You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
The A.I Megathread (LLM , GPT , Development)
More options
Who Replied?
OpenAI launches experimental GPT-4o Long Output model with 16X token capacity
It is a variation on its signature GPT-4o model from May, but with a massively extended output size: up to 64,000 tokens of output.
 venturebeat.com
venturebeat.com
OpenAI launches experimental GPT-4o Long Output model with 16X token capacity
Carl Franzen@carlfranzen
July 30, 2024 4:07 PM

Credit: VentureBeat made with OpenAI DALL-E 3 via ChatGPT
OpenAI is reportedly eyeing a cash crunch, but that isn’t stopping the preeminent generative AI company from continuing to release a steady stream of new models and updates.
Yesterday, the company quietly posted a webpage announcing a new large language model (LLM): GPT-4o Long Output, which is a variation on its signature GPT-4o model from May, but with a massively extended output size: up to 64,000 tokens of output instead of GPT-4o’s initial 4,000 — a 16-fold increase.
Tokens, as you may recall, refer to the numerical representations of concepts, grammatical constructions, and combinations of letters and numbers organized based on their semantic meaning behind-the-scenes of an LLM.
The word “Hello” is one token, for example, but so too is “hi.” You can see an interactive demo of tokens in action via OpenAI’s Tokenizer here. Machine learning researcher Simon Willison also has a great interactive token encoder/decoder.
By offering a 16X increase in token outputs with the new GPT-4o Long Output variant, OpenAI is now giving users — and more specifically, third-party developers building atop its application programming interface (API) — the opportunity to have the chatbot return far longer responses, up to about a 200-page novel in length.
Why is OpenAI launching a longer output model?
OpenAI’s decision to introduce this extended output capability stems from customer feedback indicating a need for longer output contexts.
An OpenAI spokesperson explained to VentureBeat: “We heard feedback from our customers that they’d like a longer output context. We are always testing new ways we can best serve our customers’ needs.”
The alpha testing phase is expected to last for a few weeks, allowing OpenAI to gather data on how effectively the extended output meets user needs.
This enhanced capability is particularly advantageous for applications requiring detailed and extensive output, such as code editing and writing improvement.
By offering more extended outputs, the GPT-4o model can provide more comprehensive and nuanced responses, which can significantly benefit these use cases.
Distinction between context and output
Already, since launch, GPT-4o offered a maximum 128,000 context window — the amount of tokens the model can handle in any one interaction, including both input and output tokens.
For GPT-4o Long Output, this maximum context window remains at 128,000.
So how is OpenAI able to increase the number of output tokens 16-fold from 4,000 to 64,000 tokens while keeping the overall context window at 128,000?
It call comes down to some simple math: even though the original GPT-4o from May had a total context window of 128,000 tokens, its single output message was limited to 4,000.
Similarly, for the new GPT-4o mini window, the total context is 128,000 but the maximum output has been raised to 16,000 tokens.
That means for GPT-4o, the user can provide up to 124,000 tokens as an input and receive up to 4,000 maximum output from the model in a single interaction. They can also provide more tokens as input but receive fewer as output, while still adding up to 128,000 total tokens.
For GPT-4o mini, the user can provide up to 112,000 tokens as an input in order to get a maximum output of 16,000 tokens back.
For GPT-4o Long Output, the total context window is still capped at 128,000. Yet, now, the user can provide up to 64,000 tokens worth of input in exchange for a maximum of 64,000 tokens back out — that is, if the user or developer of an application built atop it wants to prioritize longer LLM responses while limiting the inputs.
In all cases, the user or developer must make a choice or trade-off: do they want to sacrifice some input tokens in favor of longer outputs while still remaining at 128,000 tokens total? For users who want longer answers, the GPT-4o Long Output now offers this as an option.
Priced aggressively and affordably
The new GPT-4o Long Output model is priced as follows:
$6 USD per 1 million input tokens
$18 per 1 million output tokens
Compare that to the regular GPT-4o pricing which is $5 per million input tokens and $15 per million output, or even the new GPT-4o mini at $0.15 per million input and $0.60 per million output, and you can see it is priced rather aggressively, continuing OpenAI’s recent refrain that it wants to make powerful AI affordable and accessible to wide swaths of the developer userbase.
Currently, access to this experimental model is limited to a small group of trusted partners. The spokesperson added, “We’re conducting alpha testing for a few weeks with a small number of trusted partners to see if longer outputs help their use cases.”
Depending on the outcomes of this testing phase, OpenAI may consider expanding access to a broader customer base.
Future prospects
The ongoing alpha test will provide valuable insights into the practical applications and potential benefits of the extended output model.
If the feedback from the initial group of partners is positive, OpenAI may consider making this capability more widely available, enabling a broader range of users to benefit from the enhanced output capabilities.
Clearly, with the GPT-4o Long Output model, OpenAI hopes to address an even wider range of customer requests and power applications requiring detailed responses.

Gemini 1.5 Flash price drop with tuning rollout complete, and more- Google Developers Blog
Gemini 1.5 Flash is now available to developers at more than 70% lower prices. Set up billing for Gemini API in Google AI Studio and access other new features like 1.5 Flash tuning.
 developers.googleblog.com
developers.googleblog.com
Gemini 1.5 Flash price drop with tuning rollout complete, and more
AUG 08, 2024
Logan Kilpatrick Senior Product Manager Gemini API and Google AI Studio
Shrestha Basu Mallick Group Product Manager Gemini API

Gemini 1.5 Flash price drop, tuning rollout complete and improvements to Gemini API and Google AI Studio
Last week, we launched an experimental updated version of Gemini 1.5 Pro (0801) that ranked #1 on the LMSYS leaderboard for both text and multi-modal queries. We were so excited by the immediate response to this model that we raised the limits to test with it. We will have more updates soon.
Today, we’re announcing a series of improvements across AI Studio and the Gemini API:
Significant reduction in costs for Gemini 1.5 Flash, with input token costs decreasing by 78% and output token costs decreasing by 71%
1.5 Flash tuning is now available to all developers
Expanding the Gemini API to support queries in 100+ additional languages
Expanded AI Studio access for Google Workspace customers
Revamped documentation UI and API reference and more!
Gemini 1.5 Flash price decrease
1.5 Flash is our most popular Gemini model amongst developers who want to build high volume, low latency use cases such as summarization, categorization, multi-modal understanding and more. To make this model even more affordable, as of August 12, we’re reducing the input price by 78% to $0.075/1 million tokens and the output price by 71% to $0.3/1 million tokens for prompts under 128K tokens (cascading the reductions across the >128K tokens tier as well as caching). With these prices and tools like context caching, developers should see major cost savings when building with Gemini 1.5 Flash’s long context and multimodal capabilities.

Gemini 1.5 Flash reduced prices effective August 12, 2024. See full price list at ai.google.dev/pricing.
Expanded Gemini API language availability
We’re expanding language understanding for both Gemini 1.5 Pro and Flash models to cover more than 100 languages so developers across the globe can now prompt and receive outputs in the language of their choice. This should eliminate model “language” block finish reasons via the Gemini API.
Google AI Studio access for Google Workspace
Google Workspace users can now access Google AI Studio without having to enable any additional settings by default, unlocking frictionless access for millions of users. Account admins will still have control to manage AI Studio access.
Gemini 1.5 Flash tuning rollout now complete
We have now rolled out Gemini 1.5 Flash text tuning to all developers via the Gemini API and Google AI Studio. Tuning enables developers to customize base models and improve performance for tasks by providing the model additional data. This helps reduce the context size of prompts, reduces latency and in some cases cost, while also increasing the accuracy of the model on tasks.
Improved developer documentation
Our developer documentation is core to the experience of building with the Gemini API. We recently released a series of improvements, updated the content, navigation, look and feel, and released a revamped API reference.

Improved developer documentation experience for the Gemini API on ai.google.dev/gemini-api
We have many more improvements to the documentation coming soon so please continue to send us feedback!
PDF Vision and Text understanding
The Gemini API and AI Studio now support PDF understanding through both text and vision. If your PDF includes graphs, images, or other non-text visual content, the model uses native multi-modal capabilities to process the PDF. You can try this out via Google AI Studio or in the Gemini API.
Google AI Studio improvements
Over the last few weeks, we have released many improvements to AI Studio, including overhauling keyboard shortcuts, allowing dragging and dropping images into the UI, decreased loading time by ~50%, added prompt suggestions, and much more!
Developers are at the heart of all our work on the Gemini API and Google AI Studio, so keep building and sharing your feedback with us via the Gemini API Developer Forum.

LG unleashes South Korea’s first open-source AI, challenging global tech giants
LG launches Exaone 3.0, South Korea's first open-source AI model, challenging global tech giants and reshaping the AI landscape with improved efficiency and multilingual capabilities.
venturebeat.com
LG unleashes South Korea’s first open-source AI, challenging global tech giants
Michael Nuñez@MichaelFNunez
August 8, 2024 9:45 AM

Credit: VentureBeat made with Midjourney
LG AI Research has launched Exaone 3.0, South Korea’s first open-source artificial intelligence model, marking the country’s entry into the competitive global AI landscape dominated by U.S. tech giants and emerging players from China and the Middle East.
The 7.8 billion parameter model, which excels in both Korean and English language tasks, aims to accelerate AI research and contribute to building a robust AI ecosystem in Korea. This move signals a strategic shift for LG, traditionally known for its consumer electronics, as it positions itself at the forefront of AI innovation. By open-sourcing Exaone 3.0, LG is not only showcasing its technological prowess but also potentially laying the groundwork for a new revenue stream in cloud computing and AI services.
Exaone 3.0 Faces Off Against Chinese and Middle Eastern AI Powerhouses
Exaone 3.0 joins a crowded field of open-source AI models, including China’s Qwen from Alibaba and the UAE’s Falcon. Qwen, which received a major update in June, has gained significant traction with over 90,000 enterprise clients and has topped performance rankings on platforms like Hugging Face, surpassing Meta’s Llama 3.1 and Microsoft’s Phi-3.
Similarly, the UAE’s Technology Innovation Institute released Falcon 2, an 11 billion parameter model in May, claiming it outperforms Meta’s Llama 3 on several benchmarks. These developments highlight the intensifying global competition in AI, with countries beyond the U.S. making significant strides. The emergence of these models from Asia and the Middle East underscores a shift in the AI landscape, challenging the notion of Western dominance in the field.
Open-source strategy: LG’s gambit to boost cloud computing and AI innovation
LG’s approach mirrors that of Chinese companies like Alibaba, which are using open-source AI as a strategy to grow cloud businesses and accelerate commercialization. This strategy serves a dual purpose: it allows LG to rapidly iterate and improve its AI models through community contributions while also creating a potential customer base for its cloud services. By offering a powerful, open-source model, LG could attract developers and enterprises to build applications on its platform, thereby driving adoption of its broader AI and cloud infrastructure.
Exaone 3.0 boasts improved efficiency, with LG claiming a 56% reduction in inference time, 35% decrease in memory usage, and 72% reduction in operational costs compared to its predecessor. These improvements are crucial in the competitive AI landscape, where efficiency can translate directly into cost savings for enterprises and improved user experiences for consumers. The model has been trained on 60 million cases of professional data related to patents, codes, math, and chemistry, with plans to expand to 100 million cases across various fields by year-end, indicating LG’s commitment to creating a versatile and robust AI system.
Exaone 3.0: South Korea’s open-source AI leap into global competition
LG’s move into open-source AI could potentially reshape the AI landscape, offering an alternative to the dominance of deep-pocketed players like OpenAI, Microsoft, and Google. It also demonstrates South Korea’s capability to create state-of-the-art AI models that can compete on a global scale. This development is particularly significant for South Korea, a country known for its technological innovation but which has, until now, been relatively quiet in the open-source AI arena.
The success of Exaone 3.0 could have far-reaching implications. For LG, it could mark a successful diversification into AI and cloud services, potentially opening up new revenue streams. For South Korea, it represents a bold step onto the global AI stage, potentially attracting international talent and investment. On a broader scale, the proliferation of open-source models like Exaone 3.0 could democratize access to advanced AI technologies, fostering innovation across industries and geographies.
As the AI race intensifies, the true measure of Exaone 3.0’s impact will lie not just in its technical specifications, but in its ability to catalyze a thriving ecosystem of developers, researchers, and businesses leveraging its capabilities. The coming months will be crucial in determining whether LG’s ambitious gambit pays off, potentially reshaping the global AI landscape in the process.

How Microsoft is turning AI skeptics into AI power users
75% of knowledge workers are already using AI at work, and that usage has doubled in the past six months.
venturebeat.com
How Microsoft is turning AI skeptics into AI power users
VB Staff
July 26, 2024 6:50 AM

Since generative AI burst onto the scene in 2023, it quickly swept from personal to workplace use. Microsoft’s global, industry-spanning survey, the 2024 Work Trend Index Annual Report, found that 75% of knowledge workers are already using AI at work, and that usage has doubled in the past six months. But 78% of that is BYOAI, or workers bringing their own AI tools.
“The challenge for every organization and leader right now — or opportunity — is how to channel that individual enthusiasm and experimentation into business value,” said Colette Stallbaumer, WorkLab Cofounder and Copilot GM at Microsoft, joining VB CEO Matt Marshall onstage at VB Transform.
They spoke about how AI can be effectively integrated at work in a way that drives value for the business and for the employees who use it. It’s all about activating at every level of the organization, from the CEO to all line of business leaders across every function, Stallbaumer explained. As you hunt down the business problems that can most effectively be tackled with AI, it’s about embracing experimentation, identifying AI champions and channeling enthusiasm. Since the launch of Microsoft Copilot, they’ve chased that enthusiasm by continually working to keep customers engaged in an active feedback loop, learning what’s working and how to make the product better.
Adding critical new capabilities to Copilot
Customer feedback has prompted the company to add a number of new capabilities to Copilot and Copilot Lab, including prompts specific to a workplace, function-specific prompts and the ability to share them and reuse prompts. They’ve also stepped up aid in the prompt-writing process, adding both an auto-complete feature and a rewrite feature to get the best possible response. Customers are also now able to schedule prompts to run at certain times of the day, every day.
“When we introduced Copilot, we said, this is the most powerful productivity tool on the planet, and all you need are your own words,” says Stallbaumer. “It turns out that was not entirely true. We’ve learned along the way that one of the hardest things for people to do is change behavior. And in the case of Copilot and these generative AI tools, we are asking people to both create new habits, and break old ones.”
Measuring the impact of gen AI
How do you quantify enthusiasm, or employee productivity and satisfaction? Nailing down metrics, KPIs and benchmarks has generally proven to be a tricky undertaking, across industries. Microsoft has shifted its own approach over the last year, and since the introduction of Copilot. The original focus was on time savings and productivity across all the universal tasks that happen in knowledge work, such as email, writing, meetings and searching for information. What they found is that there was a growing body of evidence, both Microsoft-sourced as well as customer and third-party academic research, all saying a very similar thing: These tools do save knowledge workers anywhere from 20 to 40%. But at the same time, customers were saying they wanted more — they wanted to use these tools to fundamentally change the shape of the business, with metrics centered on real business value.
“In 2024, we’ve pivoted to that goal, which starts with understanding the business problems that AI is best positioned to solve,” Stallbaumer says. “We are working on it now, across every function — like sales, finance, HR, marketing — looking at all of the processes, hundreds of processes, and then [determining] the KPIs within those processes where AI can actually make a difference. That’s how we’re thinking about measurement now.”
For example, Microsoft has one of the largest customer service organizations in the world. They found that when applying Copilot to specific areas of an agent’s workflow, they can resolve cases 12% faster, resulting in happier customers, and requiring about 13% less intervention or peer support to resolve cases.
For the finance team, dealing with accounting and treasury means reconciling many hundreds of accounts a week, consuming a huge number of hours. With Copilot they found that tasks that used to take hours of work can be cut down to about 10 minutes.
“It’s about breaking down knowledge work,” she says. “Every job is a series of tasks, and when you can help people start to think about it that way, you start to think, ‘is this a human-powered task or an AI powered-one, and can I delegate this to AI and then build on that work?’”
The future of work, AI and AI-powered work
“We see knowledge work fundamentally changing, and how people spend their time changing,” Stallbaumer says. “We’re going to see it evolve from where people are rarely doers [and instead are] supervisors of both their own work and also AI-generated output. Things that they can set and forget, if you will, but also where AI will come back to the human and ask for further instructions when needed.”For a salesperson that could mean that backend data entry is taken entirely off their plate in the future, so they can instead focus on the customer relationship. For a finance person, it would enable them to focus on strategically growing the business rather than spending so much of their time on accounts reconciliation.
To get to that future, it’s important to prioritize training, in order to change long-ingrained, pre-AI habits. But Microsoft research shows that even for those using AI, only 39% have received AI training, and only 25% of organizations plan to offer training in the year ahead.
“So that’s our message to customers, that training is important if you want to create that flywheel of usage,” she adds.
Turning skeptics into power users
As their own best customer, they’re currently doing an internal experiment to understand the most effective training interventions, whether its nudges from a manager, or peer-to-peer. The Work Trend Index Annual Report found that organizations across the world have a spectrum of users from the skeptics to the power users, and that matches what they see internally.
The report’s research found that the power users who embrace experimentation are also the type of people who will try again if they don’t get the response they expected, as they do not give up easily. And 90% of those users say AI helps them feel more productive, enjoy their work more and manage their workload so they can focus more easily. They’re also 39% more likely to have heard from their line leader about the importance of using AI to transform their function.
“There’s a great quote from William Gibson: ‘The future’s already here, it’s just not evenly distributed,’” Stallbaumer said. “We see that inside Microsoft: functions that are already applying AI to transform in significant ways. It’s going to be a journey.”

Meet Prompt Poet: The Google-acquired tool revolutionizing LLM prompt engineering
Prompt Poet potentially offers a look at the future direction of prompt context management across Google’s AI projects, such as Gemini.
venturebeat.com
Meet Prompt Poet: The Google-acquired tool revolutionizing LLM prompt engineering
Michael Trestman
August 8, 2024 5:32 PM

Image Credit: Logitech
In the age of artificial intelligence, prompt engineering is an important new skill for harnessing the full potential of large language models (LLMs). This is the art of crafting complex inputs to extract relevant, useful outputs from AI models like ChatGPT. While many LLMs are designed to be friendly to non-technical users, and respond well to natural-sounding conversational prompts, advanced prompt engineering techniques offer another powerful level of control. These techniques are useful for individual users, and absolutely essential for developers seeking to build sophisticated AI-powered applications.
The Game-Changer: Prompt Poet
Prompt Poet is a groundbreaking tool developed by Character.ai, a platform and makerspace for personalized conversational AIs, which was recently acquired by Google. Prompt Poet potentially offers a look at the future direction of prompt context management across Google’s AI projects, such as Gemini.
Prompt Poet offers several key advantages, and stands out from other frameworks such as Langchain in its simplicity and focus:
Low Code Approach: Simplifies prompt design for both technical and non-technical users, unlike more code-intensive frameworks.
Template Flexibility: Uses YAML and Jinja2 to support complex prompt structures.
Context Management: Seamlessly integrates external data, offering a more dynamic and data-rich prompt creation process.
Efficiency: Reduces time spent on engineering string manipulations, allowing users to focus on crafting optimal prompt text.
This article focuses on the critical concept of context in prompt engineering, specifically the components of instructions and data. We’ll explore how Prompt Poet can streamline the creation of dynamic, data-rich prompts, enhancing the effectiveness of your LLM applications.
The Importance of Context: Instructions and Data
Customizing an LLM application often involves giving it detailed instructions about how to behave. This might mean defining a personality type, a specific situation, or even emulating a historical figure. For instance:
Customizing an LLM application, such as a chatbot, often means giving it specific instructions about how to act. This might mean describing a certain type of personality type, situation, or role, or even a specific historical or fictional person. For example, when asking for help with a moral dilemma, you can ask the model to answer in the style of someone specific, which will very much influence the type of answer you get. Try variations of the following prompt to see how the details (like the people you pick) matter:
Simulate a panel discussion with the philosophers Aristotle, Karl Marx, and Peter Singer. Each should provide individual advice, comment on each other's responses, and conclude. Suppose they are very hungry.
The question: The pizza place gave us an extra pie, should I tell them or should we keep it?
Details matter. Effective prompt engineering also involves creating a specific, customized data context. This means providing the model with relevant facts, like personal user data, real-time information or specialized knowledge, which it wouldn’t have access to otherwise. This approach allows the AI to produce output far more relevant to the user’s specific situation than would be possible for an uninformed generic model.
Efficient Data Management with Prompt Templating
Data can be loaded in manually, just by typing it into ChatGPT. If you ask for advice about how to install some software, you have to tell it about your hardware. If you ask for help crafting the perfect resume, you have to tell it your skills and work history first. However, while this is ok for personal use, it does not work for development. Even for personal use, manually inputting data for each interaction can be tedious and error-prone.
This is where prompt templating comes into play. Prompt Poet uses YAML and Jinja2 to create flexible and dynamic prompts, significantly enhancing LLM interactions.
Example: Daily Planner
To illustrate the power of Prompt Poet, let’s work through a simple example: a daily planning assistant that will remind the user of upcoming events and provide contextual information to help prepare for their day, based on real-time data.
For example, you might want output like this:
Good morning! It looks like you have virtual meetings in the morning and an afternoon hike planned. Don't forget water and sunscreen for your hike since it's sunny outside.
Here are your schedule and current conditions for today:
- **09:00 AM:** Virtual meeting with the marketing team
- **11:00 AM:** One-on-one with the project manager
- **07:00 PM:** Afternoon hike at Discovery Park with friends
It's currently 65°F and sunny. Expect good conditions for your hike. Be aware of a bridge closure on I-90, which might cause delays.
To do that, we’ll need to provide at least two different pieces of context to the model, 1) customized instructions about the task, and 2) the required data to define the factual context of the user interaction.
Prompt Poet gives us some powerful tools for handling this context. We’ll start by creating a template to hold the general form of the instructions, and filling it in with specific data at the time when we want to run the query. For the above example, we might use the following Python code to create a `raw_template` and the `template_data` to fill it, which are the components of a Prompt Poet `Prompt` object.
raw_template = """
- name: system instructions
role: system
content: |
You are a helpful daily planning assistant. Use the following information about the user's schedule and conditions in their area to provide a detailed summary of the day. Remind them of upcoming events and bring any warnings or unusual conditions to their attention, including weather, traffic, or air quality warnings. Ask if they have any follow-up questions.
- name: realtime data
role: system
content: |
Weather in {{ user_city }}, {{ user_country }}:
- Temperature: {{ user_temperature }}°C
- Description: {{ user_description }}
Traffic in {{ user_city }}:
- Status: {{ traffic_status }}
Air Quality in {{ user_city }}:
- AQI: {{ aqi }}
- Main Pollutant: {{ main_pollutant }}
Upcoming Events:
{% for event in events %}
- {{ event.start }}: {{ event.summary }}
{% endfor %}
"""
The code below uses Prompt Poet’s `Prompt` class to populate data from multiple data sources into a template to form a single, coherent prompt. This allows us to invoke a daily planning assistant to provide personalized, context-aware responses. By pulling in weather data, traffic updates, AQI information and calendar events, the model can offer detailed summaries and reminders, enhancing the user experience.
You can clone and experiment with the full working code example, which also implements few-shot learning, a powerful prompt engineering technique that involves presenting the models with a small set of training examples.
# User data
user_weather_info = get_weather_info(user_city)
traffic_info = get_traffic_info(user_city)
aqi_info = get_aqi_info(user_city)
events_info = get_events_info(calendar_events)
template_data = {
"user_city": user_city,
"user_country": user_country,
"user_temperature": user_weather_info["temperature"],
"user_description": user_weather_info["description"],
"traffic_status": traffic_info,
"aqi": aqi_info["aqi"],
"main_pollutant": aqi_info["main_pollutant"],
"events": events_info
}
# Create the prompt using Prompt Poet
prompt = Prompt(
raw_template=raw_template_yaml,
template_data=template_data
)
# Get response from OpenAI
model_response = openai.ChatCompletion.create(
model="gpt-4",
messages=prompt.messages
)
Conclusion
Mastering the fundamentals of prompt engineering, particularly the roles of instructions and data, is crucial for maximizing the potential of LLMs. Prompt Poet stands out as a powerful tool in this field, offering a streamlined approach to creating dynamic, data-rich prompts.
Prompt Poet’s low-code, flexible template system makes prompt design accessible and efficient. By integrating external data sources that would not be available to an LLM’s training, data-filled prompt templates can better ensure AI responses are accurate and relevant to the user.
By using tools like Prompt Poet, you can elevate your prompt engineering skills and develop innovative AI applications that meet diverse user needs with precision. As AI continues to evolve, staying proficient in the latest prompt engineering techniques will be essential.
Last edited:
OpenAI has finally released the No. 1 feature developers have been desperate for
OpenAI's new Structured Outputs helps ensure model-generated outputs match critical JSON Schemas and provide more accurate, usable outputs.
venturebeat.com
OpenAI has finally released the No. 1 feature developers have been desperate for
Taryn Plumb@taryn_plumb
August 6, 2024 3:46 PM

Credit: VentureBeat made with OpenAI DALL-E 3
The JavaScript Object Notation (JSON) file and data interchange format is an industry-standard because it is both easily readable by humans and parsable by machines.
However, large language models (LLMs) notoriously struggle with JSON — they might hallucinate, create wonky responses that only partially adhere to instructions or fail to parse completely. This often requires developers to use workarounds such as open-source tooling, many different prompts or repeated requests to ensure output interoperability.
Now, OpenAI is helping ease these frustrations with the release of its Structured Outputs in the API. Released today, the functionality helps ensure that model-generated outputs match JSON Schemas. These schemas are critical because they describe content, structure, types of data and expected constraints in a given JSON document.
OpenAI says it is the No. 1 feature developers have been asking for because it allows for consistency across various applications. OpenAI CEO Sam Altman posted on X today that the release is by “very popular demand.”
The company said that its evaluations with Structured Outputs on its new GPT-4o scores a “perfect 100%.”
by very popular demand, structured outputs in the API:https://t.co/AbfzTp4LMF
— Sam Altman (@sama) August 6, 2024
The new feature announcement comes on the heels of quite a bit of excitement at OpenAI this week: Three key executives — John Schulman, Greg Brockman and Peter Deng — suddenly each announced their departure, and Elon Musk is yet again suing the company, calling the betrayal of their AI mission “Shakespearian.”
Easily ensuring schema adherence
JSON is a text-based format for storing and exchanging data. It has become one of the most popular data formats among developers because it is simple, flexible and compatible with various programming languages. OpenAI quickly met demand from developers when it released its JSON mode on its models at last year’s DevDay.
With Structured Outputs in the API, developers can constrain OpenAI models to match schemas. OpenAI says the feature also allows its models to better understand more complicated schemas.
“Structured Outputs is the evolution of JSON mode,” the company writes on its blog. “While both ensure valid JSON is produced, only Structured Outputs ensure schema adherence.” This means that developers “don’t need to worry about the model omitting a required key, or hallucinating an invalid enum value.” (Enumeration value is a process that names constants in language, making code easier to read and maintain).
Developers can ask Structured Outputs to generate an answer in a step-by-step way to guide through to the intended output. According to OpenAI, developers don’t need to validate or retry incorrectly formatted responses, and the feature allows for simpler prompting while providing explicit refusals.
“Safety is a top priority for OpenAI — the new Structured Outputs functionality will abide by our existing safety policies and will still allow the model to refuse an unsafe request,” the company writes.
Structured Outputs is available on GPT-4o-mini, GPT-4o and fine-tuned versions of these models, and can be used on the Chat Completions API, Assistants API and Batch API, and it is also compatible with vision inputs.
OpenAI emphasizes that the new functionality “takes inspiration from excellent work from the open source community: namely, the outlines, jsonformer, instructor, guidance and lark libraries.”
OpenAI-backed startup Figure teases new humanoid robot ‘Figure 02’
Carl Franzen@carlfranzen
August 2, 2024 2:14 PM

The race to get AI-driven humanoid robots into homes and workplaces around the world took a new twist today when Figure, a company backed by OpenAI among others to the tune of $675 million in its last round in February, today published a trailer video for its newest model: Figure 02, along with the date of August 6, 2024.
As you’ll see in the video, it is short on specifics but heavy on vibes and close-ups, showing views of what appear to be robotic joints and limbs as well as some interesting, possibly flexible mesh designs for the robot body and labels for torque ratings up to 150Nm (Newton-meters, or “the torque produced by a force of one newton applied perpendicularly to the end of a one-meter long lever arm” according to Google’s AI Overview) and “ROM”, which I take to be “range of motion” up to 195 degrees (out of a total 360).

Founder Brett Adcock also posted on his personal X/Twitter account that Figure 02 was “the most advanced humanoid robot on the planet.”
Figure 02 is the most advanced humanoid robot on the planet
— Brett Adcock (@adcock_brett) August 2, 2024
Backed by big names in tech and AI
Adcock, an entrepreneur who previously founded far-out startups Archer Aviation and hiring marketplace Vettery, established Figure AI in 2022.
In March 2023, Figure emerged from stealth mode to introduce Figure 01, a general-purpose humanoid robot designed to address global labor shortages by performing tasks in various industries such as manufacturing, logistics, warehousing, and retail.
With a team of 40 industry experts, including Jerry Pratt as CTO, Figure AI completed the humanoid’s full-scale build in just six months. Adcock envisions the robots enhancing productivity and safety by taking on unsafe and undesirable jobs, ultimately contributing to a more automated and efficient future, while maintaining that they will never be weaponized.
The company, which in addition to OpenAI has among its investors and backers NVidia, Microsoft, Intel Capital and Bezos Expeditions (Amazon founder Jeff Bezos’s private fund), inked a deal with BMW Manufacturing earlier this year and showed off impressive integrations with OpenAI’s GPT-4V or vision model prior inside Figure’s 01 robot, before the release of OpenAI’s new flagship GPT-4o and GPT-4o mini.
Presumably, Figure 02 will have one of these newer OpenAI models guiding its movements and interaction, one of the leading names.
Competition to crack humanoid robotics intensifies
Figure has been a little quiet of late even as other companies debut and show off designs for AI-infused humanoid robots that they hope will assist humans in settings such as warehouses, factories, industrial plants, fulfillment centers, retirement homes, retail outlets, healthcare facilities and of course, private homes as well.
Though humanoid robots have long been a dream in sci-fi stories, their debut as commercial products has been slow going and marred by expensive designs confined primarily to research settings. But that’s changing thanks to generative AI and more specifically, large language models (LLMs) and multimodal AI models that can quickly analyze live video and audio inputs and respond with humanlike audio and movements of their own.
Indeed, recently, billionaire multi-company owner Elon Musk stated with his typical boisterous bravado and ambitious goal setting, that there was a market for more than 10 billion humanoid robots on Earth (more than one for every person) — which he hoped to command or at least take a slice of with his electric automotive and AI company Tesla Motors (which is making a rival humanoid robot of its own to Figure called Tesla Optimus).
Elon Musk says he expects there to be 10 billion humanoid robots, which will be so profound that it will mark a fundamental milestone in civilization pic.twitter.com/1OELtSPFoU
— Tsarathustra (@tsarnick) July 29, 2024
Moreover, Nvidia showed off new improvements for training the AI that guides humanoid robots through its Project GR00T effort using Apple Vision Pro headsets worn by human tele-operators to guide the robots through correct motions:
Exciting updates on Project GR00T! We discover a systematic way to scale up robot data, tackling the most painful pain point in robotics. The idea is simple: human collects demonstration on a real robot, and we multiply that data 1000x or more in simulation. Let’s break it down:… pic.twitter.com/8mUqCW8YDX
— Jim Fan (@DrJimFan) July 30, 2024
Before that, early humanoid robotics pioneer Boston Dynamics previewed its own updated version of its Atlas humanoid robot with electric motors replacing its hydraulic actuators, presumably making for a cheaper, quieter, more reliable and sturdier bot.
Thus, the competition in the sector appears to be intensifying. But with such big backers and forward momentum, Figure seems well-poised to continue advancing its own efforts in the space.
GitHub - hacksider/Deep-Live-Cam: real time face swap and one-click video deepfake with only a single image (uncensored)
real time face swap and one-click video deepfake with only a single image (uncensored) - hacksider/Deep-Live-Cam
 github.com
github.com
About
real time face swap and one-click video deepfake with only a single image (uncensored)
Topics
ai artificial-intelligence faceswap webcam webcamera deepfake deep-fake ai-face video-deepfake realtime-deepfake deepfake-webcam realtime-face-changer fake-webcam ai-webcam ai-deep-fake real-time-deepfake
Disclaimer
This software is meant to be a productive contribution to the rapidly growing AI-generated media industry. It will help artists with tasks such as animating a custom character or using the character as a model for clothing etc.The developers of this software are aware of its possible unethical applications and are committed to take preventative measures against them. It has a built-in check which prevents the program from working on inappropriate media including but not limited to nudity, graphic content, sensitive material such as war footage etc. We will continue to develop this project in the positive direction while adhering to law and ethics. This project may be shut down or include watermarks on the output if requested by law.
Users of this software are expected to use this software responsibly while abiding the local law. If face of a real person is being used, users are suggested to get consent from the concerned person and clearly mention that it is a deepfake when posting content online. Developers of this software will not be responsible for actions of end-users.
1/11
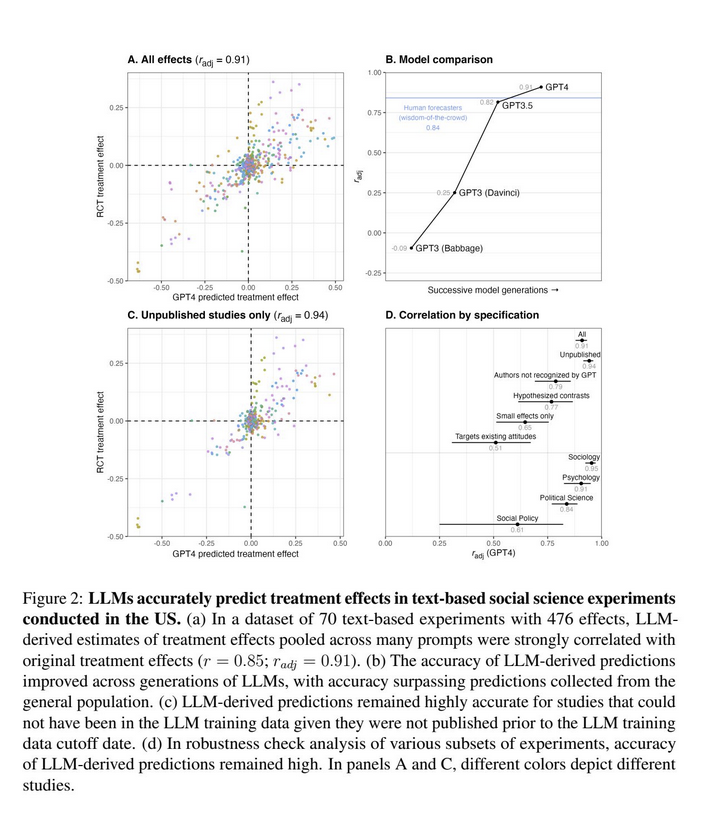
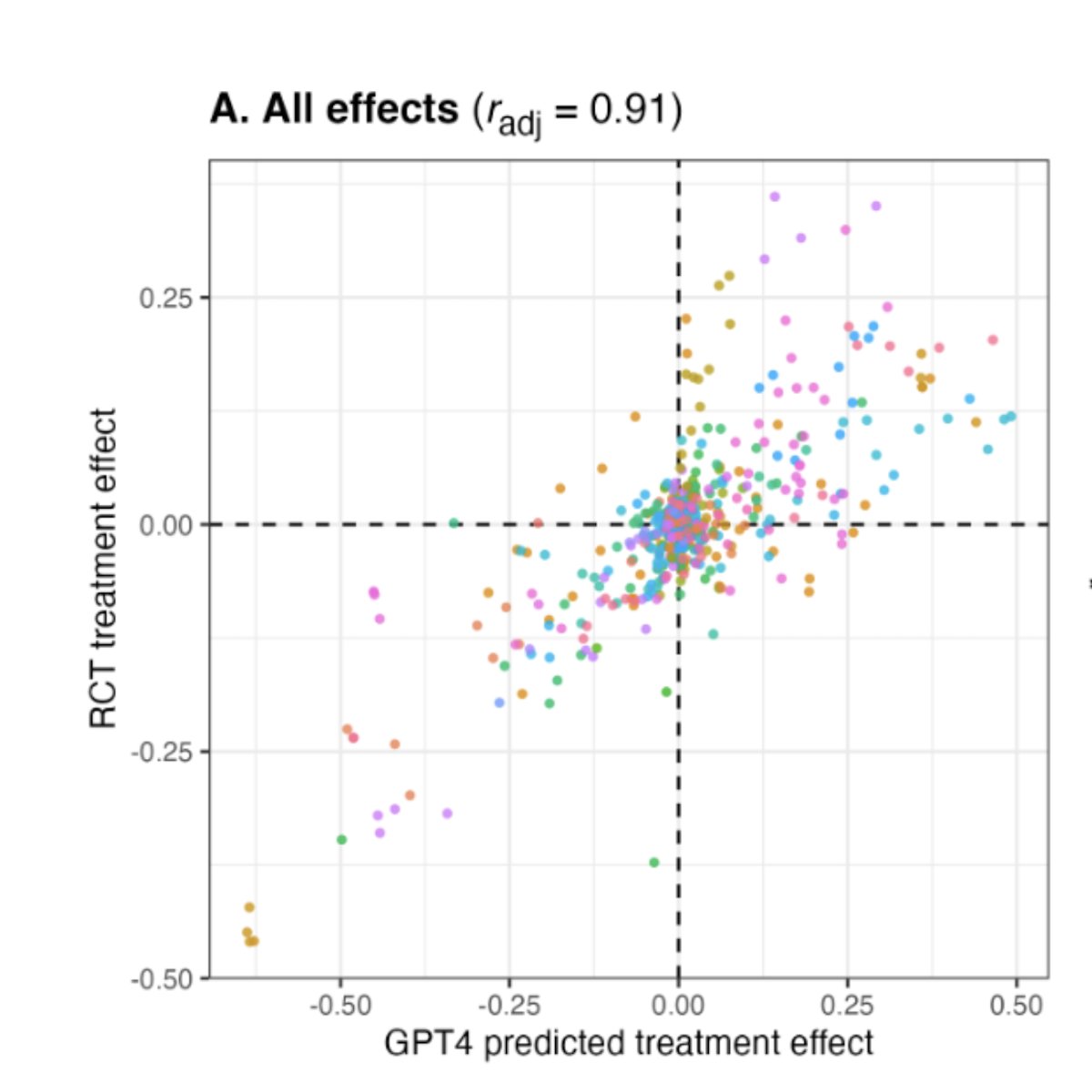
Kind of a big deal: GPT-4 simulates people well enough to replicate social science experiments with high accuracy
Note this is done by having the AI prompted to respond to survey questions as a person given random demographic characteristics & surveying thousands of "AI people"
2/11
I wrote about how this can be huge for marketing research and copywriting Why Talk to Customers When You Can Simulate Them?
3/11
Turns out I'm not that crazy in using ChatGPT to evaluate my search and recommendations models before actual users see them.
Collect enough user demographics, and it should be possible to predict users' perception of the product ahead of time.
4/11
True. AI assistants could revolutionize coaching and mentorship.
5/11
This is fine
6/11
WILD
Because LLM is so cheap and fast compared to real people. At the very least, can use LLM as an initial pass to test how a product or service might be received in the market
So who is going to build the tool around these results? SurveyMonkeys of the world add AI?
7/11
Obviously love your work and regularly cite it in mine. "What I would welcome is some scenarios for in situ applications: people still find it hard to sense and visualise how this will change stuff in actual work settings.
8/11
interesting!
9/11
We think there might be something to these idea.
Someone should build a product that allows everyone to do this.
We even thought of a cool name: Synthetic Users.

10/11
Someone said AI People?
@aipeoplegame
11/11
I've been thinking for a while that we could make much better economic simulations by using LLMs.
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
Kind of a big deal: GPT-4 simulates people well enough to replicate social science experiments with high accuracy
Note this is done by having the AI prompted to respond to survey questions as a person given random demographic characteristics & surveying thousands of "AI people"
2/11
I wrote about how this can be huge for marketing research and copywriting Why Talk to Customers When You Can Simulate Them?
3/11
Turns out I'm not that crazy in using ChatGPT to evaluate my search and recommendations models before actual users see them.
Collect enough user demographics, and it should be possible to predict users' perception of the product ahead of time.
4/11
True. AI assistants could revolutionize coaching and mentorship.
5/11
This is fine
6/11
WILD
Because LLM is so cheap and fast compared to real people. At the very least, can use LLM as an initial pass to test how a product or service might be received in the market
So who is going to build the tool around these results? SurveyMonkeys of the world add AI?
7/11
Obviously love your work and regularly cite it in mine. "What I would welcome is some scenarios for in situ applications: people still find it hard to sense and visualise how this will change stuff in actual work settings.
8/11
interesting!
9/11
We think there might be something to these idea.
Someone should build a product that allows everyone to do this.
We even thought of a cool name: Synthetic Users.
10/11
Someone said AI People?
@aipeoplegame
11/11
I've been thinking for a while that we could make much better economic simulations by using LLMs.
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196