
granite3-moe
Granite 3.1 Dense model page:
granite3.1-dense
Granite Embedding model page:
granite-embedding
3/10
@consultutah
Wow - maybe IBM shouldn't be counted out either...
4/10
@ollama
love the choices people have!
5/10
@n1d_all
We Want Qwen VL 2 please
6/10
@ollama
coming very soon!
7/10
@SaquibOptimusAI
Yeah, cool. These are actually pretty good models but quite underrated.
8/10
@Comed_Ai_n
Let’s goooo
9/10
@sa_su_ke
And there is also falcon in ollama
10/10
@arteyco
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196